
통계에서 확률변수와 확률분포가 있다. 확률변수는 이산확률변수와 연속확률변수로 나뉘고, 마찬가지로 확률분포도 이산확률분포와 연속확률분포로 나뉜다. 이산의 대표적인 분포는 이항분포가 있고 연속의 대표적인 분포는 정규분포가 있다. 하지만 이외에도 베르누이 분포, 기하분포, 초기하분포, 포아송분포, 균등분포, 지수분포, 카이제곱 분포 등이 있고 총 12가지 분포에 대해 정리하고자 한다. 이러한 확률 분포들이 필요한 핵심 이유는 모수 추정에 있다. 모수 추정에 있어 어떤 확률 분포를 따른다고 가정하면 특정 상황을 잘 표현할 수 있기 때문이다.
간단 용어 정리
표본공간: 사건에서 발생 가능한 모든 결과의 집합
확률변수: 표본공간에서 일정 확률을 갖고 발생하는 사건에 수치를 일대일 대응시키는 함수
확률분포: 흩어진 확률변수를 모아 함수 형태로 만든 것
이산확률변수: 확률변수 개수가 유한해 정수 구간으로 표현되는 확률변수
연속확률변수: 확률변수 개수가 무한해 실수 구간으로 표현되는 확률변수
확률밀도함수: 확률변수의 분포를 나타내는 함수이자 확률변수의 크기를 나타내는 값
이산 확률 분포
1. 베르누이 분포 (Bernoulli distribution)
베르누이 분포는 시행의 결과가 오직 두 가지인 분포를 말한다. 예를 들어 성공/실패나 합격/불합격 또는 앞면/뒷면이 있다. 이를 일반화하면 베르누이 분포는 특정 사건 A가 나타날 확률과 A가 나타나지 않을 확률을 나타낸 분포이다. 일반적으로 확률 변수에 사건 A가 발생할 경우를 1, 발생하지 않을 경우를 0으로 부여한다. 즉 베르누이 분포는 확률변수가 1과 0 두 가지로만 나타내는 확률분포다.
베르누이 시행을 따르는 경우의 예시로는, 동전과 주사위가 있다. 동전이 앞면이 나올 경우와 나오지 않을 경우로 나눌 수 있고, 주사위에서 어떤 수가 나올 확률과 그렇지 않은 경우로 나눌 수 있다. 만약 주사위에서 5가 나올 확률과 그렇지 않은 확률을 구하는 경우라면 베르누이 시행이지만 5,6이 나올 확률과 그렇지 않은 경우를 구하는 것이라면 베르누이 시행이 아니다. 예시를 통해 계산 방법을 알아보자. 상자 안에 흰 공7개와 검은공 3개가 있다고 가정하고 확률변수를 흰공이 나오면 성공(1), 검은공이 나오면 실패(0)로 둘때, 확률변수 값은 $p(1)=0.7, p(0)=0.3$이 된다. 이를 $\displaystyle p(x) = 0.7^x \times 0.3^{1-x}$로 나타낼 수 있고, 이를 일반화 한 식은 다음과 같다.
$\displaystyle p(x) = p^x(1-p)^{1-x}$
이 때 $x=(0, 1)$
다음으로 베르누이 분포에서 평균과 분산을 구하는 과정은 다음과 같다.
$\displaystyle E(x) = \sum xp(x)$
$= 0p(0) + 1p(1)$
$= p(1)$
$= p$
$\displaystyle V(x) = E(x^2) - \{E(x)\}^2$
$\displaystyle = \sum x^2p(x) - p^2$
$= 0p(0) + 1p(1) - p^2$
$= p - p^2$
$= p(1-p)$
$\therefore$ $E(x) = p$, $V(x) = p(1-p)$이다.
2. 이항분포 (Binomial distribution)
이항 분포는 베르누이 시행을 여러번 하는 것이다. 정의를 내리면, 어떤 사건 A가 발생할 확률이 $p$인 베르누이 시행을 $n$번 시행했을 때 사건 A가 발생한 횟수를 확률 변수로하는 분포다. 수식으로는 다음과 같이 나타낸다.
$\displaystyle P(X = r) = {}_nC_r\ p^r(1-p)^{n-r} = {n \choose k}p^r(1-p)^{n-r}$
이 때 $r= (0, 1, 2, \dots, n)$이고 $(p+q = 1)$이다.
만약 주사위를 10번 던져서 숫자 5가 r번 나올 확률을 구한다면 다음과 같다.
만약 주사위 10번 던져서 숫자 5가 한 번 나올 확률: ${}_{10}C{}_1\times({1\over6})^1\times ({5\over 6})^9$
만약 주사위 10번 던져서 숫자 5가 두 번 나올 확률: ${}_{10}C{}_2\times({1\over6})^2\times ({5\over 6})^8$
만약 주사위 10번 던져서 숫자 5가 세 번 나올 확률: ${}_{10}C{}_3\times({1\over6})^3\times ({5\over 6})^7$
만약 주사위 10번 던져서 숫자 5가 r 번 나올 확률: ${}_{10}C{}_r\times({1\over6})^r\times ({5\over 6})^{n-r}$
이러한 사건의 시행으로부터 나오는 확률을 구해 분포도를 그리면 이항분포가 된다. 정확히는 확률변수 X의 확률분포를 이항분포라고 한다. 기호로는 $\displaystyle B(n, p)$와 같이 나타내며 위의 예시로는 $\displaystyle B(10, {1\over6})$이 된다. 만약 $X \sim B(n, p)$일 때 이항분포의 평균과 분산은 각각 $\displaystyle E(x) = np$ 이며 $\displaystyle V(x) = np(1-p)$이다. 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(x) = \sum xp(x)$
$\displaystyle = \sum_{r=0}^n r{n \choose r}p^r (1-p)^{n-r}$
$\displaystyle = \sum_{r=0}^n r{n! \over (n-r)r!} p^r (1-p)^{n-r}$ (이 때 0을 대입하면 값이 0이되니 $r=1$부터 시작해도 되므로)
$\displaystyle = \sum_{r=1}^n r{n! \over (n-r)r!} p^r (1-p)^{n-r}$ (약분을 위해 $r$을 묶어서 한 번 빼주고, $n$과 $p$도 마찬가지로 한 번씩 앞으로 빼주면)
$\displaystyle = \sum_{r=1}^n r {n(n-1)! \over r(r-1)! (n-r)!} p p^{r-1} (1-p)^{n-r}$ (약분해주고 남은 np는 상수이며 앞으로 뺄 수 있으므로)
$\displaystyle = np\sum_{r=1}^n {(n-1)! \over (r-1)!(n-r)!} p^{r-1} (1-p)^{n-r}$ ($n-1 = m$로 치환, $r-1 = x$로 치환하면)
$\displaystyle = np\sum_{r=1}^n {m! \over x!(n-r)!} p^x (1-p)^{n-r}$ (이 때 $n-1 = m - x$이므로 대입해주면)
$\displaystyle = np\sum_{r=1}^n {m! \over x!(m-x)!} p^x (1-p)^{m-x}$
$\displaystyle = np\sum_{x=0}^m {m! \over x!(m-x)!}p^x (1-p)^{m-x}$ (이 때 $np$ 뒤의 형태는 시행횟수 m, 확률 p를 가지는 이항분포이므로 합은 1이 되어 사라지고)
$= np$
$\therefore E(x) = np$
3. 기하분포 (Geometric distribution)
기하분포는 베르누이 시행을 반복할 때 처음으로 알고자 하는 사건 A 관찰에 성공하기 까지의 시도 횟수를 확률변수로 가지는 분포이다. 예를 들어 연애에서 결혼까지 이어질 확률이 10%라면 $x$번째 연애에 결혼하게 되는 것을 $p(x)$라 할 수 있다. 만약 3번째 연애에 결혼한다 가정하면 다음과 같은 계산이 가능하다.
$p(1) = 0.1$
$p(2) = 0.9 \times 0.1$
$p(3) = 0.9 \times 0.9 \times 0.1$
이를 일반화 하면 $\displaystyle p(x) = (1-p)^{x-1} \times p$이 된다. ($x$번째에 성공하므로 $x-1$까지는 실패)
이 기하분포의 통계량 중 평균과 분산은 $X \sim Geo(p)$일 때 $\displaystyle E(x) = {1\over p}, V(x) = {1-p\over p^2}$이다. 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(x) = \sum xp(x) = \sum x(1-p)^{x-1}p = \lim_{n \to \infty} \sum_{x=1}^n x(1-p)^{x-1}p$ (n이 무한히 커질 수 있음. p를 앞으로 꺼내주고 식을 전개하면)
$\displaystyle E(x) = \lim_{n \to \infty} p\{1(1-p)^0 + 2(1-p)^1+3(1-p)^2+ \cdots + (n-1)(1-p)^{n-2}+n(1-p)^{n-1}\}$ (평균값 도출 위해 양변에 (1-p)를 곱하면)
$\displaystyle (1-p)E(x) = \lim_{n \to \infty} p\{(1-p)+2(1-p)^2+3(1-p)^3+\cdots+(n-1)(1-p)^{n-1}+n(1-p)^n\}$ (위 식에서 이 식을 빼면)
$\displaystyle pE(x) = \lim_{n \to \infty} p\{1+(1-p)+(1-p)^2+(1-p)^3+\cdots+(1-p)^{n-1}+(1-p)^n\}$ (첫항1, 공비(1-p), 항수n인 등비수열합이므로)
$\displaystyle E(x) = \lim_{n \to \infty} \{{1(1-(1-p)^n \over1-(1-p)} - n(1-p)^n\}$ (로피탈 정리에 의해 0으로 수렴하는 $(1-p)^n$을 고려하면)
$\displaystyle E(x) = {1\over 1-(1-p)} = {1\over p}$
$\displaystyle \therefore E(x) = {1\over p}$
4. 음이항분포 (Negative binomial distribution)
음이항 분포의 여러 정의 중 하나는 기하 분포를 일반화한 분포다. 정확히는 음이항분포에는 5가지 정의가 존재하고 그 중 하나의 정의가 기하 분포의 일반화에 해당한다. 앞서 기하분포를 설명한 대로, $n$번째 시행에서 처음으로 사건 A 관측에 성공할 확률이다. 수식으론 $\displaystyle p(x) = (1-p)^{x-1} \times p$으로 표현했다. 음이항분포의 한 정의는 $n$번째 시행에서 $k$번째 성공이 나올 확률이다. 즉 $n$번 시행 이전인 $n-1$번의 시행까지 $k-1$개의 성공이 있어야 하며, 마지막 n번째에 한 번 더 성공해야 한다. 이를 수식으로 정의하면 $n-1$에서 $k-1$개가 나올 경우의 수를 고려해야 하므로 $\displaystyle p(x) = {}_{n-1}C_{k-1}p^{k-1}(1-p)^{n-k}p$가 된다.
앞서 언급했듯 음이항분포는 5가지 정의가 존재한다. 이 5가지 정의엔 $n, k, r$이 사용된다. $n$: 전체 시행횟수, $k$: 성공 횟수, $r$: 실패 횟수이다. 이 때 $n = k + r$의 관계가 성립한다. 이 관계식에서 어떤 것을 독립 변수, 종속변수, 상수로 두느냐에 따라 음이항분포의 정의가 나뉜다.
1. $r$이 상수, $k$가 독립변수인 경우: $r$번 실패까지 성공이 $k$번 발생한 확률이다.
2. $r$이 상수, $n$이 독립변수인 경우: $r$번 실패까지 $n$번 시행할 확률이다.
3. $k$가 상수, $r$이 독립변수인 경우: $k$번 성공까지 $r$번 실패할 확률이다.
4. $k$가 상수, $n$이 독립변수인 경우: $n$번 시행에서 $k$번째 성공이 나올 확률이다.
5. $n$이 상수, $k$ 또는 $r$이 독립변수인 경우: $n$번 시행에서 $k$번 성공 또는 $r$번 실패할 확률 (= 기존 이항분포와 동일한 식)
혼동이 있을 수 있지만 결론을 먼저 말하자면 일반적으로 1번 정의를 음이항분포라고 한다. 4번 정의는 기하분포를 일반화한 것이다. 1번 정의에 대한 예시를 들기 포커 게임에서 이길 확률(p) 0.3일 때 5번의 패배가 나오기까지 발생한 승리가 $k$번일 확률 분포 $p(x)$를 구한다고 해보자. 그러면 $r=5, p=0.3$이며 $x=(0, 1, 2, 3, 4, 5)$가 된다.
p(0): 5번 패배할 때까지 0번 이긴 경우다.
(_ _ _ _ 실): 마지막 실패 제외, 모두 실패가 들어간다. 4번 중 4번 패배 + 0번 이길 경우의 수 이므로 ${}_4C_0 (0.7)^4 (0.3)^0 (0.7)$
p(1): 5번 패배할 때까지 1번 이긴 경우다.
(_ _ _ _ _ 실): 마지막 실패 제외, 5번 중 4번 패패 + 1번 이길 경우의 수 이므로 ${}_5C_1 (0.7)^4 (0.3)^1 (0.7)$
p(2): 5번 패배할 때 까지 2번 이긴 경우다.
(_ _ _ _ _ _ 실): 마지막 실패 제외, 6번 중 4번 패배 + 2번 이길 경우의 수이므로 ${}_6C_2 (0.7)^4 (0.3)^2 (0.7)$
p(3): 5번 패배할 때 까지 3번 이긴 경우다.
(_ _ _ _ _ _ _ 실): 마지막 실패 제외, 7번 중 4번 패패 + 3번 이길 경우의 수므로 ${}_7C_3 (0.7)^4 (0.3)^3 (0.7)$
. . . ($k \rightarrow \infty$)
이를 일반화한 수식은 ${}_{x+k-1}C_{x} (1-p)^r p^x$이 된다. 이를 달리 표현하면 $X \sim NB(r, p)$이다. 다른 정의를 사용하고 싶다면 $r$ 자리에 다른 상수를 넣어 사용할 수 있다. 이런 음이항분포의 평균과 분산은 각각 $\displaystyle E(x) = {pr \over 1-p}$와 $\displaystyle V(x) = {pr \over (1-p)^2}$이다. 이 중 평균을 구하는 과정만 기술하자면,
$\displaystyle E(x) = \sum xp(x)$
$\displaystyle = \sum_{x=0}^\infty x {}_{x+r-1}C_x p^x (1-p)^r$ ($x=0$은 0이므로 $x=1$부터여도 무관하며 조합식을 팩토리얼로 풀어주면)
$\displaystyle = \sum_{x=1}^\infty x {(x+r-1)! \over (r-1)!x!} p^x (1-p)^r$ ($x$을 약분하면)
$\displaystyle = \sum_{x=1}^\infty {(x+r-1)! \over (r-1)!(x-1)!} p^x (1-p)^r$ ($p$로 한 번 묶어주면)
$\displaystyle = p \sum_{x=1}^\infty {(x+r-1)! \over (r-1)!(x-1)!} p^{x-1} (1-p)^r$ (분자 분모에 $r$을 곱해주면)
$\displaystyle = p \sum_{x=1}^\infty {r(x+r-1)! \over r(r-1)!(x-1)!} p^{x-1} (1-p)^r$ ($r$을 앞으로 빼주고 팩토리얼을 합해주면)
$\displaystyle = pr \sum_{x=1}^\infty {(x+r-1)! \over r!(x-1)!} p^{x-1} (1-p)^r$ ($x-1 = y$로 치환해주면)
$\displaystyle = pr \sum_{y=0}^\infty {(y+r)! \over r!y!} p^y (1-p)^r$ (조합식으로 변경해주면)
$\displaystyle = pr \sum_{y=0}^\infty {}_{y+r}C_y p^y (1-p)^r$ ($r = k-1$로 치환해주면)
$\displaystyle = pr \sum_{y=0}^\infty {}_{y+k-1}C_y p^y (1-p)^{k-1}$ ($(1-p)^{-1})$으로 묶어주면)
$\displaystyle = {pr \over 1-p} \sum_{y=0}^\infty {}_{y+k-1}C_y p^y (1-p)^k$ (이 때 시그마 안의 식은 음이항분포의 확률분포 함수와 모양이 같으므로 합은 1이 된다.)
$\displaystyle = {pr \over 1-p}$
$\displaystyle \therefore E(x) = {pr \over 1-p}$
어떤 확률변수 $X$가 $NB(r, p)$의 음이항분포를 따를 때 이 확률변수 $X$의 평균은 $\displaystyle {pr \over 1-p}$가 된다.
5. 초기하 분포 (Hypergeometric distribution)
초기하 분포는 아래 그림처럼 크기가 $m$인 모집단에서 크기 $n$인 표본을 추출했을 때 모집단 내 원하는 원소 $k$개 중 표본 내에 $x$개 들어있을 확률 분포를 의미한다.
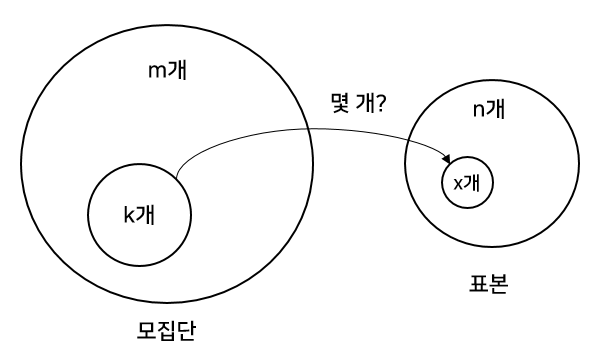
쉬운 비유는 로또가 있다. 로또는 크기 45의 모집단을 가지고, 그 중 원하는 수 $k=6$개이다. 이 때 추출한 표본 6개 중 $k$가 $x$개 들어있을 확률이다. 따라서 $p(0)$는 번호 0개 맞은 경우이며 $p(1)$은 번호 1개가 맞은 경우이고, ..., $p(6)$는 번호 6개가 맞아 1등된 확률을 의미한다.
이러한 초기하 분포식 유도를 위해선 먼저 모집단에서 표본을 추출할 경우의 수를 구해야 한다. 이는 크기 $m$인 모집단에서 크기 $n$인 표본을 뽑을 경우의 수 이므로 ${}_mC_n$이다. 또 원하는 원소가 $k$개 들어있고 크기가 m인 모집단에서, 크기가 $n$인 표본을 뽑을 때 원하는 원소 x개가 들어있을 경우의 수는 ${}_kC_x \times {}_{m-k}C_{n-x}$다. 그 이유는 표본의 $x$이외의 값은 $n-x$개로 나타내며 이는 모집단의 $m-k$개로부터 추출된 것이기 때문이다. 이를 기반으로 전체 경우의수를 나타내면 다음과 같다.
$\displaystyle p(x) = {{}_kCx \times {}_{m-k}C_{n-x} \over {}_mCn}$
여기서 $m, k, n$은 사전에 결정되는 상수이며 $x$는 확률 변수에 해당한다. 이 초기하 분포식을 기반으로 구한 평균과 분산은 각각 $\displaystyle E(x) = {kn \over m}$, $\displaystyle V(x) = n {k\over m}{m-k \over m}{m-n\over m-1}$이다. 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(x) = \sum xp(x)$
$\displaystyle = \sum_{x=0}^\infty {{}_kCx \times {}_{m-k}C_{n-x} \over {}_mCn}$ (이 때 ${}_kCx$를 팩토리얼로 풀어주면)
$\displaystyle = \sum_{x=0}^\infty x{k! \over x!(k-x)!} {{}_{m-k}C_{n-x} \over {}_mC_n}$ (이 때 0을 대입하면 0이므로 x=1부터 시작되어도 무관. x 약분 하고 k를 밖으로 꺼내주면)
$\displaystyle = k\sum_{x=1}^\infty {(k-1)! \over (x-1)!(k-x)!} {{}_{m-k}C_{n-x} \over {}_mC_n}$ (여기서 ${}_mC_n$을 팩토리얼로 전개하면 ${}_mC_n = {m! \over n!(m-n)!} = {m \over n}{(m-1)! \over (n-1)!(m-1)!} = {m\over n}{}_{m-1}C_{n-1}$)
$\displaystyle = k\sum_{x=1}^\infty {(k-1)! \over (x-1)!(k-x)!} {n\over m} {{}_{m-k}C_{n-x} \over {}_{m-1}C_{n-1}}$ (여기서 맨 앞의 식을 조합 형태로 변환)
$\displaystyle = k\sum_{x=1}^\infty {}_{k-1}C_{x-1} {n\over m} {{}_{m-k}C_{n-x} \over {}_{m-1}C_{n-1}}$ (여기서 $n\over m$은 상수이므로 앞으로 빼고 ${}_{m-k}C_{n-x}$를 변형하면)
$\displaystyle = {kn\over m} \sum_{x=1}^\infty {}_{k-1}C_{x-1} {{}_{(m-1)-(k-1)}C_{(n-1)-(x-1)} \over {}_{m-1}C_{n-1}}$ (여기서 $x-1=y$로 치환하면)
$\displaystyle = {kn\over m} \sum_{y=0}^\infty {}_{k-1}C_y {{}_{(m-1)-(k-1)}C_{(n-1)-(y)} \over {}_{m-1}C_{n-1}}$ (시그마 내 식은 크기 $m-1$인 모집단, $n-1$인 표본, 원하는 원소 $k-1$개, 원하는 원소 $y$인 초기하 분포의 모양과 같으므로 시그마 식은 초기하 분포 값을 다 더해주면 1)
$\displaystyle = {kn\over m}$
$\displaystyle \therefore E(x) = {kn \over m}$
6. 포아송 분포 (Poisson distribution)
포아송 분포는 이항 분포에서 유도된 특수한 분포다. 이항 분포에서 시행 횟수 $n$이 무수히 커지고 사건 발생 확률 $p$이 매우 작아질 경우 필요하다. 그 이유는 시행 횟수 $n$이 무한히 커질 때 이항 분포 정의인 $\displaystyle {}_nC_r\ p^r(1-p)^{n-r}$에서 $n!$ 계산이 현실적으로 가능하지 않은 경우가 있기 때문이다.
포아송 분포를 다르게 표현하면 단위 시간이나 단위 공간에서 랜덤하게 발생하는 사건 발생횟수에 적용되는 분포다. 예를 들어 1시간 내에 특정 진도 5이상의 지진 발생 확률에도 적용할 수 있다. 지진은 언제나 발생할 수 있지만 그 발생횟수는 작을 것이며 또 알 수 없다. 또 보험사는 1000건의 보험계약이 있지만 고객이 보험금을 청구 확률은 얼마가 될 지 알 수 없는 것이다.
이러한 경우에 포아송 분포가 사용되며 많은 경우에 적용된다. 포아송 분포에서는 사건발생 횟수와 확률은 알 수 없지만 대신 사건발생 평균횟수는 정의할 수 있다. 그 이유는 이항 분포에서 평균 $E(x) = np$이기 때문이다. 푸아송 분포에서는 $np$를 $\lambda$로 표현한다. ($\lambda = np$)
포아송 분포의 정의는 이항 분포 정의에서 유도되어 $\displaystyle p(x) = {\lambda^x e^{-\lambda} \over x!}$이다. 이를 사용해 포아송 분포의 평균과 분산을 구하면 각각 $E(x) = \lambda$와 $V(x) = \lambda$이다. 이 때 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(x) = \sum_{x=0}^\infty\ xp(x)$ 이므로
$\displaystyle =\sum_{x=0}^\infty x {\lambda^x e^{-\lambda} \over x!}$ (이 때 $x$에 0대입해도 0이므로 1부터 시작 가능)
$\displaystyle =\sum_{x=1}^\infty x {\lambda^x e^{-\lambda} \over x!}$ ($x$ 약분하고, 상수인 $e^{-\lambda}$를 앞으로 빼주고, $\lambda$도 하나 앞으로 빼주면)
$\displaystyle =\lambda e^{-\lambda} \sum_{x=1}^\infty {\lambda^{x-1} \over (x-1)!}$ ($x-1 = n$으로 치환. $x=1$이면 $n=0$이므로)
$\displaystyle =\lambda e^{-\lambda} \sum_{n=0}^\infty {\lambda^{n} \over n!}$ (이 때 시그마 값은 매클로린 급수 정의에 의해 $e^\lambda$. ($\displaystyle f(x) = \sum_{n=0}^\infty {f^{(n)}(0) \over n!} {x}^n$에서 $e^\lambda$대입. $e^x$의 $n$계 도함수는 자기 자신))
$\displaystyle = \lambda e^{-\lambda} e^\lambda$
$\displaystyle = \lambda$
$\displaystyle \therefore E(x) = \lambda$
연속확률분포
7. 균등분포 (Uniform distribution)
균등분포의 정의는 정해진 범위에서 모든 확률변수의 함수값이 동일한 분포이다. 연속확률분포에서 균등분포는 연속균등분포라 불려야 한다. 이산확률분포에서도 균등분포를 정의할 수 있기 때문에 구분이 필요하기 때문이다. 균등분포 함수로 표현하면 다음과 같다.
$\displaystyle f(x)= \begin{cases} {1 \over b-a}, & a\lt x \lt b \\ 0 & {x\lt a, b\lt x} \end{cases}$
확률변수의 범위를 $a\leq x \leq b$라고 하고, 이 확률변수들의 함수 값을 $f(x)$라고 하면 다음과 같은 확률밀도 그래프를 그릴 수 있다. 참고로 어떤 확률변수 $X$가 균등분포를 따른다면 $X~ U(a, b)$로 표현한다.
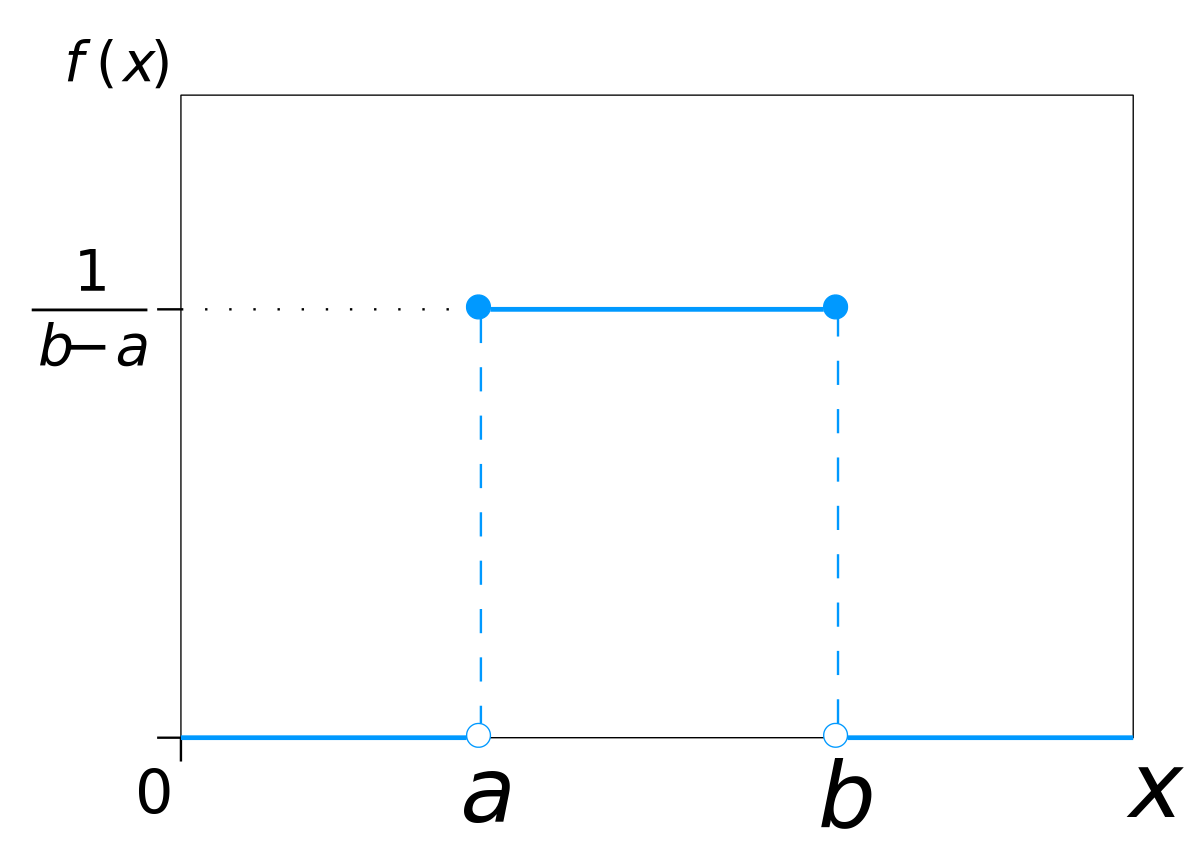
이 때 연속확률변수에서의 확률은 확률밀도로 표현되고 확률밀도는 넓이를 의미한다. 이 때 전체 확률밀도는 1이므로 $(b-a)f(x) = 1$이 된다. 따라서 $f(x) = {1 \over (b-a)}$이다.
균등분포에서 평균과 분산은 각각 $\displaystyle E(x) = {b+a \over 2}$와 $\displaystyle V(x) = {(b-a)^2 \over 12}$이다. 여기서 평균을 나타내는 과정만 기술해보자면, 연속확률변수에서 평균은 $\displaystyle E(x) = \int_{-\infty}^\infty xf(x)dx$이므로
$\displaystyle E(x) = \int_a^b x{1 \over b-a}dx$
$\displaystyle =\left[{1\over b-a} {1\over 2}x^2 \right]_a^b$
$\displaystyle ={b^2-a^2 \over 2(b-a)}$
$\displaystyle = {(b+a)(b-a) \over 2(b-a)}$
$\displaystyle = {b+a \over 2}$
$\displaystyle \therefore E(x) = {b+a \over 2}$
8. 정규분포 (Normal distribution)
정규분포는 대표적인 연속확률분포에 속하며 가우시안 분포라고도 불린다. 정규분포의 확률밀도함수는 아래의 수식으로 나타낸다. (유도과정은 크게 두 가지 방법을 사용하는데 첫 번째론 과녁 맞추기 예시를 통한 유도와 두 번째론 이항분포로부터 유도하는 방법이 있다. 유도과정은 길어지므로 생략하며 고등수학만 활용해도 유도 가능하다.)
$\displaystyle f(x) = {1 \over \sqrt{2\pi \sigma^2}} \exp (-{(x-\mu)^2 \over 2\sigma^2})$
여기서 $\mu$는 평균을 나타내며 $\sigma^2$는 분산(표준편차 제곱)을 뜻한다. 이는 곧 정규분포는 아래 그림과 같이 평균과 분산에 따라 다양한 분포를 가지게 됨을 의미한다. 이 때 정규분포의 가장 높은 함수값을 가지는 확률변수 $X$는 평균이다. 만약 어떤 확률변수 $X$가 평균이 $\mu$고 분산이 $\sigma^2$인 정규분포를 따른다고 하면 기호로 $N(\mu, \sigma^2)$와 같은 형태로도 나타낼 수 있다.

이러한 정규분포에는 몇 가지 특징이 있다. 첫 번째는 정규분포는 확률밀도함수의 한 종류이므로 전체 넓이는 전체 확률을 의미하므로 1이 된다. 두 번째는 정규분포는 평균을 기준으로 대칭성을 띤다. 평균 기준 왼쪽과 오른쪽이 각각 0.5의 확률을 갖는다. 세 번째는 정규분포별 평균과 표준편차가 다르더라도 아래 그림과 같이 표준편차 구간 별 확률은 어느 정규분포에서나 같다는 것이다.
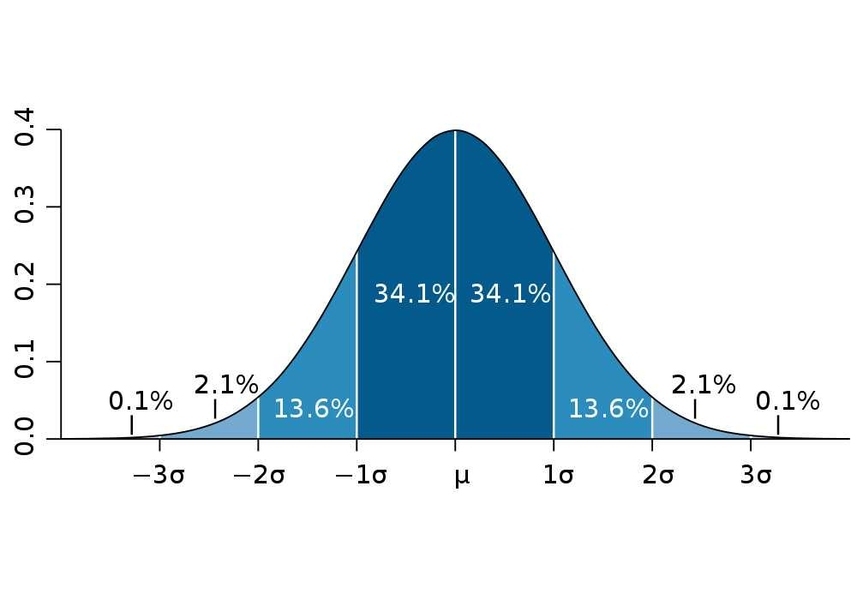
가령 예를 들어 $\displaystyle N(100, 5^2)$의 정규분포와 $\displaystyle N(64, 4^2)$ 정규분포가 두 개가 있을 때, 그 모양이 서로 다르더라도 위 그림과 같이 표준편차($\sigma$)로 나뉘어진 구간의 면적(확률)은 모두 같음을 의미한다.
이런 정규분포는 표준화 과정을 통해 표준 정규 분포(standard normal distribution)를 얻을 수 있다. 표준 정규 분포란 평균이 0 표준편차가 1인 분포를 말한다. 표준화 과정은 $\displaystyle Z = {X - \mu \over \sigma}$으로 이뤄진다. 모든 확률변수에 대해 평균을 뺀 뒤 표준편차로 나눠주는 것이다. $Z \sim N(0, 1)$의 형태로 표현하며 이를 표준정규분포 또는 Z-분포라 부른다.

이런 표준화 과정을 통해 표준정규분포로 만들면 서로 다른 모수 값(평균, 표준편차, 분산 등)을 가진 정규분포를 가진 집단 간의 비교 문제를 해결할 수 있다. 흔히 예를 드는 것으로 수학 시험 점수 비교다. 가령 A, B반의 수학 점수가 정규분포를 따른다 가정할 때 A반: 평균 70, 표준편차 30 / B반: 평균 80, 표준편차 15라면 비교로 성적 우위를 가리기 어렵다. 때문에 표준화를 통해 정규분포를 표준정규분포로 바꿔줌으로써 집단간 비교 문제를 해결할 수 있다.
9. 카이제곱분포 (Chi-square distribution)
카이제곱분포란 표준정규분포에서 파생된 것으로 한 마디로 말하면 표준정규분포의 확률변수를 제곱합한 분포다. 카이제곱 분포는 신뢰구간과 가설검정, 독립성 검정 등에서 자주 사용된다. 먼저 카이제곱분포의 기본적인 형태를 보자. 표준정규분포에서는 평균이 0이고 표준편차가 1이었다. 따라서 평균 0을 기준으로 -와 +가 있지만 카이제곱분포는 확률변수를 제곱하였으므로 +만 존재한다.

카이제곱분포의 형태에서 앞 부분에 확률 변수 값이 큰 이유는 뒤로갈수록 정규분포의 양끝과 같은 편향이 상대적으로 적어지기 때문이다. 이 카이제곱 분포를 조금 더 덧붙여 설명하면, $k$개의 서로 독립적인 표준정규분포의 확률변수를 각각 제곱한 후 더하여 얻는 분포다. 이 때 $k$는 표준정규분포를 따르는 확률변수의 개수로 카이제곱 분포의 형태를 결정하는 자유도로서 역할을 한다. 이 $k$에 따라 카이제곱 분포의 형태가 아래와 같이 달라진다. 자유도의 크기가 증가할수록 점점 대칭성을 갖게 되며 통상 $k=30$이상이면 거의 정규분포에 가까워진다고 한다.

이러한 카이제곱분포의 수식은 $\displaystyle f(x|k) = {1 \over 2^{k\over 2}\gamma ({k\over 2})} x^{{k\over 2}-1}e^{-{x\over 2}}$로 표기한다. 카이제곱분포의 평균과 분산은 각각 $E(x) = k$, $V(x) = 2k$이다. 이 중 카이제곱분포 수식을 통해 평균을 구하는 과정만 기술해보자면, (확률변수 $X$가 $k$ 자유도를 갖는 카이제곱분포를 따른다고 가정)
$\displaystyle E(x) = \int_0^\infty xf(x)dx$ (적분구간은 0부터 시작함 카이제곱분포는 표준정규분포의 확률분포를 제곱한 것이므로)
$\displaystyle =\int_0^\infty x{1\over 2^{k\over2} \gamma({k\over 2})} e^{-{x\over 2}} x^{{k\over 2}-1}dx$ (이 때 $x*x^{-1} = 1$이 되고, 상수를 앞으로 빼주면)
$\displaystyle ={1 \over {2^{k\over 2} \gamma({k\over 2})}} \int_0^\infty e^{-{x\over 2}} x^{x\over 2} dx$ (여기서 부분적분을 적용하면)
$\displaystyle ={1 \over {2^{k\over 2} \gamma({k\over 2})}} \left\{ \left[-2e^{-{x\over 2}} x^{x\over 2} \right ]_0^\infty - \int _0^\infty -2e^{-{x\over 2}} {k\over 2}x^{{k\over 2}-1}dx \right\}$
$\displaystyle ={1 \over {2^{k\over 2} \gamma({k\over 2})}} \left\{ \left[-2e^{-{x\over 2}} x^{x\over 2} \right ]_0^\infty +k \int _0^\infty e^{-{x\over 2}} x^{{k\over 2}-1}dx \right\}$ (이 때 부분적분한 앞 항은 로피탈 정리에 의해 0으로 수렴됨)
$\displaystyle ={1 \over {2^{k\over 2} \gamma({k\over 2})}} \left\{k \int _0^\infty e^{-{x\over 2}} x^{{k\over 2}-1}dx \right\}$ (앞의 항을 다시 적분식으로 넣어주면)
$\displaystyle =k\int_0^\infty {1\over {2^{k\over 2} \gamma({k\over 2})}} e^{-{x\over 2}} x^{{k\over 2}-1}dx$ (여기서 적분식은 k자유도를 갖는 카이제곱분포함수와 동일하므로 적분 시 1이 됨)
$\displaystyle =k$
$\displaystyle \therefore E(x) = k$ (어떤 확률변수 $X$가 $Q \sim \chi_k^2$의 카이제곱분포($k$ 자유도 갖는)를 따를 때 이 확률변수 $X$의 평균은 $k$다)
10. 지수분포 (Exponential distribution)
지수분포는 포아송 분포에서 유도된다. 위에서 포아송 분포는 단위 시간당 사건의 평균 발생 횟수였다. 수식으로는 $\displaystyle p(x) = {\lambda^x e^{-\lambda} \over x!}$였다. 여기서 $\lambda$는 단위 시간당 사건의 평균발생횟수($\because \lambda=np$)이며 $x$는 사건 발생 횟수이다. 예를 들어 하루 동안 모범 택시를 평균적으로 3번 마주친다면 $\displaystyle p(x) = {3^xe^{-3} \over x!}$이 된다.
지수분포는 이러한 포아송 분포가 만족하는 상황에서 사건 A가 일어날 때까지 걸리는 시간이 T이하일 확률이다. 즉 기존 포아송에서 시간까지 더 알고자 하는 것이다. 이를 일반화한 정의는 단위 시간당 사건 A의 평균발생횟수가 $\lambda$일 때, 사건 A가 처음 발생할 때 까지 걸리는 시간이 T이하일 확률이다. 지수 분포는 아래 수식으로 표현한다.
$\displaystyle f(T) = \lambda e^{-\lambda T}$
위 지수 분포 유도를 위해 하나의 예를 들어 설명 하자면, 모범 택시를 마주칠 때 까지 걸리는 기간이 5일 이하일 확률을 $\displaystyle p(0\leq t \leq 5) = \int_0^5 f(t)dt$로 표현할 수 있다. 이 확률을 구하기 위해서는 두 가지 방법이 있다. 첫 번째는 1일차에 만날 확률, 2일차에 만날 확률, ..., 5일차에 만날 확률을 구해 모두 더해주는 방식이고, 두 번째는 여사건을 사용하는 방법이다. 여사건을 통해 확률을 구하는 식은 (1 - 5일동안 모범 택시 마주치지 않을 확률 p)이다.
여사건으로 계산을 해보자면 먼저 1일차에 모범택시를 만나지 않을 확률을 구하면 $\displaystyle p(0) = {3^0e^{-3} \over 0!} = e^{-3}$이 된다. 따라서 5일동안 모범 택시를 마주치지 않을 확률은 $\displaystyle e^{{-3}\times 5}$가 된다. 이 모범 택시를 마주칠 확률은 곧 $\displaystyle \int_0^5 f(t)dt = 1 - e^{-15}$와 같다.
이렇게 구한 포아송 분포를 지수분포로 일반화 하여 어떤 사건이 발생할 때 까지 걸리는 기간이 T이하일 확률을 나타내는 과정을 나타내보자. 우선 $\displaystyle p(0\leq t\leq T) = \int_0^T f(t)dt = 1 - e^{-\lambda T}$이 있고, 여기서 구해야할 것은 지수분포를 나타내는 $\displaystyle \int_0^T f(t)dt$이다. 지수분포 식은 T로 미분해서 얻을 수 있다. $f(t)$의 부정적분을 $F(T)$로 두면, 이 적분식은 $\displaystyle F(T) - F(0) = 1-e^{-\lambda T}$가 된다. 이 식의 양변을 T로 미분하면 $\displaystyle f(T) = \lambda e^{-\lambda T}$가 되며 이 함수는 지수분포를 나타내는 식이다.
이 지수함수 분포에 대한 평균과 를 이용해 평균과 분산은 각각 $\displaystyle E(x)={1 \over \lambda}$, $\displaystyle V(x)={1\over \lambda^2}$이다. 이 중 평균을 구하는 과정만 기술해보자면,
$\displaystyle E(t) = \int_0^\infty tf(t)dt$
$\displaystyle = \int_0^\infty t \lambda e^{-\lambda t}dt$ (여기서 부분적분을 사용하면)
$\displaystyle = \left[ -te^{-\lambda t} \right]_0^\infty - \int_0^\infty -e^{-\lambda t}dt$ ($\because \int e^{f(x)} = {e^{f(x)} \over f'(x)}$이며 부분적분 공식에 의해 $\int f(x)g'(x)dx = f(x)g(x) - \int f'(x)g(x)$이므로)
$\displaystyle = \left[ -te^{-\lambda t}\right]_0^\infty + \left[-{1\over \lambda}e^{-\lambda t}\right]_0^\infty$ (이 식은 위 식에서 뒤 항을 적분해준 결과임. 여기서 극한값을 이용해 표현하면)
$\displaystyle = \lim_{t \to \infty} (-te^{-\lambda t}) - 0 + \lim_{t \to \infty} -{1\over \lambda} e^{-\lambda t} - (- {1\over \lambda}e^0)$ (이 때 $\lim_{t \to \infty} -{1\over \lambda}e^{-\lambda t}$는 0이 되므로)
$\displaystyle = \lim_{t \to \infty} (-te^{-\lambda t}) + {1\over \lambda}$ (여기서 -를 앞으로 빼고 지수 표현식을 분수로 바꿔주면)
$\displaystyle = -\lim_{t \to \infty} {t \over e^{\lambda t}} + {1\over \lambda}$ (여기서 $1 = {1 \over \lambda } \lambda$이므로 이를 추가해주면)
$\displaystyle = -{1 \over \lambda} \lim_{t \to \infty} {\lambda t \over e^{\lambda t}} + {1\over \lambda}$ (이 때 로피탈 정리에 의해 $\displaystyle \lim_{t \to \infty} {\lambda t \over e^{\lambda t}}$는 0이 됨)
$\displaystyle = {1\over \lambda}$
$\displaystyle \therefore E(t) = {1 \over \lambda}$
11. 감마분포 (Gamma distribution)
감마분포는 지수분포의 확장이다. 지수분포에서 한 번의 사건이 아닌 여러 개의 사건으로 확장한 것이다. 구체적으론 지수분포는 포아송 분포가 만족하는 상황에서 사건 A가 일어날 때까지 걸리는 시간이 T이하일 확률이었다. 감마분포는 $\alpha$번째 사건이 발생할때까지 걸리는 시간이 T이하일 확률이다. 예를 들어 평균적으로 주유소를 30분에 한 번씩 마주친다면 주유소를 4번 마주칠 때까지 걸리는 시간이 T이하일 확률과 같은 것이다. 감마분포 또한 여러 곳에 활용되지만 주로 감마분포는 모수의 베이지안 추정에 활용된다.
감마함수는 $\displaystyle \gamma(\alpha) = \int_0^\infty x^{\alpha-1}e^{-x}dx, (\alpha \gt 0)$로 표기한다. 이 감마함수는 팩토리얼 계산을 자연수에서 복소수범위까지 일반화한 함수라고 한다. 이 감마 함수를 근간으로한 감마분포함수는 $\displaystyle f_x(x) = {1 \over \gamma(\alpha)\beta^\alpha} x^{\alpha-1}e^{-x\over \beta}$로 표기한다. ($\displaystyle 0 \leq x \leq \infty$, ($\alpha \gt 0, \beta \gt 0)$). 감마분포에서 $\alpha$는 형태 모수(shape parameter), $\beta$는 척도 모수(scale parameter)라고 한다.
감마분포의 평균과 분산은 각각 $E(x)=\alpha \beta$, $V(x) = \alpha \beta^2$이다. 여기서 감마분포의 평균을 구하는 과정만 기술하자면,
$\displaystyle E(x) = \int_0^\infty xf(x)dx$
$\displaystyle = \int_0^\infty x{1 \over \gamma(\alpha)\beta^\alpha} x^{\alpha-1}e^{-x\over \beta}dx$ ($xx^{-1}=1$, 상수 부분을 앞으로 빼주면)
$\displaystyle = {1 \over \gamma(\alpha) \beta^\alpha} \int_0^\infty x^\alpha e^{-{x\over \beta}}dx$ (${x\over \beta} = t$로 치환)
$\displaystyle = {1 \over \gamma(\alpha) \beta^\alpha} \int_0^\infty (t\beta)^\alpha e^{-t} \beta dt$ ($\beta^\alpha$는 약분되어 사라지고 상수 $\beta$를 앞으로 빼주면)
$\displaystyle = {\beta \over \gamma(\alpha)} \int_0^\infty t^\alpha e^{-t}dt$ (이 때 $\gamma$ 함수의 원형과 동일하므로)
$\displaystyle = \beta {\gamma(\alpha+1) \over \gamma(\alpha)}$ ($\gamma$ 함수는 팩토리얼이므로 $\alpha$만 남게 됨)
$\displaystyle = \beta \alpha$
$\displaystyle \therefore E(x) = \alpha \beta$
12. 베타분포 (Beta distribution)
베타분포는 베이즈 추론에서 사전 확률을 가정할 때 사용되기 때문에 중요하다. 베타분포의 정의는 두 매개변수 $\alpha$와 $\beta$에 따라 [0, 1] 구간에서 정의되는 연속확률분포이다. $\alpha$와 $\beta$는 아래와 같이 베타분포 그래프의 형태를 결정하는 형태 모수(shape parameter)다. 만약 $\alpha = \beta$라면 베타분포는 대칭이 된다. 또 $\alpha$와 $\beta$가 커질수록 정규분포와 모양이 비슷해진다.

베타분포의 근간인 베타함수의 수식은 $\displaystyle B(\alpha, \beta) = {\gamma (\alpha) \gamma(\beta) \over \gamma(\alpha + \beta)} = \int_0^1 x^{\alpha -1}(1-x)^{\beta -1}dx$로 표현한다. 이 베타함수를 기반으로하는 베타분포의 확률밀도함수는 $\displaystyle f_x(x) = {\gamma(\alpha + \beta) \over \gamma(\alpha) \gamma(\beta)} x^{\alpha-1}(1-x)^{\beta-1}, (0 \lt x \lt 1, \alpha, \beta \gt 0)$이다. 평균과 분산은 각각 $\displaystyle E(x) = {\alpha \over \alpha + \beta}$, $\displaystyle V(x) = {\alpha \beta \over (\alpha+\beta)^2(\alpha+\beta+1)}$인데, 이 중 평균을 구하는 과정만 기술하면,
$\displaystyle E(x) = \int_0^1 xf(x)dx$
$\displaystyle =\int_0^1 x{1\over B(\alpha, \beta)}x^{\alpha-1}(1-x)^{\beta-1}dx$
$\displaystyle ={B(\alpha+1, \beta) \over B(\alpha, \beta)} \int_0^1 {1 \over B(\alpha+1, \beta)} x^{(\alpha+1)-1}(1-x)^{\beta-1}dx$
$\displaystyle ={\gamma(\alpha+\beta) \over \gamma(\alpha)\gamma(\beta)} {\gamma(\alpha+1)\gamma(\beta) \over \gamma(\alpha+\beta+1)}$
$\displaystyle = {\alpha \over \alpha+\beta}$
$\displaystyle \therefore E(x) = {\alpha \over \alpha+\beta}$
Reference
[1] 베르누이분포 https://www.youtube.com/watch?v=3rOIcMF0-ls
[2] 이항분포 https://www.youtube.com/watch?v=XzJkxIkP4Pg
[3] 기하분포 https://www.youtube.com/watch?v=NzQRbVP5eow
[4] 기하 분포 https://blog.naver.com/PostView.naver?blogId=chunsa0127&logNo=222049190534
[5] 음이항 분포 https://www.youtube.com/watch?v=bBo7rN3SvCg
[6] 초기하 분포 https://www.youtube.com/watch?v=HT1en9f2AcE
[7] 포아송 분포 https://www.youtube.com/watch?v=JOWYEDwqAtY
[8] 균등 분포 https://www.youtube.com/watch?v=LeUfJHzOSXo
[9] 정규 분포 https://m.blog.naver.com/algosn/221308973343
[10] 카이제곱 분포 https://math100.tistory.com/44
[11] 카이제곱 분포 https://www.youtube.com/watch?v=2ER99k6f5eQ
[12] 지수 분포 https://www.youtube.com/watch?v=OywjNb4jmtc
[13] 감마 분포 https://soohee410.github.io/gamma_dist
[14] 베타 분포 https://soohee410.github.io/beta_dist
[15] 이미지 https://quantitative-probabilitydistribution.blogspot.com/2021/01/various-types-of-probability.html
'Artificial Intelligence > 확률-통계학' 카테고리의 다른 글
| [확률/통계] 적률추정법 이해하기 (Method of Moments Estimator) (0) | 2022.10.23 |
|---|---|
| [확률/통계] 가설 검정 이해하기 (귀무가설, 대립가설) (0) | 2022.10.21 |
| [확률/통계] 베이즈 정리 이해하기 (Bayesian Theorem) (0) | 2022.10.11 |
| [확률/통계] 누적분포함수 (CDF, Cumulative Distribution Function) (0) | 2022.10.10 |
| [확률/통계] 모수 추정과 추정량, 추정치 (1) | 2022.09.28 |