multi-domain dialogue system의 기본적인 내용을 살펴보다 보니 2011년 논문까지 거슬러 올랐다. 이 논문은 multi-domain 챗봇 시스템에서 도메인을 어떻게 결정할 것이냐?는 문제에 대한 답을 한다. 이런 multi-domain 챗봇 시스템은 기존 single-domain 챗봇 시스템에서 새로운 도메인이 추가될 때 확장성이 요구되지만 이를 어떻게 충족시킬 수 있을까하는 물음으로부터 시작된 연구다. multi-domain 챗봇 시스템이 사용했던 기존의 방식은 사용자 발화에 대한 도메인을 결정하고 그 도메인에 해당하는 하위도메인 시스템이 결정되는 구조였다. 하지만 이는 한 가지 문제점이 있다. 만약 multi-turn일 경우 다음 이야기 하는 발화의 도메인이 이전에 했던 발화의 도메인과 의도치 않게 바뀔 수 있다는 것이다. 따라서 보통 이전 발화 정보에 가중치를 줘서 도메인 결정에 함께 사용했다고 한다. 하지만 이 방법 또한 한계점이 있다고 하는데 여기에 대해 언급된 바는 없었다. (유추해 보자면 가중치와는 무관하게 도메인이 추가될 때마다 새로 학습해야하는 것이 아닐까?)
다만 이 도메인 결정 문제를 해결하기 위해 3가지 요소를 사용했다. 단어, 화행, 이전 발화 도메인 정보다. 단어는 화자의 발화에 포함된 단어이고 화행은 용어에서 직관적인 이해가 되지 않았지만 예를 들어 만약 restaurant 도메인이면 ask_food, ask_location 등이 화행이다. 이전 발화 도메인 정보는 말 그대로 어떤 도메인인지를 말한다. 가령 이 논문에서는 아래와 같이 Weather, Resfinder, Songfinder, TVGuide라는 4가지 도메인을 사용했다.

딥러닝 연구가 막 약동하기 시작할 때 쯤이여서 사용한 모델은 통계기반의 최대 엔트로피 모델을 사용했다. 결과적으로 이전 발화도메인 정보와 화행을 추가했을 때 아래와 같이 성능이 제일 높게 나왔다고 한다.
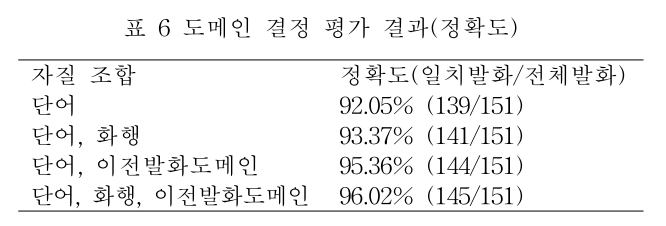
데이터셋이 적어서 일반화된 성능이라 보기는 어려울 것으로 보인다. 다만 이 논문을 통해 얻게 된 인사이트는 챗봇 시스템 구현에 있어서 이전 발화 도메인과 화행 정보를 고려해서 무분별한 도메인 전환이 이뤄지지 않도록 해야한다는 것이다. 아래의 대화 예제처럼 말이다.

또 도메인 결정 문제도 하나의 연구 주제가 될 수 있음을 알게 되었다. 최근 연구들에서는 어떻게 도메인 결정 문제를 해결하고 있을지 궁금해지는 대목이다.
'Artificial Intelligence > 논문 리딩&구현' 카테고리의 다른 글
| [논문 리뷰 #5] PPTOD 모델을 활용한 end-to-end 챗봇 시스템 설계 (0) | 2022.11.26 |
|---|---|
| [논문 구현] ResNet 파이토치로 구현하기 (0) | 2022.09.18 |
| [논문 구현] GoogLeNet 파이토치로 구현하기 (0) | 2022.09.12 |
| [논문 구현] VGGNet 파이토치로 구현하기 (0) | 2022.09.08 |
| [논문 구현] AlexNet 파이토치로 구현하기 (2) | 2022.09.07 |