에 대한 부정방정식 는 의 값이 의 배수일 때만 정수 해를 가진다 알려져있다.즉, 가 정수 해를 가지는 의 최솟값이 가 되는 것이다.따라서 확장 유클리드 알고리즘은 의 최대공약수를 구하는 것에 더 나아가, 를 만족하는 정수 해 도 구하는 알고리즘이라할 수 있다. 즉, 다음과 같다.
확장 유클리드 호제법을 이용하면 의 해가 되는 정수 짝을 찾아낼 수 있다. 특히 가 서로소인 경우 유용한데, 이와 같을 경우 이 되고, 여기서 a는 모듈러 연산의 곱의 역원이 되기 때문이다.
유클리드 확장 알고리즘 증명
유클리드 확장 알고리즘 증명에 앞서 먼저 유클리드 알고리즘은 다음과 같다.
두 양의 정수 a,b의 최대공약수 는 다음과 같은 절차를 거쳐 구할 수 있다.
만약 이라면, 가 바로 이다.
확장 유클리드 알고리즘의 경우 최대공약수 이외에도 다음을 만족하는 두 개의 정수 를 추가로 구할 수 있다.
초기 조건은 다음과 같다.
초기 조건을 대입하여 확인할 수 있으며, 1일 때 참이라 가정하고 수학적 귀납법을 사용하면 다음과 같다.
따라서 일 때, 는 가 된다.
모듈러 연산에서 곱셈에 대한 역원 구하기
법 에 대한 모듈러 연산에서 정수 의 곱셈에 대한 역원 은 다음을 만족하는 정수 로 정의한다.
모듈러 연산의 정의에 의해 를 만족하는 정수 가 존재해야하며 이는 다시 말해 다음을 만족하는 정수가 존재해야 한다는 의미이다.
와 의 최대공약수가 1, 즉 서로소이면 해가 존재하고 그렇지 않을 경우 은 존재하지 않는다.
그렇다면... (추가 기술 필요)
확장 유클리드 알고리즘 의사코드
#1
function extended_gcd(a, b)
s <- 0; old_s <- 1
t <- 1; old_t <- 0
r <- b; old_r <- a
while r ≠ 0
quotient <- old_r div r(old_r, r) <- (r, old_r - quotient * r)(old_s, s) <- (s, old_s - quotient * s)(old_t, t) <- (t, old_t - quotient * t)
output "Bézout coefficients:", (old_s, old_t)
output "greatest common divisor:", old_r
output "quotients by the gcd:", (t, s)
#2
// 초기화
r1 ← a, r2 ← b
s1 ← 1, s2 ← 0
t1 ← 0, t2 ← 1// 루프while(r2 > 0)
{
q ← r1 / r2
r ← r1 - q*r2
r1 ← r2
r2 ← r
s ← s1 - q*s2
s1 ← s2
s2 ← s
t ← t1 - q*t2
t1 ← t2
t2 ← t
}
예를 들어 7을 5로 나누면 2가 남으며 이러한 수는 7, 12, 17, 22, 가 될 수 있다.
이를 법 5에 ~대한 7의 잉여류/합동류라 표현할 수 있다.
합동의 정의
정수론에서는 합동을 를 으로 나눈 나머지가 같을 때, 와 가 법에 관하여 합동 (Congruence)이라고 하고, 으로 나타낸다.
두 정수 에 대해서 가 의 배수일 때, 와 는 을 법으로 합동(Congruent modulo m)이라한다.
합동의 기본 성질
이고,이면, 다음과 같다.
기약 잉여계와 완전 잉여계의 정의
기약 잉여계
가 법 에 대한 완전 잉여계일 때,여기서 과 서로소인 원소만 모은 집합을 법 에 대한 기약잉여계라 한다.
완전 잉여계
에서인 가 유일하게 있을 때,를 완전잉여계라고 한다.
기약 잉여계와 완전 잉여계의 예시
를 예시로 들면, 은 완전잉여계, 그리고 와 서로소가 아닌 를 제외한 는 기약잉여계가 된다. 기약잉여계가 중요한 이유는, 곱셈의 역원이 있다는 점 때문이다. 예컨대, 6에 대한 완전잉여계 와 그것의 기약잉여계 를 생각하자. 의 원소는 모두 곱셈 역원을 갖는다. 그러나, 다른 완전잉여계 원소는 그렇지 않다. 이는, 과 가 서로소일 때, 정수 가 존재하여 즉, 이기 때문이다.
역원의 정의
집합 와 이항연산자 *에 대해, 만약 항등원 e가 존재한다고 할 때, S의 원소 a에 대해
를 만족하는 의 원소 b가 유일하게 존재할 때, b를 a의 역원이라고 한다.
오일러 정의
기약 잉여계 개념은 정수론에서 오일러의 정의를 증명하는 데 사용된다. 정수론에서 유용하게 쓰이는 정리로, 합동식과 관련이 있다. 페르마의 소정리를 일반화한 것이다.
와 이 서로소인 양의 정수일 때, 이다.
여기서 은 부터 까지의 정수 중 과 서로소인 정수의 개수이다. 오일러 피 함수라고도 불린다.
양의 정수 에 대하여, 이하의 자연수 중에서 과 서로소인 정수의 개수를 으로 나타내고 함수 를 오일러의 함수라고 한다.
= varphi
또한오일러 정리는 대표적인 공개키 암호화 방식 중 하나인RSA의 가장 중요한 이론이 되는 정리이다. 참고로오일러 공식, 오일러 방정식과는 다른 것이다.
1.3 시간복잡도 정의를 이용하여 다음 4개의 문제에 대하 statement의 참, 거짓을 판별하시오 (시간복잡도 계산 문제)
1.4 임을 보여라.
모든 에 대하여 인 조건을 만족시키는 두 양의 상수 와 가 존재하기만하면 이다.
1.
2.
3. 대입 =>
4. 는 약 1.414
5.
6. n = 2라 가정하면
7.
8.
9.
1.5Big-O, Omega, Theta, small-o의 정의를 이용하여 임을 보이시오.
1.
2.
3.
2. 프림, 크루스칼, 다익스트라
2.1 비방향 그래프를 보고 크루스칼 알고리즘을 이용하여 최소 비용 신장 트리를 구하는 과정을 단계별로 보이시오
크루스칼 알고리즘의 핵심
오름차순
가중치를 기준으로 간선을 오름차순 정렬
낮은 가중치의 간선부터 시작해서 하나씩 그래프에 추가
사이클을 형성하는 간선을 추가하지 않음
간선의 수가 정점의 수보다 하나 적을 때 MST가 완성
내림차순
가중치를 기준으로 간선을 내림차순으로 정렬
높은 가중치의 간선부터 시작해서 하나씩 그래프에서 제거
두 정점을 연결하는 다른 경로가 없을 경우 해당 간선은 제거하지 않음
간선의 수가 정점의 수보다 하나 적을 때 MST가 완성
2.2 그래프를 보고 다익스트라 알고리즘을 이용하여 v6를 출발점으로하는 최단 거리를 구하는 과정을 단계별로 보이시오
간선의 가중치를 오름차순으로 정렬한다.
가중치가 낮은 순서대로 간선을 하나씩 그래프에 추가한다.
그래프 내에서 사이클을 형성하는 간선은 추가하지 않는다.
간선의 개수가 정점의 개수보다 '1' 작으면 끝낸다.
3. NP, NP-complete
3.1 NP, NP-hard, NP-complete의 정의
: 어떤 문제가 주어졌을 때 다항식으로 표현되어 polynomical time 즉, 다항 시간내에 해결 가능한 알고리즘을 의미하며 알고리즘의 복잡도가 로 표현되는 문제를 ''라 한다.(복잡도 이하를 가지는 경우 같은 복잡도 내에 모든 해를 구한다.)
: 어떤 문제가 주어졌을 때 다항식으로 표현될 수 있는지의 여부가 결정되지 않은 문제들을 'NP(Non-deterministic polynomial)'라 한다.
: NP이면서 동시에 NP-Hard 에 속한다면 그 문제는 'NP-Complete'라 한다. (전수조사가 답)
: 적어도 모든 NP 문제만큼은 어려운 문제들의 집합이며,만약P-NP 문제가P=NP로 풀린다면 P=NP=NP-Complete이므로 P와 NP는 NP-Hard의 부분집합이 되고, P≠NP인 경우는 P와 NP-Hard는서로소가 된다.*다항시간 : 는 상수 => 가 상수로 고정이 된다면 그 문제는 해결하기 쉬운 문제. 다항시간안에 풀 수 있는 문제이므로.
3.2 해밀턴회로 거리 구하기(그래프가 주어질 때 그래프의 모든 점을 정확하게 한번씩만 지나는 경로가 존재하는가?) (NP-hard)
4. 배열 제시 후 소팅 알고리즘을 사용하여 정렬 과정을 보여라
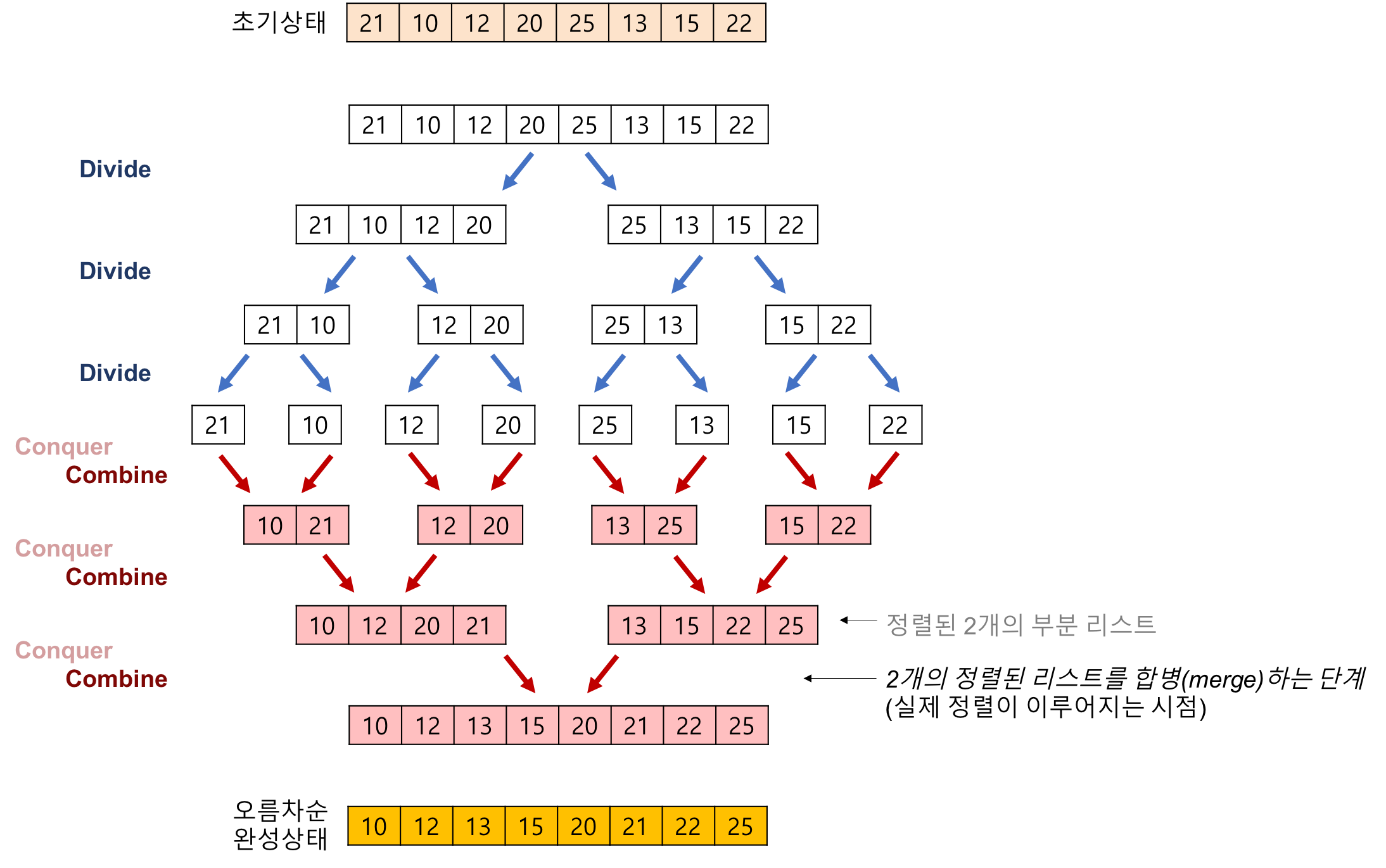
4.1 Merge sort 알고리즘을 사용하여 8개의 숫자를 정렬하는 과정을 보여라
병합 정렬의 예
4.2 각종 정렬 기법들의 장단점과 시간복잡도
5. Divide and Conquer 알고리즘과 Dynamic Programming 알고리즘 차이
5.1 분할 정복법이 비효율적인 경우를 설명하라
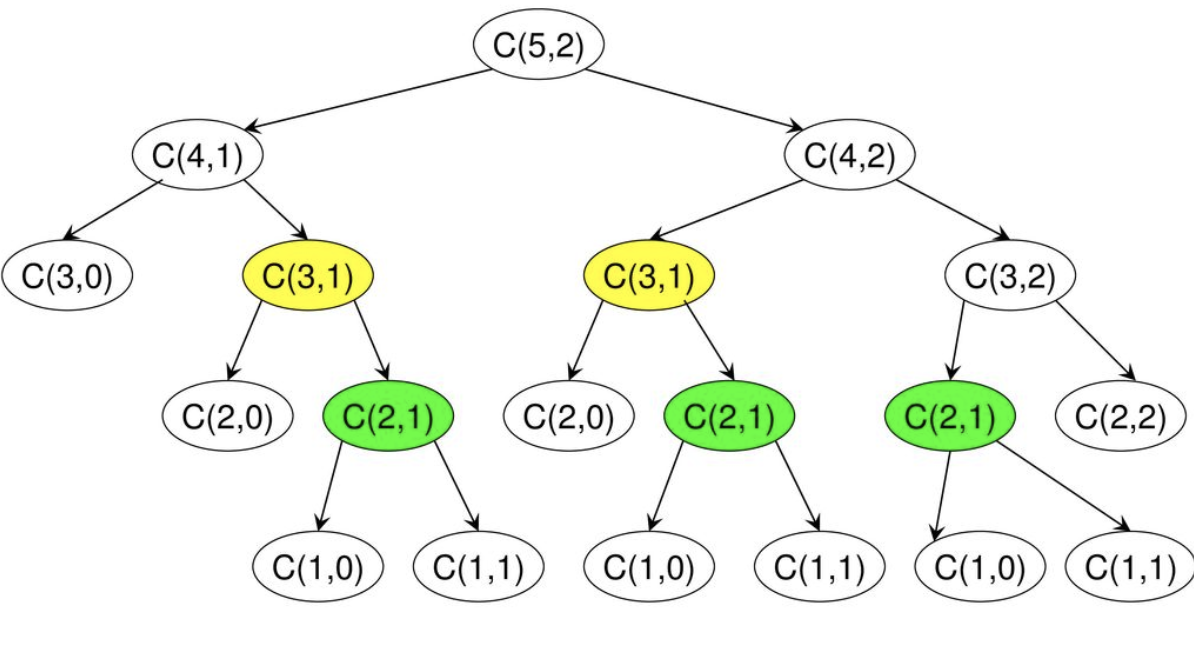
5.2 분할 정복법과 동적프로그래밍을 이용하여 이항계수를 구하는 알고리즘 작성 후 두방식의 차이점에 대해 적으시오
분할 정복법(Divide and Conquer)
어떠한 큰 문제를 해결하기 위해 큰 문제를 작은 단위의 문제로 나누어 해결하는 방법 (Top-down)
문제의 크기가 충분히 작아질때까지 반복적으로 분할
해결한 작은 문제를 가지고 바로 윗 단계의 문제를 해결해 나가는 방식
대표적인 예로는 Binary Search와 Merge Sort, Quick Sort 등이 있다.
동적 프로그래밍(Dynamic Programming)
문제를 작은 인스턴스들로 나누고 Bottom-up 순서로 풀어나가면서 문제의 값을 정해놓고 필요할 때 가져와 문제를 해결하는 방식이다. "기억하며 풀기"라 생각하면 된다.
대표적인 예로는 TSP 문제, 피보나치 수열, 파스칼의 트리 작성 등이 있다.
분할정복법과 동적 프로그래밍의 공통점과 차이점
공통점 : 문제를 작은 단위로 나누어 해결
차이점 : 분할정복법은 Top-down 방식이며, 동적 프로그래밍은 Bottom-up 방식이다.
5.3 Binomial coefficient를 계산하려할 때 다음을 구해라
Divide-and-Conquer 방법을 사용하는 pseudo code 작성
Dynamic Programming 방법을 사용하는 pseudo code 작성
위 두 접근 방법의 차이점을 서술
5.4 이항계수 수학적 귀납법으로 증명하고, 동적 프로그래밍으로 알고리즘을 구현하라.
bottom-up 방식
intbinomial(int n, int k){
for (int i=0; i<=n; i++)
{
for (int j=0; j<=k && j<=i; j++)
{
if (k==0 || n==k)
arr[i][j] = 1;
else
arr[i][j] = arr[i-1][j-1] + arr[i-1][j];
}
}
return arr[n][k];
}
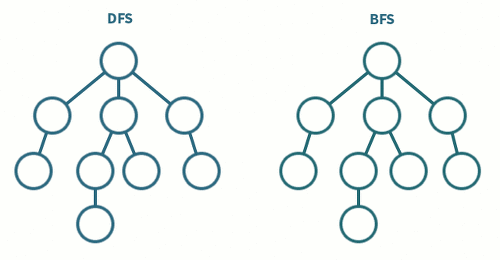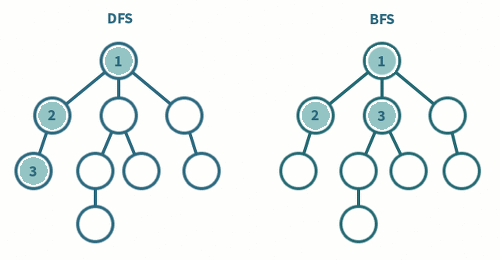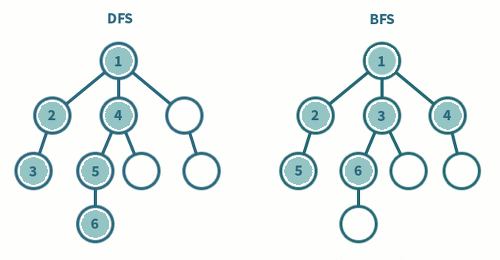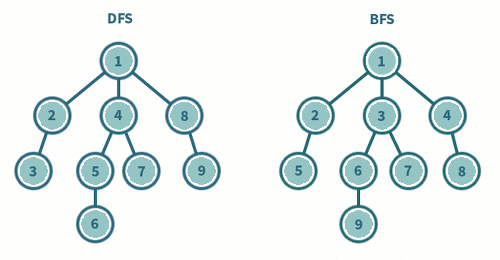
6. DFS(Depth First Search)와 BFS(Breadth First Search)의 차이
DFS, BFS의 의사코드를 작성하고 이들의 차이를 제시한 다음, 간단한 트리를 작성하여 순회하는 것을 보이시오.
8. 행렬을 주고 TSP에 관한 문제
9. Strassen 행렬 알고리즘을 사용하여 2*2 행렬 A,B의 곱 C를 구하라(m1,m2,...,m7)을 사용해야함
9.1 Strassen's Matrix Multiplication 알고리즘에 대해 설명하라
9.2 행렬 곱셉 알고리즘 + 쉬트라센 + 복잡도
아래와 같이 행렬 A,B가 있고 두 행렬의 곱이 행렬 C로 표현한다 가정한다.
이 때, 이다.
따라서일반적인 행렬의 곱은 다음과 같이 표현할 수 있으며, 총 8번의 곱셈과 4번의 덧셈으로 연산된다.
슈트라센 알고리즘은 행렬의 곱셉을 더하기 연산으로 풀어 각 원소를 구할 수 있는 이라는 연산 행렬로 표현한다. 행렬 은 7번의 곱셈과 10번의 덧셈으로 연산으로 나타낼 수 있으며 아래와 같이 표현한다.
최종적으로 행렬 C는 행렬 M의 더하기 연산으로 이루어져 있으며 각 원소에 해당하는 방법은 다음과 같다.
10. 5-Queen 문제를 백트래킹과 상태 설명 트리를 사용하여 해결하라
11. Floyd 알고리즘을 사용하여 W(=D0) 행렬과 D(=D) 행렬을 구하라. W, D를 구하는 과정을 서술하라
11.1 방향 그래프를 보고 플로이드 알고리즘을 이용하여 D와 P를 단계별로 적으시오.
12. 하노이의 탑 알고리즘을 써라
#include<stdio.h>voidHanoiTowerMove(int num, char from, char by, char to){
if (num == 1)
printf("원반 1을 %c에서 %c로 이동 \n", from, to);
else
{
HanoiTowerMove(num - 1, from, to, by);
printf("원반 %d를 %c에서 %c로 이동 \n", num, from, to);
HanoiTowerMove(num - 1, by, from, to);
}
}
intmain(void){
// 막대 A의 원반 5개를 막대 B를 경유하여 막대 C로 옮기기HanoiTowerMove(5, 'A', 'B', 'C');
return0;
}
13. 탐욕적 방법 Greedy Algorithm이 항상 최적의 해를 내지 못하는 경우의 예를 들라
Greedy Algorithm이 사용되는 대표적인 예제로는 "최소 수의 동전으로 거스름돈 거슬러주기" 문제가 있다.
만약 우리가 마트의 캐셔로 일을 하고 있고, 850원을 거슬러 주어야 할 때 500원 동전 1개와 100원 동전 3개와 50원 동전 1개 총 4개의 동전을 건넴으로써 최소한의 동전을 거슬러 줄 수 있다. 하지만 이렇게 하지 않고 10원짜리 동전 85개를 건네주거나 50원짜리 17개를 건네주는 방법과 같이 다양한 경우의 수가 존재하며 이와 같을 경우 반드시 최적의 해를 내는 것은 아니다.
또한 우리나라의 경우 총 4개의 동전 500원, 100원, 50원, 10원이 있다. 하지만 만약 400원 동전이 발행된다면 400원 동전 2개, 50원 동전 1개를 통해 총 3개의 동전을 거슬러 줄 수 있을 것이다. 가장 최적의 방법이지만, 기존 알고리즘에 따르면 500원 1개, 100원 3개, 50원 1개로 거슬러주게 될 것이다. 이와 같이 탐욕 알고리즘은 항상 최적의 결과를 보장하지 못한다.
장점 : 인접한 값만 계속해서 비교하는 방식으로 구현이 쉬우며, 코드가 직관적이다. n개 원소에 대해 n개의 메모리를 사용하기에 데이터를 하나씩 정밀 비교가 가능하다.
단점 : 최선이든 최악이든 이라는 시간복잡도를 가진다. n개 원소에 대해 n개의 메모리를 사용하기에 원소의 개수가 많아지면 비교 횟수가 많아져 성능이 저하된다.
힙 정렬
장점 : 추가적인 메모리를 필요로하지 않으면서 항상 의 시간 복잡도를 가진다. 인 정렬 방법 중 가장 효율적인 정렬방법이라 할 수 있다. 퀵 정렬의 경우 효율적이나 최악의 경우 시간이 오래걸린다는 단점이 있으나 힙 정렬의 경우 항상 이 보장된다.
단점 : 이상적인 경우에 퀵정렬과 비교했을 때 똑같이 이 나오긴 하나 실제 시간을 측정하면 퀵정렬보다 느리다고 한다. 즉, 데이터의 상태에 따라서 다른 정렬들에 비해서 조금 느린편이다. 또한, 안정성을 보장받지 못한다.
선택 정렬
장점 : 정렬을 위한 비교 횟수는 많으나 교환 횟수가 적기에, 교환이 많이 이루어져야 하는 상태에서 효율적으로 사용될 수 있으며, 이에 가장 적합한 자료상태는 역순 정렬이다. 즉, 내림차순이 정렬되어 있는 자료를 오름차순으로 재졍렬할 때 적합하다.
단점 : 정렬을 위한 비교 횟수가 많으며, 이미 정렬된 상태에서 소수의 자료가 추가되면 재정렬할 때 최악의 처리 속도를 보인다.
빠른 정렬
장점 : 기준값(Pivot)에 의한 분할을 통해 구현하는 정렬 방법으로, 분할 과정에서 이라는 시간이 소요되며, 전체적으로 으로 준수한 편이다.
단점 : 기존값에 따라 시간복잡도가 크게 달라진다(안정성이 없다). 기준값을 이상적인 값으로 선택했다면 의 시간복잡도를 가지지만, 최악의 기준값을 선택할 경우 라는 시간복잡도를 갖게 된다.
삽입 정렬
장점 : 최선의 경우 이라는 빠른 효율성을 가지고 있다. 버블정렬의 비교횟수를 줄이기 위해 고안된 정렬이다. 버블정렬의 경우 비교대상의 메모리 값이 정렬되어 있더라도 비교연산을 진행하나, 삽입정렬은 버블정렬의 비교횟수를 줄이고 크기가 적은 데이터 집합을 정렬하는 알고리즘을 작성할 때 효율이 좋다.
단점 : 최악의 경우 이라는 시간복잡도를 가지게 된다. 즉, 데이터의 상태와 크기에 따라 성능의 편차가 큰 정렬 방법이다.
병합 정렬
장점 : 퀵 정렬과 비슷하게 원본 배열을 절반씩 분할해가면서 정렬하는 정렬법으로써 분할하는 과정에서 만큼의 시간이 소요된다. 즉, 최종적으로 보게되면 이 된다. 또한 퀵 정렬과 달리 기준값을 설정하는 과정없이 무조건 절반으로 분할하기에 기준값에 따라 성능이 달라지는 경우가 없다. 따라서 항상 이라는 시간복잡도를 가지게 된다.
단점 : 병합정렬은 임시배열에 원본맵을 계속해서 옮겨주며 정렬을 하는 방식이기에 추가적인 메모리가 필요하다는 점이다. 데이터가 최악인 면을 고려하면 퀵 정렬보다는 병합정렬이 훨씬 빠르기 때문에 병합정렬을 사용하는 것이 많지만, 추가적인 메모리를 할당할 수 없다면 병합정렬을 사용할 수 없기 때문에 퀵을 사용해야 하는 것이다.
쉘 정렬
장점 : 삽입정렬의 단점을 보완하고 개념을 확대해서 만든 정렬방법으로, 삽입 정렬에 비해 성능이 우수하며, 어떤 데이터가 제 위치에서 멀리 떨어져있을 경우 여러 번의 교환이 발생하는 버블정렬의 단점을 해결한다.
단점 : 일정한 간격에 따라 배열을 보아야 하며, 간격을 잘못 설정할 경우 성능이 급격히 저하될 수 있다.
기수 정렬
장점 : 이라는 시간복잡도를 가지는 정렬방법으로 매우 빠른 속도를 가지고 있다.
단점 : 버킷이라는 데이터 전체 크기와 기수 테이블의 크기만큼의 추가적인 메모리가 할당되어야 한다.
카운팅 정렬
장점 : 비교를 하지 않고 정렬하는 방법으로 이라는 시간복잡도를 가지게 된다.
단점 : 숫자 갯수를 저장해야 될 별도의 공간, 또 결과를 저장할 별도의 공간 등 추가적인 메모리가 필요하다.
정렬 알고리즘 장단점 요약
Sorting
장점
단점
버블 정렬
인접한 두 개의 데이터를 비교하기에 구현이 쉬우며 정밀 비교 가능
원소의 갯수가 많아지면 비교 연산이 많아져서 성능이 저하
선택 정렬
정렬을 위한 교환 횟수가 적어 내림차순된 데이터를 오름차순할 때 효율이 좋음
정렬 비교 횟수가 많고,정렬된 상태서 소수의 자료가 추가되면 재정렬 시 최악의 처리 속도를 보임
삽입 정렬
버블정렬의 비교횟수를 줄이기 위해 고안된 방법이며, 크기가 적은 데이터 집합을 정렬하는 알고리즘을 작성할 때 효율이 좋음
데이터의 상태와 크기에 따라 성능 편차가 큰 정렬 방법
힙 정렬
추가적인 메모리를 필요로하지 않으면서 항상시간 복잡도 를 가짐
실제 시간을 측정 시 퀵정렬보다 느림. 즉, 데이터의 상태에 따라서 다른 정렬들에 비해 느린편. 안정성을 보장받지 못함
병합 정렬
퀵 정렬과 달리 기준값을 설정하는 과정없이 무조건 절반으로 분할하기에 기준값에 따라 성능이 달라지는 경우가 없음
병합정렬은 임시배열에 원본맵을 계속해서 옮겨주며 정렬을 하는 방식이기에 추가적인 메모리가 필요
퀵 정렬
기준값(Pivot)에 의한 분할을 통해 구현하는 정렬 방법으로, 분할 과정에서 이라는 시간이 소요되며, 전체적으로 으로 준수
: 어떤 문제가 주어졌을 때 다항식으로 표현되어 polynomical time 즉, 다항 시간내에 해결 가능한 알고리즘을 의미하며 알고리즘의 복잡도가 로 표현되는 문제를 ''라 한다.
(복잡도 이하를 가지는 경우 같은 복잡도 내에 모든 해를 구한다.)
: 어떤 문제가 주어졌을 때 다항식으로 표현될 수 있는지의 여부가 결정되지 않은 문제들을 'NP(Non-deterministic polynomial)'라 한다.
: NP이면서 동시에 NP-Hard 에 속한다면 그 문제는 'NP-Complete'라 한다. (전수조사가 답)
: 적어도 모든 NP 문제만큼은 어려운 문제들의 집합이며,만약P-NP 문제가P=NP로 풀린다면 P=NP=NP-Complete이므로 P와 NP는 NP-Hard의 부분집합이 되고, P≠NP인 경우는 P와 NP-Hard는서로소가 된다.
*다항시간 : 는 상수 => 가 상수로 고정이 된다면 그 문제는 해결하기 쉬운 문제. 다항시간안에 풀 수 있는 문제이므로.
또는 증명의 의의
또는 를 증명한다는 것은 100만 달러의 상금과 튜링상 수상 그 이상의 의미를 가진다. 만약 라 증명되면 현재 NP라고 일컬어지는 길찾기, 방문 판매 알고리즘 등을 포함한 모든 문제들이 전부 P 문제로서 풀릴 수 있다는 의미이다. 즉, 방문 판매와 알고리즘과 같이 무조건 시간이 오래 걸리는 방법으로 풀 수 밖에 없다 생각 되는 것 또한 방법만 찾는다면 다항 시간내에 해결할 수 있다는 것이다. 반대로 가 증명 되면, 수 많은 NP 문제들이 P 문제로 환원될 수 없음이 증명되었으니 더 쉬운 방법(P 문제로 환원할 방법)을 찾으려 더 이상 애쓸 필요가 없다는 것이다.
즉, 만약 우리가 이에 대한 해답을 알게된다면 지수시간(Exponential time)에 해결 가능한 모든 NP문제를 다항시간(Polynomical time)에 해결 가능한 P로 해결할 수 있기 때문에 아주 중요한 위치를 가지고 있다고 말한다.(예를 들면 암호화 알고리즘을 푸는데에 지수 시간이 걸린다. 소수를 구하는 알고리즘 또한 마찬가지이다).
복잡성 이론
'복잡성 이론 (Complexity Theory)' 이라는 컴퓨터 공학의 한 분야는 엄청난 계산을 필요로 하는 복잡한 문제들을 다룬다. 이것은 말 그대로 컴퓨터가 계산하는 여러 가지 문제들에 대한 '복잡성' 자체를 연구하는 분야다. 이 분야의 연구는 구체적인 알고리즘을 개발하는 것과 직접적인 상관은 없지만 어떤 문제가 쉽게 풀릴 수 잇는 문제고 어떤 문제가 쉽게 풀릴 수 없는 문제인지를 구별하도록 해주기 때문에 프로그래머들이 해결할 가능성이 없는 문제를 붙들고 시간을 허비하는 우를 범하지 않도록 해준다.
지수의 값이 아무리 크다고 해도 그것이 미리 정해진 상수 값이라면 그 알고리즘은 컴퓨터가 적당한 시간 안에 계산해 낼 수 있는 쉬운 알고리즘에 해당하는 것이다. 이렇게 변수위에 붙은 지수가 미리 정해진 상수인 수학 공식을 우리는 다항식 (polynomial) 이라고 부른다. 다음은 다항식의 예다.
복잡성 이론에서 다항식의 반대말은 '지수 함수 (exponential function)'다. 지수함수란 변수 위에 붙은 지수가 미리 정해져 있는 상수 값이 아니라 그 자신도 변수로 표현되는 함수를 의미한다. 다음은 지수함수의 예다
혹은
세일즈맨의 여행 문제를 풀기 위해 사용되는 factorial은 다음과 같은 수학 공식으로 표현되므로 다항식이라기보다는 지수함수에 속한다.
이 식을 모두 풀어쓰면 가장 차원이 높은 지수를 갖는 항은 맨 앞에 존재하는 n 으로 n-1 이라는 지수를 갖는다는 사실을 알 수 있다. n 의 크기가 증가하면 팩토리얼 함수 전체의 값이 엄청난 속도로 커진다. 지수함수의 특징은 바로 n 이 조금만 커지면 함수 전체의 값이 기하 급수적으로 커진다는 사실이다. 현재의 전자식 컴퓨터가 계산을 수행할수 있는 속도에는 엄연히 한계가 존재하기 때문에 계산을 수행해야 하는 양이 지나치게 커지면 컴퓨터도 계산을 수행할수 없게 된다. 이렇게 지수함수들은 n 값이 커짐에 따라서 함수의 결과가 엄청나게 빠른 속도로 증가하여 컴퓨터조차 쉽게 계산을 할 수 없기 때문에 '어려운' 문제라고 말한다. 즉 알고리즘의 속도가 다항식이 아니라 지수함수로 표현되면 그것은 어려운 알고리즘인 것이다.
복잡성 이론에서는 알고리즘의 속도가 다항식으로 표현되는 문제들을 묶어서 'P' 라고 부르고, 다항식으로 표현될 수 있는지 여부가 알려지지 않은 문제들을 묶어서 'NP' 라고 부른다. 여기서 P 는 Polynomial (다항식) 의 머리 글자고, NP 는 nondeterministic polynomial (비결정성 다항식) 의 머리 글자를 의미한다. 이때 NP 가 non-polynomial (비다항식) 을 의미하지 않는다는 사실에 유의할 필요가 있다. 다항식이 아니라는 사실과 다항식으로 표현되는지 여부가 아직 알려지지 않았다는 사실 사이에는 엄청난 차이가 존재하기 때문이다. 다항식으로 표현되는 알고리즘은 오늘날의 컴퓨터가 적당한 시간내에 해결할 수 있는 문제기 때문에 P 에 속한 문제들은 '쉬운' 문제들이고, NP 는 그와 반대로 '어려운' 문제를 의미한다.
복잡성 문제를 연구하는 학자들에게 가장 어려운 질문중의 하나는 바로 "NP 에 속하는 문제들이 궁극적으로는 모두 다항식, 즉 쉬운 알고리즘을 이용해서 해결될 수 있을까?" 라는 질문이다. 만약 그렇다면 NP 에 속한 문제나 P 에 속한 문제가 모두 종국에는 다항식으로 표현되기 때문에 'P = NP' 라는 등식이 성립하게 될 것이다. 하지만 NP 에 속하는 문제가 모두 다항식으로 해결될 수 있을지 여부를 파악하거나 증명하는 것이 너무나 어렵기 때문에 이 등식은 아직도 완전하게 입증되지 않은 어려운 명제증의 하나로 통하고 있다.
한편 'NP-hard' 라고 불리는 문제들은 세일즈맨의 여행 문제처럼 모든 경우의 수를 전부 확인해보는 방법 이외에는 정확한 답을 구할 수 있는 뾰족한 수가 없는 문제들을 뜻한다. 어떤 문제가 NP 에 속하면서, 즉 다항식으로 표현될 수 있는지 여부가 알려지지 않았으면서 동시에 NP-hard 에 속한다면, 즉 '무식한 힘' 의 방법말고 다른 절묘한 알고리즘이 알려져 있지 않다면 그 문제는 'NP 완전 문제 (NP complete)' 라고 부른다. 휴, 정말 복잡하다.
컴퓨터 학자들과 프로그래머들은 대개 NP 완전 문제를 실용적인 관점에서 해결하기 위해서 진짜 정답을 찾기를 포기하는 대신 휠씬 적은 양의 계산을 통해서 정답에 가까운 값을 찾는데 만족한다. 이러한 알고리즘은 근사 알고리즘 (Approximation algorithm) 혹은 발견적 알고리즘 (Heuristic algorithm) 이라고 부른다. 앞서 말한 MST, 탐욕 알고리즘 (Greedy algorithm), 평면절단 방법등은 모두 이러한 알고리즘의 예인데, 실전 프로그래밍의 세계에서는 이러한 근사 알고리즘이 생각보다 많이 사용된다.
해밀턴 경로
해밀턴 경로(Hamiltonian Path)의 경우 NP-Complete에 속하는 문제로서 어떤 그래프가 주어졌을 때 모든 꼭짓점을 단 한번만 지나는 경로가 존재하는지에 대한 여부를 묻는다.
시간 복잡도란 알고리즘의 효율성을 판단하기 위한 지표로서, 알고리즘의 절대시간이 아닌, 알고리즘을 수행하는데 사용되는 연산들이 몇 번 이루어지는가에 대한 것을 수로 표기한 것이다. 연산에는 산술, 대입, 비교, 이동이 있다. 시간 복잡도, 즉 성능 측정에 사용되는 표기법은 크게 세 가지로 나뉘며 Big-O, Big-Omega(), Theta()가 있다.
Big-O
모든 , 에 대해 인 조건을 만족시키는 두 양의 상수 와 가 존재하기만 하면 이다.
예를 들면 : 최악의 경우 번까지 수행되면 프로그램을 끝낼 수 있다.
Big-Omega
모든 , 에 대해 인 조건을 만족시키는 두 양의 상수 와 가 존재하기만 하면 이다.
예를 들면 : 최소 번은 수행되어야 프로그램을 끝낼 수 있다.
Theta
모든 , 에 대해 인 조건을 만족시키는 세 양의 상수 가 존재하기만 하면 이다.
와의 교집합, 즉 차수가 같은 문제이다.
추가적으로 Small-O, Small-omega() 표기법도 존재한다.
Small-O는 Big-O에서 등호를 뺀다.
예를 들면 : 최악의 경우에도 n번 미만으로 수행되면 프로그램은 끝낼 수 있다.
Small-O와 Big-O의 차이점은 다음과 같다.
- Big-O는 실수 중에서 하나만 성립해도 된다.
- Small-O는 모든 실수 에 대해서 성립해야 한다.
Big-O 표기법 성능 비교
시간 복잡도 함수의 그래프
Better < < < < < < Worse
상수 함수 < 로그 함수 < 선형 함수 < 다항 함수 < 지수 함수 < 재귀 함수
Big-O 표기법 예제
: Operation push and pop on Stack
: Binary Tree
: for loop
: Quick Sort, Merge Sort, Heap Sort
: Double for loop, Insert Sort, Bubble Sort, Selection Sort
: Fibonacci Sequence
시간 복잡도 분석 종류
: Every-case anlaysis
입력크기(input size)에만 종속
입력값과는 무관하게 결과값은 항상 일정
: Worst-case analysis
입력크기와 입력값 모두에 종속
단위연산이 수행되는 횟수가 최대인 경우 선택
: Average-case analysis
입력크기와 입력값 모두에 종속
모든 입력에 대해 단위연산이 수행되는 기대치(평균)
각 입력에 대해서 확률 할당 가능
: Best-case analysis
입력크기와 입력값 모두에 종속
단위연산이 수행되는 횟수가 최소인 경우 선택
표기법 간의 관계
표기법
의미
는 보다 크다,
는 보다 크거나 같다,
는 와 대략 같다,
는 보다 작거나 같다,
는 보다 작다,
Big-O 계산 실습
a=10# Constant 1
b=20# Constant 1
c=30# Constant 1for i in range(n):
for j in range(n):
x = i * i # n^2
y = j * j # n^2
z = i * j # n^2for k in range(n):
w = a * k + 40# n
v = b * b # n