SELECT FACTORY_ID, FACTORY_NAME, ADDRESS
FROM FOOD_FACTORY
WHERE ADDRESS like "%강원도%"
ORDER BY FACTORY_ID ASC
Lv1. 동물의 아이디와 이름
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
ORDER BY ANIMAL_ID ASC
Lv1. 모든 레코드 조회하기
SELECT *
FROM ANIMAL_INS
ORDER BY ANIMAL_ID ASC
Lv1. 상위 n개 레코드
SELECT NAME from ANIMAL_INS order by DATETIME asc limit 5
Lv1. 아픈 동물 찾기
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE INTAKE_CONDITION = 'Sick'
ORDER BY ANIMAL_ID ASC
Lv1. 어린 동물 찾기
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE INTAKE_CONDITION != 'Aged'
ORDER BY ANIMAL_ID ASC
Lv1. 여러 기준으로 정렬하기
SELECT ANIMAL_ID, NAME, DATETIME
FROM ANIMAL_INS
ORDER BY NAME ASC, DATETIME DESC
Lv1. 역순 정렬하기
SELECT NAME, DATETIME
FROM ANIMAL_INS
ORDER BY ANIMAL_ID DESC
Lv1. 조건에 맞는 회원수 구하기
SELECT COUNT(*)
FROM USER_INFO
WHERE DATE_FORMAT(JOINED, '%Y') = '2021'
AND (AGE >=20 and AGE<=29)
Lv2. 3월에 태어난 여성 회원 목록 출력하기
# SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_FORMAT(DATE_OF_BIRTH, "%Y-%m-%d") as DATE_OF_BIRTH
# FROM MEMBER_PROFILE
# WHERE TLNO is not NULL and DATE_FORMAT(DATE_OF_BIRTH, '%m') = '03' and GENDER='W'
# ORDER BY MEMBER_ID ASC
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_FORMAT(DATE_OF_BIRTH, "%Y-%m-%d") as DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE MONTH(DATE_OF_BIRTH) = 3
AND TLNO IS NOT NULL
AND GENDER = 'W'
ORDER BY MEMBER_ID ASC
Lv2. 재구매가 일어난 상품과 회원 리스트 구하기
SELECT USER_ID, PRODUCT_ID
FROM ONLINE_SALE
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(*) >= 2
ORDER BY USER_ID ASC, PRODUCT_ID DESC
Lv4. 년, 월, 성별 별 상품 구매 회원 수 구하기
-- MySQL
SELECT YEAR(S.SALES_DATE) as YEAR, MONTH(S.SALES_DATE) as MONTH, I.GENDER as GENDER, count(DISTINCT(S.USER_ID)) as USERS
FROM USER_INFO as I RIGHT JOIN ONLINE_SALE as S ON (I.USER_ID = S.USER_ID)
WHERE I.GENDER IS NOT NULL
GROUP BY YEAR, MONTH, GENDER
ORDER BY YEAR, MONTH, GENDER ASC
Lv4. 서울에 위치한 식당 목록 출력하기
-- MySQL
SELECT I.REST_ID, I.REST_NAME, I.FOOD_TYPE, I.FAVORITES, I.ADDRESS, ROUND(AVG(R.REVIEW_SCORE), 2) as SCORE
FROM REST_INFO as I JOIN REST_REVIEW as R ON (I.REST_ID = R.REST_ID)
GROUP BY I.REST_ID
HAVING I.ADDRESS LIKE '서울%'
ORDER BY SCORE DESC, I.FAVORITES DESC
Lv4. 오프라인,온라인 판매 데이터 통합하기
SELECT *
FROM (
SELECT TO_CHAR(SALES_DATE, 'YYYY-MM-DD') as SALES_DATE, PRODUCT_ID, USER_ID, SALES_AMOUNT
FROM ONLINE_SALE
WHERE TO_CHAR(SALES_DATE, 'YYYY-MM') = '2022-03'
UNION ALL
SELECT TO_CHAR(SALES_DATE, 'YYYY-MM-dd') as SALES_DATE, PRODUCT_ID, NULL AS USER_ID, SALES_AMOUNT
FROM OFFLINE_SALE
WHERE TO_CHAR(SALES_DATE, 'YYYY-MM') = '2022-03'
)
ORDER BY SALES_DATE ASC, PRODUCT_ID ASC, USER_ID ASC
2. SUM, MAX, MIN
Lv1. 가장 비싼 상품 구하기
SELECT MAX(PRICE) as MAX_PRICE
FROM PRODUCT
Lv1. 최댓값 구하기
SELECT max(DATETIME)
FROM ANIMAL_INS
Lv2. 가격이 제일 비싼 식품의 정보 출력하기
-- 서브쿼리 이용해서 풀 것. 참고로 = 아닌 IN도 가능
SELECT PRODUCT_ID, PRODUCT_NAME, PRODUCT_CD, CATEGORY, PRICE
FROM FOOD_PRODUCT
WHERE PRICE = (SELECT MAX(PRICE) FROM FOOD_PRODUCT)
Lv2. 동물 수 구하기
SELECT count(ANIMAL_ID)
FROM ANIMAL_INS
Lv2. 중복 제거하기
SELECT count(unique(NAME))
FROM ANIMAL_INS
WHERE NAME is not NULL
Lv2. 최솟값 구하기
SELECT MIN(DATETIME)
FROM ANIMAL_INS
3. GROUP BY
Lv2. 가격대 별 상품 개수 구하기
SELECT TRUNC(price / 10000)*10000 as PRICE_GROUP, count(TRUNC(price / 10000)) as PRODUCTS
FROM PRODUCT
GROUP BY TRUNC(price / 10000)
ORDER BY TRUNC(price / 10000) ASC
Lv2. 고양이와 개는 몇 마리 있을까
SELECT ANIMAL_TYPE, count(ANIMAL_TYPE)
FROM ANIMAL_INS
GROUP BY ANIMAL_TYPE
order by ANIMAL_TYPE ASC
Lv2. 동명 동물 수 찾기
SELECT NAME, count(NAME) as COUNT
FROM ANIMAL_INS
WHERE NAME IS NOT NULL
GROUP BY NAME
HAVING count(*) >=2
ORDER BY NAME ASC
Lv2. 입양 시각 구하기(1)
-- SELECT TO_CHAR(DATETIME, 'HH24') as HOUR, count(TO_CHAR(DATETIME, 'HH24')) as COUNT
-- FROM ANIMAL_OUTS
-- WHERE TO_CHAR(DATETIME, 'HH24') BETWEEN '09' and '19'
-- GROUP BY TO_CHAR(DATETIME, 'HH24')
-- ORDER BY HOUR ASC
SELECT TO_CHAR(DATETIME, 'HH24') HOUR, COUNT(TO_CHAR(DATETIME, 'HH24')) COUNT
FROM ANIMAL_OUTS
GROUP BY TO_CHAR(DATETIME, 'HH24')
HAVING TO_CHAR(DATETIME, 'HH24') >= 9 and TO_CHAR(DATETIME, 'HH24') <= 19
ORDER BY TO_CHAR(DATETIME, 'HH24') ASC
Lv3. 즐겨찾기가 가장 많은 식당 정보 출력하기
SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
FROM REST_INFO
WHERE (FOOD_TYPE, FAVORITES) in (SELECT FOOD_TYPE, MAX(FAVORITES)
FROM REST_INFO
GROUP BY FOOD_TYPE)
ORDER BY FOOD_TYPE DESC
Lv4. 입양 시각 구하기(2)
-- MySQL
SET @HOUR:= -1;
SELECT (@HOUR:= @HOUR+1) as HOUR, (SELECT COUNT(*) FROM ANIMAL_OUTS WHERE HOUR(DATETIME) = @HOUR) as COUNT
FROM ANIMAL_OUTS
WHERE @HOUR < 23
-- Oracle
SELECT HOUR, COUNT(B.DATETIME) COUNT FROM (SELECT LEVEL-1 HOUR
FROM DUAL
CONNECT BY LEVEL<=24)
A LEFT JOIN ANIMAL_OUTS B ON A.HOUR = TO_CHAR(B.DATETIME, 'HH24')
GROUP BY HOUR
ORDER BY HOUR ASC
4. IS NULL
Lv1. 경기도에 위치한 식품창고 목록 출력하기
-- SELECT WAREHOUSE_ID, WAREHOUSE_NAME, ADDRESS, NVL(FREEZER_YN, 'N') as FREEZER_YN
-- FROM FOOD_WAREHOUSE
-- WHERE ADDRESS like '경기도%'
-- ORDER BY WAREHOUSE_ID ASC
-- SELECT WAREHOUSE_ID, WAREHOUSE_NAME, ADDRESS, CASE WHEN FREEZER_YN IS NULL THEN 'N' ELSE FREEZER_YN END
-- FROM FOOD_WAREHOUSE
-- WHERE ADDRESS like '경기도%'
-- ORDER BY WAREHOUSE_ID ASC
SELECT WAREHOUSE_ID, WAREHOUSE_NAME, ADDRESS, DECODE(FREEZER_YN, null, 'N', FREEZER_YN) as FREEZER_YN
FROM FOOD_WAREHOUSE
WHERE ADDRESS like '경기도%'
ORDER BY WAREHOUSE_ID ASC
Lv1. 나이 정보가 없는 회원 수 구하기
SELECT count(USER_ID) as USERS
FROM USER_INFO
WHERE AGE IS NULL
Lv1. 이름이 없는 동물의 아이디
SELECT ANIMAL_ID
FROM ANIMAL_INS
WHERE NAME IS NULL
ORDER BY ANIMAL_ID ASC
Lv1. 이름이 있는 동물의 아이디
SELECT ANIMAL_ID
FROM ANIMAL_INS
WHERE NAME IS NOT NULL
ORDER BY ANIMAL_ID ASC
Lv2. NULL 처리하기
-- SELECT ANIMAL_TYPE, NVL(NAME, 'No name') as NAME, SEX_UPON_INTAKE
-- FROM ANIMAL_INS
-- ORDER BY ANIMAL_ID ASC
-- SELECT ANIMAL_TYPE, DECODE(NAME, null, 'No name', NAME) as NAME, SEX_UPON_INTAKE
-- FROM ANIMAL_INS
-- ORDER BY ANIMAL_ID ASC
SELECT ANIMAL_TYPE, CASE WHEN NAME IS NULL THEN 'No name' ELSE NAME END as NAME, SEX_UPON_INTAKE
FROM ANIMAL_INS
ORDER BY ANIMAL_ID ASC
5. JOIN
Lv2. 상품 별 오프라인 매출 구하기
SELECT PRODUCT_CODE, (PRICE * sum(S.SALES_AMOUNT)) AS SALES
FROM PRODUCT as P RIGHT JOIN OFFLINE_SALE as S ON P.PRODUCT_ID = S.PRODUCT_ID
GROUP BY S.PRODUCT_ID
ORDER BY SALES DESC, PRODUCT_CODE ASC
Lv3. 보호소에서 중성화한 동물
-- MYSQL
SELECT I.ANIMAL_ID, I.ANIMAL_TYPE, I.NAME
FROM ANIMAL_INS AS I INNER JOIN ANIMAL_OUTS AS O on I.ANIMAL_ID = O.ANIMAL_ID
WHERE I.SEX_UPON_INTAKE like '%Intact%' and O.SEX_UPON_OUTCOME not like '%Intact%'
Lv3. 없어진 기록 찾기
-- Oracle
SELECT O.ANIMAL_ID, O.NAME
FROM ANIMAL_OUTS O
WHERE O.ANIMAL_ID NOT IN (SELECT ANIMAL_ID FROM ANIMAL_INS)
ORDER BY O.ANIMAL_ID, O.NAME ASC
-- Oracle 2
SELECT O.ANIMAL_ID, O.NAME
FROM ANIMAL_OUTS O
WHERE NOT EXISTS (SELECT * FROM ANIMAL_INS I WHERE O.ANIMAL_ID = I.ANIMAL_ID)
ORDER BY ANIMAL_ID
-- MySQL 1
SELECT O.ANIMAL_ID, O.NAME
FROM ANIMAL_OUTS AS O LEFT JOIN ANIMAL_INS AS I ON O.ANIMAL_ID = I.ANIMAL_ID
WHERE I.ANIMAL_ID IS NULL;
Lv3. 오랜 기간 보호한 동물(1)
-- MySQL
SELECT NAME, DATETIME
FROM ANIMAL_INS
WHERE ANIMAL_ID NOT IN (SELECT ANIMAL_ID FROM ANIMAL_OUTS)
ORDER BY DATETIME ASC
LIMIT 0, 3
-- ORACLE
SELECT A.NAME, A.DATETIME
FROM (
SELECT I.NAME, I.DATETIME
FROM ANIMAL_INS I LEFT OUTER JOIN ANIMAL_OUTS O ON (I.ANIMAL_ID = O.ANIMAL_ID)
WHERE O.ANIMAL_ID IS NULL
ORDER BY I.DATETIME ASC
) A
WHERE ROWNUM <= 3
Lv3. 있었는데요 없었습니다
-- ORACLE
SELECT I.ANIMAL_ID, I.NAME
FROM ANIMAL_INS I LEFT JOIN ANIMAL_OUTS O ON I.ANIMAL_ID = O.ANIMAL_ID
WHERE I.DATETIME > O.DATETIME
GROUP BY I.ANIMAL_ID, I.NAME, I.DATETIME
ORDER BY I.DATETIME ASC
Lv4. 5월 식품들의 총매출 조회하기
SELECT P.PRODUCT_ID, P.PRODUCT_NAME, P.PRICE * sum(O.AMOUNT) as TOTAL_SALES
FROM FOOD_PRODUCT as P RIGHT JOIN FOOD_ORDER as O ON (P.PRODUCT_ID = O.PRODUCT_ID)
WHERE YEAR(PRODUCE_DATE) = 2022 and MONTH(PRODUCE_DATE) = 05 and P.PRODUCT_ID IS NOT NULL
GROUP BY P.PRODUCT_ID
ORDER BY TOTAL_SALES DESC, PRODUCT_ID ASC
Lv4. 그룹별 조건에 맞는 식당 목록출력하기
-- ORACLE
SELECT P.MEMBER_NAME AS MEMBER_NAME, R.REVIEW_TEXT AS REVIEW_TEXT, TO_CHAR(R.REVIEW_DATE, 'YYYY-MM-DD') AS REVIEW_DATE
FROM MEMBER_PROFILE P INNER JOIN REST_REVIEW R ON P.MEMBER_ID = R.MEMBER_ID
WHERE R.MEMBER_ID IN (SELECT MEMBER_ID -- 리뷰 쓴 개수가 COUNT(*)인 경우에 대해 GROUP BY후 사람들 ID 출력
FROM REST_REVIEW
GROUP BY MEMBER_ID -- 사람들이 리뷰 쓴 개수가 COUNT(*)인 경우에 대해 GROUP BY.
HAVING COUNT(*) = (SELECT MAX(COUNT(*)) -- 최대 리뷰 쓴 사람들의 개수를 구함
FROM REST_REVIEW
GROUP BY MEMBER_ID)
)
ORDER BY R.REVIEW_DATE
Lv5. 상품을 구매한 회원 비율 구하기
-- MySQL
SELECT YEAR(SALES_DATE) as YEAR, MONTH(SALES_DATE) as MONTH, count(DISTINCT(I.USER_ID)) as PUCHASED_USERS, ROUND(count(DISTINCT(I.USER_ID)) / (SELECT count(DISTINCT(USER_ID)) FROM USER_INFO WHERE YEAR(JOINED) = 2021),1) as PUCHASED_RATIO
FROM USER_INFO AS I RIGHT JOIN ONLINE_SALE as S ON (I.USER_ID = S.USER_ID)
WHERE I.USER_ID in (SELECT USER_ID FROM USER_INFO WHERE YEAR(JOINED) = 2021)
GROUP BY YEAR(SALES_DATE), MONTH(SALES_DATE)
ORDER BY YEAR, MONTH ASC
6. String, Date
Lv2. 오랜 기간 보호한 동물(2)
SELECT A.ANIMAL_ID, A.NAME
FROM ANIMAL_INS A, ANIMAL_OUTS B
WHERE A.ANIMAL_ID = B.ANIMAL_ID
ORDER BY DATEDIFF(A.DATETIME, B.DATETIME) limit 0, 2
Lv2. 이름에 el이 없는 동물 찾기
-- MySQL 1
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE ANIMAL_TYPE = 'Dog' and (NAME like '%el%' or NAME like '%EL')
ORDER BY NAME ASC
-- MySQL 2
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE ANIMAL_TYPE = 'Dog' AND UPPER(NAME) LIKE '%EL%'
ORDER BY UPPER(NAME) ASC
Lv2. 중성화 여부 파악하기
SELECT ANIMAL_ID, NAME, CASE WHEN SEX_UPON_INTAKE like '%Neutered%' or SEX_UPON_INTAKE like '%Spayed%' THEN 'O' ELSE 'X' END as 중성화
FROM ANIMAL_INS
ORDER BY ANIMAL_ID
Lv2. 카테고리 별 상품 개수 구하기
SELECT SUBSTRING(PRODUCT_CODE, 1, 2) as CATEGORY, count(SUBSTRING(PRODUCT_CODE, 1, 2)) as PRODUCTS
FROM PRODUCT
GROUP BY SUBSTRING(PRODUCT_CODE, 1, 2)
Lv2. DATETIME에서 DATE로 형 변환
-- ORACLE
SELECT ANIMAL_ID, NAME, TO_CHAR(DATETIME, 'YYYY-MM-DD') as 날짜
FROM ANIMAL_INS
ORDER BY ANIMAL_ID ASC
-- MYSQL
SELECT ANIMAL_ID, NAME, DATE_FORMAT(DATETIME, '%Y-%m-%d') AS 날짜
FROM ANIMAL_INS
ORDER BY ANIMAL_ID ASC
Lv3. 조건별로 분류하여 주문상태 출력하기
SELECT ORDER_ID, PRODUCT_ID, DATE_FORMAT(OUT_DATE, '%Y-%m-%d'),
IF (OUT_DATE <= '2022-05-01', '출고완료', IF(OUT_DATE IS NULL, '출고미정', '출고대기')) as 출고여부
FROM FOOD_ORDER
ORDER BY ORDER_ID ASC
데이터 사이언스 직군으로 면접보며 받았던 질문에 대해 정리 (Last Update: 2022.11.29)
1. Deep Learning
Q1. ReLU의 단점을 설명하라.
ReLU의 경우 Sigmoid의 단점인 gradient vanishing 문제를 극복하기 위해 사용한 활성화 함수입니다. ReLU의 장점은 입력값을 그대로 출력하기 때문에 구현이 쉽고 빠른 학습이 가능합니다. 반면 단점은 Dead ReLU 현상으로 만약 입력값이 음의 값이 들어온다면 이를 처리하지 못하는 것입니다. 이와 같이 음의 값을 처리하지 못하는 단점을 보완하기 위해 LeakyReLU와 같은 활성화함수를 사용합니다.
Q2. 모델의 일반화 성능을 위해 사용할 수 있는 방법을 설명하라.
모델 일반화 성능 향상을 위해 크게 3가지 관점으로 접근할 수 있습니다. 첫 번째는 데이터 관점, 두 번째는 모델 관점, 세 번째는 하이퍼파라미터 관점입니다. 첫 번째 데이터 관점에서는 학습 데이터셋을 추가하거나 어그멘테이션을 통해 모델 성능을 향상시킬 수 있습니다. 또 학습 데이터셋에 전처리를 통해 더미값과 같은 데이터를 제거해줌으로써 모델 성능을 향상시킬 수 있습니다. 두 번째 모델 관점에서는 트랜스포머 모델을 사용해 RNN 계열 모델의 단점인 long-term dependency와 비병렬성을 극복한 것처럼 더 좋은 모델 아키텍처를 사용하는 방법이 있습니다. 이를 위해 NAS(Neural Architecture Search)와 같은 알고리즘을 사용할 수 있습니다. 또 모델에 오버피팅을 줄이기 위해 BREDLAN이라고하여Batch Normalization,Regularization,Early Stopping,Dropout,Label Smoothing,Augmentation,Noise Robustness를적용할 수 있습니다. 마지막 하이퍼파라미터 관점에서는 Random Search나 Grid Search, HyperBand, Keras Tuner등을 통해 손실함수, 학습률, 활성화함수, Optimizer 등의 하이퍼파라미터의 최적값을 찾음으로써 모델의 성능을 향상시키고 일반화할 수 있습니다.
Q3. Word2vec 모델에 대해 설명하라.
word2vec 모델은 2013년에 나온 모델로 기존의 NNLM(Neural Network Language Model)의 단점을 보완하고자 나온 모델이라 할 수 있습니다. 기존 NNLM 모델은 단어를 벡터화시키기 위해 discrete한 방식인 one-hot encoding 방식을 사용했습니다. 하지만 이 방식은 sparse-matrix가 만들어지기 때문에 고차원 상에서 비효율적으로 분산 표상되어 학습이 잘 이루어지지 않습니다. 때문에 이를 continous하게 표상할 수 있도록 만들어진 모델이 word2vec 입니다. word2vec은 내부적으로 학습방식이 CBOW와 Skip-gram으로 나뉩니다.CBOW는 주변단어인 context에 기반해 중심단어를 예측하는 방식이며 Skip-gram은 중심단어에 기반해 주변단어를 예측하는 방식입니다. 두 방식 모두 Input layer, projection layer, output layer 3가지 레이어로 구성되어 동작합니다.
Q4. CNN의 장점과 단점을 설명하라.
CNN의 장점은 DNN의 단점을 극복한 것입니다. DNN을 통해 3차원인 이미지를 학습한다면 많은 수의 파라미터가 필요하고 오버피팅이 일어나기 쉽습니다. 반면 CNN을 사용하면 DNN에 비해 파라미터 수를 감소시켜 학습이 가능합니다. 또 DNN과 달리 CNN은 이미지의 공간적 형태를 보존합니다. DNN은 이미지의 픽셀간 관계를 고려하지 않고 1차원으로 flatten시키지만 CNN은 픽셀간 관계를 고려할 수 있습니다. CNN의 단점은 풀링 과정에서 정보손실이 발생하는 것입니다. 풀링 과정을 거치면서 정보가 요약됩니다. 이 때 각각의 local feature의 상대적인 위치 정보를 잃을 수 있습니다.
Q4-1 CNN의 동작원리를 설명해라. (예상)
우선 CNN의 구조는 convolution layer와 pooling layer, fully-conncected layer로 구성됩니다. convolution layer를 통해 Input image로부터 feature map을 추출합니다. 추출 과정은 input image에 filter로 슬라이딩 윈도우를 통해 합성곱을 계산하는 방식으로 이루어집니다. 이후 pooling layer를 통해 feature map의 크기를 줄이고 feature를 추출합니다. 최종적으로 flatten 시킨 다음 fully-connected layer에 입력하여 최종 결과를 출력하는 방식으로 동작합니다.
Q5. RNN의 장점과 단점을 설명하라.
RNN은 시퀀셜 데이터를 처리하기 위해 사용하는 신경망의 한 종류입니다. RNN의 장점은 정의 자체로서 시퀀셜 데이터를 처리할 수 있다는 데 있습니다. 반면 단점은 long-term dependency 문제가 있고 RNN 구조상 병렬처리가 불가능합니다. 이러한 RNN 계열의 단점을 극복하기 위해 Transformer가 고안되었습니다. Transformer는 attention 메커니즘을 사용해 RNN 계열의 단점인 long-term dependency 문제와 비병렬성 문제를 해결했습니다.
Q5-1. RNN의 동작원리를 설명해라. (예상)
RNN은 크게 Input layer, hidden layer, output layer로 구성되어 있습니다. RNN의 가장 큰 특징은 은닉층이 이전 데이터를 참조하도록 연결되어 있다는 것입니다. 즉 만약 t시점에서 입력 데이터가 들어왔다면 t시점에서 출력하는 것 뿐만 아니라 t+1 시점의 출력에도 영향을 미칩니다. 따라서 시퀀셜한 데이터 처리에 적합하다는 장점이 있습니다. 반면 단점은 long-term dependency 문제가 발생합니다. 가령 오래된 시점에서 입력된 데이터의 영향이 뒤로 갈수록 적어지는 것을 의미합니다. 이러한 문제점을 해결하기 위해서는 LSTM에서 cell state란 개념을 도입해 이를 해결했습니다.
Q5-2. long-term dependency 문제가 발생하는 이유는 무엇인가요?
핵심은 기울기 폭발과 기울기 소실 문제 때문입니다. RNN은 활성화함수로 tanh를 사용합니다. tanh는 -1과 1사이의 값을 가집니다. 이 때 1보다 작은 값이 반복해서 곱해지기 때문에 feed-forward 관점에선 앞의 정보를 충분한 세기로 전달할 수 없고 back-propagation 관점에서는 tanh 함수의 기울기가 0에 가깝거나 큰 값이 발생할 수 있어 기울기 폭발과 소실 문제가 발생합니다. 참고로 이 때문에 LSTM에서는 기존 RNN 구조에 cell state라는 변수를 추가함으로써 long-term dependency 문제를 해결합니다.
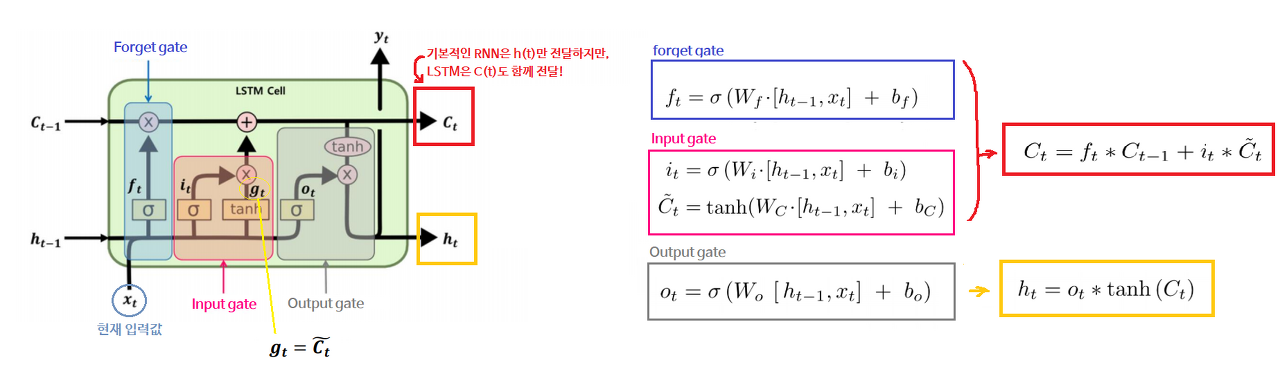
Q5-3. LSTM의 동작원리를 설명해라. (예상)
LSTM은 RNN 계열 모델로 RNN의 단점인 long-term dependency 문제를 해결하기 위해 만들어졌습니다. 이 장기의존성 문제를 해결하기 위핸 핵심 개념은 cell-state입니다. LSTM의 구조는 RNN과 유사하지만 내부적으로 게이트가 3개 있습니다. forget gate, input gate, output gate입니다. forget gate에서는 이전의 hidden state와 현재 시점의 Input을 받아 sigmoid 함수를 거쳐 0과 1사이의 값으로 출력합니다. 1이 출력되면 위 cell state의 값과 점곱을 통해 그대로 보내주고 0이 출력되면 cell state의 값이 0으로 초기화 됩니다. 만약 0~1 사이 값이 나오면 일부 정보는 지워진 채 cell state에 업데이트 됩니다. 이후 두 번째 Input gate에서는 sigmoid 함수와 tanh 함수가 있습니다. sigmoid 함수를 거쳐 나온 값과 tanh를 거쳐 나온 값을 점곱을 통해 cell state에 업데이트 해줍니다. 마지막으로 output gate에서는 hidden state 값과 현재 시점의 input값을 마찬가지로 sigmoid 함수를 거친 뒤 tanh함수와 점곱되어 출력됩니다. 그러면 최종적으로 다음 레이어로 넘어갈 cell state가 완성되는 형태입니다. 이러한 LSTM 구조를 사용할 경우 기존의 RNN에서 발생하는 long-term dependency 문제를 해결할 수 있습니다.
Q6. 트랜스포머 구조에 대해 설명하라.
트랜스포머 구조는 크게 인코더와 디코더로 구성이 되어 있습니다. 소스 시퀀스를 인코더에 넣고 압축한 다음 디코더를 통해 타겟 시퀀스를 생성하는 방식으로 동작합니다. 인코더에는 크게 3가지로 MultiHeadAttention 레이어, Poisitionwise FeedForward 레이어, skip connection이 포함된 Layer Normalization 레이어로 구성되어 있습니다. 반면 디코더도 동일하지만 추가적으로 Masked MultiHeadAttention 레이어가 포함되어 있습니다. 트랜스포머의 핵심은 self-attention 메커니즘을 사용한 Query, Key, Value 행렬의 Interaction이라 할 수 있습니다. $Softmax({QK^T \over \sqrt{d_K}})V$로 표현하며 동작 방식은 Query 행렬과 Key 행렬의 전치행렬을 곱해준 다음 smoothing을 위해 $\sqrt{d_K}$ 차원으로 나눠줍니다. 이후 softmax 함수를 취해준 다음 Value 행렬을 곱해주는 방식입니다.
Q7. Adam Optimizer 동작을 설명하라.
먼저 학습은 모델의 예측값과 정답값 사이의 오차를 최소화하는 방향인 Gradient를 구하고 이 방향에 맞춰 모델 전체 파라미터를 업데이트 하는 과정입니다. 이 오차를 최소화 하는 과정을 최적화라고하며 Optimizer는 이 최적화를 위해 사용합니다. 종류는 Stochastic Gradient Descent부터, Momentum, AdaGrad, RMSProp, AdaDelta, Adam, NAdam, Radam, AdamW, AdamP 등이 있습니다. 여기서 Adam이란 Adaptive Moment Estimation을 의미하는 것으로 수리통계학의 적률(모멘트)이란 개념에 기반합니다. (추가 작성 예정)
Adam은 RMSProp과 Momentum 방식을 합쳐 만든 알고리즘입니다. 기울기값의 지수평균과 기울기 제곱값의 지수평균을 활용해 step size를 조절합니다. Adam은 RMSProp과 Momentum 방식을 합쳐 만든 알고리즘입니다. RMSProp와 마찬가지로 기울기 제곱값의 지수 평균을 저장하고, Momentum과 마찬가지로 기울기를 계산했던 것의 지수 평균을 저장합니다.
Q8. GAN에 대해서 설명하라.
GAN이란 크게 생성자(Generator)와 판별자(Discriminator)로 구성된 모델로 동시에 두 개의 모델을 훈련합니다. 생성자는 최대한 fake 이미지를 만들고 판별자는 최대한 fake 이미지를 탐지하도록 경쟁하는 구조입니다. GAN의 학습목표는 생성자가 생성한 이미지를 판별자가 맞출 확률이 1/2에 수렴하도록하여 진짜 이미지와 가짜 이미지를 구분할 수 없도록 하는 nash equilibrium을 찾는 것입니다.
Q9. Auto Encoder에 대해 설명하라.
Auto Encoder는 크게 인코더와 디코더의 구조로 구성되어 있습니다. 인코더와 디코더의 중간에 있는 hidden layer는 Input layer보다 적은 수의 뉴런을 두는 bottleneck을 두어 차원을 줄여 압축하고 다시 디코더를 통해 압축된 데이터를 복원시키는 방식으로 동작합니다. 데이터를 압축하는 과정에서 추출한 의미있는 데이터를 보통 latent vector, z로 표현합니다. 즉 Auto Encoder는 학습을 통해 이 latent vector를 자동으로 추출해주는 모델이라 할 수 있습니다.
Q11. ViT에 대해 설명하라.
ViT는 이미지를 16x16으로 나눠 트랜스포머에 아키텍처에 입력하는 모델입니다. CNN에서 사용하던 필터를 없애고 어텐션으로 대체했습니다. 이미지를 16x16 패치로 나누어 토큰화하여 트랜스포머 아키텍처에 입력합니다. 하지만 트랜스포머는 자연어처리를 위해 만들어진 아키텍처이기 때문에 CNN에 비해 *inductive bias가 부족했기에 기존 CNN을 사용하는 것보다 성능이 떨어졌습니다. 하지만 JFT-300M 데이터셋을 이용해 3억장의 이미지를 학습한 결과 CNN 보다 더 좋은 성능을 얻을 수 있었습니다.
*inductive bias: 학습시 만나보지 못한 상황에 대해 정확히 예측하기 위해 사용하는 추가적인 가정.
CNN은 지역성(Locality)이란 가정을 활용해 공간적(spatial)인 문제를 해결함
RNN은 순차성(Sequentiality)이란 가정을 활용해 시계열(time-series)인 문제를 해결함
Q12. Diffusion model에 대해 설명하라.
Diffusion model은 generative model 중 하나입니다. 컴퓨터 비전에서 사용됩니다. 데이터에 노이즈를 조금씩 추가해가면서 데이터를 완전한 노이즈로 만드는 forward process가 있고 이와 반대로 노이즈로부터 조금씩 복원해가면서 데이터를 만들어내는 reverse process가 있습니다. (추가 필요)
Q13. Batch Normalization에 대해 설명하라.
Batch Normalization은 activation function의 출력값을 정규화하는 방식입니다. 정규화를 위해 미니 배치마다 평균과 분산을 구해 표준정규분포를 따르도록 만들어주는 방식으로 동작합니다. 이러한 batch normalization이 필요한 이유는 입력 데이터마다 다양한 분포를 갖기 때문에 학습에 있어 모델의 일반화 성능을 가져오기 못하기 때문입니다. 만약 다양한 분포를 가진채로 학습하게 되면 gradient descent에 따른 업데이트 되는 weight에 영향력이 달라지기 때문입니다.
2. Machine Learning
Q1. 앙상블 기법 종류와 특징에 대해 설명하라.
앙상블 기법은 크게 3가지로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)이 있습니다. 보팅은 여러 개의 분류기를 통해 최종 예측 결과를 결정합니다. 크게 하드 보팅과 소프트 보팅이 있습니다. 하드 보팅은 분류기의 예측 결과를 다수결 투표를 진행하는 것을 말하고 소프트 보팅은 분류기의 예측 결과의 확률값의 평균 또는 가중합 하는 것을 말합니다. 배깅도 보팅과 마찬가지로 여러 개의 분류기를 통해 나온 예측 결과값을 다수결 투표를 통해 결정하는 것을 말합니다. 차이점이 있다면 보팅은 서로 다른 분류기를 사용하고 배깅은 서로 같은 분류기를 사용해 다수결 투표를 진행하는 것입니다. 배깅의 대표적인 알고리즘은 랜덤 포레스트가 있습니다. 부스팅은 배깅과 비슷합니다. 다만 차이점이 있다면 배깅은 서로 같은 모델들이 독립적으로 학습하여 최종 예측 결과를 내지만 부스팅은 이전 모델의 결과를 기반으로 순차적으로 학습합니다. 가령 첫 번째 모델이 학습한 결과를 기반으로 두 번째 모델이 학습하고 두 번째 모델 결과를 기반으로 세 번째 모델이 학습하는 방식입니다. 이 때 학습 데이터의 샘플 가중치가 계속해서 조절되는 것이 특징입니다. 이러한 부스팅은 오답에 대해 높은 가중치가 부여될 수 있어 outlier에 취약하단 단점이 있습니다. 이러한 부스팅에는 XGBoost나, AdaBoost, GradientBoost과 같은 종류의 알고리즘이 있습니다.
Q2. 랜덤 포레스트에 대해 설명하라. (예상)
랜덤 포레스트는 앙상블 기법 종류 중 배깅 방식에 속하는 알고리즘입니다. 배깅 방식의 특징은 부트스트래핑을 통해 데이터를 랜덤 샘플링하는 과정이 있습니다. 랜덤 포레스트는 다수의 의사결정트리를 만들고 각각의 트리에서 랜덤 샘플링된 데이터를 학습한 다음 최종 예측 결과를 투표하는 방식으로 동작합니다. 또 랜덤 포레스트는 단일한 의사결정트리를 사용했을 때 오버피팅될 수 있다는 단점을 극복하기 위해 만들어진 것이기에 오버피팅을 감소시켜주고 비교적 일반화된 성능을 낼 수 있다는 장점이 있습니다.
Q3. XGBoost와 LightGBM에 대해 설명하라. (예상)
XGBoost와 LightGBM은 모두 앙상블 기법 종류 중 부스팅 방식에 해당하는 알고리즘입니다. 공통적으로 Gradient Boosting Machine에 기반한 방식입니다. XGBoost는 GBM의 3가지 단점을 개선했습니다. 첫 번째로 GBM은 병렬처리가 되지 않아 속도가 느렸다는 한계가 있었고 이를 해결하여 병렬처리를 통해 수행 속도를 빠르게 했습니다. 두 번째는 GBM에 Regularization 기능이 없어 오버피팅이 발생할 수 있단 한계가 있었지만 XGBoost는 자체적으로 Regularization 기능을 포함하고 있습니다. 세 번째로 Early Stopping 기능이 있다는 장점이 있습니다. Decision Tree 기반 알고리즘 중 성능이 우수하다고 알려져 있어 Kaggle과 같은 곳에서 많이 사용되고 있습니다. LightGBM은 XGBoost가 만들어지고 2년뒤에 만들어진 부스팅 알고리즘입니다. XGBoost가 GBM에 비해 빠르지만 여전히 학습 시간이 오래걸린다는 단점이 있습니다. 때문에 LightGBM은 이러한 XGBoost의 느린 학습 시간이라는 단점을 보완했고 또 메모리 효율성을 가져온 알고리즘입니다.
Q4. Gradient Descent에 대해 설명하라.
Gradient Descent는 cost function의 값이 최소가 되게 하는 가중치를 찾는 알고리즘입니다. 신경망에서 back-propagation을 위해 사용되며 cost function을 미분한 다음 learning rate를 곱해주고 체인룰을 적용해 앞단에 위치한 레이어의 가중치를 업데이트 하는 방식으로 동작합니다. 이 Gradient Descent 방식은 전체 데이터를 사용해 기울기를 계산하기 때문에 학습에 많은 시간이 필요하단 단점이 있습니다. 때문에 이런 단점을 보완하기 위해 미니 배치 사이즈로 나누어 학습을 진행하는 Mini-Batch Stochastic Gradient Descent 방식이 사용되기도 합니다.
Q5. Bias-Variance Trade-off에 대해 설명해주세요. (예상)
Bias는 under-fitting과 관련 있는 것으로 모든 데이터를 고려하지 못해 지속적으로 잘못된 것을 학습하는 경향입니다. 만약 Bias가 높으면 예측과 정답의 차이가 크게 벌어진 상황을 의미하고 Bias가 낮다면 예측과 정답이 차이가 작은 상황을 의미합니다. 반면 Variance는 over-fitting과 관련 있는 것으로 데이터 내에 노이즈까지 잘 잡아내어 실제 정답과 관련 없는 random한 것 까지 학습하는 경향을 의미합니다. variance가 높다는 것은 예측값과 정답값 간의 범위가 멀다는 것을 의미하고 variance가 낮다는 것은 예측값과 정답값 간의 범위가 좁다는 것을 의미합니다.
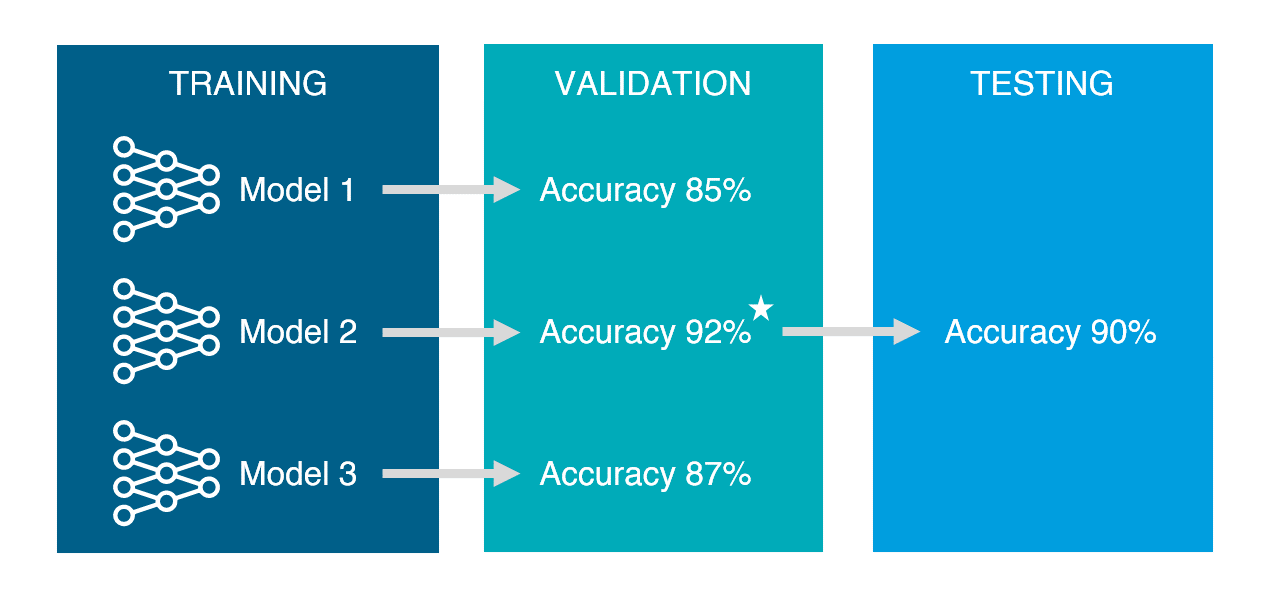
Q6. Training, Validation, Testing 셋으로 나누는 이유에 대해 설명하라. (예상)
먼저 Training set은 모델 학습을 목적으로 사용합니다. 만약 training set을 평가에 사용한다면 이미 한 번 본 시험으로 재시험을 보는 것과 같기에 별도의 validation set이나 testing set으로 나누어 주어야 합니다. 이후 validation set의 경우 training set으로 만든 모델의 성능을 측정하기 위해 사용합니다. 이를 위해 다양한 모델과 파라미터를 사용해가며 validation set에 적합한 모델을 선택해야 합니다. 이후 마지막으로 testing set을 이용해 단 한번 모델의 성능을 측정하기 위해 사용합니다. 이후 training set, validation set, testing set을 모두 합쳐 다시 모델을 학습하여 최종 모델을 만듭니다. 간단한 비유를 하자면 training set은 월별 모의고사고 validation set은 그 중에서도 9월 모의고사처럼 실제와 비슷할 것이라 판단되는 모의고사이며 마지막 testing set을 통해 수능을 보는 것과 같습니다.
Q7. K-fold cross validation에 대해 설명하라. (예상)
K-fold cross validation이란 전체 데이터에서 training set과 validation set을 번갈아가며 나누는 방법을 의미합니다. 예를 들어 전체 데이터를 5분할을 한다면 처음엔 가장 첫 번째 분할을 validation set으로 두고 나머지 네 개의 분할을 training set으로 두고 두 번째 학습에는 두 번째 분할을 validation set으로 두고 나머지 분할을 training set으로 두는 것과 같습니다. 이렇 게 하는 이유는 데이터셋의 크기가 작을 경우 validation set에 대한 성능평가 신뢰성이 떨어지기 때문입니다. 즉 특정 validation set에만 적합한 모델을 피하고 전체 데이터셋에 균형 잡힌 학습을 위해 사용합니다.
3. Probability/Statistics
Q1. Posterior, Prior, Likelihood에 대해 설명하라.
이 세 개의 개념은 베이즈 정리에 사용됩니다. 베이즈 정리란 Prior, Likelihood, Evidence를 통해 Posterior를 예측하는 방법입니다. Prior는 사전에 이미 알고 있는 확률을 뜻하고 Posterior는 새로 추정된 확률을 뜻합니다. Likelihood는 Probability와 대조적인 특징이 있습니다. Probability는 확률분포를 이미 알고 있다는 가정하에 확률변수값이 계산됩니다. 반면 Likelihood는 확률과달리 확률분포를 모른다는 가정하에 주어진 관측을 통해 확률분포를 추정해나가는 방식입니다. Probability는 특정 사건 발생확률을 더하면 1이될 수 있지만 Likelihood는 그렇지 않습니다. 즉 요약하면 사전확률과 가능도와 새로 관측된 데이터를 통해 사후확률을 계산하는 것이 베이즈 정리입니다. 이 베이즈 정리는 조건부 확률에 기반하며 손쉽게 유도가능합니다.
Q1-1. 베이즈 정리 예시를 설명해라.
Q2. Hidden Markov Chain에 대해 설명하라.
히든 마르코프 체인의 경우 마르코프 체인을 기반으로 합니다. 마르코프 체인이란 마르코프 성질을 가진 이산확률과정입니다. 마르코프 성질이란 미래 상태는 현재 상태에 의해 결정되는 성질입니다. 즉 인과성이 있다는 것입니다. 또 이산확률과정이란 시간의 흐름에 따라 확률적인 변화를 가지는 구조를 의미합니다. 마르코프 성질의 대표적인 예시로는 날씨 예측이 있고 아닌 예시로는 매 번 독립 시행인 동전던지기가 있습니다. 히든 마르코프 체인의 경우 이러한 마르코프 체인에서 확장된 것으로 시스템이 은닉 상태와 관찰 가능한 결과 두 가지의 요소로 이뤄진 모델입니다. 관찰 가능한 결과는 은닉 상태에 의해 결정되지만 은닉 상태는 직접적으로 볼 수 없습니다. 오로지 마르코프 과정을 통해 도출된 결과만 관찰할 수 있습니다. 이런 히든 마르코프 체인은 주로 시퀀셜한 데이터를 다루는데 강점이 있습니다.
Q3. Entropy, Cross entropy,KL-divergence에 대해 설명하라.
entropy는 불확실성을 뜻하는 것으로 확률분포에서 확률변수 X의 기대값을 의미합니다. 수식으로는 $\displaystyle H(x) = -\sum_{i=1}^n p(x_i)\log p(x_i)$로 정의할 수 있습니다. cross entropy 같은 경우엔 entropy가 단일 확률분포에서 어떤 확률변수가 나타날 불확실성이었으면 cross entropy는 두 확률분포 간의 차이를 나타내는 척도라고 할 수 있습니다. 수식으로는 $\displaystyle H_{p, q}(x) = -\sum_{i=1}^n p(x_i)\log q(x_i)$로 나타냅니다. 마지막으로 KL-divergence는 두 확률분포 간의 차이를 나타내는 척도입니다. cross-entropy에서 entropy를 뺀 값이며, 수식으로는 $\displaystyle KL(p||q) = \sum_{i=1}^n p(x) \log {p(x)\over q(x)}$로 나타냅니다. 사실상 cross entropy와 거의 동일해 KL-divergence를 최소화 하는 것은 cross entropy를 최소화 하는 것과 같습니다. 하지만 KL-divergence에 있는 $p(x)\log p(x)$는 모델이 예측하고자 하는 실제 모집단분포이므로 바뀌지 않고 알 수 없는 값입니다. 따라서 cost function으로 사용하려면 상수 취급되어 계산에 포함하지 않아야 합니다. 그러면 남는 것은 $\displaystyle -\sum_{i=1}^n p(x_i) \log q(x_i)$이고 이는 곧 cross entropy를 의미합니다.
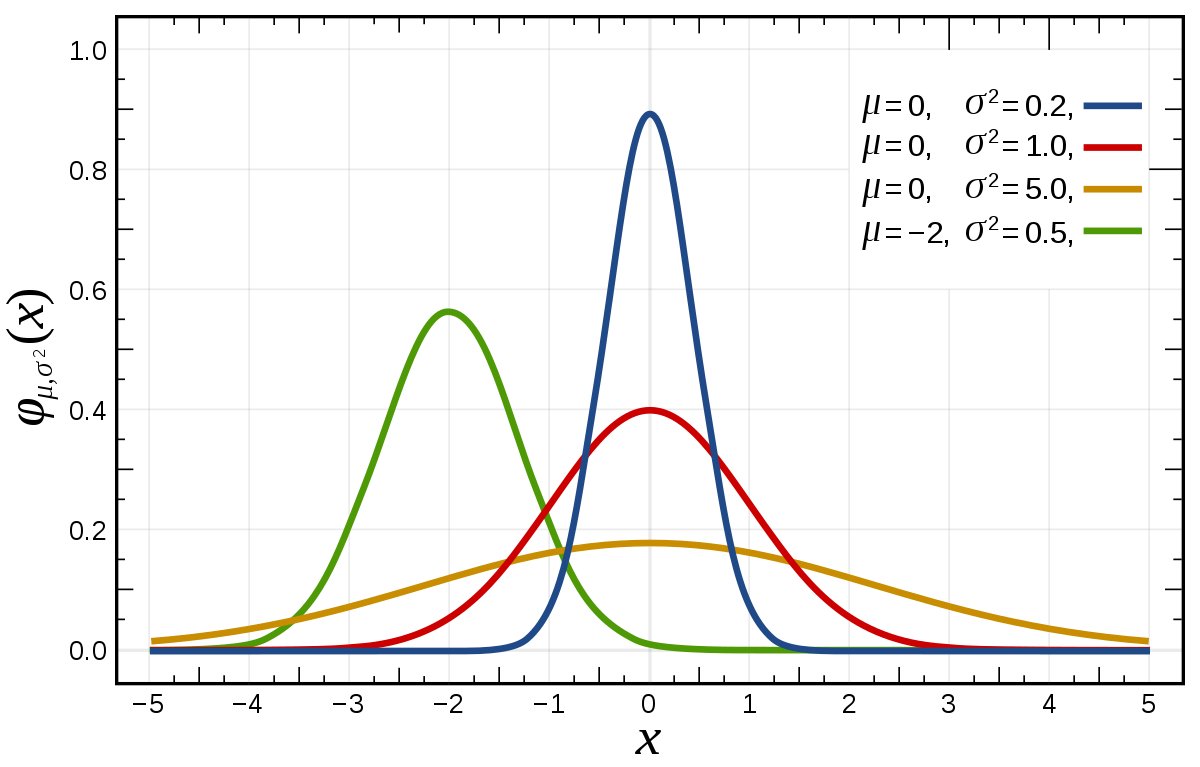
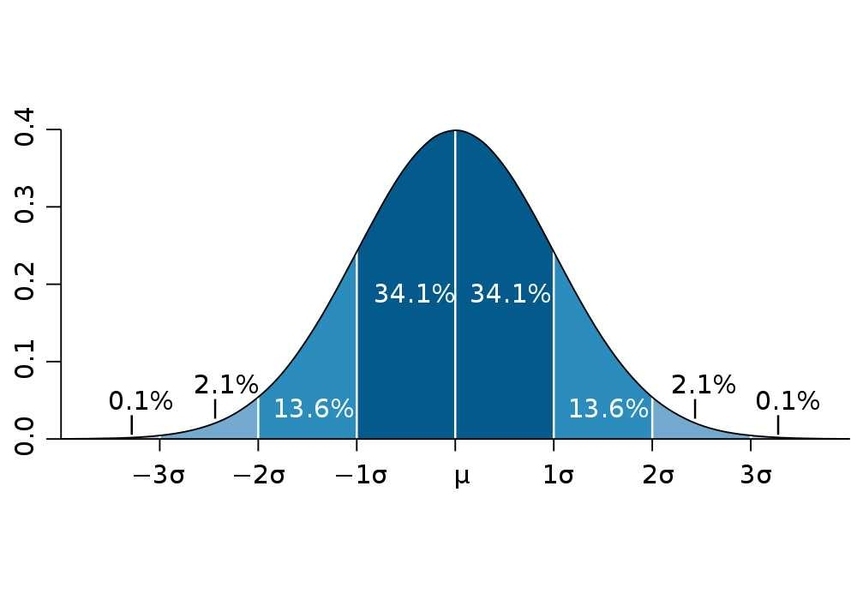
Q4. 정규분포에 대해 설명해주세요. (예상)
정규분포는 여러 확률분포함수 중에서 연속확률분포에 속하는 분포입니다. 수식은 $\displaystyle f(x) = {1 \over \sqrt{2\sigma^2}} \exp (- {(x-\mu)^2 \over 2\sigma^2})$로 나타냅니다. 이 정규분포는 평균과 분산 값에 따라 다양한 정규분포를 갖게 됩니다. 그 중 평균이 0, 분산이 1인 정규분포를 표준정규분포라 합니다. 이런 정규분포의 특징은 평균을 기준으로 대칭성을 띤다는 것입니다. 따라서 평균 기준 왼쪽과 오른쪽은 각각 0.5의 확률을 같습니다. 또 정규분포별 평균과 분산이 다르더라도 표준편차 구간 별 확률은 어느 정규분포에서나 같다는 것입니다.
Q5. 이항분포에 대해 설명해주세요. (예상)
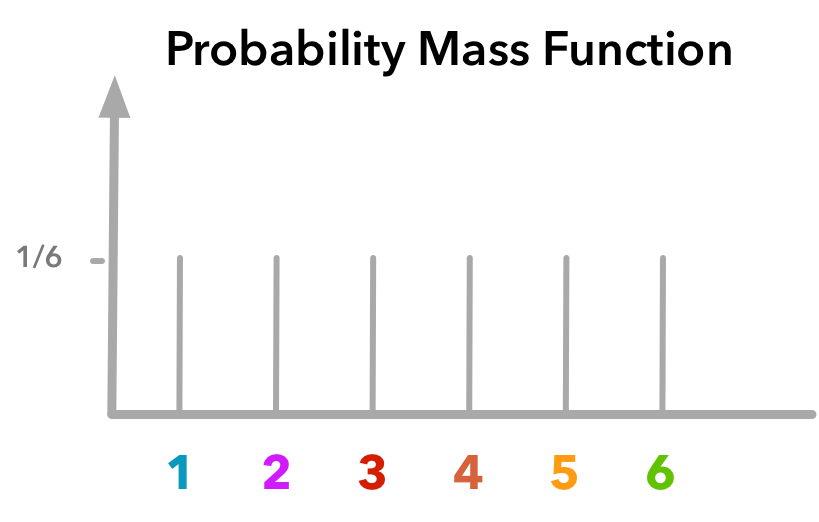
이항분포는 베르누이 시행을 n번 시행한 것 입니다. 어떤 사건 A가 발생할 확률이 p일 때 베르누이 시행을 n번 시행한다면 사건 A가 몇번 발생하는지를 확률변수로 두는 분포입니다. 수식으로는 $\displaystyle {}_n C{}_r p^r (1-p)^{n-r}$로 표현합니다. 평균 $E(x)$는 $np$입니다. 또 분산 $V(x)$는 $np(1-p)$입니다. 가장 흔한 예시로는 주사위를 n번 던졌을 때 특정 숫자가 나올 확률이 어떻게 되는가를 구할 때 사용합니다. 특정 숫자가 나올 확률은 ${1 \over 6}$ 이므로 $\displaystyle {}_n C {}_r {1\over 6}^r {5\over 6}^{n-r}$로 나타낼 수 있습니다.
벨만 기대 방정식은 강화학습에 사용됩니다. 벨만 기대 방정식은 현재 상태의 가치함수와 다음 상태의 가치함수 사이의 관계를 나타낸 식입니다. 여기서 가치함수란 에이전트가 다음 상태로 갈 경우 앞으로 받을 전체 보상에 대한 기대값입니다. 가치함수는 현재 에이전트의 정책에 의해 영향을 받는데, 이 정책을 반영한 식이 벨만 기대 방정식이라 합니다. 정의상 기대값을 알려면 모든 보상에 대해 고려해야하지만 물리적으로 불가능 하므로 하나의 변수를 두고 그 변수를 계속해서 업데이트하는 과정으로 계산됩니다. (추가 필요)
Q2. DQN에 대해 설명하라. 또 DQN의 수식의 의미를 설명하라.
5. Computer Science
Q0. 프로세스와 쓰레드의 차이는 무엇인가?
Q0. 쓰레드의 특징은 무엇인가?
Q1. 캐시는 왜 사용하는가?
캐시를 사용하는 핵심 이유는 CPU 처리속도와 메모리 처리속도 차이에서 발생하는 병목현상을 해결하기 위해 사용합니다. 주기억장치인 메모리에 있는 데이터에 접근하는 시간을 줄이기 위해 CPU와 메모리 사이에 캐시 메모리를 둡니다. 캐시 메모리에는 주기억장치 내에서 자주 읽고 쓰는 데이터의 일부를 캐시 메모리에 불러와 속도 차이를 줄입니다. 그리고 캐시 메모리에는 적중률이라는 개념이 있습니다. CPU가 메모리에 접근하기 전에 캐시 메모리에 먼저 원하는 데이터가 존재하는지 여부를 확인하는데 이 때 있다면 적중한 것이고 없다면 실패한 것입니다. 캐시 메모리를 효율적으로 활용하기 위해서는 적중률이 높아야하고 이를 위해 지역성이라는 개념을 사용합니다. 크게 시간적 지역성, 공간적 지역성, 순차적 지역성 세 가지가 있습니다. 시간적 지역성은 최근 액세스된 메모리 영역은 근 미래에 다시 액세스할 가능성이 높다는 것을 뜻하고, 공간적 지역성은 CPU가 참조한 데이터와 인접한 영역에 있는 데이터 역시 참조될 가능성이 높음을 의미합니다. 마지막으로 순차적 지역성은 메모리에 데이터가 저장된 순서대로 이용될 가능성이 높다는 것입니다.
Q2. vCPU란 무엇인가?
클라우드 환경에서 만들어지는 가상화 머신에 할당되는 형태의 CPU를 말합니다. 실제 물리적인 CPU 코어를 논리적으로 분할하여 가상화 머신에 할당하는 형태입니다.
Q3. HDD, SSD, DRAM의 차이는 무엇인가?
핵심 차이는 속도라고 할 수 있습니다. DRAM이 가장 빠르고 SSD가 그다음 HDD가 마지막입니다. DRAM은 Dynamic Random Access Memory로서 RAM의 한 종류입니다. 이외의 종류는 Static Random Access Memory인 SRAM이 있습니다. SRAM은 속도가 빨라 캐시로 사용되고 DRAM은 속도가 상대적으로 느린 대신 용량이 크다는 특징이 있습니다. SSD Solid State Drive의 약자로 비휘발성 저장장치 입니다. 물리적으로 데이터가 위치하는 원판까지 플래터를 이동시켜야하는 HDD와 달리 전자적으로 정보를 읽고 쓰기 때문에 속도가 빠르다는 장점이 있습니다.
Q4. 가상 메모리를 왜 사용 하는가?
가상 메모리를 사용하는 핵심 이유는 과거 메모리 용량의 한계가 있던 때, 메모리 크기보다 큰 프로세스를 실행시키기 위한 방법이 필요했습니다. 때문에 이를 해결하고자 디스크에서 프로세스 실행에 필요한 부분만 메모리에 적재하고 실행시킬 수 있도록 한 것입니다. 이 가상 메모리를 구현하기 위해서는 MMU라는 Memory Management Unit이 필요합니다. MMU는 가상 메모리에 사용되는 가상 주소를 실제 물리 주소로 매핑해주는 역할을 합니다. 이 때 모든 가상 주소를 물리 주소로 바꾸려면 많은 부하가 생길 수 있으므로 메모리를 페이지라는 단위로 나누어 효율적으로 처리합니다.
Q5. 페이지 폴트란 무엇입니까? (예상)
페이지 폴트란 CPU가 프로세스 실행에 필요한 단위인 페이지를 요청 할 때 그 페이지가 실제로 메모리에 적재되어 있지 않을때 발생하는 인터럽트입니다. 만약 페이지 폴트가 발생하면 운영체제는 필요로 하는 페이지를 메모리로 가져와서 실행함으로써 마치 페이지 폴트가 발생하지 않은 것처럼 합니다. 이 때 페이지 폴트가 자주 일어나면 오버헤드로 인해 컴퓨터 성능이 저하될 수 있으므로 페이지 폴트를 최소화하기 위해 여러 페이지 교체 알고리즘을 사용합니다.
Q6. 스래싱(Trashing)에 대해 설명하라. (예상)
쓰래싱은 어떤 프로세스에 지속적으로 페이지 폴트가 발생하는 현상을 의미합니다. 달리 말해 페이지 폴트율이 높아져 프로세스 처리시간보다 페이지 교체시간이 더 많이 발생하는 현상입니다. 이러한 스래싱 현상을 해결하기 위해 크게 두 가지로 Page-Fault Frequency(PFF)와 워킹셋(Working Set)을 사용합니다. 먼저 페이지 폴트율을 주기적으로 계산해서 각 프로세스에 할당할 메모리 양을 동적으로 조절합니다. 만약 어떤 threshold를 넘으면 프로세스에 할당된 프레임이 부족하다 판단하고 프로세스에게 프레임을 추가로 할당합니다. 만약 할당할 빈 프레임이 없을 경우 일부 프로세스를 스왑아웃 시켜 할당합니다. 반면 어떤 threshold이하일 경우 프로세스에게 많은 프레임이 할당된 것으로 판단해 할당된 프레임의 수를 줄입니다. 만약 모든 프로세스에 필요한 프레임을 다 할당한 뒤에도 여유 공간이 있다면 스왑 아웃되어 있던 프로세스를 스왑 인하여 다중프로그래밍정도인 MPD를 높입니다.
워킹셋은 프로세스가 실행되기 위해 한 번에 메모리에 올라와있어야 할 페이지의 집합을 의미합니다. 워킹셋 알고리즘을 통해 이러한 페이지 집합을 결정할 수 있습니다. 또 프로세스의 워킹셋이 한 번에 메모리에 올라갈 수 있는 경우에만 프로세스에게 메모리를 할당합니다. 그렇지 않은 경우 프로세스에게 할당된 페이지 프레임을 모두 반납하구 프로세스 주소 공간 전체를 디스크로 스왑 아웃시킵니다.
Q7. 페이지 스와핑에 대해 설명해주세요. (예상)
페이지 스와핑은 중기 스케쥴러에 의해 처리됩니다. 페이지 스와핑은 크게 페이지 스왑 인과 페이지 스왑 아웃으로 나뉩니다. 페이지 스왑 인의 경우 프로세스가 실행될 때 페이지 폴트가 발생할 경우 페이지를 메모리에 추가 적재하기 위해 사용합니다. 반면 페이지 스왑 아웃의 경우 워킹셋 알고리즘이 동작할 때 처럼 특정 페이지셋이 한 번에 메모리에 적재되기에 공간이 충분하지 않을 때 디스크 영역으로 옮기는 것을 말합니다.
Q8. 페이지 교체 알고리즘에 대해 설명하라.
페이지 교체는 메모리에 적재할 공간이 부족할 때 메모리에 적재된 프로세스를 디스크로 스왑 아웃하고 프로세스 실행에 필요로 하는 페이지를 메모리에 적재하는 것입니다. 이러한 페이지 교체 알고리즘의 목표는 Page-Fault Frequency를 최소화하는 것입니다. 이런 알고리즘의 종류는 FIFO, LRU, LFU, 빌레디, 클럭등이 있습니다. (추가 설명 필요)
Q9. 페이징의 장단점은 무엇인가?
페이징은 외부 단편화 문제를 해결하기 위해 사용하는 메모리 관리 기법입니다. 외부 단편화는 여분의 메모리 공간이 요청한 메모리 공간보다 커서 여유가 있지만 여유 공간이 연속적이지 않아 발생하는 현상입니다. 페이징은 페이지라는 단위로 메모리 공간에 불연속적으로도 적재할 수 있도록 합니다. 이처럼 페이징을 이용하면 외부 단편화 문제를 해결하는 장점이 있지만 반면 내부 단편화 문제가 발생하는 단점이 있습니다. 내부 단편화란 한 마디로 공간 낭비라 설명할 수 있습니다. 외부 단편화와 달리 메모리 공간에 프로세스 실행에 필요한 데이터가 적재될 공간이 충분히 있고 적재될 수 있지만 적재되고 나서 빈 영역이 발생하는 것입니다.
Q10. 세그멘테이션의 장단점은 무엇인가?
페이징 기법이 가지는 내부 단편화 문제를 극복하기 위해 세그멘테이션 기법이 사용됩니다. 페이지는 기본적으로 4KB 단위로 만들어집니다. 때문에 만약 9KB짜리 프로세스를 실행해야 한다면 메모리 공간에 12KB가 할당되고 3KB의 사용되지 못하고 낭비되는 영역이 만들어집니다. 세그멘테이션은 페이징과 똑같이 메모리 관리 기법이지만 차이점은 분할 방식입니다. 페이징은 한 단위를 기준으로 정적으로 분할하지만 세그멘테이션은 동적으로 분할하여 내부 단편화가 발생하지 않도록 합니다. 하지만 이런 세그멘테이션은 내부 단편화를 해결한다는 장점이 있지만 페이징에 비해 상대적으로 복잡한 메모리 관리로 오버헤드가 발생할 수 있다는 단점이 있습니다.
Q11. 임계 영역에 대해 설명하라.
임계 영역은 둘 이상의 쓰레드가 공유자원에 접근하는 데 있어 한 번에 한 쓰레드만 접근할 수 있도록 보장하는 영역을 말합니다. 임계 영역을 둠으로써 쓰레드는 공유자원에 대한 배타적인 사용권을 보장받을 수 있습니다. 이러한 임계 영역을 두기 위해 사용하는 방법으로 크게 뮤텍스와 세마포어가 있습니다.
Q12. 뮤텍스(Mutal Exclusion, Mutex)와 세마포어(Semaphore)의 차이를 설명하라.
뮤텍스 즉 상호배제란 임계 영역에 접근하는 쓰레드 간의 충돌을 막기 위해 사용하는 기법입니다. 이를 위해 Lock을 사용해서 임계영역에 들어가는 쓰레드가 Lock을 걸어 다른 쓰레드가 임계 영역으로 들어오지 못하도록 하고 이후 나갈 때 Lock을 해제하는 방식으로 다른 쓰레드가 임계 영역으로 들어올 수 있도록 하는 방법입니다. 세마포어 또한 임계 영역에 접근하는 쓰레드 간의 충돌을 막기 위해 사용하는 기법입니다. 기본적으로 뮤텍스와 동일하지만 차이점이 있다면 뮤텍스는 임계 영역에 들어간 쓰레드가 Lock을 걸고 해제할 수 있는 Locking 메커니즘을 사용하는 반면 세마포어는 Lock을 걸지 않은 쓰레드도 Lock을 해제할 수 있는 Signaling 메커니즘을 사용합니다.
Q13. 스케쥴링에 대해 설명하시오.
스케쥴링은 프로세스를 실행시키기 위해 CPU의 자원을 할당하는 정책을 계획하는 것입니다. 이 CPU 스케쥴링이 필요한 이유는 CPU 자원을 프로세스에게 효율적으로 할당하여 더 많은 작업을 처리할 수 있는 처리 속도를 높이기 위함입니다. 스케쥴링 방식에는 크게 선점형 스케쥴링과, 비선점형 스케쥴링이 있습니다. 선점형 스케쥴링은 한 프로세스가 CPU를 할당받아 실행되고 있을 때 우선순위가 다른 프로세스가 CPU를 강제로 점유할 수 있도록하는 기법입니다. 종류로는 라운드로빈, SRT ,다단계 큐, 다단계 피드백 큐 등의 알고리즘이 있습니다. 반면 비선점형 스케쥴링은 한 프로세스가 CPU를 항당받아 실행되고 있을 때 다른 우선 순위높은 프로세스가 CPU를 강제로 빼앗아 점유할 수 없는 기법입니다. 종류로는 FCFS, SJF, HRN 등의 알고리즘이 있습니다.
Q13-1. 스케쥴링 알고리즘에 대해 설명해주세요. (예상)
FCFS(First-Come First-Served)는 큐에 먼저 도착한 프로세스 순서대로 스케쥴링 하는 방식입니다. 비선점 스케쥴링에 방식에 해당합니다. 이런 FCFS의 단점은 CPU를 장기간 독점하는 프로세스가 있다면 다른 프로세스가 실행되지 못하고 오래 기다려야 한다는 단점이 있습니다. 이러한 단점을 보완하기 위해 SJF(Shortest-Job-First) 기법이 사용됩니다. CPU 작업시간이 짧은 프로세스 순서대로 스케쥴링하는 방식입니다. 비선점 스케쥴링 방식에 해당합니다. 특징은 만약 CPU 작업시간이 동일할 경우 FCFS 정책을 따릅니다. 이 SJF의 장점은 프로세스의 평균 대기 시간이 최소화된다는 것이며 단점은 CPU 작업시간에 대한 정확한 계산이 가능하지 않고, CPU 작업 시간이 긴 프로세스는 오랜시간 CPU를 할당받지 못할 수 있습니다. FCFS와 동일하게 이런 점유 불평등 현상이 있는 SFJ 알고리즘을 보완하기 위해 우선순위를 기반으로하는 HRN(Highest Response-ratio Next) 방식이 사용됩니다. 우선 순위는 $(대기시간 + 실행시간) \over (실행 시간)$로 계산 됩니다. 이외에도 여러 스케쥴링 알고리즘이 있지만 가장 일반적으로 사용하는 것은 Round Robin입니다. RR은 FCFS와 마찬가지로 순차적으로 스케쥴링을 진행하지만 특징은 동일한 시간의 Time Quantum만큼 CPU를 할당해 프로세스를 실행하는 방식입니다. RR 방식은 공정하다는 장점이 있지만 반면 Time Quantum이 커지면 FCFS와 같아진다는 단점이 있고, 작다면 Context Switcing이 많아져 오버헤드가 증가하는 단점이 있습니다.
Q14. Context Swiching에 대해 설명하라. (예상)
CPU가 어떤 프로세스를 실행 중일 때 인터럽트에 의해 다른 프로세스를 실행시켜야 하는 경우 기존 실행되던 프로세스 상태를 PCB에 저장하고 새로운 프로세스를 메모리에 적재하는 방법입니다. Context Swiching이 되면 실행될 프로세스의 PCB에 있는 정보와 레지스터 값을 읽어온 다음 이어서 작업을 수행합니다. 이 Context Swiching이 많이 일어나면 오버헤드가 발생하므로 Context Switching을 일으키는 스케쥴러가 최소한으로 Context Swiching이 일어나도록하는 스케쥴러 알고리즘을 사용해야 합니다.
Q15. Call By Value와 Call By Reference의 차이에 대해 설명하시오.
Call By Value란 Call By Reference는 함수에 인자를 전달하는 두 방식입니다. Call By Value는 전달받은 인자를 함수 내에서 복사해서 사용하는 것을 의미합니다. 복사해서 사용하기 때문에 원래 값에 영향을 미치지 않습니다. 반면 Call By Reference는 메모리 주소값에 있는 값을 직접 참조하는 방식입니다. 따라서 원래 값에 영향을 미치는 방식입니다.
Q16. PNG와 JPG의 차이를 설명하라.
Q17. 다이나믹 프로그래밍이란 무엇인가? 또 신경망의 관점에서는 어떻게 활용되는가?
DP는 큰 문제를 작은 문제로 나누어 푸는 방법입니다. 분할정복 알고리즘과 같이 큰 문제를 작은 문제로 나누어 푼다는 점에서 공통점을 가집니다. 하지만 차이점은 작은 문제 계산에 있어 반복이 일어나지 않는다는 것입니다. 일반적으로 DP는 점화식을 세워 문제를 해결합니다. 또 memoization을 이용해 한 번 계산해둔 값을 다시 활용한다는 특징이 있습니다. 가장 쉬운 예시로는 피보나치 수열이 있습니다. 즉 다음 수열의 값은 현재 수열 값과 이전 수열 값의 합입니다. 1, 1, 2, 3, 5, 8로 증가하는 형태를 가지며 다음 수열을 구할 때 이미 구해두었던 수열의 값을 활용합니다.
신경망의 관점에서 역전파를 진행할 때 다이나믹 프로그래밍을 사용합니다. back-propagation하면서 gradient를 전부 계산하는 것이 아니라 마지막 출력노드에서 한 번 미분값을 계산한 뒤 backward 방향의 노드로 전달하면서 재사용합니다.
Q18. 백트래킹 알고리즘에 대해 설명하라.
백트래킹 알고리즘이란 해를 찾는 도중 해가 아니라고 판단될 경우 되돌아가서 다시 해를 찾는 방법입니다.백트래킹 알고리즘은 일반적으로 DFS와 함께 사용됩니다. DFS는 알고리즘은 가능한 모든 경로를 탐색하기 때문에 계산 비용이 많이 발생합니다. 이를 해결하기 위해 가지치기가 필요한데 이 때 사용하는 것이 백트래킹 알고리즘입니다. 대표적인 예제로 N-Queen 문제가 있습니다.
Q19. 거의 정렬이 이뤄졌을 때 사용하면 좋은 정렬 알고리즘은 어떤 것인가?
삽입 정렬을 사용하면 좋습니다. 삽입 정렬은 정렬할 원소보다 index가 낮은 곳에 있는 원소들을 탐색해 정렬하는 알고리즘 입니다. 동작은 두 번째 index에 있는 원소부터 시작합니다. 삽입 정렬의 특징은 알고리즘이 동작하는 동안 반드시 맨 왼쪽 index까지 탐색하지 않아도 됩니다. 앞 부분은 이미 정렬 되어 있기 때문에 정렬 하고자 하는 원소보다 작아지는 경우 다음에만 삽입하면 됩니다. 거의 정렬이 모두 이뤄져있다면 모든 원소가 한 번씩만 비교하므로 $O(n)$의 복잡도를 가집니다.
Q20. 대칭키 암호화와 비대칭키 암호화는 무엇인가?
대칭키 암호화는 암복호화에 사용하는 키가 동일한 방식의 암호화입니다. 종류로는DES, 3DES, AES, SEED, ARIA 등이 있습니다. 장점으로는 비대칭키 암/복호화에 비해 수행 시간이 짧습니다. 반면 키교환문제가 발생한다는 단점이 있습니다. 비대칭키 암호화는 암복호화에 사용하는 키를 서로 달리하는 방식의 암호화입니다. 종류로는 RSA, ElGamal, ECC 등이 있습니다. 장점은 공개키가 있고 개인키가 있기 있기 때문에 키 교환 문제가 발생하지 않습니다. 단점은 대칭키에 비해 암복호화 수행시간이 느리다는 것이 있습니다.
Q20-1. 비대칭키는 왜 공개키와 비밀키로 나뉘는가?
키교환 문제를 해결하기 위해 사용합니다. 대칭키는 암호화와 복호화에 사용하는 키가 같기 때문에 이 키를 전달하는 과정에서 탈취될 가능성이 존재합니다. 반면 비대칭키는 공개키가 공개되어 있기 때문에 키교환 문제가 발생하지 않습니다. 동작방식은 가령 A와 B가 있을 때 B가 공개키/개인키 쌍을 생성합니다. A는 전달하고자 하는 정보를 B의 공개키로 암호화해서 B에게 주면 B는 자신의 개인키를 이용해 복호화를 수행하는 방식으로 이루어집니다.
Q21. TCP/UDP 차이를 설명하라.
TCP는 연결지향형 프로토콜이고 UDP는 비연결지향형 프로토콜입니다. 연결지향형이랑 클라이언트와 서버가 연결된 상태에서 데이터를 주고 받습니다. 반면 비연결지향형은 클라이언트와 서버가 연결되지 않은채로 데이터를 일방적으로 전송합니다. TCP를 사용하기 위해서는 3-way handshaking 과정을 거쳐야 합니다. 클라이언트는 SYN 플래그를 보내면 서버는 SYN + ACK를 보내고 다시 클라이언트는 ACK를 보냄으로써 상호 연결됩니다. 이러한 TCP의 특징은 데이터의 전송순서를 보장하고 수신여부를 확인합니다. 때문에 신뢰성이 높다는 장점이 있습니다. 반면 UDP보다 데이터 전송속도가 느리다는 단점이 있습니다. UDP는 3-way handshaking 과정 없이 데이터를 일방적으로 전송합니다. UDP의 특징은 데이터의 전송 순서가 보장되지 않으며 수신 여부를 확인하지 않습니다. 따라서 신뢰성이 낮다는 단점이 있습니다. 반면 TCP에 비해 속도가 빠르다는 장점이 있습니다.
Q22. 공유기 동작은 어떻게 이루어지는가?
공유기에 LAN 선을 연결하게 되면 공인 IP가 부여됩니다. 이 공유기에 장치를 연결하면 NAT에 의해 공인 IP가 사설 IP로 변경되어 할당됩니다. 공인 IP는 외부 인터넷과 연결을 위해 사용하고 사설 IP는 내부 인터넷 사용을 위해 사용합니다. 내부 인터넷에서 외부 인터넷으로 연결하기 위해서는 NAT를 통해 다시 공인 IP로 변경됩니다. 이 때 연결 요청이나 자원 요청에 대한 응답을 받기 위해서는 PAT를 통해 사설 IP에 할당된 포트정보까지 매핑시킴으로써 특정 디바이스를 식별할 수 있습니다. 만약 내부의 요청 없이 곧 바로 외부에서 내부로 접근하기 위해서는 포트포워딩을 통해 접속할 수 있습니다.
Q23. RESTful에 대해 설명하라. 또 단점은 무엇인가?
REST는 HTTP 프로토콜을 통해 DB에 Create, Read, Update, Delete 연산을 수행하는 것을 의미합니다. client-server 구조를 갖는게 REST의 특징 중 하나입니다. 하지만 클라이언트가 직접 DB에 접근하는 것을 위험하므로 REST API를 두어 서버가 데이터베이스에 클라이언트의 요청을 수행하고 결과를 반환합니다. 이러한 요청을 위해 HTTP METHOD를 사용하며 종류로는 GET, POST, PUT, DELETE 등이 있습니다. RESTful은 이러한 REST 아키텍처의 특징을 잘 지켜 설계한 것을 의미합니다. "REST API를 제공하는 웹 서비스는 RESTful하다"와 같이 표현할 때 사용됩니다. 이러한 REST 또는 RESTful의 장점은 쉽게 사용할 수 있다는 것입니다. REST API 메시지를 읽는 것만으로 의도하는 바를 명확히 파악할 수 있습니다. 반면 표준이 존재하지 않는다는 단점이 있습니다.
Q24. NoSQL의 장단점을 이야기하라.
NoSQL은 일반적으로 RDBMS와 함께 언급됩니다. 먼저 NoSQL의 장점은 정해진 스키마가 없기 때문에 데이터 구조가 유연하고 자유롭게 컬럼을 추가할 수 있습니다. 또 대용량 처리에 적합합니다. 반면 단점으로는 정해진 스키마가 없기 때문에 데이터의 일관성이 없습니다. 또 중복이 발생할 수 있고 발생할 경우 계속해서 모든 컬렉션에서 업데이트해야하는 번거로움이 있습니다. RDMBS의 장점은 정해진 스키마가 있기 때문에 데이터 구조의 일관성이 보장됩니다. 또 데이터의 중복이 발생하지 않습니다. 반면 단점으로는 정해진 스키마가 있기에 유연성이 떨어집니다. 또 규모가 커질수록 테이블 간 JOIN이 복잡해지고 쿼리 프로세싱도 복잡해져 성능이 저하됩니다.
회귀분석은 가장 단순화하면 독립변수(x)로 종속변수(y)를 예측하는 것을 의미한다. 이를 풀어 쓰자면 회귀분석이란 독립변수가 종속변수에 미치는 영향력을 측정하고 이를 기반으로 독립변수의 특정값에 대응하는 종속변수값을 예측하는 모델을 만드는 통계적 방법론이다. 회귀분석의 목적은 독립변수로 종속변수를 설명하는데 있다. 회귀분석에서는 독립변수와 종속변수를 동일하지만 다양한 이름으로 부른다. 독립변수의 경우 설명변수, 예측변수, 원인변수 등으로 불리고 종속변수의 경우 목표변수, 목적변수, 반응변수, 결과변수 등으로 불린다. 이를 혼동하지 않기 위해서는 이름들이 원인측에 가까운지 결과측에 가까운지 또 종속성의 여부를 떠올려 추론하면 될 것이다. 이러한 회귀분석을 진행하기 위한 전제조건은 4~5가지 기본 가정이 어긋나지 않아야 한다.
1.1 회귀분석의 기본 가정
회귀분석을 진행하기 위해 갖춰져야할 기본 몇 가지 가정이 있다. 일반적으로 4대 가정 또는 5대 가정이라 불리며 4대 가정은 앞글자를 따서 LINE이라 불린다.
선형성(Linearity): 모든 독립변수와 종속변수 사이에는 선형적인 관계를 띠어야 한다.
독립성(Independence): 1) 잔차 사이에는 상관관계 없이 독립적이어야 한다. 2) 잔차와 독립변수 간 상관관계가 없어야 한다.
정규성(Normality): 잔차가 평균이 0인 정규분포를 띠어야 한다. $E(\epsilon_i|X_i) = 0$
등분산성(Equal Variance): 잔차의 분산은 독립변수와 무관하게 일정해야 한다.
다중공선성(No Multicollinearity): 독립변수 간의 강한 상관관계가 있을 때의 성질을 의미하는 것으로 이러한 성질이 없어야 회귀분석이 가능하다.
여기서 중요한 것은 독립변수의 정규성, 독립성, 등분산성, 선형성을 고려하는 것이 아니라 잔차의 정규성, 독립성, 등분산성, 선형성을 따져야 한다. 여기서 잔차란 표본집단의 관측값에서 예측값을 뺀 값이다. 유사하게 사용되는 오차는 모집단에서 관측값에서 예측값을 뺀 값을 뜻한다.
또 만약 잔차의 등분산성이 성립하지 않을 경우 가중최소제곱법(Weighted Least Sqaure)을 사용해 잔차의 이분산성을 해결할 수 있다. 이분산성이란 데이터에 일반적인 최소제곱법을 적용할 경우 추정통계량의 신뢰도가 상실되어 회귀계수의 표준오차를 과소추정 또는 과대추정하게 되는 성질을 말한다. 이러한 이분산성은 가중최소제곱을 사용하면 회귀 모수의 오차항 분산에 반비례하는 가중치를 부여하여 가중 오차제곱합을 최소화하는 방법이다. (출처: Tony Park)
1.2 회귀분석의 종류와 특징
회귀분석은 크게 두 가지로 선형회귀분석과 로지스틱회귀분석으로 나뉜다. 선형회귀분석은 연속형 종속변수를 사용하며 분석 목적은 예측에 있다. 또 선형회귀분석은 모델을 찾기 위해 최소자승법을 사용하고 모델을 검정하기 위해 t검정, F검정 등을 사용한다. 선형회귀분석은 다시 단순 선형회귀분석과 다중 선형회귀분석, 비선형 회귀분석 셋으로 나뉜다. 단순 선형회귀분석은 독립변수가 1개 종속변수가 1개일 때 진행하는 분석이다. 다중 선형회귀분석은 독립변수가 여러 개고 종속변수가 1개일 때 진행하는 분석이다. 비선형회귀분석은 단순/다중 선형회귀분석처럼 선형으로 나타나는 식이 아니라 2차함수나 지수함수와 같이 비선형으로 나타내는 관계에 대해 분석하는 방법이다.
로지스틱회귀분석은 독립변수와 범주형 종속변수 간의 관계를 모형화하여 종속변수를 분석하거나 분류하는 통계적인 방법론이다. 로지스틱회귀분석은 범주형 연속변수를 사용하며 분석 목적은 분류에 있다. 로지스틱회귀분석은 모델을 찾기 위해 최대 우도법을 사용하고 모델 검정을 위해 카이제곱 검정 등을 사용한다.
1.3 회귀분석의 절차는?
1. 가설 수립: 귀무 가설과 대립 가설 설정 2. 데이터 경향성 확인: 독립변수와 종속변수 간 산점도 분석과 상관관계 분석 진행 3. 모델 적합성 확인: 결정계수, 분산분석, 잔차기본 가정(정규성, 등분산성, 독립성 등) 확인 4. 회귀계수 계산 및 유의성 확인: 독립변수 간 다중공선성, t검정을 통한 회귀계수 유의성, 독립변수 선택 및 해석 5. 모델 선정: 모델 적합성과 오차의 기본 가정 확인을 통해 모델 선정
1.4 결정계수란?
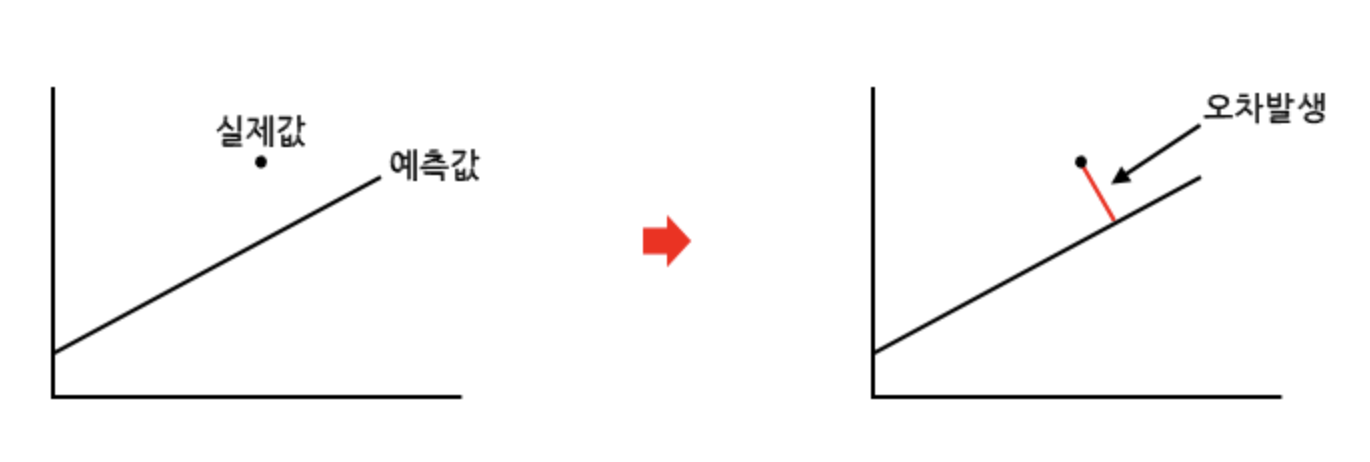
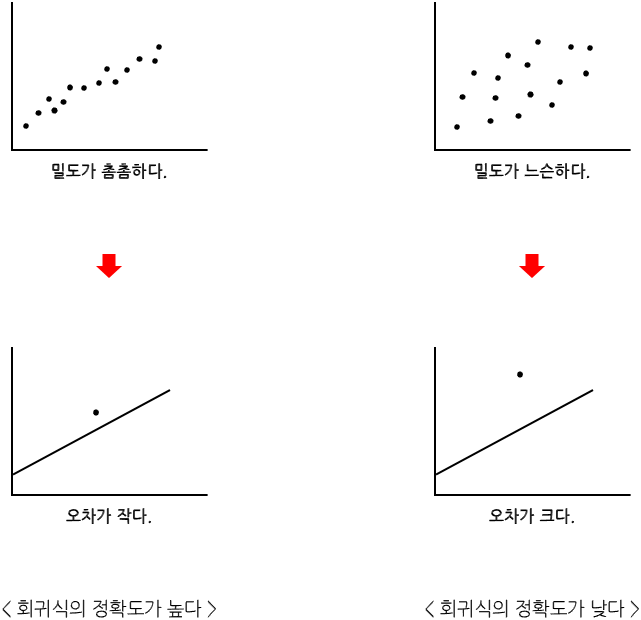
결정계수란 통계학에서 수행하는 회귀분석의 회귀식의 정확도를 평가하기 위한 척도(measure)이다. 다르게 말하면 독립변수를 통해 종속변수를 예측한 것의 설득력을 나타내는 척도라 할 수 있다. 이 결정계수를 사용하는 이유는 회귀분석에서 예측을 하더라도 실제값과의 오차가 발생할 수 밖에 없기 때문이다.
이 오차라는 것은 점의 밀도에 따라 달라진다. 예를 들어 많은 점이 모여 있어 밀도가 촘촘한 경우 예측값과 실제값의 오차가 작아진다. 반면 점들이 밀도가 느슨할 경우 예측값과 실제값의 오차가 커진다. 즉 점의 밀도, 데이터 수에 따라 오차의 크기가 달라지고 이에 따른 회귀식의 정확도가 달라지는 것이다.
위와 같이 밀도에 따라 회귀식의 오차가 달라지고 정확도가 달라지므로 이 정확도를 평가하기 위한 척도가 결정계수이다. 이 결정계수는 R-square라 부르며 $R^2$로 나타낸다. 여기서 R은 비율(Rate)를 나타낸다. 이 결정계수는 두 가지 방법으로 나뉘어 사용된다.
첫 번째는 피어슨 상관계수를 이용하는 방법이다. 결과적으로 결정계수는 피어슨 상관계수를 제곱한 값이라 할 수 있다. 피어슨 상관계수의 범위는 $-1 \leq R \leq 1$을 가지는데, 제곱하면 값의 범위가 $0 \leq R^2 \leq 1$된다. 하지만 이렇게 제곱할 수 있을 때는 후에 설명할 단순회귀분석처럼 독립변수가 하나인 경우로 제한된다. 예를 들어 $y=ax+ b$일 경우 결정계수는 독립변수 x와 종속변수 y의 상관계수의 제곱이다. 하지만 다중회귀분석처럼 $y = ax_1x_1 + b_1 + a_2x_2 + b_2$처럼 독립변수가 $x_1, x_2$로 2개 이상일 경우 $x_1, y$와 $x_2, y$의 두 상관계수를 각각 구해야 한다. 다시 돌아와 피어슨 상관계수를 제곱한 결정계수는 아래와 같은 수식으로 나타낸다.
결과적으로 SSR이 얼마나 크고 SSE가 얼마나 작냐에 따라 회귀식에서 산출된 정확도가 결정된다. 즉 결론적으로 결정계수 $R^2$이 0에 가까울수록 회귀식의 정확도는 낮고, 1에 가까울수록 회귀식의 정확도는 높다고 할 수 있다.
이러한 결정계수는 독립변수가 많아질수록 값이 커진다는 특성을 갖는다. 따라서 종속변수를 잘 설명하지 못하는 독립변수가 추가되더라도 결정계수값이 커질 수 있다. 이러한 한계점을 보완하고자 수정된 결정계수(adjusted coefficient of determination)을 사용한다. 이 수정된 결정계수는 표본 개수와 독립변수 개수를 고려해 계산하며 식은 다음과 같다.
adjusted $R^2 = {1 - {n-1 \over (n-p-1)(1-R^2)}}$
만약 단순회귀분석을 진행한다면 결정계수를 사용하면 되고, 다중회귀분석을 진행한다면 수정된 결정계수를 사용하는 것이 좋다. 이러한 결정계수와 수정된 결정계수를 계산하더라도 정확도를 판단하기 모호한 경우가 생긴다 극단적으로 0과 1이라면 정확도를 판별할 수 있지만 0.4나 0.6과 같이 값이 모호하다면 올바른 의사결정이 어려워진다. 따라서 추가적으로 가설검정을 통해 이러한 의사결정이 이루어진다.
1.5 회귀계수 계산
회귀 모델이 선택된다면 이에 대한 회귀계수를 계산하고 유의성을 검정해야 한다. 회귀계수를 구하기 위해서 회귀선의 기울기와 절편을 구해야하며 이는 최소제곱법(Least Square Method)로 계산할 수 있다. 최소제곱법은 잔차의 제곱 합(Sum of Squared Error, SSE)이 최소가 되는 회귀선을 찾는 방법이다. 잔차의 제곱 합 SSE는 다음과 같은 수식으로 나타낸다.
상관분석이란 두 변수간 상관성 정도를 알기 위해 사용하는 분석이다. 즉 상관분석의 목적은 임의의 두 변수 간의 상관성 정도를 보는 것이다. 상관분석을 통해 상관계수라는 수치로 정량화되어 표현된다. 이 상관계수는 대표적으로 3가지를 사용한다. 피어슨 상관계수, 스피어만 상관계수, 켄달 상관계수이다. 이 상관계수들은 아래의 데이터 종류에 따라 달리 사용된다.
2.1 상관계수의 종류
피어슨 상관계수 (모수적) 피어슨 상관계수란 키/몸무게 같이 분석코자 하는 두 변수가 모두 연속형 데이터일 때 사용하는 척도다. 피어슨 상관계수 사용을 위해 두 변수 모두 정규성을 따른다는 가정이 필요하다. 때문에 피어슨 상관계수는 두 변수간 선형적인 관계를 모수적 방법으로 나타내는 척도라고 할 수 있다. 또 피어슨 상관계수는 독립변수와 종속변수 간의 선형관계를 나타내는 척도이다. 피어슨 상관계수의 동일한 의미의 다른 이름은 피어슨 적률 상관계수, 피어슨 r, R 등이 있다. 또 일반적으로 상관계수라 하는 것은 피어슨 상관계수를 뜻한다. 피어슨 상관계수는 $-1 \leq R \leq 1$ 범위의 값을 갖는다. 0에 가까울수록 두 변수간 선형적 관계가 없고, -1에 가까울수록 음의 상관관계를 가지며 +1에 가까울수록 양의 상관관계를 가진다. 피어슨 상관계수의 수식은 다음과 같이 정의된다.
$n$: 표본집단 수 $\bar{x}$: 표본집단 $X$의 평균 $\bar{y}$: 표본집단 $Y$의 평균
위 수식을 통해 표본 집단으로부터 표본 상관계수를 계산할 수 있다. 표본 상관계수가 도출되면 다음으로 이 상관계수의 타당성을 위해 가설검증을 진행한뒤 가설검증 결과를 기반으로 가장 처음 수립했던 가설의 채택을 결정한다.
스피어만 상관계수 (비모수적) 분석하고자 하는 두 변수가 회귀분석의 기본 가정 중 하나인 정규성을 충족하지 않을 경우 피어슨 상관계수를 사용할 수 없다는 한계점을 극복하기 위해 사용한다. 스피어만 상관계수는 스피어만 순위 상관계수, 스피어만 $r_s$ 라고도 불린다. 순위를 이용하기에 비모수적인 방법에 해당하며 연속형 변수뿐만 아니라 순위형 변수에도 적용가능하단 특징이 있다. 예를 들어 수학 점수와 과학 점수와의 상관계수는 피어슨 상관계수로 구하고, 수학 과목 석차와 영어 과목 석차는 스피어만 상관계수로 계산할 수 있다. 스피어만 상관계수는 다음과 같은 수식으로 표현된다. 아래 수식에서 $d$는 관측값들의 등위 간 차이를 나타내고 $n$은 관측 데이터 수를 의미한다.
켄달 상관계수 (비모수적) 켄달 상관계수는 두 연속형 변수 간의 순위를 비교해 연관성을 계산하는 방법으로 순위 상관계수의 한 종류이다. 켄달 상관계수는 켄달타우 상관계수라고도 불린다. 켄달 상관계수는 피어슨 상관계수의 변수값이 정규분포를 따르지 않을 때 사용하기 어렵다는 단점을 보완하기 위해 사용한다. 켄달 상관계수를 계산하기 위한 핵심 개념은 concordant pair이다. 이는 각 변수의 비교 대상이 상하관계가 같을 때를 의미한다. 예를 들어 사람 a와 b의 키/몸무게를 비교했더니 사람 a가 모두 키/몸무게가 사람 b보다 크다면 concordant pair라고 말한다. 반면 사람 b와 c를 비교했을 때 b가 키는 크지만 몸무게는 c보다 작은 경우는 concordant pair가 아니다. 결과적으로 켄달 상관계수를 구하기 위한 수식은 다음과 같이 C와 D로 표현하며 여기서 C는 concordant pair한 수이며 D는 concordant pair하지 않은 수를 의미한다.
$\displaystyle {{C - D} \over {C + D}}$
간단 용어 정리
독립변수: 다른 변수에 영향을 받지 않는 변수이자 종속 변수에 영향을 주는 변수. 주로 입력이나 원인을 나타낸다. 종속변수: 독립 변수에 의해 영향을 받는 변수. 주로 출력이나 결과를 나타낸다. 표준오차: 표본평균들의 편차를 뜻한다. 회귀계수: 회귀분석에서 독립변수가 한 단위 변화함에 따라 종속변수에 미치는 영향력 크기다. 만약 두 변수간 상관관계가 없을 경우 회귀계수는 의미가 없게 된다.
통계학의 분석 방법은 모수(parameter)의 필요성 여부에 따라 모수적 방법과 비모수적 방법으로 분류된다. 모수란 입력 데이터의 분포를 가정(ex: 정규분포)하는 것을 의미하며, 비모수란 입력 데이터 분포를 가정하지 않음을 의미한다. 대부분의 분석법은 모수적 분석 방법에 해당한다. 하지만 만약 모수적 방법에서 가정했던 분포가 적합하지 않을 경우 입력 데이터의 특성을 잘 파악하지 못한 것이므로 비모수적 방법을 사용한다. 비모수적 방법은 입력 데이터에 대한 분포를 가정할 수 없는 경우에 사용하는 방법이다. 모수 방법에서 가정했던 입력 데이터 분포를 완화시키는 방식으로 사용한다.
머신러닝에서도 모수와 비모수가 적용되어 parametric model과 non parametric model 형태로 나타난다.
parametric model
파라미터 수가 결정된 모델을 의미한다. 파라미터 수가 결정된 이유는 입력 데이터가 어떤 분포를 따른다고 가정했기 때문이다. 따라서 non-parametric 모델과 달리 아무리 입력 데이터 양이 많더라도 학습해야 할 파라미터 수는 변하지 않는다. 이러한 parametric model의 종류는 Linear Regression, Logsitic Regression, CNN, RNN 등이 있다. 모델이 학습해야 할 parameter가 결정되어있기 때문에 non-parametric 방식에 비해 학습 속도가 빠르고 모델의 복잡성이 낮다는 장점이 있다. 반면 단점은 입력 데이터가 어떤 분포를 따른다는 가정이 있으므로 유연성이 낮고, non-parametric model에 비해 복잡한 문제를 해결하기 어렵다.
non-parametric model
파라미터 수가 결정되지 않은 모델을 의미한다. 입력 데이터가 어떤 분포를 따른다고 가정하지 않았기 때문이다. 따라서 non-parametric model은 입력 데이터에 대한 사전 지식이 없을 때 사용할 수 있다. 이러한 non-parametric model의 종류는 GAN이나 decision tree, random forest, k-nearest neighbor 등이 있다. 이런 non-parametric model은 어떤 분포를 다른다고 가정하지 않았기 때문에 parametric model에 비해 훨씬 유연성이 있다는 장점이 있다. 반면 parametric model에 비해 학습 속도가 느리거나, 더 많은 양의 데이터를 필요로 한다는 단점이 있다.
적률추정법은 통계학의 근본이 되는 수리통계학에서 나오는 개념이다. 적률추정법을 이해하는데 있어 난관은 적률의 의미이다. 적률(moment)을 한마디로 나타내면 확률변수 $X$의 $n$제곱 기대값인 $E[X^n]$이다. 하지만 왜 이렇게 표현하는지를 이해하기 위해서는 적률의 의미를 살펴볼 필요가 있다. 모멘트(=적률)란 물리학에서 사용되는 개념으로 "어떤 물리량과 어떤 기준점 사이의 거리를 곱한 형태를 가지는 것 즉, 모멘트 = 물리량 * 거리"이다. 하지만 통계학에서 적률로의 직관적인 이해로 연결되지 않는다.
모멘트는 한 마디로 질량이 분포된 모양에 따라 그 효과가 달라지는 현상을 말한다. 예를 들어 몸무게 같은 두 명의 사람이 시소를 탄다고 하자. 이 때 두 사람이 모두 양 끝에 탔을 때랑, 한 사람은 끝에 한 사람은 한 칸 앞에 탔을 때 작용하는 모멘트가 달라지는 것과 같다. 즉 두 사람의 질량은 같아도 질량이 분포된 모양(거리)에 따라 효과가 달라지는 것이다.
다시 돌아와 앞전의 어떤 물리량이란 것은 질량, 힘, 길이 등이 될 수 있고 쉽게 (질량 x 거리), (힘 x 거리), (길이 x 거리)로 표현하는 것을 모멘트(=적률)이라고 한다. 참고로 모멘트와 모멘텀(Momentum)이 비슷해 혼동되기도 하는데 이 둘은 다른 개념이다. 모멘텀은 운동량을 의미하는 것으로 모멘텀(운동량) = 질량(Mass) * 속도(Velocity)이다. 예를 들어 거대한 선박이 있다면 질량이 크고 속도는 작은 운동량을 가질 것이고, 어떤 총알이 날아간다면 질량은 작고 속도는 큰 운동량을 가진다.
통계학에서의 적률의 의미와 정의
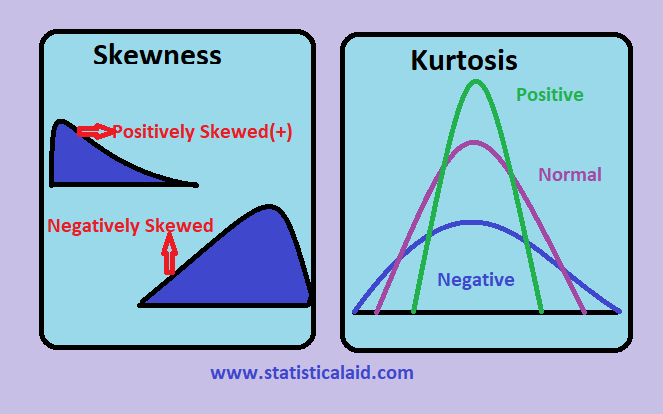
그렇다면 이 적률(모멘트)은 왜 통계에서 사용할까? 그 이유는 위 언급한 "분포"와 관련있기 때문이다. 물리학에서 모멘트는 앞서 시소 예제와 같이 질량과 거리에 따라 달라졌다. 통계학에서의 적률은 확률과 확률변수에 따라 적률이 달라진다. 질량이 확률로, 거리가 확률변수로 바뀐 것이다. 그렇다면 이제 통계에서의 적률의 의미를 살펴보자. 적률은 초반부에 설명했듯 한 마디로 확률변수 $X$의 $n$제곱의 기대값인 $\mu_n = E[X^n]$으로 표현한다. 이 때의 양수 $n$은 차수를 뜻하는 것으로 확률변수 $X$의 $n$차 적률이라 한다. 이러한 적률이 중요한 이유는 확률분포의 특징을 설명하는 지표로서 역할을 하기 때문이다. 예를 들어 1차 적률은 확률변수의 평균을 나타내고, 2차 중심적률은 분산, 3차 중심적률은 왜도(skewness), 4차 중심적률은 첨도(kurtosis)를 나타낸다. 여기서 왜도란 확률밀도함수의 비대칭성을 나타내는 척도이며, 첨도는 확률밀도함수의 뾰족한 정도를 뜻하는 척도다.
즉 확률분포의 특징을 나타내는 척도(Measure)는 4가지로 평균, 분산, 왜도, 첨도가 있고 이는 적률의 확률분포 X의 n제곱의 기대값을 통해 나타낼 수 있다. 평균은 원점에 대한 1차 모멘트로 $E[X]$로 표현하고 분산은 평균에 대한 2차 모멘트로 $E[(X-\mu)^2]$로 표현한다. 또 왜도는 평균에 대한 3차 모멘트로 $E[(X-\mu)^3]$로 표현하고 첨도는 평균에 대한 4차 모멘트로 $E[(X-\mu)^4]$로 표현한다. 만약 여기에 상수 $c$가 있다면 확률변수 $X$의 $n$차 적률은 $E[(X-c)^n]$로 표현한다. 이 때 $c=0$이면 원적률(적률)이라 하고 $c=E[X]$라면 중심적률이라 한다. 만약 어떤 두 확률변수의 모든 적률이 일치한다면 두 확률변수는 같은 분포를 가진다고 말할 수 있다. 이 특징이 가장 중요하다. 후에 모수 추정을 위해 사용하는 적률추정법의 원리가 되기 때문이다.
원점에 대한 $n$차 적률을 수식으로 나타내면 크게 이산확률변수와 연속확률변수로 표현할 수 있고 아래와 같다.
이 때 $f(x)$는 이산확률변수에선 확률질량함수가 되고 연속확률변수에선 확률밀도함수가 된다. 위 정의에 따라 $n=1$을 대입하면 일반적으로 알고 있던 확률변수 X의 기대값이 된다. 즉 원점에 대한 1차 적률이 지금껏 알고 있던 기대값이다.
적률생성함수의 필요성과 정의
적률의 수식 정의에 따라 연속확률변수에서 적률을 구하기 위해 적분을 해야하지만 적분 계산이 어렵거나 불가능한 경우도 있기 때문에 이러한 상황을 해결하고자 적률생성함수(Moment Generating Function, MGF)를 만들어 사용한다. 적률생성함수는 적률과 마찬가지로 이산확률변수와 연속확률변수로 나뉘어 다음과 같이 정의된다.
다음으로 $a=0$을 대입하여 매클로린 급수 형태로 만들어준다. 테일러 급수는 일반적으로 무한한 항을 모두 사용하는 것이 아니라 저차원의 일부 항만 사용하여 근사하는 형태로 활용한다. 고차원 항을 많이 사용하면 어떤 함수 $f(x)$에 매우 가까워지지만 그만큼 계산 비용이 많이 발생하게 되기 때문이다. 그래서 $a=0$을 대입하는 이유는 테일러 급수에 직접 대입해본다면 하나의 항을 제외한 모든 항이 사라져 $f(x) = f(a)$만 남게 되어 구하고자 하는 값을 곧바로 얻을 수 있기 때문이다. 적률생성함수에선 $t=0$일 때의 값을 사용하므로 $a=0$을 대입하면 다음과 같아진다.
즉 요약하면 적률생성함수란 확률변수 $X$의 거듭제곱의 기대값을 구하는 함수이며, 적률생성함수를 한 번 구해두기만 하면 $n$번 미분하고 $t=0$을 대입해주면 쉽게 $n$차 적률을 구할 수 있다.
적률추정법
적률의 배경과 의미와 정의부터 적률생성함수를 만들어 미분해서 $n$차 적률을 구해보았다. 그렇다면 이러한 적률은 어디에 쓰일까? 궁극적으로 적률은 적률추정법을 통해 모수를 추정하기 위해 사용한다. 적률추정법은 $n$차 모적률과 $n$차 표본적률을 일치시켜 모수를 추정하는 방법으로 최대가능도와 베이지안 추론과 같이 모수를 추정하는 점추정 방법에 속한다. 모수란 평균과 분산과 같은 모집단을 대표할 수 있는 값으로 보통 통계량 중 평균을 가장 많이 사용한다. 따라서 적률법이라고도 불리는 이 적률추정법은 표본평균을 통해 모평균과 일치하는 $\theta$를 찾는 방법이다. 평균이 아니여도 분산 등의 다른 통계량이 일치해도 된다. 하지만 일반적으로 확률분포에서 모수는 평균인 기대값 $\mu = E(x)$으로 표현한다. 예를 들어 모집단이 정규 분포를 따른다고 할 때 $N(\mu, \sigma^2)$로 표현하는 것과 같다.
돌아와 적률추정법은 $n$차 모적률과 $n$차 표본적률을 일치 시켜 모수를 추정하는 방법이라 했다. 이를 수식으로 나타내면 $n$차 모적률 ($\displaystyle m_n = E[X^n]$)을 $n$차 표본 적률 ($\displaystyle \hat{m}_n = {1\over n}\sum_{i=1}^m X_i^n$)과 일치시켜 모수를 추정한다고 표현한다. 그리고 이 표본평균이 곧 모수 $\theta$에 대한 점추정 값이 된다.
이러한 적률추정법은 점추정량을 구하는 가장 오래된 방법으로 최대가능도보다 자주 사용되진 않으나 손쉽게 계산 가능하다는 장점이 있다. 반면 비현실적인 추정량을 제시하는 경우가 있다는 단점이 존재한다. 이를 보완하기 위해 최대우도법(MLE), 베이즈 추정법 등을 사용한다.
가설 검정이란 어떤 추측이나 가설에 대해 타당성을 조사하는 것이다. 통계학에서 가설 검정은 표본통계량으로 모수를 추정할 때 추정한 모수값 또는 확률 분포 등이 얼마나 타당한지 평가하는 통계적 추론이다. 이 가설 검정에는 크게 귀무가설과 대립가설이 쓰인다. 귀무가설(null hypothesis)은 처음부터 버릴 것으로 예상하는 가설이며, 대립 가설(alternative hypothesis)은 귀무가설과 반대로 실제로 주장하거나 증명하고 싶은 가설이다.
가설 검정 단계는?
귀무가설과 대립가설을 통해 가설 검정을 진행하는 단계는 크게 4단계로 이루어진다.
위 4단계의 과정을 제약회사의 신약 개발 예시를 들어 설명하면 다음과 같다.
1. 귀무가설과 대립가설을 수립한다.
귀무가설($H0$): 신약이 효과가 없을 것이다. 따라서 제약회사에 유의미한 수익 창출이 어려울 것이다.
대립가설($H1$): 신약이 효과가 있을 것이다. 따라서 제약회사에 유의미한 수익 창출이 가능할 것이다.
이 때 귀무 가설은 보통 $H0$로 표현하며 대립 가설은 $H1$로 표현한다. 두 가설들은 아래 단계들을 거쳐 하나가 채택된다.
2. 유의수준(significant level, $\alpha$)을 설정한다.
유의수준은 가설 예측을 100% 옳게 할 수 없으므로 오차를 고려하기 위한 것이다. 유의수준을 통해 귀무가설 채택여부 결정한다.일반적으로 $\alpha = 0.05$로 설정하지만 검정 실시자의 결정에 따라 달라질 수 있다. 여기서 만약 $\alpha=0.05$로 설정한다면 이 값을 기준으로 귀무가설 또는 대립가설을 채택한다. 만약 이후 단계들로부터 검정 통계량을 기반으로 하는 p-value가 산출되었을 때 0.05보다 낮다면 귀무가설을 기각하고 대립가설을 채택한다.
유의수준을 정할 때 함께 결정해야 하는 것은 양측 검정/단측 검정이다. 양측검정은 두 가설 모두에 관심 있을 때 사용하며 단측검정은 한 가설에만 관심 있을 때 사용한다. 예를 들어 제약회사 예시에서는 신약 효과가 있는지만 증명하면 자연스럽게 효과가 없음도 증명할 수 있으므로 단측 검정을 사용할 수 있다. 하지만 만약 남자와 여자의 스트레스의 차이를 두고 가설이 수립되었다면 양쪽 모두 살펴보아야 하므로 양측 검정을 사용해야 한다.
단측 검정과 양측 검정
(* 유의수준과 함께 사용되는 기각역이라는 것은 단측 검정과 양측 검정에 위치하는 유의수준 $\alpha$ 크기에 해당하는 영역을 의미한다.)
3. 검정 통계량을 계산후 p-value를 도출한다.
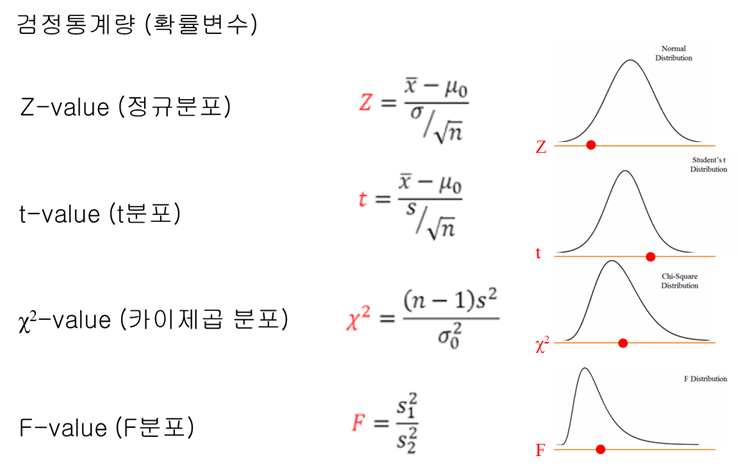
검정 통계량은 모수 추정을 위해 구하는 표본 통계량과 같은 의미를 가지는 것으로 가설 검정시 사용하는 표본 통계량을 뜻한다. 또 검정 통계량은 표본을 통해 가설 검정에 사용하는 확률 변수이다. 확률 변수라는 것은 그래프 상에서 x축을 나타내는 것이므로 확률 변수에 대한 확률 값을 나타내는 y값과는 다르다. 따라서 이 검정 통계량(확률 변수)은 확률분포 상에서 x축을 의미한다. 이 검정 통계량을 구하기 위해 사용하는 방법들은 아래와 같이 Z검정, T검정, 카이제곱 검정, F검정 등이 있다.
이쯤에서 혼동되는 것은 검정이라 부르는것과 분포라 부르는 것은 어떤 차이를 가질까? 핵심은 내부적으로 사용하는 함수 식이 다르다. 예를 들어 검정에서 사용되는 함수는 검정력 함수라 부르는 것으로 확률분포의 x축 값을 검정력 함수에 넣어 검정 통계량을 구하는데 사용한다. 반면 분포는 x축과 함께 y축은 확률을 구해 확률분포로 나타낼 수 있는 식이다. 위의 그림에선 검정력 함수만 나타내고 있다.
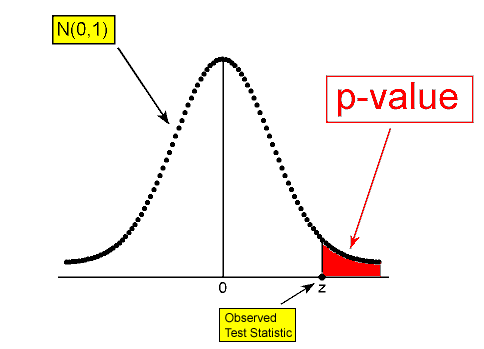
이제 가설 검정의 핵심인 p-value(유의 확률)을 구하기 위해서는 위 검정력 함수를 통해 구한 검정 통계량을 알아야 한다. 예를 들어 아래와 같이 Z분포를 따르는 검정통계량이 있고 Z검정을 통해 어떤 한 표본의 검정통계량 z를 구했을 때 x축 위의 z지점까지의 누적분포함수가 곧 p-value가 된다.
4. p-value를 기준으로 귀무가설 채택 여부를 결정한다.
만약 위 그래프에서 검정 통계량 z가 기각역이라 불리는 유의수준 $\alpha$ 영역 내에 위치하게 된다면 귀무가설을 기각하고 대립가설을 채택하게 된다. 즉 p-value가 유의수준 $\alpha$보다 같거나 작다면 귀무가설을 기각하고, p-value가 유의수준 $\alpha$보다 크다면 귀무가설을 채택한다.
제약회사 예시에서 만약 신약 효과가 없을 확률이 유의수준($\alpha=0.05$)보다 작다면 효과가 없다는 귀무가설을 기각하고 효과가 있다는 대립가설을 채택하는 것이다. 반대로 만약 신약 효과가 없을 확률이 유의수준($\alpha=0.05$)보다 크다면 신약 효과가 없을 확률이 더 높은 것이므로 귀무가설을 채택하고 대립가설을 기각한다.
1종 오류와 2종 오류
1종 오류
쉽게 말해 1종 오류란 귀무가설이 참인데 기각한 경우를 말한다. 예를 들어 신약이 효과가 있어 제약회사에서 많은 수익을 벌었지만 알고보니 신약이 효과가 없었을 때를 의미한다. 즉 귀무가설을 기각하고 대립가설을 채택했지만 이것이 잘못된 검정이었음을 뜻한다. 이에 의거하면 p-value의 의미는 1종 오류를 얼마나 범할 확률을 나타내기도 한다. 즉 p-value가 5%라면 100번 검정하면 5번 정도 1종 오류가 발생하는 것이다. 또 이에 따라 유의 수준 $\alpha$는 1종 오류의 상한선이라고 말할 수 있다. 따라서 검정 결과 p-value가 $\alpha$보다 낮다면 상한선을 벗어나지 않으므로 이를 귀무가설을 기각하고 p-value가 $\alpha$보다 높다면 상한선을 벗어났으므로 귀무가설을 채택한다.
2종 오류
쉽게 말해 2종 오류란 귀무가설이 거짓인데 참으로 판단한 경우를 의미한다. 예를 들어 신약이 효과가 없다는 귀무가설이 사실로 밝혀져서 제약회사에서 생산과 판매를 그만두었지만 알고보니 효과가 있었을 때를 의미한다.
데카르트는 "나는 생각한다 고로 존재한다" 라는 말을 남겼다. 이 말의 기저에는 데카르트의 실체관에 기인한다. 여기서 실체관이란 우주는 궁극적으로 두 개의 실체(substance)로 구성되어 있고 그것은 정신과 물질이라는 것이다. 이 실체관을 이해하기 위해선 실체라는 개념이 매우 중요하다. 실체는 드러난 현상의 배후나 본질을 뜻한다. 이 때 본질은 독립성을 띤다. 본질이기에 그 어떤 것에도 종속되지 않기 때문이다. 따라서 본질인 실체는 독립성을 띤다. 이 독립성을 띤다는 것은 곧 실체라는 존재가 존재성을 유지하기 위해 타존재에 의존하지 않는 것이다. 의존하는 순간 타존재에 종속되기에 진정한 실체라 말할 수 없기 때문이다. 이에 따라 실체는 그 자체로 존재의 독립성을 띤다.
이에 의거하면 정신과 물질은 모두 독립성을 띠어야 한다. 정신의 존립을 위해 물질을 필요로 하지 않고, 물질의 존립을 위해 정신을 필요로 하지 않는 것이다. 상호배타성을 띠는 것이며 때문에 상호교섭이 이루어질 수 없다. 상호교섭하는 순간 독립성이 성립되지 않고, 실체성이 부인되기 때문이다. 이는 곧 정신과 물질은 각각 그 자체로 자기가 원인이 되는 자기 원인자가 되는 것과 동일하다. 정신과 물질이 각각 1원인이 되는 것이며 그로 인해 나는 생각한다 고로 존재한다는 말이 성립하게 되는 것이다.
하지만 이러한 실체관은 오류다. 인간에게 있어 정신과 물질은 몸 하나에 귀속된다. 또 인간은 어떤 경우에도 고존(孤存)할 수 없다. 인간은 고립된 존재가 아니며 끊임없이 타존재와 상호교섭하며 그 존재성을 유지한다. 존재성을 유지한다는 것은 존재를 끊임없이 생성하는 것이며 끊임없이 생성하는 것은 끊임없이 변화하는 것이다. 끊임없이 변화하는 것은 곧 끊임없이 타존재와 교섭하는 것이다. 이는 자기의 존재의 존속을 위해 타존재를 필요로하지 않는다는 실체관을 거부하는 것과 같다. 따라서 정신과 물질을 이루는 자기의 몸은 존재성의 실체가 될 수 없다.
통계학에서 확률을 해석하는 두 관점이 있다. 그 관점은 빈도주의와 베이즈주의다. 빈도주의는 연역적 추론에 해당하며 베이즈주의는 귀납적 추론에 해당한다. 이러한 빈도주의와 베이주주의는 상호보완 관계에 있다. 빈도주의는 확률을 사건의 빈도로 보며, 반대로 베이즈주의는 확률을 사건 발생에 대한 믿음/척도로 바라본다. 또 빈도주의는 모수를 정적으로 전제되어 있는 상수로 보며, 반대로 베이즈주의는 모수를 동적이며 불확실한 변수로로 본다.
빈도주의는 사건을 여러 번 관측하여 발생한 확률을 검정하므로 사건이 독립성을 띤다는 장점이 있다. 예를 들어 동전 앞/뒷면을 여러 번 던져 관찰하게 되면 앞면도 0.5 뒷면도 0.5에 수렴하게 되며 앞면이 나올 확률이 0.5, 뒷면이 나올 확률이 0.5로 고정시킨다. 반면 베이지안주의는 동전이 앞면이 나왔다는 주장의 신뢰도가 50%다, 뒷면이 나왔다는 주장의 신뢰도가 50%라고 말한다. 빈도주의의 단점은 사건이 충분히 발생하지 못해 즉, 표본(데이터)이 부족할 경우 이러한 확률의 신뢰도가 떨어진다는 점이다.
베이즈주의는 이러한 빈도주의의 단점인 만약 여러 번의 사건을 관측할 수 없는 경우에 사용할 수 있다. 예를 들어 쓰나미의 예측 문제와 같다. 쓰나미가 발생하기 위해서는 여러 변수가 있다. 우선 지진이 발생해야하고 이로 인해 단층에 어긋남이 생기고 지형이 변화함에 따라 중력장이 발생할 때 주위로 퍼져나가면서 쓰나미가 된다. 이처럼 발생횟수가 적은 사건들에는 빈도주의를 적용할 수 없다. 다만 베이즈주의를 사용해 귀납적인 추론으로 쓰나미가 발생할 확률을 구할 수 있을 뿐이다. 본 글에서는 이러한 베이즈주의의 근간이 되는 베이즈 정리에 대해 정리하고자 한다.
베이즈 정리란?
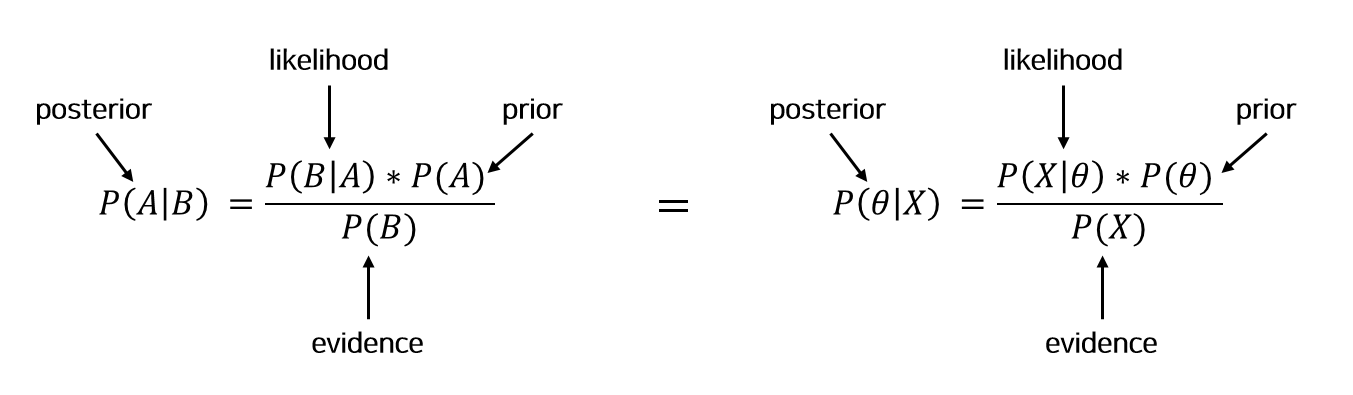
베이즈 정리는 사전 확률(prior probability)과 사후 확률(posterior probability)의 관계를 나타내는 정리다. 이 베이즈 정리는 조건부 확률을 기반으로 한다. 조건부 확률이란 사건 $A$가 발생했다는 전제하에 사건 $B$가 일어날 확률이다. $P(B|A) = {P(B \cap A) \over P(A)}$로 표현한다. 베이즈 정리는 이 조건부 확률에서 유도된 것으로 다음과 같은 수식으로 나타낸다.
위 두 수식은 동일하게 베이즈 정리를 나타낸 것으로 변수명만 달리했다. 그 이유는 이해를 조금 더 쉽게 돕기 위함으로 왼쪽은 조건부 확률로부터 유도될 때 흔히 사용하고, 오른쪽은 베이즈 정리가 결국 모수($\theta$) 추정을 목적으로 한다는 것을 보이기 위함이다. 수식의 의미를 하나씩 분석해보자면, 먼저 posterior는 새로운 표본 X가 관측됐을 때 어떤 모수값을 갖는지를 의미한다. likelihood는 어떤 표본 X가 관찰되었을 때 어떤 확률분포를 갖는 모집단(모수)에서 추출되었을 확률을 의미한다. prior는 사전확률인 모수값을 의미하며, evidence는 모집단으로부터 표본 X가 관측될 확률이다. 결국 이 베이즈 정리를 요약하면 가능도(likelihood), 사전확률(prior), 관측 데이터(evidence)를 이용해 사후 확률(posterior)를 예측하는 방법이다.
베이즈 정리 유도
베이즈 정리를 유도하는 방법은 간단하다.베이즈 정리 유도는 아래 식이 성립됨을 증명하는 것이다.
증명을 위해 조건부 확률 두 개를 구해준 다음 분모를 이항하고 양변을 나눠주면 된다. 앞서 조건부 확률은 $P(A|B) = {P(A\cap B) \over P(B)}$라고 했다. 이를 반대로 하면 $P(B|A) = {P(B\cap A) \over P(A)}$이다. 여기서 양변에 분모를 곱해주면 다음과 같은 형태가 된다.
$P(A|B)P(B) = P(A\cap B)$
$P(B|A)P(A) = P(B\cap A)$
이 때, $P(A\cap B) = P(B\cap A)$이므로
$P(A|B)P(B) = P(B|A)P(A)$가 되고 여기서 양변을 $P(B)$로 나눠주면
$P(A|B) = {P(B|A)P(A) \over P(B)}$가 된다.
베이즈 정리 예시: 스팸 메일 확률 예측
스팸 메일 필터는 특정 단어 포함 여부를 기준으로 스팸 여부를 판단한다. 어떤 한 회사에 수신되는 메일 중 30%가 스팸메일이고 70%가 정상메일이다. 또 스팸메일 내용엔 A란 특정 단어가 포함될 확률이 40%고 정상 메일은 10%다. 이 때 A라는 단어가 보일 때 이 메일이 스팸메일일 확률은 얼마인가?
$P(S) = 0.3$ (스팸메일일 확률)
$P(N) = 0.7$ (정상메일일 확률)
$P(A|S) = 0.4$ (스팸메일에 A가 포함될 확률)
$P(A|N) = 0.1$ (정상메일에 A가 포함될 확률)
$P(A) = 0.19$ (A가 정상메일/스팸메일 모두 포함될 확률)
$P(A)$의 경우 스팸메일에 A가 포함될 확률 + 정상메일에 A가 포함될 확률이다. 두 사건은 상호배타적이므로 덧셈법칙을 사용해 계산할 수 있다. 즉 $P(A) = (P(A|S) * P(S)) + (P(A|N) * P(N))$이다. 이를 계산하면 $(0.4 * 0.3) + (0.1 * 0.7) = 0.19$이다. 즉 $P(A) = 0.19$다.
이렇게 사전 정보를 전부 구했으니 A라는 단어가 보일 때 스팸메일일 확률인 $P(A|S)$를 구해보자. $P(A|S) = {P(A\cap S) \over P(S)}$다. 여기서 이항해주면 $P(A|S)P(S) = P(A\cap S)$다. 이를 계산하면 $0.3 \times 0.4 = 0.12$다.
누적분포함수란 확률론에서 주어진 확률분포가 특정 값보다 작거나 같은 확률을 나타내는 함수이다. 이 특정 값이라는 것은 어떤 사건을 의미하므로 누적분포함수는 어떤 사건이 얼마나 많이/적게 나타나는지에 관한 함수라고도 할 수 있다. 누적분포함수의 대표적인 특징은 확률변수가 이산형/연속형과 무관하게 모든 실수값을 출력한다는 것이다. 예를 들어 주사위를 던져 특정 값이 나올 확률변수 X의 값이 아래와 같이 1~6로 주어져 있다고 가정하자.
이 때 만약 확률변수 X가 2보다 같거나 낮은 수가 나타날 확률이 얼마일까? 고민할 것 없이 1, 2 두 가지 경우이므로 $2\over 6$이다. 그렇다면 만약 확률변수 X가 2.5보다 작거나 같은 경우와 같이 X가 실수 값을 가지는 경우는 어떻게 해야할까? 이 또한 마찬가지다. 확률변수는 이산 값만 갖고 있으므로 2.5보다 같거나 낮은 경우는 1, 2를 가질 경우이니 $2\over 6$다. 또 만약 확률변수 X가 10보다 작거나 같을 확률을 묻는다면? 1, 2, 3, 4, 5, 6 모든 경우가 해당하므로 ${6\over 6} = 1$이 된다. 이처럼 누적분포함수는 확률변수가 이산확률변수/연속확률변수와 무관하게 실수값을 입력으로 받을 수 있다. 이러한 누적분포함수를 수식으로는 다음과 같이 나타낸다.
$F(a) = P(X \leq a) = \sum_{x \leq a} p(x)$
수식을 세 부분으로 나누어 분석해보자면 왼쪽에 가까울수록 추상성을, 오른쪽으로 갈수록 구체성을 띤다. 가장 맨 왼쪽의 함수 $F$는 누적분포함수를 의미한다. 누적분포함수는 특정확률변수보다 같거나 작을 확률을 표현하는 함수이므로 특정확률변수로 $a$를 입력으로 한다. 가운데 식도 마찬가지다 어떤 사건에서 발생할 수 있는 여러 확률변수 중에서 $a$보다 작은 확률변수들의 확률값을 구하는 것이다. 오른쪽 식도 동일하다. $a$보다 작은 확률변수 x에 대해서 모든 합을 구해주는 것이다. 위 주사위 예를 들어 2.5보다 작을 확률이면 $a=2.5$가 되고 확률변수 x는 1,2를 가질 수 있으므로 위 식의 값은 $2\over 6$이 된다. 이러한 누적분포를 그래프로는 다음과 같이 표현할 수 있다.
위 그림에서 확인할 수 있듯 누적분포함수(CDF)는 확률밀도함수(PDF) 전체에 대한 부분을 표현하는 함수라고도 할 수 있다. PDF가 확률변수가 가질 수 있는 전체 확률 분포를 표현한 것이라면, CDF는 전체 확률 분포에서 확률변수가 $a$ 보다 작을 확률이다. 위 예시에서는 $a=1$보다 작을 확률이 되겠다. 이러한 확률밀도함수와 누적분포함수와의 관계를 다르게 말해서, 확률밀도함수를 적분하면 누적분포함수가 되며 또 반대로 누적분포함수를 미분하면 확률분포함수가 된다고 표현할 수 있다.
신장 트리란 그래프 상에서 모든 노드가 사이클 없이 연결된 부분 그래프를 뜻한다. 이 부분 그래프는 여러개가 존재할 수 있다. 따라서 최소 신장 트리란 여러 개의 부분 그래프 중 모든 정점이 최소 간선의 합으로 연결된 부분 그래프이다.
(* 트리와 그래프 관계: 트리는 그래프 중에서 특수한 경우에 해당하는 자료구조로,사이클이 존재하지 않는 방향 그래프다)
최소 신장 트리의 활용
이런 최소 신장 트리는 실생활 곳곳에 활용된다. 예를 들어 도로 건설 문제에서 도시를 노드, 도로를 간선으로 두고 도시 간 이어지는 도로 길이를 최소화 할 때 사용된다. 또 네트워크에서 최적의 라우팅 경로를 선택할 때도 사용되며, 통신에서도 전화선 길이가 최소가 되는 케이블망 구축에 사용되는 등 여러 곳에서 활용된다.
최소 신장 트리 알고리즘
최소 신장 트리를 찾을 수 있는 알고리즘은 크게 2가지로 크루스칼(Kruscal), 프림(Prim) 알고리즘이 있다. 두 알고리즘 간 차이점은 크루스칼은 간선 중심이고 프림은 정점 중심 알고리즘이다. 간선이 적으면 크루스칼을, 간선이 많으면 프림을 사용하는 것이 좋다. 알고리즘 시간 복잡도는 크루스칼이 $O(E+\log (E))$, 프림이 $O(V+E) \log (V)$이다. 두 알고리즘의 공통점 중 하나는 음수 사이클이 있더라도 최소 신장 트리를 구할 수 있다. 본 포스팅에서는 크루스칼 알고리즘만 다룬다.
크루스칼 알고리즘 (Kruscal Algorithm)
크루스칼 알고리즘은 음의 가중치가 없는 무방향 그래프에서 최소 신장 트리를 찾는 알고리즘이다. 최소 신장 트리를 찾기 위해선 사이클 발생 여부를 판단할 수 있어야 한다. 사이클 발생 여부는 union find 알고리즘을 사용해서 판단한다. union find를 알면 크루스칼 알고리즘 이해에 도움되지만 모르더라도 아래 설명을 통해 어느정도 이해 가능할 것이다.
크루스칼 알고리즘은 크게 아래 3단계로 구성되며 2~3이 반복 수행된다.
1. 주어진 모든 간선을 오름차순 정렬 수행한다.
2. 정렬된 간선을 하나씩 확인하며 현재 간선이 노드 간 사이클을 발생시키는지 확인한다.
3. 사이클 발생시키지 않을 경우 최소신장트리에 포함, 사이클 발생할 경우 포함하지 않는다.
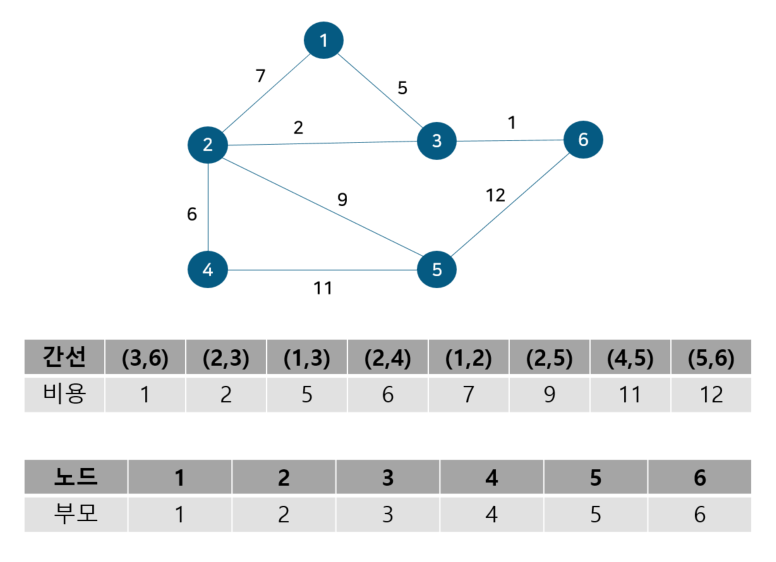
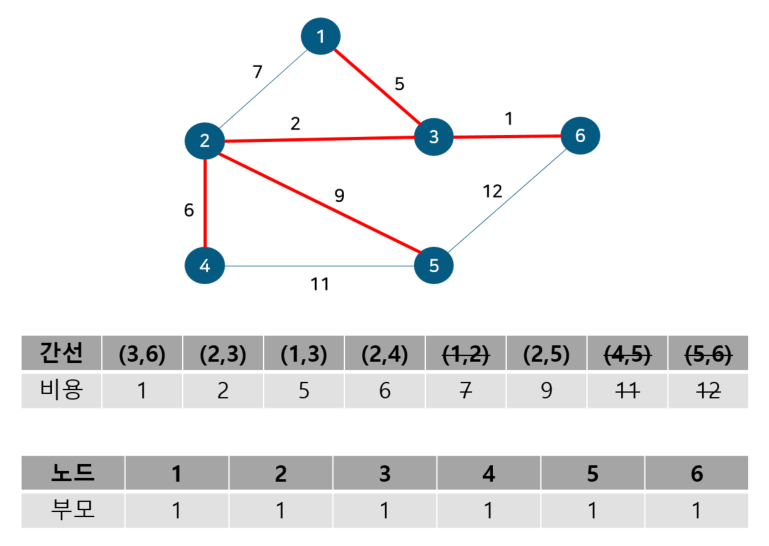
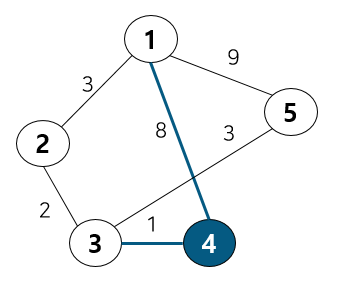
도식화 한 예시로 확인해보자. 예를 위해 아래와 같이 노드 6개와 간선 8개로 구성된 그래프가 있다 가정하자.
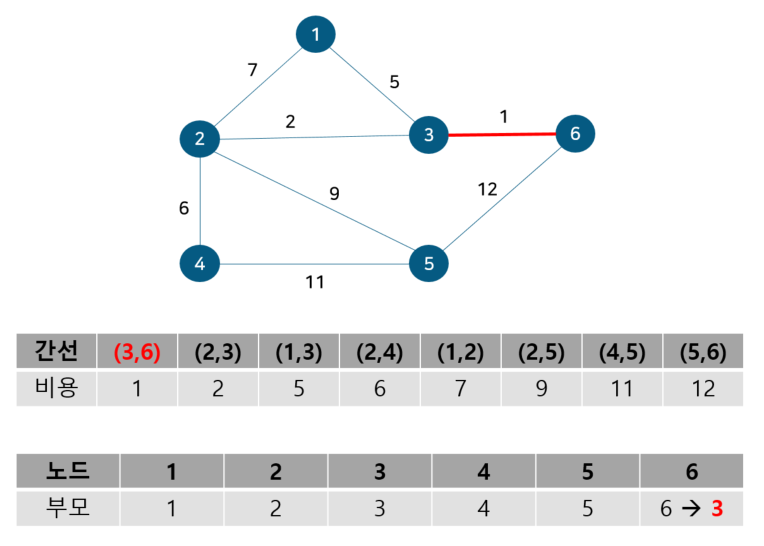
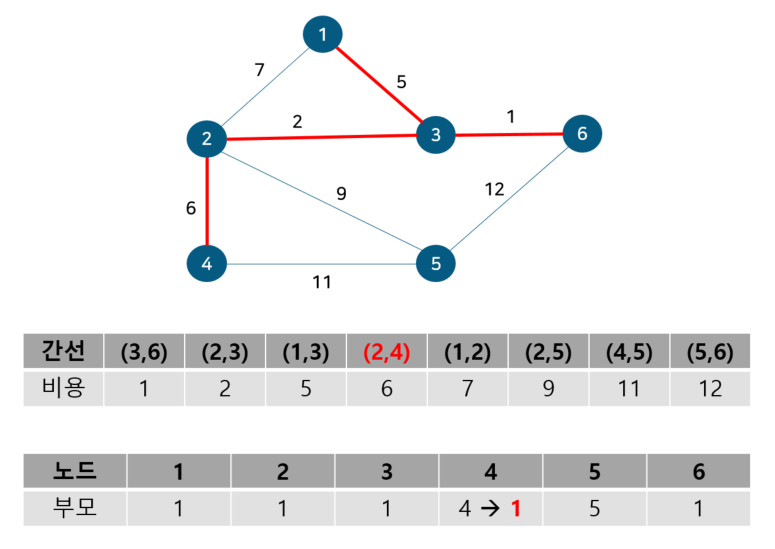
위 그림에서 간선의 비용 별로 오름차순 정렬해 주었다. 또 내부적으로 사이클 여부를 판별하기 위해 union-find 알고리즘을 사용하므로 부모 테이블을 만들어주고 초기값은 노드 자기자신으로 둔다. 이제 간선을 비용이 작은 순서대로 확인하기 위해 먼저 간선 (3,6)을 살펴보자.
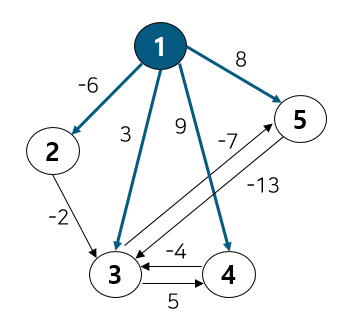
노드 3, 6의 부모 노드를 살펴보면 각각 3, 6으로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (3, 6)을 포함시키고 부모 테이블에서 노드 6의 부모를 노드 3으로 업데이트 해준다. 참고로 일반적으로 부모 노드는 작은 노드 번호 기준으로 업데이트한다. 다음으로 노드 2, 3을 살펴보자
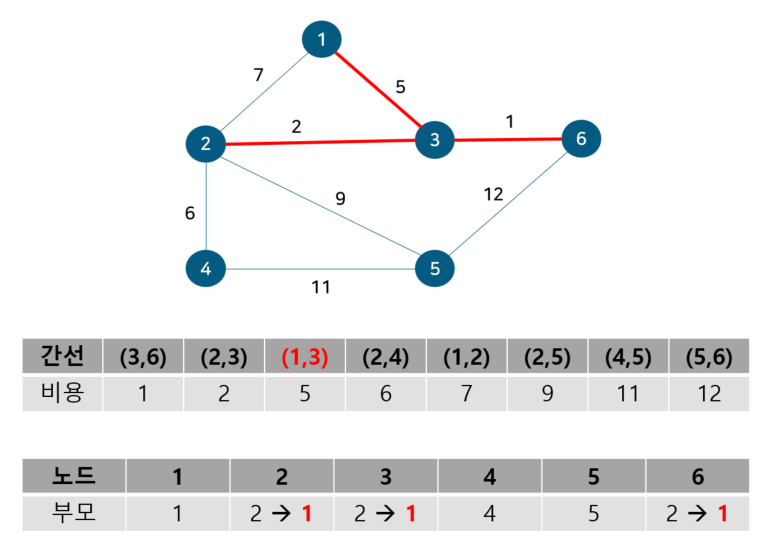
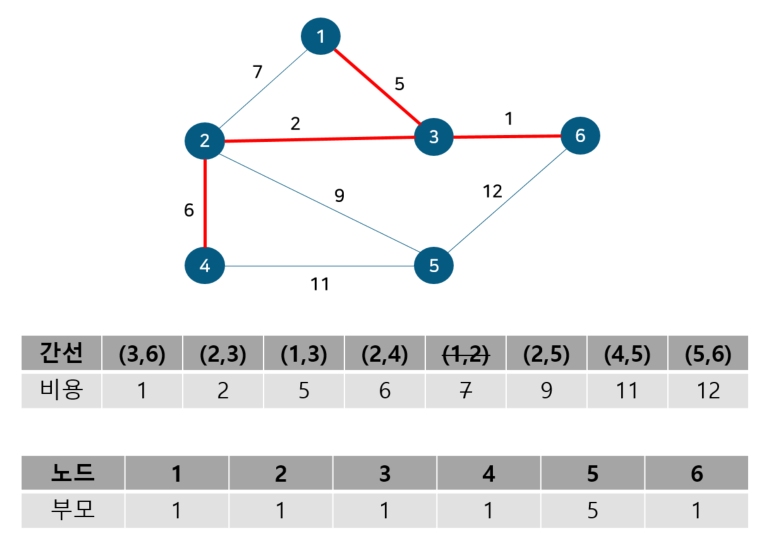
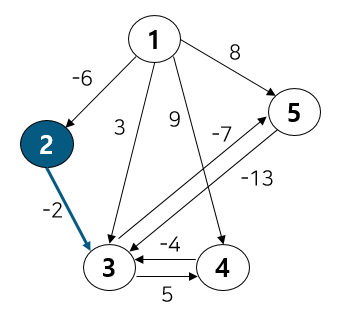
노드 2, 3의 부모 노드를 살펴보면 각각 2, 3으로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (2, 3)을 포함시키고 부모 테이블에서 노드 3의 부모를 노드 2로 업데이트 해준다. 이 때 노드 6도 부모 노드를 3으로 가지는 종속 관계에 있으므로 함께 바꿔준다. 다음으로 노드 1, 3을 살펴보자
노드 1, 3의 부모 노드를 살펴보면 각각 1, 2로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (1, 3)을 포함시키고 부모 테이블에서 노드 3의 부모를 노드 1로 업데이트 해준다. 이 때 노드 2, 6도 부모 노드를 2로 가지는 종속 관계에 있으므로 함께 바꿔준다. 다음으로 노드 2, 4를 살펴보자
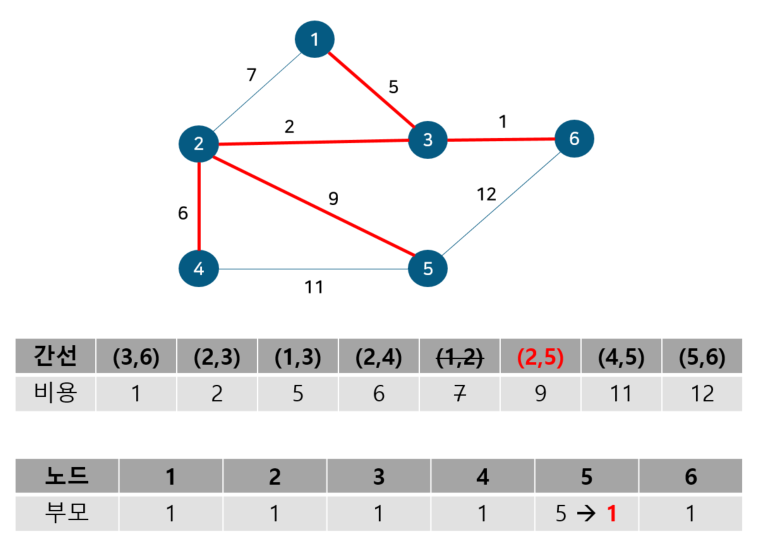
노드 2, 4의 부모 노드를 살펴보면 각각 1, 4로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (2, 4)를 포함시키고 부모 테이블에서 노드 4의 부모를 노드 1로 업데이트 해준다. 다음으로 노드 1, 2를 살펴보자
노드 1, 2의 부모 노드를 살펴보면 각각 1, 1로 같아 사이클이 발생했다. 그러므로 최소 신장 트리에 포함시키지 않고, 부모 테이블 업데이트도 이뤄지지 않는다. 다음으로 노드 2, 5를 살펴보자
노드 2, 5의 부모 노드를 살펴보면 각각 1, 5로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (2, 5)를 포함시키고 부모 테이블에서 노드 5의 부모를 노드 1로 업데이트 해준다. 다음으로 노드 4, 5를 살펴보자
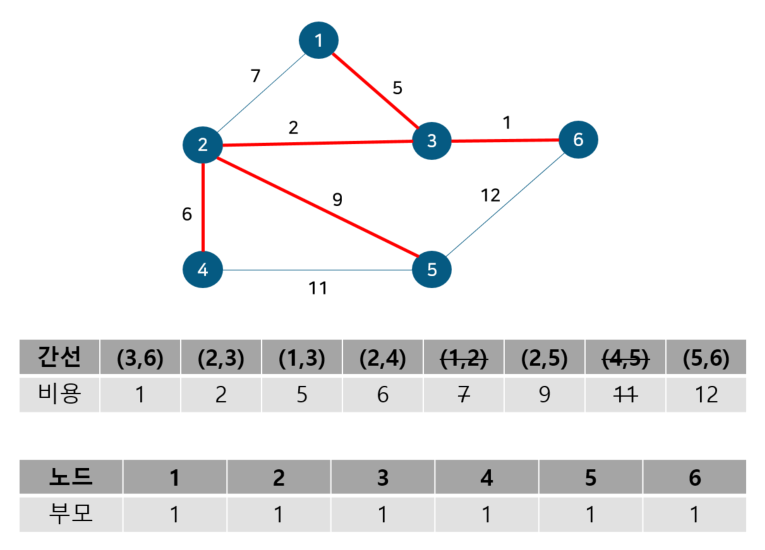
노드 4, 5의 부모 노드를 살펴보면 각각 1, 1로 같아 사이클이 발생했다. 그러므로 최소 신장 트리에 포함시키지 않고, 부모 테이블 업데이트도 이뤄지지 않는다. 다음으로 노드 5, 6를 살펴보자
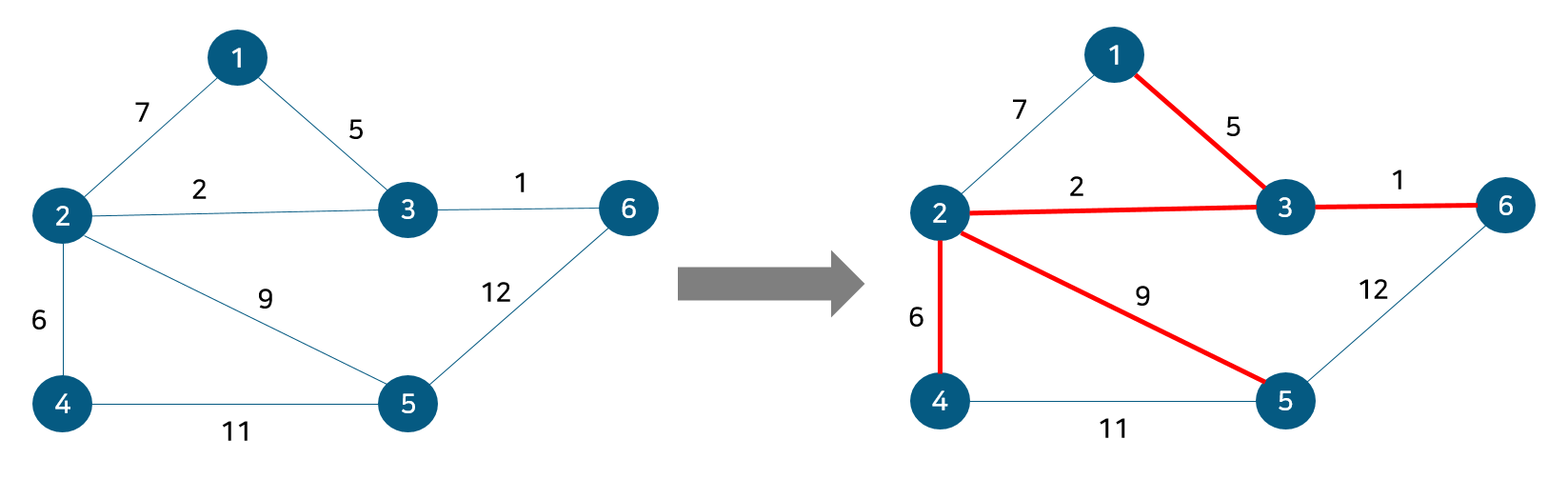
노드 5, 6의 부모 노드를 살펴보면 각각 1, 1로 같아 사이클이 발생했다. 그러므로 최소 신장 트리에 포함시키지 않고, 부모 테이블 업데이트도 이뤄지지 않는다. 이것으로 최소 신장 트리를 찾는 크루스칼 알고리즘 동작이 종료된다. 동작 전과 동작 후를 비교해보자면 다음과 같다.
기존의 그래프 전체에서 사이클 없이 모든 정점을 최소 비용 간선으로 잇는 부분 그래프인 최소 신장 트리다. 이를 코드로 구현하면 다음과 같다.
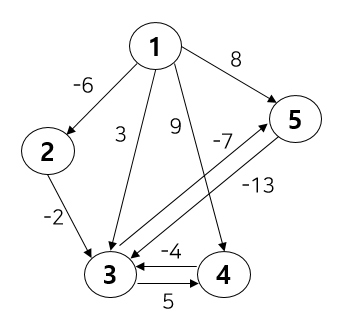
""" This is input value. you can just copy and past it.
then you can get "[(3, 6), (2, 3), (1, 3), (2, 4), (2, 5)]" and "23"
6 8
1 2 7
1 3 5
2 3 2
2 4 6
2 5 9
3 6 1
4 5 11
5 6 12
"""
import sys
input = sys.stdin.readline
def find_parent(parent, x):
""" 부모 노드를 찾기 위해 재귀 수행"""
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
def union_parent(parent, a, b):
""" 부모 노드 비교 후 부모 노드 업데이트 """
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
if __name__ == "__main__":
V, E = map(int, input().split()) # make graph
graph = []
for _ in range(E):
a, b, cost = map(int, input().split())
graph.append([a, b, cost])
graph.sort(key=lambda x:x[2])
parent = [0] * (V+1) # make parent table
for i in range(1, V+1):
parent[i] = i
costs, mst = 0, [] # get mst
for i in range(E):
a, b, cost = graph[i]
if find_parent(parent, a) != find_parent(parent, b): # check cycle
union_parent(parent, a, b)
mst.append((a, b))
costs += cost
print (mst)
print (costs)
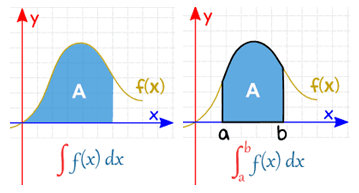
적분은 크게 부정적분과 정적분으로 나뉜다. 부정적분은 미분의 역연산이며, 정적분은 넓이/부피를 계산하는 방법이다. 실용적 관점에서 정적분이 많이 쓰이므로 적분은 대개 정적분을 의미한다. 부정적분과 정적분의 차이는 계산 형태와 적분상수 여부다. 부정적분은 대부분 답이 식으로 도출되며 정적분은 대부분 값으로 도출된다. 이는 부정적분은 $\int $처럼 정해진 구간이 없고 정적분은 $\int_a^b$처럼 정해진 구간이 있기 때문이다. 따라서 정해진 구간이 없는 부정적분은 적분상수가 있고, 정해진 구간이 있는 정적분은 적분상수가 계산 과정에서 사라진다. 이러한 부정적분과 정적분은 도출되는 형태는 다르지만 결국 공통적인 목표는 구간의 넓이/부피를 구하는 것이다.
부정적분 (indefinite integral, 不定積分)
부정적분에서의 부정은 넓이/부피를 계산할 수 있는 적분 구간을 정할 수 없다는 의미다. 따라서 모든 구간에 대해 일반화를 통해 $f(x)$의 넓이가 이러할 것이라 표현할 수 밖에 없어 식의 형태로 도출된다. 만약 함수 $f(x)$의 부정적분을 $F(x)$로 둔다면 ${d\over dx}F(x) = f(x)$으로 표현할 수 있다. 부정적분은 정적분과 달리 식의 형태로 나타나고 적분상수가 있으므로, $\int f(x)dx = F(x) + C$로 표현할 수 있다. 이 때 $F(x)$를 $f(x)$의 원시함수라고도 부른다.
정적분 (definite integral, 定積分)
정적분은 넓이와 부피를 계산할 수 있는 적분 구간이 정해져 있다는 의미다. 따라서 구간의 넓이가 계산되어 수치 형태로 도출된다. 부정적분이 가능한 모든 범위에 대한 일반화라면 정적분은 정해진 구간에 대한 특수화라 볼 수 있다. 정적분의 기호를 풀어 쓰면 $a$와 $b$ 구간에서 높이를 $f(x)$로 두고, 밑변(적분변수)을 $dx$로 두어 넓이를 계산하는 것이다. 참고로 정적분이 $\int_a^b f(x)dx = F(b) - F(a)$로 주어져 있다면 $\left[F(x)\right]_a^b$로도 표현할 수 있다. 그 이유는 정적분하는 과정에서 부정적분을 거치기 때문에 부정적분 식을 따로 쓰기 위한 목적이다.
P.S 향후 필요의 경우 정적분의 종류인 중적분, 이상적분, 스틸체스 적분, 르베그 적분, 리만 적분 등에 대한 내용 추가 예정
정보보안학 석사 과정을 졸업한지 1년 쯤 되어가고, 관심분야도 보안에서 딥러닝으로 바뀐지 꽤 오래 되었네요. 불현듯 자기 전 작년 종합시험 준비로 고통받던 때가 떠올라 이 글을 쓰게 됐습니다. 재학 기간 동안 두 번의 시험 기회가 있었고 첫 번째 기회를 날리는 고배를 마신 뒤 절치부심하는 마음으로 정리한 내용입니다. 중간/기말/종합시험 모두에 어느 정도 도움이 되리라 생각합니다. 가급적 논리적 서술이 가능하도록 정의, 배경, 특징, 장점, 단점, 차이점, 방법, 활용, 종류, 목표 등을 고려해 작성하였습니다. 아래에 예상 질문들은 강의 내용을 총 정리하다보니 자연스럽게 시험에서 이런 것을 물어볼 것 같다고 예상한 질문과 답안들입니다. 중간에 예상 답안이 부재한 경우는 2가지 이유입니다. 첫 번째는 교수님께서 매학기 수업마다 조금씩 설명을 더 해주거나 덜 해주는 파트가 있어 듣지 못해 정리할 수 없었던 부분입니다. 두 번째는 얼추 설명은 해주셨지만 정확히 이해 못하고 모호하게 알고 있는 부분은 지웠습니다. 댓글로 추가해주신다면 업데이트 하도록 하겠습니다. 또 틀린 부분이 있다면 지적해주시면 감사하겠습니다. 참고로 아래 내용들은 강의 요약 내용을 바탕으로 작성한 것이므로 포함하지 않는 내용과 설명들이 있습니다. 원본이 필요할 경우 댓글 남겨주시면 보내 드리겠습니다. 전체 글 내용은 고려대학교 정보보호대학원 김승주 교수님 보안공학 강의 내용을 기반으로 작성되었습니다.
보안공학이란 무엇인가?
H/W와 S/W를 만드는 개발 단계인 요구사항 분석, 설계, 구현, 배포, 유지보수에 이르기 까지 각 단계마다 모두 보안을 고려하고 제품을 판매하는 단계에서도 보안내재화가 이루어졌는지 제대로 이루어졌는지 확인하는 것이다.
보안공학의 목표는 무엇이고 왜 보안공학은 어려운가?
보안공학은 trusthworthy(dependable)한 시스템을 만드는 것을 목표로 한다. 보안공학은 random한 에러를 다루는 소프트웨어공학과 달리 random한 에러와 함께 의도적으로 발생한 intentional 에러도 함께 다루기 때문에 더 어렵다.
define & design approach: 보호해야할 자산을 정확하게 식별한 다음, 자산의 중요도와 이에 따른 요구사항을 정의하고 설계하는 것을 의미한다.
shift-left testing: 매 개발 단계마다 testing을 수행 함을 의미한다. shift-left testing에서 보안 담당자의 역할은 개발자가 testing에 사용할 수 있는 도구를 만들어 공급하고, 개발자가 진행한 testing에 대해 적절성 여부를 검증하는 작업을 진행한다. 이러한 shift-left testing은 자동화가 가능하고, 이른 단계에서 testing을 진행할 수 있다는 장점이 있다.
traceability:
만약 보안공학에서 보안내재화 개발 프로세스를 통해 요구사항분석부터 설계, 구현까지 완벽히 수학적으로 다 증명돼도 모의해킹이 필요한가?
모든 것을 수학적으로 증명했다 하더라도 모의해킹이 필요하다. 수학적 증명은 전제조건을 가지고 있으며 이 전제조건이 제대로 지켜지고 있는지를 검증하기 위해서는 모의해킹이 반드시 필요하다. 이는 수학적 증명과 모의해킹이 상호보완 하는 관계라고 볼 수 있다.
바람직한 S/W 요구사항 도출 조건의 6가지와 그 특징은 무엇인가?
Unambiguity: 다른 사람이 요구사항을 검토한 결과는 동일해야 하며 요구사항에 모호함이 없어야 한다.
Prioritization: 요구사항의 구현과 관련하여 우선순위가 부여되어야 한다.
Verifiability: 요구사항이 제품에 적절하게 구현되어야 하고, 검증하기 위한 Security Testing Requirement도 함께 도출되어야 한다.
Completeness: 모든 필요한 요구사항이 전부 도출되어야 한다. (지정된 모든 요구사항은 전달해야 하는 기능을 완전히 설명해야 한다)
Correctness: 해당 요구사항은 자체 모순을 가지거나 충돌되지 않고 그 기능을 정확하게 설명해야 한다.
Feasibility: 해당 요구사항은 자원 및 제약조건에서 실행 가능해야 한다.
보안성 평가에서 TCSEC의 보안등급 중 A2는 왜 사용하지 않는가?
TCSEC을 처음 만들 당시 A2 등급인 Code Proof(Code Assurance)까지 넣으려고 하였다. 하지만 TCSEC을 제작자는 Code Assurance의 입증이 어렵다고 판단하여 마지막에 A2를 제거하고 A1만 남겼다. Code Assurance는 Software testing과 Software verification으로 구성되는데, 특히 software testing에서 만약 소스코드가 대략 10,000줄이 이상 넘어가게 된다면 포인터 등으로 인한 복잡성 때문에 수학적 안정성 입증이 어려워지기 때문이다.
TCSEC의 단점을 서술하시오
보안등급평가에 있어 Assurance와 Functionality가 서로 분리되어 있지 않아, High Assurance임에도 불구하고 낮은 보안등급으로 평가하는 결점이 있다.
보안성 평가 표준인 CC, CAVP, CMVP, C&A, RMF A&A, DITSCAP에 대해 설명하시오.
CC: (개념) 보안성 평가와 관련해서 가장 권위있는 국제 표준이다. 보안성 평가 국제표준(ISO/IEC 15408)의 공통평가기준(CC)에 따라 정보보호시스템의 기능 및 취약성을 평가/인증하는 제도이다. (배경) 미국의 TCSEC으로부터 유럽연합의 ITSEC, 캐나다의 CPCPEC, FC 등이 만들어지게 되었고 이를 만든 각국가의 평가기관들은 국가적으로 독립된 평가 기준을 통합하는 프로젝트를 시작하였고 이를 CC 프로젝트라 하였다. CC 프로젝트는 TCSEC의 단점을 보완하고 기존의 평가 기준들간의 개념적/기술적 차이를 통합하여 국제 표준화를 만들자는 목표로 추진되어 만들어 졌다. (목적) CC인증은 평가과정에서 IT제품(H/W, F/W, S/W)에 적용되는 보안 기능과 보증수단에 대한 공통의 요구 사항들을 제시한다. 이를 통해 독립적으로 수행된 보안성 평가의 결과들을 비교할 수 있도록 한다. 평가 결과는 소비자가 IT 제품이 그들의 보안 요구를 충족시키는지 결정하는데 도움을 줄 수 있다.
CAVP (Cryptographic Algorithm Validation Program): 암호 알고리즘을 중심으로 제대로 구현되었는지를 검증한다.
CMVP (Cryptographic Module Validation Program): 특정한 암호 모듈이 특정한 암호 알고리즘을 올바르게 구현했느냐에 대한 구현 적합성을 시험/인증 한다. CMVP와 CC의 공통점은 제품이 요구사항분석단계부터 설계, 구현에 이르기까지 보안내재화 프로세스를 충실히 따랐는가를 본다. 이것이 발전해서 C&A 제도가 되었다.
C&A (Certification & Accrediation):
RMF A&A: 2015년 DoD Cyber Strategy를 발표했고, 이 내용은 전산시스템 뿐만 아니라 F35 스텔스 전투기나 무인 드론과 같은 첨단 무기체계들도 보안내재화 개발 프로세스를 적용하라는 것을 요구한 것이다. RMF A&A는 이러한 요구사항을 충족시키고 실제로 준수하였는지 평가하기 위해 만들어진 표준이다.
(다소 설명이 빈약하다 생각들어 몇몇 부분은 추가되면 좋을 것 같습니다)
CAVP, CMVP, CC, DITSCAP, NIST C&A, RMF A&A의 정의 및 비교와 국내외 정책비교를 서술하라.
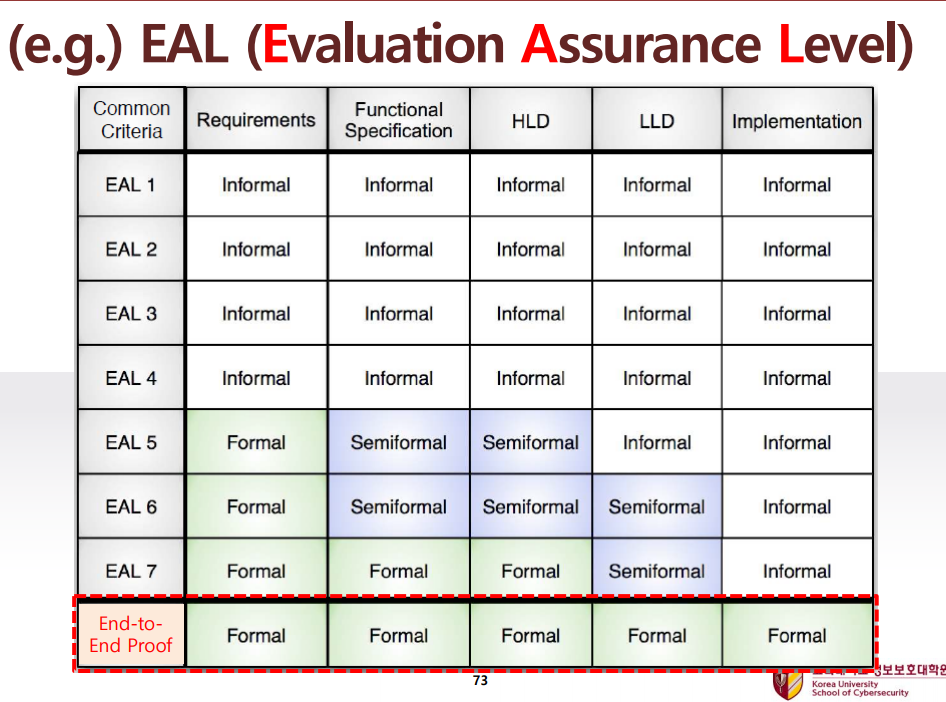
EAL 보안성평가에서 낮은등급에서 높은등급이 되기 위해 필요한 조건은?
Requirements, functional specification, HLD, LLD, implementation에 대해 formal method로 정형명세화 하여 수학적으로 만족함을 입증하여야 한다.
Information Security, Information Assurance or Cybersecurity의 차이를 서술하시오
핵심 차이는 trusthworthy라고 할 수 있다. information security는 컴퓨터와 컴퓨터에 들어있는 전자적 정보를 지키는 것을 의미하며, cybersecurity는 사이버공간과 연동된 모든것을 지키는 것을 의미하는데 여기에는 digital과 non-digital 정보도 함께 포함된다.
걸프전이 최초의 Information Assurance인 이유는 무엇인가?
이 질문에 대해 답을 정리하진 못했습니다. 다만 이 예상 질문과 관련한 부분적인 내용들을 기술하면 다음과 같습니다.
걸프전의 맥락에서 사용되어 정리하고 가야할 용어인 information security와 cybersecurity가 있다. 두 용어의 큰 차이점이자 추구하는 목표는 trustworthy이다.
Information Security: 컴퓨터와 컴퓨터 속에 들어 있는 전자적인 데이터를 보호하겠다라는 의미를 가진다.
Informaton Assurance or Cybersecurity: 사이버공간과 연동된 모든 것을 보호하겠다라는 의미를 가지며, 그 모든 것은 전자적인 형태(digital)의 데이터여도 되고 전자적인 형태(non-digital)가 아니여도 된다.
걸프전은 정보보증(Information Assurance)이라는 패러다임 shift를 발생시킨 선구자 역할을 했다는 점에서 의미가 있다.
걸프전에서는 패러다임 shift가 information security에서 information assurance로 바뀌었고, 이는 적의 정보는 교란시키고 내 정보를 유지시키는 것이 중요하다고 인식하게 되면서 이를 위한 목표인 trustworthy를 달성하기 위함이다.
걸프전을 통해 Information Assurance가 중요해졌다. 이는 원할때 Access 가능해야 하고, 그 정보는 항상 relability와 security를 유지 가능해야 함을 의미한다.
Risk Management란 무엇이고, 구성요소와 이에 대한 정의는 무엇인가?
Risk Management는 기본적으로 Risk를 제거하는 것이 아니라 줄이는 것이다. 하지만 Risk를 줄인다하더라도 잔존 위협(Residual Risk)가 남아있게 된다. 이 때 이 잔존 위협을 어떻게 잘 관리할지 고려하는 것을 Risk Management라고 한다. 참고로 이를 위해선 자산별, 중요도 별 등급화가 되있어야 Risk를 측정할 수 있다. Risk Management 방법은 크게 4가지로, Risk Transfer, Risk Avoidance, Risk Reduction, Risk Retention이 존재한다.
Risk Transfer: 위협을 보험사와 같은 제 3자에게 전가하는 것을 의미한다.
Risk Avoidance: 위협을 회피하는 것을 의미하는 것으로 단적 예로 스마트TV에 카메라 떼는 것과 같다.
Risk Reduction: 보안 대책을 만들어 위험을 감소시키는 것을 의미한다.
Risk Retention: 위험의 확률이 낮으면 위험을 안고 가는 것을 의미한다.
결과적으로 이를 통해 Risk Avoidance를 제외하고 어떤 것이 ROI가 높은지 비교하여 그에 맞는 대응책을 세운 뒤, 높은 리스크부터 낮은 리스크로 대응해야 한다.
Risk Assessment의 특징과 그 한계를 설명하시오.
Risk Assessment는 quantitative risk analysis (정성적), qualitative risk analysis (정량적)로 크게 둘로 나뉜다. 리스크 분석은 정량적으로 분석하는 것이 객관성을 담보할 수 있다는 장점이 있지만 적용하고자 하는 사람의 탄탄한 수학적 이론이 뒷받침 되어야 하므로 실적용엔 무리가 있다. 따라서 무기체계분석이나 자동차보안성평가와 같은 필드에서는 정성적 분석 방법을 사용하는 것이 특징이다. (Risk = Probability * Damage Potential)
Shannon's perfect secrecy : 무한한 컴퓨팅 자원을 가진 passive attacker로 부터 암호문에서 평문에 대한 어떠한 정보(단, 1bit라도)도 누출되서는 안된다.
Goldwasser's semantic security : 유한한 컴퓨팅 자원을 가진 passive attacker로부터 암호문에서 평문에 대한 어떠한 정보(단, 1bit라도)도 노출되서는 안된다.
MDTD(Model Driven Test Design)가 test case create에 도움이 되는 이유는?
testing하려는 대상을 작은 task 단위로 모델링하여 해당 task에 집중적으로 testing할 수 있기 때문이다.
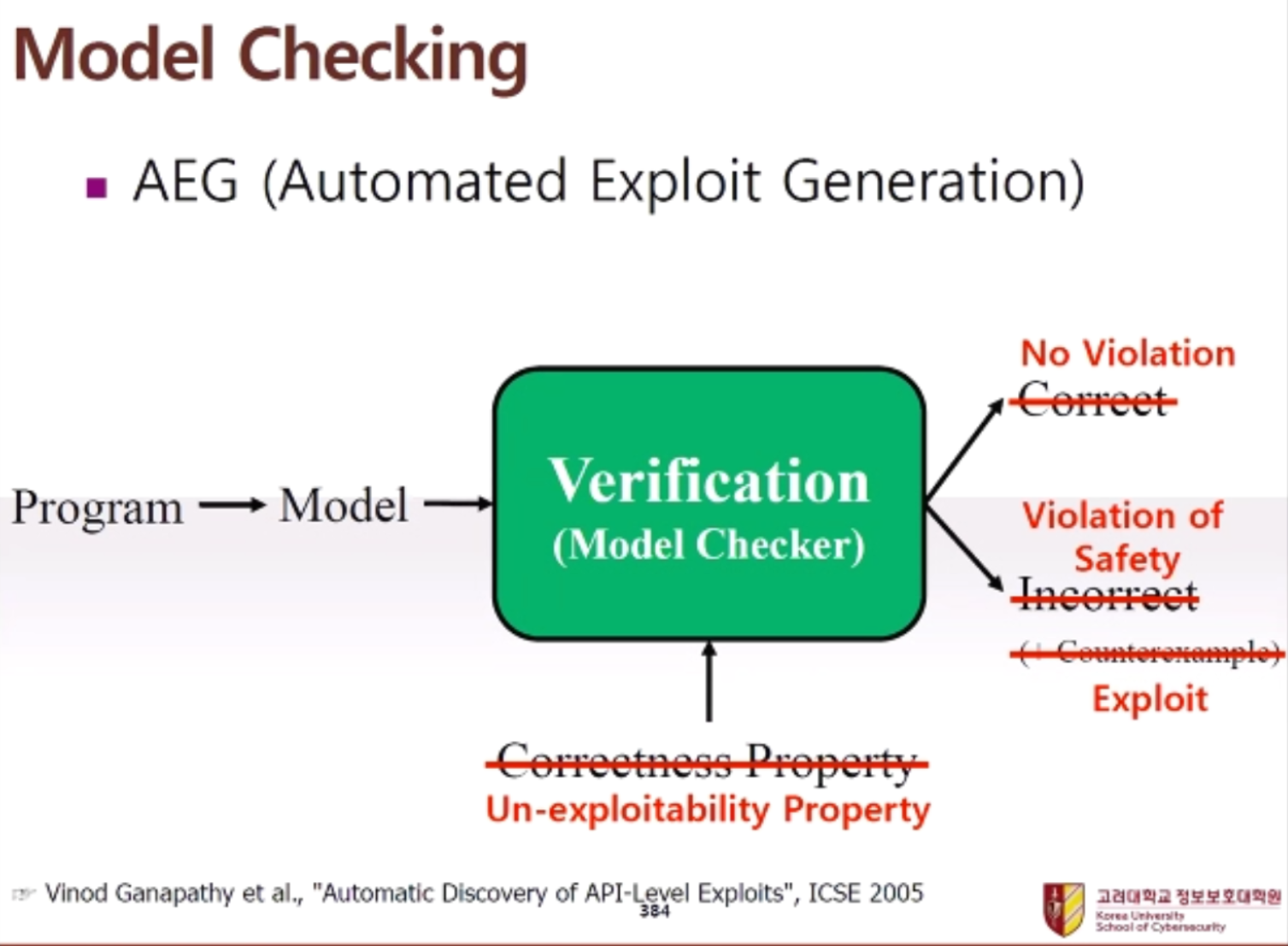
Model Checking 이론을 바탕으로 Code Assurance를 달성하는 방법 및 프로세스를 상세히 서술하시오.
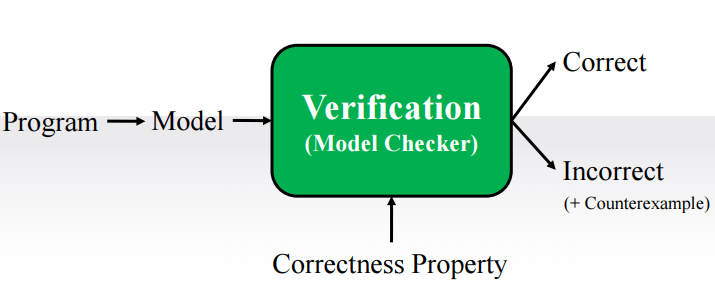
프로그램을 model로 만들고 model checker에 requirement(ex: correctness property)를 넣었을 때 model checker에서 model이 requirement를 충족하는지에 대한 여부를 Yes/No로 알려준다. 만약 No의 경우에는 counter measure도 함께 알려준다. 결과적으로 model checker를 통해 해당 프로그램의 model이 requirement를 충족하는지 판단한다. (Model Checker는 완전 자동화가 가능하다는 장점이 있고, Automatic Theorem Prover에 비해 적용 범위가 작다는 단점이 있다.)
데이터 거버넌스에 대해 설명하시오
데이터거버넌스의 핵심은 데이터 사일로(칸막이) 문제로 인해 도입된 개념으로 데이터 활용을 위한 전사적인 경영체계라 할 수 있다. 조직은 이러한 데이터 거버넌스를 통해 데이터 활용 계획과 데이터 보호 계획을 수립하여 활용도를 극대화 시켜서 궁극적으로 데이터 사일로를 제거하는 것을 목표로 한다.
14가지 Security Design Principle과 각각이 의미하는 바를 서술하시오.
Least Privilege: 사람 또는 시스템에게 부여할 최소한의 권한을 부여하는 것을 의미한다. 하지만 이 최소권한의법칙을 지키기 위해 보안레벨을 사용자와 오브젝트 사이에 어떻게 설정해야 하는가는 쉽지 않다.
Fail-Safe Default: 두 가지 의미를 가진다. 첫 째는 명시적 허용이 아니면 거부를 의미한다. 예를 들어 방화벽 룰셋에 명시되지 않은 패킷이 있을 경우 drop하는 것과 같다. 둘 째는 만약 프로그램이 비정상 상태로 빠질 경우, 바로 직전에 안전했던 상태로 돌아가는 것을 의미한다. 이를 통해 프로그램을 항상 안전한 상태로 유지시킬 수 있게 한다. 예를 들어 윈도우 블루스크린이 표시되어 먹통이 되는 상태로 빠지지 않게 하는 것과 같다.
Economy of Mechanism: H/W, S/W를 개발할 때 가능한한 시스템을 단순하고 작은 사이즈로 설계하고 구현해야 함을 의미한다. 단순하고 작은 사이즈로 설계하는 것은 모듈화 설계와 같다. 장점은 요구사항을 달성하고 있는지 검증이 쉬워진다. 심플할수록 assurance level이 높아진다. simple and small이 의미하는 바는 검증하기 쉽도록하여 assurance level을 극대화 시킨다는 것이 핵심이다.
Complete Mediation: 자원에 접근할 때 마다 반드시 그 권한에 대해 확인해야하는 것을 의미한다. 모든 접근을 전부 확인하는 것을 zero-trust라고 한다. 하지만 실질적으로 모든 접근에 대한 확인은 부하로 인한 속도저하가 심해서 구현하기 어려운 것이 특징이다.
Design by Contract: 어떤 일을 처리할 때 항상 확인된 인터페이스를 통해서만 해당 일을 처리해야함을 의미한다. 예를 들어 중요한 시스템일수록 사전 정의된 인터페이스 또는 사전 정의된 프로토콜을 통해서만 중요 자원에 접근할수 있도록 하는 것을 의미한다.
Open Design: 어떤 시스템을 만들었을 때 그 시스템의 설계도나 소스코드가 공개되어도 안전도가 유지될 수 있어야 한다는 것을 의미하고, 시스템의 안전성을 설계도나 소스코드의 폐쇄성에 의존하지 않아야 한다는 것을 의미한다. 예를 들어 군에서 같은 모듈을 사용하는 무전기를 분실하게 되면 리버싱하여 소스코드를 알아낼 수 있기 때문에 시스템을 만들때 설계도나 소스코드가 공개됐다고 전제한 다음 시스템을 만들라는 것이다. 그래서 만약 안전하다면 오픈 디자인 원칙에 충실하다 할 수 있다. 동의어는 Kerckhoff's 법칙이라고도 하며, 반대말로 Security through Obsecurity 또는 Security by Obsecurity라고도 한다.
Seperation of Prvilege: 중요시스템에 접근할 때는 그 권한을 분산 또는 분리해야 함을 의미한다. 예를 들어 핵무기를 동작시킬 때 두 사람의 암호를 동시에 입력해야 작동하는 것과 같다.
Least Common Mechanism: 시스템의 공통 모듈을 최소화해서 활용해야 함을 의미한다. 이는 보안에서 한 부분에 문제가 생겼을 때 다른 부분으로 파급되는 것을 최소화하는 것이 중요하기 때문이다. 하지만 현실적용에는 어려운 부분이 있는데 이는 공통모듈을 쓰면 생산성은 높아지나, Economy of mechanism의 개념과 정면으로 위배되는 특징이 있기 때문에 시스템을 만들다보면 이 개념에 충실하기 쉽지 않은 것이 특징이다.
Psychological Acceptability: Usable Security라고도 부르며 이는 시스템이 사용하기 편리해야 함을 의미한다.
Defense in Depth: 보안 시스템을 둘 때 계층을 두어 한 계층이 뚫히더라도 다음 계층이 막아줄 수 있도록 시스템을 설계해야 함을 의미한다.
Effective Logging: 로그를 잘 남겨야 함을 의미하는 것으로, 개인정보보호법으로 인해 로그에 어떤 정보가 들어가면 안되는지 또한 중요해진 것이 특징이다.
Build In, Not Bolt On: 시스템을 개발한 다음 보안제품을 사서 쓸 것이 아니라, 처음 만들 때 보안이 Build In되도록 만들어야 함을 의미한다.
Design for Updating: 업데이트를 어떻게 할 것인가를 설계해야 함을 의미한다.
Centralized vs Decentralized: 중앙화 시킬 것인지 분산화 시킬 것인지를 의미한다.
What is 'sound'?
Threat Modeling의 개념과 절차적 특징을 서술하시오.
Threat Modeling은 목표 시스템에 대한 어떤 위협요소가 없는지를 공격자의 입장에서 체계적으로 분석할 수 있는 방법론을 의미한다. 이를 통해 목표 시스템의 attack surface 식별, 얼마만큼의 위협이 발생하는 가를 측정할 수 있다. 또한 보안대책과 보안대책에 대한 테스트와 같은 일련의 청사진을 도출해낼 수 있다는 것이 특징이다. 전반적인 프로세스는 다음과 같다.
DFD를 통해 우선적으로 모델링한 후 지켜야할 자산을 중요도 별로 우선순위를 식별한다.
분석대상 시스템에 대해 취약점정보와 관련된 attack library를 수집한다.
공격자의 관점에서 STRIDE를 이용하여 어떤 element에 취약점이 매핑될 수 있는지를 확인한다.
매핑된 정보를 기반으로 공격시나리오를 생성 후 attack tree로 표현한다.
SRIDE: 모델링된 시스템에서 element 별로 공격자의 입장에서 취약점을 도출할 수 있는 보안위협모델링 방법이다. Spoofing(위장), Tampering(변조), Repudiation(부인), Information DIsclosure(정보유출), Denial of Service(서비스거부), Elevation of prvilege(권한상승)으로 구성되어 있다. SRIDE에는 분석 방법이 2가지로 stride-per-element와 stride-per-interaction이 있다. stride-per-element는 element 별로 S,T,R,I,D,E 공격이 발생할 수 있을지 검증하는 것을 의미하고 stride-per-interaction은 trust boundary를 넘나드는 데이터 흐름들에 대해 중점적으로 분석하는 방법을 의미한다.
Attack Tree: 수집한 취약점 정보를 엮어 공격시나리오화 시킬 수 있는 방법으로, 하나의 목표 별로 하나의 Attack Tree가 만들어지는 것이 특징이다.
DREAD: DREAD는 5가지 항목으로 구성되어 있고 각각은 다음과 같다.
Damage Potential: 공격자가 굉장히 민감한 데이터를 탈취하거나 파괴할 수 있음을 의미한다.
Reproducibility: Timing winodow가 크거나 작음을 의미하는 것으로, Timing window가 작은 예시로는 컴퓨터가 부팅될 때만 공격이 가능하고 Timing winodw가 큰 예시로는 컴퓨가 켜져 있으면 언제든 가능할 때를 의미한다.
Exploitability: 공격 프로그램으로 만들기가 얼마나 쉬운가를 의미한다.
Affected Users: 공격으로부터 영향을 받는 사용자가 얼마나 많은가를 의미한다.
Discoverability: 해당 취약점을 얼마나 발견하기 쉬운가를 의미한다.
Risk score = DREAD/5이다. 이러한 Risk score의 단점은 절대적이지 않고 사람마다 상대적인 것이다. 따라서 2010년 이후 MS에선 더이상 사용하지 않고, security response center bulletin ratings를 사용해 사람마다 오차가 생기는 것을 막고자 하였다.
LINDDUN을 설명하시오.
LINDDUN은 DFD를 작성한 뒤 개인정보보호의 관점으로 보안위협식별을 수행하는 방법이다. LINDDUN을 이루는 구성요소와 이에 대한 설명은 아래와 같다.
Linkability:
Identifiability:
Non-repudiation:
Detectability:
Disclosure of Information:
Unawareness:
Non-compliance:
TARA를 설명하시오.
Threat Assessment and Remediation Analysis로 2011년 MITRE에서 만들어진 것으로, 국가의 지원을 받는 해커들이 있다는 전제하에 위협모델링을 어떻게 할 수 있을까를 위해 만들어졌다. 일반적인 해커와 달리 국가의 지원을 받는 해커는 기존의 Threat Modeling을 할 수 없는데 이는 투입비용의 한계가 없기 때문이다.
Structured Threat Assessment Process란 무엇인가?
핵심은 모의해킹과 위협모델링(Threat modeling)을 합쳐서 수행하는 것을 의미한다.
Formal Method의 특징을 서술하시오
어떤 시스템에 대한 요구사항을 수학적 기법을 이용하여 요구사항을 정확하게 기술하고 그 요구사항이 제대로 달성되었는지를 검증하는 것을 의미하는 것으로, 크게 formal specification과 formal verification으로 구성된다.
security policy는 security requirement의 집합으로, 어떤 것을 보호해야하고 그것을 어떻게 보호할 수 있을까를 의미한다.
security policy modeling은 좁은 의미로는 security policy를 정형명세로 기술해둔 것을 의미하고, 넓은 의미로는 security policy를 정형명세로 기술하고 그 요구사항이 제대로 충족되었는지를 검증까지 하는 것이다. 검증에는 두 가지 의미가 포함된다. requirement 간의 모순점이 없는지를 검증하고, 설계도가 요구사항을 전부 반영하여 제대로 설계되었는지를 검증한다.
또한 보안성평가의 국제표준인 CC을 확인하면 EAL1~EAL7이 있는데 EAL4까지는 security policy를 제출할 것을 요구하나 EAL5부터는 security policy model을 제출할 것을 요구한다. 여기서 model은 정형명세로 제출하는 것을 의미한다.
DAC의 개념, 특징, 장단점 등에 대해 서술하시오.
DAC은 임의적 접근통제정책을 의미하는 것으로 데이터의 소유주가 데이터에 접근가능한 권한을 결정할 수 있고, 운영체제에 의해 시행되는 것이 특징이다. 장점으로는 필요한 사람에게 권한을 부여할 수 있는 최소권한법칙을 달성하기 쉽고 협업이 편하다는 장점이 있다. 반면 카피에 취약한 구조로 내가 권한을 부여했던 사람이 다시 다른 사람에게 데이터에 접근하는 권한을 부여할 수 있다는 것이 단점이다. 따라서 군에서는 이를 사용할 수 없는데 이에 대안으로 만들어진 것이 강제적 접근정책인 MAC이다.
MAC의 개념, 특징, 장단점 등에 대해 서술하시오.
MAC은 강제적 접근통제정책을 의미하는 것으로 주체와 객체의 보안등급에 따라 허가 또는 제한하는 것이 특징이다. 중앙집중형으로 엄격한 보안을 제공할 수 있는 것이 장점이나 모든 접근에 대해 확인해야 하므로 성능 저하가 발생할 수 있다는 단점이 있다. 또한 최소권한의법칙을 충족하지 못한다는 단점이 있고, 이 때문에 보안레벨로만 접근권한을 통제하지 않고 Compartment의 개념을 추가하여 최소권한의법칙을 달성하고자 하는 MLS 정책이 만들어졌다.
BLP 모델의 개념, 특징, 장단점 등에 대해 서술하시오.
벨과 라파듈라는 MLS 정책또한 충분하지 않기 때문에 Define and Design Approach를 해야 한다고 주장하며 1973년 BLP 모델을 제시하였다. 가장 먼저 달성해야할 것을 정의하고, 접근통제정책이 올바르게 시행되려면 SS-Property, *-Property가 만족해야되어야 한다고 하였다.
SS-Property (Simple Security Property): 기존의 MLS의 특징인 사용자가 가진 보안등급과 compartment의 범위가 접근하려고 하는 object의 보안등급과 compartment 범위보다 커야지만 object에 접근할 수 있음을 의미한다.
*-Property (Start Property): 기존 MLS를 충족하는 시스템은 SS-Property만 충족한다는 단점을 보완하기 위해 나온 개념으로 subject가 SS-property를 만족했다는 전제하에 보안등급이 높은 object에서 데이터를 읽고 낮은 등급의 object에 쓰면 안된다는 것을 의미한다. 어떤 것을 충족하고 어떤 것을 충족하지 않는지를 명확히 표현하는 것이 중요하다는 것을 보였다는 점에서 의의가 있는 것도 특징이다.
BLP 모델은 security property를 기밀성 관점에서만 고려하기 때문에 무결성 관점을 고려하지 못한다는 단점이 있고, Covert Channel에 취약하다는 단점이 있다.
BLP 모델에서 권한이 높은 프로세스와 권한이 낮은 프로세스간의 통신 방법은 무엇인가?
권한이 높은 프로세스가 권한이 낮은 프로세스와 통신을 해야할 때가 있지만 권한이 높은 곳에서 낮은 곳으로의 데이터가 쓰이는 것을 막았기 때문에 데이터를 전달할 수 없다는 단점이 있다. 이를 해결하기 위한 대안이 2가지가 있는데 첫 번째는 subject security level을 순간적으로 낮추는 방법이 있고, 두 번째는 *-Property를 위반해도 되는 Trusted subject group을 생성하여 서로간의 등급이 다르더라도 데이터를 주고 받을 수 있도록 하는 방법이 있다. 첫 번째 방법을 실제로 구현한 것이 MULTICS이다.
McLean이 BLP 모델에서 비판한 평정속성은 무엇을 의미하는가?
Tranquility(평정속성): 시스템이 한 번 세팅되면 사용자들의 권한은 바뀌지 않음을 의미한다. 벨과 라파듈라는 BLP 모델의 전제를 평정속성으로 하였지만 McLean으로부터 전제조건이 위반되었다고 지적하였다.
BLP 모델에서 주어진 formal method를 참고하여 SS-Property를 표현하시오.
SS Property = No Read Up
A state $(b, M, f)$ satisfies the SS-Property if
$\forall (s, o, a) \in b,$ such that $a \in \{read, write\}$
$f_O(o) \leq f_S(s)$
a subject can only observe objects of lower classification.
read 또는 write를 하고 있는 모든 subject와 object에 대해 object의 보안등급이 subject의 보안등급보다 낮으면 모든 action은 read 또는 write이다.
BLP 모델에서 주어진 formal method를 참고하여 *-Property를 표현하시오.
BiBa 모델의 개념, 특징, 장단점 등에 대해 서술하시오.
BLP 모델이 나온 뒤 기밀성만 다룬다는 단점을 보완하기 위해 무결성 관점을 다루기 위해 나오게 된 것으로 BLP 모델과 logical dual이라 할 수 있다. 무결성 관점에서는 정보의 흐름이 높은 곳에서 낮은 곳으로 가야한다. BLP 모델과 동일하게 SS-property와 *-Property를 동일하게 주장하였다.
SS- property (Read up)
subject의 integrity level이 object의 integrity level보다 높거나 같아야 데이터를 읽을 수 있음을 의미한다.
*-property (Write down)
subject의 integrity level이 object의 integrity level보다 높거나 같아야데이터를 쓸 수 있음을 의미한다.
클락 윌슨의 상용 컴퓨터 시스템과 군 전용 시스템에 대한 비교 논문의 의의를 서술하시오.
1983년 클락윌슨이 상용컴퓨터시스템의 보안정책과 군에서 쓰는 보안정책의 비교논문을 낸 바 있다. 내용의 핵심은 군에서는 Integrity가 중요하지 않을지 모르나 상용시스템에서는 Confidentiality보다 Integrity가 훨씬 중요하기 때문에 Integrity와 관련한 security requirement를 명확히 정의하고 디자인하는 것이 중요하다고 주장하였다. 이 논문은 사람들이 접근통제정책이 confidentiality 뿐만 아니라 Integrity도 중요하다고 생각하게 되었다는 점에서 의의가 있다.
Clark-Wilson Model을 설명하시오
가장 큰 특징 & 종류 및 개념 Clark-Wilson 모델의 가장 큰 특징은 Well formed transaction을 정의했다는 것이고 이는 절차가 잘 정의된 프로세스를 의미한다. Clark-Wilson Model은 CDIs, UDIs, TP, IVPs의 4가지 요소로 구성된다.
CDIs: Contrained Data Items의 약자로 Integrity가 중요한 데이터셋을 의미한다.
UDIs: Unconstrained Data Items의 약자로 Integrity가 중요하지 않은 데이터셋을 의미한다.
TP: Transformation Procedures로 일종의 업무 매뉴얼을 의미하는 것으로 업무 매뉴얼에 따라 절차가 엄격히 정의된 프로세스를 통해서만 접근 가능한 것이 특징이다. 예컨데 CDIs에 접근하려는 USER는 반드시 TP를 통해서만 접근해야 한다.
IVPs: Integrity Verification Procedures의 약자로, 주기적으로 CDIs의 무결성이 올바르게 지켜지고 있는지를 검증한다.
이러한 Clark-Wilson 모델의 예는 은행시스템이 있다. 은행에서 돈과 관련된 모든 데이터는 CDIs에 해당하고 이외의 데이터는 UDIs에 해당한다. TP는 입금, 출금, 계좌이체와 같이 명확히 정해진 절차가 있고 이 절차에 따라 움직이는 것을 의미한다. 그리고 어제 은행이 가지고 있던 돈에서 오늘 들어온 돈을 더하고 나간 돈을 빼는 것과 같이 정기적으로 검증과정을 거치는 것을 IVPs라고 한다. Clark-Wilson 모델은 크게 두 개의 업적을 가진다. 첫 번째는 상용시스템에서 Integrity가 중요할 수 있음을 강조했다는 점이다. 두 번째는 기존 BLP, Biba모델은 사용자가 데이터에 접근한다 생각하였지만 Clark-Wilson은 사용자는 프로그램(TP)에 접근하고 프로그램이 데이터에 접근한다고 하였다.
HRU (Harrison-Ruzo-Ullman) 모델에 대해 서술하시오.
HRU 모델은 BLP 모델의 전제조건이었던 평정속성을 위반했다는 McLean에 비판에 의해 권한이 바뀌어도 보안을 유지할 수 있는 방안을 연구한 모델이다. 동작원리는 권한을 요구하는 요청이 올 경우 임시로 matrix를 변경해보고 state가 잘 유지되는지를 검증한다. 예를 들어 matrix를 바꿨을 때도 기존과 동일하게 SS-property가 충족되는지를 체크하는 것이다. 충족된다면 바꾸고 충족되지 않으면 바꾸지 않는다는 것이 기본 개념이다. 하지만 HRU 모델은 state가 잘 유지되는지를 체크하는 것이 쉽지 않다는 단점이 있다. 따라서 HRU 모델에서는 제약조건을 추가하였다.
Monotonic protection system: destory나 delete 명령이 없는 시스템을 의미한다.
Monocondtional system: 각 명령의 조건 부분에 하나의 조건만 있는 시스템을 의미한다.
Finite number of subjects: subject의 개수가 finite한가?
Chinese Wall 모델에 대해 서술하시오.
Chinese Wall 모델은 HRU 모델이 더 발전된 형태이다. 접근권한이 사전에 세팅되고 요청이 있을 때마다 접근권한이 동적으로 변경되는 특징을 가진다. 또한 Chinese-Wall 모델은 subject의 접근권한이 바로 직전에 한 행동에 의해 다음 접근권한이 결정된다는 특징을 가지고 있다. 예를 들어 변호사가 CITI 은행의 변호를 맡는 순간 KB, NH, SH와 같은 다른 은행에 대한 접근권한이 차단된다. 하지만 S-OIL, GS 칼텍스와 같은 이해상충집단(COI, Conflict Of Interest)이 아닌 클래스의 데이터에는 접근할 수 있다. Brewer와 Nash가 Chinese-wall 모델을 정의할 때도 SS-property와 *-Property를 충족해야 한다고 하였다.
SS-Property: 데이터에 접근하는 동시에 이해상충집단에 해당하는 데이터의 접근하지 못함을 의미한다. 하지만 만약 이해상충되더라도 접근을 계속 유지하고 있거나 완전히 COI Class에 속한다면 접근 가능하다.
*-Property: Information flow에 있어 이해상충집단간의 un-sanitised information이 흐르지 못하도록 하는 것이다. 또한 write access는 이해상충집단에 속해있는 object가 현재 읽혀지지 않고 있거나, 또는 un-sanitised information을 가지고 있을때만 허용된다.
RBAC에 대해 서술하시오
RBAC은 역할기반접근통제정책이다. 기존의 DAC, MAC에서의 접근권한이 사람에게 부여되지만 실제 세상에서의 접근권한은 사람에게 부여되는 것이 아닌 그 사람의 역할에 부여된다는 점에 기반하였다. (그림 그리기) User와 Role사이에 Session이 있고, 이는 동시에 여러 개의 역할을 할당받기 위해 필요한 개념으로, 윈도우에서 창을 여러개 띄워 놓는 것과 같다. RBAC에서 role이 분리되어야할 경우가 2가지가 존재하는데 첫 번째로는 static seperation of Duty로 예를 들어 한 사람이 총무의 역할을 맡으면서 동시에 감사의 역할을 맡을 수 없음을 의미한다. 두 번째로는 dynamic seperation of Duty로 예를 들어 은행 업무를 하고 있는 직원의 역할을 가진 동시에 고객의 역할을 할 수없음을 의미한다.
우리나라의 리스크 관리에 있어 최대 문제점은 무엇인가?
데이터의 중요도에 따른 데이터의 등급화가 되어 있지 않다는 것이 핵심이다. 중국의 경우에도 의료, 금융, 개인정보 등을 Low, Medium, High, Very High와 같이 4단계로 나누나 우리나라의 경우 그렇지 않다. 또한 데이터의 중요도에 따라 데이터의 등급을 나눈 뒤 망분리와 망연계가 명확히 되어야 하지만 잘 이루어지지 않고 있는 것이 실태이다.
Covert Channel은 무엇이고 Side Channel과 어떻게 다르며 이 Covert Channel을 해결하기 위한 방안은 무엇인가?
Covert Channel은 설계자가 의도하지 않았던 방향으로 데이터를 유출하는 채널을 의미한다. Side Channel과의 차이점은 Covert Channel의 경우 송신자와 수신자간의 Covert Channel에 대한 약속이 필요하고, Side Channel의 경우 송신자가 필요하지 않고 수신자 입장에서 별도의 채널을 통해 정보를 추출하는 것이다. Covert Channel은 기본적으로 전부 막을 수는 없으나 이를 해결하기 위한 방안으로 Lattice Based 모델이 있다. Lattice Based 모델은 수학에서 이야기하는 Lattice 구조를 이용하여 정보가 흘러도되는 것과 흐르면 안되는 것을 포멀하게 정의하는 모델이다. Lattice 구조가 성립하는 조건으로는 GLB와 LUB가 있고, 모든 Subset에 대해서 GLB와 LUB가 존재할 경우에 해당한다. 하지만 현업에서 실제로 사용하기에는 복잡하다는 단점이 존재하고 이를 조금 더 적용하기 쉽고, 구현에 용이하게 만든 모델이 Non-Interference 모델이다. Non-Interference 모델은 covert-channel과 Inference attack을 주로 다룬다.
Execution Monitor의 개념과 특징을 서술하시오.
Execution Monitor는 이벤트가 발생할 때 시스템 정책들에 위반되는 사항이 있는지 확인하는 시스템이다. 구체적으로 어떤 함수가 error 상황을 야기하도록 하는 위험한 함수인지 아닌지를 검증하는 것으로, 그 함수 외부로 undesirable exception이 propagate 되지 않는지 또 그 결과에 대한 report가 제대로 되는지를 모니터링 한다.
Execution Monitor는 운영체제 안에서 동작하는 것으로 프로그램을 한 줄 한 줄 실행시켜보며 이벤트가 발생했을 때 EM 시스템이 괜찮은지 검증 후 괜찮다면 실행시키고 문제가 발생하면 빠져나오는 시스템이다. EM을 활용하면 DAC, MAC 정책에서 정책을 위반 여부를 관찰할 수 있는 것이 특징이다. 하지만 Information flow security 같이 정보가 제대로 흐르는지 아닌지는 EM으로 체크할 수 없다. 예를 들어 DDOS 같은 경우는 EM으로 체크할 수 없는데, 이는 EM이 항상 과거의 데이터를 보기 때문에 DDOS와 같이 미래를 보아야 하는 공격은 체크할 수 없는 단점이 있다. 즉 EM으로 모든 보안정책을 제어하기에 한계가 있고 불충분하기에 RM에 다른 요구사항이 추가되어야해서 복잡한 구조를 가지게 된다.
Liveness property와 Safety property에 대해 서술하시오.
Liveness property는 프로그램은 언젠가 종료될 것이지만 언제인지 알 수 없다는 의미를 가지며, Safety property는 나쁜일은 생기지 않는다는 것을 의미한다. Liveness property는 미래를 보아야 하기 때문에 어렵고 safety property는 과거를 보기 때문에 비교적 쉽다. Execution Monitor는 safety property에 속하는 것은 전부 측정할 수 있다. 하지만 EM으로는 모든 보안정책을 제어하기엔 한계가 있고, 불충분하기에 Reference Monitor에 다른 것이 추가되어야 해서 복잡한 구조를 가지게 된다.
Reference Monitor의 세 가지 기본원칙을 설명하시오
Reference Monitor: 감시 프로그램인 Reference Monitor는 운영체제에서 발생하는 모든 이벤트를 감시할 수 있어야 하고 정책에 위반되는 것을 차단해야 한다.
Simplicity & Assurance: RM이 중요하기 떄문에 수학적으로 증명해야 한다. 하지만 RM이 복잡하다면 수학적 증명이 어려워진다. 따라서 RM을 단순하게 만들고 이를 통해 Assurance를 높여야 한다.
Evaluation & Certification: 평가제도를 운영하여 정부가 이를 받아들이도록 해야 한다.
Reference Monitor의 세 가지 요구조건을 더 명확히 표현하여 설명하시오
Complete Mediation: RVM이 있어서 운영체제에서 발생하는 모든 이벤트를 통제할 수 있어야 한다. (Reference Validation Mechanism)
Tamper-Proof: RVM은 해커가 리버싱할 수 없어야 하고 non-bypassible하여 해커가 우회할 수 없어야 한다.
Verifiable: RVM은 충분히 작아서 수학적으로 검증 가능해야 한다.
Trusted Computing Base (TCB)를 설명하시오.
Security Kernel과 다른 보호메커니즘을 결합한 것으로, TCB는 신뢰가 필요한 모든 H/W와 S/W가 포함된다. (Security kernel: Reference Monitor를 실제로 구현해둔 것을 의미한다.)
Authentication vs Identification을 설명하시오.
Authentication은 사용자 인증을 의미하고, Identifiaction은 개인 식별을 의미한다. 예를 들어 네이버에 아이디와 비밀번호로 로그인하는 것은 사용자 인증에 해당하고 범죄현장에서 지문을 발견하여 데이터베이스에서 매칭하여 범인을 알아내는 것은 개인 식별에 해당한다. 내가 나임을 증명한다면 Authentication이고, 타인이 나를 식별한다면 Identification이다.
High Assurance Crypto Library란 무엇인가?
설계부터 구현까지 수학적으로 전부 증명된 것을 의미한다.
Secure Design Principle 12가지를 서술하시오
Least Privilege: 사람 또는 시스템이 필요로 하는 최소한의 권한만 부여하는 것을 의미한다.
Fail-Safe Defult: 명시적 허용이 아니면 거부를 의미한다. 예를 들어 방화벽 룰셋에 설정되어 있지 않다면 패킷을 drop하는 것과 같다.
Economy of mechanism: H/W나 S/W를 만들 때 설계를 심플하고 작게 만들어야 함을 의미한다.
Complete Mediation: 중요 자원에 접근하려는 것을 모두 통제할 수 있어야 함을 의미한다.
Design by Contract: 정해진 인터페이스나 프로토콜로만 중요 자원에 접근할 수 있어야 함을 의미한다.
Open Design: 설계도의 소스코드가 공개되더라도 안전도를 유지할 수 있어야 할 수 있어야 함을 의미한다.
Seperation of Privilege: 중요 권한은 분리되어야 함을 의미한다.
Least Common Mechanism: 공통 모듈 사용 최소화를 의미하는 것으로, Economy of mechanism과 정면으로 위배되는 특징이 있다.
Psychological Acceptability: 심리적으로 사용하기 좋아야함을 의미하는 것으로 Usable security라고도 불린다.
Defense In Dept: 보안 시스템을 둘 때 계층적으로 구성해야함을 의미한다.
Effective Logging: 효율적인 로깅이 가능해야 함을 의미한다. 최근 개인정보보호법으로 인해 무엇을 기록하지 말아야 할지도 고려해야 하는 것이 특징이다.
Built In, Not Bolt on: 시스템을 만들고 나서 보안을 고려하는 것이 아니라 시스템을 만들때 함께 보안을 고려하는 것을 의미한다.
Design Assurance를 쉽게 달성하는 방법은?
Design Assurance를 쉽게 달성하기 위해서는 전제조건을 맞추어 두면 된다. 또한 가정(Assumption)이 많으면 쉽게 달성할 수 있다.
Design Assurance를 입증하는 방법에 대해 서술하시오
크게 2가지로 나뉘며 Symbolic method와 Confidential method로 나뉜다.
Symbolic Method: 수학적 증명을 자동화하는데 사용하는 방법으로, 주로 리플레이 공격을 분석하는데 사용된다. 하지만 confidential method와 달리 복잡한 공격에 대해서는 증명이 어렵다는 단점을 가진다.
Computational Method: 정교한 공격에 대해 수학적 증명이 가능한 방법으로 골드아서와 미칼리가 주로 기여한 분야이다. Symbolic method와 달리 자동화시키기 어렵기 때문에 대부분 manual하게 증명하는 것이 특징이다.
SPN (Substitution-Permutation Network)의 특징을 서술하시오.
주로 대칭키인 AES 암호화에 사용되는 네트워크로, 네트워크 내부적으로 크게 Diffusion과 Confusion이 있다. Diffusion은 확산으로 암호문과 평문사이의 관계를 알아낼 수 없도록 복잡하게 섞어주는 것을 의미한다. 주로 permutation을 통해 데이터의 순서를 바꾸는 방법(P-Box)을 사용한다. Confusion은 혼돈으로 키와 암호문간의 관계를 알아낼 수 없도록 복잡하게 섞는 것을 의미한다. 주로 Substituion을 통해 다른 symbol로 바꾸는 방법(S-box)을 사용한다. 이러한 Diffusion과 Confusion을 극대화하기 위해서는 permutation과 substitution을 반복적으로 하면된다. 이러한 대칭키 암호에서 Design Assurance를 입증하기 위한 전제조건으로는 S-box와 P-box는 안전한 것으로, 특히 S-Box는 랜덤하다는 전제가 필요하다.
RSA 암호의 특징에 대해 설명하시오
디피와 헬만이 공개키 암호를 정의하였고 이러한 정의를 충족하여 만들어진 최초의 공개키 암호가 RSA 암호이다. RSA 암호의 안전성은 소인수분해에 기반한다. 하지만 RSA 암호의 해독방법은 소인수분해 말고도 존재하여 안전성은 증명되지 않았다. 대신 소인수분해 문제를 제외하고 RSA 암호에 대한 공격기법이 개발되면 그에 맞추어 업그레이드 시키는 것이 특징이다.
레빈암호 시스템에 대해 설명하시오
레빈암호시스템은 RSA 암호시스템과 달리 수학적구조가 아름답다. RSA 암호시스템은 기본적으로 안전성은 소인수분해 문제의 어려움에 기반하지만 소인수분해이외에도 암호를 해독할 수 있는 방법이 존재한다. 따라서 RSA 암호를 해독할 수 있는 공격 방법이 만들어질 때 마다 암호시스템을 업그레이드한다. 이와는 달리 레빈암호시스템은 해독가능한 방법이 소인수분해 밖에 없다는 것을 수학적으로 증명되어 있다. 이러한 레빈암호시스템은 Design Assurance를 만족하는 최초의 공개키 암호라는 것에 의의가 있다.
Random Oracle Model이란 무엇인가?
전제조건이 해쉬암호는 안전하다는 것으로, 정확히는 해시암호의 출력은 랜덤함을 전제하는 것을 의미한다. 이를 통해 기존의 theoretical한 암호시스템과 practical한 암호시스템이 결합되기 시작되었다는 점에서 의의가 있는 것이 특징이다.
Perfect Secrecy의 특징을 서술하시오.
Perfect secrecy는 샤논이 만든 개념으로 passive 공격자가 무한한 컴퓨팅 파워가 있더라도 암호문으로부터 어떠한 정보도 얻어낼 수 없는 것을 의미한다. 하지만 이는 대칭키에서는 성립하지만 공개키암호에는 적용할 수 없다는 단점을 가진다. 이는 공개키가 있기 때문에 전수조사로 비밀키를 찾을 수 있기 때문이다.
Semantic Security의 특징을 서술하시오
기존의 샤논이 만든 개념인 perfect secrecy의 단점인 공개키에서는 적용할 수 없다는 단점을 보완하기 위해 골드아서 박사가 정의한 개념으로 "유한한 컴퓨팅 파워를 가진 공격자가 암호시스템으로부터 그 어떠한 1비트의 정보도 알아낼 수 없음"을 의미한다. design assurance의 관점에서 요구사항이 한 단계 진화할 수 있었고 이후에는 이러한 정의를 충족하는 암호 알고리즘이 만들어지게 되었다는점에서 의의가 있다.
공개키암호의 message space가 작으면 발생할 수 있는 문제는 무엇이고 해결방법은 무엇인가?
공개키 암호에서 message space가 작다면 대칭키 암호와 달리 전수조사를 통해 해독이 가능하다는 문제점이 있다. 이를 해결하기 위한 방안으로는 같은 메시지더라도 출력값이 달라지게 하기 위해 랜덤패딩을 붙이는 방법이 있다. 이러한 랜덤패딩을 붙이는 방법이 Polynomial Security(IND-CPA)이다. 즉, 암호알고리즘이 polynomial security를 만족하려면 랜덤패딩이 필요하다.
Polynomial security (IND-CPA)의 특징을 서술하시오.
기존의 공개키암호시스템에서 message space가 작다면 대칭키암호시스템과 달리 전수조사를 통해 알아낼 수 있다는 단점을 보완하기 위해 나온 개념으로, 동일한 평문이 동일한 암호문을 출력하지 않도록 랜덤패딩을 붙이는 방법을 의미한다. 즉, polynomial security를 만족하려면 랜덤패딩이 필요하다. polynomial security는 semantic security와 다르게 표현되었지만 동치라는 특징을 가진다. 즉 암호알고리즘에 랜덤패딩을 추가하면 암호문으로부터 그 어떠한 정보도 노출되지 않는다.
암호문을 위/변조하는 Active Attacker를 막는 설계 방법은 무엇인가?
크게 3가지 방법이 있다. 첫 번째는 전자서명을 사용하는 것이다. 암호문에 전자서명을 붙여서 보내는 방식으로 가능하다. 하지만 공개키 암호문을 설계하는데 전자서명도 사용해야하기 때문에 비효율적인 방법에 해당한다. 두 번째는 Message Authentication Code를 붙이는 방법이 있다. 하지만 이 또한 MAC 알고리즘의 안전성에 대해 증명해야한다는 단점이 있다. 세 번째는 고정된 형태의 패딩을 추가하는 것이다. 하지만 semantic security를 만족하려면 랜덤한 패딩을 추가해야한다. 이러한 문제점을 해결하기 위한 방법이 OAEP이다.
OAEP(IND-CCA)의 특징을 서술하시오.
IND-CCA의 경우 기존의 골드아서와 미칼리의 semantic security가 passive한 공격자로 전제한다는 단점을 보완하기 위해 나온 개념으로 active한 공격자에서도 암호시스템을 안전하게 만들기 위한 방법이다. 이는 고정된 형태의 패딩을 추가하는 방식으로 충족시킬 수 있다. 하지만 semantic security를 만족하기 위해서는 랜덤패딩을 추가하여야 한다. OAEP는 이러한 고정패딩과 랜덤패딩을 함께 추가하는 방법으로 Chosen Cipher Attack에 안전하다는 특징을 가진다.
Non-malleability (NM-CCA)의 특징을 서술하시오.
전통적으로 암호문을 해독하거나 부분정보를 끄집어내는 방법과 달리 암호문을 해독하지 않고 암호문에 변조를 가하는 것을 의미한다. 이를 통해 암호문이 갖추어야 할 requirement가 semantic security와 non-malleability가 되었다. 하지만 후에 이는 다르게 표현되었으나 동치임이 확인되었고 결국 semantic security, polynomial security, non-malleability는 다르게 표현되었지만 하나라는 요구조건임을 확인하였다는 점에서 의의가 있다.
암호에서 Active 공격을 방어하기 위해 사용하는 방법은 무엇인가?
암호에서 active 공격이 많이 발생하기 때문에 암호알고리즘만 사용하지 않고 MAC과 함께 사용되는 경우가 많다. 크게 3가지 방법이 있다.
Encrypt-and-MAC: 메시지에 대해 암호화시키고 그것과 별개로 메시지에 대해 MAC 코드를 만드는 방법이다.
MAC-then-Encrypt: 메시지에 대해 MAC을 만들고 원래 메시지 뒤에 붙인 뒤 전체를 암호화시키는 방법이다.
Encrypt-then-MAC: 메시지를 먼저 암호화시키고 그 암호문에 대해 MAC을 붙이는 방법이다.
여기서 주요 쟁점은 설계방법에 따른 안전도 문제(합성보안 문제)가 제기되는데 통상적으로 Encrypt-then-MAC이 가장 안전하다고 알려져있다.
Compositional Security란 무엇인가?
합성보안문제로 예를 들어 블록체인에서 떠오르는 분야인 DeFi에서도 사용되는 개념이다. DeFi는 머니레고시스템이라고도 부르는데 이는 소스코드가 공개되어 있어 자신들이 만들고자하는 서비스를 만들어 DeFi 시스템에 붙이는게 가능하다. 이 때 공개된 소스코드에 취약점이 있다면 DeFi 전체시스템에 대해 합성보안 문제가 야기된다. 또한 BlackHat 2017에서 발표되었던 WPA2의 사례와 같다. 유닛테스트에서는 안전함이 증명되었지만 통합테스트(합성)에서는 안전하지 않았다.
Zero-knowledge 시스템의 특징을 서술하시오.
암호화 알고리즘과 전자서명은 단방향으로 보내면 되는 1-way 형식이지만 세상에는 interactive하게 동작하는 것이 많다는 점에 착안하여 어떤 client, server, verifier가 interactive하게 동작했을 때 안전하다는 것은 어떻게 입증하는가와 같은 문제가 대두되면서 도입된 개념이다. 영지식 증명의 개념은 3가지 조건을 만족해야 한다.
완전성(Completeness): 어떠한 정보가 참일 경우에 정직한 증명자는 정직한 검증자에게 그것을 납득시킬 수 있어야 한다.
건전성(Soundness): 어떤 정보가 거짓일 경우에 부정직한 증명자는 거짓말을 통해 정직한 검증자에게 그것이 ‘참’임을 납득시킬 수 없어야 한다.
영지식성(Zero-Knowledge): 검증자는 어떤 정보가 참 혹은 거짓이라는 사실 이외에는 아무것도 알 수 없어야 한다.
CC와 EAL7에서 소프트웨어 검증보다 소프트웨어 테스팅에 의존하는가? or Code Assurance의 한계는 무엇인가?
Software Fault, Error, Failure를 설명하고 왜 구분해야 하는지에 대한 이유를 서술하시오.
Software Fault: 소프트웨어 자체가 가지고 있는 결함을 의미하는 것으로 문제가 발생하는 근본 원인이다.
Software Error: 불안정한 프로그램 상태를 의미하는 것으로 어떤 값을 넣어 software의 문제가 있는 Falut까지 도달하면 내부적으로 이상상태가 발생하는 것을 의미한다.
Software Failure: Fault까지 도달하여 내부적으로 불안정한 프로그램 상태가 외부로 표출되는 것을 의미한다.
구분 없이 모두 합쳐서 bug라 부르면 안된다. 명확히 구분해야 test case가 제대로 되었는지 아닌지 구분할 수 있기 때문이다. 만약 모두 합쳐 bug라 부른다면 test case를 설명할 방법이 없어진다.
Software Fault의 종류는 무엇이 있는가?
Random Fault: 사람의 실수에 의해 발생하는 Fault를 의미한다.
Intentional Fault: 의도성을 가지고 발생시킨 Fault를 의미한다.
Software Testing과 Debugging의 차이점을 서술하시오.
Software testing은 소프트웨어를 체크할 수 있는 test value인 input값을 뽑아내는 것을 의미한다. 반면 debugging은 외부로 표출된 failure를 보고 결함이 있는, 문제의 원인이 되는 fault부분을 찾아가는 것을 의미한다.
Static testing과 Dynamic testing의 차이점을 서술하시오
Static testing은 프로그램을 실행시키지 않고 테스팅하는 것을 의미하는 것으로 소스코드, 바이너리, 중간언어가 될 수 있다. 반면 Dynamic testing은 프로그램을 실행시키면서 테스팅하는 것을 의미하는 것으로 체계적인 테스팅을 위해 DART라는 프로그램을 사용하기도 한다.
Black box testing이 먼저인가 White box testing이 먼저인가 그리고 이유를 설명하시오.
black box testing이 먼저이다. 개발공정상 개발단계 전까지 코드가 없기 때문에 white box testing을 할 수 없다. black box testing은 바이너리가 아닌 코드가 없이 테스팅하는 것을 의미한다. 때문에 설계문서와 같은 모든 것들이 black box testing의 대상이 된다. 이후 코드가 완성되면 white box testing까지 하여 정교한 테스팅이 가능해진다.
Validation과 Verification의 차이점을 서술하시오
Validation은 사용자의 마음에 맞도록 만들어졌는가를 의미하는 것으로 Verification보다 어려운 것이 특징이다. 여기에는 사용자의 요구를 전부 분석하여 requirement를 제대로 도출하였는지까지가 들어간다. Verification은 specification이 있고 이를 통해 requirement가 제대로 도출되었다고 전제하고 requirement가 specification대로 만들었는지 검증하는 것으로 validation보다 쉽다는 것이 특징이다.
test case 선정 시 잘 도출하였는지 평가하기 위해 네 요소를 사용하는데 이 네 요소와 특징에 대해 서술하시오.
4가지 요소는 RIPR이다.
Reachability: test input 값이 문제의 근원인 소프트웨어 fault가 있는 지점까지 도달해야 함을 의미한다.
Infection: test input 값이 문제의 근원인 소프트웨어 fault까지 있는 지점까지 도달하여 프로그램 내부 상태가 불완전한 상태(error state)로 만드는 것을 의미한다.
Propagation: 불완전한 상태가(erorr state)가 전이되어 최종적으로 Incorrect한 final state로 가는 것을 의미한다.
Revealability: 프로그램의 Incorrect한 final state가 실제로 외부로 드러나는 것을 의미한다.
Test requirement와 Coverage Criteria의 관계는 무엇인가?
test case → test set → test requirement → coverage criterion → coverage criteria의 단계를 가지는 구조이다. 둘 간의 관계를 예시를 들면 다음과 같다. 예를 들어 젤리의 맛이 6가지와 색이 4가지가 있을 때 Coverage Criteria는 두개가 될 수 있다. 젤리봉투를 뜯었을 때 맛이 6가지가 있어야 한다는 C1의 Criterion과 색이 4가지가 있어야 한다는 C2의 Criterion이다. C1과 C2를 합쳐 Coverage Criteria라고 하며, 이를 통해 test requirement를 도출할 수 있다.
소프트웨어를 모델링하는 대표적인 방법을 서술하시오. (Coverage Criteria를 줄 때 사용하는 방법)
소프트웨어를 모델링하기 위해 사용하는 방법은 크게 4가지로 Input domain, Graph, Logical Expression, Syntax Structure 방식이 있다. 어떤 방법론을 사용하느냐에 따라 coverage criteria는 다른 형태로 주어진다.
Input Domain model based testing: 함수에 들어가는 입력 값만보고 테스트케이스를 만드는 계획을 세우는 방법을 의미한다.
Graph model based testing: 소스코드를 그래프의 형태로 바꾸어 모델링하는 방법으로 소프트웨어 테스팅에 가장 많이 사용되는 기법이다.
Logical Expression model base testing: 조건문만 가지고 test case를 도출하는 모델링 방법으로, predicates라고도 부른다.
Syntax Structure model based testing: 문법 규칙을 주고 문법 규칙에 따라 test case를 생성하는 모델링 방법이다. 그래프만큼 모델링에 많이 사용되며 grammar-based modeling이라고도 한다.
Generator와 Recognizer를 설명하시오.
Generator는 coverage criteria를 주면 알아서 test case를 만들어주는 것을 의미하며, Recognizer는 test case가 주어지면 어느 coverage까지 달성하는지를 분석해주는 것이다.
Graph model based testing의 특징을 서술하시오.
소스코드를 그래프의 형태로 바꾸어 모델링하는 방법으로 소프트웨어 테스팅에서 가장 많이 사용되는 기법이다. 크게 2가지 기법으로 Structural coverage criteria와 Data flow coverage criteria로 분류 된다. (분류 특징 서술하기). 그래프 모델링 기법은 소스코드에 사용하는 것이 주로 일반적이나 설계단계의 문서와 더불어 제품을 개발하는 여러 단계에 테스팅하는데 활용할 수 있다. 그래프 모델링에서 test case 도출을 어렵게하는 요소로는 루프가 있다. 기존에는 루프를 만나면 사이클을 한 번만 돈다고 가정하였으나 이는 abstraction gap이 크다는 단점이 존재한다. 따라서 이를 해결하기 위한 방안으로 touring, sidetrips, detours라는 prime path 를 사용하여 abstraction gap을 줄이려는 노력을 하고 있다.
Call-Graph를 설명 하시오
Control Flow Graph, Data Flow Graph 이외에 Call Graph가 있는데 이는 어떤 모듈이 어떤 모듈을 부르는가에 대한 호출 관계를 표시하는 그래프이다. 모듈을 어떻게 분배시킬까에 대한 sub-system level에서 사용되며, 결과적으로 design integration test에 활용한다. (좀더 포멀하게 바꿀 수 있으면 좋겠습니다.)
Logical Expression Model based testing에 대해 서술하시오.
조건문만 가지고 test case를 도출해내는 모델링 방법으로 이를 predicates라고도 한다. logic expression은 소스코드에서 발견되는 predicates와 clause에 따라 이를 테스트할 수 있는 test case를 도출하는 것이 특징이다. clause에는 major clause와 minor clause가 있다. major clause는 predicates를 결정짓는 핵심이되는 것을 의미하며, minor clause는 그 이외의 것을 의미한다. 효율적인 test case 도출을 위해서는 major clause를 도출해내는 것이 중요하다. 하지만 logical expression 모델링 방법은 프로그램을 실행시키전까지는 파악하기 어렵다는 단점을 가진다. 예를 들어 어떤 값에 n을 나누거나 y를 나눌 때 어떤 값이 나올지 알기 어려운 것과 같다.
Syntax Structure Based Testing에 대해 서술하시오.
문법 규칙에 따라 test case를 생성하는 모델링 방법이다. Graph-based 모델링 방법만큼 많이 사용되며 Grammar-based modeling이라고도 한다. grmmar가 구성되면 두 가지 목적으로 사용가능하다. 첫 번째는 grammar에 맞춰 여러 test case를 생성할 수 있고, 두 번째로는 어떤 값이 grammar를 충족하는지에 대한 여부를 확인할 수 있다.
Structural Coverage Criteria과 Data Flow Coverage Criteria의 특징을 서술하시오.
Control Flow는 structural coverage criteria와 연계되고 Data Flow는 data flow coverage criteria로 연계된다. structural coverage criteria는 노드와 엣지로 그래프를 정의하고 분기(e.g. if)를 통해 프로그램이 실행되는 코드가 달라지는 것을 기준으로 하는 방법이다. 대표적으로 node coverage, edge coverage, edge-pair coverage, complete path coverage, specified path coverage 등이 있다. data flow coverage criteria는 프로그램이 어떻게 변수가 정의되고 사용되는지를 기반하여 커버리지 기준을 적용하는 방법을 의미한다. 즉, 데이터 흐름 그래프상에서 각 변수의 def-use-pair가 다양한 방식으로 실행되도록 하는 기준이다. 대표적으로 all-defs coverage, all-uses coverage, all-du-paths coverage이 있다.
mutant에 대해 설명하시오
mutant는 원본 프로그램이 있고 일부를 바꾸었을 때를 의미한다. mutant는 크게 valid mutant와 Invalid mutant로 나뉜다. valid mutant는 시드값을 바꾸었을 때 그래머를 만족하는 mutant를 의미하며, Invalid mutant는 시드값을 바꾸었을 때 그래머를 만족하지 않는 mutant를 의미한다. 주로 mutation testing에 사용 된다.
mutation testing을 설명하시오.
grammar(subject)로부터 ground string(seed) 값을 뽑아낸다. 이후 ground string(seed)에서 일부를 바꾸면 mutant가 생성된다. 이 때 test case를 generate하여 ground string와 mutant에 각각 넣고 같은지를 비교하며 이를 mutation testing이라 한다. 쉽게 말해 원본 프로그램은 run tests on subject에 들어가고 변형된 프로그램은 run tests on mutant에 들어간다. 이후 test case를 생성하여 각각의 프로그램에 넣었을 때 원본 프로그램과 변형된 프로그램을 구분할 수 있으면 이를 mutant를 죽였다 표현하고 이를 mutation testing이라 한다.
program-based mutation testing에 대해 서술하시오.
test case가 제대로 만들어졌는지 test할 때 주로 사용되는 testing 기법이다. coverage 개념과는 다르며, 얼마나 많은 mutant를 제거하였는지가 핵심이다. 즉, grammar를 따르지 않은 mutant와 grammar를 제대로 따른 원본을 test case가 구별해낼 수 있는 가이다.
여러 소프트웨어 테스팅 기법 중 grammar-based mutation testing이 가지는 특징은 무엇인가?
Input domain, graph, logical expression 등의 테스팅 기법과 달리 grammar-based mutation testing은 test case를 test 할 수 있다는 것이 가장 큰 특징이다. 또한 기본적인 grmmar를 정해두고 조금씩 변형해가며 input을 넣어보는 퍼징에도 효과적으로 사용할 수 있다.
Software verification의 특징을 서술하시오
software testing의 한계인 실제로 버그가 없음을 입증하기 위해 모든 가능한 인풋값에 대해 전부 테스트해보아야 한다는 것을 보완하기 위해 나온 것으로, software가 requirement를 충족하는지 충족하지 않는지를 수학적으로 증명하는 방법이다. 하지만 문제점은 어떤 software가 requirement를 충족하는지 하지 않는지를 증명하는 것은 undecidable problem에 속하기 때문에 이론적으로 software verification이 불가능하다고 입증되었다. 하지만 현실에서 마주하는 것은 모든 software가 아닌 특정 타입의 software이기 때문에 범위를 줄이게 되면 불가능하지 않다. software verification에서 사용되는 요소 기술의 종류는 symbolic execution, automatic theorem prover, model checker 등이 있다.
Concrete Execution이란 무엇인가?
프로그램을 실행시키면서 변수 값이 어떻게 변형되어 가는지 확인하며 프로그램이 제대로 동작하는지 하지 않는지를 검증하는 것이다.
Symbolic Execution에 대해 서술하시오.
기호실행은 프로그램에 구체적인 값을 넣지 않고 모든 것을 기호로 바꾸어 전개시키고, 실제 테스팅하고자 하는 영역의 방정식을 충족하는 값을 구하는 방식이다. 전개된 상태에서 방정식만 풀면 어떤 경로를 테스트할지 test case를 자동으로 뽑아낼 수 있다. 즉 testing input generation이 가능하여 어떤 경로로 갈지 바로 뽑아낼 수 있다는 것이 장점이다. 반대로 path explosion 때문에 적용이 쉽지 않은 것이 단점인데 이는 구체적인 값이 아니라 기호를 넣으면 길이가 긴 경로가 나올 수 있기 때문이다. 이에 대한 대안으로는 pre-conditioned symbolic execution으로, 이는 프로그래밍할 때 BOF와 같이 에러가 많이 발생할 수 있는 조건에 사용할 수 있다. 보안관점에서는 buggy path만 체크하면 경우의 수가 줄어 Exploitable한 path에 대해 symbolic execution하여 효과적인 test case 도출이 가능하다.
Automatic Theorem Prover에 대해 서술하시오.
software verification에서 자주 사용되는 요소 기술 중 하나이다. 프로그램을 정형명세로 바꾸어 표현하는 것이 특징이다. 구성요소는 3가지로 variable, precondition, postcondition이 있다. 만약 a와 b를 더한 결과인 result를 출력해주는 프로그램이 있다 가정할 경우 a,b,result는 variable에 해당하고 이에 할당된 초기값은 precondition에 해당한다. 마지막으로 a, b, result에 대한 관계는 postcondition에 해당한다. 프로그램이 전부 수행되었을 때 Automatic Theorem Prover가 자동으로 정형명세를 충족하였는지 검증하며, 이를 Floyd-Hoare Triple이라고도 한다.
Floyd-Hoare Triple에 대해 서술하시오.
Variable, Precondition, Postcondition으로 구성되는 것으로, Precondition {P}가 주어졌을 때 논리적 흐름에 따라 전개되면 반드시 Postcondition {Q}에 도달한다. 따라서 프로그램에 Precondition과 Postcondition을 정형명세로 바꾸어 중간 중간 끊어서 주게되면 실제 프로그램이 제대로된 논리 흐름을 따르는지 검증할 수 있는 것이 특징이다. 이러한 Precondition과 Postcondition을 정형명세로 표현하면 Theorem Prover가 정형명세를 지키고 있는지를 검증한다.
(Automatic) Theorem Prover와 Model Checker의 차이를 서술하시오.
Model Checker는 기본적으로 automatic theorem prover에서 확장된 개념이다. 둘간의 차이점은 크게 자동화 여부, 적용 범위, requirement 개수로 3가지다. 자동화여부: theorem prover의 경우 프로그램 중간중간에 precondition과 postcondition을 정형명세로 다 입력해주어야 하는 반자동이다. 반면 model checker는 프로그램을 모델로 바꾸고 모델이 도달해야할 요구사항을 준 뒤 충족했는지의 여부를 yes or no로 출력 가능한 것으로 완전 자동에 해당한다. 적용범위: theorem prover의 경우 반자동이기에 적용 범위가 넓어 많은 프로그램에 적용할 수 있다 반면 model checker는 적용할 수 있는 프로그램이 theorem prover 보다는 적다는 단점을 가진다. requirement 개수: theorem prover는 반자동인 대신 체크할 수 있는 (security) requirement개수가 많고, model checker는 완전자동이지만 적용할 수 있는 (security) requirement 개수가 적다.
Model Chcker에 대해 서술하시오.
모델 체커는 프로그램을 모델링하여 모델체커에 넣고 도달해야할 requirement를 주어 도달여부를 검증하는 것으로, 관점을 조금 바꾸면 exploit을 자동 생성하는 도구를 만들어 counter example을 뽑을 수 있는게 특징이다. 아래와 같이 아키텍처가 구성된다(그림 그리기). 이를 활용하여 cyber grand challenge에서 취약점 탐지 자동화 도구가 나왔었다. 하지만 이는 모든 가능한 exploit 코드를 만들어지는 것은 아닌데 이는 취약 가능성이 높은 buggy path만 보기 때문이다.
부분 적분은 미적분학에서 두 함수의 곱을 적분하는 기법이다.치환 적분은 미적분학에서 기존 변수를 새로운 변수로 바꾸어 적분하는 기법이다. 부분 적분은 변수가 바뀌지 않으므로 적분 구간이 바뀌지 않지만, 치환 적분은 변수가 바뀌므로 적분 구간이 바뀐다. 부분 적분은 치환 적분이 적용되지 않을 때 사용한다.
부분적분
부분적분에서는 두 함수를 $f(x)$와 $g(x)$로 두고 적분을 진행한다. 이 때 $f(x)$와 $g(x)$로 두는 함수의 기준이 존재한다. 그 기준은 미분의 용이성과 적분의 용이성이다. 일명 로다삼지로 알려져 있는데 로그함수, 다항함수, 삼각함수, 지수함수를 뜻한다. 만약 로그함수에 가깝다면 미분이 쉬우므로 $f(x)$로, 지수함수에 가깝다면 적분이 쉬우므로 $g(x)$로 두어야 한다. 이는 추후 계산의 용이성을 위함이다. 두 함수를 두는 방법의 예로, 로그함수와 삼각함수가 곱해진 경우라면 로그함수는 $f(x)$로 삼각함수는 $g(x)$로 둔다. 또 다항함수와 지수함수가 곱해진 경우라면 다항함수를 $f(x)$로 지수함수를 $g(x)$로 둔다. 로다삼지의 예시로 로그함수는 $logx$, $\ln x$를 말하고, 다항함수는 $n$차 다항식/일차함수/이차함수를 말한다. 또 삼각함수는 $sin$, $cos$, $tan$, $secx$, $cscx$, $cotx$를 말하고, 지수함수는 $n^x$, $e^x$를 말한다. (참고로 지수함수를 부정적분하는 공식은 $\int e^{f(x)}dx = {e^{f(x)} \over f'(x)} + C$다.)
그렇다면 부분적분의 공식은 무엇이고 어떻게 유도될까? 부분적분의 공식은 다음과 같다.
$\int f(x)g'(x)dx = f(x)g(x) - \int f'(x)g(x)dx$
이를 유도하는 과정은 매우 간단하다. 부분적분은 미분가능한 두 함수 $f(x)$, $g(x)$가 있을 때 두 함수의 곱인 $f(x)g(x)$를 미분한다. 미분한 결과는 $\{f(x)g(x)\}' = f'(x)g(x) + f(x)g'(x)$이다. 이 상태에서 다시 적분하면 $f(x)g(x)$가 되어야 할 것이다. 따라서 양변을 x에 대해 적분하면 $f(x)g(x) = \int f'(x)g(x)dx + \int f(x)g'(x)dx$가 된다. 이 때$\int f'(x)g(x)dx$를 이항하게 되면 위 공식이 된다.
그렇다면 3개의 예시를 통해 실제로 부분적분을 적용해보자. 만약 $\int xe^xdx$라면 미분이 쉬운 다항식인 $x$를 $f(x)$로, 적분이 쉬운 지수함수인 $e^x$를 $g'(x)$로 둔다. 부분적분 공식에 의해 $\int xe^xdx = xe^x - \int 1\times e^xdx$가 되므로 결과적으로 $xe^x-e^x+C$가 된다. $e^x$를 적분하면 $e^x$가 되므로. (+미분해도 $e^x$)
두 번째로 $\int \ln xdx$라면 $f(x)$를 $\ln x$로 $g'(x)$를 1로 둔다. 부분적분 공식에 의해 $\int \ln xdx = x\ln x - \int {1\over x}xdx$이다. 따라서 $\int \ln x = x\ln x - \int dx$가 되므로 결과는 $\int \ln x = x\ln x - x + C$가 된다.
세 번째로 $\int x\sin 2xdx$라면 $f(x)=x$로, $g'(x)=\sin 2x$로 둔다. 부분적분 공식에 의해 $\int x\sin 2xdx = x\times -{1\over 2}cos2x - \int 1\times -1{1\over 2}cos2xdx$가 되고 추가 계산하면 결과적으로 $\int x\sin 2xdx = -{1\over 2}xcos2x + {1\over}4\sin 2x + C$가 된다.
이러한 부분적분을 매우 쉽게할 수 있는 경우가 있다. 만약 계속 미분하면 0이되는 함수와 계속 적분할 수 있는 함수와의 곱이라면 가능하다. 아래 그림의 두 예시와 같은 과정으로 이뤄진다. 참고로 +와 -는 차례대로 번갈아가며 적용한다. 또 아래의 $g(x)$는 위의 $g'(x)$와 같다.
치환 적분
치환 적분은 복잡한 함성함수를 적분할 때 사용하는 방법으로 $ g(x) = t$ (이 때 g(x)는 미분가능 함수)와 같이 적분 변수($x$)를 다른 변수($t$)로 바꾸어 적분하는 방법이다. 예를 들어 $\int \cos(2x+1)dx$와 같은 함수를 적분해야 하는 상황에서 $2x+1 = t$와 같이 치환하여 단순화 시키는 것이다. 먼저 결론을 말하자면 치환 적분의 공식은 다음과 같다.
$\int f(x)dx = \int f(g(t))g'(t)dt$
그렇다면 이 치환 적분의 공식은 어떻게 유도될까? 간단하다. 먼저 $dy \over dx$는 $x$에 대한 $y$의 변화량이다. 하지만 이는 ${dy \over dx} = {dy \over dt} {dt \over dx}$로도 표현할 수 있다. 이후 $\int f(x)dx$라는 식이 있을 때 $x = g(t)$로 둔다. 이때 $x$를 미분하면 ${dx\over dt} = g'(t)$가 된다. 이를 기존의 식에 대입하면 $\int f(g(t))g'(t)dt$가 된다. 즉 $x$에 대한 적분을 $t$에 대한 적분으로 치환한 것이다.
이 치환 적분 공식을 2개의 예시에 적용해보자. 첫 번째로 $\int \cos (2x+1)dx$의 부정적분을 구해보자. 먼저 $2x+1 = t$로 둔다. 이후 양변을 $x$에 대해 미분하면 ${dt\over dx}=2$이므로, $dx={1\over 2}dt$가 된다. 따라서 이를 적분하고자 했던 식에 대입하면 $\int \cos t \times {1\over 2}dt$이 된다. 이제 이를 적분하면 ${1\over2} \sin t + C$의 형태가 되며 t에 대환 치환을 다시 $x$로 돌려주면 결과적으로 ${1\over 2}\sin (2x+1) +C$로 적분 계산 값이 도출된다.
두 번째 예시는 $\int x{\sqrt{x+1}}dx$이다. 마찬가지로 $x+1 = t$로 치환한다. $x$에 대해 미분하면 ${dt\over dx} = 1$이므로 $dt = dx$가 된다. 따라서 이를 대입해주면 $\int (t-1)\sqrt{t}dt$가 되고, 조금 난잡해보일 수 있지만 루트 표현식을 분수 표현식으로 바꾸면 $\int (t{3\over 2}-t{1\over 2})dt$가 된다. 이제 적분할 수 있다. 계산하면 ${2\over 5} t^2\sqrt{t} - {2\over 3}t\sqrt{t} +C$가 된다. $t$로 치환된 값을 다시 $x$로 풀어주면 결과적으로 ${2\over 5}(x+1)^2 \sqrt{x+1} - {2\over 3}(x+1)\sqrt{x+1} + C$로 적분 계산 값이 도출된다.
통계에서 확률변수와 확률분포가 있다. 확률변수는 이산확률변수와 연속확률변수로 나뉘고, 마찬가지로 확률분포도 이산확률분포와 연속확률분포로 나뉜다. 이산의 대표적인 분포는 이항분포가 있고 연속의 대표적인 분포는 정규분포가 있다. 하지만 이외에도 베르누이 분포, 기하분포, 초기하분포, 포아송분포, 균등분포, 지수분포, 카이제곱 분포 등이 있고 총 12가지 분포에 대해 정리하고자 한다. 이러한 확률 분포들이 필요한 핵심 이유는 모수 추정에 있다. 모수 추정에 있어 어떤 확률 분포를 따른다고 가정하면 특정 상황을 잘 표현할 수 있기 때문이다.
간단 용어 정리
표본공간: 사건에서 발생 가능한 모든 결과의 집합
확률변수: 표본공간에서 일정 확률을 갖고 발생하는 사건에 수치를 일대일 대응시키는 함수
확률분포: 흩어진 확률변수를 모아 함수 형태로 만든 것
이산확률변수: 확률변수 개수가 유한해 정수 구간으로 표현되는 확률변수
연속확률변수: 확률변수 개수가 무한해 실수 구간으로 표현되는 확률변수
확률밀도함수: 확률변수의 분포를 나타내는 함수이자 확률변수의 크기를 나타내는 값
이산 확률 분포
1. 베르누이 분포 (Bernoulli distribution)
베르누이 분포는 시행의 결과가 오직 두 가지인 분포를 말한다. 예를 들어 성공/실패나 합격/불합격 또는 앞면/뒷면이 있다. 이를 일반화하면 베르누이 분포는 특정 사건 A가 나타날 확률과 A가 나타나지 않을 확률을 나타낸 분포이다. 일반적으로 확률 변수에 사건 A가 발생할 경우를 1, 발생하지 않을 경우를 0으로 부여한다. 즉 베르누이 분포는 확률변수가 1과 0 두 가지로만 나타내는 확률분포다.
베르누이 시행을 따르는 경우의 예시로는, 동전과 주사위가 있다. 동전이 앞면이 나올 경우와 나오지 않을 경우로 나눌 수 있고, 주사위에서 어떤 수가 나올 확률과 그렇지 않은 경우로 나눌 수 있다. 만약 주사위에서 5가 나올 확률과 그렇지 않은 확률을 구하는 경우라면 베르누이 시행이지만 5,6이 나올 확률과 그렇지 않은 경우를 구하는 것이라면 베르누이 시행이 아니다. 예시를 통해 계산 방법을 알아보자. 상자 안에 흰 공7개와 검은공 3개가 있다고 가정하고 확률변수를 흰공이 나오면 성공(1), 검은공이 나오면 실패(0)로 둘때, 확률변수 값은 $p(1)=0.7, p(0)=0.3$이 된다. 이를 $\displaystyle p(x) = 0.7^x \times 0.3^{1-x}$로 나타낼 수 있고, 이를 일반화 한 식은 다음과 같다.
$\displaystyle p(x) = p^x(1-p)^{1-x}$
이 때 $x=(0, 1)$
다음으로 베르누이 분포에서 평균과 분산을 구하는 과정은 다음과 같다.
$\displaystyle E(x) = \sum xp(x)$
$= 0p(0) + 1p(1)$
$= p(1)$
$= p$
$\displaystyle V(x) = E(x^2) - \{E(x)\}^2$
$\displaystyle = \sum x^2p(x) - p^2$
$= 0p(0) + 1p(1) - p^2$
$= p - p^2$
$= p(1-p)$
$\therefore$ $E(x) = p$, $V(x) = p(1-p)$이다.
2. 이항분포 (Binomial distribution)
이항 분포는 베르누이 시행을 여러번 하는 것이다. 정의를 내리면, 어떤 사건 A가 발생할 확률이 $p$인 베르누이 시행을 $n$번 시행했을 때 사건 A가 발생한 횟수를 확률 변수로하는 분포다. 수식으로는 다음과 같이 나타낸다.
만약 주사위 10번 던져서 숫자 5가 한 번 나올 확률: ${}_{10}C{}_1\times({1\over6})^1\times ({5\over 6})^9$
만약 주사위 10번 던져서 숫자 5가 두 번 나올 확률: ${}_{10}C{}_2\times({1\over6})^2\times ({5\over 6})^8$
만약 주사위 10번 던져서 숫자 5가 세 번 나올 확률: ${}_{10}C{}_3\times({1\over6})^3\times ({5\over 6})^7$
만약 주사위 10번 던져서 숫자 5가 r 번 나올 확률: ${}_{10}C{}_r\times({1\over6})^r\times ({5\over 6})^{n-r}$
이러한 사건의 시행으로부터 나오는 확률을 구해 분포도를 그리면 이항분포가 된다. 정확히는 확률변수 X의 확률분포를 이항분포라고 한다. 기호로는 $\displaystyle B(n, p)$와 같이 나타내며 위의 예시로는 $\displaystyle B(10, {1\over6})$이 된다. 만약 $X \sim B(n, p)$일 때 이항분포의 평균과 분산은 각각 $\displaystyle E(x) = np$ 이며 $\displaystyle V(x) = np(1-p)$이다. 평균을 구하는 과정만 기술해보자면,
$\displaystyle = np\sum_{x=0}^m {m! \over x!(m-x)!}p^x (1-p)^{m-x}$ (이 때 $np$ 뒤의 형태는 시행횟수 m, 확률 p를 가지는 이항분포이므로 합은 1이 되어 사라지고)
$= np$
$\therefore E(x) = np$
3. 기하분포 (Geometric distribution)
기하분포는 베르누이 시행을 반복할 때 처음으로 알고자 하는 사건 A 관찰에 성공하기 까지의 시도 횟수를 확률변수로 가지는 분포이다. 예를 들어 연애에서 결혼까지 이어질 확률이 10%라면 $x$번째 연애에 결혼하게 되는 것을 $p(x)$라 할 수 있다. 만약 3번째 연애에 결혼한다 가정하면 다음과 같은 계산이 가능하다.
$p(1) = 0.1$
$p(2) = 0.9 \times 0.1$
$p(3) = 0.9 \times 0.9 \times 0.1$
이를 일반화 하면 $\displaystyle p(x) = (1-p)^{x-1} \times p$이 된다. ($x$번째에 성공하므로 $x-1$까지는 실패)
이 기하분포의 통계량 중 평균과 분산은 $X \sim Geo(p)$일 때 $\displaystyle E(x) = {1\over p}, V(x) = {1-p\over p^2}$이다. 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(x) = \sum xp(x) = \sum x(1-p)^{x-1}p = \lim_{n \to \infty} \sum_{x=1}^n x(1-p)^{x-1}p$ (n이 무한히 커질 수 있음. p를 앞으로 꺼내주고 식을 전개하면)
음이항 분포의 여러 정의 중 하나는 기하 분포를 일반화한 분포다. 정확히는 음이항분포에는 5가지 정의가 존재하고 그 중 하나의 정의가 기하 분포의 일반화에 해당한다. 앞서 기하분포를 설명한 대로, $n$번째 시행에서 처음으로 사건 A 관측에 성공할 확률이다. 수식으론 $\displaystyle p(x) = (1-p)^{x-1} \times p$으로 표현했다. 음이항분포의 한 정의는 $n$번째 시행에서 $k$번째 성공이 나올 확률이다. 즉 $n$번 시행 이전인 $n-1$번의 시행까지 $k-1$개의 성공이 있어야 하며, 마지막 n번째에 한 번 더 성공해야 한다. 이를 수식으로 정의하면 $n-1$에서 $k-1$개가 나올 경우의 수를 고려해야 하므로 $\displaystyle p(x) = {}_{n-1}C_{k-1}p^{k-1}(1-p)^{n-k}p$가 된다.
앞서 언급했듯 음이항분포는 5가지 정의가 존재한다. 이 5가지 정의엔 $n, k, r$이 사용된다. $n$: 전체 시행횟수, $k$: 성공 횟수, $r$: 실패 횟수이다. 이 때 $n = k + r$의 관계가 성립한다. 이 관계식에서 어떤 것을 독립 변수, 종속변수, 상수로 두느냐에 따라 음이항분포의 정의가 나뉜다.
5. $n$이 상수, $k$ 또는 $r$이 독립변수인 경우: $n$번 시행에서 $k$번 성공 또는 $r$번 실패할 확률 (= 기존 이항분포와 동일한 식)
혼동이 있을 수 있지만 결론을 먼저 말하자면 일반적으로 1번 정의를 음이항분포라고 한다. 4번 정의는 기하분포를 일반화한 것이다. 1번 정의에 대한 예시를 들기 포커 게임에서 이길 확률(p) 0.3일 때 5번의 패배가 나오기까지 발생한 승리가 $k$번일 확률 분포 $p(x)$를 구한다고 해보자. 그러면 $r=5, p=0.3$이며 $x=(0, 1, 2, 3, 4, 5)$가 된다.
p(0): 5번 패배할 때까지 0번 이긴 경우다.
(_ _ _ _ 실): 마지막 실패 제외,모두 실패가 들어간다. 4번 중 4번 패배 + 0번 이길 경우의 수 이므로 ${}_4C_0 (0.7)^4 (0.3)^0 (0.7)$
p(1): 5번 패배할 때까지 1번 이긴 경우다.
(_ _ _ _ _ 실): 마지막 실패 제외, 5번 중 4번 패패 + 1번 이길 경우의 수 이므로 ${}_5C_1 (0.7)^4 (0.3)^1 (0.7)$
p(2): 5번 패배할 때 까지 2번 이긴 경우다.
(_ _ _ _ _ _ 실): 마지막 실패 제외, 6번 중 4번 패배 + 2번 이길 경우의 수이므로 ${}_6C_2 (0.7)^4 (0.3)^2 (0.7)$
p(3): 5번 패배할 때 까지 3번 이긴 경우다.
(_ _ _ _ _ _ _ 실): 마지막 실패 제외, 7번 중 4번 패패 + 3번 이길 경우의 수므로 ${}_7C_3 (0.7)^4 (0.3)^3 (0.7)$
. . . ($k \rightarrow \infty$)
이를 일반화한 수식은 ${}_{x+k-1}C_{x} (1-p)^r p^x$이 된다. 이를 달리 표현하면 $X \sim NB(r, p)$이다. 다른 정의를 사용하고 싶다면 $r$ 자리에 다른 상수를 넣어 사용할 수 있다. 이런 음이항분포의 평균과 분산은 각각 $\displaystyle E(x) = {pr \over 1-p}$와 $\displaystyle V(x) = {pr \over (1-p)^2}$이다. 이 중 평균을 구하는 과정만 기술하자면,
$\displaystyle = {pr \over 1-p} \sum_{y=0}^\infty {}_{y+k-1}C_y p^y (1-p)^k$ (이 때 시그마 안의 식은 음이항분포의 확률분포 함수와 모양이 같으므로 합은 1이 된다.)
$\displaystyle = {pr \over 1-p}$
$\displaystyle \therefore E(x) = {pr \over 1-p}$
어떤 확률변수 $X$가 $NB(r, p)$의 음이항분포를 따를 때 이 확률변수 $X$의 평균은 $\displaystyle {pr \over 1-p}$가 된다.
5. 초기하 분포 (Hypergeometric distribution)
초기하 분포는 아래 그림처럼 크기가 $m$인 모집단에서 크기 $n$인 표본을 추출했을 때 모집단 내 원하는 원소 $k$개 중 표본 내에 $x$개 들어있을 확률 분포를 의미한다.
쉬운 비유는 로또가 있다. 로또는 크기 45의 모집단을 가지고, 그 중 원하는 수 $k=6$개이다. 이 때 추출한 표본 6개 중 $k$가 $x$개 들어있을 확률이다. 따라서 $p(0)$는 번호 0개 맞은 경우이며 $p(1)$은 번호 1개가 맞은 경우이고, ..., $p(6)$는 번호 6개가 맞아 1등된 확률을 의미한다.
이러한 초기하 분포식 유도를 위해선 먼저 모집단에서 표본을 추출할 경우의 수를 구해야 한다. 이는 크기 $m$인 모집단에서 크기 $n$인 표본을 뽑을 경우의 수 이므로 ${}_mC_n$이다. 또 원하는 원소가 $k$개 들어있고 크기가 m인 모집단에서, 크기가 $n$인 표본을 뽑을 때 원하는 원소 x개가 들어있을 경우의 수는 ${}_kC_x \times {}_{m-k}C_{n-x}$다. 그 이유는 표본의 $x$이외의 값은 $n-x$개로 나타내며 이는 모집단의 $m-k$개로부터 추출된 것이기 때문이다. 이를 기반으로 전체 경우의수를 나타내면 다음과 같다.
여기서 $m, k, n$은 사전에 결정되는 상수이며 $x$는 확률 변수에 해당한다. 이 초기하 분포식을 기반으로 구한 평균과 분산은 각각 $\displaystyle E(x) = {kn \over m}$, $\displaystyle V(x) = n {k\over m}{m-k \over m}{m-n\over m-1}$이다. 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(x) = \sum xp(x)$
$\displaystyle = \sum_{x=0}^\infty {{}_kCx \times {}_{m-k}C_{n-x} \over {}_mCn}$ (이 때 ${}_kCx$를 팩토리얼로 풀어주면)
$\displaystyle = \sum_{x=0}^\infty x{k! \over x!(k-x)!} {{}_{m-k}C_{n-x} \over {}_mC_n}$ (이 때 0을 대입하면 0이므로 x=1부터 시작되어도 무관. x 약분 하고 k를 밖으로 꺼내주면)
$\displaystyle = {kn\over m} \sum_{y=0}^\infty {}_{k-1}C_y {{}_{(m-1)-(k-1)}C_{(n-1)-(y)} \over {}_{m-1}C_{n-1}}$ (시그마 내 식은 크기 $m-1$인 모집단, $n-1$인 표본, 원하는 원소 $k-1$개, 원하는 원소 $y$인 초기하 분포의 모양과 같으므로 시그마 식은 초기하 분포 값을 다 더해주면 1)
$\displaystyle = {kn\over m}$
$\displaystyle \therefore E(x) = {kn \over m}$
6. 포아송 분포 (Poisson distribution)
포아송 분포는 이항 분포에서 유도된 특수한 분포다. 이항 분포에서 시행 횟수 $n$이 무수히 커지고 사건 발생 확률 $p$이 매우 작아질 경우 필요하다. 그 이유는 시행 횟수 $n$이 무한히 커질 때 이항 분포 정의인 $\displaystyle {}_nC_r\ p^r(1-p)^{n-r}$에서 $n!$ 계산이 현실적으로 가능하지 않은 경우가 있기 때문이다.
포아송 분포를 다르게 표현하면 단위 시간이나 단위 공간에서 랜덤하게 발생하는 사건 발생횟수에 적용되는 분포다. 예를 들어 1시간 내에 특정 진도 5이상의 지진 발생 확률에도 적용할 수 있다. 지진은 언제나 발생할 수 있지만 그 발생횟수는 작을 것이며 또 알 수 없다. 또 보험사는 1000건의 보험계약이 있지만 고객이 보험금을 청구 확률은 얼마가 될 지 알 수 없는 것이다.
이러한 경우에 포아송 분포가 사용되며 많은 경우에 적용된다. 포아송 분포에서는 사건발생 횟수와 확률은 알 수 없지만 대신 사건발생 평균횟수는 정의할 수 있다. 그 이유는 이항 분포에서 평균 $E(x) = np$이기 때문이다. 푸아송 분포에서는 $np$를 $\lambda$로 표현한다. ($\lambda = np$)
포아송 분포의 정의는 이항 분포 정의에서 유도되어 $\displaystyle p(x) = {\lambda^x e^{-\lambda} \over x!}$이다. 이를 사용해 포아송 분포의 평균과 분산을 구하면 각각 $E(x) = \lambda$와 $V(x) = \lambda$이다. 이 때 평균을 구하는 과정만 기술해보자면,
$\displaystyle =\lambda e^{-\lambda} \sum_{n=0}^\infty {\lambda^{n} \over n!}$ (이 때 시그마 값은 매클로린 급수 정의에 의해 $e^\lambda$.($\displaystyle f(x) = \sum_{n=0}^\infty {f^{(n)}(0) \over n!} {x}^n$에서 $e^\lambda$대입. $e^x$의 $n$계 도함수는 자기 자신))
$\displaystyle = \lambda e^{-\lambda} e^\lambda$
$\displaystyle = \lambda$
$\displaystyle \therefore E(x) = \lambda$
연속확률분포
7. 균등분포 (Uniform distribution)
균등분포의 정의는 정해진 범위에서 모든 확률변수의 함수값이 동일한 분포이다.연속확률분포에서 균등분포는 연속균등분포라 불려야 한다. 이산확률분포에서도 균등분포를 정의할 수 있기 때문에 구분이 필요하기 때문이다. 균등분포 함수로 표현하면 다음과 같다.
$\displaystyle f(x)= \begin{cases} {1 \over b-a}, & a\lt x \lt b \\ 0 & {x\lt a, b\lt x} \end{cases}$
확률변수의 범위를 $a\leq x \leq b$라고 하고, 이 확률변수들의 함수 값을 $f(x)$라고 하면 다음과 같은 확률밀도 그래프를 그릴 수 있다. 참고로 어떤 확률변수 $X$가 균등분포를 따른다면 $X~ U(a, b)$로 표현한다.
이 때 연속확률변수에서의 확률은 확률밀도로 표현되고 확률밀도는 넓이를 의미한다. 이 때 전체 확률밀도는 1이므로 $(b-a)f(x) = 1$이 된다. 따라서 $f(x) = {1 \over (b-a)}$이다.
균등분포에서 평균과 분산은 각각 $\displaystyle E(x) = {b+a \over 2}$와 $\displaystyle V(x) = {(b-a)^2 \over 12}$이다. 여기서 평균을 나타내는 과정만 기술해보자면, 연속확률변수에서 평균은 $\displaystyle E(x) = \int_{-\infty}^\infty xf(x)dx$이므로
정규분포는 대표적인 연속확률분포에 속하며 가우시안 분포라고도 불린다. 정규분포의 확률밀도함수는 아래의 수식으로 나타낸다. (유도과정은 크게 두 가지 방법을 사용하는데 첫 번째론 과녁 맞추기 예시를 통한 유도와 두 번째론 이항분포로부터 유도하는 방법이 있다. 유도과정은 길어지므로 생략하며 고등수학만 활용해도 유도 가능하다.)
여기서 $\mu$는 평균을 나타내며 $\sigma^2$는 분산(표준편차 제곱)을 뜻한다. 이는 곧 정규분포는 아래 그림과 같이 평균과 분산에 따라 다양한 분포를 가지게 됨을 의미한다. 이 때 정규분포의 가장 높은 함수값을 가지는 확률변수 $X$는 평균이다. 만약 어떤 확률변수 $X$가 평균이 $\mu$고 분산이 $\sigma^2$인 정규분포를 따른다고 하면 기호로 $N(\mu, \sigma^2)$와 같은 형태로도 나타낼 수 있다.
이러한 정규분포에는 몇 가지 특징이 있다. 첫 번째는 정규분포는 확률밀도함수의 한 종류이므로 전체 넓이는 전체 확률을 의미하므로 1이 된다. 두 번째는 정규분포는 평균을 기준으로 대칭성을 띤다. 평균 기준 왼쪽과 오른쪽이 각각 0.5의 확률을 갖는다. 세 번째는 정규분포별 평균과 표준편차가 다르더라도 아래 그림과 같이 표준편차 구간 별 확률은 어느 정규분포에서나 같다는 것이다.
가령 예를 들어 $\displaystyle N(100, 5^2)$의 정규분포와 $\displaystyle N(64, 4^2)$ 정규분포가 두 개가 있을 때, 그 모양이 서로 다르더라도 위 그림과 같이 표준편차($\sigma$)로 나뉘어진 구간의 면적(확률)은 모두 같음을 의미한다.
이런 정규분포는 표준화 과정을 통해 표준 정규 분포(standard normal distribution)를 얻을 수 있다. 표준 정규 분포란 평균이 0 표준편차가 1인 분포를 말한다. 표준화 과정은 $\displaystyle Z = {X - \mu \over \sigma}$으로 이뤄진다. 모든 확률변수에 대해 평균을 뺀 뒤 표준편차로 나눠주는 것이다. $Z \sim N(0, 1)$의 형태로 표현하며 이를 표준정규분포 또는 Z-분포라 부른다.
이런 표준화 과정을 통해 표준정규분포로 만들면 서로 다른 모수 값(평균, 표준편차, 분산 등)을 가진 정규분포를 가진 집단 간의 비교 문제를 해결할 수 있다. 흔히 예를 드는 것으로 수학 시험 점수 비교다. 가령 A, B반의 수학 점수가 정규분포를 따른다 가정할 때 A반: 평균 70, 표준편차 30 / B반: 평균 80, 표준편차 15라면 비교로 성적 우위를 가리기 어렵다. 때문에 표준화를 통해 정규분포를 표준정규분포로 바꿔줌으로써 집단간 비교 문제를 해결할 수 있다.
9. 카이제곱분포 (Chi-square distribution)
카이제곱분포란 표준정규분포에서 파생된 것으로 한 마디로 말하면 표준정규분포의 확률변수를 제곱합한 분포다. 카이제곱 분포는 신뢰구간과 가설검정, 독립성 검정 등에서 자주 사용된다. 먼저 카이제곱분포의 기본적인형태를 보자. 표준정규분포에서는 평균이 0이고 표준편차가 1이었다. 따라서 평균 0을 기준으로 -와 +가 있지만 카이제곱분포는 확률변수를 제곱하였으므로 +만 존재한다.
카이제곱분포의 형태에서 앞 부분에 확률 변수 값이 큰 이유는뒤로갈수록정규분포의 양끝과 같은 편향이 상대적으로 적어지기 때문이다.이 카이제곱 분포를 조금 더 덧붙여 설명하면, $k$개의 서로 독립적인 표준정규분포의 확률변수를 각각 제곱한 후 더하여 얻는 분포다. 이 때 $k$는 표준정규분포를 따르는 확률변수의 개수로 카이제곱 분포의 형태를 결정하는 자유도로서 역할을 한다. 이 $k$에 따라 카이제곱 분포의 형태가 아래와 같이 달라진다. 자유도의 크기가 증가할수록 점점 대칭성을 갖게 되며 통상 $k=30$이상이면 거의 정규분포에 가까워진다고 한다.
이러한 카이제곱분포의 수식은 $\displaystyle f(x|k) = {1 \over 2^{k\over 2}\gamma ({k\over 2})} x^{{k\over 2}-1}e^{-{x\over 2}}$로 표기한다. 카이제곱분포의 평균과 분산은 각각 $E(x) = k$, $V(x) = 2k$이다. 이 중 카이제곱분포 수식을 통해 평균을 구하는 과정만 기술해보자면, (확률변수 $X$가 $k$ 자유도를 갖는 카이제곱분포를 따른다고 가정)
지수분포는 포아송 분포에서 유도된다. 위에서 포아송 분포는 단위 시간당 사건의 평균 발생 횟수였다. 수식으로는 $\displaystyle p(x) = {\lambda^x e^{-\lambda} \over x!}$였다. 여기서 $\lambda$는 단위 시간당 사건의 평균발생횟수($\because \lambda=np$)이며 $x$는 사건 발생 횟수이다. 예를 들어 하루 동안 모범 택시를 평균적으로 3번 마주친다면 $\displaystyle p(x) = {3^xe^{-3} \over x!}$이 된다.
지수분포는 이러한 포아송 분포가 만족하는 상황에서 사건 A가 일어날 때까지 걸리는 시간이 T이하일 확률이다. 즉 기존 포아송에서 시간까지 더 알고자 하는 것이다. 이를 일반화한 정의는 단위 시간당 사건 A의 평균발생횟수가 $\lambda$일 때, 사건 A가 처음 발생할 때 까지 걸리는 시간이 T이하일 확률이다. 지수 분포는 아래 수식으로 표현한다.
$\displaystyle f(T) = \lambda e^{-\lambda T}$
위 지수 분포 유도를 위해 하나의 예를 들어 설명 하자면, 모범 택시를 마주칠 때 까지 걸리는 기간이 5일 이하일 확률을 $\displaystyle p(0\leq t \leq 5) = \int_0^5 f(t)dt$로 표현할 수 있다. 이 확률을 구하기 위해서는 두 가지 방법이 있다. 첫 번째는 1일차에 만날 확률, 2일차에 만날 확률, ..., 5일차에 만날 확률을 구해 모두 더해주는 방식이고, 두 번째는 여사건을 사용하는 방법이다. 여사건을 통해 확률을 구하는 식은 (1 - 5일동안 모범 택시 마주치지 않을 확률 p)이다.
여사건으로 계산을 해보자면 먼저 1일차에 모범택시를 만나지 않을 확률을 구하면 $\displaystyle p(0) = {3^0e^{-3} \over 0!} = e^{-3}$이 된다. 따라서 5일동안 모범 택시를 마주치지 않을 확률은 $\displaystyle e^{{-3}\times 5}$가 된다. 이 모범 택시를 마주칠 확률은 곧 $\displaystyle \int_0^5 f(t)dt = 1 - e^{-15}$와 같다.
이렇게 구한 포아송 분포를 지수분포로 일반화 하여 어떤 사건이 발생할 때 까지 걸리는 기간이 T이하일 확률을 나타내는 과정을 나타내보자. 우선 $\displaystyle p(0\leq t\leq T) = \int_0^T f(t)dt = 1 - e^{-\lambda T}$이 있고, 여기서 구해야할 것은 지수분포를 나타내는 $\displaystyle \int_0^T f(t)dt$이다. 지수분포 식은 T로 미분해서 얻을 수 있다. $f(t)$의 부정적분을 $F(T)$로 두면, 이 적분식은 $\displaystyle F(T) - F(0) = 1-e^{-\lambda T}$가 된다. 이 식의 양변을 T로 미분하면 $\displaystyle f(T) = \lambda e^{-\lambda T}$가 되며 이 함수는 지수분포를 나타내는 식이다.
이 지수함수 분포에 대한 평균과 를 이용해 평균과 분산은 각각 $\displaystyle E(x)={1 \over \lambda}$, $\displaystyle V(x)={1\over \lambda^2}$이다. 이 중 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(t) = \int_0^\infty tf(t)dt$
$\displaystyle = \int_0^\infty t \lambda e^{-\lambda t}dt$ (여기서 부분적분을 사용하면)
$\displaystyle = \left[ -te^{-\lambda t}\right]_0^\infty + \left[-{1\over \lambda}e^{-\lambda t}\right]_0^\infty$ (이 식은 위 식에서 뒤 항을 적분해준 결과임. 여기서 극한값을 이용해 표현하면)
감마분포는 지수분포의 확장이다. 지수분포에서 한 번의 사건이 아닌 여러 개의 사건으로 확장한 것이다. 구체적으론 지수분포는 포아송 분포가 만족하는 상황에서 사건 A가 일어날 때까지 걸리는 시간이 T이하일 확률이었다. 감마분포는 $\alpha$번째 사건이 발생할때까지 걸리는 시간이 T이하일 확률이다. 예를 들어 평균적으로주유소를 30분에 한 번씩 마주친다면 주유소를 4번 마주칠 때까지 걸리는 시간이 T이하일 확률과 같은 것이다. 감마분포 또한 여러 곳에 활용되지만 주로 감마분포는 모수의 베이지안 추정에 활용된다.
감마함수는 $\displaystyle \gamma(\alpha) = \int_0^\infty x^{\alpha-1}e^{-x}dx, (\alpha \gt 0)$로 표기한다. 이 감마함수는 팩토리얼 계산을 자연수에서 복소수범위까지 일반화한 함수라고 한다. 이 감마 함수를 근간으로한 감마분포함수는 $\displaystyle f_x(x) = {1 \over \gamma(\alpha)\beta^\alpha} x^{\alpha-1}e^{-x\over \beta}$로 표기한다. ($\displaystyle 0 \leq x \leq \infty$, ($\alpha \gt 0, \beta \gt 0)$). 감마분포에서 $\alpha$는 형태 모수(shape parameter), $\beta$는 척도 모수(scale parameter)라고 한다.
감마분포의 평균과 분산은 각각 $E(x)=\alpha \beta$, $V(x) = \alpha \beta^2$이다. 여기서 감마분포의 평균을 구하는 과정만 기술하자면,
$\displaystyle E(x) = \int_0^\infty xf(x)dx$
$\displaystyle = \int_0^\infty x{1 \over \gamma(\alpha)\beta^\alpha} x^{\alpha-1}e^{-x\over \beta}dx$ ($xx^{-1}=1$, 상수 부분을 앞으로 빼주면)
$\displaystyle = {1 \over \gamma(\alpha) \beta^\alpha} \int_0^\infty (t\beta)^\alpha e^{-t} \beta dt$ ($\beta^\alpha$는 약분되어 사라지고 상수 $\beta$를 앞으로 빼주면)
$\displaystyle = {\beta \over \gamma(\alpha)} \int_0^\infty t^\alpha e^{-t}dt$ (이 때 $\gamma$ 함수의 원형과 동일하므로)
$\displaystyle = \beta {\gamma(\alpha+1) \over \gamma(\alpha)}$ ($\gamma$ 함수는 팩토리얼이므로 $\alpha$만 남게 됨)
$\displaystyle = \beta \alpha$
$\displaystyle \therefore E(x) = \alpha \beta$
12. 베타분포 (Beta distribution)
베타분포는 베이즈 추론에서 사전 확률을 가정할 때 사용되기 때문에 중요하다. 베타분포의 정의는 두 매개변수 $\alpha$와 $\beta$에 따라 [0, 1] 구간에서 정의되는 연속확률분포이다. $\alpha$와 $\beta$는 아래와 같이 베타분포 그래프의 형태를 결정하는 형태 모수(shape parameter)다. 만약 $\alpha = \beta$라면 베타분포는 대칭이 된다. 또 $\alpha$와 $\beta$가 커질수록 정규분포와 모양이 비슷해진다.
베타분포의 근간인 베타함수의 수식은 $\displaystyle B(\alpha, \beta) = {\gamma (\alpha) \gamma(\beta) \over \gamma(\alpha + \beta)} = \int_0^1 x^{\alpha -1}(1-x)^{\beta -1}dx$로 표현한다. 이 베타함수를 기반으로하는 베타분포의 확률밀도함수는 $\displaystyle f_x(x) = {\gamma(\alpha + \beta) \over \gamma(\alpha) \gamma(\beta)} x^{\alpha-1}(1-x)^{\beta-1}, (0 \lt x \lt 1, \alpha, \beta \gt 0)$이다. 평균과 분산은 각각 $\displaystyle E(x) = {\alpha \over \alpha + \beta}$, $\displaystyle V(x) = {\alpha \beta \over (\alpha+\beta)^2(\alpha+\beta+1)}$인데, 이 중 평균을 구하는 과정만 기술하면,
신경계를 이해하기 위해서는 가장 작은 단위인 뉴런의 동작을 우선 이해해야 한다. 뉴런 동작의 핵심은 이온(ion)의 움직임이다. 이온은 전하를 띠는 원자와 분자를 의미한다. 예를 들어 소금인 염화나트륨은 양전하를 띠는 나트륨 이온(Sodium, Na+)와 음전하를 띠는 염소 이온(Chloride, Cl-)로 나뉜다. 이 두 이온은 뉴런의 전기 신호 전달에서 중요한 역할을 하며 추가적으로 칼륨 이온 칼륨 이온(Potassium, K+)과 유기음이온 (A-)(단백질 분자)도 마찬가지다.
이러한 이온들은 일종의 출입문인 이온 채널을 통해 세포막 내/외부로 이동한다. 세포막에 나트륨 채널과 칼륨 채널이 있다. 세포막을 기준으로 외부에는 나트륨 이온, 세포막 내부에는 칼륨이 존재한다. 세포막 외부는 양극으로로 대전, 세포막 내부는 음극으로 대전되어 있는데 만약 나트륨 채널이 열려 세포막으로 들어오게 되면 안과 밖이 극이 바뀌는 탈분극 상태가 발생하며 뉴런에서 신호가 발생하게 된다.
이러한 탈분극 상태에 의한 신호 전달을 자세히 이해하기 앞서 뉴런의 구조를 먼저 살펴보면, 뉴런에는 크게 네 가지 주요 영역이 있다. 수상돌기, 세포체, 축삭돌기, 축삭 종말이다. 간단히 설명하자면 수상돌기/축삭돌기는 각각 신호 수신/발신 역할을 한다. 세포체(Cell body)는 세포호흡(Cell respiration)과 폴리펩티드 생산과 관련한 세포 소기관을 갖고 있다. 축삭 종말은 안쪽에 소포(vesicle)이라는 작은 막이 있어 신경전달물질을 저장하는 역할을 한다. 이외에 미엘린은 절연체로 축삭을 감쌈으로써 입력 신호를 더 빠르게 전달할 수 있도록 경로를 매끄럽게 만드는 역할을 한다.
structure of neuron
수상돌기에는 가시 모양으로 뻗은 돌기들이 있다. 이 부분에서 다른 뉴런들로부터 유입 신호(incoming signal)을 받는다. 유입신호는 세포체로 이동하는 과정에서 통합된다. 만약 신호 통합이 세포막(cell membrane)을 가로질러 충분히 강하게 탈분극 한다면 축삭(axon)이 시작되는 세포막에서 극파(spike)가 발생되어 축삭을 따라 전파된다. 만약 극파가 축삭 종말(axon terminal)에 도달하면 신경전달물질이 시냅스 간극으로 방출되고 일부는 시냅스 후 뉴런의 수용체에 결합한다. 참고로 이러한 신경 전달 과정은 단방향인 수상 돌기 → 세포체 → 축삭돌기 → 축삭 종말로만 흐른다.
유입 신호가 축삭 종말에 도달하기 전에는 축삭 돌기에서는 휴지 전위(Resting potential)를 유지한다. 휴지 전위란 뉴런이 흥분하여 신호를 전달하기 전, 준비 상태를 말한다. 만약 휴지 전위가 없다면 뉴런은 더 이상 신호를 전달할 수 없게 된다.그렇다면 이런 휴지 전위는 왜 발생할까? 휴지 전위는 결과적으로 이온의 불균등한 분포(농도)차이 때문에 발생한다. 세포막을 기준으로 세포막 외부에는 나트륨 이온의 농도가 높고 세포막 내부에는 칼륨 이온의 농도가 높다.
휴지 상태에서는 세포막에 있는 나트륨 채널과 칼륨 채널이 모두 닫힌 상태이다. 이런 휴지 상태에서는 세포막 외부는 내부에 비해 양극(positive)로 대전된 상태이며 세포막 내부는 외부에 비해 음극(negative)로 대전된 상태이다. 즉 세포막을 넘어 전압 차이가 발생한다.
세포막 외부와 세포막 내부 사이에 존재하는 이온 채널. 채널이 모두 닫힌 상태를 휴지 전위라 한다.
만약 이 휴지상태에서 유입 신호가 축삭 돌기에 도달한다면 탈분극 단계로 바뀐다. 탈분극 단계에는 나트륨 이온이 세포의 분극이 역전될 때 까지 세포 내부로 들어가며 결과적으로 세포 내부가 양극으로 대전된다. 이 상태가 되면 재분극 단계(Repolarizing phase)로 바뀌어 나트륨 이온 채널이 닫히고 칼륨 이온 채널이 열린다. 이 때 칼륨 이온은 세포 외부로 방출되며, 방출됨으로써 평형을 이루게 되어 다시 휴지 전위 상태가 된다.
여기서 평형 상태를 유지하기 위해서는 크게 두 가지 메커니즘이 작용한다. 첫 번째는 정전기력이다. 정전기력에 의해 양이온과 음이온이 서로 끌어 당기게 된다. 두 번째 힘은 확산(diffusion)이다. 확산은 모든 물질이 농도가 높은 곳에서 낮은 곳으로 퍼져나가려는 성질이 있음을 의미한다. 예를 들어 칼륨 이온의 경우 세포막 안쪽에 많이 위치하기 때문에 농도가 높다. 따라서 농도가 낮은 세포막 외부로 빠져나가려고 한다. 하지만 칼륨 이온은 양이온이기 때문에 음이온이 더 많은 세포막 내부로 정전기력에 의해 끌리게 된다. 추가적으로 이런 평형 상태를 유지하는 데 있어 기여하는 것은 위 그림 중간에 있는 나트륨-칼륨 펌프이다. 이는 일종의 경비원으로 만약 휴지전위에서 양전하를 띤 나트륨 이온이 일부 채널을 통해 유입되면 다시 바깥으로 방출하는 역할을 한다.
다시 돌아와, 유입 신호로부터 휴지전위 → 탈분극 → 재분극 → 휴지전위와 같은 일련의 단계가 축삭 돌기를 따라 연쇄적으로 발생하며 축삭 종말에 다다라서는 축삭 종말에 있는 신경전달물질이 다음 뉴런으로 방출되며 신경 전달이 이루어진다.
통계학의 대전제는 분석 대상 전체(모집단)를 분석하기에는 많은 비용이 발생하므로 부분(표본)을 통해 모집단의 특성을 파악하는 것이다. 모집단의 일부인 표본에 통계 분석 방법을 적용해 모수를 추정하는 방법을 모수 추정이라 한다. 모수는 모집단의 특성을 나타내는 수치를 의미한다. 모수의 종류는 모평균, 모분산, 모비율, 모표준편차, 모상관관계 등이 있다. 이런 모수들은 모집단 전체에 대한 값들이므로 알려지지 않은 수치다. 모집단의 특성을 파악하기 위해서는 이 모수들을 산출할 필요가 있다. 하지만 모집단 전체를 대상으로 산출하기에 비용이 많이 들어 현실적으로 가능하지 않다. 따라서 앞서 말한 것 처럼 표본을 추출하여 모집단의 일반적 특성을 추론하는데, 이를 통계적 추론이라 한다. 또 모수와 마찬가지로 표본의 특성을 나타내는 수치 종류로 표본평균, 표본분산, 표본비율, 표본표준편차, 표본상관관계 등이 있다. 이러한 수치들을 표본 통계량이라 한다. 정리하면 표본 통계량을 기반으로 모수를 구하는 것을 모수 추정 또는 통계적 추론이라 한다. 하지만 이러한 통계적 추론에는 부분을 통해 전체를 추정하는 격이므로 오차가 발생할 수 밖에 없다. 이러한 모수 추정에서 발생하는 오차를 표준오차라고 한다.
2. 모수 추정 방법: 점 추정(point estimation)과 구간 추정(interval estimation)
2.1 점 추정 (point estimation)
점 추정이란 표본으로부터 추론한 정보를 기반으로 모집단의 특성을 단일한 값으로 추정하는 방법이다. 예를 들어 대한민국 남녀 100명씩 표본으로 추출해 키를 조사한 결과 평균이 167.5가 나왔다면 모 평균을 단일한 점인 167.5로 추정하는 방법이다. 이러한 추정을 위해 표본평균과 표본분산 등을 계산해 모집단 평균과 모집단 분산 등을 추정한다. 이 때 표본평균과 표본분산 등은 모수를 추정하기 위해 계산되는 표본 통계량이자 추정량이라 부른다. 이 추정량은 추정치를 계산할 수 있는 함수(확률변수)이다. 이 추정량을 통해 표본에서 관찰된 값(표본평균, 표본분산 등)을 넣고 추정치(모평균, 모분산 등)를 계산한다.
표본평균과 표본분산 등의 추정량(표본 통계량)을 구하기 위해 먼저 표본이 추출되어야 한다. 표본 추출에 있어 가장 중요한 것은 무작위성(비편향성)이다. 편향되어 어떤 표본이 자주 추출된다면 모집단의 일반화된 특성을 추론할 수 없기 때문이다. 아래 그림을 보면 두번째는 편향은 작되 분산이 큰 경우고, 세 번째는 편향이 크되 분산이 작은 경우다. 네 번째는 편향도 크고 분산도 큰 경우다. 모수 추정의 목표는 표본으로부터 구한 표본 분산과 표본 편향 등의 추정량(표본 통계량)이 모수(과녁)와 오차가 작은 첫 째 그림과 같은 형태가 되는 것이다. (만약 모수와 표본 간의 관계를 더 자세히 알고 싶다면 중심극한정리를 볼 것, 모수추정을 가능하게 하는 수학적 근간이다.)
위 그림이 나타내는 바와 같이 추정량에 따라 추정치가 달라지므로 모수와 오차가 적은 추정치를 구하기 위해서는 추정량 선정에 있어 4가지 기준을 고려해야 한다. 아래 4가지를 설명하기 위해 수식 몇 가지만 간단히 정의하자면 모수: $\theta$ 표본 통계량: $\hat{\theta}$ 기대값: $E$이다.
1. 비편향성 (unbiasedness): 표본으로부터 구한 통계량 기대치가 추정하려는 모수의 실제 값과 같거나 가까운 성질을 의미 한다. 즉 편향(편의)은 추정량의 기대치와 모수와의 차이를 의미하는 것으로 $E(\hat{\theta}) - \theta = 0$이다. 편향이 0에 가까워질수록 좋은 추정량이 된다. 이러한 비편향성을 띠는 추정량을 unbiased estimator라고 하며 결국 편향이 적은 추정량을 선택해야 한다. $E(\hat{\theta}) = \theta$을 최대한 만족하는.
2. 효율성 (efficiency): 추정량 분산이 작게 나타나는 성질을 의미한다.
3. 일치성 (consistency): 표본 크기가 클수록 추정량이 모수에 점근적으로 근접하는 성질을 의미한다.
4. 충분성 (sufficiency): 어떤 추정량이 모수 $\theta$에 대해 가장 많은 정보를 제공하는지 여부를 나타내는 성질을 의미한다.
2.2 구간 추정 (interval estimation)
점 추정의 추정치가 모수와 같을 확률이 낮고 따라서 신뢰성이 낮다는 한계를 극복하기 위해 나온 방법이 구간 추정이다. 구간 추정을 통해 표본으로부터 추정한 정보를 기반으로 모수 값을 포함할 것이라 예상되는 구간을 제시한다. 이 구간을 신뢰 구간이라 한다. 신뢰 구간은 표본평균의 확률분포에 모평균이 신뢰수준 확률로 포함되는 구간을 의미한다. 즉 어떤 구간 내에 몇 % 확률로 존재하는지 추정하는 것이다. 구간 추정은 구간의 [하한, 상한]으로 표현하고 구간의 간격(interval)이 작을수록 모수를 정확하게 추정할 수 있다. 따라서 구간 추정은 점 추정에 비해 신뢰성이 높다는 장점이 있다. 신뢰성이 높다하여 점 추정이 불필요한 것은 아니다. 점 추정치를 기반으로 구간 추정이 이뤄지기 때문이다.
3. 추정량 정확성 평가 척도
그렇다면 추정량의 '좋다'의 기준인 정확성 평가는 어떻게 이뤄질까? 추정량이 모수와 근사할수록 좋을 것이다. 이를 위해 정확성 평가는 정량적으로 이뤄지며 일반적으로 크게 3가지 방법을 사용한다. 평균 제곱 오차(MSE), 제곱근 평균 제곱 오차(RMSE), 가능도(Likelihood)이다.
3.1 평균 제곱 오차 (MSE, Mean Squared Error)
오차의 제곱에 대해 평균을 취한 것으로 값이 작을수록 좋다. 식으로는 다음과 같이 나타낸다. 참고로 $\theta$는 $X$로 표기하였다.
일반적으로 가능도를 이해하기 위해 확률과 비교하며 함께 설명된다. 그 이유는 가능도는 확률의 반대 개념이기 때문이다. 그렇다면 어떻게 반대될까? 이를 잘 나타내는 그림은 다음과 같다. (출처: adioshun)
즉 확률이란 모수를 알고 있는 상태에서 표본이 관찰될 가능성을 의미하는 값이다. 모수를 알고 있다는 것을 다른 말로 확률분포가 결정되어 있는 상태라고 할 수 있다. 반면 가능도는 모수를 모르는 상태(=확률분포를 모르는 상태)에서 관측한 표본이 나타날 가능성에 기반해 모수 추정(확률분포 추정)을 진행한다. 즉, 가능도는 표본을 관측해 이 표본들이 어떤 확률분포를 갖는 모집단에서 추출되었는지를 역으로 찾는 것을 의미한다.
가능도의 필요성에 대한 배경
이런 가능도는 왜 필요할까? 왜 만들어졌을까? 그 이유는 확률의 한계 때문이다. 확률은 이산형 확률과 연속형 확률로 나뉜다. 이 때 연속형 확률에서 특정 표본이 관찰될 확률은 전부 0으로 계산되기 때문에 표본이 관찰될 확률을 비교하는 것이 불가능하다. 예를 들어 아래와 같이 연속형 확률을 표현하기 위한 확률 밀도 함수(PDF, Probability Density Function)가 있다 가정하자.
이 때 a와 b사이의 여러 표본들이 추출되어 관측될 수 있는 확률은 a와 b사이의 면적과 같다. 즉 a에서 b까지 적분하면 면적(확률)을 구할 수 있게 된다. 하지만 만약 어떤 특정 하나의 표본이 추출되면 하나의 직선만 되므로 넓이를 계산할 수 없게 된다는 문제점이 있는 것이다. 즉, 특정 관측치에선 확률값이 전부 0이 되어 버리는 것이다. 이러한 한계점을 해결해주는 것이 가능도인 것이다.
가능도에 대한 예시와 특징
가능도란 한 마디로 추출된 표본으로부터 어떤 분포를 가진 확률밀도함수의 y값을 구해 모두 곱해준 값을 의미한다. 또 다른 의미로 가능도는 관측된 표본이 어떤 분포로부터 나왔을지를 수치로 표현한 것을 말한다. 아래 그림을 살펴보자 (출처: 공돌이의 수학정리노트)
만약 모수로부터 추출된 표본이 [1, 4, 5, 6, 9]가 있고, 모수의 후보인 주황색 확률밀도함수와 파란색 확률밀도함수 중 어떤 것이 더 모수와 가깝다고 추정할 수 있을까? 직관적으로 주황색 확률밀도함수라 할 수 있다. 이를 수치적으로 계산하기 위해서는 각 후보 확률밀도함수를 대상으로 각 표본을 전부 넣고 해당 확률밀도함수의 y값(높이)인 기여도를 구해 모두 곱해준다. 이렇게 기여도를 모두 곱하면 likelihood 값이 된다. 이때 이 likelihood 값이 가장 큰 확률밀도함수가, 모수가 지닌 분포를 따를 가능성이 가장 높다. 또 이런 가장 높은 likelihood 값으로 모수의 확률밀도함수를 추정하는 방법을 최대가능도법(Maximum Likelihood Estimation, MLE)이라 한다. 참고로 주의해야할 것은 가능도 함수는 확률 함수가 아니기 때문에 모두 합해도 1이 되지 않는다. 그 이유는 가능도의 수치적 계산은, 관측값이 나올 수 있는 확률분포를 추정하여 얻은 값을 모두 곱해주기 때문이다.
가능도 함수의 수식적 이해
앞서 설명한대로 가능도는 어느 한 분포에 대하여 표본들의 기여도를 전부 곱해준 값이라 했다. 이러한 가능도를 함수로 표현하면 다음과 같다.
$P(X|\theta) = \prod_{k=1}^nP(x_k|\theta)$
가능도 함수에 사용한 수식 기호는 다음과 같은 의미를 지닌다.
$\theta = \theta_1, \theta_2, \theta_3, \dots, \theta_m$: 어떤 분포를 따른다 가정하는 확률분포함수 집합
$X = x_1, x_2, x_3, \dots, x_n$: 모수에서 추출된 표본의 집합
$p$: 확률밀도함수(기여도, 높이값)
따라서 정리하자면 확률밀도함수에 표본을 넣고 구한 기여도인 $p(x|\theta)$값을 전부 곱해주게 되면 어떤 한 확률밀도함수에 대한 liklihood 값이 된다. 그리고 표본에 대해 이 likelihood 값이 가장 큰 확률밀도함수가 모수를 잘표현한다고 하며 이런 모수를 찾는 것을 최대가능도법이라 한다.
참고로 일반적으로 계산의 용이를 위해 자연 로그를 취해주는 아래의 log likelihood 함수를 사용한다.
$logP(X|\theta) = \sum_{k=1}^nlogP(x_k|\theta)$
4. 추정량 구하는 방법
추정량을 구하는 방법에는 일반적으로 크게 3가지 방법을 사용한다. 최대 가능도 추정법, 적률 방법, 베이즈 추정법이다. 이 세 방법은 모두 점 추정에 속하는 방법들이다.
4.1 최대가능도법 (MLE, Maxmimum Likelihood Estimation)
최대우도추정이라고도 불리는 MLE는 위에서도 설명한 바와 마찬가지로 모수 $\theta$를 추정하는 방법 중 하나이다. 관측치가 주어졌을 때 likelihood 함수 값을 최대화하는 $\theta$를 찾는 것이 목표이다. 이 $\theta$는 어떤 확률밀도함수들을 표현한 것이다. 또 관측치 $X = x_1, x_2, x_3, \dots, x_n$이 있을 때 이들을 수식으로 표현하면 likelihood 함수는 다음과 같은 형태를 가진다.
베이즈 추정은 베이즈 정리를 기반으로 한다. 베이즈 정리는 사전 확률(prior probability)과 사후 확률(posterior probability)의 관계를 나타내는 정리다. 이 베이즈 정리는 조건부 확률을 기반으로 한다. 조건부 확률이란 사건A가 발생했다는 전제하에 사건B가 일어날 확률이다.P(B|A)=P(B∩A)P(A)로 표현한다. 베이즈 정리는 이 조건부 확률에서 유도된 것으로 다음과 같은 수식으로 나타낸다.
위 두 수식은 동일한 것으로 변수명만 달리했다. 그 이유는 이해를 조금 더 쉽게 돕기 위함으로 왼쪽은 조건부 확률로부터 유도될 때 흔히 사용하고, 오른쪽은 베이즈 정리가 결국 모수(θ) 추정을 목적으로 한다는 것을 보이기 위함이다. 수식의 의미를 하나씩 분석해보자면, 먼저 posterior는 새로운 표본 X가 관측됐을 때 어떤 모수값을 갖는지를 의미한다.likelihood는 어떤 표본 X가 관찰되었을 때 어떤 확률분포를 갖는 모집단(모수)에서 추출되었을 확률을 의미한다. prior는 사전확률인 모수값을 의미하며, evidence는 모집단으로부터 표본 X가 관측될 확률이다. 결국 이베이즈 정리를 요약하면 가능도(likelihood), 사전확률(prior), 관측 데이터(evidence)를 이용해 사후 확률(posterior)를 예측하는 방법이다.
간단 용어 정리
추정 (Estimation) : 표본 통계량(표본 평균, 표본 분산 등)에 기초해 모집단의 모수(모 평균, 모 분산 등)를 추정하는 것
추정량 (Estimate) : 모수를 추정하는 통계량. 표본 통계량은 모두 추정량이 될 수 있음. 추정량은 어떤 표본 분포를 띤 확률변수가 됨. 추정량은 관측된 표본에 따라 모수를 추정하는 것으로써 관측 표본 때 마다 값이 달라지는 확률변수임.
주성분 분석은 차원 축소에 사용되는 대표적인 알고리즘이다. 차원 축소는 고차원 공간 데이터를 저차원 공간으로 옮기는 것을 말한다. 그렇다면 이 차원축소가 왜 필요할까? 고차원으로 표현된 데이터는 계산 비용 많고 분석에 필요한 시각화가 어렵기 때문이다. 또 고차원을 이루는 피처 중 상대적으로 중요도가 떨어지는 피처가 존재할 수 있기 때문이다. 따라서 중요도가 낮은 피처를 제외하는 대신 계산 비용이나 비교적 준수한 성능을 얻는다. 주성분 분석을 진행하면 차원 축소로 인해 표현력이 일부 손실된다. 만약 4차원에서 2차원으로 축소를 통해 첫 번째 주성분과 두 번째 주성분을 얻고, 이 두 개가 원래 피처 표현력의 90%를 띤다면 나머지 10%의 손실을 감수하더라도 계산 효율을 얻게 된다.
주성분 분석을 통해 저차원 공간으로 변환할 때 피처 추출(feature extraction)을 진행한다. 이는 기존 피처를 조합해 새로운 피처로 만드는 것을 의미한다. 이 때 새로운 피처와 기존 피처 간 연관성이 없어야 한다. 연관성이 없도록 하기 위해 직교 변환을 수행한다. 직교 변환을 수행하면 새로운 피처 공간과 기존 피처 공간이 90도를 이루게 된다. 즉 내적하면 0이 되는 것이다. 이러한 직교 변환을 수행할 때 기존 피처와 관련 없으면서 원 데이터의 표현력을 '잘' 보존해야 한다. 잘 보존하는 것은 주성분 분석의 핵심인 분산(Variance)을 최대로 하는 주축을 찾는 것이다.
여기서 분산이란? 데이터가 퍼진 정도를 의미한다. 예를 들어 만약 4차원 공간이 있고 3차원 공간으로 차원 축소를 한다면 3차원 공간상에서 데이터 분포가 넓게 퍼지는, 즉 분산을 가장 크게 만드는 벡터를 찾아야 한다. 만약 3차원 공간이 있고 2차원 공간으로 차원 축소한다면, 2차원 공간상에서 데이터 분포가 가장 넓게 퍼지도록 하는 벡터를 찾아야 한다. 만약 2차원 공간이 있고 1차원 공간으로 차원 축소 한다면 1차원 공간상에서 데이터 분포가 가장 넓게 퍼지게 만드는 벡터를 찾아야 한다.
애니메이션으로 이해하자면 다음과 같다.
2차원 공간을 1차원으로 줄일 때 2차원에 넓게 퍼진 데이터 분포를 1차원 상에서도 똑같이 넓게 퍼질 수 있도록 하는 "벡터"를 찾아야 한다. 여기서 "벡터"는 곧 주축을 의미한다. 이 때 주축과의 동의어를 Eigen vector라고 한다. 주축을 찾고 주축에 피처들을 사상시키게 되면 주성분이 된다. 다르게 말해 피처들을 주축에 사상시킬 때 분산이 최대가 되는 주성분이 만들어진다. 이렇게 분산이 가장 큰 주성분을 첫 번째 주성분, 두 번째로 큰 축을 두 번째 주성분이라 한다.
그렇다면 이 주축인 Eigen vector는 어떻게 구하고, Eigen vector에 피처를 어떻게 사상시킬수 있는 것일까? Eigen vector를 구하기 위해서는 특이값 분해 (SVD, Singular Value Decomposition)가 수행된다. 또 사상을 위해서 공분산 행렬이 필요하다. 따라서 사실상 PCA를 한마디로 말하면 데이터들의 공분산 행렬에 대한 특이값 분해(SVD)로 볼 수 있다. 먼저 공분산 행렬에 대해 알아보자.
공분산 행렬이란 무엇일까?
공분산은 한 마디로 두 피처가 함께 변하는 정도, 즉 공변하는 정도를 나타낸다. 수식으로 표현하면 다음과 같다.
$\sum = Cov(X) = {X^TX\over n}$
여기서 n은 행렬 X에 있는 데이터 샘플 개수를 나타내며 $X$란 전체 피처와 데이터 값을 나타낸다. X의 열축은 피처가 되고 X의 행축은 데이터 개수가 된다. 예를 들어 $x_1, x_2, x_3 $ 피처 3개가 있다고 가정하면 $X^T \times T$는 아래와 같이 표현할 수 있다.
이 행렬에서 모든 대각 성분은 같은 피처 간 내적이므로 분산에 해당한다. 대각 성분 이외에는 모두 다른 피처 간 내적이므로 공분산에 해당한다. 즉 이러한 피처 간 내적을 통해 수치적으로 i번 피처와 j번 피처가 공변하는 정도를 알 수 있게 된다. 이것이 수식이 나타내는 의미이다. 수식에서 n으로 나눈 것은 공분산이 커질 수 있으므로 데이터 개수로 나누어 평균을 구한 것이다. 이렇게 만들어진 행렬을 공분산 행렬이라 한다.
공분산 행렬이 가지는 의미는 무엇이고 어떻게 활용할까?
공분산 행렬은 피처 간에 서로 함께 변하는 정도를 의미한다고 했다. 공분산 행렬은 이러한 공변의 의미와 더불어 한 가지 의미가 더 있다. 그 의미는 바로 벡터에 선형 변환(사상)을 가능하게 하는 것이다. 즉, 공간상에 한 벡터가 있을 때 공분산 행렬을 곱해주게 되면 그 벡터의 선형 변환이 이루어진다. 이는 선형대수학에서 행렬이 벡터를 선형 변환시키는 역할을 하기 때문이다. 즉 공분산 행렬엔 피처간 공변 정보가 담겨 있으므로 이를 주축인 Eigen vector에 사상시키면 주성분을 구할 수 있다. 다음으로 주축을 구하기 위한 특이값 분해(SVD)를 살펴보자.
특이값 분해란 무엇이며 이를 통해 어떻게 Eigen vector를 구할 수 있을까?
먼저 특이값 분해란 일종의 행렬에서 이뤄지는 인수 분해다. 정확히는 행렬을 대각화하는 방법 중 하나이다. 대각화하는 이유는 대각화된 행렬의 대각선에 있는 값이 특이값(Singular Value)에 해당하기 때문이다. PCA에서 특이값 분해 대상은 위에서 본 공분산 행렬이다. 공분산 행렬을 특이값 분해 함으로써 PCA에 필요한 주축인 Eigen vector와, Eigen vector 스케일링에 필요한 Eigen value를 얻을 수 있다. Eigen value를 얻은 뒤 내림차순으로 정렬했을 때 가장 첫 번째 값이 분산을 최대로 하는 값이다.
일반적으로 특이값 분해는 고유값 분해(EVD)와 함께 설명된다. 고유값 분해의 경우 m x m의 정방 행렬에서만 사용할 수 있지만, 특이값 분해의 경우 m x n 인 직사각 행렬에도 적용가능하다. 따라서 일반화가 가능하단 장점이 있다. 또 특이값이란 고유값에 루트를 씌운 값이다. 그렇다면 특이값 분해는 어떻게 진행될까? 먼저 실수 공간에서 임의의 m x n 행렬에 대한 특이값 분해는 다음과 같이 정의된다.
$ A = U\sum V^T$
수식 성분이 나타내는 바는 다음과 같다. 참고로 여기서 $\sum$이란 합을 의미하는 기호가 아니라 행렬을 의미한다.
$A = m \times n $ 직사각 행렬 (diagonal matrix)
$U = m \times m $ 직교 행렬 (orthogonal matrix)
$\sum = m \times n$ 직사각 대각행렬 (diagonal matrix)
$V = n \times x $ 직교 행렬 (orthogonal matrix)
특이값 분해를 이해하기 앞서 두 가지 선형대수적 특성을 알아야 한다. 첫 번째는 $U$, $V$가 직교 행렬이라면 선형대수적 특성에 의해 $UU^T = VV^T = E$, $U^{-1} = U^T, V^{-1} = V^T$가 만족한다는 것이다. 여기서 $E$는 항등행렬이다. 여기서 항등행렬이란 가령 $U$에 역행렬인 $U^{-1}$를 곱했을 때 나오는 행렬을 의미한다. 두 번째론 대칭 행렬은 고유값 분해가 가능하며 또 직교행렬로 분해할 수 있다는 것이다. 앞에 보았던 공분산인 행렬 $A$는 대각선으로 기준으로 값들이 대칭을 띠는 대칭 행렬이었다. 그러므로 고유값 분해 또는 직교행렬로 분해할 수 있다. 또 행렬 $A$가 대칭행렬이므로 $A^T$도 대칭 행렬이다.
결과적으로 PCA는 특이값 분해를 통해 $\sum$를 구하고자 한다. 이 $\sum$는 $AA^T, A^TA$를 고유값 분해해서 나오는 고유값들에 루트를 씌운 값들이 대각선에 위치하는 행렬이다. 그리고 $AA^T$와 $A^TA$의 고유값이 같다. 이를 증명하는 하는 과정은 다음과 같다.
앞서 특이값 분해의 정의는 $A = U\sum V^T$라고 했다. 이때 $A$는 대각행렬이므로 고유값 분해가 가능하다.
$AA^T = (U\sum V^T)(U\sum V^T)^T$
$= U\sum V^T V\sum^T U^T$(이 때 $V^TV$ = $V^{-1}V$ 즉 직교행렬이므로 항등 행렬이 되어 사라짐)
$= U(\sum \sum^T)U^T$
즉 $AA^T$를 고유값 분해하면 = $U(\sum \sum^T)U^T$가 된다. 또,
$A^TA = (U\sum V^T)^T(U\sum V^T)$
$= V\sum^T U^TU\sum V^T$(이 때 $U^TU$ = $U^{-1}U$ 즉 직교행렬이므로 항등 행렬이 되어 사라짐)
$= V(\sum ^T\sum)V^T$
즉 $A^TA$를 고유값 분해하면 = $ V(\sum ^T\sum)V^T$가 된다.
그리고 이를 정리하고 덧붙이면,
$U$는 $AA^T$를 고유값 분해 해서 얻은 직교행렬이다. 그리고 U의 열벡터를 A의 leftsingular vector라 부른다.
$V$는 $A^TA$를 고유값 분해 해서 얻은 직교행렬이다. 그리고 V의 열벡터를 A의 right singular vector라 부른다.
$\sum$은 $AA^T, A^TA$를 고유값 분해해서 나온 고유값($\lambda$, eigen value)들의 제곱근을 대각원소로 하는 직사각 대각행렬이다.
이 $\sum$의 대각원소들을 행렬 A의 특이값(singular value)라 부른다. 아래 수식과 같다.
최단 거리 알고리즘이란 그래프 상에서 노드 간의 탐색 비용을 최소화하는 알고리즘이다. 일반적으로 네비게이션과 같은 길찾기에 적용된다. 최단 거리 알고리즘 종류는 크게 3가지가 있다. 1. 다익스트라(Dijkstra) 2. 플로이드 워셜(Floyd Warshall) 3. 벨만 포드(Bellman Ford)이다.
1. 다익스트라 (Dijkstra) 알고리즘
다익스트라 알고리즘은 그래프 상에서 특정 한 노드에서 다른 모든 노드까지의 최단거리를 구하는 알고리즘이다. 다르게 표현하면 가중 그래프에서 간선 가중치의 합이 최소가 되는 경로를 찾는 알고리즘 중 하나이다.
다익스트라는 그리디와 동적 계획법이 합쳐진 형태이다. 현재 위치한 노드에서 최선의 경로를 반복적으로 찾으면서도 계산 해둔 경로를 활용해 중복된 하위 문제를 풀기 때문이다. 다익스트라는 만약 그래프에 음의 가중치가 있다면 사용할 수 없다. 그 이유는 그리디를 통해 최단 경로라고 여겨진 경로 비용을 DP 테이블에 저장한 뒤, 재방문하지 않는데, 만약 음의 가중치가 있다면 이러한 규칙이 어긋날 수 있기 때문이다. 음의 가중치가 포함된다면 플로이드 워셜이나 벨만 포드 알고리즘을 사용해 최단 경로를 구할 수 있다. 다만 시간 복잡도가 늘어나는 단점이 있기에 해결하고자 하는 문제에 맞게 사용해야 한다.
만약 아래와 같은 그래프가 있다 가정하고 동작 원리를 확인해보자.
위와 같은 초기 노드와 간선을 테이블에 나타내보자면 다음과 같다. 예를 들자면 1행 4열은 1번 노드에서 4번 노드로 가는 것을 나타내며 비용은 8이 든다.
0
3
INF
8
9
3
0
2
INF
INF
INF
2
0
1
3
8
INF
1
0
INF
9
INF
3
INF
0
다익스트라 알고리즘은 특정 한 노드에서 다른 모든 노드까지의 최단 거리를 구하는 알고리즘이라 했다. 예를 들어 특정 한 노드를 1이라 가정하면 [0, 3, INF, 8, 9]는 다음과 같은 과정을 통해 업데이트 된다.
아래와 같이 노드 1을 선택하게 되면 1과 연결된 3개의 간선을 확인한다.
이 중에서 다른 정점으로 가는 최소 비용이 2번 노드가 가장 작기 때문에 2번 노드로 이동하고, 노드 1번은 방문 처리한다. 이 때 테이블 값 변화는 없다.
0
3
INF
8
9
2번 노드에 연결된 노드는 1번과 3번이다. 하지만 1번의 경우 이미 방문했고, 비용이 크므로 볼 필요 없다. 2와 최소비용으로 연결된 노드는 3이기 때문에 노드 3으로 이동하고, 2를 방문처리 한다. 이 때 테이블 값 변화가 발생한다. 1과 3은 연결되지 않았었다. 하지만 그리디와 같이 계속해서 최적의 상태를 업데이트 하므로 다른 노드를 탐색하다 3을 방문할 수 있기 때문에 1 → 2 → 3으로 이동하는 동안의 비용인 5로 업데이트 해준다.
0
3
5
8
9
다음으로 3번 노드에 연결된 간선은 총 3개이다. 하지만 2의 경우 방문처리 되었으니 노드 4, 5번 두 개만 고려하면 된다.
노드 4, 5번 중 더 비용이 적은 것은 4번 노드이므로, 4번 노드로 이동하고 3번 노드는 방문처리 해준다. 마찬가지로 테이블 값 변화가 발생한다. 기존에는 1 → 4로 가는 비용이 8이었지만 1 → 2 → 3 → 4를 거치는 것이 6이 들기에 테이블 값을 6으로 업데이트 시켜준다.
0
3
5
6
9
다음으로 4번 노드에 연결된 간선은 총 2개이다. 하지만 두 개 모두 방문처리 되었고 5로 가는 간선이 없다.
따라서 테이블 값 업데이트는 없다. 또 알고리즘은 여기서 끝이 난다. 최종적으로 1에서 다른 모든 노드까지의 비용은 아래 테이블이 된다.
0
3
5
6
9
이를 코드로 구현하기 위해서는 가중치에 중요도가 있으므로 자료구조 힙을 사용해 표현해준다. 전체 코드는 다음과 같다.
""" This is input value. you can just copy and paste it.
5 6 1
1 2 3
1 4 8
1 5 9
2 1 2
2 3 2
3 2 2
3 4 1
3 5 3
4 1 8
4 3 1
5 1 9
"""
import heapq
def dijkstra(start):
heap = []
heapq.heappush(heap, [0, start]) # 최소힙은 배열의 첫 번째 값을 기준으로 배열을 정렬.
INF = float('inf')
weights = [INF] * (vertex+1) # DP에 활용할 memoization 테이블 생성
weights[start] = 0 # 자기 자신으로 가는 사이클은 없으므로.
while heap:
weight, node = heapq.heappop(heap)
if weight > weights[node]: # 비용 최적화 전부터 큰 비용일 경우 고려할 필요 없음.
continue
for n, w in graph[node]: # 최소 비용을 가진 노드를 그리디하게 방문한 경우 연결된 간선 모두 확인
W = weight + w
if weights[n] > W: # 여러 경로를 방문해 합쳐진 가중치 W가 더 비용이 적다면
weights[n] = W # 업데이트
heapq.heappush(heap, (W, n)) # 최소 비용을 가진 노드와 합쳐진 가중치 추가
return weights
vertex, edge, start = map(int, input().split())
graph = [[] for _ in range(vertex+1)]
for i in range(vertex+edge):
src, dst, weight = map(int, input().split())
graph[src].append([dst, weight])
weights = dijkstra(start)
print (weights) # [inf, 0, 3, 5, 6, 8]
최종 출력되는 최소 비용 중 1에서 1로 가는 사이클은 없으므로 0이 된다. 또한 만약 주어진 문제가 1에서 3으로 가는 최소비용을 구하는 것이라면 5가 되고, 1에서 4로가는 최소 비용을 구하는 것이라면 6이 된다.
벨만 포드 알고리즘은 가중 유향 그래프 상에서 특정 한 노드로 부터 다른 노드까지의 최단 경로를 구하는 알고리즘이다. 다익스트라 알고리즘의 한계점을 보완하기 위해 나왔다. 그 한계점이란 간선이 음수일 때 최단 경로를 구할 수 없다는 것이다. 사실 정확히는 음의 가중치 자체가 문제가 되진 않는다. 문제는 사이클 형성 여부에 따라 달렸다. 만약 사이클을 형성하면 문제가 된다. 아래 그림을 보자.
만약 다익스트라 알고리즘을 통해 특정 한 노드(1)에서 다른 노드(2)로의 최소 거리를 구하는 문제를 해결하려 한다면 가중치 3 → 4 → 5를 거쳐 비용이 12가 된다. 하지만 중간에 사이클이 있기 때문에 3 → 4 → -6 → 4 → -6 → 4 → -6 ...이 되어 비용이 무한히 작아지게 된다.
이러한 문제점을 해결하기 위해 나온 알고리즘이 벨만 포드이다. 기본적으로 다익스트라와 동일하지만 핵심 차이점은 간선의 가중치가 음일 때도 최소 비용을 구할 수 있다. 다만 시간복잡도가 늘어나기 때문에 가중치가 모두 양수일 경우 다익스트라를 사용하는 것이 좋다. 시간 복잡도가 늘어나는 이유는 그리디하게 최소 비용 경로를 찾아가는 다익스트라와 달리, 벨만 포드는 모든 경우의 수를 고려하는 동적 계획법이 사용되기 때문이다.
그렇다면 모든 경우의 수를 어떻게 고려할까? 그 방법은 매 단계 마다 모든 간선을 전부 확인하는 것이다. 다익스트라는 출발 노드에서만 연결된 노드를 반복적으로 탐색하며 다른 모든 노드까지의 최소 거리를 구했다. 하지만 벨만 포드는 모든 노드가 한번씩 출발점이 되어 다른 노드까지의 최소 비용을 구한다.
아직 조금 추상적이니 구체적인 아래 그림을 보며 동작 과정을 알아보자.
위와 같은 그래프가 있다고 할 때 모든 노드가 한 번씩 출발 노드가 될 것이다. 복잡하지 않다. Itertation 1회, 2회일 때를 이해하면 귀납적으로 적용하여 이해할 수 있기 때문이다.
위와 같은 초기 상태의 그래프가 있을 때, 가중치를 담을 DP 테이블 값은 아래와 같이 모두 INF가 된다.
INF
INF
INF
INF
INF
[Iteration 1] 첫 번째로 노드 1번을 먼저 탐색해보자.
1번 노드에 연결된 인접노드에 해당하는 간선의 가중치를 업데이트 해준다.
0
3
5
6
9
가중치 업데이트에 있어 시작 노드는 사이클이 없으므로 0이 되고, 2~5모두 연결된 간선이 있으므로 해당 가중치 값을 업데이트 해준다.
[Iteration 1] 이제 2번 노드를 보자. 2번 노드는 3번과 연결되어 있다.
1 → 3 경로 비용인 3보다 1 → 2 → 3 경로 비용인 -8이 더 작으므로 DP 테이블 값을 3에서 -8로 업데이트 해준다.
0
-6
-8
9
8
[Iteration 1] 이제 3번 노드를 보자. 4번과 5번 노드에 연결되어 있다.
1 → 4 비용인 9보다 1 → 2 → 3 → 4 비용인 -3이 작으므로 9를 -3으로 업데이트 해준다.
0
-6
-8
-3
8
또 1 → 5 비용인 8보다 1 → 2 → 3 → 5 비용인 -15가 작으므로 8을 -15로 업데이트 해준다.
0
-6
-8
-3
-15
[Iteration 1] 이제 4번 노드를 보자. 3번 노드와 연결되어 있다.
DP 테이블의 3번에 담긴 비용인 -8이 1 → 4 → 3 비용인 5보다 작으므로 업데이트 하지 않는다.
0
-6
-8
-3
-15
[Iteration 1] 이제 5번 노드를 보자. 3번 노드와 연결되어 있다.
DP 테이블 3번의 -8이 1 → 5 → 3의 비용 -5보다 더 작으므로 업데이트 하지 않는다.
0
-6
-8
-3
-15
이를 노드 개수(V) - 1까지 반복 진행한다. 그리고 추가적으로 음의 사이클의 존재 여부를 파악하고 싶다면 마지막으로 1번더 반복하여 총 V번의 반복 했을 때 V-1번 했을 때와 값이 달라진다면 음의 사이클이 있는 것이라 판별할 수 있다. 음의 사이클이 있다면 반복시 무한히 작아지기 때문이다.
Iteration1 종료시 [inf, 0, -6, -8, -3, -15]
Iterataion2 종료시 [inf, 0, -6, -28, -23, -35]
Iteration3 종료시 [inf, 0, -6, -48, -43, -55]
Iteration4 종료시 [inf, 0, -6, -68, -63, -75]
가되며 마지막으로 여기서 한 번더 수행했을 때 값이 바뀐다면 음의 사이클이 존재하는 것이다.
Iteration5 종료시 [inf, 0, -6, -88, -63, -75]
이를 코드로 구현하면 다음과 같다.
"""
5 9
1 2 -6
1 3 3
1 4 9
1 5 8
2 3 -2
3 4 5
3 5 -7
4 3 -4
5 3 -13
"""
import sys
input = sys.stdin.readline
def bellman_ford(start):
weights[start] = 0
for i in range(V):
for src, dst, weight in graph:
W = weights[src] + weight
if weights[src] != INF and weights[dst] > W:
weights[dst] = W
if i == V -1:
return False # negative cycle exists
return True # there is no cycle
V, E = map(int, input().split())
graph = []
for _ in range(E):
src, dst, weight = map(int, input().split())
graph.append([src, dst, weight])
INF = float('inf')
weights = [INF] * (V+1)
if bellman_ford(1): # 출발 노드를 인자 값으로 넣어줄 것
for i in range(2, V+1): # 출발 노드인 1을 제외하고 다른 모든 노드로 가기 위한 최단 거리 출력
print (weights[i], end = ' ')
else:
print ("There is negative cycle.")
플로이드 워셜 알고리즘은 모든 노드 간의 최단거리를 구할 수 있다. 한 노드에서 다른 모든 노드까지의 최단 거리를 구하는 다익스트라와 벨만포드 알고리즘과 대조된다. 플로이드 워셜 알고리즘은 그래프 상에서 음의 가중치가 있더라도 최단 경로를 구할 수 있다. 하지만 음의 가중치와 별개로 음의 사이클이 존재한다면 벨만 포드 알고리즘을 사용해야 한다.
플로이드 워셜 알고리즘은 모든 노드 간의 최단거리를 구하고 이 때, 점화식이 사용되기에 동적 계획법에 해당한다. 동적 계획법에 해당하므로 최단 거리를 업데이트할 테이블이 필요하다. 이 때 모든 노드간의 최단 거리이므로 2차원 배열이 사용된다. 특정 한 노드에서 출발하는 다익스트라가 1차원 배열을 사용하는 것과 차이점이 있다.
플로이드 워셜 알고리즘의 핵심은 각 단계마다 특정한 노드 k를 거쳐 가는 경우를 확인한다. 아래 점화식을 살펴보면 다음과 같다.
$D_{ij} = min(D_{ij}, D_{ik} + D_{kj})$
$i$에서 $j$로 가는 것과 $i$에서 $k$를 거쳐 $j$로 가는 것 중 어느 것이 최소 비용인지를 찾는 것이다.
구현은 매우 간단하여 3중 for문이 사용된다. 아래 코드는 위 점화식을 기반으로 코드화 시킨 것이다.
for k in range(1, V+1): # via
graph[k][k] = 0 # 사이클 없으므로 자기 자신 0
for i in range(1, V+1): # src
for j in range(1, V+1): # dst
graph[i][j] = min(graph[i][j], graph[i][k]+graph[k][j])
코드와 함께 동작 과정을 아래 그래프를 통해 살펴보자.
노드 4개와 간선 7개로 구성된 그래프다. 이를 바탕으로 DP 테이블 초기 상태를 만들면 다음과 같다. 하나의 노드에서 다른 노드로 바로 갈 수 있다면 가중치를, 없다면 INF를 저장해준다.
INF
5
INF
7
4
INF
-3
INF
6
INF
INF
4
INF
INF
2
INF
이제 3중 for문을 사용해 거쳐가는 노드를 설정 후 해당 노드를 거쳐갈 때 비용이 줄어드는 경우 값을 업데이트 시켜줄 것이다. 먼저 거쳐가는(k) 노드가 1일 때의 경우를 살펴보자
[Iteration 1] 거쳐가는 노드 K = 1
Iteration 1의 테이블 첫 번째 행을 업데이트 해보자. 노드 1에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[1][2] = min(graph[1][2], graph[1][1]+graph[1][2]) : 5와 0+5를 비교하는 것이므로 업데이트 X
graph[1][3] = min(graph[1][3], graph[1][1]+graph[1][3]): INF와 0+INF를 비교하는 것이므로 업데이트 X
graph[1][4] = min(graph[1][4], graph[1][1]+graph[1][4]): 7과 0+7을 비교하는 것이므로 업데이트 X
Iteration 1의 테이블 첫 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 없었으므로 전과 동일하다. 다만 graph[k][k] = 0에 의해 첫번째 값만 INF에서 0으로 바뀌었다.
0
5
INF
7
4
INF
-3
INF
6
INF
INF
4
INF
INF
2
INF
Iteration 1의 테이블 두 번째 행을 업데이트 해보자. 노드 2에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[2][1] = min(graph[2][1], graph[2][1]+graph[1][1]): 4와 4+0을 비교하는 것이므로 업데이트 X
graph[2][2] = min(graph[2][2], graph[2][1]+graph[1][2]): INF와 4+9를 비교하는 것이므로 업데이트 O
graph[2][3] = min(graph[2][3], graph[2][1]+graph[1][3]): -3과 4+INF를 비교하는 것이므로 업데이트 X
graph[2][4] = min(graph[2][4], graph[2][1]+graph[1][4]): INF와 4+7을 비교하는 것이므로 업데이트 O
Itertaion 1의 테이블 두 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 두 번 이뤄졌다.
0
5
INF
7
4
INF → 9
-3
INF → 11
6
INF
INF
4
INF
INF
2
INF
Iteration 1의 테이블 세 번째 행을 업데이트 해보자. 노드 3에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[3][1] = min(graph[3][1], graph[3][1]+graph[1][1]): 6과 6+0을 비교하는 것이므로 업데이트 X
graph[3][2] = min(graph[3][2], graph[3][1]+graph[1][2]): INF와 11을 비교하는 것이므로 업데이트 O
graph[3][3] = min(graph[3][3], graph[3][1]+graph[1][3]): INF와 6+INF를 비교하는 것이므로 업데이트 X
graph[3][4] = min(graph[3][4], graph[3][1]+graph[1][4]): 4와 13을 비교하고 원래 4였으므로 업데이트 X
Itertaion 1의 테이블 세 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 한 번 이뤄졌다.
0
5
INF
7
4
9
-3
11
6
INF → 11
INF
4
INF
INF
2
INF
Iteration 1의 테이블 네 번째 행을 업데이트 해보자. 노드 4에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[4][1] = min(graph[4][1], graph[4][1]+graph[1][1]): INF와 INF+0을 비교하므로 업데이트 X
graph[4][2] = min(graph[4][2], graph[4][1]+graph[1][2]):INF와 INF+5를 를 비교하므로 업데이트 X
graph[4][3] = min(graph[4][3], graph[4][1]+graph[1][3]): 2와 INF+INF를 비교하고 원래 2였으므로 업데이트 X
graph[4][4] = min(graph[4][4], graph[4][1]+graph[1][4]): INF와 INF+7을 비교하므로 업데이트 X
Itertaion 1의 테이블 네 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 이뤄지지 않았다.
0
5
INF
7
4
9
-3
11
6
11
INF
4
INF
INF
2
INF
이러한 과정을 노드의 수만큼 반복해주면 된다. 이를 요약하면 다음과 같다.
Iteration2는 노드 1~4에서 노드2를 거쳐 노드 1~4를 탐색하는 경우가 될 것이다.
Iteration3은 노드 1~4에서 노드3을 거쳐 노드 1~4를 탐색하는 경우가 될 것이다.
Iteration4는 노드 1~4에서 노드4를 거쳐 노드 1~4를 탐색하는 경우가 될 것이다.
이를 코드로 나타내면 앞서 본 것과 동일하다. 중요한 것은 거쳐서 노드 k를 거쳐갈때 다이렉트로 가는 것보다 비용이 적어지는가를 판단하는 것이다.
for k in range(1, V+1): # via
graph[k][k] = 0 # 사이클 없으므로 자기 자신 0
for i in range(1, V+1): # src
for j in range(1, V+1): # dst
graph[i][j] = min(graph[i][j], graph[i][k]+graph[k][j])
이러한 플로이드 워셜 알고리즘을 구현하는 전체 코드는 다음과 같다.
""" This is input value. you can just copy and paste it.
4 7
1 2 5
1 4 7
2 1 4
2 3 -3
3 1 6
3 4 4
4 3 2
"""
import sys
input = sys.stdin.readline
V, E = map(int, input().split())
INF = float('inf')
graph = [[INF] * (V+1) for _ in range(V+1)]
for _ in range(E):
src, dst, weight = map(int, input().split())
graph[src][dst] = weight
for k in range(1, V+1): # via
graph[k][k] = 0
for i in range(1, V+1): # src
for j in range(1, V+1): # dst
graph[i][j] = min(graph[i][j], graph[i][k]+graph[k][j])
for i in range(1, V+1):
for j in range(1, V+1):
print (graph[i][j], end= ' ')
print()
학회: IEEE Conference on Computer Vision and Pattern Recognition
게재: 2016년
컴퓨터 비전에서 높은 이미지 인식 능력 모델의 발전은 AlexNet → VGGNet → GoogLeNet → ResNet 순으로 이뤄진다. 이러한 높은 인식 능력의 배경에는 네트워크의 깊이를 늘림으로써 high level feature부터 low level feature를 효율적으로 추출할 수 있기 때문이다. 대개 네트워크의 깊이를 늘림으로써 모델의 성능이 늘어난다. 하지만 반드시 그렇지는 않다. 아래 그래프가 이를 뒷받침 한다.
Training error & Test error on CIFAR-10 of "plain" network (no residual network)
위 그래프를 보면 상대적으로 더 깊은 네트워크가 training error가 더 높다. 즉 성능이 더 낮아진다. 왜 이렇게 낮아질까? 네트워크 깊이를 늘리는 데 있어 한계가 있기 때문이다. 그리고 그 한계란 gradient vanishing 문제를 말한다. 이는 레이어가 깊을수록 역전파를 하는 과정에서 미분 값이 줄어들기 때문에 앞단 레이어는 영향을 거의 받지 못하기 때문이다. 이 문제를 해결하기 위해 ResNet이 만들어졌다. 즉 ResNet은 gradient vanishing 문제를 해결하는 모델인 것이다. 그 핵심 방법은 아래 그림 오른쪽과 같이 residual network를 사용하는 것이다.
residual network는 앞단 레이어의 출력값이 입력으로 들어온 x를 feed forward 한 값에 다시 x를 더해준다. 이게 왜 효과가 있을까? 왼쪽 일반 신경망과의 학습 방식이 다르기 때문이다. 일반 신경망은 입력 $x$를 통해 출력 $H(x)$를 얻는 $H(x) = x$다. 반면 오른쪽 residual network는 $H(x) = F(x) + x$가 된다. 중간에 $F(x)$가 추가된 것이다. 이 때 이 추가된 $F(x)$를 0이 되도록 학습한다면 일반 신경망인 $H(x) = x$와 같아진다. 하지만 이렇게 둘러온다면 하나의 큰 장점이 있다. 일반 신경망처럼 역전파가 진행될 때 $H(x) = x$에서 미분하는 것과 달리 residual network를 이용해 미분하게 되면 $H'(x) = F'(x) + 1$이 된다. 즉 1도 남기 때문에 기울기가 0에 수렴하여 소실되지 않고 역전파가 끝까지 진행될 수 있는 것이다.
이해가 안될 경우를 대비해 조금 더 설명하면, $H(x) = F(x) +x$을 이항하면 $F(x) = H(x) - x$가 된다. 이 때 $F(x)$를 0에 근사하게 만든다면 $H(x) - x$도 0에 근사하게 된다. 다시 이항하면 기존 신경망과 같이 $H(x) = x$의 형태가 된다. 양쪽 모두 역전파로 인해 미분되어 0에 근사하게 되면 기울기 소실 문제가 발생하는 것이다. 참고로 $H(x) - x$을 residual이라 부르며, residual network에선 기존 신경망의 학습 목적인 $H(x)$를 최소화 해주는 것이 아니라 $F(x)$를 최소화 시켜주는 것이다. $F(x) = H(x) - x$이므로.
ResNet에서는 residual network를 아래 두 가지 방식을 사용해 구현했다. 첫 번째는 바로 위 그림과 마찬가지로 단순한 구조를 사용하는 Identity 방식과, 두 번째는 1x1 convolution 연산을 통해 차원을 스케일링 해주는 Projection 방식이다.
기존의 Identity 방식에 더해 Projection 방식이 더해진 이유는 입력/출력 차원이 다를 때 스케일링 해주기 위함이다. 또 Projection 방식은 네트워크를 깊게 만들어줄 때 학습 시간을 줄이기 위해 사용하는데, 위 두 구조가 비슷한 시간 복잡도를 갖기 때문이라고 한다.
다시 돌아와 이러한 residual network 구조를 사용하는 것이 ResNet 이해의 핵심이다. 이렇게 residual network를 모델 레이어로 쌓으면 다음과 같은 성능 증가를 가져오게 된다.
가는 선: training error / 굵은 선: validation error
좌측의 residual network를 적용하지 않은 plain network를 살펴보면 레이어를 깊게 해줄수록 성능이 오히려 떨어지게 된다. 반면 residual network를 모델에 적용하게 되면 레이어가 깊더라도 error rate가 떨어져 성능이 더 좋아지는 것을 확인할 수 있다.
그렇다면 더욱 더 residual network를 쌓게 되면 어떤 결과가 나올까? 아래를 보자. 참고로 ResNet에서 50개의 layer가 넘어가는 모델들은 Projection 방법 (Bottleneck building block)을 사용하여 만든 모델이다. 반대로 50개 미만은 Identity 방법 (Basic building block)으로 만들었다.
model performance comparison on CIFAR-10 datasets
좌측 residual network를 적용하지 않은 plain network의 경우에는 레이어가 깊어질수록 성능이 계속 떨어지는 것을 볼 수 있다. 반면 가운데 그래프처럼 ResNet을 적용하면 error율이 아닐 때 보다 더 감소한 것을 볼 수 있다. 또한 110개의 네트워크를 쌓더라도 성능이 증가하는 것을 볼 수 있다. 다만 우측 그래프처럼 residual network를 1202개까지 쌓게 되면 오히려 110개를 쌓았을 때 보다 성능이 좋지 않다. 하지만 이를 두고 1202개 가량을 쌓았을 때가 ResNet의 한계라고 해석할 수 없다. 그 이유는 CIFAR-10 데이터셋만으로는 불충분해 overfitting 되었을 가능성이 있기 때문이고, 또 ResNet 논문 저자들은 그 어떤 Dropout과 같은 Regularization을 적용하지 않았다고 말했다. 따라서 강력한 Regularization을 적용한다면 성능 향상의 여지가 있는 것이다.
마지막으로, ResNet 모델의 개선 여지가 있음에도 불구하고 아래 표와 같이 이전에 나온 VGGNet과 GoogLeNet 모델보다도 높은 성능을 보였다.
Error rate on ImageNet validation
ResNet을 구현하기 위해 먼저 가장 핵심인 ResNet 모델 아키텍처를 살펴보면 다음과 같다.
하나의 max-pool 레이어와, 하나의 average-pool 레이어를 제외하고 모두 convolution 레이어로 구성되어 있다. 또 18, 34 layer는 레이어 구조상 Basic Building Block을 사용하며 50, 101, 152 layer는 Bottleneck Building Block을 사용한다.
그리고 논문에서 구현에 적용되었던 augmentation 기법과 레이어 특이 사항, 하이퍼파라미터 값을 정리하면 다음과 같다.
1. Augmentation
이미지를 스케일 별 augmentation을 위해 이미지 사이즈를 256~480 범위에서 랜덤 샘플링 진행
논문: Going Deeper with convolutions 게재: 2015년 학회: CVPR
GoogLeNet이란?
GoogLeNet은 한 마디로 네트워크의 depth와 width를 늘리면서도 내부적으로 inception 모듈을 활용해 computational efficiency를 확보한 모델이다. 이전에 나온 VGGNet이 깊은 네트워크로 AlexNet보다 높은 성능을 얻었지만, 반면 파라미터 측면에서 효율적이지 못하다는점을 보완하기 위해 만들어졌다.
CNN 아키텍처와 GoogLeNet
2010년 초/중반 CNN 아키텍처를 활용해 높은 이미지 인식 능력을 선보인 모델은 AlexNet (2012) → VGGNet (2014) → GoogLeNet (2014) → ResNet (2015) → ... 순으로 계보가 이어진다. 이 모델들은 네트워크의 depth와 width를 늘리면서 성능 향상이 이루어지는 것을 보며 점점 depth와 width를 늘려갔다. 하지만 이렇게 네트워크가 커지면서 두 가지 문제점이 발생했다. 첫 번째는 많은 파라미터가 있지만 이를 학습시킬 충분한 데이터가 없다면 오버피팅이 발생하는 것이고, 두 번째는 computational resource는 늘 제한적이기에 비용이 많이 발생하거나 낭비될 수 있다는 점이다. GoogLeNet은 이러한 문제점을 해결하기 위해 fully-connected layer의 neuron 수를 줄이거나 convolution layer의 내부 또한 줄여 상대적으로 sparse한 network를 만들고자 만들어졌다. 결과적으로 GoogLeNet은 가장 초반에 나온 AlexNet보다도 파라미터수가 12배 더 적지만 더 높은 성능을 보이는 것이 특징이다. 결과적으로 GoogLeNet은 ILSVRC 2014에서 classification과 detection 트랙에서 SOTA를 달성했다.
Inception: GoogLeNet 성능의 핵심
파라미터 효율적이면서도 높은 성능을 낼 수 있는 GoogLeNet 아키텍처의 핵심은 내부 Inception 모듈의 영향이다. Inception 모듈을 보기전 먼저 GoogLeNet 아키텍처를 살펴보면 다음과 같다.
왼쪽(아래)에서 출발하여 오른쪽(위)으로 점점 깊어진다. Inception 모듈은 위 GoogLeNet 네트워크에서 사용되는 부분 네트워크에 해당한다. 그 부분 구조는 아래와 같다. 두 가지 버전이 있다.
두 버전 모두 이미지 feature를 효율적으로 추출하기 위해 공통적으로 1x1, 3x3, 5x5 필터 크기를 갖는 convolution 연산을 수행한다. 이렇게 이미지의 다양한 영역을 볼 수 있도록 서로 다른 크기의 필터를 사용함으로써 앙상블하는 효과를 가져와 모델의 성능이 높아지게 된다. 참고로 필터 크기를 1x1, 3x3, 5x5로 지정한 것은 필요성에 의한 것이기보다 편의성을 기반으로 했다. 만약 짝수 크기의 필터 크기를 갖게 된다면 patch-alignment 문제라고하여 필터 사이즈가 짝수일 때 patch(필터)의 중간을 어디로 두어야 할지 결정해야하기에 번거로워지기 때문이다.
두 버전의 Inception 모듈을 비교해보자면, 먼저 좌측 naive Inception 모듈의 경우 1x1, 3x3, 5x5 convolution 연산과 3x3 max pooling 연산을 병렬 수행한 뒤 concatenation을 통해 결과를 합쳐주는 구조로 되어 있다. 하지만 결과적으로 이는 잘 동작하지 않았다. 그 이유는 convolution 결과와 max pooling 결과를 concatenation하면 기존 보다 차원이 늘어나는 문제점이 발생했기 때문이다. 정확히는 max pooling 연산의 경우 channel 수가 그대로 보존되지만 convolution 연산에 의해 더해진 channel로 인해 computation 부하가 늘어나게 된다. 이 과정을 도식화 한 것은 아래 그림과 같다. (출처: 정의석님 블로그)
위 그림과 같이 output channel의 크기가 증가하여 computation 부하가 커지는 문제점을 해결하기 위해 우측 두 번째 Inception 모듈이 사용된다. 두 번째 Inception 모듈을 통해 output channel을 줄이는 즉 차원을 축소하는 효과를 가져온다. 실제로도 이러한 효과로 인한 computation efficiency 때문에 GoogLeNet 아키텍처에서도 첫 번째 naive Inception 모듈이 아닌 두 번째 dimension reduction Inception 모듈을 사용한다.
그렇다면 두 번째 Inception module에서의 차원축소는 어떻게 이루어질까? 이에 대한 핵심은 1x1 convolution 연산에 있다. 1x1 convolution 연산은 Network in Network (Lin et al) 라는 연구에서 도입된 방법이다. 이름 그대로 1x1 필터를 가지는 convolution 연산을 하는 것이다. 1x1 convolution 연산은 아래 GIF와 같이 동작한다. 그 결과 feature map 크기가 동일하게 유지된다. 하지만 중요한 것은 1x1 filter 개수를 몇 개로 해주느냐에 따라 feature map의 차원의 크기(채널)를 조절할 수 있게 되는 것이다. 따라서 만약 input dimension 보다 1x1 filter 개수를 작게 해준다면 차원축소가 일어나게 되며, 그 결과 핵심적인 정보만 추출할 수 있게 된다.
Global Average Pooling (GAP)
GoogLeNet 아키텍처에선 Global Average Pooling 개념을 도입하여 사용한다. 이는 마찬가지로 Network in Network (Lin et al) 에서 제안된 것으로, 기존 CNN + fully connected layer 구조에서 fully-connected layer를 대체하기 위한 목적이다. 그 이유는 convolution 연산의 결과로 만들어진 feature map을 fully-connected layer에 넣고 최종적으로 분류하는 과정에서 공간 정보가 손실되기 때문이다. 반면 GAP은 feature map의 값의 평균을 구해 직접 softmax 레이어에 입력하는 방식이다. 이렇게 직접 입력하게 되면 공간 정보가 손실되지 않을 뿐만 아니라 fully-connected layer에 의해 파라미터를 최적화 하는 과정이 없기 때문에 효율적이게 된다.
Auxiliary classification
먼저 Auxiliary란 보조를 뜻하는 것으로 Auxiliary classification은 최종 classification 결과를 보조하기 위해 네트워크 중간 중간에 보조적인(Auxiliary) classifier를 두어 중간 결과 값을 추출하는 것이다. 아래 그림은 GoogLeNet 아키텍처를 부분 확대한 것이다. Auxiliary Classification 과정은 이 중 노란 박스 열에 해당한다.
이렇게 Auxiliary classifier를 중간 중간에 두는 이유는 네트워크가 깊어지면서 발생하는 gradient vanishing 문제를 해결하기 위함이다. 즉 네트워크가 깊어지면 loss에 대한 back-propagation이 영향력이 줄어드는 문제를 해결하기 위해 도입된 것이다. 이렇게 함으로써 중간에 있는 Inception layer들도 적절한 가중치 업데이트를 받을 수 있게 된다. 하지만 Inception 모듈 버전이 늘어날수록 Auxiliary classifier를 점점 줄였고 inception v4에서는 완전히 제외했다. 그 이유는 중간 중간에 있는 layer들은 back-propagation을 통해 학습이 적절히 이루어 졌지만 최종 classification layer에서는 학습이 잘 이루어지지 못해 최적의 feature가 뽑히지 않았기 때문이다.
파이토치로 GoogLeNet 구현하기
GoogLeNet 모델의 핵심은 Inception 모듈을 구현하는 것이다. 1. Inception 모듈 구현에 앞서 Inception 모듈에서 반복적으로 사용될 convolution layer를 생성하기 위해 ConvBlock이란 클래스로 다음과 같이 구현해준다. convolution layer 뒤에 batch normalization layer와 relu가 뒤따르는 구조이다.
import torch
import torch.nn as nn
from torch import Tensor
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs) -> None:
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
2. ConvBlock 클래스를 활용하여 Inception module을 구현하기 위한 Inception 클래스를 다음과 같이 구현해준다.
Inception 클래스를 확인하면 내부적으로 4개의 branch 변수를 만든다. 이 4개의 branch라는 변수는 각각 아래 Inception module에서 네 갈래로 분기되는 것을 구현해준 것이다.
Inception 모듈에 들어갈 인자는 다음과 같다. 1x1 convolution의 경우 kernel_size=1, stride= 1, padding=0 3x3 convolution의 경우 kernel_size=3, stride= 1, padding=1 5x5 convolution의 경우 kernel_size=5, stride= 1, pading=2 max-pooling의 경우 kernel_size=3, stride=1, padding=1
kernel_size는 아키텍처에 보이는 그대로와 같고, GoogLeNet에서는 stride를 공통적으로 1로 사용했다. 각각의 padding은 추후 네 개의 branch가 합쳐졌을 때의 크기를 고려하여 맞춰준다.
3. Auxiliary Classifier를 구현하기 위해 아래와 같이 InceptionAux라는 클래스로 구현해주었다. 1x1 convolution의 output channel의 개수는 논문에 기술된 대로 128을 적용해주었으며 dropout rate 또한 논문에 기술된 대로 0.7을 적용해주었다.
import torch
import torch.nn as nn
from torch import Tensor
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
super(InceptionAux, self).__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = ConvBlock(in_channels, 128, kernel_size=1, stride=1, padding=0)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=0.7)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.avgpool(x)
x = self.conv(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
InceptionAux 클래스는 아래와 그림과 같이 Auxiliary Classification 과정을 구현해 준 것이다.
4. ConvBlock, Inception, InceptionAux를 활용하여 GoogLeNet을 다음과 같이 구현할 수 있다.
import torch
import torch.nn as nn
from torch import Tensor
class GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=1000) -> None:
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
self.conv1 = ConvBlock(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.conv2 = ConvBlock(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0)
self.conv3 = ConvBlock(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(kernel_size=8, stride=1)
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = None
self.aux2 = None
def transform_input(self, x: Tensor) -> Tensor:
x_R = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_G = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_B = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat([x_R, x_G, x_B], 1)
return x
def forward(self, x: Tensor) -> Tensor:
x = self.transform_input(x)
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool3(x)
x = self.a4(x)
aux1: Optional[Tensor] = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
aux2: Optional[Tensor] = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.e4(x)
x = self.maxpool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1) # x = x.reshape(x.shape[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return aux1, aux2
else:
return x
Inception 모듈에 들어갈 모델 구성은 Table 1의 GoogLeNet 아키텍처를 참고하였다.
전체 코드는 다음과 같이 구현할 수 있다.
import torch
import torch.nn as nn
from torch import Tensor
from typing import Optional
class Inception(nn.Module):
def __init__(self, in_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj) -> None:
super(Inception, self).__init__()
self.branch1 = ConvBlock(in_channels, n1x1, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
ConvBlock(in_channels, n3x3_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n3x3_reduce, n3x3, kernel_size=3, stride=1, padding=1))
self.branch3 = nn.Sequential(
ConvBlock(in_channels, n5x5_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n5x5_reduce, n5x5, kernel_size=5, stride=1, padding=2))
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
ConvBlock(in_channels, pool_proj, kernel_size=1, stride=1, padding=0))
def forward(self, x: Tensor) -> Tensor:
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)
class GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=1000) -> None:
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
self.conv1 = ConvBlock(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.conv2 = ConvBlock(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0)
self.conv3 = ConvBlock(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = None
self.aux2 = None
def transform_input(self, x: Tensor) -> Tensor:
x_R = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_G = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_B = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat([x_R, x_G, x_B], 1)
return x
def forward(self, x: Tensor) -> Tensor:
x = self.transform_input(x)
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool3(x)
x = self.a4(x)
aux1: Optional[Tensor] = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
aux2: Optional[Tensor] = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.e4(x)
x = self.maxpool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1) # x = x.reshape(x.shape[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return aux1, aux2
else:
return x
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs) -> None:
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
super(InceptionAux, self).__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = ConvBlock(in_channels, 128, kernel_size=1, stride=1, padding=0)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=0.7)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.avgpool(x)
x = self.conv(x)
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
model = GoogLeNet(aux_logits=True, num_classes=1000)
print (model(x)[1].shape)
위 코드에서 Auxiliary Classifier의 입력 차원 같은 경우는 논문에서 기술된 대로 512, 528을 적용해주었고, fully-connected layer 또한 1024개의 unit으로 설정해주었다.
만약 GoogLeNet으로 간단한 학습을 진행해보고자 할 때 다음과 같이 코드 구현이 가능하다. 다만 CIFAR10 데이터셋을 예시로 사용하므로 위 코드에서 num_classes=10로 바꿔줘야 한다.
제목: Very Deep Convolutional Networks For Large-Scale Image Recognition
게재: 2015년
학회: ICLR (International Conference on Learning Representations)
이 글에서는 크게 두 개의 파트로, 첫 번째론 VGGNet 논문의 연구를 설명하고, 두 번째로 VGGNet 모델을 구현한다.
개요
VGGNet은 2014년 ILSVRC에서 localisation과 classification 트랙에서 각각 1위와 2위를 달성한 모델이다. 이 모델이 가지는 의미는 2012년 혁신적이라 평가받던 AlexNet보다도 높은 성능을 갖는다는 점에서 의미가 있다. 실제로 아래 벤치마크 결과를 확인해보면 맨 아래에 있는 Krizhevsky et al. (Alexnet) 보다도 성능이 월등히 좋은 것을 확인할 수 있다.
2010년 초/중반에는 위 성능 비교표가 나타내는 것처럼 Convolutional network를 사용한 모델의 성능이 점점 높아졌다. 이러한 성능 증가의 배경에는 ImageNet과 같은 large scale 데이터를 활용가능 했기 때문이고 high performance를 보여주는 GPU를 사용했다는 점이다.
2012년 AlexNet이 나온 이후에는 AlexNet을 개선하려는 시도들이 많았다. 더 작은 stride를 사용하거나 receptive window size를 사용하는 등 다양한 시도들이 있었다. VGGNet은 그 중에서 네트워크의 깊이 관점으로 성능을 올린 결과물이라 할 수 있다.
VGGNet을 만들기 위해 사용했던 아키텍처를 살펴보면 아래와 같다. 모든 모델 공통적으로 convolutional layer이후 fully-connected layer가 뒤 따르는 구조이다. 모델 이름은 A, A-LRN, B, C, D, E로 지정했으며 이 중 VGG라 불리는 것은 D와 E이다. 참고로 간결성을 위해 ReLU 함수는 아래 표에 추가하지 않았다.
표 1. Convolutional Network Configuration
이 논문에선 실험을 위해네트워크의 깊이를 늘려가면서도 동시에 receptive field를 3x3과 1x1로 설정했다. receptive field는 컨볼루션 필터가 한 번에 보는 영역의 크기를 의미한다. AlexNet은 receptive field가 11x11의 크기지만 VGGNet은 3x3으로 설정함으로써 파라미터 수를 줄이는 효과를 가져왔고 그 결과 성능이 증가했다. 실제로 3x3이 두 개가 있으면 5x5가 되고 3개를 쌓으면 7x7이 된다. 이 때 5x5 1개를 쓰는 것 보다 3x3 2개를 써서 layer를 더 깊이할 수록 비선형성이 증가하기에 더 유용한 feature를 추출할 수 있기에 위 아키텍처에서는 receptive field가 작은 convolution layer를 여러 개를 쌓았다. 참고로 receptive field를 1x1로 설정함으로써 컨볼루션 연산 후에도 이미지 공간 정보를 보존하는 효과를 가져왔다고 한다.
위 표 1에서 확인할 수 있는 A-LRN 모델을 통해서 보인 것은 AlexNet에서 도입한 LRN(Local Response Network)이 사실상 성능 증가에 도움되지 않고 오히려 메모리 점유율과 계산 복잡도만 더해진다는 것이다. 아래 표를 통해 LRN의 무용성을 확인할 수 있다. 또한 표 1에서 네트워크 깊이가 가장 깊은 모델 E (VGGNet)가 가장 좋은 성능을 보이는 것을 확인할 수 있다.
표 3. single test scale에서의 ConvNet 성능 비교
참고로, S, Q는 각각 train과 test에 사용한 이미지 사이즈 크기를 의미한다. 이를 기술한 이유는 scale jittering이라는 이미지 어그멘테이션 기법을 적용했을 때 성능이 더 높아진다는 것을 보인 것이다. 이 논문에선 scale jittering에 따라 달라지는 성능을 비교하기 위해 single-scale training과 multi-scale training으로 나누어 진행했다. single-scale training이란 이미지의 크기를 고정하는 것이다. 가령 train 때 256 또는 384로 진행하면 test때도 각각 256 또는 384로 추론을 진행하는 것이다. 반면 multi-scale training의 경우 S를 256 ~ 512에서 랜덤으로 크기가 정해지는 것이다. 이미지 크기의 다양성 때문에 모델이 조금더 robustness해지며 정확도가 높아지는 효과가 있다. 아래 표 4는 multi-scale training을 적용했을 때의 성능 결과이다.
표 4. multi test scale에서의 ConvNet 성능 비교
single-scale training에 비해 성능이 더욱 증가한 것을 알 수 있다. 추가적으로 S를 고정 크기의 이미지로 사용했을 경우보다 S를 256 ~ 512사이의 랜덤 크기의 이미지를 사용했을 때 더욱 성능이 높아지는 것을 확인할 수 있다.
또한 이 논문에서는 모델의 성능을 높이기 위해 evaluation technique으로 multi-crop을 진행했다. dense와 multi-crop을 동시에 사용하는 것이 더 높은 성능을 보이는 것을 확인할 수 있다.
표 5. ConvNet evaluation 테크닉 비교
마지막으로 여지껏 개별 ConvNet 모델에 대해 성능을 평가했다면 앙상블을 통해 여러 개의 모델의 출력을 결합하고 평균을 냈다. 결론적으로 D, E 두 모델의 앙상블을 사용해 오류율을 6.8%까지 현저히 줄이는 것을 보였다.
표 6. Multiple ConvNet fusion 결과
여기까지가 VGGNet 논문에 대한 내용이다. 다음은 VGGNet 논문 구현에 관한 것이다. 이 논문을 읽으며 구현해야 할 목록을 정리해본 것은 다음과 같다.
1. Model configuration.
Convolution Filter
3x3 receptive field
좌/우/상/하를 모두를 포착할 수 있는 가장 작은 사이즈
1x1 convolution filter 사용
spacial information 보존을 위함
Convolution Stride
1로 고정
Max-Pooling Layer
kernel size: 2x2
stride: 2
5개의 max-pooling 레이어에 의해 수행됨. 대부분 max-pooling은 conv layer와 함께하지만 그렇지 않은 것도 있음
Fully-Connected Layer
convolutional layer 스택 뒤에 3개의 FC layer가 따라 옴
앞의 2개는 4096 채널을 각각 가지고 마지막은 1000개를 가지면서 소프트맥스 레이어가 사용됨
Local Response Normalization
Local Response Normalization 사용 X: LRN Layer가 성능 개선X이면서 메모리 점유율과 계산 복잡도만 높아짐
2. Initialization
잘못된 초기화는 deep network에서 gradient 불안정성으로 학습 지연시킬 수 있기에 중요함
weight sampling: 평균 0, 분산이 $10^{-2}$ variance인 정규분포 사용
bias: 0로 초기화
3. Augmentation
random crop:고정된 224x224 입력 이미지를 얻기 위함
horizontal flip
random RGB color shift
고정 사이즈 224x224 RGB image를 사용했고, 각 픽셀에 대해 RGB value의 mean을 빼주는 것이 유일한 전처리(?)
4. Hyper-parameter
optimizer: SGD
momentum: 0.9
weight decay: L2 $5\cdot 10^{-4} = 0.0005$
batch size: 256
learning rate: 0.1
validation set 정확도가 증가하지 않을 때 10을 나눔
학습은 370K iteration (74 epochs)에서 멈춤
dropout: 0.5
1, 2번째 FC layer에 추가
이를 바탕으로 VGGNet에 대한 코드를 구현하면 다음과 같다. 크게 1. 모델 레이어 구성 2. 가중치 초기화 3. 하이퍼파라미터 설정 4. 데이터 로딩 5. 전처리 6. 학습으로 구성된다 볼 수 있다.
적용 배경은 모델의 일반화를 돕는 것을 확인 (top-1, top-2 error율을 각각 1.4%, 1.2% 감소)
Activation Function
ReLU를 모든 convolution layer와 fully-connected에 적용
적용 배경은 아래 그래프처럼 실선인 ReLU가 점선인 tanH보다 빠르게 학습했음
2. 하이퍼 파라미터
optimizer: SGD
momentum: 0.9
weight decay: 5e-4
batch size: 128
learning rate: 0.01
adjust learning rate: validation error가 현재 lr로 더 이상 개선 안되면 lr을 10으로 나눠줌. 0.01을 lr 초기 값으로 총 3번 줄어듦
epoch: 90
그리고 별도로 레이어에 가중치 초기화를 진행 해줌
편차를 0.01로 하는 zero-mean 가우시안 정규 분포를 모든 레이어의 weight를 초기화
neuron bias: 2, 4, 5번째 convolution 레이어와 fully-connected 레이어에 상수 1로 적용하고 이외 레이어는 0을 적용.
def _init_bias(self):
for layer in self.layers:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01)
nn.init.constant_(layer.bias, 0)
nn.init.constant_(self.layers[4].bias, 1)
nn.init.constant_(self.layers[10].bias, 1)
nn.init.constant_(self.layers[12].bias, 1)
nn.init.constant_(self.classifier[1].bias, 1)
nn.init.constant_(self.classifier[4].bias, 1)
nn.init.constant_(self.classifier[6].bias, 1)
참고로 헷갈렸던 것은 위 nn.init.constant_(layer.bias, 0)에서의 0은 bool로 편향 존재 여부를 나타내는 것이지 bias를 0으로 설정하는 것이 아니다.
3. 이미지 전처리
고화질 이미지를 256x256 사이즈로 다운 샘플링후 이미지의 center에서 cropped out
각 픽셀에서 training set에 대한 평균 값을 빼줌
이를 바탕으로 전체 코드를 구현하면 아래와 같다. 크게 나누어 보자면 5가지 정도가 될 수 있다.
1. 레이어 구성 2. 가중치 초기화 3. 하이퍼파라미터 설정 4. 이미지 전처리 5. 학습 로직 작성이다. 참고로 이미지 전처리에 사용하는 transform 메서드에서 사용되는 상수 값은 별도로 논문에 기재되어 있지 않기에 pytorch 공식 documentation에서 기본 값을 가져와서 사용했다.
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils import data
import logging
from glob import glob
logging.basicConfig(level=logging.INFO)
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.num_classes = num_classes
print (f"[*] Num of Classes: {self.num_classes}")
self.layers = nn.Sequential(
nn.Conv2d(kernel_size=11, in_channels=3, out_channels=96, stride=4, padding=0),
nn.ReLU(), # inplace=True mean it will modify input. effect of this action is reducing memory usage. but it removes input.
nn.LocalResponseNorm(alpha=1e-3, beta=0.75, k=2, size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(kernel_size=5, in_channels=96, out_channels=256, padding=2, stride=1),
nn.ReLU(),
nn.LocalResponseNorm(alpha=1e-3, beta=0.75, k=2, size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(kernel_size=3, in_channels=256, out_channels=384, padding=1, stride=1),
nn.ReLU(),
nn.Conv2d(kernel_size=3, in_channels=384, out_channels=384, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(kernel_size=3, in_channels=384, out_channels=256, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2))
self.avgpool = nn.AvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=256, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=self.num_classes))
self._init_bias()
def _init_bias(self):
for layer in self.layers:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01)
nn.init.constant_(layer.bias, 0)
nn.init.constant_(self.layers[4].bias, 1)
nn.init.constant_(self.layers[10].bias, 1)
nn.init.constant_(self.layers[12].bias, 1)
nn.init.constant_(self.classifier[1].bias, 1)
nn.init.constant_(self.classifier[4].bias, 1)
nn.init.constant_(self.classifier[6].bias, 1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.layers(x)
x = self.avgpool(x)
x = torch.flatten(x, 1) # 1차원화
x = self.classifier(x)
return x
if __name__ == "__main__":
seed = torch.initial_seed()
print (f'[*] Seed : {seed}')
NUM_EPOCHS = 1000 # 90
BATCH_SIZE = 128
NUM_CLASSES = 1000
LEARNING_RATE = 0.01
IMAGE_SIZE = 227
TRAIN_IMG_DIR = "C:/github/paper-implementation/data/ILSVRC2012_img_train/"
#VALID_IMG_DIR = "<INPUT VALID IMAGE DIR>"
CHECKPOINT_PATH = "./checkpoint/"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print (f'[*] Device : {device}')
alexnet = AlexNet(num_classes=NUM_CLASSES).cuda()
checkpoints = glob(CHECKPOINT_PATH+'*.pth') # Is there a checkpoint file?
if checkpoints:
checkpoint = torch.load(checkpoints[-1])
alexnet.load_state_dict(checkpoint['model'])
#alexnet = torch.nn.parallel.DataParallel(alexnet, device_ids=[0,]) # for distributed training using multi-gpu
transform = transforms.Compose(
[transforms.CenterCrop(IMAGE_SIZE),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
train_dataset = datasets.ImageFolder(TRAIN_IMG_DIR, transform=transform)
print ('[*] Dataset Created')
train_dataloader = data.DataLoader(
train_dataset,
shuffle=True,
pin_memory=False, # more training speed but more memory
num_workers=8,
drop_last=True,
batch_size=BATCH_SIZE
)
print ('[*] DataLoader Created')
optimizer = torch.optim.SGD(momentum=0.9, weight_decay=5e-4, params=alexnet.parameters(), lr=LEARNING_RATE) # SGD used in original paper
print ('[*] Optimizer Created')
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer, factor=0.1, verbose=True, patience=4) # used if valid error doesn't improve.
print ('[*] Learning Scheduler Created')
steps = 1
for epoch in range(50, NUM_EPOCHS):
logging.info(f" training on epoch {epoch}...")
for batch_idx, (images, classes) in enumerate(train_dataloader):
images, classes = images.cuda(), classes.cuda()
output = alexnet(images)
loss = F.cross_entropy(input=output, target=classes)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if steps % 50 == 0:
with torch.no_grad():
_, preds = torch.max(output, 1)
accuracy = torch.sum(preds == classes)
print ('[*] Epoch: {} \tStep: {}\tLoss: {:.4f} \tAccuracy: {}'.format(epoch+1, steps, loss.item(), accuracy.item() / BATCH_SIZE))
steps = steps + 1
lr_scheduler.step(metrics=loss)
if epoch % 5 == 0:
checkpoint_path = os.path.join(CHECKPOINT_PATH, "model_{}.pth".format(epoch))
state = {
'epoch': epoch,
'optimizer': optimizer.state_dict(),
'model': alexnet.state_dict(),
'seed': seed
}
torch.save(state, checkpoint_path)
AlexNet의 경우 비교적 구현이 어렵지 않은 편이기에 논문 구현을 연습하기에 좋다고 느낀다.
링크드 리스트란 데이터와 포인터를 담은 노드를 연결시킨, 연결 자료구조다. 다음 노드만 가리키는 포인터만 있다면 단순 연결 리스트(Single Linked List)라 하고, 다음 노드와 이전 노드를 가리키는 포인터 두 개가 있다면 이중 연결 리스트(Doubly Linked List)라고 한다. 만약 두 링크드 리스트에서 head와 tail이 서로 앞 뒤로 연결되어 있다면 환형 연결 리스트(Circular Linked List)이다.
링크드리스트는 순차 자료구조인 배열과 달리 포인터를 사용하기에 삽입과 삭제가 용이하다. 또한 배열과 달리 크기를 동적으로 조절할 수 있는 것도 장점이다. 반면 링크드 리스트는 특정 노드를 바로 접근할 수 없는 것이 단점이다. 링크드 리스트를 전부를 탐색해야 할 수 있도 있다. 따라서 링크드 리스트와 배열은 경우에 따라 나누어 사용해야 한다. 데이터가 빈번히 추가되거나 삭제될 경우 링크드리스트를 쓰는 것이 적합하고, 데이터 탐색과 정렬이 위주라면 배열을 쓰는 것이 적합하다. 참고로 윈도우 작업 관리자가 대표적인 링크드 리스트를 사용한 구현물이다. 하나의 프로세스는 앞 뒤로 다른 프로세스들과 연결되어 있는 Circular Linked List 구조로 되어 있다. 첫 번째 프로세스부터 다음 포인터를 계속 탐색하면 모든 프로세스 리스트를 가져올 수 있다.
단순 연결 리스트의 경우 기능은 크게 삽입/삭제/조회/탐색으로 구성된다. 이를 구현하기 위해 노드에 정보를 담을 Node 클래스와 기능을 구현할 SinglyLinkedList 클래스가 필요하다. 구현물은 다음과 같다.
class Node:
def __init__(self, data, next = None) -> None:
self.data = data
self.next = next
class SinglyLinkedList:
def __init__(self) -> None:
self.head = None
self.size = 0
def size(self):
return self.size
def is_empty(self):
return self.size == 0
def insert_front(self, data):
if self.is_empty():
self.head = Node(data, None)
else:
self.head = Node(data, self.head)
self.size += 1
def insert_back(self, data, current):
current.next = Node(data, current.next)
self.size += 1
def delete_front(self):
if self.is_empty():
raise LookupError("There is no node in the linked list")
self.head = self.head.next
self.size -= 1
def delete_back(self, current):
if self.is_empty():
raise LookupError("There is no node in the linked list")
temp = current.next
current.next = temp.next
self.size -= 1
def traverse(self):
array = []
current = self.head
while current:
array.append(current.data)
current = current.next
return array
def search(self, target):
current = self.head
for i in range(self.size):
if current.data == target:
return i
current = current.next
return None
def print_list(self):
current = self.head
while current:
if current.next != None:
print (current.data, '→ ', end='')
else:
print (current.data)
current = current.next
if __name__ == "__main__":
S = SinglyLinkedList()
# Insert
S.insert_front('apple')
S.insert_front('bear')
S.insert_front('cat')
S.insert_back('dog', S.head.next)
S.insert_front('egg')
S.insert_front('fish')
# Search
S.print_list() # fish → egg → cat → bear → dog → apple
print(f"Index: {S.search('dog')}") # Index: 4
# Delete
S.delete_front()
S.print_list() # egg → cat → bear → dog → apple
S.delete_back(S.head)
S.print_list() # egg → bear → dog → apple
# Traverse
print (S.traverse()) # ['egg', 'bear', 'dog', 'apple']
더블 링크드 리스트 또한 구현을 위해 노드에 정보를 담을 Node 클래스와 기능을 구현할 SinglyLinkedList 클래스가 필요하다. 구현물은 다음과 같다.
class Node:
def __init__(self, data=None, prev=None, next=None):
self.data = data
self.prev = prev
self.next = next
class DoublyLinkedList:
def __init__(self):
self.head = Node()
self.tail = Node(prev=self.head)
self.head.next = self.tail
self.size = 0
def size(self):
return self.size
def is_empty(self):
return self.size == 0
def insert_front(self, current, data):
temp = current.prev
next = Node(data, temp, current)
current.prev = next
temp.next = next
self.size += 1
def insert_back(self, current, data):
temp = current.next
next = Node(data, current, temp)
temp.prev = next
current.next = next
self.size += 1
def delete(self, current):
front = current.prev
back = current.next
front.next = back
front.prev = back
self.size -= 1
return current.data
def print_list(self):
if self.is_empty():
raise LookupError('There is no node in the linked list')
else:
current = self.head.next
while current != self.tail:
if current.next != self.tail:
print(current.data, '←→ ', end='')
else:
print(current.data)
current = current.next
D = DoublyLinkedList()
D.insert_back(D.head, 'apple')
D.insert_front(D.tail, 'bear')
D.insert_front(D.tail, 'cat')
D.insert_back(D.head.next, 'dog')
D.print_list() # apple ←→ dog ←→ bear ←→ cat
D.delete(D.tail.prev)
D.print_list() # apple ←→ dog ←→ bear
D.insert_front(D.tail.prev, 'fish') # apple ←→ dog ←→ bear ←→ fish ←→ cat
D.print_list()
D.delete(D.head.next) # dog ←→ bear ←→ fish ←→ cat
D.print_list()
D.delete(D.tail.prev) # dog ←→ bear ←→ fish
D.print_list()
연기론이란 싯다르타가 설파하고자 했던 핵심 수행법이자 가르침이다. 먼저 연기론에서의 연기란 한 마디로 상호의존성이다. 이것이 있기에 저것이 있고 저것이 있기에 이것이 있으므로 상호의존한다는 의미한다. 즉 세상의 존재라고 부르는 것은 독립적으로 존재할 수 없고 상호의존적으로 존재하는 것이다. 다르게 말하면 원인이 있기에 결과가 있고 결과가 있기에 원인이 있다. 그리고 원인과 결과는 둘이 아닌 하나이다 라고도 표현하며, 인식자가 있기에 인식대상이 있고 인식대상이 있기에 인식자가 있다고도 표현한다. 결국 존재의 상호의존성을 말한다. 사물들은 결코 본래 홀로 존재한 것이 아니라 다른 것들에 의해 생겨났다. 이를 연기된 존재라고 말하며 실재가 아닌 환영과 같은 존재이다. 존재하지만 존재하지 않는 것이다. 이렇듯 존재의 실상이 무엇인지 깨달을 수 있도록 한 내용이 연기론이다.
깨달음이란?
깨달음이란 나와 나를 둘러싼 세상이란 존재가 무엇인지를 깨닫는 것이다. 즉 존재의 실체가 무엇인지 아는 것이다. 이를 깨닫게 되면 반야(般若)의 지혜를 얻게 된다. 또 깨달음이란 스스로 주인임을 아는 것이다. 그러므로 그 무엇도 숭배대상이 되지 않는다. 만약 숭배하게 되면 깨달음을 향한 수행은 어려워진다. 숭배는 필연적으로 숭배 대상의 존재 하중을 느끼게 되며 종속적인 위치에 놓이고 또 굴종을 낳기 때문이다.
깨달음을 얻기 위한 두 가지 수행 방법
깨달음 즉, 반야의 지혜를 얻기 위해서 크게 두 가지 수행 방법이 있다. 첫 번째는 연기법을 통한 수행 방법이 있고 두 번째는 선불교에서 행하는 명상과 같은 심법이 있다. 첫 번째로 연기법은 개체의 생멸 과정을 보는 사유 방식이다. 이러한 생멸 과정을 통해 모든 존재가 무아(無我)임을 깨닫는 것이 연기론 수행의 목표다. 여기서 무아란 존재 없음, 내가 없음으로 오인되기도 한다. 하지만 무아란 정확히는 모든 존재에는 그 존재라고 불릴만한 성질, 자성이 없음을 말한다. 나라는 존재에 나일 수 있도록 하는 그 무엇도 없다는 것이다. 즉 연기법이란 이 세상의 모든 존재에 존재성이 없음을 보는 사유 방식이다.
가령 자동차를 볼 때 그 자동차는 자동차일 수 있도록 하는 것이 없다. 바퀴가 없다면 자동차라 할 수 있는가? 페달이 없다면 자동차라 할 수 있는가? 엔진이 없다면 자동차라할 수 있는가? 자동차란 바퀴, 페달, 엔진 등의 여러 수 많은 요소들이 의존적으로 모여 자동차로 불리우지 자동차는 본디 자동차라 할 수 있는 그 어떤 것도 없는 것이다. 이러한 연기론적 사유 방식을 통해 거듭 세상을 바라보다 보면 세상의 공(空)성을, 즉 모든 존재가 무아임을 깨달을 수 있다. 반야 지혜를 얻게 되는 것이다. 반야 지혜 얻어야만 색 그대로 공, 공 그대로 색을 깨닫고 번뇌 그대로 보리 보리 그대로 번뇌임을 깨닫고 살아갈 수 있다.
즉, 있는 그대로 볼 수 있게 되는 것으로 존재가 어떻게 생겨나고 소멸되는지 전면적으로 관찰할 수 있게 된다. 이렇게 되면 한 알의 모래에서도 우주를 볼 수 있게 되는 것이다. 일진법계(一眞法界)를 깨닫는 것이다. 이렇게 존재의 생멸을 관하게 되면 모든 것은 끊임없이 원인과 조건으로 말미암아 생겼다 사라지는 환영과 같음을 알게 된다. 싯다르타는 이러한 연기법적 사유를 통해 깨달음을 얻었다. 연기법적 사유는 지극히 이성적이며 누구나 납득할 수 있는 방식으로 시작하면서도 이성적인 사고의 틀을 넘어서게 한다.
두 번째로 선 불교의 수행 방식인 심법이 있다. 심법을 통한 목표는 모든 존재가 진아(眞我)임을 깨닫는 것이다. 진아란 생각을 일으키는 주체라 할 수 있다. 사실 궁극적으로 깨달아야 할 것은 연기법을 통해 깨닫는 무아와, 심법을 통해 깨닫는 진아가 둘이 아닌 하나임을 아는 것이다. 심법은 연기법과 달리 문자를 통하지 않고 진아를 직접적으로 드러내 단 번에 깨닫는 방식으로 위빠사나나 사마띠와 같은 명상을 통해 수행하는 방식이다.
이러한 심법의 배경에는 불교 교리인 불립문자가 있다. 문자가 가지고 있는 형식과 틀에 집착하거나 빠지지 않도록 경계하는 것을 말한다. 하지만 문자를 활용하지 않는다고 오해하여 쉽게 깨달을 수 있다고 생각하는 자도 있다. 하지만 불립문자는 충분한 문자 공부가 선행됨을 전제한다. 그렇지 않고 단번에 깨달을 수 있다는 말에 현혹되면 평생 고생만 하게 된다. 또한 충분한 문자 공부가 선행되지 않으면 깨달음 이후 삶에서의 지적 활동이 단절될 수 있다. 싯다르타는 선 수행을 통한 심법만으로 깨달으려 노력했지만 포기했다. 선 수행을 통한 선정 상태에서는 아무런 문제가 없지만 현재의 의식으로 돌아왔을 때 여전히 오온이 취착했기에 수행 상태와의 괴리감이 느껴졌기 때문이다.
연기법과 심법
연기법은 주로 현상적 존재에 맞춘 가르침을 펼칠 때 설하는 방식이며 심법은 주로 현상적 존재의 근원에 대한 가르침을 펼칠 때 사용하는 방식이다. 현상적 존재들 상호 간의 상즉상입으로 보는 방식이 연기법이라면 현상적 존재의 근원을 밝혀서, 현상적 존재는 근원이 형상화된 것이라 보는 방식이 심법이다. 쉽게 말해 연기법은 생각하는 방법으로, 심법은 생각을 배재한 직관으로 깨달음을 얻는 방식이다. 존재가 어떻게 생겨났는가를 관하면 연기법을 깨치게 되고, 존재의 근원이 무엇인가를 관하면 마음을 깨치게 된다. 연기법은 주로 사유형 인간에게 적합하며 심법은 직관형 인간에게 적합하다. 사람마다 성향에 맞는 수행법을 선택하면 된다. 심법을 통해 진아를 깨닫는 것은 연기법을 통해 무아를 깨달아야만 보다 선명해진다. 즉 중요한 것은 두 방법 모두 함께해야 효과적이란 것이다. 연기법을 통해 존재가 무아임을 알고 이해수준에 머물 것이 아니라 심법을 통해 이해수준에서 증득수준으로 넘어가야 한다.
삶의 통찰을 배울 수 있는 책이다. 진리나 삶에 대한 사상을 간결하고 날카롭게 표현한 경구나 명언을 엮은 형식으로 구성되어 있다. 이 책은 책을 좋아하기 이전 스무살쯤 샀었다. 당시엔 읽을 땐 아무런 감흥이 없었으나 5~6년 이후인 지금은 이해하고 절실히 느끼는 바가 전과는 달라짐을 느낀다. 아마 몇 년이 지난 이후 다시 읽으면 또 다르게 다가올 것 같다. 매일 일기를 적으며 하루 있던 일로부터 삶의 통찰을 도출해오고 있다. 그러나 홀로 도출해내는 통찰의 양이 한계가 있고, 일반화 가능 여부가 모호 했고, 다각도적인 측면을 고려하기 어렵다고 느꼈다. 하지만 이 책을 읽음으로써 이러한 부족한 부분을 보완할 수 있었다. 곧 바로 이런 책을 읽어야 겠단 생각과 결단을 하지 못했던 것을 반성한다.
책 속에는 많은 삶의 통찰이 있었다. 가치관의 존속을 위해 모든 것을 받아들일 수 없기에 내가 가진 가치의 벡터와 비슷한 방향을 가진 경구를 밑줄 그으며 보았다. 많은 부분은 나의 가치와 다른 부분이 있었고, 철학적인 사색의 결과물이지만 실용성 측면에서는 큰 의미를 갖지 못하는 것도 있었다. 아래 경구 모음은 밑줄 그었던 문장 중에서도 앞으로도 되새기고 싶은 가치이다.
1. 인간이 지향해야 할 최고의 가치들!
소년기의 이상주의는 진리를 인식하는 것이며, 그것은 이 세상 어떤 것도 대신할 수 없는 부를 지니고 있다. - 슈바이처
우리의 지혜가 깊으면 깊을수록 우리는 더욱 관대해진다. - 스탈 부인
사람이 거짓말을 하고 난 뒤에는 뛰어난 기억력이 필요하다. - 코르네유
정직한 사람은 타인에게 모욕을 주는 결과를 초래하더라도 진실을 말하며, 잘난 척 하는 사람은 모욕을 주기 위해서 진실을 말한다. - 헤즐릿
악은 필요하다. 만약 악이 존재하지 않는다면 선 역시 존재하지 않는다. 악이야말로 선의 유일한 존재이다. - 아나톨 프랑스
복수할 때 인간은 그 원수와 같은 수준이 된다. 그러나 용서할 때는 그 원수의 위에 서 있다. - 베이컨
사람의 선과 악은 그 사람의 마음 안에 있다. - 에픽테토스
모든 사람을 좋게 말하는 인간을 신뢰하지 말라. - 콜린스
위대한 것은 단순하게 말해야 효과가 있고, 강조를 하면 망치고 만다. 그러나 사소한 것은 표현과 어조를 고상하게 해야 한다. - 라 브뤼에르
우리는 현명해지기 위해서 먼저 어리석은 사람이 되어야 한다. 스스로를 이끌기 위해서는 먼저 장님이 되어야 한다. - 몽테뉴
긴 세월 동안 인간성에 대해 연구를 해본 결과, 우수한 사람과 평범한 사람의 차이는, 하나의 특징 유무로 결정된다는 사실을 확인하였다. 그것은 '호기심'이었다. 우수한 사람들은 대부분 많은 호기심을 가지고 있었으나 평범한 사람은 이것이 거의 없었다. - 찰스 부토
자기를 높이 평가해주는 사람을 거스를 수 있는 사람은 거의 없다. - 워싱턴
격렬한 말은 그 의미가 빈약하다는 것을 증명하는 것이다. - 위고
받은 상처는 모래에 기록하라. 받은 은혜는 대리석에 새겨라 - 프랭클린
오래 산 사람은 나이를 많이 먹은 사람이 아니고 많은 경험을 한 사람이다. - 루소
다른 사람을 믿지 못하는 사람은 그 자신이 신용을 못 받는다는 것을 알고 있다는 증거이다. - 아웨르바흐
2. 성공과 실패의 모든 것!
사람의 처세법에 있어서 가장 중요한 것은, 정(情)과 이치에도 쏠리지 말아야 하며, 동시에 두 가지를 모두 억제할 줄 알아야 한다. - 나폴레옹
우리가 성공하기 위해서는 겉으로는 어리석은 것처럼 보이면서 속으로 영리해야 한다. -몽테스키외
최상의 성공은 실망 뒤에 온다. - F. 비처
자신감은 최고의 성공 비결이다. - 토마스 에디슨
자신의 마음을 감추지 못하는 사람은 어떠한 일에도 성공하지 못한다. - 칼라일
돈을 빌리러 가는 것은 자유를 팔러 가는 것이다. - 프랭클린
지혜를 얻기 전에 돈을 쥐게 된 사람은 돈주인 노릇을 잠깐밖에 하지 못한다. - T. 플러
못난 사람도 돈만 있으면 잘나 보인다. - 서양 속담
절약은 돈지갑의 밑바닥이 드러났을 때는 이미 늦다. - 세네카
'이 일이 정말 필요한 일인가'하고 의심하는 마음이 없을 때 비로소 기쁨을 느낄 수 있다. - 톨스토이
쉽게 허락한 것은 반드시 신뢰성이 의심스럽고, 쉽게 일을 시작하면 반드시 어려움이 따른다. - 노자
인간은 늘 자신이 종사하고 있는 업무 속에서 세계관의 기초를 구축해야만 한다. - 페스탈로치
세상에 천한 직업은 없으며 다만 천한 사람이 있을 뿐이다. - 링컨
세상에 천한 직업은 없다. 다만 그것을 천하다고 여기는 천한 사람이 있을 뿐이다. - 나
남의 은혜를 망각한다면 벌써 인간으로서의 약점을 지니고 있다는 증거이다. 따라서 유능한 사람이 남의 은혜를 잊었다는 예는 어디에도 없다. - 괴테
남에게 예리하게 상처를 주고 싶거든, 그의 이기심을 겨누어서 치면 된다. - L. 윌리스
얼마나 많은 사람이 명성에 의해 칭송을 받은 후에 망각 속에 묻혀버렸던가? 그리고 타인의 명성을 찬양했던 사람들도 결국은 죽었다. - 아우렐리우스
적이 나보다 약하다고 해서 결코 동정해서는 안 된다. - 사드
우리의 진정한 적은 언제나 침묵하고 있다. - 발레리
가난하더라도 깨끗이 집안을 청소하고, 깨끗이 머릴르 손질하면 자연히 기품이 나타나게 마련이다. - 채근담
빈곤을 수치스럽다고 여기는 것은 부끄러운 일이다. 그러나 자신이 극복하기 위해 노력하지 않는 것은 더 부끄러운 일이다. - 투키디데스
이름이 무슨 소용인가, 장미꽃은 다른 이름으로 불려도 같은 향기가 나는걸. - 셰익스피어
강한 인간이 되고 싶다면 물과 같아야 한다. - 노자
정말로 바쁜 사람은 자기의 몸무게가 얼마나 되는지 모른다. - 하우
3. 시간
인간은 항상 시간이 모자란다고 불평을 하면서, 실제로는 마치 시간이 무한정 있는 것 처럼 행동한다. - 세네카
시간 엄수는 군주의 예절이다. - 루이 18세
내가 헛되이 보낸 오늘 하루는 어제 죽어간 이들이 그토록 바라던 하루이다. - 소포 클레스
승자는 시간을 관리하며 살고, 패자는 시간에 끌려 산다. - J. 하비스
시간을 지키고 안 지킴에 따라 사람의 품위가 결정된다. - 브하그완
현재는 과거의 제자다. - 프랭클린
청년이 청년을 인도하는 것은 맹인이 맹인을 인도하는 것과 같다. 그들은 머지않아 도랑에 같이 빠질 것이다. - 체스터필드
우리는 젊었을 때 배우고, 나이 먹어서 이해한다. - 에센바흐
세상에서 젊음처럼 귀중한 것은 없다. 젊은은 마치 돈과 같다. 돈과 젊음은 모든 것을 가능하게 한다. - 고리키
노년의 결핍을 보충할 수 있는 것을 젊을 때 익혀둬라. 만약 노년의 식량이 지혜란 것을 이해한다면 영양실조에 걸리지 않도록 젊을 때 공부해라. - 다빈치
4. 인간 정신의 최고의 자양분, 예술!
시의 한 가지 장점을 부정할 사람은 없을 것이다. 즉 그것은 산문보다 적은 말로써 더 많은 것을 표현한다는 것이다. - 볼테르
책을 백 번 읽으면 그 뜻이 저절로 통한다. - 위략
대화할 때는 그 얼굴이나 용맹함이나 조상이나 문벌을 가지고 이야기할 것이 아니다. 독서한 내용을 가지고 이야기해야 한다. - 공자
누구에게나 정신적으로 하나의 기원(紀元)을 만들어주는 책이 있다. - 파브르
독서는 다만 지식의 재료를 공급할 뿐이며, 그것을 자기 것이 되게 하는 것은 사색의 힘이다. - 존 로크
어떤 책은 맛만 봐도 되고, 어떤 책은 통째로 삼켜야 하며, 또 어떤 책은 씹어서 소화시켜야 할 것이 있다. - 베이컨
생각하지 않고 책을 읽는 것은 제대로 씹지 않고 음식물을 삼키는 것과 같다. - 바이크
보기 드문 지식인을 만났을 때는 그가 무슨 책을 읽는가를 물어보아야 한다. - 에머슨
독서에 소비한 만큼의 시간을 생각하는 데 소비하라. - 베넷
아무리 어려운 글이라도 일백 번 정 도 되풀이하여 읽으면 그 참뜻을 스스로 깨우쳐 알게 된다. - 주차훈학육기
우선 제1급의 책을 읽어라. 그러지 않으면 그것을 읽을 기회를 전혀 갖지 못하게 될지도 모른다. - 도로
사귀는 벗을 보면 그 사람을 알 수 있듯이 읽는 책을 보면 그 사람의 품격을 알 수 있다. - 스마일스
큰 도서관은 인류의 일기장과 같다. - G. 도슨
만 권의 책을 읽으면 신의 경지에 이른다. - 소식
내가 인생을 알게 된 것은 사람과 접촉해서가 아니라 책과 접촉하였기 때문이다. - A. 프랜스
잡서의 난독은 일시적으로는 다소 이익을 가져다줄지 모르지만, 궁극적으로는 시간과 정력의 낭비로 돌아간다. - E.S. 마틴
독서는 천천히 해야 하는 것이 첫번째 법칙이다. 이것은 모든 독서에 해당한다. 이것이야말로 독서의 기술이다. - E. 파게
자기 스스로 사물에 대해 생각하지 않는 자는 결국 다른 사람의 사상에 예속된다. (생략) 그러므로 그대 자신의 머리로 생각하라. - 톨스토이
항상 깊이 생각하라. 그리고 무엇보다도 당신의 사상을 풍부히하라. (생략) 현실이란 곧 사상의 그림자에 불과하다. - 칼라일
모든 책은 우리에게 지식의 자료를 줄 뿐이며, 진정 나 자신의 것은 나의 생각과 실천의 힘뿐이다. - 로크
현명한 사람은 어리석은 자가 현명한 사람에게 배우는 것보다 어리석은 자에게서 더 많이 배운다. - 카토
언어의 고전적 순수성이라는 문제를 너무 중시할 필요는 없다. 믿음직한 천재는 그 시대의 언어, 이미지, 사상 가운데 똑바로 뛰어들어서 빈틈없는 제빵공처럼 그것을 반죽해야 한다. - 로맹 롤랑
5. 인생에 주어진 진정한 보성, 우정
제 아무리 친한 친구라 할지라도 자신의 생각을 전부 말로 해버리면 평생토록 적이 될 수 있다. - 샤를 뒤클로
우정을 위한 최대의 노력은 벗에게 그의 결점을 스스로 깨닫게 하는 일이다. - 라 로셰호크
옳은 일을 권하는 것이 친구의 도리이다. - 맹자
진정한 친구란 서로의 약점을 포용해주어야 한다. - 셰익스피어
벗을 사귈 때는 그 사람의 장점만을 취하고 단점은 취하지 말라! 이렇게 하면 오래도록 사귈 수 있다. - 공자
우정에 있어서 최상의 노력은 친구가 자신의 결점을 우리에게 보여주게끔 만드는 일이다. - 라 로슈푸코
친구란 모든 것을 알고 있으면서도 사랑해주는 사람을 말한다. - 앨버트 하버드
우정은 사랑을 받는 데에 그 의미가 있는 것이 아니라 사랑을 주는 데에 있다. - 루소
어떠한 충언을 하건 말이 길어서는 안 된다. - 호라티우스
6. 우리의 일상을 지배하는 달콤한 환상!
우리들이 연애에 대해서 이야기를 하게 되면 곧 한가지 문제에 부딪힌다. 즉 사람은 무엇을 사랑하느냐 하는 것이다. 이에 대한 유일한 답은, '사람은 사랑할 가치가 있는 것을 사랑한다'는 것이다 - 키에르케고르
사랑을 받는 것, 그것은 행복이 아니다. 사랑하는 것, 그것이야 말로 진정한 행복이다 - 헤세
사랑의 본질은 개인을 보편화하는 것이다. - 콩트
사랑은 연령과 상관이 없다. 사랑은 어느 때든지 할 수 있다. - 파스칼
인간은 사랑에 의해 살아가고 있다. 그것은 자기 자신의 시작이다. 신과 인류에 대한 사랑은 삶의 시작이다. - 톨스토이
7. 결혼의 실체 & 고달픈 인생의 안식처, 가정!
타인이 좋아할 여자를 아내로 맞지 말고 자신의 취향에 맞는 여성을 아내로 맞아라. - 니체
결혼을 하십시오. 그러면 당신을 후회하게 될 것입니다. 결혼을 하지 마십시오. 그래도 당신을 후회하게 될 것입니다. - 키에르케고르
성공적인 결혼은 적당한 짝을 찾는 데 있기보다는 적당한 짝이 되어주는 데 있다. - 텐드우드
결혼은 발열로 시작해서 오한으로 끝난다. - 리히텐베르크
인간적인 사랑의 최고의 목적은 종교적인 사랑의 경우와 마찬가지로 사랑하는 사람과 하나가 되는 일이다. - 보부아르
서둘러서 한 결혼이 순조로운 경우는 매우 드물다. - 셰익스피어
결혼은 지혜로운 사람이나 어리석은 사람이나 모두 한 번씩 동경과 후회를 경험하는 기본 코스이다. - 서양 속담
교양이 있는 사람일수록 타인을 한 번보고 자신의 취향에 맞는지 구분하는 것은 쉽지 않음을 알 수 있다. - 체스터필드
결혼하기 전에 상대와의 결합을 열 번, 백 번도 더 생각해보는 것이 좋다. 단순한 성적 교섭으로 자신의 인생과 타인의 전 인생을 결합한다는 것은 매우 어리석은 일이기 때문이다. - 톨스토이
남자는 결혼해서 여자의 지혜로움을 알고, 여자는 결혼해서 남자의 어리석음을 안다. - 히세가와 조세칸
국가의 기본은 한 가정에 있다. 모든 가정이 제 역할을 잘 하면 국가는 바로 설 수 있다. - 대학
부모 앞에서는 결코 늙었다는 말을 해서는 안 된다. - 소학
자녀에게 침묵하는 것을 가르쳐라. 말하는 것은 너무나 쉽게 배울 수 있다. - B. 프랭클린
어진 남편은 그 아내를 귀하게 만들고, 악한 남편은 그 아내를 천하게 만든다. - 명심보감
8. 우리의 삶을 가장 인간답게 만드는 것
깍듯한 예절로 크게 이겨라. 최후의 승자는 친절한 사람의 것이다. 힘없는 사람, 용기 없는 사람은 다만 친절을 가장할 뿐이다. - 중국 격언
겸손도 정도를 넘으면 교만이 된다. - 영국 격언
남에게 친절함으로써 그 사람에게 준 유쾌함은 곧 나에게 돌아온다. 뿐만 아니라 때로는 이자를 가져오기도 한다. - 스미스
누구든지 자기를 높이는 자는 낮아지고, 자기를 낮추는 자는 높아지리라. - 신약성서
인간은 타인을 칭찬함으로써 자기가 낮아지는 것이 아니다. 그렇게 함으로써 오히려 자기를 상대방과 같은 위치에 올려놓는 것이다. - 괴테
겸손은 가장 얻기 어려운 미덕이다. 반면에 자기 자신을 높이 평가하는 것보다 더 어리석은 것은 없다. - T. S. 엘리엇
대화는 항상 겸손하고 부드럽게 하라. 그리고 부탁하건대 말수를 줄여라. 그러나 말을 할 때는 요령 있게 하라. - W. 존슨
우쭐대거나 뽐내지 않는 사람은 자기 자신이 믿고 있는 것보다 훨씬 큰 인물이다. - 괴테
말하는 사람은 씨를 뿌리고, 침묵하는 사람은 거두어들인다. - J. 레이
가장 무서운 자는 침묵을 지키는 자이다. - 호라티우스
사람의 인격은 항상 그 사람의 언어에서 드러난다. - 메난드로스
우리가 말을 할 때는 말하는 이유가 필요하지만 침묵을 지킬 때는 침묵해야 할 이유가 필요 없다. - P. 니콜
바른 말은 듣기에는 좋지 않은 법이다. - 한비자
훌륭한 사람일수록 말수가 적은 법이다. - 헤세
후회하지 않는 방법, 그것은 바로 침묵을 지키는 것이다. - 중국 격언
사람은 침묵하고 있어서는 안 될 경우에만 말해야 한다. 그리고 자신이 극복해온 일에 대해서만 말을 해야 한다. 그 이외의 것은 모두 쓸데없는 것들이다. - 니체
주의 깊게 듣고 현명하게 질문하고 조용히 대답하고, 그리고 더 이상 말이 필요 없을 때에 입을 열지 않는 사람은 인생에서 가장 필요한 의의를 깨달은 사람이다. - 라하테르
타인을 헐뜯거나 비방하고 싶은 마음이 들거든 차라리 침묵을 지켜라, 절대 타인의 욕설을 하지 말라. - 톨스토이
자신이 하는 말을 상대방이 듣게만 할 것이 아니라 이해를 시켜야 한다. 즉 말에는 기억력과 지성과 상상력이 자연스럽게 조화를 이루어야 한다. - 주베르
좋은 웅변은 필요한 것을 전부 말하지 않고, 필요하지 않은 것은 절대로 말하지 않는 데 있다. - 라 로슈푸코
마땅히 말해야 할 때에 말을 하지 못하는 사람은 전진할 수 없는 사람이다. 그 대신 침묵해야 할 때 그것을 참지 못하는 사람은 처세의 비결을 모르는 사람이다. - 스마일스
마음에 없는 이야기를 하기보다는 말을 하지 않는 것이 오히려 사교성에 도움을 준다. - 지눌
말이 많은 사람의 말 중에는 어리석은 말도 많이 섞여 있다. - 코르네유
친구와 교제하면서 자신의 이야기를 하는 편이 혼자서 자기 자신의 정신을 연구하는 것보다 더 많은 것을 정신에서 끄집어낼 수 있다. - 몽테뉴
필요 이상으로 말을 하지 말라. - R. B. 세리틴
인간의 마음속에는 언제나 선과 악이 대립된 형태로 갈등한다. 이때 현자의 선은 악보다 강하고 우자의 선은 악보다 약하다. 여기에서 사람의 차이가 나타난다.
시기와 질투는 항상 타인을 쏘려다가 자신을 쏜다. - 맹자
타인의 지난날의 행동과 말을 가지고 그의 일평생을 꺾어서 단정하기는 어려운 일이다. - 명심보감
내일을 위해서 오늘 분수를 지키는 것이 지혜로운 사람의 도리이다. - 세르반테스
9. 인간 내면의 다양한 색채들!
삶의 즐거움은 자기보다 어려운 사람들과 함께 어울려 사는 것이다. - 대커리
네가 가는 길의 마지막에는 만족이 있다. 그러나 처음부터 만족하는 사람은 멀리 가지 못한다. - 류카르
어떤 일에 있어서든 가장 오래 기다리는 사람이 반드시 승리한다. - 잭슨
모든 일에 있어서 성공을 결정짓는 첫번째이자 유일한 조건은 인내이다. - 톨스토이
야심은 하늘을 나는 동시에 땅을 길 줄도 안다. - 에드먼드 버크
행복의 원칙은 첫째 어떤 일을 할 것, 둘째 어떤 사람을 사랑할 것, 셋째 어떤 일에 희망을 가질 것. - 칸트