먼저 배경을 설명하자면, 대표적인 ASCII 코드의 경우 1Byte의 크기를 차지한다. 하지만 ASCII 코드만으로 다른 문자 체계를 전부 표현할 수 없다는 한계가 있다. 이로 인해 2Byte 문자 집합의 구성이 필요해졌으며 멀티 바이트를 2Byte 문자 집합으로 구성하고 ISO-2200에 멀티바이트로 정의하게 되었다.
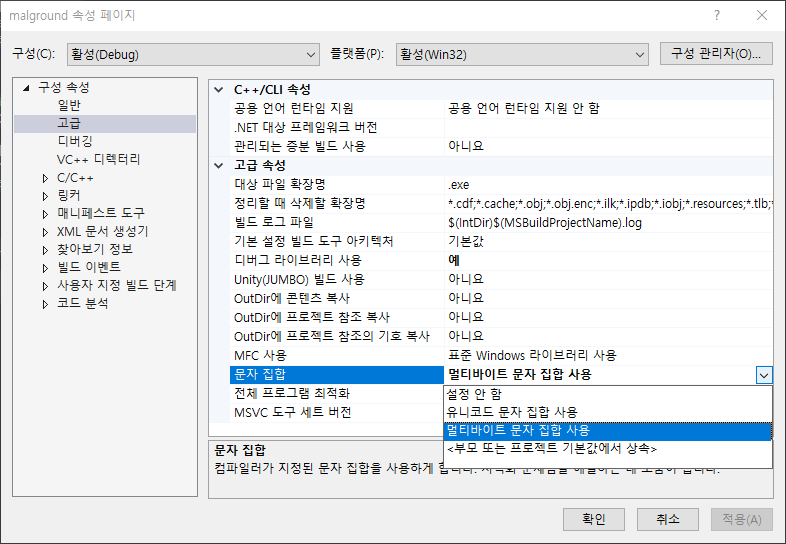
멀티바이트는 유니코드와 같이 2Byte 이상의 문자 집합이나, 표준으로서 합의가 이루어지지 않은 윈도우에서 개발된 코드이기 때문에 차이가 있게 된다. 이에 따라 기본적으로 Visual Studio에서 개발 시 유니코드를 사용할 것인지 멀티바이트를 사용할 것인지에 대한 기본 값을 설정한 뒤 개발을 진행해야 한다.
유니코드 문자열을 사용하려면 문자열에 L을 붙여 사용하면 된다.
ex) 유니코드 : (L"Hello World")
ex) 멀티바이트 : ("Hello World")
유니코드로 개발된 프로그램을 멀티바이트로 포팅하려면 위와 같은 표현을 모두 수정해주어야 하는 불편함이 따른다. 이를 해결하기 위해 _T 매크로라는 것이 사용되며, 문자열을 따옴표로 감싼 뒤 유니코드에서 사용한 L 대신 _T를 사용하면 매크로가 알아서 개발 환경에 맞게 번형되어 컴파일 될 수 있도록 한다.
먼저 정보은닉이란, 멤버변수를 private로 선언하고, 해당 변수에 접근하는 함수를 별도로 정의해서, 안전한 형태로 멤버 변수의 접근을 유도하는 것이 '정보은닉'이며, 이는 좋은 클래스가 되기 위한 기본조건이 된다.
int GetX() const;
bool SetX(int xpos);
int GetY() const;
bool SetY(int ypos);
위를 가리켜 액세스 함수라 한다. 이들은 멤버변수를 private로 선언하면서 클래스 외부에서의 멤버변수 접근을 목적으로 정의되는 함수들이다. 하지만 이들 함수는 정의되었으되 호출되지 않은 경우도 많은데 이는 지금 클래스의 정의과정에서 필요하진 않지만, 필요할 수 있다고 판단되는 함수들도 더불어 멤버에 포함시키는 경우도 많기 때문이다.
캡슐화
캡슐화가 무너지면 객체의 활용이 매우 어려워진다. 뿐만 아니라, 캡슐화가 무너지면 클래스 상호관계가 복잡해지기 때문에 이는 프로그램 전체의 복잡도를 높이는 결과로 이어진다.
캡슐화의 경우 어려운 개념에 속하며 이는 캡슐화의 범위를 결정하는 일이 쉽지 않기 때문이다.
경험이 많은 객체지향 프로그래머를 구분하는 첫 번째 기준은 캡슐화가 된다. 캡슐화는 일관되게 적용할 수 있는 단순한 개념이 아니고, 구현하는 프로그램의 성격과 특성에 따라서 적용하는 범위가 달라지는, 흔히 하는 말로 정답이란 것이 딱히 없는 개념이기 때문이다.
차원축소는 매우 많은 피처로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 것이다. 일반적으로 차원이 증가할수록 데이터 포인트 간의 거리가 기하급수적으로 멀어지게 되고, 희소(sparse)한 구조를 가지게 된다. 수백 개 이상의 피처로 구성된 데이터 세트의 경우 상대적으로 적은 차원에서 학습된 모델보다 예측 신뢰도가 떨어진다. 또한 피처가 많을 경우 개별 피처간에 상관관계가 높을 가능성이 크다. 선형 회귀와 같은 선형모델에서는 입력 변수 간의 상관관계가 높을 경우 이로 인한 다중 공선성 문제로 모델의 예측 성능이 저하된다.
다차원의 피처를 차원 축소해 피처 수를 줄이면 더 직관적으로 데이터를 해석할 수 있다. 가령 수십 개 이상의 피처가 있는 데이터의 경우 이를 시각적으로 표현해 데이터의 특성을 파악하기는 불가능하다. 이 경우 3차원 이하의 차원 축소를 통해서 시각적으로 데이터를 압축해서 표현할 수 있다. 또한 차원 축소를 할 경우 학습 데이터의 크기가 줄어들어서 학습에 필요한 처리 능력도 줄일 수 있다.
일반적으로 차원 축소는 피처 선택(feature selection)과 피처 추출(feature extraction)로 나눌 수 있다. 피처 선택, 즉 특성 선택은 말 그대로 특정 피처에 종속성이 강한 불필요한 피처는 아예 제거하고, 데이터의 특징을 잘 나타내는 주요 피처만 선택하는 것이다. 피처 추출은 기존 피처를 저차원의 중요 피처로 압축해서 추출하는 것이다. 이렇게 새롭게 추출된 중요 특성은 기존의 피처가 압축된 것이므로 기존의 피처와는 완전히 다른 값이 된다.
피처 추출은 기존 피처를 단순 압축이 아닌, 피처를 함축적으로 더 잘 설명할 수 있는 또 다른 공간으로 매핑해 추출하는 것이다. 가령 학생을 평가하는 다양한 요소로서 모의고사 성적, 종합 내신성적, 수능성적, 봉사활동, 대외활동, 학교 내외 수상경력 등과 관련된 여러 가지 피처로 돼 있는 데이터 세트라면 이를 학업 성취도, 커뮤니케이션 능력, 문제 해결력과 같은 더 함축적인 요약 특성으로 추출할 수 있다. 이러한 함축적인 특성 추출은 기존 피처가 전혀 인지하기 어려웠던 잠재적인 요소(Learning Factor)를 추출하는 것을 의미한다. (위의 학생 평가 요소는 함축적 의미를 인지하기 어려운 것은 아니나, 함축성의 예시를 든 것이다)
차원 축소는 단순히 데이터의 압축을 의미하는 것이 아니다. 더 중요한 의미는 차원 축소를 통해 좀 더 데이터를 잘 설명할 수 있는 잠재적인 요소를 추출하는 데에 있다. PCA, SVD, NMF는 이처럼 잠재적인 요소를 찾는 대표적인 차원 축소 알고리즘이다. 매우 많은 차원을 가지고 있는 이미지나 텍스트에서 차원 축소를 통해 잠재적인 의미를 찾아 주는 데 이 알고리즘이 잘 활용된다.
차원 축소 알고리즘은 매우 많은 픽셀로 이뤄진 이미지 데이터에서 잠재된 특성을 피처로 도출해 함축적 형태의 이미지 변환과 압축을 수행할 수 있다. 이렇게 변환된 이미지는 원본 이미지보다 훨씬 적은 차원이기 때문에 이미지 분류 등의 분류 수행 시에 과적합 영향력이 작아져서 오히려 원본 데이터로 예측하는 것보다 예측 성능을 더 끌어 올릴 수 있다. 이미지 자체가 가지고 있는 차원의 수가 너무 크기 때문에 비슷한 이미지라도 적은 픽셀의 차이가 잘못된 예측으로 이어질 수 있기 때문이다. 이 경우 함축적으로 차원을 축소하는 것이 예측 성능이 훨씬 도움이 된다.
차원 축소 알고리즘이 자주 사용되는 또 다른 영역은 텍스트 문서의 숨겨진 의미를 추출하는 것이다. 문서는 많은 단어로 구성돼 있다. 일반적으로 사람의 경우 문서를 읽으면서 이 문서가 어떤 의미나 의도를 가지고 작성됐는지 쉽게 인지할 수 있다. 차원 축소 알고리즘은 문서 내 단어들의 구성에서 숨겨져 있는 시맨틱(Semantic) 의미는 토픽(Topic)을 잠재 요소로 간주하고 이를 찾아낼 수 있다. SVD와 NMF는 이러한 시맨틱 토픽(Semantic Topic) 모델링을 위한 기반 알고리즘으로 사용된다.
PCA
PCA (Principal Component Analysis)는 가장 대표적인 차원 축소 기법이다. PCA는 여러 변수 간에 존재하는 상관관계를 이용해 이를 대표하는 주성분(Principal Component)을 추출해 차원을 축소하는 기법이다. PCA로 차원을 축소할 때는 기존 데이터의 정보 유실이 최소화되는 것이 당연하다. 이를 위해 PCA는 가장 높은 분산을 가지는 데이터의 축을 찾아 이 축으로 차원을 축소하는데, 이것이 PCA의 주성분이 된다(즉, 분산이 데이터의 특성을 가장 잘 나타내는 것으로 간주한다) 키와 몸무게 2개의 피처를 가지고 있는 데이터가 세트가 있다고 가정하면 아래와 같은 방식으로 축소를 진행한다.
위와 같이 키와 몸무게라는 피처가 2개 있을 때 1개의 주성분을 가진 데이터 세트로 차원 축소를 한다. 데이터 변동성이 가장 큰 방향으로 축을 생성하고, 새롭게 생성된 축으로 데이터를 투영하는 방식이다. PCA는 제일 먼저 가장 큰 변동성(Variacne)을 기반으로 첫 번째 벡터 축을 생성하고, 두 번째 축은 이 벡터 축에 직각이 되는 벡터(직교 벡터)를 축으로 한다. 세 번째 축은 다시 두 번째 축과 직각이 되는 벡터를 설정하는 방식으로 축을 생성한다. 이렇게 생성된 벡터 축에 원본 데이터를 투영하면 벡터 축의 개수만큼의 차원으로 원본 데이터가 차원 축소된다. (긴 벡터가 첫 번째 PCA 축, 짧은 벡터가 두번째 PCA 축)
PCA, 즉 주성분 분석은 이처럼 원본 데이터에 피처 개수에 비해 매우 작은 주성분으로 원본 데이터의 총 변동성을 대부분 설명할 수 있는 분석법이다.
PCA를 선형대수 관점에서 해석해 보면, 입력 데이터의 공분산 행렬(Covariance Matrix)을 고유값 분해하고, 이렇게 구한 고유벡터에 입력 데이터를 선형 변환하는 것이다. 이 고유벡터가 PCA의 주성분 벡터로서 입력 데이터의 분산이 큰 방향을 나타낸다. 고유값(eigenvalue)은 바로 이 고유벡터의 크기를 나타내며, 동시에 입력 데이터의 분산을 나타낸다.
일반적으로 선형 변환은 특정 벡터에 행렬 A를 곱해 새로운 벡터로 변환하는 것을 의미한다. 이를 특정 벡터를 하나의 공간에서 다른 공간으로 투영하는 개념으로도 볼 수 있고, 이 경우 이 행렬을 바로 공간으로 가정하는 것이다.
보통 분산은 한 개의 특정한 변수의 데이터 변동을 의미하나, 공분산은 두 변수 간의 변동을 의미한다. 즉, 사람 키 변수를 X, 몸무게 변수를 Y라고 하면 공분산 Cov(X, Y) > 0은 X(키)가 증가할 때 Y(몸무게)도 증가한다는 의미다. 공분산 행렬은 여러 변수와 관련된 공분산을 포함하는 정방형 행렬이다.
X
Y
Z
X
3.0
-0.71
-0.24
Y
-0.71
4.5
0.28
Z
-0.24
0.28
0.91
위 표에서 보면 공분산 행렬에서 대각선 원소는 각 변수(X, Y, Z)의 분산을 의미하며, 대각선 이외의 원소는 가능한 모든 변수 쌍 간의 공분산을 의미한다. X, Y, Z의 분산은 각각 3.0, 4.5, 0.91이다. X와 Y의 공분산은 -0.71, X와 Z의 공분산은 -0.24, Y와 Z의 공분산은 0.28이다. (덧붙여 공분산이 0이라면 두 변수 간에는 아무런 선형 관계가 없으며 두 변수는 서로 독립적인 관계에 있다. 그러나 두 변수가 독립적이라면 공분산은 0이 되지만, 공분산이 0이라고 해서 항상 독립적이라할 수 없다.)
고유벡터는 행렬 A를 곱하더라도 방향이 변하지 않고 그 크기만 변하는 벡터를 지칭한다. 즉, Ax = ax(A는 행렬, x는 고유벡터, a는 스칼라값)이다. 이 고유벡터는 여러 개가 존재하며, 정방 행렬은 최대 그 차원 수만큼의 고유벡터를 가질 수 있다. 예를 들어 2x2 행렬은 두 개의 고유벡터를, 3x3 행렬은 3개의 고유벡터를 가질 수 있다. 이렇게 고유벡터는 행렬이 작용하는 힘의 방향과 관계가 있어서 행렬을 분해하는 데 사용된다.
공분산 행렬은 정방행렬(Diagonal Matrix)이며 대칭행렬(Symmetric Matrix)이다. 정방행렬은 열과 행이 같은 행렬을 지칭하는데, 정방행렬 중에서 대각 원소를 중심으로 원소 값이 대칭되는 행렬, 즉 $A^T = A$인 행렬을 대칭행렬이라 부른다. 공분산 행렬은 개별 분산값을 대각 원소로 하는 대칭행렬이다. 이 대칭행렬은 고유값 분해와 관련해 매우 좋은 특성이 있다. 대칭행렬은 항상 고유벡터를 직교행렬(orthogonal matrix)로, 고유값을 정방 행렬로 대각화할 수 있다는 것이다.
입력 데이터의 공분산 행렬 C라고 하면 공분산 행렬의 특성으로 인해 다음과 같이 분해할 수 있다.
$C = P \sum P^T$
이때 $P$는 n x n의 직교행렬이며, $\sum$은 n x n 정방행렬, $P^T$는 행렬 $P$의 전치 행렬이다. 위 식은 고유벡터 행렬과 고유값 행렬로 다음과 같이 대응된다.
즉, 공분산 C는 고유벡터 직교 행렬 * 고유값 정방 행렬 * 고유벡터 직교 행렬의 전치 행렬로 분해된다. $e_i$는 $i$번째 고유벡터를, $\lambda_i$는 $i$번째 고유벡터의 크기를 의미한다. $e_1$는 가장 분산이 큰 방향을 가진 고유벡터이며, $e_2$는 $e_1$에 수직이면서 다음으로 가장 분산이 큰 방향을 가진 고유벡터이다.
선형대수식까지 써가면서 강조하고 싶었던 것은 입력 데이터의 공분산 행렬이 고유벡터와 고유값으로 분해될 수 있으며, 이렇게 분해된 고유벡터를 이용해 입력 데이터를 선형 변환하는 방식이 PCA라는 것이다. 보통 PCA는 다음과 같은 단계로 수행된다.
선형 회귀의 경우 회귀 계수의 관계를 모두 선형으로 가정하는 방식이다. 일반적으로 선형 회귀는 회귀 계수를 선형으로 결합하는 회귀 함수를 구해, 여기에 독립변수를 입력해 결과값을 예측하는 것이다. 비선형 회귀 역시 비선형 회귀 함수를 통해 결과값을 예측한다. 다만 비선형 회귀는 회귀 계수의 결합이 비선형일 뿐이다. 머신러닝 기반의 회귀는 회귀 계수를 기반으로 하는 최적 회귀 함수를 도출하는 것이 주요 목표이다.
회귀 트리는 회귀 함수를 기반으로 하지 않고 결정 트리와 같이 트리기반으로 한다. 즉, 회귀를 위한 트리를 생성하고 이를 기반으로 회귀 예측을 하는 것이다. 회귀 트리의 경우 분류 트리와 크게 다르지 않다. 다만 리프 노드에서 예측 결정값을 만드는 과정에 차이가 있다. 분류 트리가 특정 클래스 레이블을 결정하는 것과는 달리 회귀 트리는 리프 노드에 속한 데이터 값의 평균값을 구해 회귀 예측값을 계산한다.
결정 트리, 랜덤 포레스트, GBM, XGBoost, LightGBM 등의 앞 4장의 분류에서 소개한 모든 트리 기반의 알고리즘은 분류뿐만 아니라 회귀도 가능하다. 트리 생성이 CART 알고리즘에 기반하고 있기 때문이다. CART(Classification And Regression Trees)는 이름에서도 알 수 있듯 분류뿐만 아니라 회귀도 가능하게 해주는 트리 생성 알고리즘이다.
사이킷런에서는 결정 트리, 랜덤 포레스트, GBM에서 CART 기반의 회귀 수행을 할 수 있는 Estimator 클래스를 제공한다. 또한 XGBoost, LightGBM도 사이킷런 래퍼 클래스를 통해 이를 제공한다. 다음은 사이킷런의 트리 기반 회귀와 분류의 Estimator 클래스를 표로 나타낸 것이다.
알고리즘
회귀 Estimator 클래스
분류 Estimator 클래스
Decision Tree
DecisionTreeRegressor
DecisionTreeClassifier
Gradient Boosting
GradientBoostingRegressor
GradientBoostingClassifier
XGBoost
XGBRegressor
XGBClassifier
LightGBM
LGBMRegressor
LGBMClassifier
* 사이킷런의 회귀 트리 Regressor의 하이퍼 파라미터는 분류 트리 Classifier의 하이퍼 파라미터와 거의 동일하다
로지스틱 회귀는 선형 회귀 방식을 분류에 적용한 알고리즘이다. 즉, 로지스틱 회귀는 분류에 사용된다. 로지스틱 회귀 역시 선형 회귀 계열이다. 회귀가 선형인가 비선형인가는 독립변수가 아닌 가중치 변수가 선형인지 아닌지를 따른다. 로지스틱 회귀가 선형 회귀와 다른 점은 학습을 통해 선형 함수의 회귀 최적선을 찾는 것이 아니라 시그모이드(Sigmoid) 함수 최적선을 찾고 이 시그모이드 함수의 반환 값을 확률로 간주해 확률에 따라 분류를 결정한다는 것이다.
<로지스틱 회귀의 시그모이드 함수>
많은 자연, 사회 현상에서 특정 변수의 확률 값은 선형이 아니라 위의 시그모이드 함수와 같이 S자 커브 형태를 가진다. 시그모이드 함수의 정의는 $y = {1 \over 1 + e^-x}$이다. 위의 그림과 식에서 알 수 있듯이 시그모이드 함수는 x 값이 +, -로 아무리 커지거나 작아져도 y 값은 항상 0과 1 사이 값을 반환한다. x 값이 커지면 1에 근사하며 x 값이 작아지면 0에 근사한다. 그리고 x가 0일 때는 0.5이다.
주로 부동산 가격과 같은 연속형 값을 구하는 데 회귀를 사용했다. 이번에는 회귀 문제를 약간 비틀어서 분류 문제에 적용하려 한다. 가령 악성 종양을 탐지하기 위해 악성 종양의 크기를 X축, 악성 종양 여부를 Y축에 표시할 때 데이터 분포가 다음과 같이 될 수 있다.
선형 회귀를 적용하게 되면 데이터가 모여 있는 곳으로 선형 회귀 선을 그릴 수 있다. 하지만 이 회귀 라인은 0과 1을 제대로 분류하지 못하고 있는 것을 확인할 수 있다. (분류를 못하는 것은 아니지만 정확도가 떨어진다) 하지만 오른쪽 로지스틱 회귀와 같이 S자 커브 형태의 시그모이드 함수를 이용하면 조금 더 정확하게 0과 1에 대해 분류를 할 수 있음을 알 수 있다. 로지스틱 회귀는 이처럼 선형 회귀 방식을 기반으로 하되 시그모이드 함수를 이용해 분류를 수행하는 회귀이다.
LogisticRegression in sklearn
선형 회귀 계열의 로지스틱 회귀는 데이터의 정규 분포도에 따라 예측 성능 영향을 받을 수 있으므로 데이터에 먼저 정규 분포 형태의 표준 스케일링을 적용한 뒤에 train_test_split()을 이용하여 데이터 셋을 분리할 수 있다.
사이킷런 LogisticRegression 클래스의 주요 하이퍼 파라미터로 penalty와 C가 있다. penalty는 규제의 유형을 설정하며 'l2'로 설정 시 L2 규제를, 'l1'으로 설정 시 L1 규제를 뜻한다. 기본은 'l2'이다. C는 규제 강도를 조절하는 alpha 값의 역수이다. 즉 $C = {1 \over alpha}$다. C 값이 작을 수록 규제 강도가 크다.
선형 회귀 모델과 같은 선형 모델은 일반적으로 피처와 타겟 간에 선형의 관계가 있다 가정하고, 이러한 최적의 선형함수를 찾아내 결과를 예측한다. 또한 선형 회귀 모델은 피처값과 타겟값의 분포가 정규 분포(즉 평균을 중심으로 종 모양으로 데이터 값이 분포된 형태) 형태를 매우 선호한다. 특히 타겟값의 경우 정규 분포 형태가 아니라 특정값의 분포가 치우친 왜곡된 형태의 분포도일 경우 예측 성능에 부정적인 영향을 미칠 가능성이 높다. 피처값 역시 결정값보다는 덜하지만 왜곡된 분포도로 인해 예측 성능에 부정적인 영향을 미칠 수 있다.
따라서 선형 회귀 모델을 적용하기전에 먼저 데이터에 대한 스케일링/정규화 작업을 수행하는 것이 일반적이다. 하지만 이러한 스케일링/정규화 작업을 선행한다고 해서 무조건 예측 성능이 향상되는 것은 아니다. 일반적으로 중요한 피처들이나 타겟값의 분포도가 심하게 왜곡됐을 경우에 이러한 변환 작업을 수행한다. 일반적으로 피처 데이터 셋과 타겟 데이터 셋에 이러한 스케일링/정규화 작업을 수행하는 방법이 조금은 다르다. 사이킷런을 이용한 피처 데이터 셋에 적용하는 변환 작업은 다음과 같은 방법이 있을 수 있다.
StandardScaler 클래스를 이용해 평균이 0, 분산이 1인 표준 정규 분포를 가진 데이터 셋으로 변환하거나 MinMaxScaler 클래스를 이용해 최소값이 0이고 최대값이 1인 값으로 정규화를 수행한다.
스케일링/정규화를 수행한 데이터 셋에 다시 다항 특성을 적용하여 변환하는 방법이다. 보통 1번 방법을 통해 예측 성능에 향상이 없을 경우 이와 같은 방법을 적용한다.
원래 값에 log 함수를 적용하면 보다 정규 분포에 가까운 형태로 값이 분포된다. 이러한 변환을 로그 변환이라 부른다. 로그 변환은 매우 유용한 변환이며, 실제로 선형 회귀에서는 앞서 소개한 1,2번 방법보다 로그 변환이 훨씬 많이 사용되는 변환 방법이다. 그 이유는 1번 방법의 경우 예측 성능 향상을 크게 기대하기 어려운 경우가 많으며, 2번 방법의 경우 피처의 개수가 매우 많을 경우에는 다항 변환으로 생성되는 피처의 개수가 기하급수로 늘어나서 과적합의 이슈가 발생할 수 있기 때문이다.
타겟값의 경우 일반적으로 로그 변환을 적용한다. 결정값을 정규 분포나 다른 정규값으로 변환하면 변환된 값을 다시 원본 타겟값으로 원복하기 어려울 수 있다. 무엇보다도, 왜곡된 분포도 형태의 타겟값을 로그 변환하여 예측 성능 향상이 된 경우가 많은 사례에서 검증되었기 때문에 타겟값의 경우는 로그 변환을 적용한다.
회귀 모델은 적절히 데이터에 적합하면서도 회귀 계수가 기하급수적으로 커지는 것을 제어할 수 있어야 한다. 이전까지 선형 모델의 비용 함수는 RSS를 최소화하는, 즉 실제값과 예측값의 차이를 최소화하는 것만 고려했다. 단편적으로 고려하다보니 학습 데이터에 지나치게 맞추게 되고, 회귀 게수가 쉽게 커졌다. 이렇게 될 경우 변동성이 오히려 심해져서 테스트 데이터 셋에서는 예측 성능이 저하되기 쉽다. 이를 반영해 비용 함수는 학습 데이터의 잔차 오류 값을 최소로 하는 RSS 최소화 방법과 과적합을 방지하기 위해 회귀 계수 값이 커지지 않도록 하는 방법이 서로 균형을 이뤄야 한다.
회귀 계수의 크기를 제어해 과적합을 개선하려면 비용(Cost) 함수의 목표가 다음과 같이 $RSS(W) + alpha * ||W||_2^2$를 최소화하는 것으로 변경될 수 있다.
비용 함수 목표 =$Min(RSS(W) + alpha * ||W||_2^2)$
alpha는 학습 데이터 적합 정도와 회귀 계수 값을 크기 제어를 수행하는 튜닝 파라미터이다. 위 비용 함수 목표가 해당 식의 값을 최소화하는 W 벡터를 찾는 것일 때 alpha가 0 또는 매우 작은 값이라면 비용 함수 식은 기존과 동일한 $Min(RSS(W) + 0)$이 될 것이다. 반면에 alpha가 무한대 또는 매우 큰 값이라면 비용 함수 식은 $RSS(W)$에 비해 $alpha * ||W||_2^2$ 값이 너무 커지게 되므로 W 값을 0 또는 매우 작게 만들어야 Cost가 최소화되는 비용 함수 목표를 달성할 수 있다. 즉 alpha 값을 크게 하면 비용 함수는 회귀 계수 W의 값을 작게 해 과적합을 개선할 수 있으며 alpha 값을 작게 하면 회귀 계수 W의 값이 커져도 어느 정도 상쇄가 가능하므로 학습 데이터 적합을 더 개선할 수 있다.
즉, alpha를 0에서부터 지속적으로 값을 증가시키면 회귀 계수 값의 크기를 감소시킬 수 있다. 이처럼 비용 함수에 alpha 값으로 페널티를 부여해 회귀 계수 값의크기를 감소시켜 과적합을 개선하는 방식을 규제(Regularization)라고 부른다. 규제는 크게 L2 방식과 L1 방식으로 구분된다. L2 규제는 위에서 설명한 바와 같이 $alpha * ||W||_2^2$와 같이 W의 제곱에 대해 패널티를 부여하는 방식을 말한다. L2 규제를 적용한 회귀를 릿지(Ridge) 회귀라 한다. 라쏘(Lasso) 회귀는 L1 규제를 적용한 회귀이다. L1 규제는 $alpha * ||W||_1$와 같이 W의 절대값에 대해 패널티를 부여한다. L1 규제를 적용하면 영향력이 크지 않은 회귀 계수 값을 0으로 변환한다.
릿지 회귀 (Ridge Regression)
릿지 회귀의 경우 회귀 계수를 0으로 만들지는 않는다.
라쏘 회귀 (Lasso Regression)
회귀 계수가 0인 피처는 회귀 식에서 제외되면서 피처 선택의 효과를 얻을 수 있다.
엘라스틱넷 회귀 (ElasticNet Regression)
엘라스틱넷 회귀는 L2 규제와 L1 규제를 결합한 회귀이다. 엘라스틱넷 회귀 비용함수의 목표는 $RSS(W) + alpha2 * ||W||_2^2 + alpha1 * ||W||_1$ 식을 최소화하는 W를 찾는 것이다. 엘라스틱넷은 라쏘 회귀가 서로 상관관계가 높은 피처들의 경우에 이들 중에서 중요 피처만을 선택하고 다른 피처들은 모두 회귀 계수를 0으로 만드는 성향이 강하다. 특히 이러한 특징으로 인해 alpha 값에 따라 회귀 계수의 값이 급격히 변동할 수도 있는데, 엘라스틱넷 회귀는 이를 완화하기 위해 L2 규제를 라쏘 회귀에 추가한 것이다. 반대로 엘라스틱넷 회귀의 단점은 L1과 L2 규제가 결합된 규제로 인해 수행시간이 상대적으로 오래 걸린다는 것이다.
엘라스틱넷 회귀는 사이킷런 ElasticNet 클래스를 통해 구현할 수 있으며 해당 클래스의 주요 파라미터인 alpha와 l1_ratio중 alpha는 Ridge와 Lasso 클래스에서 사용되는 alpha 값과는 다르다. 엘라스틱넷 규제는 a * L1 + b * L2로 정의될 수 있으며, 이 때 a는 L1 규제의 alpha값, b는 L2 규제의 alpha 값이다. 따라서 ElasticNet 클래스의 alpha 파라미터 값은 a + b 값이다. ElasticNet 클래스의 l1_ratio 파라미터 값은 a / (a + b)이다. l1_ratio가 0이면 a가 0이므로 L2 규제와 동일하고, l1_ratio가 1이면 b가 0이므로 L1 규제와 동일하다.
정리
규제 선형 회귀의 가장 대표적인 기법인 릿지, 라쏘, 엘라스틱넷 회귀가 있고, 이들 중 어떤 것이 가장 좋은지는 상황에 따라 다르다. 각각의 알고리즘에서 하이퍼 파라미터를 변경해 가면서 최적의 예측 성능을 찾아내야 한다. 하지만 선형 회귀의 경우 최적의 하이퍼 파라미터를 찾아내는 것 못지않게 먼저 데이터 분포도의 정규화와 인코딩 방법이 매우 중요하다.
편향 분산 트레이드오프는 머신러닝이 극복해야 할 중요한 이슈 중 하나이다. 다음은 편향 분산을 직관적으로 나타내고 있는 양궁 과녁 그래프이다.
왼쪽 상단의 저편향/저분산은 예측 결과가 실제 결과에 매우 잘 근접하면서도 예측 변동이 크지 않고 특정 부분에 집중되어 있는 아주 뛰어난 성능을 보여준다. 상단 오른쪽의 저편향/고분산은 예측 결과가 실제 결과에 비교적 근접하지만, 예측 결과가 실제 결과를 중심으로 꽤 넓은 부분에 분포되어 있다. 왼쪽 하단의 고편향/저분산은 정확한 결과에서 벗어나면서도 예측이 특정 부분에 집중돼 있다. 마지막으로 하단 오른쪽의 고편향/고분산은 정확한 예측 결과를 벗어나면서도 넓은 부분에 분포되어 있다.
일반적으로 편향과 분산은 한 쪽이 높으면 한 쪽이 낮아지는 경향이 있다. 즉, 편향이 높으면 분산은 낮아지고(과소적합) 반대로 분산이 높으면 편향이 낮아진다(과적합). 다음 그림은 편향과 분산의 관계에 따른 전체 오류값의 변화를 보여준다. 편향이 너무 높으면 전체 오류가 높다. 편향을 점점 낮추면 동시에 분산이 높아지고 전체 오류도 낮아지게 됩니다. 편향을 낮추고 분산을 높이면서 전체 오류가 가장 낮아지는 골디락스지점을 통과하면서 분산을 지속적으로 높이면 전체 오류값이 오히려 증가하면서 예측 성능이 다시 저하된다.
높은 편향/낮은 분산에서 과소적합되기 쉬우며 낮은 편향/높은 분산에서 과적합되기 쉽다. 편향과 분산이 서로 트레이드오프를 이루면서 오류 Cost 값이 최대로 낮아지는 모델을 구축하는 것이 가장 효율적인 머신러닝 예측 모델을 만드는 것이다.
경사 하강법은 데이터를 기반으로 알고리즘이 스스로 학습한다는 머신러닝의 개념을 가능하게 만들어준 핵심 기법 중 하나이다. 경사 하강법의 사전적 의미인 점진적인 하강이라는 뜻에서도 알수 있듯, 점진적으로 반복적인 계산을 통해 W 파라미터 값을 업데이트하면서 오류값이 최소가 되는 W 파라미터를 구하는 방식이다.
최초 오류값이 100이었다면 두 번째 오류값은 100보다 작은 90, 세 번째는 80과 같은 방식으로 지속해서 오류를 감소시키는 방향으로 W 값을 계속 업데이트한다. 그리고 오류값이 더 이상 작아지지 않으면 그 오류값을 최소 비용으로 판단하고 그때의 W 값을 최적 파라미터로 반환한다.
경사하강법의 핵심은 어떻게 하면 오류가 작아지는 방향으로 W 값을 보정할 수 있는가에 대한 물음이 핵심이다. 속도와 같은 포물선 형태의 2차 함수의 최저점은 해당 2차 함수의 미분값인 1차 함수의 기울기가 가장 최소일 때이다. 경사 하강법은 최초 w에서부터 미분을 적용한 뒤 이 미분 값이 계속 감소하는 방향으로 순차적으로 w를 업데이트한다. 더 이상 미분된 1차 함수의 기울기가 감소하지 않는 지점을 비용 함수가 최소인 지점으로 간주하고 그때의 w를 반환한다.
일반적으로 경사 하강법은 모든 학습 데이터에 대해 반복적으로 비용함수를 최소화를 위한 값을 업데이트하기 때문에 수행 시간이 매우 오래 걸린다는 단점이 있다. 때문에 실전에서는 대부분 확률적 경사 하강법(Stochastic Gradient Descent)를 이용한다. 확률적 경사 하강법은 전체 입력 데이터로 w가 업데이트되는 값을 계산하는 것이 아니라 일부 데이터에만 이용해 w가 업데이트되는 값을 계산하므로 경사 하강법에 비해서 빠른 속도를 보장한다. 따라서 대용량의 데이터의 경우 대부분 확률적 경사 하강법이나 미니 배추 확률적 경사 하강법을 이용해 최적 비용함수를 도출한다.
회귀는 현대 통계학을 떠받치고 있는 주요 기둥 중 하나이다. 회귀 기반의 분석은 엔지니어링, 의학, 사회과학, 경제학 등의 분야가 발전하는 데 크게 기여해왔다. 회귀 분석은 유전적 특성을 연구하던 영국의 통계학자 갈톤(Galton)이 수행한 연구에서 유래했다는 것이 일반론이다. 부모와 자식 간의 키의 상관관계를 분석했던 갈톤은 부모의 키가 모두 클 때 자식의 키가 크긴 하지만 그렇다고 부모를 능가할 정도로 크지 않았고, 부모의 키가 모두 아주 작을 때 그 자식의 키가 작기는 하지만 부모보다는 큰 경향을 발견했다. 부모의 키가 아주 크더라도 자식의 키가 부모보다 더 커서 세대를 이어가면서 무한정 커지는(발산) 것은 아니며, 부모의 키가 아주 작더라도 자식의 키가 부모보다 더 작아서 세대를 이어가며 무한정 작아지는(수렴) 것이 아니라는 것이다. 즉, 사람의 키는 평균 키로 회귀하려는 경향을 가진다는 자연의 법칙이 있다는 것이다.
회귀는 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법을 통칭한다. 예를 들어 아파트의 방 개수, 방 크기, 주변 학군 등 여러 개의 독립변수에 따라 아파트 가격이라는 종속변수가 어떤 관계를 나타내는지를 모델링하고 예측하는 것이다. $Y = W_1 * X_1 + W_2 * X_2 + W_3 * X_3 + \dots + W_n * X_n$이라는 선형 회귀식을 예로 들면 $Y$는 종속변수, 즉 아파트 가격을 뜻한다. 그리고 $X_1, X_2, X_3, \dots, X_n$은 방 개수, 방 크기, 주변 학군 등의 독립변수를 의미한다. 그리고 $X_1, X_2, X_3, \dots, X_n$은 독립변수의 값에 영향을 미치는 회귀 계수(Regression coefficients)이다. 머신러닝 관점에서 보면 독립변수는 피처에 해당되며 종속변수는 결정 값이다. 머신러닝 회귀 예측의 핵심은 주어진 피처와 결정 값 데이터 기반에서 학습을 통해 최적의 회귀 계수를 찾아내는 것이다.
회귀는 회귀 계수의 선형/비선형 여부, 독립변수의 개수, 종속변수의 개수에 따라 여러가지 유형으로 나눌 수 있다. 회귀에서 가장 중요한 것은 회귀 계수이며, 이 회귀 계수가 선형인지 아닌지에 따라 선형 회귀와 비선형 회귀로 나눌 수 있다. 그리고 독립변수의 개수가 한 개인지 여러 개인지에 따라 단일 회귀, 다중 회귀로 나뉜다.
지도학습은 크게 분류와 회귀로 나뉜다. 이 두 기법의 가장 큰 차이는 분류는 예측값이 카테고리와 같은 이산형 클래스 값이고, 회귀는 연속형 숫자 값이라는 것이다.
여러 가지 회귀 중에서 선형 회귀가 가장 많이 사용된다. 선형 회귀는 실제 값과 예측값의 차이(오류의 제곱 값)를 최소화하는 직선형 회귀선을 최적화하는 방식이다. 선형 회귀 모델은 규제(Regularization) 방법에 따라 다시 별도의 유형으로 나뉠 수 있다. 규제는 일반적인 선형 회귀의 과적합 문제를 해결하기 위해서 회귀 계수에 패널티 값을 적용하는 것을 말한다. 대표적인 선형 회귀 모델은 다음과 같다.
선형 회귀 모델
일반 선형 회귀 : 예측값과 실제값의 RSS(Residual Sum of Squares)를 최소화할 수 있도록 회귀 계수를 최적화하며, 규제(Regularization)를 적용하지 않은 모델이다.
릿지(Ridge) : 릿지 회귀는 선형 회귀에 L2 규제를 추가한 회귀 모델이다. 릿지 회귀는 L2 규제를 적용하는데, L2 규제는 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키기 위해서 회귀 계수값을 더 작게 만드는 규제 모델이다.
라쏘(Lasso) : 라쏘 회귀는 선형 회귀에 L1 규제를 적용한 방식이다. L2 규제가 회귀 계수 값의 크기를 줄이는 데 반해, L1 규제는 예측 영향력이 적은 피처의 회귀 계수를 0으로 만들어 회귀 예측 시 피처가 선택되지 않게 하는 것이다. 이러한 특성 때문에 L1 규제는 피처 선택 기능으로도 불린다.
엘라스틱넷(LeasticNet) : L2, L1 규제를 함께 결합한 모델이다. 주로 피처가 많은 데이터 셋에서 적용되며, L1 규제로 피처의 개수를 줄임과 동시에 L2 규제로 계수 값의 크기를 조정한다.
로지스틱 회귀(Logistic Regression) : 로지스틱 회귀는 회귀라는 이름이 붙어 있지만, 사실은 분류에 사용되는 선형 모델이다. 로지스틱 회귀는 매우 강력한 분류 알고리즘이다. 일반적으로 이진 분류뿐만 아니라 희소 영역의 분류, 예를 들어 텍스트 분류와 같은 영역에서 뛰어난 예측 성능을 보인다.
단순 선형 회귀를 통한 회귀 이해
단순 선형 회귀는 독립변수도 하나, 종속변수도 하나인 선형 회귀이다. 예를 들어, 주택 가격이 주택의 크기로만 결정된다고 하면 2차원 평면에 직선(선형)형태의 관계로 표현할 수 있다. $X$축이 주택의 크기이고, $Y$축이 가격이라할 경우 1차 함수식으로 모델링할 수 있다.
$\hat{Y} = \omega_0 + \omega_1 * X$
위 설명의 모델링과는 별개로 선형 회귀 모델을 보이기 위한 자료
독립 변수가 1개인 단순 선형 회귀에서는 기울기인 $\omega_1$과 절편인 $\omega_0$을 회귀 계수로 지칭한다. 위와 같은 1차 함수로 모델링했다면 실제 주택 가격은 이러한 1차 함수 값에서 실제 값만큼의 오류 값을 빼거나 더한 값이 된다.
이렇게 실제값과 회귀 모델의 차이에 따른 오류값을 남은 오류, 즉 잔차라 부른다. 최적의 회귀 모델을 만든다는 것은 전체 데이터의 잔차(오류값) 합이 최소가 되는 모델을 만든다는 의미이며, 동시에 오류값 합이 최소가 될 수 있는 최적의 회귀 계수를 찾는다는 의미이다.
오류값은 +나 -가 될 수 있기에 전체 데이터의 오류합을 구하기 위해 단순히 더할경우 뜻하지 않게 오류합이 줄어들 수 있다. 따라서 보통 오류합을 계산할 때는 절대값을 취해서 더하거나, 오류값의 제곱을 구해서 더하는 방식(RSS, Residual Sum of Square)를 취한다. 일반적으로 미분 등의 계산을 편리하게 하기 위해서 RSS(Residual Sum of Square) 방식으로 오류합을 구한다. 즉, $Error^2 = RSS$이다.
$RSS$는 이제 변수가 $\omega_0, \omega_1$인 식으로 표현할 수 있으며, 이 $RSS$를 최소로 하는 $\omega_0, \omega_1$, 즉 회귀 계수를 학습을 통해서 찾는 것이 머신러닝 기반 회귀의 핵심 사항이다. $RSS$는 회귀식의 독립변수 $X$, 종속변수 $Y$가 중심 변수가 아니라 $\omega$ 변수(회귀 계수)가 중심 변수임을 인지하는 것이 매우 중요하다(학습 데이터로 입력되는 독립변수와 종속변수는 $RSS$에서 모두 상수로 간주한다. 일반적으로 $RSS$는 학습 데이터의 건수로 나누어서 다음과 같이 정규화된 식으로 표현된다.
회귀에서 $RSS$는 비용(Cost)이며 $\omega$ 변수(회귀 계수)로 구성되는 $RSS$를 비용 함수라고 한다. 머신러닝 회귀 알고리즘은 데이터를 계속 학습하면서 이 비용 함수가 반환하는 값(즉, 오류값)을 지속해서 감소시키고 최종적으로는 더 이상 감소하지 않는 최소의 오류값을 구하는 것이다. 비용 함수를 손실 함수(loss function)라고도 한다.
회귀 평가 지표
회귀의 평가를 위한 지표는 실제값과 회귀 예측값의 차이값을 기반으로 한 지표가 중심이다. 실제값과 예측값의 차이를 단순히 더하면 +와 -가 섞여서 오류가 상쇄된다. 예를 들어 데이터 두 개의 예측 차이가 하나는 -3, 다른 하나는 +3일 경우 단순히 더하면 오류가 0으로 나타나기 때문에 정확한 지표가 될 수 없다. 따라서 오류의 절대값 평균이나 제곱, 또는 제곱한 뒤 다시 루트를 씌운 평균값을 구한다. 일반적으로 회귀의 성능을 평가하는 지표는 다음과 같다.
평가 지표
설명
수식
MAE
Mean Absolute Error이며 실제값과 예측값의 차이를 절대값으로 변환해 평균한 것
분산 기반으로 예측 성능을 평가한다. 실제값의 분산 대비 예측값의 분산 비율을 지표로 하며, 1에 가까울수록 예측 정확도가 높음
$R^2 = {예측값 Variacne \over 실제값 Variance}$
이외에도 MSE나 RMSE에 로그를 적용한 MSLE(Mean Squared Log Error)와 RMSLE(Root Mean Squared Log Error)도 사용한다. 사이킷런은 RMSE를 제공하지 않는다. 따라서 RMSE를 구하기 위해서는 MSE에 제곱근을 씌워서 계산하는 함수를 직접 만들어야 한다. 다음은 각 평가 방법에 대한 사이킷런의 API 및 cross_val_score나 GridSearchCV에서 평가 시 사용되는 scoring 파라미터의 적용값이다.
이상치 데이터는 아웃라이어라고도 불리며 전체 데이터의 패턴에서 벗어난 이상 값을 가진 데이터이다.
이로인해 머신러닝 모델의 성능에 영향을 받는 경우가 발생하기 쉽다. 이상치를 찾는 방법은 여러 가지가 있지만 대표적으로 IQR(Inter Quantile Range) 방식을 적용할 수 있다
Inter Quantile Range
IQR는 사분위(Quantile) 값의 편차를 이용하는 기법으로 흔히 박스 플롯(Box Plot) 방식으로 시각화할 수 있다.
사분위는 전체 데이트를 값을 오름차순하고 1/4(25%)씩 구간을 분할하는 것을 지칭한다.
가령 100명의 시험 성적이 0점부터 100점까지 있다면, 이를 100등부터 1등까지 성적순으로 정렬한 뒤에 1/4 구간으로 Q1, Q2, Q3, Q4와 같이 나누는 것이다.
IQR을 이용해 이상치 데이터를 검출하는 방식은 아래와 같이 보통 IQR에 1.5를 곱해서 생성된 범위를 이용해 최댓값과 최솟값을 결정한 뒤 최댓값을 초과하거나 최솟값에 미달하는 데이터를 이상치로 간주하는 것이다.
이상치 데이터를 검출하기 위해서는 가장 먼저 어떤 피처의 이상치를 뽑을 것인지에 대한 선택이 중요합니다. 매우 많은 피처가 있을 경우 이들 중 결정값과 가장 상관성이 높은 피처들을 위주로 이상치를 검출하는 것이 좋다. 모든 피처들의 이상치를 검출하는 것은 시간 자원이 많이 소모되며, 결정값과 상관성이 높지 않은 피처일 경우 이상치를 제거하더라도 성능 향상에 기여하지 않기 떄문이다. DataFrame의 corr()를 이용해 각 피처별로 상관도를 구한 뒤 시본의 heatmap을 사용해 시각화가 가능하다.
지도학습에서 극도로 불균형한 레이블 값 분포로 인한 문제점을 해결하기 위해선 적절한 학습 데이터를 확보하는 방안이 필요하다. 대표적으로 오버 샘플링과 언더 샘플링 방법이 있다. 오버 샘플링 방식이 예측 방식이 예측 성능상 더 유리한 경우가 많아 주로 사용된다. 다음은 샘플링 방법을 설명한다.
언더 샘플링은 많은 데이터 셋을 적은 데이터 셋 수준으로 감소시키는 방식이다. 가령 정상 레이블을 가진 데이터가 10,000건, 비정상 레이블을 가진 데이터가 100건이 있을 경우 정상 레이블 데이터를 100건으로 줄이는 방식이다.
오버 샘플링은 비정상 데이터와 같이 적은 데이터 셋을 증식하여 학습을 위한 충분한 데이터를 확보하는 방법이다. 동일한 데이터를 단순히 증식하는 방법은 과적합이 되기 때문에 의미가 없으므로 원본 데이터의 피처 값들을 아주 약간만 변경하여 증식하며 대표적으로 SMOTE(Synthetic Minority Over-Sampling Technique) 방법이 있다.
SMOTE
SMOTE는 적은 데이터 셋에 있는 개별 데이터들의 K 최근접 아웃(K Nearest Neighbor)을 찾아서 이 데이터와 K개 이웃들의 차이를 일정 값으로 만들어서 기존 데이터와 약간 차이가 나는 새로운 데이터들을 생성하는 방식이다.
LightGBM은 XGBoost와 함께 부스팅 계열 알고리즘에서 가장 각광을 받고 있다. XGBoost의 경우 매우 뛰어난 부스팅 알고리즘이지만 여전히 학습 시간이 오래 걸린다는 단점이 있다.
XGBoost에서 GridSearchCV로 하이퍼 파라미터 튜닝을 수행하다 보면 수행 시간이 너무 오래걸려서 많은 파라미터를 튜닝하기에 어려움을 겪을 수 밖에 없다. 물론 GBM보다는 빠르지만, 대용량 데이터의 경우 만족할 만한 학습 성능을 기대하려면 많은 CPU 코어를 가진 시스템에서 높은 병렬도로 학습을 진행해야 한다.
LightGBM의 가장 큰 장점은 XGBoost보다 학습에 걸리는 시간이 훨씬 적고 메모리 사용량도 상대적으로 적다. 'Light'라는 이미지가 가벼움을 뜻하게되어 상대적으로 떨어진다든가 기능상의 부족함이 있다고 인식될 수 있으나 실상은 그렇지 않다.
LighGBM과 XGBoost의 예측 성능은 별다른 차이가 존재하지 않는다. 또한 기능상의 다양성은 LightGBM이 약간 더 많다. XGBoost가 만들어진 2년 후에 LightGBM이 만들어졌기에 XGBoost의 장점은 계승하고 단점은 보완하는 방식으로 개발되었기 때문이다.
그럼에도 불구하고 LightGBM의 한 가지 단점으로는 적은 데이터 셋에 적용할 경우 과적합이 발생하기 쉽다는 것이다. 적은 데이터 셋의 기준은 일반적으로 10,000건 이하의 데이터 셋이라 LightGBM 공식 문서에서 기술하고 있다.
LightGBM은 일반 GBM 계열의 트리 분할 방법과 달리 리프 중심 트리 분할(Leaf Wise) 방식을 사용한다. 기존의 대부분 트리 기반 알고리즘은 트리의 깊이를 효과적으로 줄이기 위한 균형 트리 분할(Level Wise) 방식을 사용한다.
즉, 최대한 균형 잡힌 트리를 유지하면서 분할하기 때문에 트리의 깊이가 최소화될 수 있다. 반대로 균형을 맞추기 위한 시간이 필요하다는 상대적 단점이 있다.
LightGBM의 리프 중심 트리 분할 방식은 트리의 균형을 맞추지 않고, 최대 손실 값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 규칙 트리가 생성된다. 하지만 이렇게 최대 손실값을 가지는 리프 노드를 지속적으로 분할해 생성된 규칙 트리는 학습을 반복할수록 결국은 균형 트리 분할 방식보다 예측 오류 손실을 최소화 할 수 있다는 것이 LightGBM의 구현 사상이다.
LightGBM 하이퍼 파라미터
LightGBM의 하이퍼파라미터의 경우 XGBoost와 달리 리프 노드가 계속 분할되면서 트리의 깊이가 깊어지므로 이러한 트리 특성에 맞는 하이퍼 파라미터 설정이 필요하다. 예를들면 max_depth를 매우 크게 가지는 것이 있다.
- learning_rate를 작게하면서 n_estimators를 크게 하는 것은 부스팅 계열 튜닝에서 가장 기본적인 튜닝 방안
- n_estimators를 너무 크게 하는 것은 과적합으로 오히려 성능 저하가 될 수 있음
- 과적합을 제어하기 위해 reg_lambda, reg_alpha와 같은 regularization을 적용하거나 학습 데이터에 사용할 피처의 개수나 데이터 샘플링 레코드 개수를 줄이기 위해 colsample_bytree, subsample 파라미터를 적용할 수 있음
※ 주의: LightGBM이 버전업 되면서boost_from_average파라미터의 디폴트 값이 False에서 True로 변경됨. 레이블 값이 극도로 불균형한 분포를 이루는 경우 boost_from_average=True 설정은 재현률 및 ROC-AUC 성능을 매우 크게 저하시킨다. LightGBM 2.1.0 이상의 버전이 설치되어 있거나 불균형한 데이터 셋에서 예측 성능이 매우 저조할 경우 LightGBMClassifer 객체 생성 시 boost_from_average=False로 파라미터 설정해야함.
XGBoost(eXtra Gradient Boost)는 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나이다. 캐글 경연 대회에서 상위를 차지한 많은 데이터 사이언티스트가 XGBoost를 이용하면서 널리 알려졌다. 압도적 수치의 차이는 아니지만, 분류에 있어 일반적으로 다른 머신러닝보다 뛰어난 예측 성능을 나타낸다.
XGBoost는 GBM에 기반하고 있지만, GBM의 단점인 느린 수행 시간 및 과적합 규제(Regularization) 부재 등의 문제를 해결해서 매우 각광을 받고 있다. 특히 XGBoost는 병렬 CPU 환경에서 병렬 학습이 가능해 기존 GBM보다 빠르게 학습을 완료할 수 있다.
XGBoost 장점
일반적으로 분류와 회귀 영역에서 뛰어난 예측 성능을 발휘
일반적인 GBM은 순차적으로 Weak learner가 가중치를 증감하는 방법으로 학습키 때문에 전반적으로 속도가 느림. 하지만 XGBoost는 병렬 수행 및 다양한 기능으로 GBM에 비해 빠른 수행성능 보장
표준 GBM의 경우 과적합 규제 기능이 없으나 XGBoost는 자체 과적합 규제 기능으로 과적합에 좀 더 강한 내구성을 가질 수 있음
다른 GBM과 마찬가지로 max_depth 파라미터로 분할 깊이를 조정하기도 하지만, tree pruning으로 더 이상 긍정 이득이 없는 분할을 가지치기 해서 분할 수를 더 줄이는 추가적인 장점이 있음
반복 수행 시마다 내부적으로 학습 데이터 셋과 평가 데이터셋에 대한 교차 검증을 수행해 최적화된 반복 수행 횟수를 가질 수 있고, 최적화 되면 반복을 중간에 멈출 수 있는 조기 중단 기능이 있음.
XGboost는 자체적으로 교차 검증, 성능 평가, 피처 중요도 등의 시각화 기능을 가지고 있음
DMatrix
파이썬 래퍼 XGBoost는 사이킷런과 차이가 여러 가지 있지만, 먼저 눈에 띄는 차이는 학습용과 테스트용 데이터 셋을 위해 별도의 객체인 DMatrix를 생성한다는 점이다. DMatrix는 주로 넘파이 입력 파라미터를 받아서 만들어지는 XGBoost만의 전용 데이터셋이다. DMatrix의 주요 입력 파라미터는 data와 label이다.
data는 피처 데이터 셋이며, label은 분류의 경우에는 레이블 데이터 셋, 회귀의 경우는 숫자형인 종속값 데이터 셋이다.
xgboost 모듈을 사용해 학습을 수행하기 전에 하이퍼 파라미터를 설정하며 하이퍼 파라미터의 경우 주로 딕셔너리 형태로 입력한다. 또한 xgboost 모듈의 경우 train() 함수에 파라미터로 전달하며 사이킷런에서는 Estimator의 생성자를 하이퍼 파라미터로 전달하는 데 반해 차이가 있다.
부스팅 알고리즘은 여러 개의 약한 학습기를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식이다.
구현 알고리즘
부스팅의 대표적인 구현은 AdaBoost(Adaptive boosting)와 GBM(Gradient Boost Machine)이 있다.
AdaBoost
오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘
학습 진행 방법은 다음과 같다.
만약 +, -로 피처 데이터셋이 존재하고 Iteration 1과 같이 +를 탐지하려 하였으나 탐지를 하지 못하게되면 Iteration 2와 같이 +의 크기를 키워(가중치를 키워) 다음 약한 학습기가 더 잘 분류할 수 있도록 진행한다.
에이다 부스트는 위와 같이 약한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측을 수행한다.
그 결과 위 그림의 Final Classifier/Strong classifier와 같이 이전의 학습기를 모두 결합한 예측을을 하여 정확도가 높아지는 것을 알 수 있다.
GBM (Gradient Boosting Machine)
에이다부스트와 유사한, 가중치 업데이트를 경사 하강법을 이용하는 것이 큰 차이다.
오류 값은 "실제 값 - 예측 값"이다. 분류의 실제 결과값을 $y$, 피처를 $x_1, x_2,\dots, x_n$, 그리고 이 피처에 기반한 예측 함수를 $F(x)$ 함수라고 하면 오류식 $h(x) = y - F(x)$가 된다.
해당 오류식 $h(x) = y - F(x)$를 최소화 하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것이 경사 하강법이다. 경사 하강법은 머신러닝에서 중요한 기법 중 하나이며, "반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법"으로 이해하면 좋다. 또한 경사 하강법의 경우 회귀를 다룰 때 구체적인 개념을 더 필요로 한다.
배깅(bagging)은 앞에서 보팅과는 다르게, 같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 알고리즘이다. 배깅의 대표적인 알고리즘이 랜덤 포레스트이며 이는 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있고, 다양한 영역에서 높은 예측 성능을 보인다.
랜덤 포레스트의 기반 알고리즘은 결정 트리로서, 결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있다.
또한 랜덤 포레스트뿐만 아니라 부스팅 기반의 다양한 앙상블 알고리즘 역시 대부분의 결정 트리 알고리즘을 기반 알고리즘으로 채택하고 있다.
랜덤 포레스트는 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측을 결정하게 된다.
랜덤 포레스트는 개별적인 분류기의 기반 알고리즘은 결정 트리지만 개별 트리가 학습하는 데이터 셋은 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 셋이다.
여러 개의 데이터 셋을 중첩되게 분리하는 것을 부트스트래핑(bootstrapping) 분할 방식이라 한다. 그래서 배깅(Bagging)이 bootstrap aggregating의 줄임말이다. 원래 부트스트랩은 통계학에서 여러 개의 작은 데이터 셋을 임의로 만들어 개별 평균 분포도를 측정하는 등의 목적을 위한 샘플링 방식을 지칭한다.
랜덤 포레스트의 서브셋(Subset) 데이터는 이러한 부트스트래핑으로 데이터가 임의로 만들어진다. 서브셋 데이터 건수는 전체 데이터 건수와 동일하지만, 개별 데이터가 중첩되어 만들어진다. 원본 데이터의 건수가 10개인 학습 데이터 셋에 랜덤 포레스트를 3개의 결정 트리 기반으로 학습하려고n_estimators = 3으로 하이퍼 파라미터를 부여하면 다음과 같이 데이터 서브 셋이 만들어진다.
앙상블 학습을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종예측을 도출하는 기법을 의미
어려운 문제의 결론을 내기 위해 여러 명의 전문가로 위원회를 구성해 다양한 의견을 수렴하고 결정하듯, 앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것
즉, 집단지성을 이용.
앙상블 알고리즘
앙상블 알고리즘의 대표격인 랜덤포레스트와 그래디언트 부스팅 알고리즘의 경우 뛰어난 성능과 쉬운 사용, 다양한 활용도로 인해 많이 사용되어 옴
부스팅 계열의 앙상블 알고리즘의 인기와 강세가 계속 이어져 기존의 그래디언트 부스팅을 뛰어넘는 새로운 알고리즘이 개발 가속화가 됐으며, 이로 인해 캐글에서는 XGBoost 그리고 XGBoost와 유사한 예측 성능을 가지면서 훨씬 빠른 수행 속도를 가진 LightGBM, 여러가지 모델의 결과를 기반으로 메타 모델을 수립하는 스태킹(Stacking)을 포함해 다양한 유형의 앙상블 알고리즘이 머신러닝의 선도 알고리즘으로 인기를 모으고 있음
XGboost, LightGBM과 같은 최신 앙상블 모델 한두 개만 잘 알고 있어도 정형 데이터의 분류나 회귀 분야에서 예측 성느이 매우 뛰어난 모델을 쉽게 만들 수 있음.
앙상블 학습 유형
보팅(Voting)
배깅(Bagging)
Bootstrap Aggregating의 줄임말이다.
원래 데이터에 대해서 여러개의 작은 데이터셋 N개를 샘플링해서 만든다음, 각각의 데이터를 작은 모델 N개로 학습을 시킨다.
이후 다음 학습된 N개의 모델을 모두 하나로 합쳐서 최종적인 모델로 사용하는(bag에 담는 느낌) 방법론을 의미한다. (병렬적으로 데이터를 나누어 여러 개의 모델을 동시에 학습시킴)
부스팅(Boosting)
보팅과 배깅의 경우 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식
보팅과 배깅의 차이점은 보팅의 경우 일반적으로 서로 다른 알고리즘을 가진 분류기를 결합하는 것이고, 배깅의 경우 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅을 수행하는 것. 대표적인 배깅방식이 바로 랜덤 포레스트 알고리즘임
아래는 보팅 분류기를 도식화한 것임
Voting 방식
아래 그림 수정 필요 잘못 삽입.
Bagging 방식
보팅 유형
하드 보팅 (Hard Voting)
다수결의 원칙과 비슷하며, 예측 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정
소프트 보팅 (Soft Voting)
분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정. 일반적으로 소프트 보팅 방법으로 적용됨
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 것이다.
일반적으로 규칙을 가장 쉽게 표현하는 방법은 if/else 기반으로 나타내는 것이다.
예를 들면 스무고개 게임과 유사하며 규칙 기반 프로그램에 적용되는 if, else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘이다.
- Q1이루트 노드가 된다.
- Q2, Q3가규칙 노드가 된다.
- Q4, Q5, Q6, Q7이규칙 노드가 된다.
- 빨간색으로 표시된 END1, END3, END5, END7이 결정이 된 분류값으로리프 노드가 된다.
- 결정되지 않은 값인 END2, END4, END6, END8은 다시 규칙 노드가 되며 아래로 계속해서 노드가 생성된다.
- 트리의 깊이가 깊어질수록 과적합이 발생할 가능성이 있고 성능 저하를 초래할 수 있다
!! 따라서 가능한 적은 결정 노드로 최대한 많은 데이터 셋이 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 하며, 이를 위해서어.떻.게 트리를 분할할 것인가에 대한기준을 정하는 것이가장 중요하다.
결정 노드의 정보 균일도
결정노드는 정보 균일도가 높은 데이터 셋을 먼저 선택할 수 있도로 규칙 조건을 만든다.
정보의 균일도를 측정하는 대표적 방법은 엔트로피를 이용한 정보 이득(Information Gain)지수와 지니 계수가 있다.
정보 이득
엔트로피를 기반으로 하며, 여기서 엔트로피는 주어진 데이터 집합의 혼잡도를 의미한다. 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다. 정보 이득 지수는 1에서 엔트로피 지수를 뺀 값이다.결정트리는 정보 이득 지수로 분할 기준을 정한다.
지니 계수
경제학에서 불평등 지수를 나타낼 때 사용하는 계수다. 경제학자인 코라도 지니의 이름에서 딴 계수로, 0이 가장 평등하고 1로 갈수로 불평등하다. 머신러닝에 적용될 때는 지니 계수가 낮을수록 데이터 균일도가 높은 것으로 해석된다.따라서 결정트리는 지니 계수가 낮은 속성을 분할기준으로 정한다.
결정트리 알고리즘을 사이킷런에서 구현한DecisionTreeClassifier는 기본으로 지니 계수를 이용해 데이터 셋을 분할한다.
결정 트리 모델의 특징
결정 트리의 경우 '균일도'라는 룰을 기반으로 하고 있어, 알고리즘이 쉽고 직관적이다. 정보의 균일도만 신경 쓰면 되기에 특별한 경우를 제외하고, 각 피처의 스케일링과 정규화 같은 전처리 작업이 필요하지 않다.
반면 결정 트리 모델의 가장 큰 단점으로는 과적합으로 인해 정확도가 떨어진다는 점이다.
모든 데이터의 상황을 만족하는 완벽한 규칙을 만들지 못하는 경우가 훨씬 많다. 정확도를 높이기 위해 계속해서 규칙을 추가할 경우 트리가 깊어지고, 커지고, 복잡해진다. 이렇게 될 경우 유연하게 대처할 수 없기에 예측 성능이 떨어진다. 따라서 완벽할 수 없다는 것을 인정하면 더 나은 성능을 보장할 가능성이 높다. 즉, 트리의 크기를 사전에 제한하는 것이 오히려 성능 튜닝에 더 도움이 된다.
결정 트리 파라미터
사이킷런은 결정 트리 알고리즘을 구현한 두 가지 클래스를 제공한다.
DecisionTreeClassifier
분류를 위한 클래스
DeicsionTreeRegressor
회귀를 위한 클래스
DecisionTreeClassifier와DeicsionTreeRegressor는 모두 동일한 파라미터를 사용한다.
min_samples_split
노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는 데 사용
디폴트는 2고 작게 설정할수록 분할되는 노드가 많아져서 과적합 가능성 증가
과적합을 제어. 1로 설정할 경우 분할되는 노드가 많아져 과적합 가능성 증가
min_samples_leaf
말단 노드가 되기 위한 최소한의 샘플 데이터 수
min_samples_split과 유사하게 과적합 제어 용도. 그러나 비대칭(imbalanced) 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 이 경우는 작게 설정 필요
max_features
최적의 분할을 위해 고려할 최대 피처 개수. 디폴트는 None으로 데이터 셋의 모든 피처를 사용해 분할 수행
max_depth
트리의 최대 깊이 규정, 디폴트는 None
None으로 설정하면 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키우며 분할하거나, 노드가 가지는 데이터 개수가 min_samples_split보다 작아질 때까지 계속 깊이를 증가시킴
max_leaf_nodes
말단 노드의 최대 개수
결정 트리 모델의 시각화
Graphviz 패키지를 사용해서 가능하다. 사이킷런은 Graphviz 패키지와 쉽게 인터페이스할 수 있도록export_graphviz()API를 제공한다.
export_graphviz()는 함수 인자로 학습이 완료된 Estimator, 피처의 이름 리스트, 레이블 이름 리스트를 입력하면 학습된 결정 트리 규칙을 실제 트리 형태로 시각화해 보여준다.
결정트리의 하이퍼파라미터
하이퍼 파라미터의 경우 과적합이 쉽게 되는 결정 트리 알고리즘을 제어하기 위해 사용되며, 복잡한 트리가 생성되는 것을 막는다.
max_dpeth 하이퍼 파라미터
max_depth의 경우 결정 트리의 최대 깊이를 제어하며, 만약 더 작은 수로 깊이를 설정할 경우 더 간단한 결정 트리가 된다.
min_samples_split 하이퍼 파라미터
자식 규칙 노드를 분할해 만들기 위한 최소한의 샘플 데이터 개수
만약 min_samples_splits 하이퍼 파라미터 값을 4로 설정한 경우 다음과 같은 결정트리 그래프가 생성된다.
표시된 사선 박스를 확인하면 [0, 2, 1]과 [0, 1, 2]로 서로 상이한 클래스 값이 있어도 더 이상 분할하지 않고 리프 노드가 된다.
만약 min_samples_splits 하이퍼 파라미터 값을 5로 지정해주면 다음과 같은 결정트리 그래프가 생성된다.
앞서 보인 그래프와 달리 깊이가 1 증가하면서 추가적인 노드가 생성되어 모든 분류가 진행된 것을 확인할 수 있다.
min_samples_leaf 하이퍼 파라미터
해당 파라미터의 값을 키울 경우 더 이상 분할하지 않고, 리프 노드가 될 수 있는 조언이 완화된다. 즉, 지정 값 기준만 만족하면 리프노드가 된다
예시로는 min_samples_leaf 값을 4로 설정할 경우 샘플이 4이하이면 리프 노드가 되기에, 지니 계수 값이 크더라도 이를 무시한다.
Sample이 4이상인 노드는 리프 클래스 노드가 될 수 있음므로 규칙이 sample 4인 노드를 만들 수 있는 상황을 반영하여 변경된다.
결정 트리의 경우 어떤 속성을 규칙 조건으로 선택하느냐가 중요한 요건이다.
Feature의 중요 역할 지표
사이킷런에서는 결정트리 알고리즘이 학습을 통해 규칙을 정하는 데 있어 피처의 중요한 역할 지표를 DecisionTreeClassifier 객체의 feature_importances_ 속성으로 제공한다.
피처의 값이 높을 수록 중요도가 높음을 의미하고 예시는 다음과 같다.
네 가지 피쳐중 petal length에 해당하는 피처가 가장 중요도가 높음을 알 수 있다.