모델 학습 후 성능 최적화를 위해 하이퍼파라미터 튜닝을 수행할 때가 있다. Optuna 사용 방법은 여러 문서에 기술되어 있어 참고할 수 있지만 파이토치에서 분산처리를 적용한 Multi-GPU 환경에서 Optuna를 함께 실행하는 방법에 대한 레퍼런스가 적어 약간의 삽질을 수행했기 때문에 추후 참고 목적으로 작성한다. 또한 파이토치로 분산처리 적용하여 Multi-GPU 학습을 수행하고자할 때 mp.spawn의 리턴값을 일반적으로는 받아오지 못하는 경우가 있어 이에 대한 내용도 덧붙이고자 한다.
Optuna 사용 핵심은 objective 함수 작성이다. 함수 내에는 튜닝할 하이퍼파라미터의 종류와 그 값의 범위값을 작성해준다. 이후 학습 루틴을 수행 후 그 결과를 리턴값으로 전달해주는 것이 끝이다. 학습루틴을 objective 함수 내부에 정의해도 되나 분산학습을 함께 적용하기 위해 별도의 함수로 만들어 실행한다.
run_tuning은 실제로 하이퍼파라미터 튜닝을 수행할 함수를 첫 번째 인자(tuning_fn)로 받는다. mp.spawn은 리턴값이 없으므로 학습 관련 결과에 대한 값을 받아올 수 없다. 만약 multi-gpu를 통한 분산처리의 리턴값을 받아올 필요가 없다면 mp.spawn() 한 줄만 작성해주어도 된다. 하지만 필요한 경우가 있다. 이를 해결하기 위해 mp.Pipe()를 사용한다. 학습 관련 결과를 child_conn을 이용해 parent_conn으로 전송하는 것이다. child_conn은 학습 함수인 tuning_fn의 인자로 들어가서 학습 관련 결과에 대해 parent_conn으로 전달한다. mp.spawn이 종료되면 parent_conn에서 poll() 메서드와 recv() 메서드를 통해 그 결과를 가져올 수 있다.
아래 함수는 실제로 파이토치에서 Multi-GPU를 활용해 학습하는 루틴을 정의한 함수다.
함수의 가장 처음과 끝은 setup()과 cleanup()으로 각각 Multi-GPU로 학습 가능하도록 초기화하고 학습 이후 환경 초기화를 수행하는 역할을 한다. 모델은 DDP로 래핑해주고 데이터셋도 DistributedSampler를 사용한 결과로 데이터로더를 만들어준다. 이후 학습을 수행하고 conn.send()를 통해 그 결과를 parent_conn()으로 전달한다.
return torch.stack(batch, 0, out=out) RuntimeError: stack expects each tensor to be equal size, but got [3, 64] at entry 0 and [4, 64] at entry 1
데이터로더로부터 데이터를 가져와 학습시키기 전 발생한 오류다. 텐서 사이즈가 동일하지 않다고 한다. 원인은 배치 사이즈 별로 데이터가 묶이지 않아 발생한다고 한다. 직접적으로 텐서 사이즈를 조작 해주어도 잘 해결되지 않았다. 해결 방법은 DataLoader에 collate_fn 파라미터를 사용해줌으로써 학습을 시작할 수 있었다. collate_fn 파라미터는 텐서 간의 사이즈를 조절하는 역할을 한다. 아래와 같이 함수 하나를 만들어 주고 DataLoader(dataset, ..., collate_fn = collate_fn)과 같은 형식으로 입력해주면 문제 해결 가능하다.
최근 몇 년간 Large Language Model을 만드는 추세가 계속해서이어지고 있다. 이런 거대 모델의 경우 파라미터를 역전파로 업데이트하기 위해 많은 양의 메모리와 컴퓨팅 파워가 필요하다. 따라서 여러 프로세서에 분산시켜 모델을 학습하는 분산 학습이 필요하다. 분산 학습을 통해 CPU 또는 GPU 상의 학습 속도 향상을 이룰 수 있다. 많은 사람들이 사용하는 딥러닝 라이브러리인 파이토치에서 이런 분산 학습을 돕는 아래 API들이 있다.
1. torch.multiprocessing
여러 파이썬 프로세스를 생성하는 역할. 일반적으로 CPU나 GPU 코어 수 만큼 프로세스 생성 가능
학습 데이터셋을 프로세스 수 만큼 분할해 분산 학습 세션의 모든 프로세스가 동일한 양의 데이터로 학습하도록 만드는 역할.
프로세스 수만큼 나누기 위해 world_size라는 인자를 사용.
4. torch.nn.parallel.DistributedDataParallel
해당 API는 내부적으로 5가지 동작이 이뤄짐
분산 환경에서 각 프로세스마다 고유한 모델 사본이 생성됨.
고유 모델 사본 별 자체 옵티마이저를 갖고, 전역 이터레이션과 동기화됨
각 분산 학습 이터레이션에서 개별 loss를 통해 기울기가 계산되고, 각 프로세스의 기울기 평균을 구함
평균 기울기는 매개변수를 조정하는 각 모델 복사본에 전역으로 역전파됨.
전역 역전파 때문에 모든 모델의 매개변수는 이터레이션마다 동일하도록 자동으로 동기화됨.
2. 분산 학습 루틴 정의
그렇다면 실제로 위 API를 이용해 어떻게 분산 학습 루틴을 정의할 수 있을까? 아래 예시 코드를 통해 알아보자.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torch.multiprocessing as mp
import torch.distributed as dist
import os
import time
import argparse
class ConvNet(nn.Module):
pass
def train(gpu_num, args):
rank = args.machine_id * args.num_gpu_processes + gpu_num
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu_num)
model.cuda(gpu_num)
criterion = nn.NLLLoss().cuda(gpu_num) # nll is the negative likelihood loss
train_dataset = datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1302,), (0.3069,))]))
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.world_size,
rank=rank
)
train_dataloader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=0,
pin_memory=True,
sampler=train_sampler)
optimizer = optim.Adadelta(model.parameters(), lr=0.5)
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu_num])
model.train()
for epoch in range(args.epochs):
for b_i, (X, y) in enumerate(train_dataloader):
X, y = X.cuda(non_blocking=True), y.cuda(non_blocking=True)
...
if b_i % 10 == 0 and gpu_num==0:
print (...)
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--num-machines', default=1, type=int,)
parser.add_argument('--num-gpu-processes', default=1, type=int)
parser.add_argument('--machine-id', default=0, type=int)
parser.add_argument('--epochs', default=1, type=int)
parser.add_argument('--batch-size', default=128, type=int)
args = parser.parse_args()
args.world_size = args.num_gpu_processes * args.num_machines
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '8892'
start = time.time()
mp.spawn(train, nprocs=args.num_gpu_processes, args=(args,))
print(f"Finished training in {time.time()-start} secs")
if __name__ == '__main__':
main()
ConvNet 클래스는 코드가 길어지지 않도록 한 것으로 모종의 컨볼루션 레이어가 들어있다고 가정한다. 분산 학습의 루틴이 되는 로직의 핵심은 train 함수에 들어있다. 살펴보면 가장 먼저 첫번째로 rank가 할당된다. rank는 전체 분산시스템에서 프로세스 순서를 지칭하는 것이다. 예를 들어 4-CPU를 가진 시스템 2개가 있다면 8개의 프로세스를 생성할 수 있고 각 프로세스는 0~7번까지 고유 번호를 가질 것이다. rank를 구하기 위해 사용하는 식은 $rank = n*4 + k$이다. 여기서 n은 시스템 번호(0, 1)이 되고, k는 프로세스 번호(0, 1, 2, 3)이다. 참고로 rank가 0인 프로세스만 학습에 대한 로깅을 출력한다. 그 이유는 rank가 0인 프로세스가 다른 프로세스와의 통신의 주축이 되기 때문이다. 만약 그렇지 않다면 프로세스 개수만큼 로그가 출력될 것이다.
두 번째로 dist.init_process_group 메서드가 보인다. 이는 분산 학습을 진행하는 각 프로세스 간의 통신을 위해 사용한다. 정확히는 매개변수로 들어가는 backend 인자가 그 역할을 한다. pytorch에서 지원하는 backend 인자에는 Gloo, NCCL, MPI가 있다. 간단히 언급하면 주로 Gloo는 CPU 분산 학습에 NCCL은 GPU 분산 학습에, MPI는 고성능 분산 학습에 사용된다. init method는 각 프로세스가 서로 탐색하는 방법으로 URL이 입력되며 기본값으로 env://이 설정된다. world_size는 분산 학습에 사용할 전체 프로세스 수다. world_size 수 만큼 전체 학습 데이터셋 수가 분할된다.
세 번째로 torch.utils.data.distributed.DistributedSampler다. world_size 수 만큼 데이터셋을 분할하고 모든 프로세스가 동일한 양의 데이터셋을 갖도록 한다. 이후에 DataLoader가 나오는데 shuffle=False로 설정한 것은 프로세스 간 처리할 데이터셋의 중복을 피하기 위함이다.
네 번째로 torch.nn.parallel.DistributedDataParallel다. 분산 환경에서 사용할 각각의 모델 복사본을 생성한다. 생성된 각 모델 복사본은 각자 옵티마이저를 갖고, loss function으로부터 기울기를 계산하고 rank 0을 가지는 프로세스와 통신하여 기울기의 평균을 구하고 rank 0을 갖는 프로세스로부터 평균 기울기를 받아 역전파를 수행한다. 이 DistributedDataparallel을 사용하면 각각 독립된 프로세스를 생성하므로 파이썬 속도 한계의 원인인 GIL 제약이 사라져 모델 학습 속도를 늘릴 수 있다는 장점이 있다.
다섯 번째로 MASTER_ADDR은 rank가 0인 프로세스를 실행하는 시스템의 IP 주소를 의미하고 MASTER_PORT는 그 장치에서 사용 가능한 PORT를 의미한다. 이는 앞서 언급했듯 rank 0인 시스템이 모든 백엔드 통신을 설정하기 때문에 다른 프로세스들이 호스팅 시스템을 찾기 위해 사용한다. IP에 따라 local이나 remote를 설정해 사용할 수 있다.
마지막으로 데이터로더에 pin_memory=True는 데이터셋이 로딩 된 장치(ex: CPU)에서 다양한 장치(GPU)로 데이터를 빠르게 전송할 수 있도록 한다. 예를 들어 데이터셋이 CPU가 사용하는 고정된 page-lock 메모리 영역에 할당되어 있다면 GPU는 이 CPU의 page-lock 메모리 영역을 참조하여 학습도중 필요한 데이터를 복사해 사용한다. pin_memory=True는 참고로 학습 루틴 상에서 non_blocking=True라는 매개변수와 함께 동작한다. 결과적으로 GPU 학습 속도가 향상되는 효과를 가져온다.
훈련이 완료된 ML/DL 모델은 실제 서비스에 적용하기 위해 프로덕션 레벨로 배포하고 서빙해야한다. 이를 위한 모델 서빙 종류는 로컬에 플라스크로 모델 서버 구축, 도커로 모델 서빙 환경 구축, 토치서브로 모델 서빙하는 방법, 클라우드로 모델 서빙하는 방법이 있다. 모델 서빙은 모델 훈련이 완료되고 저장되어 있어 재사용가능 할때 이루어지므로 간단히 모델 저장 방법에 대해 언급하고 넘어가자.
파이토치 모델 저장 및 로딩 방법
파이토처리 모델을 저장하고 로딩하는 방법은 2가지가 있다. 첫 번째 방법은 가장 간단한 방식으로 전체 모델 객체를 저장하고 로딩하는 방식이다.
torch.save(model, PATH)
model = torch.load(PATH)
모델 전체를 저장하므로 간편하다. 하지만 이 방식은 경우에 따라 문제가 발생할 수 있다. 그 이유는 모델 객체 전체를 저장하기 때문에 모델 객체 내부에 매개변수, 모델 클래스, 디렉터리 구조까지 함께 저장한다. 따라서 만약 추후 디렉터리 구조라도 변경된다면 모델 로딩에 실패하게 되고 문제 해결이 어려워질 수 있다. 따라서 모델 매개변수만 저장하는 아래 두 번째 방법을 사용하는 것이 좋다.
torch.save(model.state_dict(), PATH)
model = ConvNet()
model.load_state_dict(torch.load(PATH))
모델 매개변수만 저장하기 위해 state_dict() 메서드를 사용하고, 추후 빈 모델 객체를 인스턴스화해 빈 모델 객체에 매개 변수를 로딩해 사용하는 방법이다. 간단히 파이토치 모델 저장하는 방법을 알아보았으니 다음으로 이 모델을 배포하여 서빙하는 방법에 대해 알아보자.
1. 플라스크로 로컬에 모델 서버 구축하기
가장 간단하게 설치해 사용할 수 있는 플라스크를 서버로 사용한다. 플라스크 서버에 입력(추론 요청)이 들어오면 추론한 결과를 출력값으로 하여 되돌려 보내준다. 중요한 것은 플라스크 서버 내부에서 추론해 결과를 돌려주는 일이므로 추론 함수 작성이 필요하다. 예시를 위해 MNIST 숫자를 예측하는 모델이라 가정한다. 그렇다면 다음과 같은 추론 함수를 작성할 수 있다.
위와 같이 작성한 추론 요청 함수를 실행시키면 플라스크 모델 서버로부터 추론한 결과를 받을 수 있게 된다. 하지만 이와 같이 구축된 모델 추론 파이프라인을 다른 환경에서 동일하게 구축하려면 수동으로 동일한 라이브러리 설치부터 폴더구조를 맞춰주고 파일을 복사하는 등의 작업이 필요하다. 때문에 이 환경을 그대로 복제하여 다른 환경에서도 사용할 수 있도록 하는 확장성이 필요하다. 이 때 사용할 수 있는 것이 도커다. 도커를 통해 손쉽게 위 환경을 복제하고 실행하는 방법에 대해 알아보자.
2. 도커로 모델 서빙 환경 구축하기
도커를 사용하면 서버 구축에 사용되었던 소프트웨어 환경을 손쉽게 만들 수 있다.
2.1 Dockerfile 만들기
도커를 사용하기 위해서는 가장 먼저 Dockerfile을 만들어야 한다. Dockerfile을 실행하면 결과적으로 위 플라스크로 구축했던 모델 서빙환경이 그대로 재현되어야 한다. Dockerfile 실행하면 도커 이미지가 생성되고 이 과정을 이미지 빌드라고 한다. 이를 위해 Dockerfile에 다음과 같은 스크립트를 작성할 수 있다.
FROM python:3.8-slim
RUN apt-get -q update && apt-get -q install -y wget
COPY ./server.py ./
COPY ./requirements.txt ./
RUN wget -q https://raw.githubusercontent.com/wikibook/mpytc/main/Chapter10/convnet.pth
RUN wget -q https://github.com/wikibook/mpytc/raw/main/Chapter10/digit_image.jpg
RUN pip install --no-cache-dir -r requirements.txt
USER root
ENTRYPOINT ["python", "server.py"]
간단히 각 명령에 대해 설명하자면 FROM을 통해 도커에 python3.8이 포함된 표준 리눅스 OS를 가져오도록 지시하고, RUN을 통해 업데이트 하고 wget을 다운로드 한다. 이후 COPY를 통해 로컬에 만들어두었던 서버 파일과 환경구축에 필요한 requirements.txt 파일을 복사해준다. 이후 추론에 필요로한 모델과 예제 이미지를 다운로드 받고, pip install을 통해 파이썬 라이브러리를 모두 설치해준다. 참고로 requirements.txt에는 다음과 같은 라이브러리가 들어있다. (만약 동작하지 않는다면 Flask를 업데이트 할 것)
USER를 통해 루트 권한을 부여하고 ENTRYPOINT를 통해 python server.py 명령이 실행되면 도커상에서 플라스크 모델 서버가 실행된다.
2.2 도커 이미지 빌드
도커 파일이 작성되었으면 이를 빌드해주어 도커 이미지로 만들어주어야 한다. 이를 위해 다음과 같은 명령어를 사용한다.
docker build -t <tag name> .
여기서 <tag name>은 임의 설정이다.
2.3 도커 이미지 배포 (실행)
도커 이미지 빌드를 통해 만들어진 도커 이미지를 다음과 같은 명령 실행을 통해 배포가 가능하다.
docker run -p 8890:8890 <tag name>
위 명령이 실행되면 다음과 같이 도커 이미지가 실행되어 모델 서빙이 가능하도록 플라스크 서버가 구동되는 것을 확인할 수 있다.
구동된 플라스크 서버에 다시 추론을 요청하는 request를 날리면 이에 대한 응답이 결과로 반환되는 것을 확인할 수 있다.
도커 실행을 중지하려면 현재 실행 중인 도커 컨테이너를 확인해야 하며 이는 docker ps -a 명령으로 확인할 수 있다. 그러면 CONTAINER ID를 확인할 수 있고 이를 복사하여 docker stop <CONTAINER ID> -t 0을 실행시켜주면 도커 컨테이너가 중지된다. 만약 도커 컨테이너를 삭제하고 싶다면 docke rm <CONTAINER ID> 명령을 실행하면 된다. 빌드했던 도커 이미지까지 삭제하려면 docker images 명령을 통해 <tag name>을 확인하고 docker rmi <tag name>을 통해 삭제할 수 있다.
3. 토치서브로 모델 서빙하기
torchserve는 파이토치 모델 서버 라이브러리다. 메타와 AWS에서 만들었고, 파이토치 모델 배포를 도와주는 역할을 한다. torchserve를 사용하기 위해서 Java 11 SDK 설치와, pip install torchserve torch-model-archiver 명령 실행을 통해 라이브러리 설치가 우선적으로 필요하다. 여기서 torch-model-archiver는 압축 라이브러리다. 입력값을 3개 받아 .mar 파일로 만들어주는 역할을 한다. 입력값 3개란 1. 모델 클래스 파일 2. 훈련된 모델 파일 3. 핸들러(전처리, 후처리) 파일이다.
1. 클래스 파일은 모델 레이어가 구성된 파일로, 앞서 플라스크 서버 구축때 사용할 때 정의했던 ConvNet 클래스를 별도 파일로 만들어준 것이다.
2. 훈련된 모델 파일은 convnet.pth와 같이 모델 학습이 완료된 파일이며
3. 핸들러는 torchvision의 transform 클래스와 같이 전처리를 할 수 있는 로직이나 별도의 후처리 로직이 담긴 파일이다.
torch-model-archiver를 사용해 아래 명령을 실행시켜주면 목표로하는 convnet.mar 파일이 생성된다.
결과적으로 추론한 결과 숫자가 터미널에 출력될 것이다. 만약 토치서브로 구동한 서버를 종료하고 싶다면 torchserve --stop 명령을 통해 중지할 수 있다. 덧붙여 만약 서버의 모델 서빙 여부를 확인하기 위한 핑을 보내는 명령은 다음과 같이 사용할 수 있다. 참고로 포트 정보는 torchserve 실행에 의해 서버가 실행될 때 로그를 통해 확인 가능하다.
curl http://localhost:8081/models
4. 토치스크립트로 범용 파이토치 모델 만들기
지금까지는 로컬 플라스크 서버, 도커 환경, 토치서브 환경을 통해 모델 서버를 구현했다. 하지만 이는 파이썬 스크립트 환경에서 이루어진 것이다. 훈련한 모델이 반드시 훈련했던 환경에서 모델 서빙이 이뤄진다 할 수 없다. 파이썬이 실행되지 않는 외부환경에서도 실행될 수 있다. 따라서 파이토치 모델을 C++과 같은 타 언어에서도 실행될 수 있도록 중간 표현으로 만들 필요성이 있다. 이 때 토치스크립트를 사용할 수 있다. 토치스크립트는 별도의 라이브러리는 아니고 파이토치 내부에서 모델 연산 최적화를 위해 사용하는 JIT compiler에서 사용된다. 토치스크립트는 간단히 torch.jit.script(model) 또는 torch.jit.trace(model, input)를 실행시켜 만들 수 있다.
파이토치 모델을 토치스크립트로 컴파일하기 위해선, 언급했듯 두 가지 방식이 존재한다. 첫 번째는 trace 방식이고 두 번째는 script 방식이다. trace 방식을 위해선 모델과 더미(임의) 입력값이 필요하다. 더미 입력값을 모델에 넣어서 입력값이 어떻게 흐르는지 추적해 기록한다. trace 방식을 사용해 모델을 만든다면 다음과 같은 형태로 만들 수 있다.
model = ConvNet()
PATH_TO_MODEL = "./convnet.pth"
model.load_state_dict(torch.load(PATH_TO_MODEL, map_location="cpu"))
model.eval()
for p in model.parameters():
p.requires_grad_(False)
demo_input = torch.ones(1, 1, 28, 28)
traced_model = torch.jit.trace(model, demo_input)
# print (traced_model.graph)
# print(traced_model.code)
torch.jit.save(traced_model, 'traced_convnet.pt')
loaded_traced_model = torch.jit.load('traced_convnet.pt')
중간에 있는 torch.jit.trace() 메서드를 통해 토치스크립트 형식의 객체를 만들어주는 것이 핵심이다. 이후 모델을 저장하게 되면 C++과 같은 다른 언어에서도 파이토치 모델을 로딩해 추론할 수 있다. 위를 살펴보면 model과 loaded_trace_model 두 개가 있는데 향후 모델에 입력값을 넣고 추론해보면 추론 결과는 완벽히 동일하게 출력된다.
하지만 이러한 trace 방식을 이용하면 한 가지 큰 문제가 발생할 수 있다. 예를 들어 모델 순전파가 if나 for문과 같은 제어 흐름으로 구성된다면 trace는 여러 가능한 경로 중 하나만 토치 스크립트로 렌더링할 것이다. 따라서 기존 모델과 동일성을 보장할 수 없다. 이를 해결하기 위해서는 script 방식을 사용해 토치 스크립트로 컴파일 해야 한다. script 방식도 위 trace 방식과 동일하다. 다만 차이점이 있다면 더미 입력이 사용되지 않는 것이 특징이다.
model = ConvNet()
PATH_TO_MODEL = "./convnet.pth"
model.load_state_dict(torch.load(PATH_TO_MODEL, map_location="cpu"))
model.eval()
for p in model.parameters():
p.requires_grad_(False)
scripted_model = torch.jit.script(model)
# print(scripted_model.graph)
# print(scripted_model.code)
torch.jit.save(scripted_model, 'scripted_convnet.pt')
loaded_scripted_model = torch.jit.load('scripted_convnet.pt')
마찬가지로 중간에 있는 torch.jit.script() 메서드를 통해 토치스크립트 형식의 객체를 만들어주는 것이 핵심이다. 또 model과 loaded_scripted_model에 모두 입력값을 넣고 추론해보면 추론 결과가 동일하게 출력된다. 이렇게 script 방식을 사용해 토치스크립트 코드로 만들면 trace 방식에 비해 정확성을 더 얻을 수 있다. 다만 script 방식이 가지는 단점이 있다면 파이토치 모델이 토치스크립트에서 지원하지 않는 기능을 포함하면 동작할 수 없다. 이 때는 모델 순전파에 if for문 로직을 제거한 뒤 trace 방식을 사용해야 한다.
결론을 이야기하자면 사실상 토치스크립트는 모델 서빙을 위해 필수적으로 사용해야 한다. 그 이유는 파이썬 내부에서는 전역 인터프리터 잠금(GIL)이 설정되어 있어 한 번에 한 쓰레드만 실행될 수 있어 연산 병렬화가 불가능하기 때문이다. 하지만 토치스크립트를 통해 중간 표현으로 바꾸어 범용 형식으로 만들어두면 연산 병렬화가 가능해져 모델 서빙 속도 향상이 가능해진다.
5. ONNX로 범용 파이토치 모델 만들기
토치스크립트와 마찬가지로 ONNX 프레임워크를 사용해도 파이토치 모델을 범용화할 수 있다. 그렇다면 토치스크립트와의 차이점은 무엇일까? 토치스크립트는 파이토치에서만 사용할 수 있다면 ONNX는 텐서플로우나 이외의 딥러닝 라이브러리와 같이 더 넓은 범위에서 표준화 시킬 수 있다. 예를 들어 파이토치로 만든 모델을 텐서플로우에서 로드하여 사용할 수 있다. 이를 위해 ONNX 라이브러리 설치가 필요하다. pip install onnx onnx-tf 명령을 통해 필요한 라이브러리를 설치할 수 있다.
학습한 파이토치 모델을 ONNX 포맷으로 바꾸어 저장하기 위해서는 다음과 같은 예시 코드를 사용할 수 있다.
model = ConvNet()
PATH_TO_MODEL = "./convnet.pth"
model.load_state_dict(torch.load(PATH_TO_MODEL, map_location="cpu"))
model.eval()
for p in model.parameters():
p.requires_grad_(False)
demo_input = torch.ones(1, 1, 28, 28)
torch.onnx.export(model, demo_input, "convnet.onnx")
토치스크립트에서 trace 방식과 마찬가지로 더미 입력값이 필요하다. 핵심은 torch.onnx.export() 메서드를 사용해 onnx 포맷 형식으로 파일을 생성하는 것이다. 이후 텐서플로우 모델로 변환하기 위해서는 다음과 같은 예시 코드를 사용할 수 있다.
tf.rep.export_graph() 메서드가 실행되면 텐서플로우에서 사용 가능한 모델 파일인 convnet.pb가 생성된다.
이후 텐서플로우에서 사용하기 위해 모델 그래프를 파싱하는 과정이 필요하다. (참고로 TF 1.5 버전)
with tf.gfile.GFile("./convnet.pb", "rb") as f:
graph_definition = tf.GraphDef()
graph_definition.ParseFromString(f.read())
with tf.Graph().as_default() as model_graph:
tf.import_graph_def(graph_definition, name="")
for op in model_graph.get_operations():
print(op.values())
그래프를 파싱하고 그 결과를 출력하면 아래와 같이(간략화된) 그래프의 입출력 노드 정보를 확인할 수 있다.
지금까지의 전체 과정을 요약하자면 파이토치 모델을 서빙하는 방법과 모델을 범용화 시키는 방법에 대해 알아봤다. 모델 서빙을 위해서는 크게 3가지로 로컬에서 플라스크 서버를 실행시켜 서빙하는 방법, 플라스크 서버를 도커 이미지화 하는 방법, 토치서브를 통해 서빙하는 방법이 있었다. 도커 이미지화를 위해선 Dockerfile을 생성해주고 몇몇 명령어를 실행시켜주었고, 토치서브를 실행시키기 위해 torch-model-archiver를 통해 .mar 파일로 만들어준 뒤, 서버를 실행시켜 추론 결과를 응답해주었다. 다음으로 파이토치 모델의 범용화를 위해 토치스크립트를 사용해 모델 범용화하는 방법과 ONNX를 통해 모델 범용화하는 방법이다.
잘 이뤄지는 모델 학습이 중요한 만큼 서비스와 제품화를 위해 모델을 배포하고 서빙하는 과정도 중요하다. 특히 실제 사용되는 서비스에서는 속도가 중요하므로 토치스크립트나 ONNX를 통해 모델을 범용 포맷으로 만듦으로써 파이썬 속도 한계의 원인인 전역 인터프리터 잠금(GIL)으로부터 벗어날 수 있다. 이후 플라스크 서버나 토치서브 환경을 도커 컨테이너로 만들어 둔다면 개발 속도 측면이나 효율성 등의 측면에서 많은 이점을 얻을 수 있을 것이다. 글을 작성하며 사용한 예시 코드의 전체 코드는 아래 링크를 참조하였다.
챗봇을 구축하기 위해 사용할 수 있는 라이브러리로는 Rasa가 있고, 한글 버전으로는 Kochat이 있다. 웹 인터페이스 기반으로 코드를 사용하지 않고 쉽게 챗봇을 만들 수 있는 DialogFlow라는 클라우드 서비스가 있지만 간단한 챗봇을 만들 때만 쓸 수 있고, 디테일한 구현이 필요할 땐 Rasa와 같은 오픈소스 라이브러리를 써야한다. Rasa는 크게 Rasa NLU와 Rasa Core로 나뉜다. rasa nlu는 인텐트(intent) 분류와 엔티티(entity) 추출에 사용하는 라이브러리이다. 이를 통해 챗봇 커스터마이징이 가능하고 상상한 거의 모든 종류의 챗봇을 만들 수 있다고 한다. rasa core는 인텐트 추가와 같은 스케일업을 도와주는 라이브러리다. 이 rasa core를 통해 챗봇 응답과 챗봇 동작을 명시 가능하다. 이 명시되는 정보를 액션(Action)이라 하는데, 다르게 말하면 dialouge state에 응답하기 위해 취해야할 행동을 뜻한다. 더하여 rasa core는 과거 히스토리(대화내역)을 기반으로 다음에 이루어져야 할 액션을 예측하는 확률모델을 생성하는 역할을 한다.
Rasa NLU
rasa nlu를 사용하면 학습과 추론을 매우 손쉽게 할 수 있다. 아래 예시 코드와 같이 라이브러리를 제외하면 단 9줄 가량의 코드로도 동작한다.
from rasa_nlu.training_data import load_data
from rasa_nlu.model import Trainer
from rasa_nlu import config
from rasa_nlu.model import Interpreter
def train_horoscopebot(data_json, config_file, model_dir):
training_data = load_data(data_json)
trainer = Trainer(config.load(config_file))
trainer.train(training_data)
model_directory = trainer.persist(model_dir, fixed_model_name='horoscopebot')
def predict_intent(text):
interpreter = Interpreter.load('./models/nlu/default/horoscopebot')
print(interpreter.parse(text))
위 예시 코드는 별자리를 알려주는 태스크를 수행하는 챗봇을 구현하기 위해 사용된 것으로 사용자 입력이 들어오면 아래와 같이 추론 가능하다.
위 결과를 보면 네 개의 사전 정의한 인텐트(greeting, get_horoscope, dob_intent, subscription)중 예측한 인텐트에 대한 신뢰점수가 confidence로 계산되는 것을 확인할 수 있다. 사용자는 별자리를 알고 싶다 말했고, 학습을 진행했던 결과 사용자의 발화(utterance)는 별자리를 묻는 get_horoscope일 확률이 96.12%라는 것을 보여준다. 위와 같이 rasa nlu를 사용해 챗봇 시스템을 학습하고 추론하기 위해서는 간단한 아래 과정을 거친다.
1. 챗봇 구현 범위 설정
2. 데이터셋 생성 (data.json)
3. 모델 학습
4. 추론
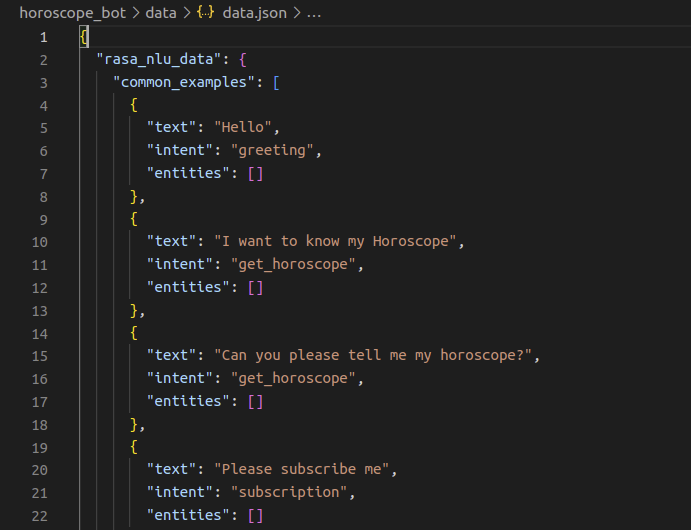
네 가지지만 사실상 챗봇 구현 범위 설정과 데이터셋 생성이 대부분이다. 챗봇 구현 범위 설정이란 모종의 태스크를 수행하는 챗봇을 만든다 가정할 때 사용자가 어떤 종류의 의도를 가질 수 있을지 정하는 것이다. 가령 음식점에서 사용할 수 있는 챗봇을 만든다면 손님은, 주문하거나 결제하거나 화장실 위치를 묻거나 인사하거나 기타 의도를 가진 말을 할 것이다. 이러한 사용자 발화의 범위 설정이 챗봇 시스템 구현의 첫 단계이다. 이후엔 데이터셋 생성이다. rasa nlu를 통해 학습하기 위해서는 json 형태로 데이터를 만들어야 한다. 별자리를 알려주는 태스크를 학습하기 위해 생성한 데이터셋의 예시는 아래와 같다.
기본적으로 예상되는 사용자의 발화를 text에 입력하고 그에 따른 라벨이 되는 인텐트의 종류를 입력해준다. 빈 칸의 엔티티는 현재 별자리 운세를 알려주는 태스크에서는 사용되지 않는다. 하지만 간단한 설명을 하자면, 엔티티는 범주를 의미하는 것으로 가령 음식 주문 할 때 A라는 음식 2개를 가져달라고 요청할 수 있다고 가정하면 "음식 종류"라는 엔티티는 "A"라는 값을 가질 것이고 "음식 수량"이란 엔티티는 '2'라는 값을 가질 것이다. 이처럼 하나의 인텐트에는 여러 엔티티를 가질 수 있는 것이 특징이다.
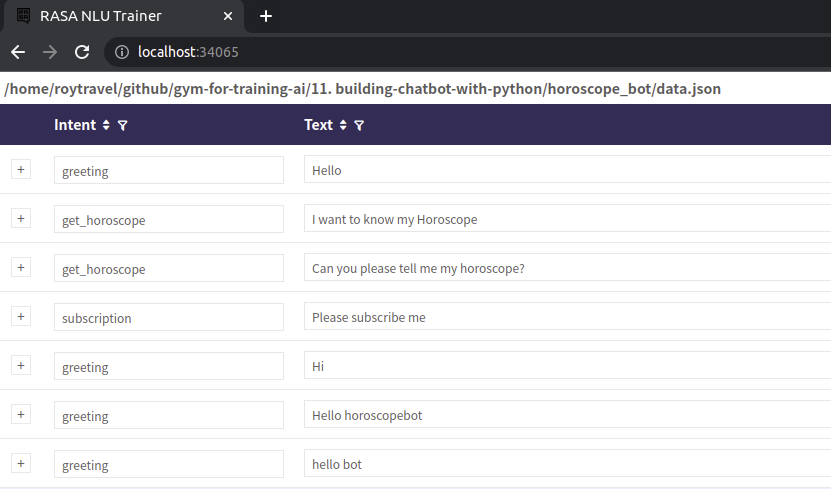
위와 같이 사용자 발화 별 인텐트와 엔티티를 지정하기 위해서 직접 json 포맷으로 작성해줄 수 있지만 쉽게 작성할 수 있는 웹 인터페이스가 있으면 좋을 것이다. rasa에서는 rasa-nlu-trainer라는 웹 인터페이스를 통해 데이터셋을 만드는 작업을 쉽게 할 수 있도록 한다. 일종의 annotation 도구인 것이다. rasa-nlu-trainer는 node.js 기반으로 동작하기 때문에 별도로 node.js를 설치해주어야 하고 sudonpm i -g rasa-nlu-trainer라는 명령어를 통해 설치할 수 있다. 여기서 i는 install이고 g는 global을 뜻한다. 이를 실행하게 되면 다음과 같이 웹으로 쉽게 데이터셋을 만들 수 있도록하는 인터페이스를 제공한다.
데이터셋을 직접 만드는데 가장 시간이 많이 걸릴 것이다. 가급적이면 공개되어 있는 것을 가져올 수 있겠지만 내가 원하는 특정 태스크를 수행하기 위해서는 대부분 커스터마이징이 필요할 것이고 이에 따른 데이터는 직접 구축하는 경우가 많을 것이다.
Rasa Core
rasa nlu를 통해 예측된 intent에 따라 챗봇의 응답과 동작이 이루어질 것이다. 이 때 사용하는 것이 rasa core이다. rasa core를 통해 챗봇 응답과 챗봇 동작을 명시할 수 있다. 챗봇에서 동작을 'Action'이라 한다. rasa core를 사용하면 과거의 대화내역을 기반으로 챗봇이 해야할 다음 Action을 예측하는 모델을 생성할 수 있다. 이를 위해 가장 먼저 도메인 파일이라 불리는 것을 만들어 주어야 한다. 도메인 파일이란 쉽게 말해 어떤 주제 속에서 대화가 이뤄지는지 정의하는 파일이다. 음식점에서 사용할 챗봇이면 도메인이 음식점이 되는 것과 같다. 이 도메인 파일은 크게 5가지 내용을 포함 해야한다. 1. 인텐트 2. 엔티티 3. 슬롯 4. 템플릿 5. 액션이다. 도메인 파일은 yml 확장자를 가지며 아래와 같은 형태로 정의할 수 있다.
1. 인텐트는 언급했듯 발화의 의도를 말한다.
2. 엔티티는 발화 속 캐치해야 할 핵심 키워드를 뜻하고
3. 슬롯은 키워드가 채워질 공간을 말한다. 별자리 별 운세를 알려주는 태스크에서는 월/일을 알아야 하므로 MM, DD같은 슬롯이 정의될 수 있다.
4. 템플릿은 말 그대로 인텐트에 대한 기본 응답을 뜻한다. 여러 개의 기본 응답을 만들어 랜덤으로 사용한다면 다양하기에 사용자 경험에 있어 친근감을 줄 수 있는 요소가 될 것이다.
5. 액션은 사용자 발화에 따라 어떤 행동을 취할 수 있을지를 정의하는 것이다.
이렇게 도메인 파일 내에 5개의 요소를 넣어 yml 파일로 정의했으면 다음으론 거의 끝으로 스토리 파일을 만들어 주어야 한다.
스토리 파일이란 대화가 어떤 시나리오로 흐를 수 있는지 정의한 파일이다. 파일은 마크다운 확장자로 만들어준다. 예시는 아래와 같다.
간단하다. 첫 번째 스토리는 챗봇이 사용자에게 인사하고 별자리가 무엇이냐고 물어본다. 이후 Capricorn(마갈궁자리)라는 응답을 받아 slot에 채워주고 현재 별자리 운세를 가져와서 보내주고 이 서비스를 구독하겠는지 묻고 끝나는 상황이다. 두 번째 스토리는 첫 번째와 달리 챗봇이 인사한 다음 사용자가 바로 별자리를 알려주고 cancer(게자리)라는 정보를 slot에 채우고 현재 별자리 운세를 가져와 사용자에게 전달하고 이 서비스를 구독하겠는지 묻고 사용자가 구독한다는(True) 발화를 캐치한 다음 구독자 목록에 추가하는 프로세스로 이뤄지는 것을 알 수 있다.
사용자는 미리 정의된 템플릿에 따라 액션을 취할 수 있지만 이는 정적이다. 예컨데 운세를 가져오거나 구독자 추가와 같은 동적으로 이뤄저야 하는 것은 별도의 API를 사용해 외부 데이터베이스와 연결될 필요가 있다. 이 때는 Custom 액션이라 하여 파이썬 스크립트를 별도로 만들어 주어야 한다. 간단한 코드 예시는 다음과 같다.
오늘 별자리 별 운세를 가져오기 위해 GetTodaysHoroscope라는 클래스를 만들어주고 내부에 run이라는 비즈니스 로직을 작성해줄 수 있다. run의 매개변수로 크게 dispatcher, tracker, domain이 들어가는 것을 알 수 있다. 먼저 tracker는 현재 상태 추적기로 슬롯에 접근해 값을 가져올 수 있고 이외에도 최근 사용자의 발화 정보 내역들에 접근할 수 있다. dispatcher는 별자리 정보를 기반으로 운세를 알려주는 API 호출 결과를 사용자에게 전달하는 역할을 한다. domain은 글자 그대로 이 챗봇의 도메인을 의미한다. 마지막으로 보면 SlotSet이 있는데 이는 추후 사용자 발화 정보를 히스토리로 활용하기 위해 슬롯이라는 공간에 저장하는 것이다.
마지막으로 학습은 아래와 같이 간단한 로직으로 이루어진다.
""" Training a chatbot agent """
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
from rasa_core import utils
from rasa_core.agent import Agent
from rasa_core.policies.keras_policy import KerasPolicy
from rasa_core.policies.memoization import MemoizationPolicy
from rasa_core.policies.sklearn_policy import SklearnPolicy
import warnings
import ruamel
warnings.simplefilter('ignore', ruamel.yaml.error.UnsafeLoaderWarning)
if __name__ == "__main__":
utils.configure_colored_logging(loglevel="DEBUG")
training_data_file = "./data/stories.md"
model_path = "./models/dialogue"
agent = Agent("horoscope_domain.yml", policies=[MemoizationPolicy(), KerasPolicy(), SklearnPolicy()])
training_data = agent.load_data(training_data_file)
agent.train(
training_data,
augmentation_factor=50,
epochs=500,
batch_size=10,
validation_split=0.2
)
agent.persist(model_path)
main을 살펴보면 1. 로깅 설정 2.스토리 파일 경로 설정 3. 모델 저장 경로 설정 4. 다음 액션을 가져오는 에이전트 세팅 5~6. 학습, 마지막으로 에이전트 오브젝트(모델)를 지정된 경로에 저장하여 재사용하는 로직으로 구성된다. 이렇게 해주면 에이전트 모델 학습이 이루어진다. rasa nlu를 통해 추론한 사용자 발화 의도를 기반으로 rasa core를 통해 학습한 에이전트로 다음 챗봇 Action을 수행할 수 있다.
이 포스팅은 『밑바닥부터 시작하는 딥러닝』을 기반으로 작성되었습니다. 간단한 이론이지만 누군가에게 설명할 수 있는가에 대해 생각한 결과, 올바르게 설명하지 못한다고 판단되어 이를 쇄신하고자 하는 마음으로 작성합니다.
신경망 학습과 손실함수
신경망을 학습한다는 것은 훈련 데이터로부터 매개변수(가중치, 편향)의 최적값을 찾아가는 것을 의미한다. 이 때 매개변수가 얼마나 잘 학습되었는지를 어떻게 판단할 수 있을까? 방법은 손실함수(loss function)을 사용하는 것이다. 손실함수란 훈련 데이터로부터 학습된 매개변수를 사용하여 도출된 출력 신호와 실제 정답이 얼마나 오차가 있는지를 판단하는 함수이다. 다시 말해 학습된 신경망으로부터 도출된 결과 값과 실제 정답이 얼마나 차이가 나는지를 계산하는 함수이다. 값의 차이를 손실이라고 말하며 신경망은 이 손실함수의 값이 작아지는 방향으로 매개변수를 업데이트 하게 된다.
그렇다면 신경망의 학습을 위해 사용하는 손실함수의 종류들은 무엇이 있을까? 종류를 논하기에 앞서 손실함수는 풀고자하는 태스크에 따라 달라질 수 있다. 예를 들어 머신러닝 태스크는 크게 분류 태스크와 회귀 태스크가 있을 것이다. 분류 태스크라고 한다면 이 사진이 강아지, 고양이, 원숭이 중 어디에 해당할지 분류 하는 것이다. 분류 태스크의 특징은 실수와 같이 연속적인 것이 아니라 정수와 같이 불연속적으로 정확하게 강아지, 고양이, 원숭이 중 하나로 나눌 수 있다. 반면 회귀 태스크는 연속이 아닌 불연속적(이산적)인 값을 가지는 태스크를 수행하는 것을 의미한다. 예를 들어 사람의 키에 따르는 몸무게 분포를 구하는 태스크일 경우 몸무게와 같은 데이터는 실수로 표현할 수 있기 때문에 출력 값이 연속적인 특징을 가지는 회귀 태스크라 할 수 있다.
그렇다면 손실함수의 종류와 특징들에 대해서 알아보도록 하자.
손실함수 (Loss Function)
평균제곱오차 (Mean Squared Error, MSE)
여러 종류의 손실함수 중 평균제곱오차라는 손실함수가 있다. 이 손실함수를 수식으로 나타내면 다음과 같다.
$$ MSE = {1\over n}\sum_i^n(\hat{y}_i - y_i)^2 $$
간단한 수식이다. 천천히 살펴보자면, $\hat{y}_i$는 신경망의 출력 신호이며 $y_i$는 실제 정답이다. $n$은 학습 데이터 수를 의미한다. 이를 해석하자면 출력(예측) 신호와 실제 정답 간의 차이를 구한다음 제곱을 해준 값을 데이터셋 수 만큼 반복하며 더해주는 것이다. 제곱을 해주는 이유는 음수가 나오는 경우를 대비하여 마이너스 부호를 없애기 위함이다. $1\over n$를 곱해주는 이유는 평균 값을 구해주기 위함이다. 즉 MSE를 한마디로 이야기하면 오차의 제곱을 평균으로 나눈다고 할 수 있다. 따라서 MSE는 값이 작으면 작을 수록 예측과 정답 사이의 손실이 적다는 것이므로 좋다.
출력 신호인, 예측 확률 output이 가지고 있는 가장 높은 확률 값과 정답이 차이가 적을수록 손실 함수의 출력 값도 적은 것을 확인할 수 있다. 반면 가장 높은 확률이 정답이 아닌 다른 곳을 가리킬 때 손실함수의 출력 값이 커지는 것을 확인할 수 있다. 위에서 볼 수 있듯 평균제곱오차(MSE)는 분류 태스크에 사용 된다.
교차 엔트로피 오차 (Cross-Entropy Error, CEE)
위와 달리 회귀 태스크에 사용하는 손실함수로 교차 엔트로피 오차가 있다. 수식으로 나타내면 다음과 같다.
$$ CEE = -\sum_i\hat{y_i}\ log_e^{y_i} $$
$\hat{y_i}$는 신경망의 출력이며 $y_i$는 실제 정답이다. 특히 $\hat{y_i}$는 one-hot encoding으로 정답에 해당하는 인덱스 원소만 1이며 이외에는 0이다. 따라서 실질적으로는 정답이라 추정될 때($\hat{y_i}=1$)의 자연로그를 계산하는 식이 된다. 즉 다시 말해 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정하게 된다.
실제로 구현할 때는 log가 무한대가 되어 계산 불능이 되지 않도록 하기 위해 delta 값을 더해주는 방식으로 구현한다. 예측 정답이 2번이고 실제 정답이 2번일 경우의 손실함수 값은 0.051이고 이와 달리 예측 정답이 2번이고 실제 정답이 7번일 경우 손실함수 값은 2.302가 된다. 즉, 정답에 가까울수록 손실함수는 줄어들고 오답에 가까울수록 손실함수는 커진다고 볼 수 있다. 신경망의 목표는 이러한 손실함수의 값을 줄이는 방향으로 학습하는 것이다.
이 포스팅은 『밑바닥부터 시작하는 딥러닝』을 기반으로 작성되었습니다. 간단한 이론이지만 누군가에게 설명할 수 있는가에 대해 생각한 결과, 올바르게 설명하지 못한다고 판단되어 이를 쇄신하고자 하는 마음으로 작성합니다.
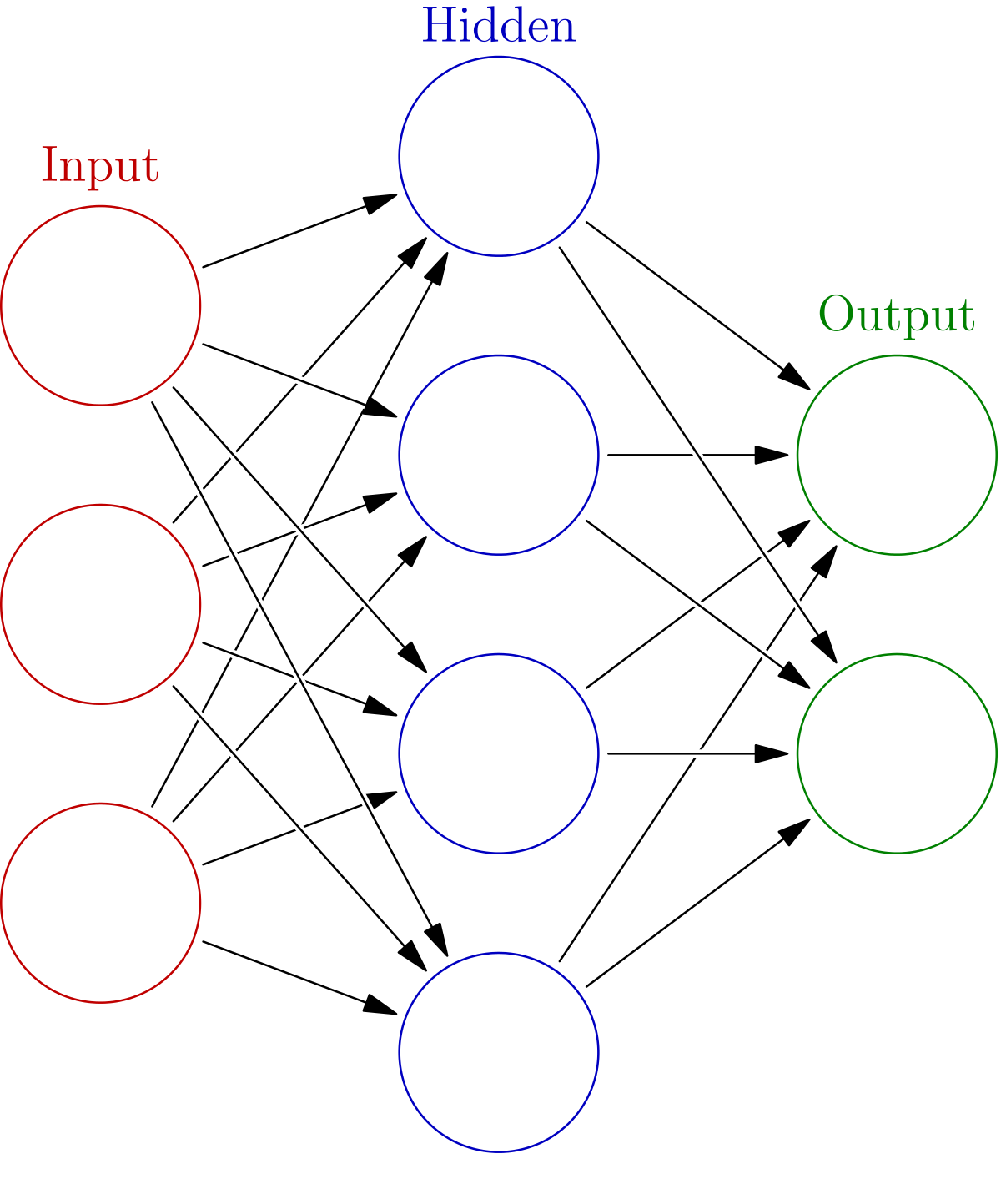
1. 신경망의 구조 (Structure of Neural Network)
신경망(neural network)의 구조는 아래와 같이 심플하게 입력 레이어(Input layer), 은닉 레이어(hidden layer), 출력 레이어(output layer)로 총 3개의 레이어(layer)로 구성된다.
신경망 구조 (Structure of Neural Network)
위 신경망의 구조는 레이어가 3개이므로 3층 레이어라고 표현하지만, 정확히는 입력 레이어와 은닉 레이어 사이, 은닉 레이어와 출력 레이어 사이에 있는 가중치를 기준으로 하기 때문에 2층 레이어라 표현하는 것이 일반적이다. 입력 레이어와 출력 레이어는 하나씩 존재한다. 하지만 은닉 레이어를 여러 개 쌓음으로써 신경망의 층을 깊게(크게) 만들 수 있게 된다.
2. 활성화 함수 (Activation Function)
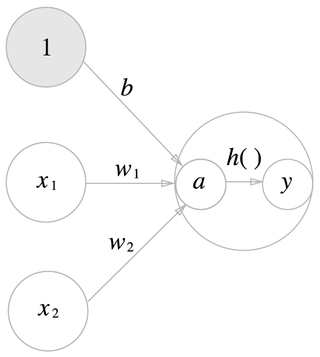
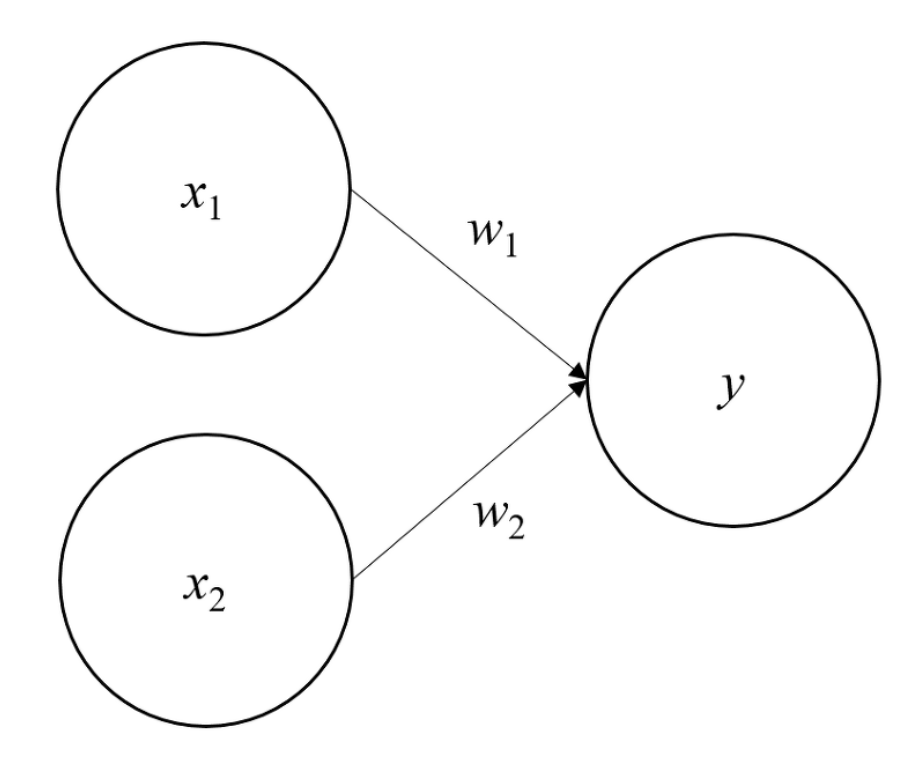
위 그림에서 보는 신경망은 퍼셉트론(Perceptron)과 어떻게 다를까? 본질적으로 신경망과 퍼셉트론은 구조적으로 동일한 형태이다. 하지만 핵심 차이점은 활성화 함수의 차이이다. 그렇다면 활성화 함수란 무엇일까? 아래 그림을 확인해보자.
위 그림에서 활성화 함수는 $h()$이다. $h()$의 역할은 입력 신호(x1, x2)와 가중치 (w1, w2)를 곱한 것과 편항(b)의 합인 $a$를 기준으로 활성화 할지(1) 활성화 하지 않을지(0) 여부를 결정하는 함수이다.
다시 말해 간단하게 퍼셉트론을 구성했던 수식은 1)과 같다. 이 때 활성화 함수는 입력 신호와 가중치의 곱 그리고 편향의 합을 입력으로 하는 수식 2)가 된다. 수식 2)의 활성화 함수 $h()$를 통해 신호의 합이 활성화(1) 할지 활성화 하지 않을지(0) 표현하는 함수이다.
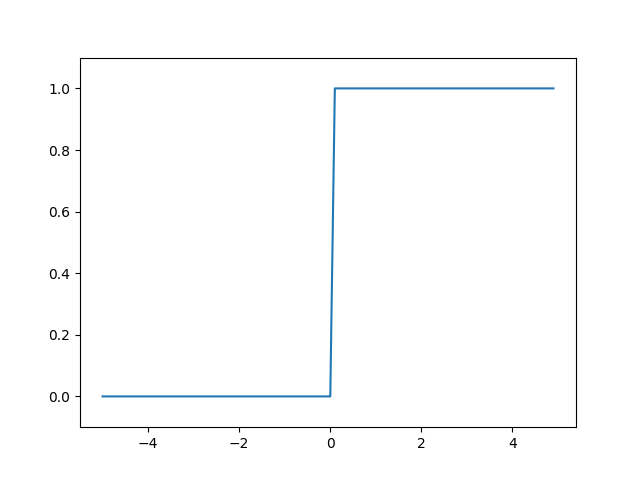
퍼셉트론은 위와 같이 활성화 함수로 계단형 함수를 사용했다. 계단형 함수란 값이 연속적(continuous)이지 않고 이산적(discrete)인 특징을 갖는 함수를 말한다. 예컨데 계단 함수를 코드로 구현한 것과 그래프로 나타낸 것은 다음과 같다.
2.1 계단 함수 구현과 그래프 (Step Function & Graph)
import numpy as np
import matplotlib.pyplot as plt
def step_function(x):
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
간단히 다시 말해 계단 함수는 x가 0보다 크면 활성화(1) 작으면 비활성화(0)를 하는 것이다. 계단 함수는 x=0을 기준으로 하여 비활성화(0) 활성화(1)가 뚜렷하게 나뉜다.
계단 함수 (step function) 그래프
퍼셉트론은 이러한 계단 함수를 사용하는 데, 이러한 계단 함수의 단점은 비연속적/이산적이기 때문에 “매끄러움”을 갖지 못한다는 것에 있다. 따라서 이 퍼셉트론을 신경망으로 동작해줄 수 있게 하기 위해서는 비연속적인 활성화 함수가 아닌 연속적인 활성화 함수를 사용해야 한다. 즉 다른 말로 비선형 활성화 함수를 사용해야 하는 것이다. 대표적인 비선형 활성화 함수에는 시그모이드(Sigmoid) 함수가 있다.
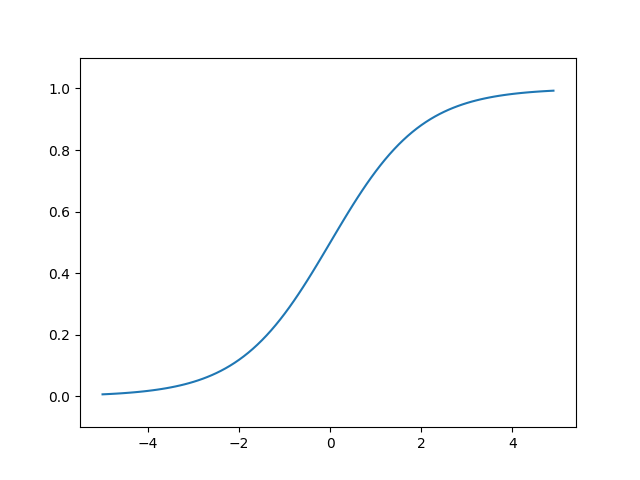
2.2 시그모이드 함수 구현과 그래프 (Sigmoid Function & Graph)
시그모이드(Sigmoid) 함수란 S자 형태의 띠는 함수를 의미한다. 신경망(뉴럴넷)에 사용되는 대표적인 비선형 활성화 함수로 간단하게 코드로 구현한 것과 함수의 그래프는 다음과 같다.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
간단하게 코드를 설명하면 시그모이드 함수는 내부적으로 자연상수 $e(=2.7182...)$를 사용한다. 자연상수를 기반으로한 시그모이드 함수는 계단 함수와 마찬가지로 동일한 입력 신호 $x$를 입력으로 준 뒤 그래프로 나타내면 아래와 같다.
시그모이드 함수 (sigmoid function) 그래프
계단 함수와 비교해 연속적이고 매끄러운 형태를 갖는 다는 것을 확인할 수 있다. 앞서 설명했듯 퍼셉트론과 신경망의 핵심 차이는 활성화 함수라고 했다. 퍼셉트론의 경우 이산적인 정수를 출력(0, 1)하는 반면 신경망의 경우 연속적인 실수를 출력(0.1, 0.2, 0.3, ...) 한다. 그렇다면 왜 매끈한 형태를 갖는 비선형 함수가 신경망과 퍼셉트론의 차이를 결정짓는 것일까?
그 이유는 이산적인 특징을 갖는 선형 함수를 사용하게 된다면 층을 깊게 하는 것에 의미가 없기 때문이다. 예를 들면 선형 함수 $h(x) = cx$가 있다고 가정할 경우 3층으로 쌓으면 $y(x) = h(h(h(x)))$가 된다. 하지만 이 계산은 $y(x) = ax$와 동일한 식이다. 단순히 $a=c^3$이라고 치환하면 끝인 것이다. 즉, 은닉층 없는 네트워크로 표현이 가능하게 된다. 이와 같은 예시처럼 선형 함수를 이용하면 여러 층으로 구성하는 신경망의 이점을 살릴 수 없다. 따라서 층을 쌓는 이점을 얻기 위해서는 활성화 함수를 반드시 비선형 함수를 사용해야 한다.
그렇다면 또 다른 비선형 함수들의 종류와 특징들은 어떤 것들이 있을까? 추가적으로 더 알아보자.
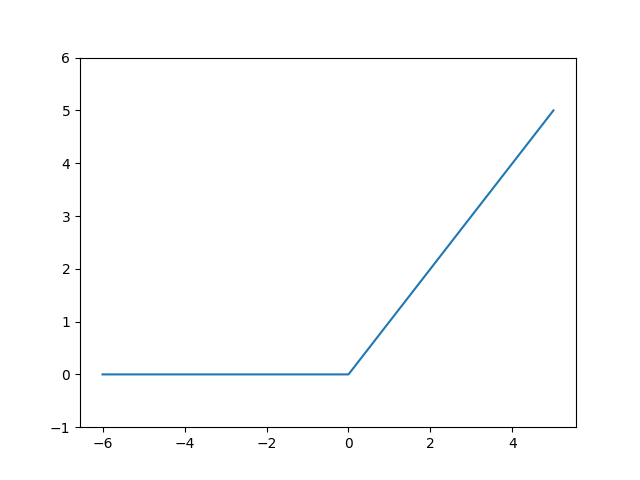
2.3 ReLU 함수 구현과 그래프 (ReLU Function & Graph)
시그모이드 함수는 신경망에서 자주 사용되었으나 최근에는 시그모이드 대신 ReLU를 주로 사용한다. ReLU란 입력 값이 0보다 작으면 0을 출력하고 0보다 크면 입력 값을 그대로 출력하는 함수이다. 코드로 구현한 것과 ReLU 함수를 그래프로 나타낸 것은 아래와 같다.
import numpy as np
import matplotlib.pyplot as plt
def ReLU(x):
return np.maximum(0, x)
x = np.arange(-6, 6, 1)
y = ReLU(x)
plt.plot(x, y)
plt.ylim(-1, 6)
plt.show()
렐루 함수 (ReLU function) 그래프
다시 말해 입력 값이 0보다 작으면 0으로 출력하고 입력 값이 0보다 크다면 입력 값을 그대로 출력한다. 하지만 이런 ReLU 함수의 한계점은 한 번 활성화 값이 0인 출력값을 다음 레이어의 입력으로 전달하게 되면 이후 뉴런들의 출력 값이 모두 0이 되는 현상이 발생하는 것이다. 이를 dying ReLU라 하며 이러한 한계점을 개선하기 위해 음수 값을 일부 표현할 수 있도록 개선한 활성화 함수들이 사용된다. 그 종류로는 LeakyReLU, ELU, PReLU, ThresholdReLU, Softplus, Swish 등이 있다.
2.4 항등 함수 및 소프트맥스 함수의 구현과 그래프
출력층의 활성화 함수는 풀고자 하는 문제에 적합한 활성화 함수를 사용해야 한다. 예를 들면 분류 문제와 회귀 문제가 있다. 분류 문제는 크게 이중 분류와 다중 분류로 나뉜다. 이중 분류를 한다면 시그모이드 함수를 사용하는 것이 적합하고, 다중 분류를 사용한다면 소프트맥스 함수를 사용하는 것이 적합하다. 그리고 회귀 문제의 경우는 항등 함수를 사용하는 것이 적합하다. 그렇다면 소프트맥스 함수와 항등 함수는 무엇일까?
먼저 항등 함수의 경우 ReLU와 비슷한 맥락으로 입력 값 자기 자신을 출력하는 함수를 의미한다. ReLU와 다른점이 있다면 음수 입력도 그대로 출력하는 것이다. 코드로 표현하면 아래와 같다.
def identity_function(x)
return x
소프트맥스 함수는 다중 분류에 사용된다 했다. 소프트맥스 함수를 한 마디로 표현하면 분류해야 할 출력 개수에 대해 각각의 확률을 출력하는 함수이다. 예를 들어 이 사진이 강아지, 고양이, 원숭이인지 분류해야할 다중 분류에는 어떤 한 사진이 입력 신호로 들어왔을 때 최종 출력으로 강아지일 확률 0.A%, 고양이일 확률 0.B%, 원숭이일 확률 0.C%로 표현하는 것이다. 이 때 소프트맥스 함수의 특징은 A+B+C = 1이 되는 것이다. 즉, 모든 출력 확률의 합은 1이 된다. 그렇다면 이런 소프트맥스 함수는 어떤 형태를 갖고 있을까? 그 형태는 다음과 같다.
$y_k = {exp(a_k)\over \sum_{i=1}^nexp(a_i)}$
여기서 $n$은 출력층의 뉴런 수(=분류해야할 크기), $exp$는 지수함수 $e^x$, $y_k$는 $k$번째 출력을 의미한다. 분모는 모든 입력 신호의 지수 함수 값의 합을 의미하고, 분자는 입력 신호의 지수 함수 값을 의미한다. 이를 코드로 구현하면 다음과 같다.
import numpy as np
a = np.array([0.3, 2.9, 4.0])
def softmax(x):
exp_a = np.sum(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
2.4.1 소프트맥스 함수 한계점과 개선
하지만 위와 같은 소프트맥스 함수에는 한가지 큰 단점이 있다. 바로 오버플로우 문제이다. 지수 함수의 특성상 과도하게 큰 수치의 값을 출력할 수 있게 되어 컴퓨터가 이를 올바르게 표현하지 못할 수 있다. 따라서 컴퓨터로 하여금 이러한 오버플로우 문제를 해결하기 위해서 소프트맥스 함수를 개선하여 구현하는 것이 일반적이다. 핵심 방법은 입력 신호 중 최대값을 빼는 것이다. 코드로 구현하면 다음과 같다.
import numpy as np
a = np.array([0.3, 2.0, 4.0])
def sofmtax(x):
maximum = np.max(a)
exp_a = np.exp(a-c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
즉 C라고 하는 임의의 정수를 곱해준 다음, $log$ 함수로 표현하여 지수 함수 내부로 옮겨준 뒤 마지막으로 $logC$를 $C'$로 치환해주는 식이다. 이러한 방식을 통해 오버플로우 문제를 개선한다. 이렇게 임의의 정수를 초기에 곱해주고 마지막으로 $C'$로 치환해도 함수 상 문제가 없는 것은 분모 분자 모두 동일한 임의의 정수 $C$를 곱해준 것이기 때문에 결론적으로 동일한 계산이 된다. 다른 말로 표현하면 소프트맥스 함수에서 내부적으로 사용되는 지수 함수인 $exp(x)$는 단조증가함수이기 때문에 가능한 것이다. 여기서 단조증가 함수란 $a\leq b$일 때 항상 $f(a)\leq g(b)$가 되는 함수를 의미한다.
이 포스팅은 『밑바닥부터 시작하는 딥러닝』을 기반으로 작성되었습니다. 간단한 이론이지만 누군가에게 설명할 수 있는가에 대해 생각한 결과, 올바르게 설명하지 못한다고 판단되어 이를 쇄신하고자 하는 마음으로 작성합니다.
1. 퍼셉트론(Perceptron)
퍼셉트론이란 여러 개의 입력 신호를 받아 하나의 출력 신호를 만들어내는 알고리즘이다. 1957년에 고안된 것으로 딥러닝의 기원이된 개념이다. 딥러닝을 이해하기 위한 가장 기초가 되는 개념이다. 그림으로 표현하면 아래와 같다.
퍼셉트론 구조
$x_1, x_2$는 퍼셉트론이라는 신경망 알고리즘의 입력 신호에 해당한다. $w_1, w_2$는 가중치(weight)로, 입력된 신호가 얼마나 중요한지를 표현하기 위한 매개변수이다. 가중치가 클수록 해당 신호가 그만큼 중요한 것이다. 가중치 $w$는 일종의 전류의 저항과 같이 흐름을 제어하는 요소로써 중요한 입력 신호는 더 큰 신호로 만들어주고 덜 중요한 신호는 비교적 작은 신호로 만들어 주는 역할을 한다. 딥러닝에서 학습을 한다는 것은 입력된 신호를 잘 나타내기 위해 $w_1, w_2$와 같은 가중치를 업데이트 하는 과정이라 할 수 있다. 입력 신호와 출력 신호에 해당하는 둥그런 원들을 뉴런 또는 노드라고 부른다. 입력 신호와 가중치의 곱셈합이 $y$가 되는데 수식으로 나타내면 아래와 같다.
$\theta \rightarrow -b$로 치환된 것에 불과하다. 여기서 $b$는 bias를 의미하는 것으로 입력 신호가 얼마나 쉽게 활성화(결과를 1로 출력)하는지를 조정하는 매개변수이다.
예를 들어 $b=-0.5$라면 입력신호와 매개변수의 합 $(x_1w_1+x_2w_2)$의 값이 0.5가 넘어야만 활성화 할 수 있는 것이다.
3. 논리게이트와 퍼셉트론의 한계
퍼셉트론을 통해 컴퓨터의 가장 기본이 되는 논리 게이트를 구현할 수 있다. 논리 게이트 종류는 AND, OR, XOR, NOR, NAND, NOT이 있지만 퍼셉트론을 통해서는 XOR을 구현할 수 없다. XOR이라는 논리게이트를 구현하지 못하는 것은 큰 의미를 갖는다. 논리 게이트는 컴퓨터에 있어 가장 근간이 되는 것이다. 컴퓨터에서 일어나는 연산은 모든 논리 게이트의 합이라 할 수 있다. XOR을 구현할 수 없다는 것은 기본이 되는 연산 중 하나를 못하게 되는 것으로, 복합 논리 연산을 하지 못한다는 것이다. 이 XOR 연산을 하지 못한다는 것이 퍼셉트론의 한계이다.
하지만 정확히는 하나의 층으로 이루어진 싱글레이어 퍼셉트론(single-layer perceptron)으로는 구현할 수 없다는 것이 한계이다. 이를 해결하는 방법이 퍼셉트론을 중첩해서 쌓는 멀티레이어 퍼셉트론(multi-layer perceptron)이다. 퍼셉트론의 아름다움은 여러 개의 층을 쌓는 멀티레이어 퍼셉트론에 있는 것이다.
예를 들면 위 퍼셉트론 기본 구조 그림에서 $x_1, x_2$은 0층이고 $y$는 1층으로 이루어진 싱글레이어 퍼셉트론이라 할 수 있다. 여기서 $x_1, x_2$와 $y$사이에 층을 하나 더 쌓게 되면 XOR 연산을 표현할 수 있게 된다. 이렇게 층이 하나씩 더 쌓일 때 마다 복잡한 회로를 만들 수 있게 되면서 다양한 논리 연산이 가능해진다.
NAVER CLOVA 이기창님의 『BERT와 GPT로 배우는 자연어 처리』 책 내용 요약과, 알고 있는 내용을 기반으로 각색하여 작성되었습니다. 이 책은 전반적으로 누구나 이해하기 쉬운 비유와 그림을 사용하고 핵심만 이야기 해주기 때문에 정보의 홍수로부터 자유로울 수 있다는 것이 장점인 것 같습니다. 쉬운 실습도 함께 포함되어 있어 자연어처리에 입문하는 사람이 보면 큰 맥락을 파악하기에 좋은 책이 되는 것 같습니다.
1. Transformer: 최근 자연어처리의 핵심 모델
최근 자연어처리를 이해하는 데 있어서 알아야 할 핵심 한 가지가 있다면 Transformer이다. 이 책에서 설명하는 BERT 모델과 GPT 모델은 모두 Transformer를 기반으로 하기 때문이다. BERT와 GPT 모델이 자연어처리 트렌드에 있어 의의가 있는 것은 크게 3가지 이유가 있다. 첫 번째는 Transformer를 통해 대규모 언어 모델 학습을 할 수 있게 되었고, 두 번째는 대규모 언어 모델 학습을 통해 전이 학습(Transfer Learning)이 가능해졌다는 것이며, 세 번째는 대규모 언어 모델 학습과 전이 학습을 통해 기존 존재하던 모델들의 성능을 압도했기 때문이다. 다른 말로 표현하면 자연어처리 패러다임의 변화(paradigm shift)를 가져온 것이다. Transformer에 대해 자세히 알기 전에 먼저 전이 학습이란 무엇인가를 살펴보자.
2. 전이 학습 (Transfer Learning)
전이 학습이란 쉽게 말해 축구, 배구, 농구, 탁구 등의 여러 운동을 넓게 미리 가르쳐 일종의 운동신경을 만들어두면 배우지 않았던 특정 종목인 피구, 야구도 쉽게 배울 수 있는 것을 의미한다. 물리학, 화학, 지구과학을 미리 배워두면 배웠던 지식들로 하여금 생명과학이라는 분야에도 "전이"를 통해 쉽게 배울 수 있는 것과 같다. 정리하자면 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법이라 할 수 있다. 이 전이 학습의 장점으로는 모델학습 속도 향상이 가능하고, 새로운 태스크를 더 잘 수행할 수 있다는 점이다. 이러한 전이 학습을 활용하는 대표적인 모델의 예시가 BERT와 GPT인 것이다. 전이 학습 방법은 크게 두 가지로 나뉜다. 업스트림 태스크(upstream task)와 다운스트림 태스크(downstream task)다.
2.1 업스트림 태스크 (upstream task)
업스트림 태스크는 쉽게 말해 일단 넓게 배우는 것이다. 넓게 배우기 위해 대규모 말뭉치(corpus)를 학습한다. 학습하기 위한 대표적인 방법으로 크게 2가지로 다음 단어(문장) 맞히기 (Next Sentence Prediction,NSP)와 빈칸 맞히기 (Masked Language Model, MLM)가 있다. NSP는 일종의 문장간의 연관성을 학습하여 어떤 단어 뒤에 나올 다음 단어는 무엇인가 맞히는 것이며, 빈칸 맞히기는 단어에 빈칸을 둔 뒤 이를 맞히는 것이다. 이러한 방법을 통해 업스트림 태스크를 수행하는 것을 pre-training이라고 한다. 대표적으로 BERT 모델은 위 두 가지 방식 모두를 사용하여 업스트림 태스크(=pre-training)를 수행하고, GPT는 NSP 방법만을 통해 업스트림 태스크를 수행한다.
NSP에 대해 조금더 구체적으로 이야기하면, "티끌 모아 __"일 때, "티끌 모아"는 문맥이 되고, "__"는 맞춰야할 다음 단어가 된다. 정답이 "태산"일 경우 태산에 대한 확률 값을 높이고 이외의 모든 단어는 확률을 낮추는 방향으로 모델을 업데이트 하는 것이다.
MLM 또한 예를 들어 "티끌 __ 태산"일 때, 티끌과 태산은 문맥이 되며 "__"은 맞혀야 할 빈칸 단어가 된다. 정답이 "모아"일 경우 "모아"에 대한 확률이 높아지며 이외의 단어는 확률이 낮아지는 방향으로 모델이 업데이트 된다.
이러한 업스트림 태스크의 장점은 self-supervised 학습이 가능하다는 것이다. 다른 말로 손수 라벨을 붙인 데이터가 필요한 지도 학습과 달리 수작업 라벨링 작업 없이 학습 데이터 생성이 가능하다는 것이다. 즉 데이터 내에서 정답을 생성하고 이를 바탕으로 학습하는 방법을 의미한다.
2.2 다운스트림 태스크 (downstream task)
다운스트림 태스크는 쉽게 말해 깊게 배우는 것을 의미한다. 업스트림 태스크를 통해 넓게 배운 다음 깊게 배우는 것이다. 다른 말로 downstream task는 실제로 구체적으로 풀고자하는 문제를 수행하는 것을 의미한다. 여러가지 task를 생성할 수 있지만 대표적인 예시는 아래와 같다.
- 문장 분류 (SC): → 문장에 대한 긍정, 부정, 중립에 대한 확률 값을 반환하는 태스크이다.
- 자연어 추론 (NLI) → 문장에 대한 참, 거짓, 중립 확률 값 반환하는 태스크이다.
- 개체명 인식 (NER) → 기관명, 인명, 지명 등 개체명 범주 확률값 반환하는 태스크이다.
- 질의 응답 (QA) → 질문이 주어질 때 답변에 대한 확률값을 반환하는 태스크이다 (각 단어가 정답의 시작일 확률값 + 끝일 확률값 반환
- 문장 생성 (SG) → 문장을 입력 받고 어휘 전체에 대한 확률 값 반환하는 태스크이다.
다운스트림 태스크에는 크게 3가지 방법이 존재한다. 파인 튜닝(fine-tuning)과 프롬프트 튜닝(prompt-tuning)과 인컨텍스트 러닝(in-context learning)이다.
2.2.1 파인튜닝 (fine-tuning)
다운스트림 태스크 데이터 전체를 사용하는 것으로, 모델 전체를 업데이트 하는 것이 특징이다. 단점으로는 언어 모델이 크면 클수록 모델 전체 업데이트에 필요한 계산 비용이 발생한다. 이러한 단점으로 인해 프롬프트 튜닝과 인컨텍스트 러닝이 주목을 받는다.
2.2.2 프롬프트 튜닝(prompt tuning)
다운스트림 태스크 데이터 전체를 사용해서 모델을 일부 업데이트 하는 방법을 의미한다.
2.2.3 인컨텍스트 러닝(in-context learning)
다운스트림 태스크 데이터 일부만 사용하는 방법으로 모델을 업데이트하지 않고 다운스트림 태스크를 수행하는 방법이다. 인컨텍스트 러닝은 크게 3가지 방식으로 나뉜다. 제로샷 러닝(zero-shot learning), 원샷 러닝(one-shot learning), 퓨샷 러닝(few-shot learning)이다.
- 제로샷 러닝: 다운스트림 태스크 데이터를 전혀 사용하지 않고 모델이 바로 다운스트림 태스크를 수행하는 것이다.
- 원샷 러닝: 다운스트림 태스크 데이터를 1건만 사용하는 것을 의미한다. 모델이 1건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 태스크를 수행한다.
- 퓨샷 러닝: 다운스트림 태스크 데이터를 몇 건만 사용하는 것을 의미한다. 모델은 몇 건의 데이터가 어떻게 수행되는지 참고한 뒤 다운스트림 태스크를 수행한다.
전이 학습에 대한 큰 범주의 내용은 위와 같다. 다음은 이제 Transformer란 무엇이고 BERT와 GPT에 어떻게 영향을 주었는지 알아보자.
3. 트랜스포머 (Transformer)
트랜스포머는 2017년 구글(Google)에서 제안한 시퀀스 투 시퀀스(sequence to sequence) 모델로 자연어처리를 위해 만들어졌고 이후에는 컴퓨터 비전에도 사용되고 있다(Vision Transformer). 앞서 말했듯 BERT와 GPT 또한 Transformer를 기반으로 만들어졌다. 트랜스포머 모델은 크게 인코더와 디코더로 구성되는데 BERT는 트랜스포머의 인코더, GPT는 트랜스포머의 디코더를 사용하여 만들어진 것이 특징이다. BERT는 Bidirectional Encoder Representation from Transformer의 약자이며 GPT는 Generative Pre-trained Transformer의 약자이다. 이름에서 모두 Transformer가 사용된 것을 알 수 있다. 트랜스포머에 대해 구체적으로 알아보기 위해 간단히 배경, 활용, 특징, 구조에 대해 차례대로 알아보자.
3.1 트랜스포머 모델 탄생 배경
트랜스포머 모델이 나오게 된 배경은 기존 자연어 처리 모델의 단점 때문이다. 트랜스포머 모델은 시퀀스 투 시퀀스 모델이라 했다. 이 시퀀스 투 시퀀스 모델을 처리하는 기존의 모델은 RNN 계열 모델이었다. 대표적으로 LSTM이 있었는데 이 방식의 단점은 크게 2가지 였다. long-term dependency 문제와 비병렬성 문제였다. long-term dependency 문제란 문장의 길이가 길고 단어 사이의 간격이 클수록 모델이 "잊게" 되어 단어 간의 관계 파악이 어려워지는 문제이며, 비병렬성의 경우 문장을 처리하는데 있어 LSTM 모델이 순차적으로 처리하기 때문에 시간 복잡도가 높다는 단점이다. 이를 극복하는 모델이 바로 트랜스포머 모델이다. 병렬처리를 통해 속도가 빠르면서도, 긴 문장 또한 관계 파악을 분명하게 처리할 수 있는 것이다.
3.2 트랜스포머 모델 활용 및 특징
이러한 트랜스포머 모델이 활용된 부분은 자연어처리 태스크 중 기계번역에 가장 처음으로 사용되었다. 예를 들면 소스 언어 (source language)인 한국어를 타겟 언어(target language)인 영어로 번역하는 것이다. 인코더를 통해 소스 언어의 시퀀스를 압축하며, 디코더를 통해 타겟 언어의 시퀀스를 생성하는 것이다.
소스 언어: 어제, 카페, 갔었어, 거기, 사람, 많더라
타겟 언어: I, went, to, the, cafe, there, were, many, people, there
여기서 특징은 소스 언어의 길이(시퀀스)와 타겟 언어의 길이(시퀀스)가 달라도 해당 태스크를 수행할 수 있다는 것이다. 트랜스포머의 특징 중 하나는 임의의 시퀀스나 속성이 다른 시퀀스 변환 작업 또한 가능하다. 예를 들면 필리핀 앞바다 한 달치 기온 데이터를 기반으로 1주일간 하루 단위 태풍 발생 예측이 가능하다. 즉, 기온 시퀀스로 태풍 발생 여부 시퀀스를 예측할 수 있는 것이다.
트랜스포머의 최종 출력값 즉, 디코더의 출력은 타겟 언어의 어휘 수 만큼의 차원으로 구성된 벡터이다. 학습은 인코더와 디코더에 입력이 주어질 때 정답에 해당하는 단어의 확률값을 높이는 방식으로 수행된다. "어제 카페 갔었어 거기 사람 많더라"라는 입력이 들어갈 경우 출력으로는 "I went to cafe there were a lot of people"이 나오는데, 이 때 가장 처음 번역되어야 할 "I"에 대한 확률값이 높아지고 나머지 went, to, cafe, there, were, a, lot, of, people는 확률값이 낮아지고 "I"다음에 나올 단어는 "went"일 때 "went"에 대한 확률값이 높아지고 나머지 단어는 확률이 낮아지는 것이다.
트랜스포머의 활용에 있어 특징 중 하나는 학습 도중의 디코더 입력과 학습 후 인퍼런스 때의 디코더의 입력이 다르다는 것이다. 학습 과정에는 디코더의 입력에 맞혀야 할 단어가 went라면 이전의 정답 타겟 시퀀스인 "<s> I"를 입력한다. 반면 인퍼런스 과정에는 현재 디코더 입력에 직전 디코딩 결과를 사용한다.
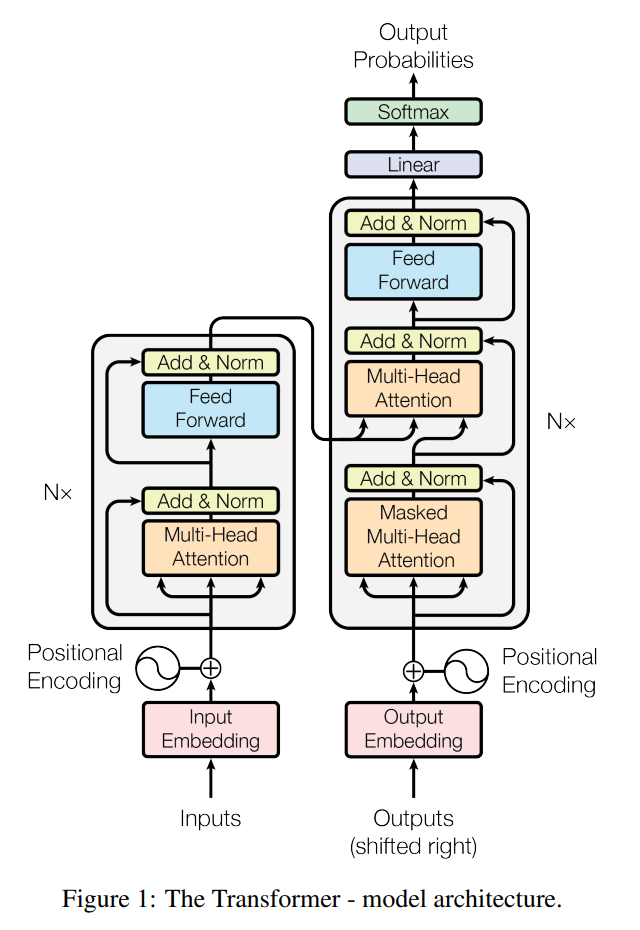
3.3 트랜스포머 모델 구조
트랜스포머 모델은 앞서 언급한대로 아래와 같이 크게 인코더와 디코더로 구성되어 있다.
왼쪽 회색 박스에 해당하는 영역이 인코더이며 오른쪽에 회색박스에 해당하는 영역이 디코더이다. 실제 트랜스포머를 사용할 때는 인코더를 N개 디코더를 N개 만큼 쌓아 사용한다. 인코더와 디코더에는 공통적인 요소는 멀티 헤드 어텐션(Multi-Head Attention), 피드포워드 뉴럴넷(Feedforward Neural Network), 잔차 연결 & 레이어 정규화(Residual-Connection & Layer Normalization)이다. 그 중 트랜스포머 모델의 가장 핵심이 되는 것은 멀티 헤드 어텐션이다. 따라서 먼저 멀티 헤드 어텐션에 대해 알아보자.
3.3.1 셀프 어텐션(self attention)
트랜스포머가 다른 sequence to sequence 모델에 비해 경쟁력을 가질 수 있는 원천은 셀프 어텐션(self attention)에 있다. 정확히는 멀티 헤드 어텐션인데 이 멀티 헤드 어텐션이란 단순히 셀프 어텐션을 여러 개(head)를 붙인 것에 불과하다. 먼저 어텐션(attention)이란 단어 시퀀스 요소 중 중요한 요소에만 집중해 특정 태스크의 성능을 올리는 기법을 뜻한다. 앞서 언급한대로 셀프 어텐션은 RNN의 단점인 long-term dependency 문제와 비병렬성 문제를 극복하는 방식으로 동작한다. 또한 어텐션은 CNN의 단점 또한 극복하는 방법이기도 하다. CNN의 단점은 컨볼루션 필터의 크기를 넘어서는 문맥을 읽어내기 어렵다는 것이다. 때문에 어텐션은 RNN과 CNN의 핵심 단점인 전체 문맥을 고려할 수 없다는 것을 극복하는 방법이다. 개별 단어와 전체 입력 시퀀스를 대상으로 어텐션 계산을 진행하는 방식으로 동작한다. 모든 경우의 수를 고려하기 때문에 지역적 문맥만 고려할 수 있는 CNN보다 강하며, 시퀀스의 길이가 길어도 RNN처럼 정보를 잊거나 (기울기 소실로 인해) 정보가 왜곡되지 않는다. 셀프 어텐션은 이 어텐션 개념을 자신에게 수행하는 것이다. 가령 "I love you"라는 시퀀스가 있을 경우 아래와 같이 모든 경우의 수에서 어텐션 스코어를 계산해 특정 시퀀스 요소(I, love, you)가 어떤 것과 가장 연관성이 높은지 판단한다.
I → I
I → love
I → you
love → I
love → love
love → you
you → I
you → love
you → you
3.3.1.1 셀프 어텐션 동작 원리
셀프 어텐션의 어텐션 스코어를 계산하기 위해 필요한 것은 Query, Key, Value이다. 다른 말로 셀프 어텐션이란 Query, Key, Value의 세 요소 사이의 문맥적 관계성을 추출하는 과정이라할 수 있다. Query, Key, Value로부터 문맥적 관계성을 추출하는 절차는 아래와 같다.
(1) Query, Key, Value 생성 하기
먼저 Q, K, V 행렬을 생성해야 한다. 이는 입력 벡터 시퀀스인 $X$를, 랜덤 초기화된 행렬 $W_Q$, $W_K$, $W_V$과 곱해서 Q, K, V 행렬을 생성한다. 수식으로 나타내면 아래와 같다.
$Q = X \times W_Q$
$K = X \times W_K$
$V = X \times W_V$
이후 $W_Q, W_K, W_V$세 행렬은 태스크를 잘 수행하는 방향으로학습 과정에서 업데이트 된다.
(2) 셀프 어텐션 출력값 계산
(1)의 과정을 통해 Q, K, V 행렬을 계산했다면 셀프 어텐션을 계산할 수 있게 된다. 과정을 단일 수식으로 나타내면 다음과 같다.
이를 풀어서 이야기하면 $Q \times K^T$한 뒤, 모든 요소 값을 $K$ 차원 수의 제곱근으로 나누고(if 차원 = 3, $d_K=3$), 이 행렬을 행 단위로 소프트맥스를 취해 스코어 행렬로 만들어 주는 것이다. 그리고 이 스코어 행렬에 V를 행렬곱하면 셀프 어텐션 계산이 된다.
이러한 수식을 가지게 되는 이유는 다음과 같다.
1. $QK^T$라는 내적을 통해 시퀀스 요소 간의 유사도를 구할 수 있다. 예를 들어 $Q$에는 I, love, you라는 시퀀스가 올 경우 3개의 행과 전체 어휘 차원수의 열을 가지게 되고, $K^T$는 I, love, you라는 시퀀스가 3차원 열을 만들고 전체 어휘 차원수 만큼이 행이 되는 것이다. 결과적으로 $QK^T$는 I, love, you라는 시퀀스 간의 유사도, 정확히는 벡터의 유사도를 구할 수 있는 것이다.
2. $\sqrt{d_K}$로 나누어줌으로써 안정적인 경사값(gradient)를 계산할 수 있게 된다. 참고로 이러한 셀프 어텐션에서 $QK^T$의 내적을 계산한 다음 $\sqrt{d_K}$로 나누는 것을 스케일 닷 프로덕트 어텐션(scaled dot product attention)이라고도 부른다.
3. softmax 함수를 통해 정규화를 한다. 이를 통해 모든 요소는 0~1 사이의 값을 갖게 된다. 참고로 softmax 함수를 수식으로 나타내면 $softmax (x_i)= {exp(x_i) \over \sum_jexp(x_j)}$이다.
멀티 헤드 어텐션이란 앞서 언급한대로 셀프 어텐션을 동시에 여러 번(multi-head) 수행하는 것을 의미한다. 여러 헤드가 독자적으로 셀프어텐션을 계산하는 것이다. 비유를 하자면 같은 문서(입력)를 두고 여러 명(헤드)이 함께 읽는 것이다. 여러 번의 셀프 어텐션을 수행하여 결과값을 더함으로써 일종의 앙상블 효과를 낸다. 치우치지 않고 정확성이 높은 결과를 도출할 수 있는 것이다.
개별 헤드의 셀프 어텐션 수행 결과 = $\times$ $W^O$
$W^O$의 크기 = 셀프 어텐션 수행 결과 행렬 열 수 $\times$ 목표 차원 수
최종 수행 결과 → 입력 단어 수 $\times$ 목표 차원 수
여기까지 트랜스포머의 구성요소 중 멀티 헤드 어텐션에 대해 알아보았다. 다음으로는 피드포워드 뉴럴넷, 잔차 연결, 레이어 정규화, 드롭 아웃에 대해 알아보자.
3.3.2 피드포워드 뉴럴넷(feedforward neural network)
피드포워드 뉴럴넷의 구성요소는 DNN의 형태로 Input layer, hidden layer, output layer로 3가지로 구성되어 있으며, 피드포워드 뉴럴넷의 학습대상은 weight와 bias이다. 흔히 알고 있는 가장 기본적인 뉴럴넷 구조이다.
3.3.3 잔차 연결(residual connection)
잔차 연결이란 블록 또는 레이어 계산을 건너뛰는 경로를 하나 두는 것을 의미한다. 책의 그림상 3개의 잔차 연결을 두면 8개의 새로운 경로가 생기는 것을 확인할 수 있었다. 이러한 잔차 연결의 역할은 모델이 다양한 관점에서 블록이나 레이어 계산을 수행 가능하다. 딥러닝 모델은 레이어가 많아질수록 학습이 어려워진다. 그이유는 모델 업데이트를 위한 gradient가 전달되는 경로가 길어지기 때문이다. 하지만, 잔차 연결을 통해 모델 중간에 블록을 건너뛰는 경로를 설정함으로써 학습을 쉽게하는 효과가 있다.
3.3.4 레이어 정규화(layer normalization)
미니 배치 인스턴스 별로 평균 ($\mathbb{E}[x])$을 빼주고 표준편차($\sqrt{\mathbb{V}[x]}$로 나눠 정규화를 수행하는 기법이다. 이를 통해 학습이 안정되고 속도가 빨라지는 효과를 얻을 수 있다. 레이어 정규화에 사용되는 수식 요소는 엡실론($\epsilon$), 감마($\\gamma$), 베타($\beta$)이다. 감마, 베타는 학습 과정에서 업데이트 되는 가중치이며 엡실론은 분모가 0이 되는 것을 방지하기 위해 사용된다. 보통 $1e^{-5}$로 설정한다. 딥러닝 프레임워크 중 하나인 파이토치에서 레이어 정규화를 위한 LayerNorm 객체는 감마와 베타를 각각 1과 0으로 초기화 하며 이후 업데이트 과정을 거친다.
3.3.5 드롭아웃(dropout)
드롭아웃은 트랜스포머에서 추가적인 요소로 더 나은 일반화를 위해 사용된다.드롭아웃은 과적합(overfit) 방지 기법으로 모델이 표현력이 좋아서 외워버리는 것을 방지한다. 드롭아웃을 적용할 때 딥러닝 프레임워크 중 하나인 파이토치의 특징은 torch.nn.Dropout을 사용할 때 안정적인 학습을 위해 각 요소 값에 1/(1-p)를 곱하는 역할을 수행한다. 예를 들면 드롭아웃 비율을 p=0.2로 설정할 경우 1/(1-p)에 의해 드롭아웃 적용후 살아남은 요소값에 각각 1.25를 곱하게 된다. 드롭아웃은 일반적으로 0.1을 사용한다. 또 드롭아웃은 학습 과정에만 적용하고 인퍼런스에는 적용하지 않는 것이 특징이다.
4. 토큰화
토큰화란 문장을 작은 단위로 분리하는 것을 의미한다. BERT와 GPT와 같은 자연어처리 모델에 입력을 위해서 우선적으로 토큰화 절차를 필요로 한다. 토큰화 방법은 크게 3가지가 존재한다. 단어 단위, 문자 단위, 서브워드 단위이다..
단어 단위 토큰화 (word-level)
단어(어절) 단위로 토큰화를 수행하는 것을 의미한다. 예시로는 "어제 카페 갔었어"라는 문장은 "어제", "카페", "갔었어"로 분리 되는 식이다. 이 방식의 단점은 가능한한 많은 단어에 대해 고려해야 하기 때문에 어휘 집합(lexical set)의 크기가 커질 수 있고, 커지면 모델 학습이 어려워지게 된다.
문자 단위 토큰화 (character level)
문자 단위로 토큰화를 수행하는 것을 의미한다. 문자 단위란 ㄱ, ㄴ, ㄷ, ㄹ / a, b, c, d를 의미한다. 참고로 한글로 표현 가능한 글자는 총 11,172개이다. 문자 단위 토큰화 방식의 장점은 해당 언어의 모든 언어를 포함할 수 있기 때문에 미등록된 토큰(Out Of Vocabulary, OOV) 문제로부터 자유롭다. 반면 단점으로는 각 문자 토큰은 의미있는 단위가 어렵다는 것이다. 예를 들면 "어제"의 어와 "어미"의 어의 구분이 사라지게 된다. 또한 토큰 시퀀스 길이가 길어지기 때문에 학습 성능이 저하된다는 단점도 존재한다. 예시로는 "어제 카페 갔었어" → 어, 제, 카, 페, 갔, 었, 어로 변환되어 토큰 시퀀스가 길어지는 것이다.
서브워드 단위 토큰화 (sub-word level)
단어 단위 토큰화와 문자 단위 토큰화의 중간 형태로 둘의 장점만 취한 것이다. 특징은 어휘 집합의 크기가 지나치게 크지도 않고, 미등록 토큰 문제를 해결하며, 토큰 시퀀스가 너무 길어지지 않게 하는 특징을 가진다. 대표적인 구현 예시가 BPE (Byte Pair Encoding)이다.
4.1 Byte Pair Encoding (BPE)
BPE는 1994년에 처음제안된 정보 압축 알고리즘이다. 하지만 근래에는 자연어처리의 토큰화 기법으로 사용된다.(BPE는 기계 번역분야에서 가장 먼저 쓰임) 토큰화를 진행 할 때 빈도수 높은 문자열을 병합해 데이터를 압축한다. 압축 알고리즘의 동작 절차 예시는는 다음과 같다.
1. aaabdaaabac가 있을 때 빈도수가 가장 높은 aaa를 Z로 치환해 ZabdZabac로 치환한다.
2. 다음 빈도수가 높은 ab를 Y로 치환해 ZYdZYac로 만든다.
3. ZY를 다시 X로 치환하여 XdXac로 치환한다.
기존의 어휘수는 (a, b, c, d) 였으나 압축 어휘수는 (a, b, c, d, Z, Y, X)로 늘었고, 압축 전 글자수는 11글자에서 압축 후 글자수는 5글자가 되었다. 이러한 BPE 알고리즘의 장점은 사전 크기 증가를 적당히 억제하면서도 정보를 효율적으로 압축 가능하며, 분석 대상 언어에 대한 지식이 필요하지 않다는 것이다. 이러한 BPE 알고리즘의 대표적인 활용 예시는 GPT 모델에서 사용된다. GPT 모델은 BPE를 통해 토큰화를 수행한다. 반면 BERT는 wordpiece로 토큰화를 수행한다.
4.2 BPE 어휘 집합 구축
BPE 어휘 집합은 구축은 한 마디로 요약하면 고빈도 bi-gram 쌍을 병합하는 방식으로 구축한다. 구체적으로는 먼저, pre-tokenize를 통해 corpus의 모든 문장을 공백기준으로 나눈다. 이후 사용자가 정의한 크기(어휘 집합)이 될 때 까지 가장 높은 빈도수대로 추가한다. 높은 빈도수란 n-gram을 기준으로 하며, 일반적으로 성능과 계산량의 trade-off 관계로 인해 5-gram 아래를 사용하는 것이 좋다고 알려져 있다.
4.3 WordPiece (워드피스)
워드피스 알고리즘 또한 토큰화를 수행하는 방법 중 하나로 자주 등장한 문자열을 토큰으로 인식한다는 점에서 BPE와 본질적으로 유사성을 가진다. 차이점으로는 병합 기준에 있다. 워드피스는 BPE 처럼 단순 빈도수 기반이 아니라, 우도(likelihood)를 가장 높이는 쌍을 병합하는 것이다. 한 마디로 워드피스는 우도를 가장 높이는 글자 쌍을 병합한다.
4.4 어휘 집합 구축하기
BPE & wordpiece 기반 토크나이저 만들기
Q. 왜 wordpiece에는 special char인 [PAD]를 사용하지 않는가? 정확히는 BPE는 special char [PAD]를 추가해주는데 wordpiece tokenizer에는 그런 과정이 없는가?
A. ?
Q. 왜 위 둘의 결과물은 유니코드로 되어 있어 보기 힘들까?
A. 학습 데이터가 한글이고, 한글은 3개의 유니코드 바이트로 표현됨. GPT 모델은 바이트 기준 BPE를 적용하기 때문임.
indexing: 토큰 → 인덱스
예시: “별루 였다..” → 4957, 451, 363, 263, 0, 0, 0, ...
input_ids: vocab.txt 또는 vocab.json에 순서대로 부여된 번호로 나타내는 토큰 인덱스 시퀀스
attention_mask: 일반 토큰(1), 패딩 토큰(0) 구분하는 역할
token_type_ids: BERT 모델은 기본적으로 문장 2개 이상을 입력받기에 문장 번호를 이것으로 구분
5. Pretrained Language Model (PLM)
언어 모델이란 단어 시퀀스에 확률을 부여하는 모델이다. 수식은 $P(w_1, w_2, w_3, ..., w_n)$로 표현 가능하다. 넓은 의미에서의 언어 모델은 맥락이 전제된 상태서 특정 단어(w)가 나타날 조건부 확률이다. 수식으로는 $P(w|context)$로 표현 한다. 예시는$P(운전|난폭) = {P(난폭, 운전) \over P(난폭)}$이다. 만약 잘 학습된 한국어 모델이 있을 경우 $P(무모|운전)$ 보다 $P(난폭|운전)$이 확률이 더 높을 것이다.
단어가 3개 동시에 등장 확률은 $P(w_1, w_2,w_3) = P(w_1) * P(w_2|w_1) * P(w_3|w_1,w_2)$이 된다.
언어 모델을 조건부 확률로 다시 쓰면, $P(w_1, w_2,w_3, w_4, \dots, w_n) = \prod_{i=1}^nP(w_i|w_1,w_2,w_3,\dots,w_{i-1})$이다.
언어 모델 종류에는 크게 순방향과 역방향이 있다. 순방향의 예시는 "어제 → 카페 → 갔었어 → 거기 → 사람 → 많더라" 순으로 순차적으로 예측하는 것을 의미한다. 대표적인 예시로는 GPT와 ELMo가 이 방식으로 pretrain을 수행한다. 역방향의 예시는 "많더라 → 사람 → 거기 → 갔어어 → 카페 → 어제"로 역순으로 예측하는 것을 의미한다. 대표적으로 ELMo가 이 방식으로 pretrain을 수행한다. 참고로 ELMo는 순방향, 역방향을 모두 활용하는 기법이다.
5.1 마스크 언어 모델(Masked Language Model)
마스크 언어 모델이란 학습 대상 문장에 빈칸을 만들고 빈칸에 올 적절한 단어를 분류하는 과정으로 학습하는 것이다. 대표적으로 BERT가 이 방식을 이용하여 업스트림 태스크를 수행한다. 마스크 언어 모델의 장점은 문장 전체의 맥락을 참고 가능하다는 것이다. 때문에 마스크 언어 모델에 양방향 성질이 있다고 말한다.
5.2 스킵-그램 모델(skip-gram model)
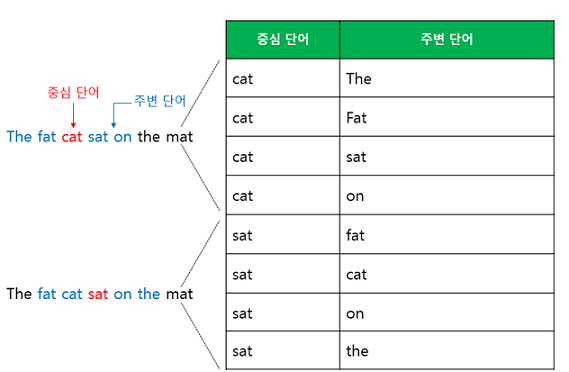
단어 앞뒤 특정 범위(window size)를 지정 후, 범위 내에 어떤 단어 올지 분류하는 과정으로 학습하는 것이다. 예시로는 window size = 2라 가정할 경우, 아래와 같이 center word 앞 뒤로 2개씩 단어(context word)가 있고 context word를 기반으로 center word를 예측(분류)하는 방식이다.
어제카페갔었어거기사람 많더라
어제 카페갔었어거기사람많더라
6. 자연어 처리 태스크 종류
6.1 문서 분류 태스크
문서 분류 모델은 (이 책에서 사용하는) 입력 문장을 토큰화한 뒤 [CLS]와 [SEP]를 토큰 시퀀스 앞뒤에 붙인다. 이후 BERT 모델에 입력하고 문장 수준 벡터인 pooler_output을 뽑는다. 이 벡터에 추가 모듈을 덧붙여 모델 전체의 출력이 긍정 확률, 부정 확률 형태로 만든다.
pooler_output 벡터 뒤 붙는 추가 모듈은 pooler_output 벡터에 드롭아웃 적용 일부를 768차원중 일부를 0으로 변경한다.
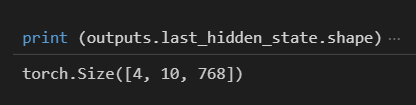
만약 분류 대상이 2가지라면 가중치 행렬 크기는 768 * 2가 됨.
여기서 pooler_output이란 무엇일까? pooler_output은 메서드의 하나로 last_hidden_state라는 메서드와 연관이 있다. pooler_output과 last_hidden_state는 모두 BERT 모델에서 단어와 문장을 벡터로 변환한 것이다. 구체적으로 pooler_output은 BERT 모델에서의 최종 출력값인 벡터 시퀀스이다. 예를 들어 768차원으로 임베딩된다 가정하고, 입력 문장이 [”안녕하세요”, “저의”, "이름은“, "로이입니다”]일 경우 pooler_output은 4 x 768의 shape을 가지게 된다. 즉 아래와 같은 형태로 특정 단어에 대한 확률값을 벡터를 가진 요소이다. (예시를 위해 확률값은 임의 설정함)
안녕하세요 = [0.01, 0.04, 0.09, ... , 0.02]
저의 = [0.02, 0.03, 0.04, ... , 0.01]
이름은 = [0.04, 0.07, 0.09, ... , 0.09]
로이입니다 = [0.03, 0.06, 0.01, ... , 0.1]
이러한 pooler_output을 다르게 말해 문장 수준 임베딩이라 할 수 있다. 다시 말해 4개의 문장(단어)이 768차원의 벡터로 바뀐 것이다. 1개의 벡터 (1x768)은 하나의 문장 전체를 표현한다. pooler_output 메서드를 통해 이 결과값을 확인할 수 있다.
반면 last_hidden_state는 단어 수준 임베딩을 의미하는 것으로 예를 들어 4x10x768의 3차원 형태로 표현될 수 있다. 이는 4개의 문장이 길이 10을 가지고 있고, 768차원 형태라는 것이다.
6.1.1 문서 분류 모델 학습하기
Korpora 라이브러리를 통해 데이터를 내려받을 수 있다. 문서 분류 모델 학습을 위해 NSMC 데이터셋을 다운로드 받는다. 이후 데이터로더를 통해 학습 데이터를 배치 단위로 모델에 공급한다. 배치 단위로 공급할 때 데이터셋 내에 있는 인스턴스를 배치 크기 만큼으로 뽑는다. 데이터셋이 100개가 있다고 가정할 경우 인스턴스는 개별 요소 1개가 되며 배치크기가 10이라면 인스턴스 10개가 모여 1개의 배치를 이루게 된다.
6.1.2 인퍼런스 실습
토크나이저 초기화
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
args.pretrained_model_name,
do_lower_case=False,
)
from transformers import BertConfig
pt_model_config = BertConfig.from_pretrained(
args.pretrained_model_name,num_labels=fine_tuned_model_ckpt["stte_dict"]["model.classifier.bas"].shape.numel(),
)
BERT 모델 초기화
from transformers import BertForSequenceClassification
model = BertForSequenceClassificiation(pt_model_config)
체크포인트 주입
model.load_state_dict({k.replace(”model.”, “”): v for k, v in fine_tuned_model_cpkt[’state_dict’].items()})
평가 모드 전환
model.eval()
6.2 문장 쌍 분류 태스크
문장 2개가 주어졌을 때 문장 사이 관계가 어떤 범주일지 분류하는 것을 의미한다. 두 문장 관계는 참(entailment), 거짓(contradiction), 중립 또는 판단 불가(neutral)로 가려낼 수 있다. 예를 들어 "나 출근했어 + 난 백수야"는 거짓이 된다. 반면 "나 출근했어 + 난 개발자다"면 중립이 되는 식이다. 문장 쌍 분류 태스크를 위해 업스테이지가 공개한 KLUE-NLI 데이터셋을 활용하여 실습을 진행하였다.
모델 구조
문장 쌍 분류 모델은 전제와 가설 두 문장을 사용한다. 따라서 "[CLS] + 전제 + [SEP] + 가설 + [SEP]"의 형태로 이어 붙인다. 이후 토큰화 후 모델에 입력한 뒤, 문장 수준 벡터(pooler_output)을 추출한다. pooler_output에는 전제와 가설의 의미가 응축되어 있음. 여기에 추가 모듈을 붙여 모델 전체 출력이 아래의 형태가 되도록 한다.
전제에 대해 가설이 참일 확률
전제에 대해 가설이 거짓일 확률
전제에 대해 가설이 중립일 확률
6.3 개체명 인식 태스크
범주 수가 m개이고 입력 토큰이 n개일 때 문서 분류, 문장 쌍 분류 모델은 모델 출력은 m차원의 확률 벡터 1개이다. 시퀀스 레이블링은 m차원 확률벡터가 n개 만들어진다.
방법론 입력 출력 대표 과제
문서 분류
문장 1개
한 문서가 속하는 범주에 대한 확률
감성 분석
문장 쌍 분류
문장 2개
두 문서를 아우르는 범주에 대한 확률
자연어 추론
시퀀스 레이블링
문장 1개
토큰 각각의 범주 확률
개체명 인식
6.4 질의응답 태스크
질의응답 태스크의 유형은 다양하지만 본 책에서는 지문(context)에서 답을 찾는 것으로함 즉, open-book qa이다.
모델의 입력은 질문과 지문(Question, Context)가 되며, 모델 출력은 입력한 각 토큰이 [정답 시작일 확률, 정답 끝일 확률]이 된다. 질의응답 모델은 출력 확률을 적당한 후처리 과정을 통해 사람이 이해 가능한 형태로 가공한다. 실습을 위해 LG CNS가 공개한 KorQuAD 1.0 데이터를 활용하였다. 모델 구조는 토큰화 후, "[CLS] 질문 [SEP] 지문 [CLS]"의 형태로 입력된다.
6.5 문장 생성 태스크
문장 생성은 컨텍스트(context)가 주어졌을 때 다음 단어로 어떤 단어가 오는 게 적절한지 분류하는 것이다. 모델 입력은 컨텍스트가 되며 모델 출력은 다음 토큰이 등장할 확률이 된다. 수식으로 일반화하여 나타내면 $P(w|context)$이다. 조금 구체적으로는 $P(w|안녕)$일 경우 "안녕" 다음에 올 단어의 확률이 출력된다. 이런 문장 생성 태스크는 문서 분류, 문서 쌍 분류, 개체명 인식, 질의응답 태스크와 특성이 다르다. 가장 큰 차이는 모델 구조이다.
모델 구조
GPT
BERT
pretrain task
다음 단어 맞히기
빈칸 맞히기
fine tuining
다음 단어 맞히기
각 다운스트림 태스크
GPT는 BERT와 달리 pretrain task와 fine tuning 자체가 다음 단어를 맞히는 것으로, 문장 생성 Task에 더 적합한 모델이라 할 수 있다.
6.5.1 토크나이저
eos_token은 문장 마지막에 붙는 스페셜 토큰으로 SK Telecom이 모델을 pretrain할 때 지정했으므로 같은 방식으로 사용
from transformers import PreTrainedTokenizerFast tokenier = PreTrainedTokenizerFast.from_pretrained( args.pretrained_model_name, eos_token=”</s>”, )
6.5.2 문장 생성 전략 수립
문장 생성을 위해서는문장 생성 전략 수립이 제일 중요하다. 이를 위해, 문장 생성을 위한 단어를 탐색하는 테크닉 종류 두 가지가 있다. 크게 빔서치와 그리드 서치로 나뉜다. 두 방법 모두 최고 확률을 내는 단어 시퀀스를 찾는 방법이다. 차이점이 있다면 빔서치의 계산량이 그리디 서치의 계산량보다 많다는 것이다. 그 이유는 그리디 서치는 최고 확률을 내는 한 가지 경우의 수를 내지만, 빔서치의 경우 빔 크기만큼의 경우의 수를 낼 수 있기 때문이다. 빔서치는 그리디 서치보다 조금 더 높은 확률을 내는 문장생성이 가능하다는 장점이 있다. 이런 빔서치와 그리드 서치에 도움을 주는 내부 파라미터가 4개 있다. repetition_penalty, top-k sampling, top-p sampling, temperature scaling이다.
repetition_penalty
반복되는 표현을 줄여주는 역할을 한다. default 값은 1.0이다. 만약 이 값을 적용하지 않는다면 그리디 서치와 동일한 효과를 낸다.
top-k sampling
모델이 예측한 토큰 확률 분포에서 확률값이 가장 높은 k개 토큰 가운데 하나를 다음 토큰으로 선택하는 기법이다. top_k를 1로 설정할 경우 그리디 서치와 동일한 효과를 낸다.
top-p sampling
확률값이 높은 순서대로 내림차순 정렬 후 누적 확률값이 p 이상인 최소 개수의 토큰 집합 가운데 하나를 다음 토큰으로 선택하는 기법이다. 뉴클리어스 샘플링이라고도 한다. 특징은 0에 가까울수록 후보 토큰이 줄어 그리디 서치와 비슷해지며, 1이 되면 모든 확률값을 고려하기 때문에 이론상 어휘 전체를 고려하게 된다.
템퍼러처 스케일링(temperature scaling)
토큰 확률 분포의 모양을 변경하는데 이는 모델의 출력 로짓의 모든 요소값을 temperature로 나누는 방식이기 때문이다. 예를 들어 로짓: [-1.0 2.0 3.0], temperature: 2라면 템퍼러처 스케일링 후 로짓은 [-0.5 1.0 1.5]가 된다. 이 템퍼러처 스케일링의 특징은 0에 가까울수록 확률분포모양이 원래보다 뾰족해진다. 또 1보다 큰 값을 설정할 시 확률분포가 평평(uniform) 해진다. 핵심은 이 값이 1보다 적으면 상대적으로 정확한 문장, 1보다 크면 상대적으로 다양한 문장이 생성되는 특징을 가진다. 템퍼러처 스케일링은 top-k 샘플링과 top-p 샘플링과 함께 적용해야 의미가 있다고 한다.
7. BERT와 GPT 비교와 모델 크기를 줄이는 기법
BERT는 의미 추출에 강점을, GPT는 문장 생성에 강점을 지닌다. BERT는 트랜스포머의 인코더를 사용했고 GPT는 디코더만을 사용했다. 최근 자연어처리 트렌드는 모델 크기를 키우는 것으로 크기를 키움으로써 언어 모델의 품질이 향상되고 다운스트림 태스크의 성능도 좋아지게 하는 것이다. 하지만 모델의 크기가 너무 커지면 계산 복잡도가 높아지는데 이러한 계산량 또는 모델 크기를 줄이려는 여러 시도가 있는데 대표적으로 4가지가 있다.
디스틸레이션 (distillation), 퀀타이제이션 (quantization), 프루닝 (pruning),파라미터 공유 (weight sharing)
8. 학습 파이프라인
자연어 처리 모델을 학습시키기 위한 일련의 파이프라인은 다음과 같다.
1. 하이퍼파라미터 설정 (learning rate, batch size, epochs, ...)
2. 학습 데이터셋 준비
3. pretrain된 모델 준비
4. tokenizer 준비
5. 데이터 로더 준비
6. 태스크 정의
7. 모델 학습
의 과정으로 이루어진다.
여기서 데이터 로더란 데이터를 모델의 입력에 필요한 형태인 배치(batch)로 만들어주는 역할을 한다. 배치를 만들기 위해 전체 데이터셋 가운데 일부 샘플(instance)를 추출해 배치로 구성한다. 배치 구성을 위한 인스턴스 추출방식에는 랜덤 샘플링과 시퀀셜 샘플링 방식이 있다. 랜덤 샘플링 방식은 주로 train 데이터셋을 구성할 때 사용되고 시퀀셜 샘플링은 valid, test 데이터셋을 구성할 때 사용한다. 배치란 인스턴스의 합이다. 여기서 인스턴스란 문장과 라벨을 갖는 하나의 가장 작은 요소이다. 여기서 인스턴스란 문장과 라벨을 갖는 하나의 가장 작은 요소이며, 인스턴스가 모여서 배치를 이루게 된다. 데이터 로더에는 컬레이트라는 과정이 있다. 컬레이트는 모델의 최종 입력으로 만들어주는 과정이다. 태스크 정의에는 주로 요즘은 파이토치 라이트닝을 사용한다. 그 이유는 딥러닝 모델 학습시 반복적인 내용을 대신 수행해줘 사용자가 모델 구축에만 신경쓸 수 있도록 돕기 때문이다.
Word2Vec의 내부 구조로 CBOW와 Skip-gram 방식이 있고 이 두 개의 아키텍처가 기존 NNLM 모델보다 뛰어남.
1. Word2Vec 모델의 배경
Word2Vec이라 불리는 이 논문의 핵심은 Word2Vec의 구조에 있다. 우선 Word2Vec은 단어를 분산 표상(distributed representation)하는 방법이다. 분산 표상이란 고차원 공간상에 단어를 continous하게 벡터화시키는 것이다. Word2Vec이 나오기 전인 2003년 가장 초기에는 NNLM(Nueral Network Language Model) 모델이라고 하여 단어를 컴퓨터로 하여금 이해 시키기 위해 내부적으로 one-hot encoding 방법을 사용했다. 하지만 이 one-hot encoding 방법의 sparse matrix라는 것이다. 예를 들면 one-hot encoding은 강아지, 고양이, 호랑이가 있을 때 강아지를 [1, 0, 0]으로, 고양이를 [0, 1, 0]으로 호랑이를 [0, 0, 1]로 표현하는 방식이다.
하지만 단점은 표현하고자 하는 단어의 수가 늘어날 수록, 단어를 표현하는 matrix의 크기가 커지지만 matrix 상에 실제 단어를 나타내는 위치 이외에는 전부 0으로 표현된다. 때문에 고차원 공간을 간헐적(?)으로 사용하므로 비효율적이다. 다른 말로 표현하면, one-hot encoding을 사용할 경우 단어를 discrete하게 학습시키는 것이다. 또한 sparse matrix의 단점은 단어간 유사도를 계산할 수 없다는 것이다. 예를 들면 big과 bigger는 의미상 유사성을 띠지만 one-hot encoding은 각각의 단어를 모두 일종의 독립된 개인으로 간주하기 때문에 유사성을 표현할 수 없다. 이러한 one-hot encoding 방식의 한계를 극복하기 위해 나온 것이 분산 표상 방법이다. 분산 표상 방식의 특징은 one-hot encoding과 달리 단어 벡터를 continuous하게 표현가능하다. 이 분산 표상 방식을 제안한 모델이 Word2Vec이다.
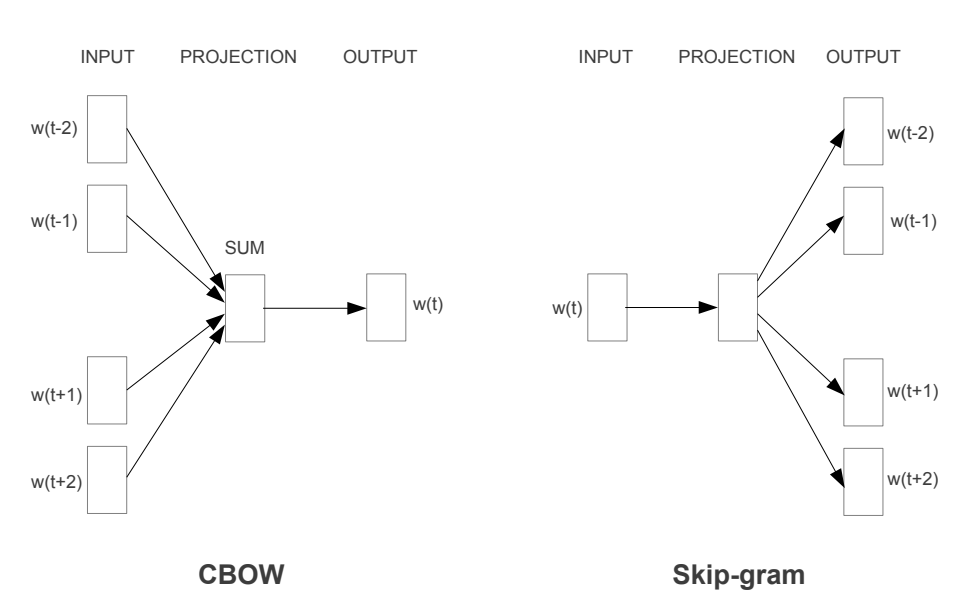
2. Word2Vec의 구조
앞서 언급한대로 Word2Vec 모델의 핵심은 그 구조에 있다. Word2Vec의 동작에는 내부적으로 2가지 방식이 있다. 첫 번째는 CBOW (continous Bag-of-Words)와 Skip-gram 방식이다. 아키텍처는 아래 그림과 같다.
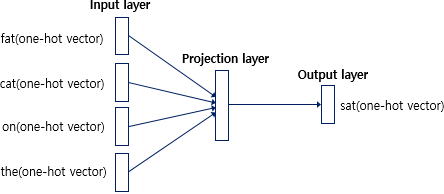
먼저 CBOW 방법은 주변 단어를 의미하는 context에 기반해 중심 단어(centric word)를 예측하는 방식이며, Skip-gram 방식은 중심 단어에 기반해 주변 단어를 예측하는 방식이다. CBOW와 Skip-gram 방식 모두 간단한 구조인 3가지 레이어로 구성되어 있다. Input layer, projection layer, output layer이다. 참고로 Input layer에는 one-hot encoding된 값이 들어가는데 그 이유는 word2vec 모델이 기본 뼈대를 NNLM 모델로 취했기 때문이다.
2.1 CBOW
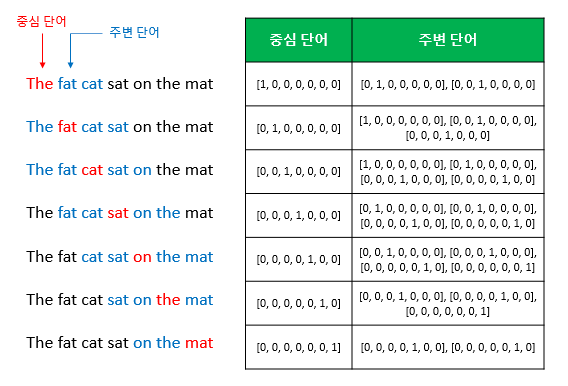
CBOW 방법을 통해 중심 단어를 예측하기 위해서는 주변 단어(앞뒤)의 개수를 결정해야 하는데 이를 window size를 통해 결정 가능하다. 예를 들어 window size가 2일 경우 앞뒤로 2개씩 하여 총 4개의 단어를 CBOW 모델의 입력으로 사용하는 것이다. 다음은 『딥러닝을 이용한 자연어 처리 입문』에서 가져온 CBOW의 동작 원리이다.
window size가 2인 경우 중심 단어를 예측 하기 위해 주변 앞뒤 단어를 2개씩 Input layer에 넣어주게 된다. 만약 중심 단어 앞에 window size만큼의 단어가 없을 경우 가능한 만큼만 입력으로 넣게 된다. 만약 "sat"을 예측하고 싶다면 아래와 같다.
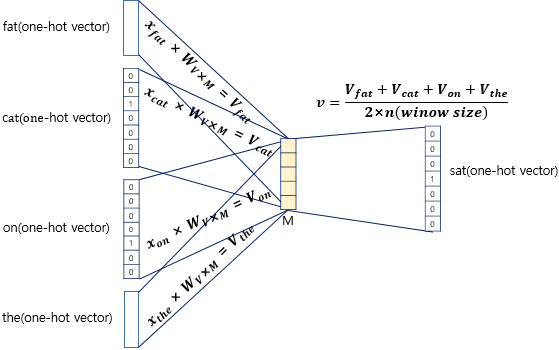
"sat"에 대한 one-hot encoding된 값인 one-hot vector를 output layer에 label로 두며, Input layer에는 window size 2에 의해 앞 뒤로 두 개의 단어를 one-hot encoding시킨 값을 Input layer에 입력으로 넣어주게 된다. Projection layer의 역할은 lookup table 연산을 담당한다. lookup table이란 주어진 연산에 대해 미리 계산된 결과들의 집합을 의미하는 행렬이다. 쉽게 말해 사전이라 표현할 수 있다. CBOW에서의 lookup table의 구체적인 연산 과정은 아래와 같다.
Projection layer는 M차원을 가진다. M은 하이퍼파라미터로서 임의로 설정될 수 있다. 기존의 one-hot vector의 차원인 7에서 Input layer를 거치게 되면 M이 된다. 위의 예시에서는 "The fat cat sat on the mat"의 단어의 개수인 7개를 차원으로 두고 W라하는 랜덤 초기화된 가중치 행렬과 계산하게 되면 M차원이 된다. W는 차원의 크기를 나타내는 V와 Projection layer의 크기를 나타내는 M의 곱으로 표현된다. 이 때 W를 살펴보면, Input layer에서 입력된 2번째 index에 1이라는 값을 가지는 one-hot vector와 가중치 행렬 W의 곱은 사실상 W 행렬의 2번째 행을 그대로 읽어 오는 것과 동일하다. 이 가중치 행렬 W를 lookup table이라 한다.
word2vec에 의해 단어가 학습되면 W가 업데이트 되는데 W의 각 행 벡터는 M차원, 위의 예시로는 5차원 임베딩 벡터로 표현된다. 예를 들면 2번째 index의 값인 cat이라는 단어는 5차원 임베딩 벡터로 [2.1, 1.8, 1.5, 1.7, 2.7]이라는 값을 갖게 된다. W'는 M차원 벡터에서 다시 one-hot vector가 가지고 있던 기존의 차원으로 바뀌는 과정에서 업데이트 된다. 일종의 decoding을 진행하며 가중치 행렬 W'를 학습시킨다 볼 수 있다. 구체적인 과정은 아래와 같다.
만약 중심 단어 sat을 예측하고자 하고, window size가 2일 경우 주변 단어를 총 2N개를 input layer에 입력해준다. 이후 가중치 행렬 W에 의해 생성된 결과 벡터들은 Projection layer에서 벡터들의 평균값을 구하게 된다. 이후 구해진 평균 벡터와 가중치 행렬 W'와 곱하여 기존의 one-hot vector와 같은 차원의 값이 도출된다. 여기서 output layer에 label인 "sat"을 예측하기 위해서 내부적으로 아래와 같이 softmax 함수를 사용한다.
softmax 함수를 사용하여 one-hot vector들의 각 원소를 0~1사이의 확률값으로 표현한다. 확률값 중 가장 높은 것이 중심 단어일 가능성이 가장 높은 것이다. 여기까지의 과정을 요약하면 CBOW는 주변단어로 중심 단어를 잘 예측하기 위해 W와 W'를 업데이트해 나가는 방법이라 할 수 있다.
이외의 CBOW의 특징은 기존의 BOW와 달리 continuous distributed representation을 사용한다. 또한 Input layer와 projection layer 사이의 가중치 행렬은 NNLM과 같은 방식으로 모든 단어 위치에 대해 공유된다. 또 순서가 projection에 영향을 미치지 않기 때문에 Bag-of-words라 한다.
2.2 Skip-gram
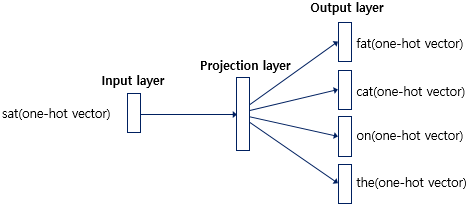
Skip-gram 방식은 CBOW 방식과 매우 유사하다. 다만 크게 2가지 차이점이 있다. CBOW는 주변단어로 중심단어를 예측했다면 Skip-gram 방식은 아래 그림과 같이 중심단어로 주변단어를 예측하는 것이 첫 번째이다.
두 번째는 Skip-gram의 Input layer의 입력 값이 중심단어 하나이기에 projection layer에서 벡터의 평균을 구하지 않는다는 것이다. Skip-gram의 전체 과정을 도식화 하면 아래와 같다.
Input layer에 중심 단어를 입력하며, 벡터 평균 계산이 없는 projection layer를 거쳐 주변단어의 label이 위치한 output layer로 학습이 이루어진다. Skip-gram이 CBOW보다 성능이 좋다고 알려져 있다 한다.
3. 모델 성능 및 결론
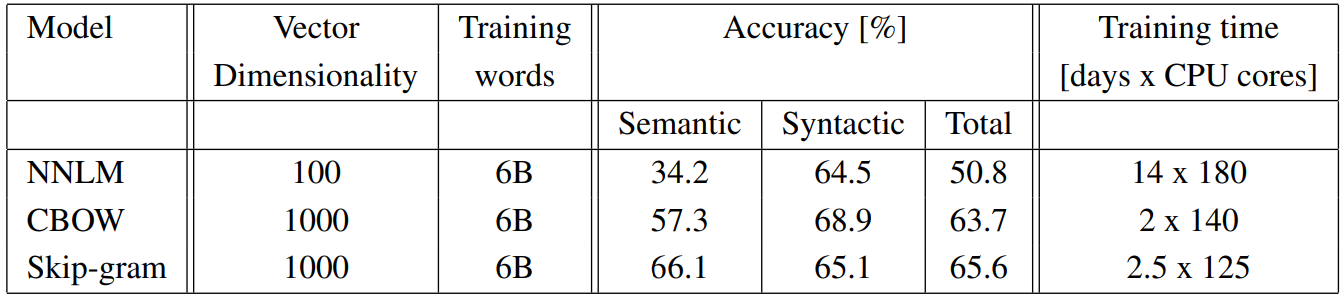
기존 모델은 RNNLM과 NNLM을 뛰어넘는 성능을 보임
여러 NNLM 변형과 CBOW, Skip-gram의 성능 비교 결과 저자들이 내세운 아키텍처의 성능이 전반적으로 높은 것을 확인 가능
논문에는 연구 배경이나 연구 목표들의 여러 내용이 있었지만 핵심만 요약하자면 Word2Vec의 구조인 CBOW와 Skip-gram 방식의 메커니즘이 그 핵심이며 또한 그 결과 CBOW와 Skip-gram 방식이 기존 NNLM 모델보다 뛰어나다는 것이다.
이외의 장점은
1. 벡터 산술 연산이 가능하다. ex: King - Man + Woman = Queen
2. Very simple한 모델 아키텍처로 고퀄리티로 단어 벡터를 학습 가능하다.
3. 기존 모델들 대비 낮은 계산 복잡도를 가진다.
4. continous representation of word를 계산하기 위해 기존엔 LSA, LDA를 사용했으나 word2vec은 LSA를 뛰어 넘었고 LDA는 이제 계산 비용이 높은 알고리즘이 되었다.
4. 기타 추가로 알게된 부분
word2vec은 feedforward NNLM의 한계인 context length 문제를 해결하기 위해 고안됨.
RNNLM에서의 벡터는 Context Vector 또는 Thought Vector라 부름
projection layer: 기존 입력층이 이산 표상인데 비해 입력층에서 넘어오게 되면 연속 표상으로 바뀜.
word2vec은 은닉층이 1개인 shallow NN임
word2vec은 일반적 은닉층과 달리 활성화 함수가 존재X, lookup table 연산을 담당하는 projection layer가 있음
DistBelief → 병렬 실행 가능이 핵심
모델을 여러개로 복제해서 병렬로 실행하고, 중앙집중화 서버를 통해 gradient 업데이트를 동기화가능하게 함.