삶에서 무의미 직시는 주체적인 삶으로의 시작이다. 이는 피상적인 삶에 대한 의심으로부터 비롯된다. 우리는 인간의 생애주기라는 파도에 떠밀려 살아간다. 우리는 이 파도를 거스를순 없어도 파도에 떠밀리고 있다는 사실은 자각할 수 있다. 하지만 이러한 자각은 쉽게 주어지지 않는다. 내 생각이 실은 나로부터 비롯되지 않았음을 깨달아야 하기 때문이다. 그것은 파도가 나에게 부여했던 생각이며, 나는 파도 그가 원하는 방향으로 휩쓸리고 있다는 것 말이다. 이러한 자각은 인간 자신이 좇던 목표가 맹목적이었음을, 사실은 파도에 의해 떠밀리고 있음을, 무의미했음을 깨달을 때 주어진다. 자각의 정도는 목표를 향해 헌신했던 정도에 비례한다. 많은 시간과 에너지를 쏟았던 것이 허무한 것이었음을 깨달을 때 그 간극만큼 고통을 느끼게 된다. 이 때 인간은 자기자신을 마주하고 소통할 기회를 갖게 되며 삶의 의미를 묻기 시작한다.
삶의 의미는 주로 철학과 종교에서 다루는 영역으로 그 의미의 정점은 '신'이라는 이름으로 불리우는 것을 알게 된다. 이러한 '신'이라는 것의 표상을 이해한 자의 삶에는 불변하는 삶의 목적이 들어서게 된다. 그러한 자는 그 목적을 위해 헌신하는 삶으로의 방향으로 나아가고자 한다. 거대한 파도와의 합일을 이룰 수 있는 주체적인 목표를 설정하는 것이다. 하지만 이 또한 잠시 '신'으로부터 비롯된 삶의 의미는 파도의 전모를 이해하는 반쪽이었음을 알게 된다. 니체는 '신'으로부터 연역된 삶의 의미를 강렬하게 거부하고 비판했다. 이를 통해 인간은 다시 한 번 삶의 무의미로 회귀하게 되었지만 이전에 자각한 무의미와는 다르다. 이전에 자각한 무의미는 방향을 상실한 것이었다면, 니체가 제시한 무의미는 삶의 초점으로서 이를 긍정하는 것이다. 즉 삶은 본디 무의미하지만, 인간실존으로서 주체적으로 삶의 의미를 부여하며 살 것을 말한 것이다. 이러한 자각을 가진 자는 실존에게 주어진 자유를 느끼며 진정 자기자신이 원하는 삶을 향해 서핑을 하게 된다.
물질주의가 현시하는 삶의 무목적성에서 깨어난 이들이 마주하는 현실은 악이 선(善)을 휘두르는 세상이며, 많은 이들이 선을 알지 못해 악으로 향하는 세상이다. 추상적으로 느껴지던 선악에 대한 관념은 깨어난 이들에게 명료하게 인식되기 시작하며 이러한 자들은 선악식별을 명확히하기 어려운 자들이 악을 선이라 착각하고 또 악에 휘둘리는 비참한 광경을 목도하게 된다. 이러한 광경으로부터 선을 지키려는 문제 의식이 태동하며 나아가 사회에 대한 만연한 악을 걷어내고자 하는 고독한 길을 향한 의지를 불피우게 된다. 이를 통해 인간은 삶의 목적과 의미를 파악하게 되며 널리 선을 구현하고자 하는 소명의식이 깃들게 된다.
선을 통해 깃든 소명의식은 앞으로 나아가야할 방향을 제시한다는 점에서 인간이 삶을 영위하는 데 있어 훌륭한 지침이자 기준이 된다. 또 이를 통해 많은 사람이 구가하는 돈, 명예, 권력과 같은 세속적인 가치의 혼탁함에서 벗어나 삶을 더욱 명징하게 볼 수 있게 된다. 이러한 소명의식이 깃든 사람이 제시하는 삶의 방향과 가치는 많은 사람을 감화시킬 수 있는 힘이 있다. 감화된 많은 사람들은 기꺼이 자발적으로 동참하여 뜻을 함께하고자 하며 이러한 형태가 권력으로서 작용한다. 이러한 형태로 잉태된 권력은 선의지를 향한다.
선을 인식하고 소명의식이 깃든 자는 공동체를 향한 삶에 뜻을 두고 살아간다. 하지만 필연적으로 가해지는 선의 무게는 삶을 짓누르며 삶에는 발랄한 생기보다는 엄숙함이 들어서게 된다. 속담대로 왕관을 쓰려는 자 그 무게를 견뎌야 하는 것이다. 엄밀하게는 왕관을 써야되는 자 그 무게까지 견뎌내야 하는 것이다. 그 이유는 ‘자신’의 자유의지가 아닌 선이 내리는 ‘명령’의 인식이 세상에 대한 사랑과 책임감의 형태로 나타나 한 인간의 의식에서 삶을 짓누르기 때문이다.
이러한 선의 ‘명령’은 인간이면 누구나 들을 수 있다. 하지만 자신의 본성에 내재된 선을 인식하고 개화하는 자들은 소수에 해당한다. 이러한 소수들은 때때로 자신과 세상과 자연에 대한 의문과 호기심에서 출발한다. 나는 누구인가? 세상은 무엇이며 자연은 어떻게 존재할 수 있는가? 우리 인간은 어디를 향해 나아가며, ‘신’이란 또 무엇인가?와 같은 존재의 근원을 탐구하면서 선을 인식할 수 있는 기틀을 마련하게 된다. 이러한 존재의 근원에 대한 탐구는 강한 지적 호기심에서도 시작되지만 삶의 위기로부터도 시작된다. 큰 성취 뒤에 느껴지는 허무감과 삶의 방향에 대한 강한 회의와 의문은 인간의 삶에 실존의 위협을 주며 이 때 인간은 근본적으로 존재의 근원에 대한 물음이 일지 않을 수 없다.
이러한 존재 근원에 대한 물음은 인류의 수 많은 철학자 또는 성인이라 불리는 자들이 끌어안았던 문제다. 인류의 4대 성인이라 불리는 부처, 예수, 공자, 소크라테스의 공통점은 인간 존재에 대한 깊은 이해가 있었다는 점이며 그들의 육체는 죽었으나 그들의 위대한 정신은 죽지 않고 현대까지도 살아남아 계승되고 있다. 인류가 나아갈 방향을 제시했다는 점에서 먼 훗날에 도래할 인류에게까지 영향을 미칠 것이다.
부처는 존재 근원에 대한 물음에 무아(無我)라고 했다. 우리가 ‘나’라고 생각하고 살아가는 ‘존재’에 대해 '나’라고 결정지을 수 있는 그 어떠한 속성도 없다는 것이다. 이를 확장하여 부처는 삼라만상이 제행무상(諸行無常)이라 했다. 세상 만물은 상호의존에 의해 일시적으로 생성하고 소멸하는 존재라는 것이다. 이를 두고 부처는 세상 만물이 비어있다, 공(空)하다고 표현했고 인류가 이를 깨닫기를 바랐다. 이러한 ‘자아’의 무상함을 깨닫게 되면 ‘나’라는 존재에서 이기심이 줄어들고 그 자리에 이타심이 피어오를 것이기 때문이며, 또 이 이타심은 세상을 향한 선으로 작용하여 궁극적으로 모두가 하나 된 마음인 화엄의 세계가 펼쳐질 것이기 때문이다.
예수는 존재 근원에 대한 물음에 사랑이라 했다. 여기서 말하는 사랑이란 아가페적인 사랑으로 인류를 널리 사랑하는 박애정신을 의미한다. 기독교 정신의 핵심은 내 안에 깃든 성령을 인식하고 이 성령이 ‘하나님’과 같다는 것을 깨닫는 것이다. 기독교에서는 우리는 모두 ‘하나님’의 자녀이기 때문에 형제 자매라고 부른다. 그리고 우리 형제 자매에게는 모두 성령이 깃들어 있다고 말한다. 또 우리는 성령으로 하나된다고 말한다. 기독교 삼위일체에 따르면 성부, 성자, 성령은 하나다. 즉 형제 자매에게 깃든 성령은 성부안에서 하나되는 것이다. ‘하나’ 되기 때문에 이는 우리가 서로 다른 존재가 아님을 의미한다. ‘너’라고 부르는 타인은 ‘나’인 것이다. 이를 진정으로 인식하게 된다면 ‘나’의 또 다른 모습인 ‘너’를 위해 용서하고 배려하고 자비를 베푸는 사랑을 실천하게 되는 것이다. 그리고 이 성령을 모두가 인식하고 서로가 하나의 존재임을 인식하며 살아가는 세상이 천국이 되는 것이다. 이 천국이 곧 모든 악을 걷어내고 모두가 선을 구가하는 세계가 된다.
공자는 존재 근원에 대한 물음에 인(仁)이라 했다. 여기서 인(仁)이란 인의예지(仁義禮智)의 인(仁)이다. 인의예지란 ‘인’을 깨닫게 되면 ‘의(옳음)’가 무엇인지 알게되고 ‘의(옳음)’를 알면 ‘예’를 행하게 되며 ‘예’를 행하는 삶의 태도가 ‘지(지혜)’로 나타난다는 것이다. 따라서 인의예지 구조에는 순서가 있다. 인(仁)을 깨닫는 것이 먼저다. 그러면 나머지는 자연스레 체득하게 된다. 그렇다면 인(仁)이란 무엇일까? 인(仁)이라는 문자의 형상을 보면 두 사람이다. 이는 곧 ‘우리’를 의미하며 ‘우리’는 ‘나’와 ‘너’가 하나되기 위한 사랑안에서 가능해진다. 유교에 따르면 인(仁)은 우리 안에 내재된 본성이다. 이 본성을 인식하면 타인에 대한 사랑이 피어오르며 공동체를 향한 삶을 지향하게 된다. 인(仁)을 인식하는 것은 천명(天命)을 ‘듣게’되는 것이자 선을 인식할 수 있게 된 것과 같다. 천명(天命)을 들은자 선을 펼치는 삶에 뜻을 두고 살게 된다.
힌두교 경전 우파니샤드와 베다에서 존재 근원에 대한 핵심 가르침은 범아일여(梵我一如)다. 범아일여의 문자 그대로의 뜻은 모든 존재는 하나와 같다는 것이며, 힌두교식 표현으로는 아트만과 브라만이 하나라는 것이다. 아트만이란 ‘나’라는 존재의 근원이자 본성이다. 기독교의 성령이자 유교의 인(仁)과 같다. 브라만은 우주의 궁극적 실재를 의미한다. 기독교의 삼위일체와 같은 맥락으로 아트만은 브라만과 같다. 우리 모두는 아트만을 인식하지 못한 채 우리의 육신을 ‘나’라고 생각하며 살아가고 있다. 힌두교를 통한 구원은 ‘나’라는 존재에 내재한 아트만을 인식하는 것이다. 기독교와 마찬가지로 내 안의 아트만(성령)을 인식하게 되면 모든 존재가 브라만(성부)과 하나됨을 알게 된다. 아트만을 인식하는 순간은 육신을 나라고 알고 있는 에고가 죽는 순간이며 ‘나’와 ‘너’의 경계가 사라지고 모든 존재와 하나가 되는 순간이다. 이후 모든 존재에 대하여 자연스레 사랑이 피어오르게 되고 타인을 향한 선의와 이타심이 피어오르게 된다.
위대한 성인과 종교의 가르침으로부터 존재의 의미를 깨닫고 선을 인식하는 자, 결코 이전으로 되돌아갈 수 없다. 선이 인간의 정신과 의식에 기거하는 것을 느낄 수 있기 때문이다. 선은 인간의 가치판단에 있어 가장 우선순위가 된다. 이러한 특성으로 인해 선은 인간에게 어떠한 ‘의무’를 부과한다. 여기서 ‘의무’란 인간 자신의 존재 의미를 실현하기 위한 어떤 것이다. 그 것은 세상을 향한 박애정신이자 공동체를 향한 삶이고 인류의 미래를 위한 일이라는 형태로 나타난다. 이를 실현하는 과정이 인간의 삶이다. 선을 추구하며 악을 걷어내는.
경제성장률이란 무엇인가? 실질 국내총생산(GDP)의 변화율이다. 그렇다면 국내총생산(GDP)이란 무엇인가? 국내총생산이란 일정 기간 동안 한 국가안에서 모든 경제주체들이 생산한 부가가치의 합이다. 그 자체로 국가의 경제규모가 된다. 여기서 실질이란 의미는 경제규모가 증가했다고 착시로 여겨질 수 있는 물가변동을 제외한 순수한 생산량의 변화를 의미한다. 그렇다면 실질 국내총생산량이 늘었다는 것은 무엇을 의미할까? 경제주체의 관점에서 기업의 생산과 투자와 고용이 늘었고 이로 인해 가계의 소득과 소비가 늘었음을 의미한다.
그렇다면 경제성장률은 왜 중요할까? 국가의 경제성장을 가장 집약적으로 보여주는 대표적인 거시경제지표기 때문이다. 정부는 경제성장률의 향상을 목표로 경제정책을 수립하고 시행한다. 따라서 정부가 목표 경제성장률을 얼마나 성취했는지를 측정할 수 있는 일종의 종합성적표와 같다. 그러면 우리나라 경제성장률의 변화는 어떠한가? 1970~1980년대 고도성장기에는 성장률이 10%대가 넘었으나 최근에는 3%도 어려워졌다. 하지만 이러한 현상은 경제의 규모가 커지면서 발생하는 불가피한 측면이 있다.
경제성장률은 한국은행이 분기 또는 연간 단위로 발표한다. 발표되는 수치는 기업과 투자자의 의사결정에 영향을 미친다. 크게 세 단계로 속보치 → 잠정치 → 확정치 순으로 공개하며 미국도 이와 같다. 확정치로 갈수록 정확해진다. 하지만 확정치는 잠정치의 미세조정 수준이라 큰 주목을 받지 못하는 측면이 있다.
2. 물가상승률
물가상승률이란 무엇인가? 소비자 물가지수의 변화율이다. 소비자 물가지수란 무엇일까? 소비자 물가지수는 가계가 많이 구매하는 460개 품목을 기준으로 중요도에 따라 가중치를 부여해 계산되는 경제지표다. 460개 품목에는 식료품비, 대중교통비, 통신비, 학원비 등이 포함된다. 만약 전년도의 소비자 물가지수가 100이었고 금년도 소비자 물가지수가 110이라면 물가상승률이 10%가 되는 것이다.
그렇다면 물가가 왜 중요할까? 정부가 물가상승률을 근거로 근로자의 임금과, 국민연금과, 최저생계비를 조정하므로 국민의 생계와 직결되어 있기 때문이다. 따라서 정부는 안정적인 경제성장을 위해 '물가안정목표'를 정하고 관리한다.
소비자 물가지수는 물가지수의 하위 개념으로 물가지수에는 소비자 물가지수, 생산자 물가지수, 수출입 물가지수가 있다. 생산자 물가지수는 기업 관점에서의 물가지수다. 기업이 국내시장에 공급하는 상품과 서비스 878개 품목을 정하고 이에 대한 가격 변동을 측정하여 생산자 물가지수를 계산한다. 수출입 물가지수도 동일한 맥락으로 수출 206개, 수입 230개 품목에 대한 가격 변동을 측정해 물가지수를 계산한다.
3. 환율
환율이란 무엇인가? 서로 다른 국가 화폐간의 교환비율이다. 그렇다면 근본적으로 환율은 왜 발생할까? 그 이유는 국가의 경제상황에 따라 화폐의 가치가 바뀌기 때문이다. 예를 들어 각 나라마다 돈의 가치를 조절하는 금리가 다르고, 어떤 물건에 대해 국가마다 수요와 공급이 달라 물가가 다르기 때문이다. 그렇다면 환율을 결정짓는 핵심 요인들은 무엇이 있을까? 대표적으로 금리, 인플레이션률, 고용률/실업률, 무역수지, 정치적 안정성 등이 있고 이들 간의 복잡한 상호작용으로 결정된다.
환율은 왜 중요할까? 환율 등락에 따라 무역수지가 달라지기 때문이다. 무역수지란 수출과 수입의 차이를 의미한다. 수출이 많으면 흑자 수입이 많으면 적자다. 그렇다면 환율이 상승하면 어떻게 될까? 우리나라 경제에서 가장 중요한 환율은 원-달러 환율이므로 이를 통해 예시를 들자면, 원-달러 환율이 증가한다는 의미는 달러의 가치가 높아지고 원화의 가치가 낮아진 것이다. 이렇게 되면 낮아진 원화가치로 인해 수출에 있어 가격경쟁력이 생긴다. 다른 나라와 같은 물품을 수출하더라도 원화가치가 낮으므로 상대교역국에서 다른 나라보다 더 싸게 더 많이 살 수 있기 때문이다. 그렇기 때문에 수출이 많은 기업은 환율 상승은 호재와 같다. 반대로 환율이 하락하면 어떻게 될까? 환율이 하락한다는 것은 달러가치가 하락하고 원화가치가 상승한다는 것이다. 원화가치가 상승하면 수입이 많은 기업에게 호재다. 상대교역국에서 물건을 사올 때 원화가치가 높으므로 더 많이 더 싸게 사올 수 있기 때문이다. 따라서 이러한 환율 상승은 양날의 검이라 볼 수 있다.
하지만 환율이 과도하게 변동하면 어떻게 될까? 만약 과도하게 환율상승이 이뤄졌다면 원화가치는 과도하게 떨어지는 것이다. 이는 국가와 기업의 외채의 상환부담이 커지게 된다. 또 불안정해진 화폐가치로 인해 국내에 투자한 외국인 투자자들이 한국주식과 채권을 팔고 떠난다면 국내 기업과 투자자들에게 손실이 발생하게 되고 기업의 생산과 투자가 줄고 고용이 줄면서 국민경제의 불안정성을 초래할 수 있다.
4. 국제수지
국제수지란 무엇인가? 외화 입출금의 차이를 국가 단위에서 가계부 쓰듯 체계적으로 기록한 것이다. 나라 안으로 들어온 외화가 많을 경우 국제수지 흑자, 나라 밖으로 나간 외화가 많을 경우 국제수지 적자다. 국제수지는 구체적으로 어떻게 결정될까? 국제수지의 구성요소는 거래유형에 따라 경상수지, 자본수지, 금융계정이 있으나 경제신문이 주목하는 핵심은 경상수지다. 경상수지란 상품수지, 서비스수지, 본원소득수지, 이전소득수지로 나뉜다. 이 중에서 중요한 것은 상품수지와 서비스수지다. 상품수지란 상품수출입의 결과이며, 서비스수지란 운수, 여행 등의 서비스 거래의 결과다. 이 상품수지와 서비스수지가 중요한 이유는 많은 상품과 서비스를 수출할수록 기업의 이익이 커지고 생산이 커지고 고용이 늘어나고 결과적으로 국민소득이 올라가게 된다.
하지만 국제수지의 흑자가 과도하게 커져도 문제다. 그 이유는 상대교역국과 무역마찰이 발생할 수 있기 때문이다. 흑자를 보고 있다는 것은 상대교역국이 적자를 보고 있다는 말과 같다. 실례로 도널드 트럼프는 대통령 취임이후 한국의 대미 무역수지의 흑자가 과도하다는 점을 물고 늘어진 적 있다. 또한 현재 진행중인 미중 무역전쟁은 미국이 중국과의 무역에서 과도한 적자를 보고있다는 불만에서 비롯된 측면도 있다. 따라서 국제수지의 대규모 흑자는 반드시 좋다고 할 수는 없고 타 교역국과 경제협력을 위해 균형을 이루는 것이 합리적이라 할 수 있다.
5. BSI/CSI/ESI
BSI/CSI/ESI란 무엇인가? 경제주체의 주관적인 체감경기를 나타내는 경제지표다. BSI(Business Survey Index)는 기업경기실사지수로 기업의 관점에서 느끼는 체감경기를 나타낸 지표이며, CSI(Customer Survey Index)는 소비자의 관점에서 느끼는 체감경기를 나타낸 지표다. ESI(Economic Survey Index)는 BSI와 CSI를 종합한 지표다.
이러한 BSI/CSI/ESI가 왜 필요할까? 수 많은 경제현상이 책에 나오는 경제이론과 경제지표들만으로 설명하기 어려운 측면이 있기 때문이다. 따라서 이를 보완하기 위해 심리적인 관점을 고려해 만든 심리지표라 할 수 있다. 그렇다면 이러한 주관적인 체감경기지표는 누가 어떻게 조사할까? 먼저 BSI는 한국은행, 산업은행, 대한상공회의소 등이 분기마다 조사를 실시하며, 기업의 업황, 재고, 생산설비, 설비투자, 인력, 신규수주, 생산, 매출, 가격 등의 요소를 묻는다. CSI는 한국은행이 매달 조사를 실시하며 전국 2,200여개 가구를 대상으로 가계 수입, 소비지출, 현재 경기 판단과 향후 전망 등의 항목을 묻는다.
BSI/CSI/ESI 지표의 어떠한 판단 가능한 수치가 있을까? BSI/CSI/ESI는 복잡해보이나 수치 해석 방법은 매우 간단하다. 세 지표 모두 0~200의 값을 가지며 기준치는 100이다. 100이란 의미는 긍정과 부정의 수치가 같다는 말이다. 100보다 크면 체감경기를 긍정적으로 바라본다는 의미며 100보다 작으면 체감경기를 부정적으로 바라본다는 의미다.
6. 고용률/실업률
고용률이란 무엇인가? 생산가능인구 중에서 취업자가 차지하는 비율이다. 생산가능인구란 만 15세~64세에 해당하는 인구를 일컫는다. 그렇다면 고용률은 어떤 역할을 할까? 국가경제의 실질적인 고용창출능력을 보여주는 역할을 한다.
실업률이란 무엇인가? 경제활동인구 중 실업자가 차지하는 비율이다. 경제활동인구란 만 15세 이상 인구 중 취업자 + 실업자를 일컫는다. 여기서 말하는 실업자란 취업을 원하지만 취업하지 못한 사람을 일컫는다. 통상적으로 취업준비자나 구직단념자는 실업자에서 제외되어 실업률에 반영되지 않고, 별도의 비경제활동인구로 분류된다. 때문에 취업난이 지속되면 취업준비자나 구직단념자가 늘면서 오히려 실업자가 줄어드는 현상이 나타날 수 있다.
고용률과 실업률의 관계는 어떻게 될까? 흔히 고용률이 오르면 실업률이 떨어지고 실업률이 오르면 고용률이 오르는 역의 관계가 성립한다고 생각할 수 있다. 하지만 정확히는 그렇지 않을 수 있다. 그 이유는 비경제활동인구가 고용률을 산출할 때는 포함되고 실업률을 계산할 때는 제외되기 때문이다. 따라서 정확한 고용동향을 파악하기 위해서는 고용률과 실업률의 지표를 함께 보아야 한다.
7. 주가지수
주가지수란 무엇일까? 수 많은 주식 종목의 가격 변화를 종합해 주식시장의 전반적인 상황을 보여주는 지수이다. 주가지수의 종류는 한국에서는 유가증권시장의 코스피지수와 코스닥시장의 코스닥지수가 있다. 코스피지수는 1980.1.4 기준시점에서 상장주식 가치의 총합을 100으로 기준삼으며 코스닥지수는 1996.7.1 기준시점으로 상장주식 가치의 총합을 1000으로 기준삼는다. 미국에서는 다우지수, 나스닥지수, S&P500이 대표적이다. 다우지수의 정식명칭은 다우존스 산업평균지수이며 뉴욕증권거래소의 대표 우량주 30개의 시세 움직임이다. 이외에 일본은 닛케이지수, 영국은 FTSE100 지수가 있다. 앞서 열거된 지수는 영향력 있는 주가지수로 통한다.
그렇다면 주가지수는 왜 중요할까? 증시와 경제의 흐름을 보여주는 거울이기 때문이다. 또 경제의 호황과 불황을 가늠하는 지표며 또 지수만으로 투자상품이 되는 유의미성 때문이다.
8. 기준금리
기준금리란 무엇인가? 한 나라의 금리를 대표하는 정책금리로 시중 금리의 기준이 되는 금리다. 정책금리란 각국 중앙은행이 특별히 콕 찍어서 결정한 금리다. 중앙은행이란 은행들의 은행을 의미하는 것으로 한국의 '중앙은행'은 한국은행이다. 한국은행이 기준금리를 올리거나 내리면 시중은행도 이를 반영해 개인과 기업을 대상으로 한 예대 금리를 조절한다. 시중금리란 정책금리를 제외한 모든 금리를 일컫는 것으로 채권금리, 대출금리 등이 있다.
그렇다면 이 기준금리란 왜 중요성을 가지는 것일까? 돈의 가치가 달라지는 것이기 때문이다. 돈의 가치가 달라지면 이에 따라 채권, 주식, 부동산 시장에 미치는 파급효과가 생기기 때문이다. 예를 들어 시장금리가 낮아지면 기본적으로 예금이 줄고 대출이 많아진다. 또 기준금리가 낮아지면 국내 금융상품의 수익률은 상대적으로 낮아진다. 따라서 외국인의 국내 투자가 줄고, 기존 외국인의 투자금이 빠져나가 원화가치가 하락(환율상승)하는 요인으로 작용한다. 환율이 상승하면 수출시 가격경쟁력이 높아진다는 장점이 있다. 하지만 기준금리가 낮아진다고 해서 경기를 반드시 살린다는 보장은 없다. 낮아진 대출이자로 인해 부동산 대출 급증을 유발해 자산 거품을 일으킬 수 있기 때문이다.
9. 가계부채/국가채무
가계부채와 국가채무란 무엇인가? 가계부채는 가계가 갚아야할 대출금의 총액이며 국가채무는 정부가 갚아야할 대출금의 총액이다. 가계부채와 국가채무는 왜 중요할까? 가계부채와 국가채무가 증가하면 국가신용등급이 하락하고 경제의 불안정성을 야기할 수 있기 때문이다. 따라서 가계부채와 국가채무를 관리하는 것이 중요한데 이 때 기준이 되는 것은 GDP다. GDP 대비 가계부채와 GDP 대비 국가채무가 얼마나 되는지 비율을 고려한다. 적절한 비율에 대한 고정된 기준은 없으나 이를 '잘' 조절할 수 있어야 한다. 참고로 문재인 정부의 최근 5년간의 국가채무와 GDP 대비 비율은 아래 그림과 같다.
10. 어닝 쇼크/어닝 서프라이즈
어닝 쇼크와 어닝 서프라이즈란? 어닝 쇼크는 기업의 실적이 시장예상치보다 부진한 상황을 의미하며 어닝 서프라이즈는 시장 예상치를 훨씬 뛰어넘는 상황이다. 이러한 어닝 쇼크와 어닝 서프라이즈는 어닝 시즌에 발표된다. 어닝시즌이란 상장사들이 1년에 네 차례 분기별 실적을 발표하는 시기다. 여기서 실적의 핵심지표는 매출액, 영업이익, 당기순이익 3가지다. 매출액은 기업의 성장성을 나타내는 주요 지표다. 영업이익은 기업의 수익성을 나타내는 주요 지표다. 당기순이익은 영업과 영업과 무관한 활동으로 얻은 수익을 나타내는 지표다. 예를 들어 제품 판매와 별개로 부동산 매각이나 주식처분으로 올린 수익이다. 따라서 당기순이익은 일회성인 경우가 있기에 영업이익과 당기순이익이 차이를 보이는 경우가 있다.
드론자율주행시스템 구축을 위해 기존에는 Ubuntu 22.04, ROS2, PX4, Gazebo를 사용했다. 다만 Gazebo를 사용하는 과정에서 해당 시뮬레이터의 안정성이 매우 떨어지고 비행제어가 잘 이뤄지지 않는 느낌을 강하게 받아 시뮬레이터를 AirSim으로 바꿔보고자 했다. AirSim 구동을 위한 UnrealEngine과 PX4와의 연동 예제가 Windows를 중점으로 이뤄져 있어 Windows 환경에 설치를 수행하기로 했다.
Windows 11에서 드론비행제어 시뮬레이션 환경을 구성하기 위해 설치해야할 항목은 4가지다. ROS2, PX4, UnrealEngine, AirSim다. Windows 11 환경에 AirSim 시뮬레이션 환경을 구축하며 느낀 것은 Ubuntu 22.04에 ROS2, PX4, Gazebo 환경을 설치할 때 보다 잡다한 에러가 상대적으로 많이 발생했다는 것이고, 레퍼런스가 많지는 않아 공식 문서와 약간의 유튜브 영상을 잘 보고 환경 구성을 해야한다는 것이다.
1. ROS2
ROS2 설치는 humble 배포판을 기준으로 수행했으며 전반적으로 아래 링크를 참조하여 수행하였다.
참고로 UnrealEngine 설치를 수행할 때 UnrealEngine 4.27 이상을 다운로드 받으라고 되어 있는데 23.07.31 기준 5.2.1 버전을 다운로드 받게 되면 UnrealEngine을 구동할 때 "Physxvehicles" 플러그인이 없다는 오류가 발생하므로 4.27 버전으로 맞춰 다운로드 해야 에러가 발생하지 않는다. UnrealEngine은 아래와 같이 독립적인 버전을 각각 설치해 관리할 수 있다. 4.27.2 버전을 다운로드 받자.
3. PX4
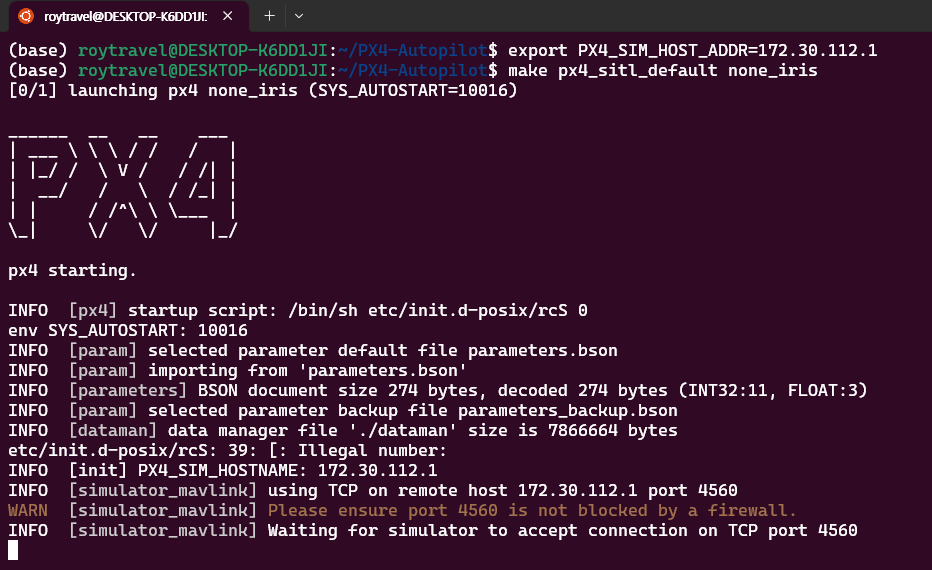
PX4를 설치하기 위해 Windows의 WSL2를 사용한다. 기존에 사용하던 Ubuntu 22.04를 삭제하고 재설치하는 과정에서 에러가 발생해서 Ubuntu 20.04를 설치했다. Ubuntu 20.04 환경에서 아래 명령을 통해 소스코드를 내려받고 빌드해주었다.
git clone https://github.com/PX4/PX4-Autopilot
make px4_sitl_default none_iris
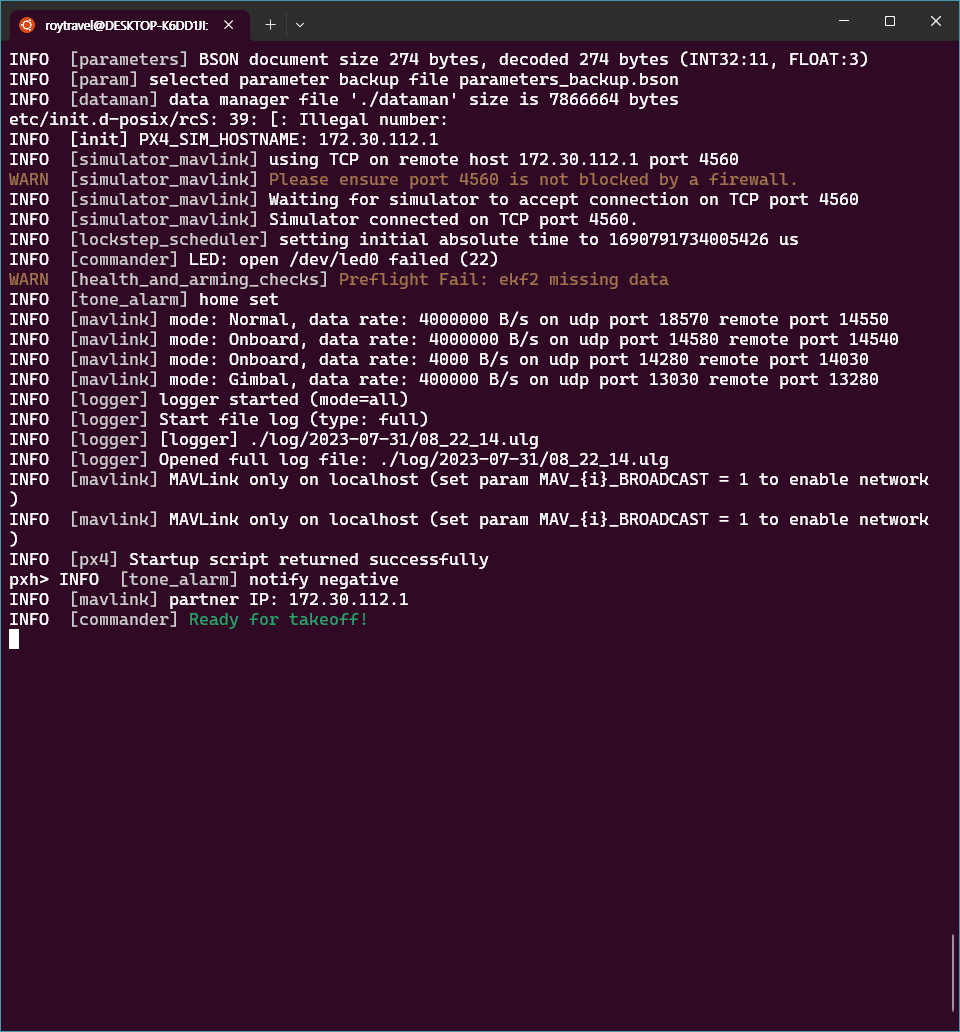
만약 make 과정에서 오류가 발생한다면 g++, cmake 등의 빌드를 위해 필요한 패키지를 설치해주어야 한다. 그리고 Windwos 11에서 구동되는 AirSim이 PX4와 연결되기 위해서 PX4의 IP address를 알아야 한다. ipconfig를 통해 WSL에 할당된 IP를 환경변수 PX4_SIM_HOST_ADDR에 할당해준다.
알다시피 export를 통한 환경변수는 일회성이기 때문에 .bashrc의 제일 아랫 부분에 아래 명령을 추가해서 셸이 생성될 때마다 실행될 수 있도록 해주는 것이 좋다.
이후에 UnrealEngine의 AirSim에서 해당 IP와 연결하기 위해 C:\Users\<user>\Documents\AirSim 경로에 있는 settings.json 파일을 아래와 같이 수정해준다. 참고로 이 때 LocalHostIp는 위 PX4의 IP address를 기입해준다.
이후 UnrealEngine에서 AirSim 시뮬레이션 모드인 AirSimGameMode를 선택해주고 시뮬레이션을 수행하면 아래와 같이 AirSim의 settings.json을 로딩하고 PX4의 IP와 연결하는 것을 확인할 수 있다. 참고로 UnrealEngine에서 월드를 구성하고 시뮬레이션을 수행하는 과정 전부는 아래 링크를 참조하였다.
본 글은 국내 신동원, 장형기님께서 배포해주신 "SLAM의 이해와 구현"이라는 자료를 기반으로 요약하였음을 밝힙니다.
01. SLAM 이란?
SLAM이란 동시적 위치추정 및 맵핑을 의미한다. 아주 쉽게 말해 Localization은 내가 어디에 있지를 알아내는 것이고 Mapping은 내 주변에 뭐가 있는지를 알아내는 것이다. 이 두 문제를 동시에 풀고자하는 방법이 SLAM이다.
02. SLAM 응용분야
SLAM 활용
모바일 로보틱스 (Mobile Robotics)
자율주행 (Autonomous Driving)
로봇 관련 회사
소프트뱅크(Softbank) - 페퍼로봇
테미(Temi) - 테미로봇
테슬라 - 옵티머스
03. SLAM 알고리즘 종류
1900년대
베이즈 필터 기반: Prior + Likelihood = Posterior를 계산.
확장칼만필터 SLAM (EKF SLAM)
파티클 필터 기반
Fast SLAM
2000년대
그래프 최적화 기반
그래프 노드: 로봇 위치
그래프 엣지: 회전 & 이동
특징점 기반: 카메라 궤적 추적 및 맵핑 수행
ORB-SLAM
밝기 기반 (Intensity-based)
LSD-SLAM
04. SLAM 알고리즘 파이프라인
프론트엔드(Frontend)
카메라 or 라이다 센서 데이터 수집 + 전처리(노이즈 제거)
2.1 Visual Odometry (시각적 주행 거리 측정)
- 센서의 상대적인 움직임을 예측
2.2 루프 폐쇄 검출 (Loop closure detection)
- 현재 센서 위치가 이전 방문 위치인지 판단 - 비연속적 데이터로 상대적인 움직임 예측
백엔드(Backend)
백엔드 최적화
프론트엔드에서 얻은 센서 위치와 주변 환경 정보를 이용해 불확실성 제거하고 일관성 있는 지도 만들기 위한 최적화 과정 수행
현재 센서의 자세와 주변 환경의 랜드마크 정보를 그래프 노드로 표현 후 노드 사이의 제약조건을 그래프 엣지로 표현해 모든 그래프 사이의 제약조건을 최소화 하는 형태로 센서의 자세와 랜드마크 위치를 최적화
지도 표현
최적화 정보를 기반으로 시나리오에 적합한 환경지도를 생성
Visual Odometry란? (시각적 주행 거리 측정)
정의: 인접 이미지 사이의 센서 움직임을 예측해 회전과 이동 파라미터를 계산하는 알고리즘
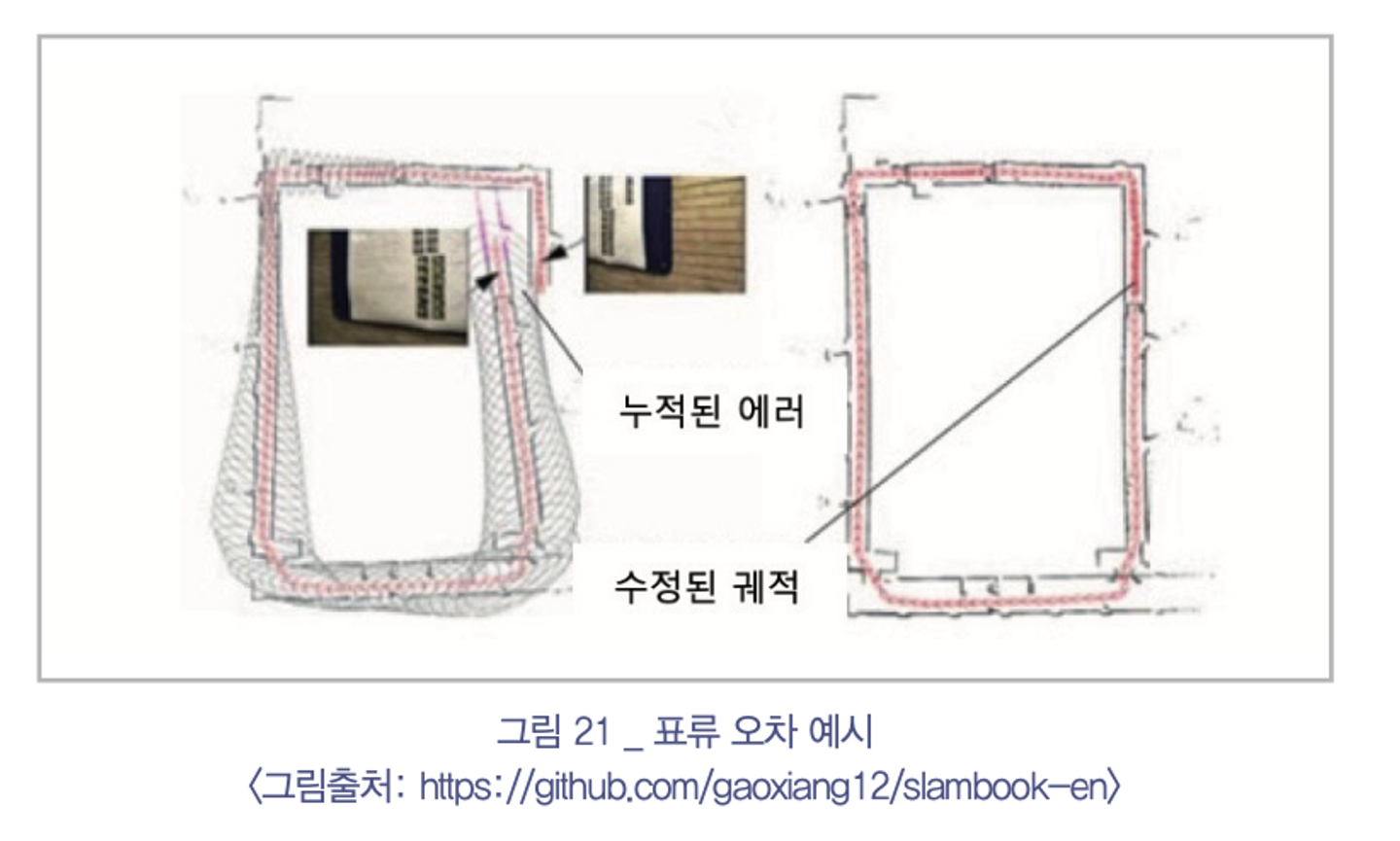
한계점: Visual Odometry만 사용해 연속적인 센서 궤적을 예측하면 누적된 표류 오차(Drift Erorr) 때문에 실제 궤적과 차이를 보임
보완방법: 루프 폐쇄 검출과 백엔드 최적화 과정이 반드시 필요함
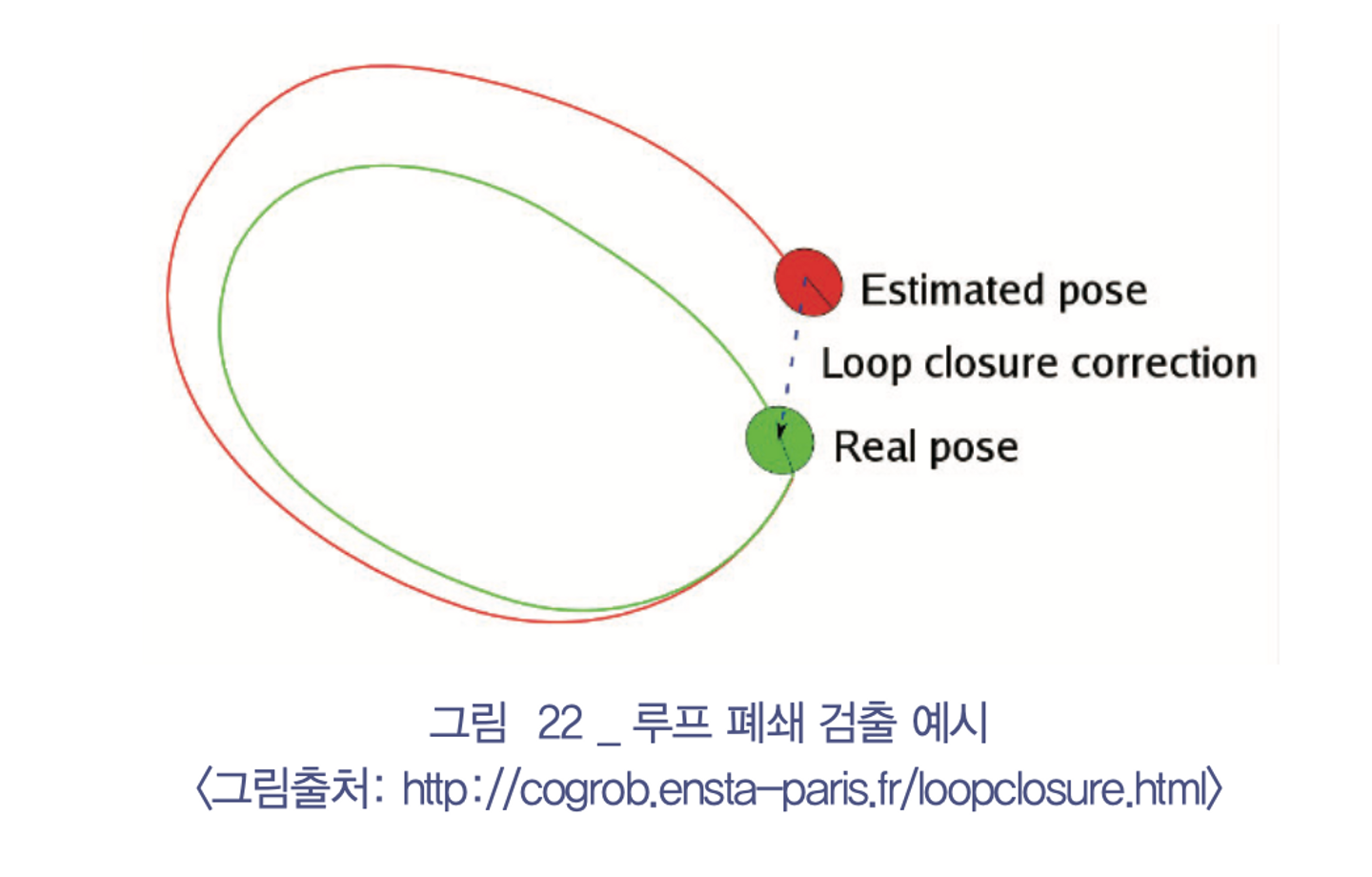
루프 폐쇄 검출 (Loop Closure Detection)이란?
정의: 현재 센서 위치가 이전에 방문한 곳인지 판단하는 알고리즘
방법: 현재 센서 입력과 이전 센서 입력 사이의 유사성을 고려
효과: 아래와 같이 Visual Odometry에 의해 표류오차가 누적된 빨간 선에서 루프 폐쇄 검출 알고리즘을 통해 같은 위치임을 판단해 전체 궤적을 초록선에 가까이 보정할 수 있음
동작원리: 센서 입력 사이 유사성은 크게 이미지 간 유사성이나 기하학적 유사성을 고려함
이미지 간 유사성은 같은 장소에서 촬영한 사진임에도 불구하고 다른 시간, 날씨, 조명, 시점과 같은 다양한 요인에 의해 시각적으로 큰 차이가 나는 영상이 나올 수 있음. 하지만 이러한 다양한 변화 요인들에도 불구하고 강건하게 같은 장소임을 판단하는 알고리즘이 루프 폐쇄 검출 알고리즘
기하학적 유사성은 라이다 센서와 같은 3차원 공간에 대한 형상 정보를 수집할 때 사용할 수 있음
백엔드 최적화 (Backend optimization)란?
정의: 노이즈가 많은 데이터로부터 전체 시스템의 상태를 정확하게 추정(State estimation) 방법
분류: 필터 기반, 비선형 최적화 기반
필터 기반
베이즈 필터: 사전확률 + 가능도를 융합해 사후확률을 업데이트해 센서의 자세 또는 랜드마크의 위치를 업데이트 하는 방법
칼만 필터
파티클 필터
비선형 최적화 기반
정의
센서 자세와 랜드마크 사이에 비선형적 관측 모델이나 연속적인 센서 사이의 비선형적 움직임 모델이 주어졌을 때 이러한 비선형 모델에 의해 만들어지는 제약조건을 최소화시키는 방향으로 센서의 자세와 랜드마크를 업데이트하는 방법
종류
번들 조정(Bundle adjustment)
그래프 최적화(Graph optimization)
Map representation이란?
정의: SLAM 파이프라인의 마지막 단계로 최적화된 센서 자세와 랜드마크 자세를 이용해 환경 맵을 만드는 과정
고려: 환경 지도는 응용 시나리오에 따라 다르게 구현될 필요가 있음. 예컨데 가정용 로봇 청소기는 2차원 지도만으로 충분하나 자율주행 드론은 3차원 지도가 필요한 것과 같이 시나리오에 따라 정확성, 가용 가능 컴퓨팅 자원을 고려해 지도 표현 방법을 선정해야 함.
로봇 청소기와 같은 실내환경에서 사용하는 2차원 점유 그리드 지도
지하철 노선도와 같은 정점과 간선으로 표현하는 위상 지도
3차원 환경 맵을 표현하는 일반적인 방법은 3차원 점군 지도
가상/증강 현실의 몰입감을 위한 밀도 있는 볼륨형태의 3차원 볼륨 지도
05. SLAM의 수학적 정의
처음시간 부터 현재 시간 T까지의 로봇 움직임 제어 정보 $u_{1:T}=\{{u_1, u_2, \dots, u_T\}}$와 주변 환경에 대한 관찰 정보 $z_{1:T} = \{{z_1, z_2, z_3, \dots, z_t\}}$가 주어졌을 때 이것으로부터 정확한 로봇의 궤적에 대한 정보 $x_{1:T}=\{{x_1, x_2, x_3, \dots, x_T\}}$와 지도 정보 $m$을 계산하는 알고리즘이다.
그림으로 예를 들자면 파란색 원은 센서가 장착된 로봇의 위치를 나타내고, 노란색이 랜드마크 위치를 나타낸다. 이 때 파란색 화살표로 표시된 로봇 움직임 제어 정보와 검은선으로 표시된 랜드마크에 대한 관찰 정보가 주어졌을 때 오른쪽과 같이 처음부터 현재(T)까지의 로봇 이동 궤적에 대한 정보와 랜드마크 위치 정보를 계산하는 것이 목표다. 이에 대한 결과로서 정확한 로봇의 위치를 추정할 수 있고 주변 환경에 대한 지도를 작성할 수 있게 된다.
하지만 문제점은 실세계는 불확실성이 산재해 있기 때문에 1미터를 움직이라는 제어 명령을 주어도 외부요인에 의해 움직이는 거리가 달라질 수 있다. 또 센서도 노이즈가 포함되어 있기 때문에 이러한 불확실성을 줄이고 정확한 상태값을 추정하기 위한 최선의 방법으로 확률론적으로 접근이 필요하며 아래와 같은 수식으로 정의할 수 있다.
즉 SLAM은 처음 시점(0)부터 현재 시점(T)까지 불확실성이 포함된 주변 환경에 대한 관찰 정보와 센서가 장착된 로봇에 대한 움직임 제어 정보가 주어졌을 때, 가장 확률이 높은 로봇의 궤적 정보와 주변 환경에 대한 맵 정보를 추정하는 문제라고 할 수 있다. 이러한 SLAM의 수식적 정의를 도식화해 각 변수의 의존성을 나타내면 다음과 같이 표현할 수 있다.
동그라미는 변수를 나타내고 화살표는 변수 사이의 의존성을 나타냄
t-1 시점의 로봇 자세$(x)$는 t-1 시점의 로봇 움직임 제어 정보$(u)$에 영향 받음
t-1 시점의 로봇 자세$(x)$는 t-1 시점에서 주변 환경에 대한 관찰 정보$(z)$와 다음 시점인 t 시점의 로봇 자세$(x)$에 영향을 미침
- 항공기의 동적특성은 주로 안정성(Stability)과 조종성(Control)에 의해 규정됨
- 항공기의 동적특성에 직접적인 영향을 주는 것은 공력계수며 이를 이해하려면 에어포일과 날개의 기하학적, 공기역학적 특성을 살펴봐야함
- 시스템을 해석에는 주파수영역 해석기법이 있고 시간영역 해석기법이 있음
2.2 항공기의 기하학적, 공기역학적 특성
- 에어포일: 항공기 날개의 2차원 단면
- 날개: 2차원 모양의 에어포일을 날개 길이 방향으로 유한한 길이를 갖도록 포개서 만든 3차원 모형
- 양력발생원리: 에어포일 주변에 받음각으로 인해 에어포일 윗면과 아랫면의 유속차의 발생에 따라 압력분포가 달리 작용해 양력을 얻음
- 압력중심: 압력분포에 의한 모멘트 합이 0이 되는 점. 특징으론 받음각이 변하면 압력분포가 달라지므로 압력중심 위치도 변함
- 공력중심: 항공기 무게 중심에 대한 힘과 모멘트 계산에 있어 압력중심을 기준으로 사용하면 받음각의 변화로 압력중심이 달라지는 문제를 해결하기 위해 받음각에 따라 위치가 변하지 않는 점인 공력중심을 사용.
- 피칭 모멘트(pitching moment): 모멘트가 Y축으로 작용(회전)하려는 힘
모멘트(Moment): 물체의 회전운동에 대한 양을 나타내는 개념이다. 즉 물체가 회전력을 받는 정도를 뜻한다. 모멘트는 어떤물리량과 어떤 기준점 사이의 거리를 곱한 형태로 정의된다. 예를 들어 물리량은 질량, 힘, 길이 등이 될 수 있고 (질량 x 거리), (힘 x 거리), (길이 x 거리) 등으로 표현할 수 있다. 실제로 관성 모멘트는 질량과 거리제곱의 곱으로 표현되고 힘의 모멘트(토크)는 힘과 거리의 곱으로 표현된다. 모멘트는 어떤 물리량의 분포에 따라 물리적 특성이 달라질 때 사용한다.
2.4 비행안전성 개요
- 항공기 운동은 크게 병진운동과 회전운동으로 구분되며 이 둘은 서로 독립이라 가정해 별도의 해석이 필요함.
- 병진운동: 물체를 하나의 질점으로 간주해 질점계의 모든 질점이 평행이동 즉 모든 지점이 똑같이 이동하는 운동.
- 회전운동: 물체가 한 점을 축으로 회전하는 운동. 주로 자세안정성해석이나 제어시스템 설계에 이용됨. 정적안정성과 동적안정성으로 구분됨. 정적안정성이란 크게 3가지로 정의됨. 한 물체가 초기에 평형상태에 있다고 가정했을 때 외력이 발생했지만 평형상태로 되돌아 가려는 1. 정적 안정, 외력이 발생해서 평형상태에서 멀어지는 2. 정적불안정, 평형이 유지되는 3. 정적중립. 동적안정성은 시간에 대한 변화를 염두에 두고 정의되는 특성으로 평형상태를 벗어난 뒤 어느 정도의 시간이 경과한 후 다시 평형상태로 되돌아오는 경향으로 정의
강체: 물리학에서 형태가 변하지 않는 물체. 외력이 가해져도 크기나 모양이 변형되지 않거나 무시할 만큼의 변형이라면 강체라 함. 강체의 가장 일반적인 운동은 질량중심의 병진운동과 질량중심을 지나는 축에 대한 회전운동의 결합.
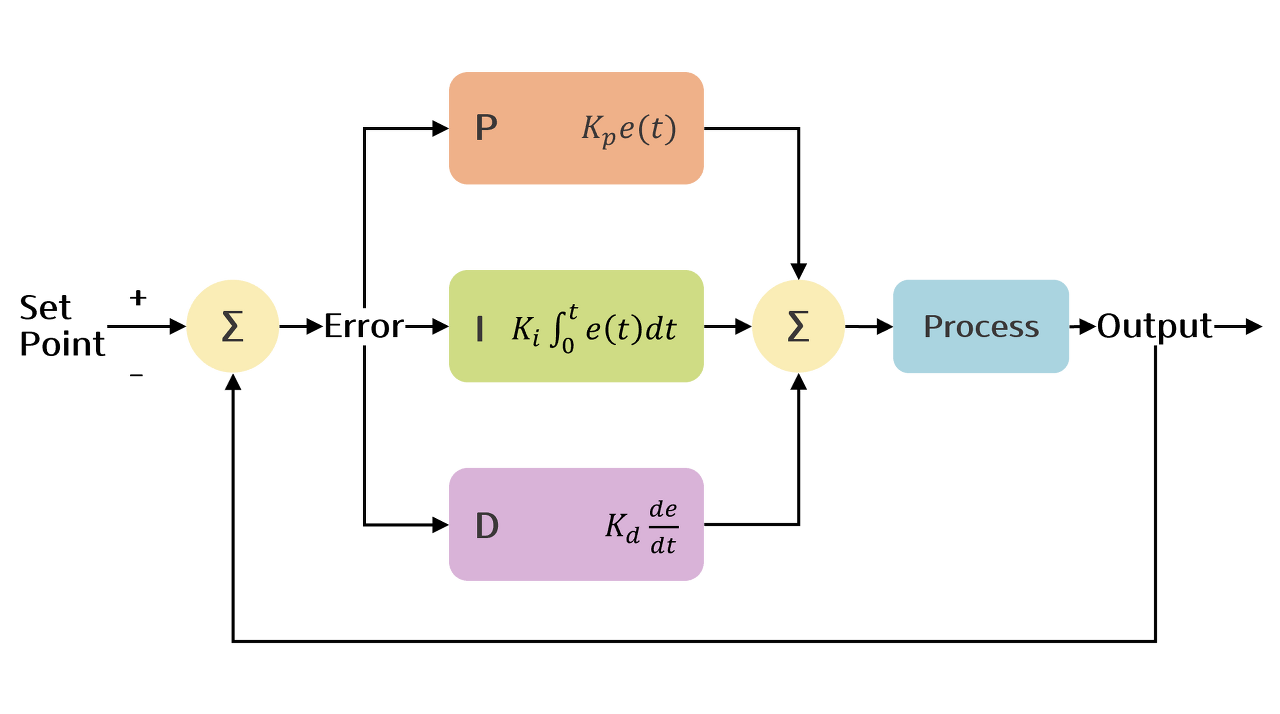
드론 자율주행을 위해 목표 GPS 좌표를 설정하고 현재 GPS 좌표와의 차이를 구해 이동해야 할 좌표를 계산하는 데 있어 PID 제어가 쓰이는 것을 알 수 있었고 이에 대한 이해가 필요하다 판단했다. PID 제어는 목표값에 도달하기 위해 현재값과의 차이를 반복적으로 줄여나가는 시스템으로 아래와 같은 구성을 갖는다. 여기서 반복적으로 줄여나간다는 말은 Feedback loop가 있다는 것이다.
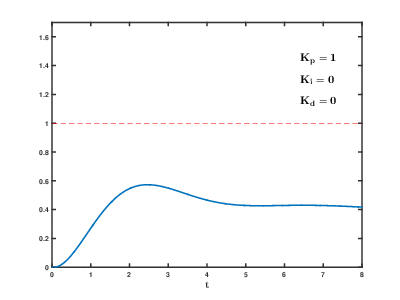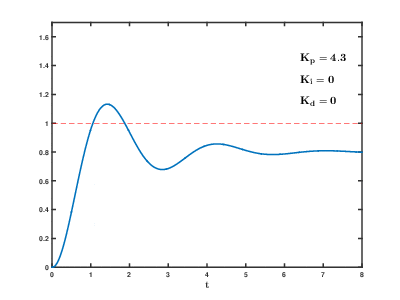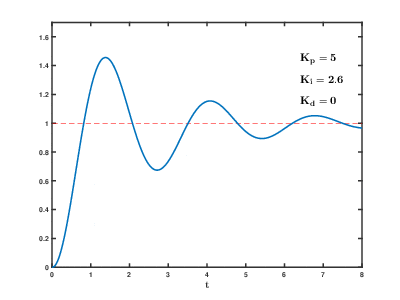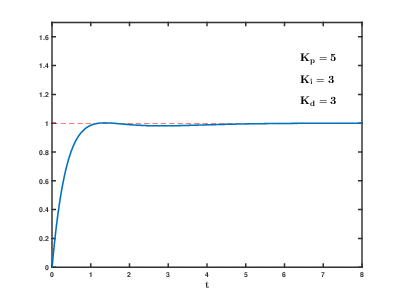
PID 제어에서 P, I, D가 나타내는 것은 비례(Proportional), 적분(Integral), 미분(Derivative)를 나타내며 이 세 요소는 에러를 줄여 목표지점에 도달하는 공통의 목표를 가지고 각자 역할을 수행한다. 이 요소는 각각 비례항, 적분항, 미분항이라 부르며 각각의 항에서 사용되는 상수(파라미터)는 Kp, Pi, Kd(비례이득, 적분이득, 미분이득)가 있다. 비례항, 적분항, 미분항을 살펴보기 바로 이전에 결론적으로 이러한 각 항의 상수들이 적절하게 설정되었을 때 시스템에 어떤 영향을 미칠 수 있는지 살펴보자.
위 GIF를 보면 Kp, Ki, Kd가 적절하게 전부 설정되었을 때 시스템이 안정화되는 것을 확인할 수 있다. 이는 비례항, 적분항, 미분항의 파라미터들이 함께 사용되었을 때 상보적인 효과를 가져온다는 것을 의미한다. 그렇다면 이제 오차에 대해 비례항과 적분항과 미분항의 역할을 살펴보고 각 항의 구성과 특징을 살펴보자.
1. 비례항
비례항은 오차값에 비례해서 시스템의 제어를 수행한다. 가장 직관적인 제어 방식이다. 수식으로는 $ P = K_p \times e$와 같다. e는 error를 의미한다. 여기서 비례항의 파라미터인 비례이득 $K_p$가 높으면 오차에 큰 반응으로 빠른 오차 감소가 가능하지만 불안정한 상태가 된다. 즉 목표지점(setpoint) 근처까지 빠르게 도달할 수 있지만 불안정한 상태로 도달하게 된다. 반대로 $K_p$가 낮으면 오차에 작은 반응을 보여 느린 오차 감소를 보이지만 안정한 상태가 된다. 즉 목표 지점 근처까지 천천히 도달하지만 안정한 상태로 도달할 수 있는 것이다. 비례항을 통해 비례제어를 수행해도 즉, $K_p$를 조절해도 목표지점에 정확히 도달하지 못하는 문제점이 있다. 이는 오버슈팅 현상 때문이다. 오버슈팅 현상은 목표값보다 오차가 커지는 것을 말한다. 제어기가 목표값에 도달해도 지나치게 흔들리거나 진동하는 경우가 있기 때문이다. 따라서 이러한 비례항만으로는 안정성있고 정확하게 목표지점에 도달하기 어렵기 때문에 이를 보완하기 위해 아래 적분항을 함께 사용한다.
2. 적분항
적분항은 오차값의 누적을 이용해 시스템의 제어를 수행한다. 적분항은 비례항과 마찬가지로 오차를 줄이기 위한 역할을 수행한다. 비례항은 단순히 오차에 비례이득을 곱했다면 적분항은 오차의 누적을 구해 적분이득을 곱해준다. 수식으로는 $I = K_i \times \int{e}$와 같다. 즉 적분이득($K_i$)을 작게 설정하면 오차의 누적이 둔화되어 안정적인 제어가 가능하지만 오차추종속도가 느릴 수 있고, 반대로 적분이득을 크게 설정하면 오차의 누적이 크게 반영되어 제어신호가 더 많이 증가하고 오차추종속도가 빠르지만 비례항과 마찬가지로 오버슈팅이 발생할 수 있다.
3. 미분항
미분항은 오차의 변화율에 따라 시스템의 제어를 수행한다. 조금 더 구체적으로는 목표값과 제어값의 편차를 비교해 이와 기울기가 반대되는 쪽에 값(힘)을 주어 힘을 상쇄시킨다. 다른 두 항과 마찬가지로 오차를 줄이는 역할을 한다. 다만 특히나 다른 두 항에 비해 안정성을 높이는 역할을 한다. 이는 적분항에 있던 오차들을 변화율에 따라 제거해줌으로써 시스템이 안정화시키기 때문이다. 수식은 $D = K_d \times {de \over dt}$와 같다. 미분이득($K_d$)을 큰 값으로 설정하면 오차의 변화에 민감하게 반응해 오차추종속도가 빨라지나 진동이나 불안정성이 발생할 수 있다. 반면 미분이득을 작은 값으로 설정하면 오차변화에 대한 반응이 둔화되어 안정적인 제어가 가능하지만 오차추종속도가 느릴 수 있다.
이러한 비례이득, 적분이득, 미분이득은 함께 상호작용하며 시스템의 균형을 잡기 때문에 올바른 조합을 찾는 것이 중요하다. 이들 간의 균형은 시스템에 따라 달라질 수 있으므로 실험을 통해 최적의 값을 도출하는 것이 필요하다. 이를 PID 튜닝이라고 하며 가장 널리 알려진 방법으로는 지글러-니콜스 방법이 있다고 한다.
쿼터니언(Quaternion)이란 선형대수학에서 사용되는 개념으로 3차원 벡터 공간에서 회전을 표현하는 수학적 개념이다. 우리말로 사원수라고 일컬으며 4개의 요소로 구성된 복소수 시스템이다.
쿼터니언은 어떤 배경에서 고안되었는가?
쿼터니언은 3차원 공간의 회전을 표현한다고 했다. 이러한 3차원 공간의 회전을 표현하는 데 있어 원래는 오일러 각(roll, pitch, yaw)을 사용해 표현한다. 하지만 이 오일러 각을 사용할 경우 Gimbal Lock 현상이 발생한다. 잠깐 Gimbal에 대한 개념을 설명하자면, 단일 축에 대한 회전을 허용하는 수평 유지 장치를 의미한다.
(좌): 각각의 짐벌은 roll, pitch, yaw의 자유도를 갖는다.
Gimbal Lock 현상은 3차원 공간상에서 두 축이 겹쳐 한 축이 소실되거나 자유도가 떨어지는 현상이다. 각 Gimbal들은 각자 특정 축(x, y, z)으로만 회전하도록 되어 있다. 하지만 위 우측 그림의 STATIC POSITION을 보면 맨 안쪽의 Gimbal은 다른 Gimbal을 회전시켜 두지 않는 이상 더 이상 roll 축으로 회전할 수 없게 된다. 이를 Gimbal Lock 현상이라 한다. 그렇다면 왜 Gimbal Lock 현상이 발생할까? 그 원인은 세 축이 의존적이기 때문이다. 예를 들어 z축을 회전시키면 x, y축도 함께 회전하게 되기 때문이다.
또 다르게 말하면 오일러 각에서 회전 자체를 세 축으로 나눠서 계산하기 때문이다. 예를 들어 어떤 물체 a가 있고 이 물체 a를 roll에 대해 회전하고 pitch에 대해 회전하고 yaw에 대해 회전한다고 가정하자. 어떤 물체 a는 roll에 대해 회전한 뒤 a’가 된다. 이후 pitch에 대해 회전한다고 하면 a에 대해 회전하는 게 아니라 a` 에서 회전하게 된다. 또 yaw에 대해 회전한다고 하면 a`가 아니라 a``에 대해 회전시킨다. 즉 각 축에 대한 회전은 이전 축에 의존하는 것이다.
쿼터니언은 이 Gimbal Lock 문제를 어떻게 해결할까?
쿼터니언은 정확히는 Gimbal Lock 문제를 해결하진 못한다. 다만 오일러 각을 사용해 회전을 표현할 때보다 Gimbal Lock 문제를 최소화시킬 수 있다. 쿼터니언은 4차원 복소수 공간의 벡터로 마찬가지로 벡터 공간에서의 회전을 표현하는 역할을 한다. 쿼터니언은 다음과 같은 형태를 가진다.
$$ q = xi + jy + zk + w $$
크게 보자면 쿼터니언 q는 xi + jy + zk는 벡터 요소, w는 스칼라 요소로 구성된다. i, j, k는 각각 x, y, z 축을 나타내는 허수 단위 벡터다. 이러한 쿼터니언은 4개의 요소로 구성되어 4차원 공간에서 회전을 표현한다. 이렇게 회전을 4차원으로 표현하는 쿼터니언은 세 개의 축을 사용하는 3차원 오일러 각과 달리 축의 의존성을 없애고 독립성을 가져오는 데 도움을 준다. 쿼터니언의 수식적 표현으로 파고들어 쿼터니언의 4차원 구조와 회전 연산 수식에 내재된 특성으로 짐벌락 문제를 해결하는 원리를 이해하는 데 도움될 수 있다 생각드나 짐벌락 문제 자체는 직관적으로 이해하는 것이 더 직접적이란 생각이 든다.
지구중심 관성 좌표계란 관성의 법칙이 적용되는 좌표계다. 관성의 법칙이란 뉴턴의 운동법칙 제1법칙으로 물체에 아무런 힘이 가해지지 않을 경우 물체는 정지하거나 등속직선운동을 하는 것이다. 즉 시간의 변화에 따라 가속하거나 회전하지 않는 좌표계다. 실제로는 지구가 회전하고 있기 때문에 존재하지 않는 좌표지만 다른 좌표계들과의 관계를 기술하기 위한 목적으로 만든 가상의 좌표계다. 이러한 관성 좌표계와 달리 가속운동을 하는 좌표계를 비관성 좌표계 또는 가속 좌표계라 부른다.
지구중심 지구고정 좌표계란 회전이 포함된 지구중심 관성 좌표계다. 즉 지구의 자전으로 인해 회전하는 좌표계며 t=0 시점에서 지구중심 관성 좌표계와 동일하다.
3. 지면좌표계 (NED: North East Down frame)
지면 좌표계(NED frame)는 항공 및 우주분야에서 널리 사용되는 좌표계다. LLA(Latitude-Longitude-Altitude) 좌표계라고도 불리는 NED 좌표계는 비행체의 상대적인 위치와 방향을 표현하기 위해 사용된다. N은 North, E는 East, D는 Down을 나타낸다. North는 경도선과 평행을 이루며 북쪽을 바라보는 방향을 표현한다. 적도를 기준으로 북반구는 + 남반구는 -이다. x, y, z를 기준으로 상대적인 좌표를 표현하는 local frame 좌표계에서의 x축과 같다. East는 위도선과 평행을 이루며 동쪽은 + 서쪽은 -로 방향을 표현한다. 마찬가지로 local frame 좌표계에서 y축과 같다. Down(Depth)은 지구 중심, 내부를 바라보는 방향을 표현하는 것으로 지구 중심과 가까워지는 방향은 + 중심과 멀어지는 방향은 -로 표현한다. 마찬가지로 local frame 좌표계에서 z축과 같다.
이러한 NED 좌표계는 일반적으로 3차원 직교 좌표계로 표현된다. (North, East, Down)이며 예를 들어 (100, 200, -50)은 북쪽으로 100 단위, 동쪽으로 200단위 아래로 50단위로 이동한 지점을 나타낸다. NED 좌표계는 항공 및 우주 분야에서 좌표와 방향을 정확하게 표현하는데 사용되는 다른 좌표계와 결합되어 사용될 수 있다. 예컨데 GPS 좌표는 NED 좌표계로 변환되어 위치를 정확하게 나타낼 수 있다.
4. 동체 좌표계 (Body frame)
동체 좌표계는 물체(ex: 비행체, 선박 등)의 질량 중심을 원점으로 하는 좌표계다. 물체의 운동을 설명하는데 사용하는 좌표계로 일반적으로 물체의 운동방정식을 동체 좌표계상에서 표현하기 대문에 운동 방정식을 전개해 나가는데 편리한 좌표계다. 동체 좌표계는 물체의 중심에 대한 위치와 물체의 방향을 기준으로 한다. 위치는 일반적으로 (x, y, z)로 표현되고 방향은 (roll, pitch, yaw)의 각도로 표현된다.
동체 좌표계는 무언가 오일러 좌표계와 관계가 있고 비슷해 보인다. 어떤 관계를 가지고 어떻게 다를까? 결론적으로 동체 좌표계 안에 오일러 좌표계가 부분집합으로 속해있는 형태다. 그 이유는 동체 좌표계는 대상체의 위치와 방향을 나타내는 반면 오일로 좌표계는 대상체의 방향을 나타내기 때문이다. 오일러 좌표는 물체의 방향(자세)를 설명하기 위해 사용하는 좌표계로 세 개의 연속된 회전 각도를 사용해 물체의 자세를 나타낸다. 일반적으로 (roll, pitch, yaw)로 회전을 나타내며 이는 곧 물체의 방향과 같다. 따라서 오일러 좌표계는 동체 좌표계의 방향 정보를 나타내기 위해 사용될 수 있다.
본 논문은 2021년에 나온 논문으로 스테레오 카메라를 통해 장애물을 인지하고 이를 기반으로 목표 지점까지 최적의 경로를 계산하는 드론 시스템을 개발하여 이를 검증한다. 장애물 회피 시뮬레이션에서 인지한 장애물은 Octomap을 사용하여 3차원 공간에 장애물 위치를 매핑하고 드론의 목표지점까지 최적의 경로를 계산했다. 나아가 간단히 실외 환경에서도 장애물 회피가 가능함을 보였다.
관련연구를 통해 강화학습 기반의 장애물 회피 연구가 수행되고 있음을 알게 되었고 결과적으로는 추후에는 강화학습 기반으로 연구를 이어가야겠다는 생각이 들었다. 장애물을 회피하면서 자율비행을 수행하는 드론 시스템 개발을 위해 저자는 먼저 하드웨어 측면과 소프트웨어 측면으로 나누어 시스템을 구성했다. 먼저 하드웨어 측면은 다음과 같다.
간단한 딥러닝 연산이 가능한 Jetson Nano Develop Kit을 장착
미션 컴퓨터는 비행제어 컴퓨터와 유선 시리얼 통신으로 연결되며 비행 상태 정보를 기반으로 최적 경로를 계산함
장애물 인지를 위해 스테레오 카메라 인텔 리얼센스 D455 사용
0.6m ~ 최대 6m 까지의 물체를 인식해 Point Cloud 형태로 출력함
카메라는 최대 해상도 1280x720로 30fps의 Point Cloud 데이터 획득 가능
정밀 위치 추정을 위해 Piksi Multi GNSS 모듈 사용 (LTE 모듈)
개발한 드론은 이륙 중량 2kg, 4셀 6400mah 배터리에 최대 20분 비행 가능
한 가지 팁은 대용량의 Point Cloud 데이터를 원활하게 얻기 위해선 USB 3.0 인터페이스를 사용해야 하나 USB 3.0 케이블에 전원이 인가되면 주변 GPS 정보를 교란하는 현상이 있어 USB 2.0 케이블을 이용해 스테레오 카메라 정보를 획득해야 했다는 점이다.
소프트웨어 측면으로는 microRTPS를 통해 uORB 토픽을 ROS2 토픽으로 바꿔 비행제어 데이터를 미션 컴퓨터 측으로 송신하도록 구성했다. 또 스테레오 카메라가 획득하는 Point Cloud 데이터의 경우 순간 데이터 통신량이 높기 때문에 대용량 데이터 처리를 위한 QoS 설정을 통해 원활한 데이터 처리가 가능하도록 설정했다.
여기까지가 드론 시스템 개발에 대한 하드웨어 측면과 소프트웨어 측면에 대한 기술이다. 이후에는 핵심인 장애물 회피 시스템을 개발하고 시뮬레이션 한 것에 대해 기술하고자 한다.
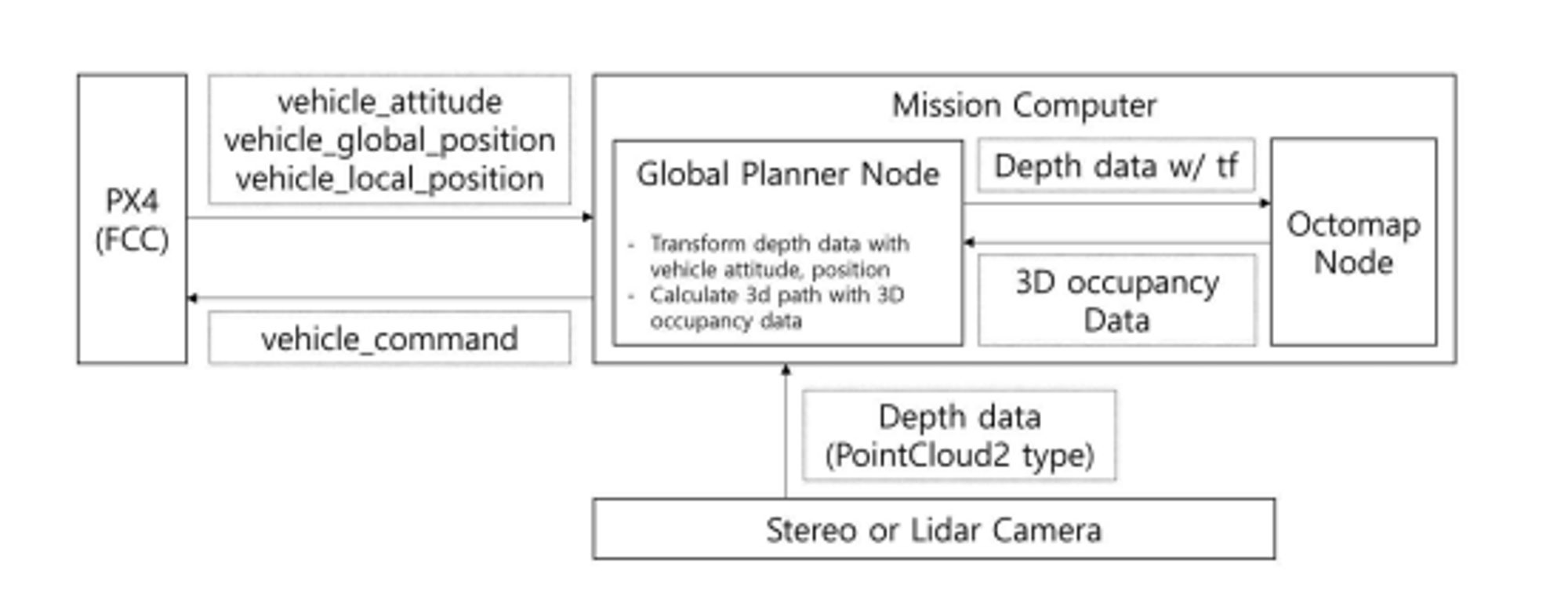
저자는 장애물을 회피하고 목표지점까지 갈 수 있는 전역경로계획(Global Path Planner)를 개발하여 적용했다. 아래는 전역경로계획 시스템의 아키텍처다.
크게 경로를 계산하는 Global Planner Node와 주변환경과 장애물을 3차원 그리드로 저장하는 Octomap Node로 구성되어 있다. Global Planner Node는 비행제어 컴퓨터(FCC)로부터 자세 정보인 vehicle_attitude와 위치 정보인 vehicle_global_position, vehicle_local_position을 수신한다. 또 스테레오 카메라로부터 획득하는 주위 환경에 대한 Depth 데이터를 모두 결합하여 드론의 주변 환경을 인식한 결과를 Octomap Node로 전달한다.
Octomap Node는 이렇게 전달받은 데이터를 기반으로 3차원 occupancy grid 형태로 만들고 다시 Global Planner Node로 전달하면 이 3차원 정보를 기반으로 비행목적지까지 장애물을 우회해 비행 가능한 최적의 경로를 실시간으로 계산한다. 이후 Global Planner Node는 현재 위치에서 목표 지점을 vehicle_command를 통해 PX4로 전달하고 PX4는 이 지점을 다음 waypoint로 설정하여 비행을 수행하는 방식이다.
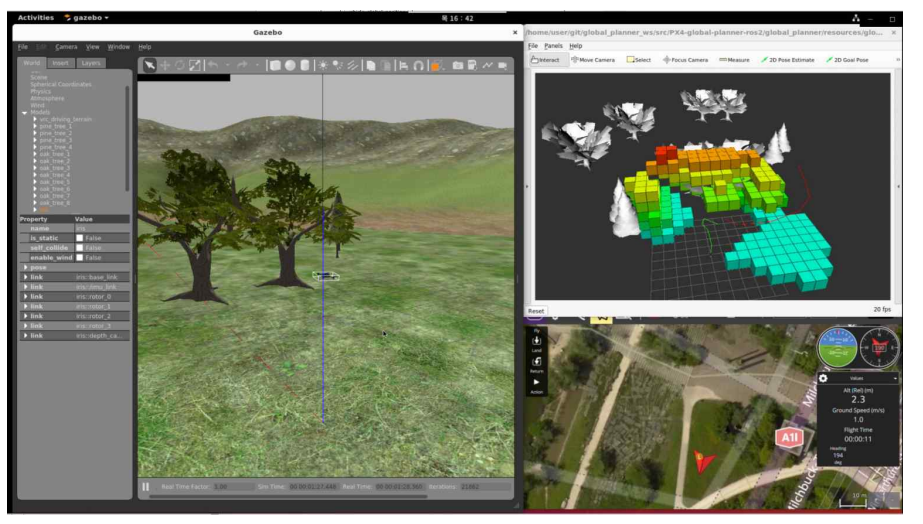
아래는 전역경로계획을 사용하여 장애물회피주행을 수행하는 그림이다. 좌측에는 Gazebo 시뮬레이션이 구동되고 우측상단은 Octomap Node에서 생성한 3차원 occupancy grid이며 그 아래는 GCS인 QgroundController다.
여기까지가 전역경로계획을 기반으로 장애물을 회피하여 목표지점까지가는 시스템에 대한 설명이다. 저자는 나아가 장애물을 회피하면서 비행을 할 때 효율적인 비행이 필요하다고 말한다. 여기서 말하는 효율적인 비행이란 위험도가 낮은 비행구간에서는 빠른 비행을 하고 위험도가 높은 구간에서는 천천히 비행할 필요성이 있다고 말한다. 여기서 위험도는 어떻게 정의될까? 아쉽게도 이에 대한 내용은 없다. 다만 현재의 위험도가 사용자가 임의 지정한 threshold를 넘으면 속도를 최소화하고 그렇지 않다면 속도를 증가시키는 방면으로 다음과 같이 알고리즘이 동작한다는 것만 알 수 있었다.
저자는 비행을 위해 사용한 파라미터를 다음과 같이 별도로 정리했다. PX4에는 수 백 여개의 파라미터가 있는 만큼 비행과 관련된 중요한 몇몇 파라미터를 정리해주었다는 점에서 다소 큰 팁이라 느낀다. 아래 파라미터 중 위험도 기반 속도제어에 사용했던 파라미터는 min_speed_와 max_speed_다.
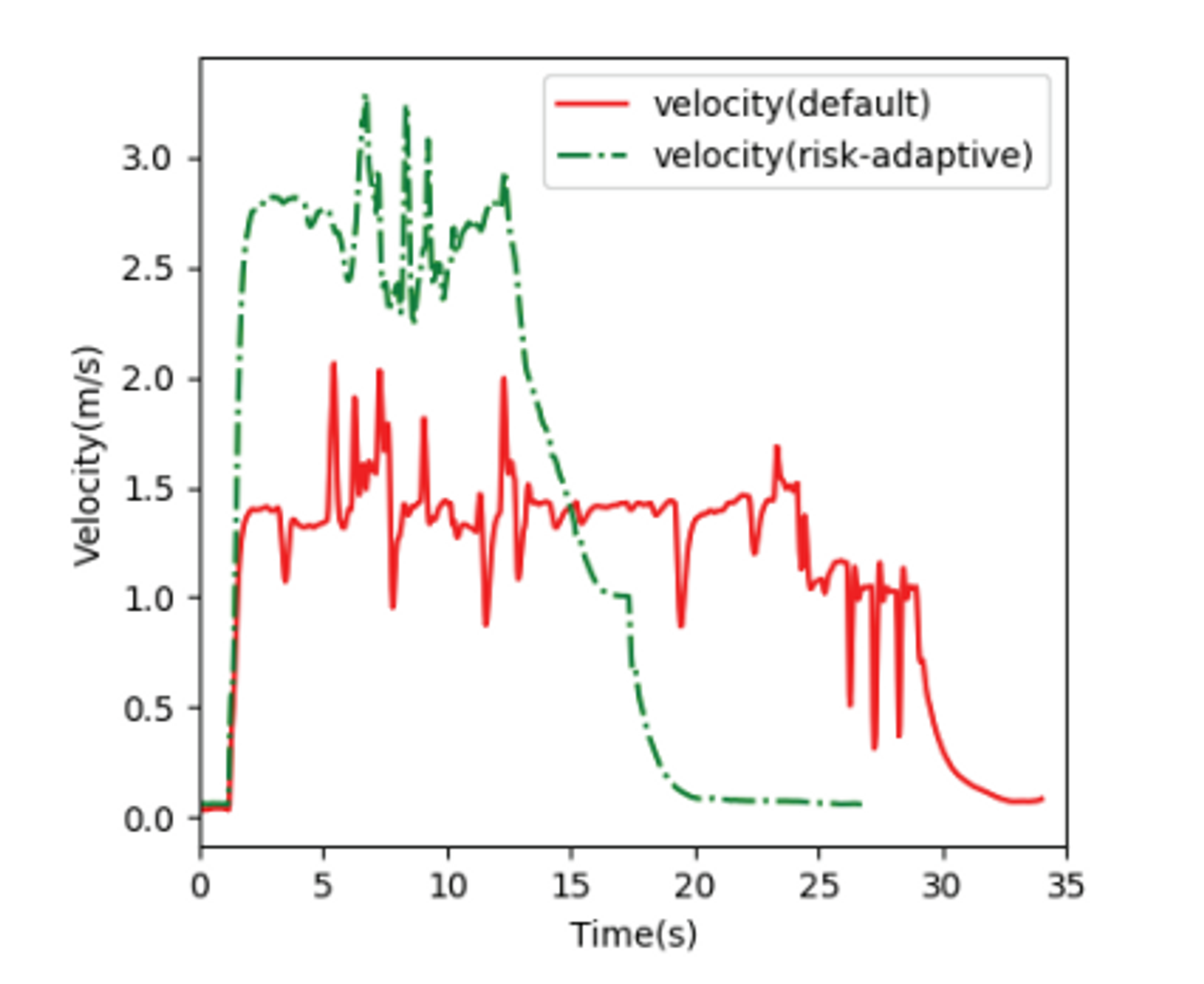
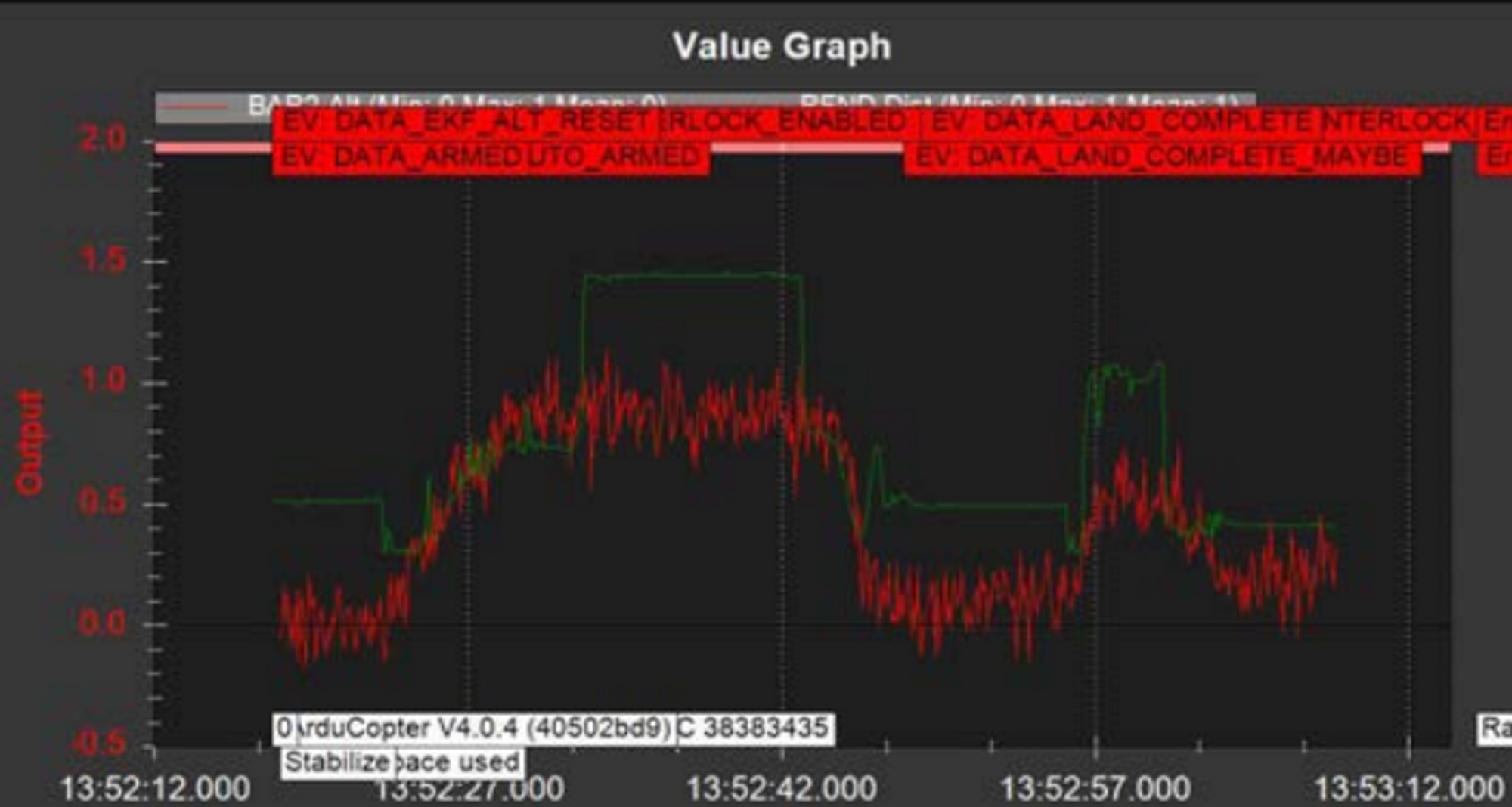
아래 그림은 위험도를 고려했을 때와 고려하지 않았을 때의 비행을 비교하여 나타낸 것이다.
초록선은 속도조절 알고리즘을 적용한 것이며 빨간선은 속도조절 알고리즘을 적용하지 않았을 때다. 그 결과 적용했을 때 목표지점까지 20초가 걸렸고 적용하지 않았을 때 32초가 걸렸다. 이를 통해 효율적인 주행을 위해서는 이러한 위험도를 계산하고 때에 따라 속도를 조절하는 알고리즘이 필요하다는 것을 알 수 있다.
2020년 한국항공우주학회에서 나온 논문으로, 핵심 내용은 PX4 기반 쿼드콥터에 스테레오 카메라를 사용하여 3차원 공간에서 자율탐사와 실시간 경로계획을 수행한 것이다. 경로계획을 위해 크게 광역 경로계획과 지역 경로계획으로 나누어 알고리즘을 수행했다.
광역경로계획
광역경로계획은 그리드 맵을 사용하는 A* 계열 알고리즘이 많이 사용된다. A* 알고리즘은 2차원에서는 8방향 3차원에서는 26방향으로 인접한 노드를 연결하여 경로를 생성한다. 하지만 이러한 A* 알고리즘은 직선과 45도 방향의 대각선만 사용할 수 있다는 단점이 있다. 따라서 이러한 고정된 각도가 아닌 임의의 각도를 사용할 수 있는 Theta* 알고리즘이 만들어졌고, 또 A* 알고리즘의 검색 정보를 다음 검색에 재활용하여 빠른 속도로 탐색할 수 있는 D* 알고리즘 등이 연구되고 있다.
해당 논문에서는 A* 계열 알고리즘 중 속도가 가장 빠른 JPS 알고리즘을 사용했다. JPS 알고리즘은 논리적 동치 관계를 이용해 탐색 노드수를 크게 줄인 알고리즘이다. 그리드 맵의 크기가 커질수록 탐색 시간이 지수 함수 형태로 증가하는 A* 알고리즘을 선형에 가까운 탐색시간 증가율을 보이기 때문에 계산효율이 좋다는 특징이 있다.
지역경로계획
그리드 맵에 거리 정보를 추가하는 것은 그리드 맵의 각 장애물 셀마다 주변 셀에 거리 정보를 전파하는 방식으로 구현된다. 하지만 3차원 공간에서는 전파해야 할 정보가 상대적으로 많기 때문에 실시간 경로계획에 많은 시간이 소요된다. 이러한 계산효율 문제를 해결하기 위해 지역 그리드 맵이 사용된다. 아래 그림은 광역 경로계획(빨강)으로 출력된 경로를 지역 경로계획으로 수정한 경로(노랑)를 시각화한 것이다. 저자에 따르면 수정된 노란 경로가 더 안전한 경로라고 한다.
결과적으로 경로계획 알고리즘 수행 알고리즘으로 목표 속도와 yaw rate를 계산하여 PX4 노드에 Offboard 명령 메시지로 전달하여 드론을 제어한다. 이를 Gazebo 시뮬레이션 상에 적용하여 자율탐사로 매핑을 수행한 결과는 다음과 같다.
새롭게 알게 된 점은 경로계획 관련 알고리즘에 A*, Theta*, D* 이 사용된다는 점이고, 아직 사용해보지 않았지만 SLAM을 위해 Octomap을 사용한다는 점을 알게됨
본 논문은 2022년 한국소프트웨어종합학술대회에서 나온 논문으로 드론 내부 데이터 추출을 통한 포렌식의 활용 가능성에 대한 논문이다. UAV 시장이 군사, 건설, 물류 산업 등의 분야로 확장되면서 UAV 산업의 중요성이 높아졌다. 이에 따라 UAV를 대상으로 한 취약점 기반 공격이 증가했고 이에 따른 포렌식의 중요성이 대두 된 것이 이 연구의 배경이다.
1. PX4 Autopilot 데이터 저장 방식
아래는 PX4 Autopilot의 아키텍처다. 빨간 박스로 표시된 부분이 PX4 Autopilot에서 데이터 저장과 관련된 모듈이다.
크게 3가지 모듈로 구성되며 dataman, param, logger다.
dataman 모듈: MAVLink로부터 전달받은 비행미션에 관련한 데이터를 SD Card에 저장
param 모듈: 사용자가 셸 커멘드를 통해 설정가능한 PX4 Autopilot 관련 파라미터를 EEPROM, SD Card, Flash 메모리에 저장
logger 모듈: GPS, IMU, 기압계 등의 센서로부터 들어오는 입력이나 Controller, Estimator에서 처리된 데이터를 PX4의 미들웨어인 uORB의 API를 통해 SD card에 저장하며 파일 형식은 ULog로 uORB 토픽 데이터를 저장함.
2. 드론 주요 데이터 정의 및 분석
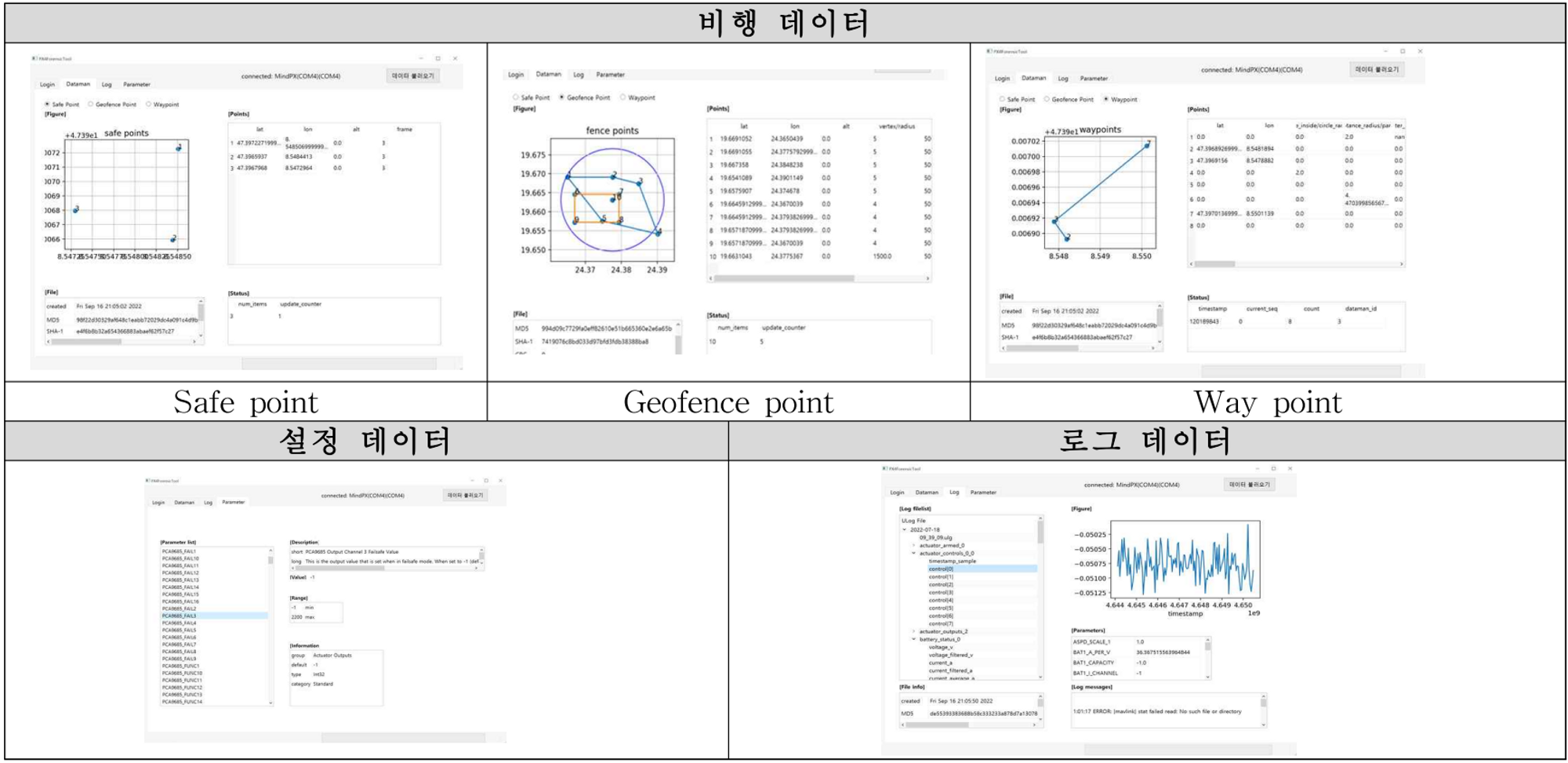
비행 데이터: 비행 경로 & 미션 수행에 관한 데이터로 dataman 모듈에 의해 파일명이 ‘dataman’인 바이너리 파일로 SD card에 저장된다. dataman 파일에는 드론의 안전귀환지점인 Safe point, 비행구역인 Geofence point, 미션수행 정보인 Way point를 저장한다. Safe point는 UAV가 안전하게 착륙할 수 있는 지점을 의미하고 좌표계와 좌표로 구성된다. Geofence는 UAV가 안전하게 비행할 수 있는 구역으로 각 지점의 좌표와 Fence 형태로 저장한다. Way point는 UAV가 비행하는 경로 또는 수행해야 할 임무를 나타낸다.
설정 데이터: 기체 드라이버, 모듈에서 사용되는 파라미터 값으로 param 모듈에 의해 관리된다. 초기 설정 파라미터는 펌웨어에 저장되어 있고 설정값을 변경하는 경우 EEPROM에 저장된 mtd_params 파일에 파라미터 명과 함께 변경된 설정값을 저장한다. PX4 부팅시 퍼웨어에서 초기 파라미터를 RAM에 로드하고 mtd_params 파일에서 변경된 파라미터를 덮어써 기체의 파라미터를 수정한다. GCS에 전달하기 위한 파라미터값은 별도의 /tc/parameters.json.xz 파일에 저장된다.
로그 데이터: logger 모듈이 저장하는 uORB 토픽 데이터로 ULog 파일 형태로 SD card에 저장된다. 센서 데이터나 기체 내부 상태, 파라미터 값, 로그 메시지, RC 입력, CPU 부하, EKF 상태 등 여러 데이터가 저장된다.
3. 드론 내부 데이터 추출 방법
드론 내부의 데이터를 추출하기 위해 드론 기체와 로컬 PC와 USB 시리얼 포트로 연결 후 MAVLink의 하위 프로토콜인 MAVFTP를 이용해 추출한다. 아래는 PX4 Autopilot mini 4의 디렉터리 구조라고 한다.
/bin, /dev, /obj는 가상 파일 시스템에 의해 관리되어 MAVFTP로 폴더 추출이 불가능하다고 한다. proc의 경우도 추출이 불가능했으나 cat을 통해 데이터를 추출했다고 한다. 이외의 /etc와 /fs 디렉터리는 추출이 가능했다. 이렇게 추출 가능한 디렉터리를 활용해 데이터 분석 도구를 개발했고 포렌식에 활용하기 위해 간단히 파일 생성 타임스탬프와 해시값 계산, CSV 추출 기능 등의 기능을 구현했다.
결론적으로 드론 포렌식을 위해 MAVFTP 프로토콜로 접근 드론 내부 데이터에 접근해 추출하는 방안을 제시했고, 데이터 추출을 위해 GUI 도구를 개발하였다.
-- Question
Q1. Waypoint는 UAV가 비행하는 경로만을 나타내는 것이 아닌가? 수행해야 할 임무를 나타낸단 건 무슨 의미인가? 같은 의미로 볼 수 있는가?
2020년 대한전자공학회에서 나온 논문이다. 핵심은 제목 그대로 자율주행드론을 위한 위치제어와 고도제어가 핵심이다. 연구배경은 GPS와 같은 센서는 외부환경에서는 사용할 수 있지만 실내와 같은 내부환경에 들어오게 되면 차폐된 내부로 인해 GPS 신호가 단절될 수 있어 자율주행의 한계가 있다는 점이다. 따라서 실내환경에서 드론의 자율비행 임무수행을 위한 위치제어와 고도제어 방법에 대해 제시한다.
1. 위치제어
위치제어란 실내에서 장애물회피 임무를 수행할 뿐아니라 드론 기체가 외력을 받아 Drift되지 않도록 위치를 제어하는 것을 말한다. 논문에서는 위치제어를 위한 방법으로 px4flow를 사용해 컴퓨터비전 알고리즘을 적용했다. px4flow란 optical flow 센서 중 하나인데 optical flow는 영상을 통해 호버링 시 기체의 위치가 흔들리지 않도록 도와주는 센서다. (https://docs.px4.io/v1.13/ko/sensor/px4flow.html)
px4flow: 영상 변화에 따른 빛의 변화를 계산하는 기능의 카메라
2. 고도제어
고도제어란 지면으로부터 거리를 조절하는 것이다.
자율주행에 고도제어가 필요한 이유는 3차원 공간(x, y, z)의 특정지점에서 비행이 가능해야 하기 때문이다. 드론의 고도제어를 위해 사용하는 센서는 적외선 센서, 기압센서, 초음파센서, 라이다센서가 있다. 결론부터 말하면 논문에선 다 사용해보았으나 라이다센서가 가장 높은 정확성을 보였다. 서술한 센서의 실험 결과를 차례대로 기술해보자면,
2.1 적외선 센서
적외선 센서를 사용한 결과 온도에 영향을 받아 외부환경 파악에 신뢰성 떨어지는 신호를 수신했다.
2.2 기압 센서
Pixhawk에 내장되어 있다고만 서술되어 있고 이에 대한 실험 내용은 누락되어 있음.
2.3 초음파 센서
초음파 센서는 초음파 방출 후 물체에 반사되어 돌아오는 시간을 통해 물체와의 거리를 구하는 센서다. 초음파 센서를 사용한 결과 비교적 고른 값을 수신하나 중간값, 평균값에 차이가 많이나는 이상치가 수신되는 경우가 발생했다. 이 이상치는 확장칼만필터(EKF)로 보정을 했음에도 고도제어에 부정확성을 야기하는 것이 관찰되었다.
실험에 사용한 초음파센서는 Maxbotix사의 HRLV-MaxSonar-EZ4 센서이며, EZ4에서 0~4는 빔폭을 나타내고 클수록 빔폭이 좁아진다. 초음파 센서에 들어온 아날로그 신호를 ADC 포트를 거쳐 디지털 신호로 바뀐다음 Pixhawk로 전달된다. 초음파 센서의 입력값을 정확히 이용하기 위해선 Scaling 파라미터를 조절해주어야 한다. 이는 Ardupilot 공식 홈페이지에서 제시하는 값이 있으나 오차가 커서 잘 들어맞지 않았다.
2.4 라이다 센서
라이다 센서를 px4flow 센서와 함께 사용한 결과 드론 위치와 고도를 제어할 수 있었고 실내 환경에서 높은 신뢰성을 얻었다. 실험에 사용한 제품은 Benewake 사의 TF mini LiDAR를 사용했다. 이는 단거리 측정을 목적으로 개발된 센서로 실내에서 최대 12m, 실외에서 최대 7m 거리를 측정가능하다. TF mini Lidar는 Serial, UART, I2C 통신 등 다양한 방법으로 연결할 수 있고 실험에선 Serial 포트를 통해 연결했다. LiDAR 센서를 통한 실험의 결과로는 별다른 센서 calibration 없이 비교적 정확한 값을 측정할 수 있었다. 논문에선 Pixhawk와 LiDAR 센서의 Serial 통신에서 BaudRate를 115200으로 설정해줘야 한다고 한다.
TF Mini LiDAR
3. 실험 결과
초록선이 라이다 센서고 빨간선이 초음파 센서다. 초음파의 경우 드론이 움직일 때 마다 값의 변화가 크다. 즉 노이즈가 많이 추가되는 것을 볼 수 있다. 반면 라이다 센서는 안정적인 고도값을 측정했다. 초음파 센서는 0.5m 이상 오차가 발생했지만 라이다 센서는 0.05m의 오차만 발생했다고 한다. 위에서도 기술했지만 초음파 센서 값을 EKF로 보정했으나 오히려 이착륙시 고도제어가 더 불안정하게 되었고 결론적으로 고도제어에는 초음파 센서가 적합하지 않다는 결론을 내렸다.
--- 결론 ---
다른 적외선 센서나 기압 센서와의 비교가 없으나 결론적으로 라이다 센서가 가장 드론 위치제어와 고도제어에 안정적이라고 한다.
--- 이외 기타 내용 정리 ---
- px4flow 사용을 위해 초점 조절과 calibration을 수행해야 하는데 이는 파라미터로서 지원되고 파라미터 설정이 가능한 GCS를 사용해 가능함. 논문에선 Mission Planner 사용
- px4flow calibration은 기체의 자이로 정보와 px4flow의 자이로 정보를 일치시킴으로써 수행함. 이를 위해 기체 프로펠러를 뺀 체 손으로 roll, pitch 동작을 반복하고 이후 로그를 통해 pixhawk의 자이로 값과 px4flow의 자이로 값을 비교해 오차가 있다면 파라미터를 변경해 오차를 줄이는 방식을 사용함.
- px4flow 정상작동을 위한 전원공급을 위해 BEC를 이용해 5V 전원 별도 공급
- px4flow와 pixhawk 간의 연결을 위해 I2C 통신포트를 사용.
--- Question ---
Q1. 위 그래프의 초록선은 저자가 간단히만 언급했던 라이다 센서와 px4flow 센서를 함께 결합한 성능인가 라이다 센서의 독립적인 성능인가?
Q2. 라이다 센서 vs 카메라 센서를 비교하면 어떨까?
Q3. PMW란 무엇인가?
Q4. QGroundController에서도 px4flow calibration을 수행할 수 있는가?
2019년 한국통신학회에서 나온 논문이다. Gazebo 시뮬레이션 환경에서 드론에 LiDAR를 장착한 다음 장애물 회피 알고리즘을 통해 테스트를 한 것이 핵심이다. 장애물 회피 알고리즘은 가장 처음 직관적으로 떠올릴 수 있는 로직이자 심플한 절차로 수행된다.
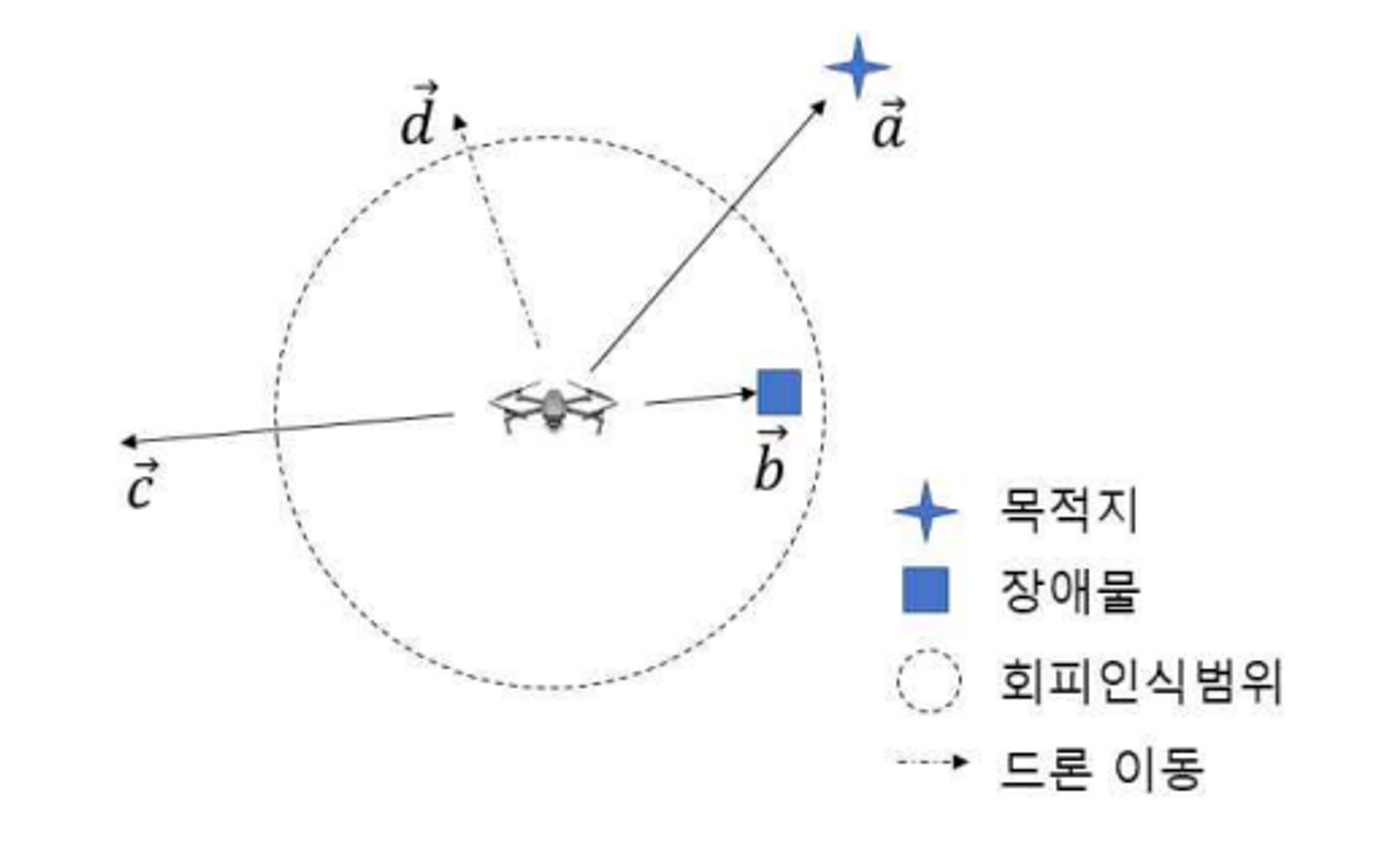
목표를 정하고 장애물을 인식하고 장애물과 이에 반대 방향의 벡터를 만들고 목표 벡터와 반대 방향의 벡터를 결합하는 것이 골자다. 위와 같은 장애물 회피 알고리즘을 적용했을 때 아래와 같은 경로로 드론이 장애물을 회피하며 목표지점에 도달하게 된다.
이외에 몇 가지 팁이있다면 첫 번째는 드론을 너무 빠른 속도로 움직이면 관성에 의해 장애물에 부딪히기 때문에 드론의 최대 비행 속도를 적절히 제어해야 한다. 두 번째는 Gazebo 시뮬레이션은 URDF, SDF를 사용하는데 URDF가 SDF에 비해 ROS와 호환성이 좋아 로봇 모델링에 많이 사용한다는 것이다. SDF는 Gazebo 시뮬레이션에 사용할 수 있지만 ROS와 호환성이 좋지 않다고 한다. 따라서 URDF로 모델링하는 것이 최선이라고 함. 저자들은 URDF로 기술된 드론 모델에 추가코드를 통해 PX4Flow, SF-10a, RPLIDAR 센서가 장착된 드론을 모델링 했다. 세 번째는 원하는 모델(메쉬)이 없다면 Blender나 Sketchup와 같은 모델링 툴을 이용해 직접 모델을 구성할 수 있다.
2021년 한국항공우주학회에서 나온 논문이다. 내용의 핵심은 드론이 장애물을 회피하면서도 안전하게 비행할 수 있는 전역 경로 플래너(Global Path Planner)를 개발한 것으로 아래와 같은 아키텍처를 갖는다. 비행제어 S/W로는 PX4를 활용했고 미션 컴퓨터로는 Jetson Nano를 사용했다.
위 아키텍처의 핵심은 Mission Computer 내의 Global Planner Node와 Octomap Node 두 가지다. Global Planner Node는 PX4로부터 드론의 자세정보(vehicle_attitude)와 위치정보(vehicle_local_position, vehicle_global_position)를 수신하고 동시에 Depth data를 수신한다. 이후 Depth data의 정확한 위치를 계산한 값을 Octomap Node로 보낸다. Octomap Node는 수신 받은 데이터를 사용해 비행 구역의 장애물 유무를 3차원 occupancy grid map으로 만들어 Global Planner Node로 전달한다. 이후 Global Planner Node는 Octomap Node에서 전달받은 3차원 지형정보를 기반으로 드론이 목표지점까지 장애물과 충돌하지 않고 안전히 비행할 수 있는 경로를 지속적으로 계산하여 PX4에 다음 위치를 명령하는 방식으로 비행이 이뤄진다.
위와 같이 구성한 아키텍처는 gazebo 환경에서 PX4-ROS2 기반의 경로 계획을 수행하는 시뮬레이션을 통해 그 동작을 확인하였다. 인식한 장애물을 우측상단의 rviz를 통해 3차원 맵으로 시각화하였고 또 목적지까지 장애물을 회피하며 비행하였다.
실질적으로 얼마나 잘 동작했는지는 확인할 수 없었지만 목표지점 도달을 위해 경로 계획(Path planning)이 필요하고 이러한 경로 계획에 필요한 여러 파라미터 값을 알 수 있었다. 예컨데 vehicle_command를 통해 드론의 위치 명령을 내리거나 up_cost, down_cost를 조정해 드론의 수직이동에 소모되는 에너지를 다르게 계산한다는 점, 또 risk_factor, neighbor_risk_flow를 조정해 지형지물의 위험도 수준을 다르게 줄 수 있다는 점을 알게 됐다. 또 새롭게 접하게 Octomap과 occupancy grid map이 있었고 향후 이에 대해 알아보고자 한다.
최근 드론의 수평제어를 위해 PX4의 gazebo에서 출력하는 IMU 센서 데이터를 기반으로 calibration을 수행하여 보정값을 다시 드론으로 전달하는 기능 구현이 필요하다 생각됐다. 결론부터 말하자면 삽질이었고 이미 PX4 펌웨어에서는 센서 데이터에 대해 확장칼만필터를 적용하여 제공하고 있어서 별도로 기능 구현을 할 필요가 없었다. 그래도 간단히나마 삽질 과정을 기록해본다.
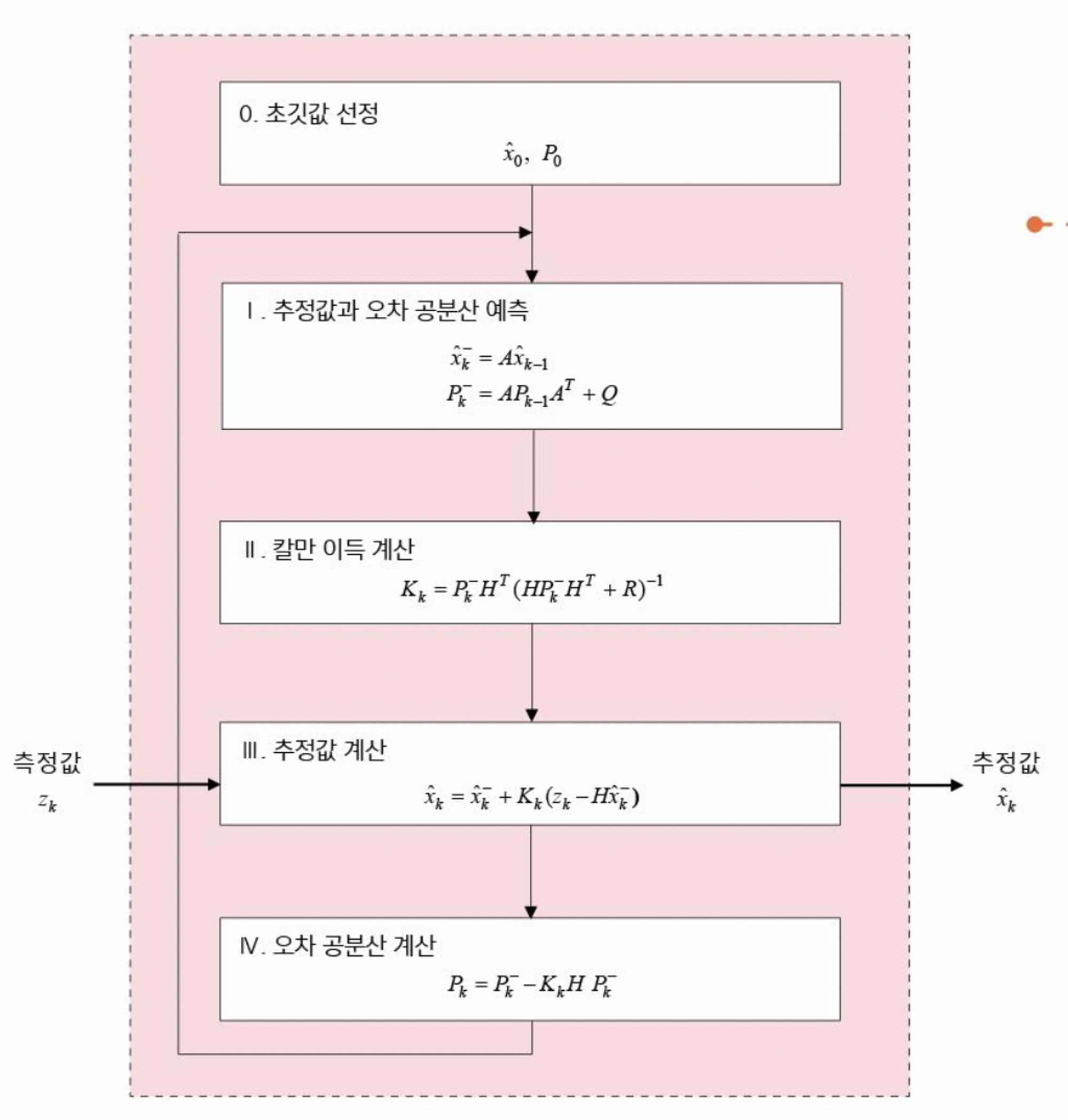
찾다보니 IMU 센서 데이터를 보정하기 위해 칼만필터와 확장칼만필터가 사용되는 것을 알 수 있었다. 칼만필터는 선형시스템의 상태추정을 위해 사용되고 확장칼만필터는 비선형시스템의 상태추정을 위해 사용된다. 이러한 칼만필터와 확장칼만필터을 통해 드론의 자세추정과 수평제어에 사용할 수 있어 비행의 안정성을 가져올 수 있기 때문에 필수적이다. 칼만필터는 선형시스템의 실제상태와 추정상태 간의 차이를 나타내는 '오차공분산'을 최소화하는 알고리즘이다. 통계 기반 알고리즘이며 이전 추정상태가 다음 상태추정에 영향을 미치므로 마르코프 연쇄를 가정한 알고리즘이다. 이러한 칼만필터는 선형시스템일 경우 최적화된 상태 추정이 가능하다는 것이 수학적으로 증명되어 있다고 한다. 하지만 대부분의 경우 비선형시스템을 따르므로 모델링을 위해서는 확장칼만필터를 사용한다. 확장칼만필터는 비선형시스템을 나타내는 상태식을 매 순간 미분하여 선형시스템으로 근사한 다음 칼만필터를 적용하여 비선형시스템의 상태를 추정한다. 아래는 칼만필터의 알고리즘이다.
칼만필터에 사용되는 주요 변수는 A, H, Q, R, P, K로 여섯 가지다. 이 중 네 가지(A, H, Q, R)는 이미 정해진 값이며 칼만이득인 K는 자연스럽게 계산되는 값이다. 실제로 구해야할 것은 P 밖에 없다. 이 P가 오차공분산이며 이를 계산하여 다음 상태추정에도 활용한다. 이 P를 최소화하는 것이 칼만필터 알고리즘의 목표다. 이러한 칼만필터를 활용해 IMU 센서 데이터를 보정하여 드론 수평제어 기능을 만들고 싶었다. 나이브했던 접근은 PX4 uORB topic 중 IMU 센서 관련 토픽을 구독해 칼만필터 알고리즘을 적용해 보정하고 보정값을 다시 토픽 발행을 통해 적용해주려 했다.
PX4 uORB의 topic 중 /fmu/out/sensor_combined에서 IMU 센서값을 얻을 수 있었고 C++로 /fmu/out/sensor_combined 데이터를 구독하는 기능을 구현했다. 다만 칼만필터 알고리즘 적용이전 간단히 하드코딩된 값으로 설정해 발행해보았지만 적용되는 것 같지 않았다. 알고보니 /fmu/in/sensor_combined가 있을 것이고 여기로 보정값을 전달하면 수평제어가 되지 않을까 했었는데 /fmu/in/sensor_combined 토픽 자체가 없었던 것이다. 왜 없을까 생각해보았을 때 어쩌면 안정성을 추구하는 PX4의 철학때문이지 않을까 싶다. 잘은 알지 못하겠다. 아무튼 이렇게 IMU 센서 관련 정보를 직접적으로 calibration할 수 없다면 어떻게 이뤄질까하며 찾다보니 /fmu/out/sensor_combined는 이미 확장칼만필터가 적용된 센서값임을 알 수 있었다. PX4에는 이러한 확장칼만필터와 같은 기능을 활성화할지 비활성화할지를 결정하는 여러 개의 'parameter'가 있다. 이러한 paramter는 PX4의 펌웨어에 접근하거나 QGroundController 내부에서 변경이 가능하다. (https://docs.px4.io/v1.11/en/advanced_config/parameter_reference.html)
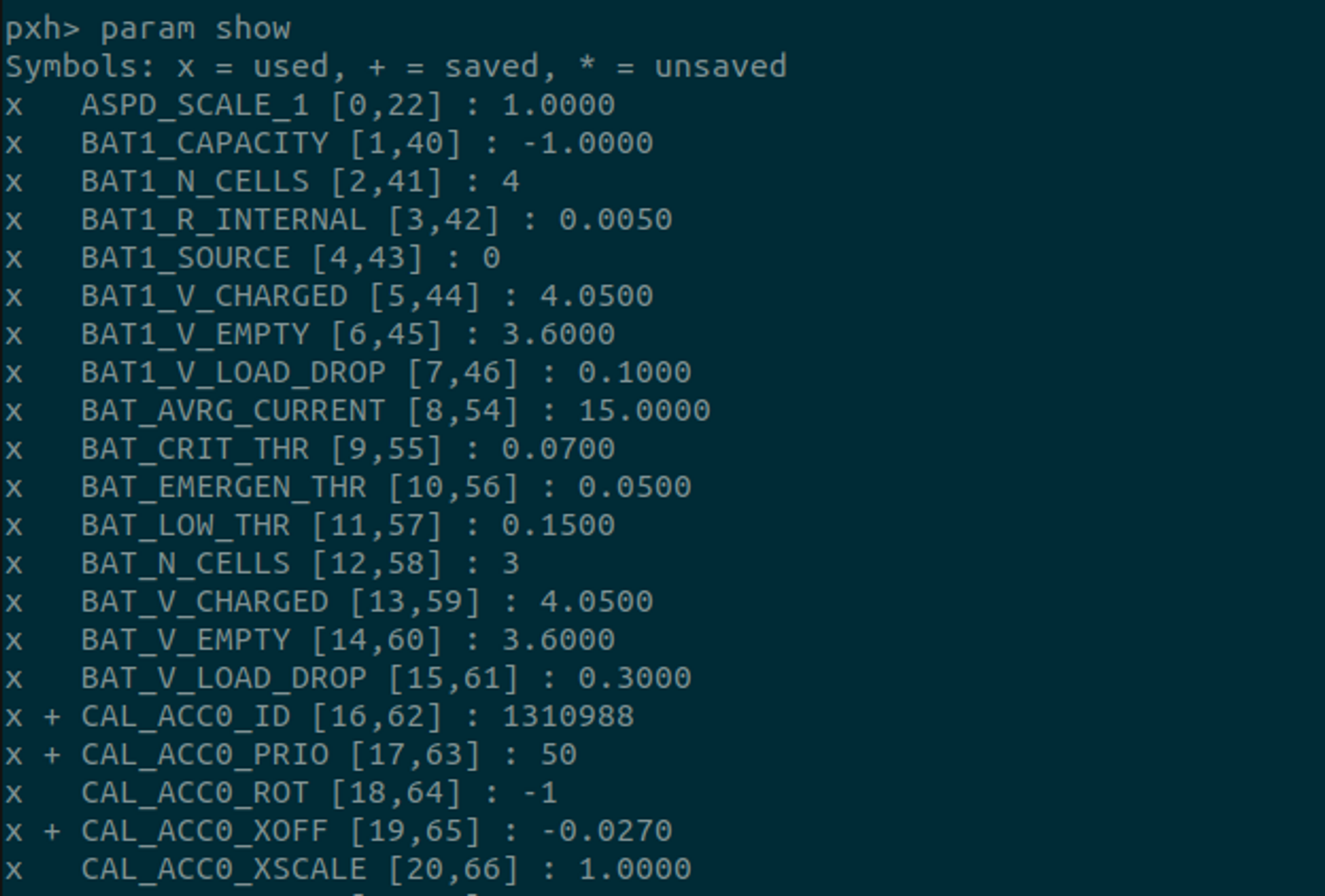
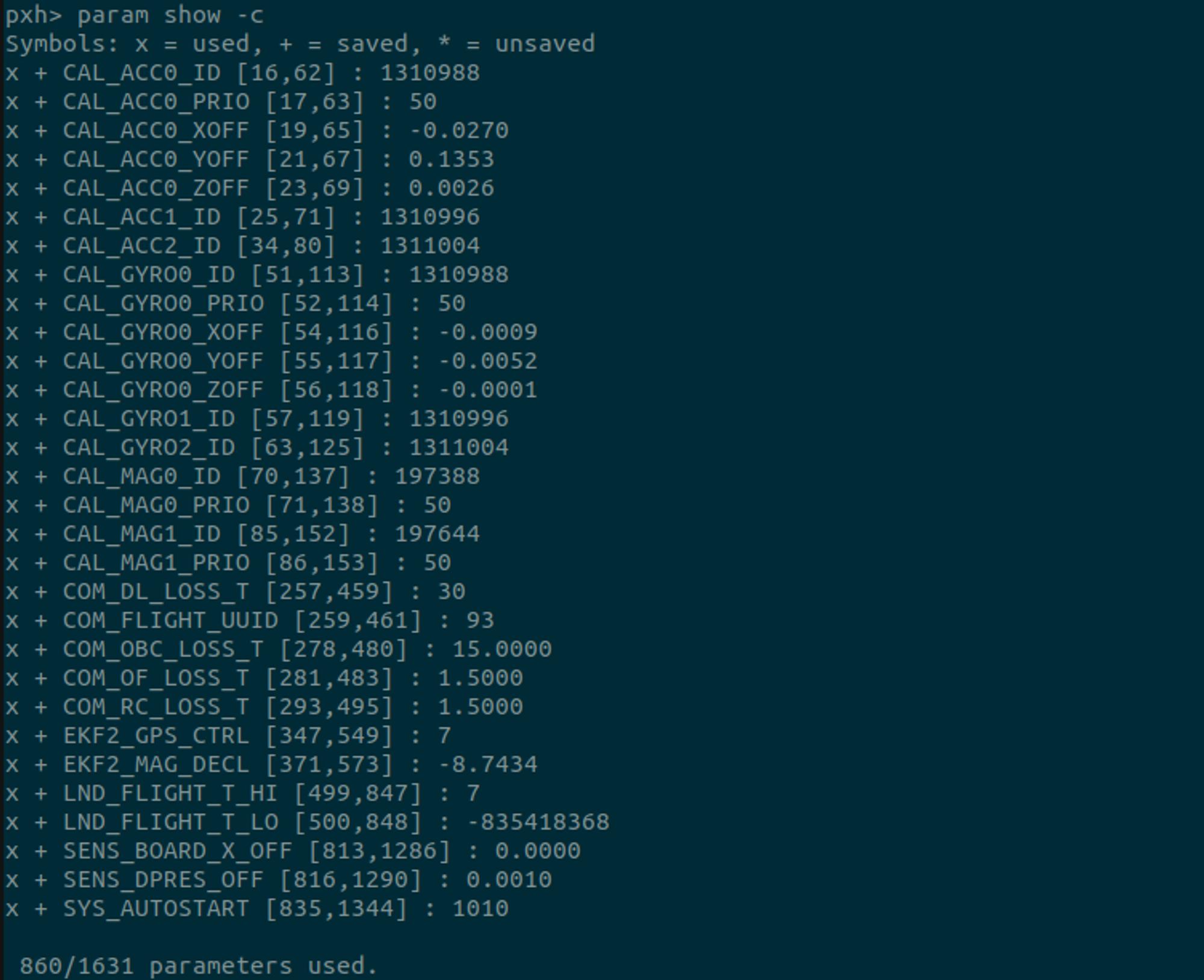
위 parameter reference에서 보다보면 확장칼만필터(EKF) 관련 parameter가 수 십여 개가 있는 것을 확인할 수 있다. EKF2_*로 시작하는 parameter들이다. 이러한 parameter들을 포함하여 PX4에서 사용하는 여러 paramter들은 PX4 셸에서 param show 명령을 통해서도 그 목록을 확인할 수 있다. 또 param show -c 옵션을 통해 default 값에서 바뀐 모든 매개변수를 확인할 수도 있다.
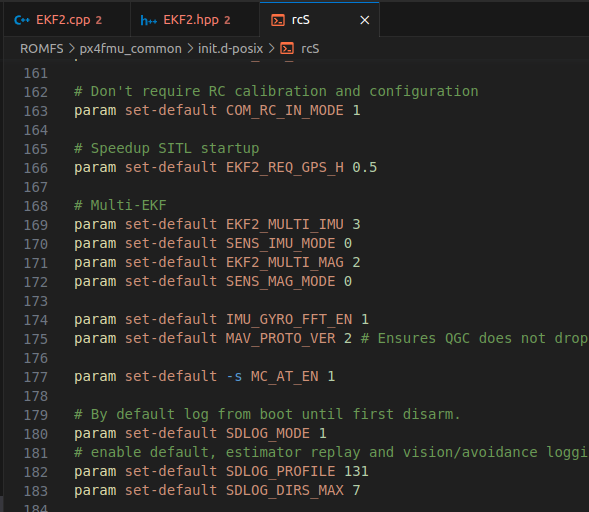
또 이런 parameter들은 PX4가 실행할 때 start script인 /PX4-Autopilot/ROMFS/px4fmu_common/init.d-posix/rcS 파일에서도 설정할 수 있음을 확인할 수 있었다.
또 PX4 셸에 구현되어 있는 uORB 앱 중에서 확장칼만필터를 보완한 ekf2를 확인할 수 있었다. ekf2 start를 통해 실행시킬 수도 있는 것 같은데 에러가 발생한다. 잘 모르겠다.
참고로 이 확장칼만필터인 ekf2는 PX4-Autopilot/src/modules/ekf2에서 구현체를 확인할 수 있다. 워낙 PX4 관련 레퍼런스가 적고 여기저기 찾으면서 부분을 더듬고 있다보니 작성한 글에도 오류가 있을진 모르겠다. PX4에 대해 익숙해진다면 고생하는 초심자들을 위해 관련 가이드 서적을 만들고 싶단 생각이 든다. 다음엔 어떤 기능을 만들어야 할까.
Gazebo 내의 데이터를 가져오기 위해 gazebo plugin을 사용해 ros2 topic으로 구독하려는 과정에서 libgazebo_gps_plugin.so 파일을 로딩할 수 없다는 에러 메시지를 확인할 수 있었다. 해당 파일은 있었지만 gazebo가 해당 파일이 위치하는 디렉터리의 경로를 찾지 못하는 것으로 판단됐다. 찾다보니 리눅스에서 공유 라이브러리를 찾을 때 사용하는 환경변수 LD_LIBRARY_PATH 설정이 필요했고 아래 명령을 .bashrc 파일에 작성하여 셸이 열릴 때 마다 실행되도록 해주었다.
이러한 리눅스에서 사용하는 환경변수 외에도 Gazebo에서 사용하는 주요 환경변수들을 찾다보니 아래와 같은 환경변수를 확인할 수 있었다.
GAZEBO_PLUGIN_PATH
Gazebo plugin을 검색할 경로를 지정하는 변수다. 이는 LD_LIBRARY_PATH와 유사해보인다. 어떻게 같고 다를까? LD_LIBRARY_PATH는 실행 중인 프로그램이 공유 라이브러리 파일을 검색할 경로를 지정할 때 사용하는 환경변수다. 반면 GAZEBO_PLUGIN_PATH는 Gazebo 플러그인을 검색할 경로를 의미하는 환경변수다. 즉 GAZEBO_PLUGIN_PATH를 통해 Gazebo plugin을 찾고 LD_LIBRARY_PATH를 통해 Gazebo plugin이 필요로 하고 의존하는 공유 라이브러리 파일을 찾는다.
GAZEBO_MODEL_PATH
Gazebo에서 모델을 검색할 경로를 지정하는 변수다. 이를 통해 사용자 정의 모델이나 외부 모델 경로를 추가할 수 있다.
GAZEBO_RESOURCE_PATH
Gazebo에서 리소스 파일을 검색할 경로를 지정하는 변수다. 여기서 리소스란 월드, 모델, 플러그인 등을 뜻한다.
GAZEBO_MASTER_URI
Gazebo 마스터 서버의 URI를 설정하는 변수다. Gazebo의 다중 인스턴스를 실행하거나 원격 Gazebo 서버와 통신할 때 사용한다.
GAZEBO_MODEL_DATABASE_URI
Gazebo 모델 데이터베이스 서버의 URI를 설정하는 변수다. 즉 원격으로 Gazebo 모델 데이터베이스에 접근하고 모델을 다운로드 받을 때 사용한다
접근 지정자에는 크게 public, private, protected가 있다. 접근지정자는 C++에서 클래스안의 멤버함수와 멤버변수에 접근 여부를 제어할 때 사용한다. public에 멤버함수나 멤버변수를 두면 클래스 외부를 포함한 모든 곳에서 접근가능하다. private에 멤버변수나 멤버변수를 두면 클래스 내부에서만 접근가능하고 외부에서는 접근할 수 없다. protected는 상속과 관련됨 (추가 이해 필요)
# this
C++에서 this는 클래스의 실제 인스턴스에 대한 주소를 가리키는 포인터다. 클래스의 모든 함수는 함수가 호출된 객체를 가리키는 this 포인터를 갖는다. 이는 컴파일러가 동작하는 과정에서 implicit하게 this 포인터를 사용가능하도록 만들기 때문이다. this 포인터는 크게 두 가지 측면으로 활용된다. 첫 번째는 멤버변수와 매개변수의 이름이 같을 때 구분할 수 있고, 두 번째는 함수에서 *this를 반환하는 방식으로 함수체이닝으로 코드를 간결하게 작성할 수 있다.
# auto
auto는 자료형을 자동으로 추론할 때 사용한다. 예를 들어 다음과 같다.
int main(void)
{
int a = 5;
int b = 21;
auto sum = a + b;
}
별도의 int, float, double, char 등을 지정해주지 않아도 자동 타입추론을 통해 자료형을 할당한다.
# 람다함수
람다함수는 메모리 효율을 위해 사용한다. 일반 함수와 달리 함수명이 없는 것이 특징이다. 람다함수의 구조는 크게 4가지로 구성된다. [](){}()다. 역할을 먼저 설명하면 가장 첫번째인 []는 캡처, ()는 매개변수, {}는 함수동작, ()는 호출인자다. []인 캡처는 매개변수와 동일하게 값을 받아와 사용할 수 있다. call-by-value 또는 call-by-reference로 받아올 수 있다. call-by-value는 외부변수를 변경하지 않을때 사용하고 call-by-reference는 외부변수를 변경할 때 사용한다. 예를 들어 call-by-reference로 사용할 때는 다음과 같다.
int main(void)
{
int r1 = 1;
int r2 = 2;
[r1, r2](int a, int b)
{
cout << r1 + r2 + a + b << endl;
}
}
call-by-reference로 사용할 때는 다음과 같다.
int main(void)
{
int r1 = 1;
int r2 = 2;
[&r1, &r2](int a, int b)
{
r1 = 2;
r2 = 4;
cout << r1 + r2 + a + b << endl;
}
}
캡처는 이외에도 [=]를 통해 외부변수 전체를 복사해 가져올 수도 있고 [&]를 통해 외부변수 전체를 참조할 수도 있다.
람다함수 구조의 두 번째인 ()는 매개변수를 의미한다. 위 코드에서 (int a, int b)와 같다. 세 번째인 {}는 동작할 함수 동작이다. 위 코드 예시에서는 값을 더해주고 출력하는 것이다. 네 번째인 ()는 두 번째 매개변수와 다른 호출인자다. (int a, int b)에 실질적으로 넣어줄 값을 의미한다.
PX4에서 앱을 만들고 SITL 상에서 실행시키는 'Hello World' 수행 예시를 정리하고자 하는 목적으로 작성한다. PX4에서 새로운 앱을 만들어 구동시키고자 한다면 PX4-Autopilot/src/ 폴더에서 수행해야 한다. 본 예제를 위해서는 새 디렉토리 'px4_simple_app'을 PX4-Autopilot/src/examples 하위에 생성한다. 이후 폴더와 동일한 이름의 px4_simple_app.c를 생성하고 아래 Hello World가 수행되는 코드를 붙여준다.
1. px4_simple_app.c 파일 생성
#include <px4_platform_common/log.h>
__EXPORT int px4_simple_app_main(int argc, char *argv[]);
int px4_simple_app_main(int argc, char *argv[])
{
PX4_INFO("Hello roytravel!");
return 0;
}
코드를 간단히 설명하자면 #include <px4_platform_common/log.h>를 통해 C언어의 printf와 같은 PX4의 출력 함수인 PX4_INFO를 실행할 수 있도록 라이브러리를 불러온다. 그리고 main 함수를 만들어주되 main 앞에 추후 PX4 상에서 사용할 모듈 이름을 함께 사용해준다. 이후 위 .c 파일과 마찬가지로 PX4-Autopilot/src/examples/px4_simple_app/ 하위에 CMakeLists.txt 파일을 만들어준다.
2. CMakeLists.txt 파일 생성
px4_add_module(
MODULE examples__px4_simple_app
MAIN px4_simple_app
SRCS
px4_simple_app.c
DEPENDS
)
MODULE은 PX4-Autopilot/src 하위의 examples에서 '/'를 '__'로 치환한 다음 모듈 이름을 적어주는 것 같다.
MAIN은 PX4 셸 또는 SITL 콘솔에서 호출할 수 있도록 NuttX에 명령을 등록하는 모듈의 진입점이라고 한다.
SRCS는 말그대로 빌드할 소스코드들을 기술한다. DEPENDS는 의존 라이브러리가 없으므로 널 값으로 보인다.
3. Kconfig 파일 생성
마찬가지로 PX4-Autopilot/src/examples/px4_simple_app/ 하위에 별도 확장자 없이 Kconfig 파일을 생성해주고 아래와 같이 값을 추가해준다.
PX4에서 lockstep이란 PX4와 시뮬레이터(ex: Gazebo) 간 동기화/비동기화 여부를 의미한다. Lockstep이 설정되어 있을 경우 PX4와 시뮬레이터는 자체 속도로 실행되지 않고 센서와 액츄에이터 메시지를 서로 기다리게 된다. 만약 설정되어 있지 않을 경우 PX4와 시뮬레이터는 각자의 속도로 수행된다. 이를 설정하기 위한 두 방법이 있다. 첫 번째는 PX4에서 설정하는 것이고 두 번째는 시뮬레이션 관련 파일에서 설정하는 것이다.
PX4에서 Lockstep을 해제하기 위해서는 make px4_sitl_default boardconfig 명령을 통해 보드 설정으로 접속하면 다음과 같은 화면을 볼 수 있다.
위 화면에서 방향키를 이용해 Toolchain에 들어가면 아래와 같이 “Force disable lockstep”이 있다.
기본값으로 활성화로 설정되어 있고 비활성화를 원할경우 엔터를 통해 비활성화 설정이 가능하다.
만약 시뮬레이션(Gazebo)에서 Lockstep을 해제하기 위해서는 SDF 파일 수정이 필요하며 아래 요소를 .sdf 파일에 추가해준다.
uXRCE-DDS: Extremely Resource Constrained Environment - Data Distribution Service
uXRCE-DDS는 미들웨어이자 프로토콜이다. uXRCE-DDS는 ROS2와 PX4 중간에서 통신을 매개하는 역할을 한다. uXRCE-DDS를 통해 ROS2에서 드론 관련 정보를 받아오고 또 명령을 보낼 수 있도록 한다. 아래 아키텍처를 살펴보자.
아주 직관적인 구성이다. PX4와 ROS2로 양분되어 있고 PX4와 ROS2 사이를 uXRCE-DDS 프로토콜로 연결한다. 드론 관련 정보를 ROS2로 제공하는 쪽이 uXRCE-DDS client고 이러한 정보를 가공하여 PX4쪽으로 명령을 내리는 곳이 uXRCE-DDS agent다.
PX4는 ROS2와 마찬가지로 토픽을 통해 드론 비행제어를 위한 정보를 주고 받는다. 즉 publisher를 통해 드론 관련 정보를 발행하고 subscriber를 통해 드론을 제어한다. PX4에서는 토픽을 통해 publisher/subscriber을 사용하는 형식은 ROS2와 같지만 ROS2의 publisher/subscriber와 달라 호환되지 않는다. 이러한 호환을 가능하게 하는 것이 uXRCE-DDS인 것이다.
PX4는 토픽 publish/subscribe를 uORB를 통해 수행한다. uORB는 PX4의 내부에서 토픽이 동작할 수 있도록 하는 PX4 내부통신 메커니즘이다. PX4에서도 토픽을 사용하기 위해서는 ROS2에서와 마찬가지로 메시지 포맷이 필요하다. ROS2에서와 같이 *.msg 확장자를 가진다. 직접 확인해보자. https://github.com/PX4/PX4-Autopilot에서 소스를 다운로드 받아 msg 폴더를 살펴보면 아래와 같이 미리 정의되어 저장된 msg 파일을 확인할 수 있다.
간단한 예시를 위해 Airspeed.msg를 살펴보면 다음과 같은 데이터 포맷으로 메시지 파일이 정의가 되어 있다.
PX4에서는 토픽을 사용하기 위해 *.msg 파일을 사용하지만 *.msg 파일을 바로 읽어 사용하는 것은 아니다. *.msg 파일은 빌드되어 C++ 구조체로 변환되어 사용된다. 실제로 *.msg 파일이 빌드되면 PX4-Autopilot/build/px4_sitl_default/uORB/topics 폴더에 *.h 파일로 저장된다. 아래는 Airspeed.msg가 빌드되어 저장된 airspeed.h 파일이다.
이렇게 변환된 헤더 파일에 저장된 메시지 포맷을 통해 토픽 publish/subscribe가 이뤄진다. 참고로 토픽은 빌드될 때 *.msg 파일 명과 동일한 이름으로 등록된다. abc.msg를 빌드하면 abc라는 이름의 토픽으로 등록되는 것이다.
이러한 토픽은 ROS2에서 노드(Node) 내부에서 구현된다. PX4에서도 마찬가지다. PX4에서는 ROS2의 노드를 모듈(module)이라 부르며 모듈 단위로 토픽을 publish/subscribe한다. 예컨데 카메라 센서 모듈, IMU 센서 모듈 등으로 모듈을 구현하여 토픽을 publish하고 subscribe하는 것이다. 만약 여러 모듈 간의 통신이 필요한 경우라면 PX4는 내부적인 모듈 간의 통신을 uORB를 통해 수행한다.
핵심 요약을 하자면 미들웨어라 불리는 XRCE-DDS client와 XRCE-DDS agent가 PX4-ROS2 통신의 핵심이다. 또 ROS2의 노드는 XRCE-DDS agent/client를 거쳐 PX4의 uORB 메시지 형태로 바뀌어 드론에게 전달되고 uORB 메시지는 XRCE-DDS client/agent를 거쳐 ROS2에서 제어 가능한 형태로 바뀌어 전달된다.
실제로 uXRCE-DDS client와 uXRCE-DDS agent를 사용해 드론 비행제어를 수행해보자.
uXRCE-DDS agent
uXRCE-DDS agent를 실행하기 위해서는 소스코드를 다운로드 받아야 한다.
git clone https://github.com/eProsima/Micro-XRCE-DDS-Agent.git
cd Micro-XRCE-DDS-Agent
mkdir build
cd build
cmake ..
make
sudo make install
sudo ldconfig /usr/local/lib/
cd ~/Micro-XRCE-DDS-Agent/build
./MicroXRCEAgent udp4 -p 8888
위 명령을 수행하면 아래와 같이 Agent가 실행됨을 확인할 수 있다.
uXRCE-DDS client
uXRCE-DDS client는 단순히 make px4_iris_default gazebo 명령을 통해 시뮬레이션 환경을 실행할 때 자동으로 실행된다.
cd ~/PX4-Autopilot
make px4_sitl_default gazebo
위 명령을 수행하면 아래와 같이 로그에 uxrce_dds_client가 실행되는 것을 확인할 수 있다.
여기까지하면 ROS2를 통해 드론 비행제어할 준비가 된 것이다. 마지막으로 이를 제어하기 위한 소스코드를 다운로드 받아 실행시켜보자.
mkdir -p ~/ws_offboard_control/src
cd ~/ws_offboard_control/src
git clone https://github.com/PX4/px4_msgs.git
git clone https://github.com/PX4/px4_ros_com.git
cd ..
source /opt/ros/humble/setup.bash
colcon build
source install/local_setup.bash
ros2 run px4_ros_com offboard_control
위 명령을 수행하게 되면 아래와 같이 ROS2를 통해 PX4에서 실행된 gazebo 환경에서 드론 비행이 가능한 것을 확인할 수 있다.
모델 학습 후 성능 최적화를 위해 하이퍼파라미터 튜닝을 수행할 때가 있다. Optuna 사용 방법은 여러 문서에 기술되어 있어 참고할 수 있지만 파이토치에서 분산처리를 적용한 Multi-GPU 환경에서 Optuna를 함께 실행하는 방법에 대한 레퍼런스가 적어 약간의 삽질을 수행했기 때문에 추후 참고 목적으로 작성한다. 또한 파이토치로 분산처리 적용하여 Multi-GPU 학습을 수행하고자할 때 mp.spawn의 리턴값을 일반적으로는 받아오지 못하는 경우가 있어 이에 대한 내용도 덧붙이고자 한다.
Optuna 사용 핵심은 objective 함수 작성이다. 함수 내에는 튜닝할 하이퍼파라미터의 종류와 그 값의 범위값을 작성해준다. 이후 학습 루틴을 수행 후 그 결과를 리턴값으로 전달해주는 것이 끝이다. 학습루틴을 objective 함수 내부에 정의해도 되나 분산학습을 함께 적용하기 위해 별도의 함수로 만들어 실행한다.
run_tuning은 실제로 하이퍼파라미터 튜닝을 수행할 함수를 첫 번째 인자(tuning_fn)로 받는다. mp.spawn은 리턴값이 없으므로 학습 관련 결과에 대한 값을 받아올 수 없다. 만약 multi-gpu를 통한 분산처리의 리턴값을 받아올 필요가 없다면 mp.spawn() 한 줄만 작성해주어도 된다. 하지만 필요한 경우가 있다. 이를 해결하기 위해 mp.Pipe()를 사용한다. 학습 관련 결과를 child_conn을 이용해 parent_conn으로 전송하는 것이다. child_conn은 학습 함수인 tuning_fn의 인자로 들어가서 학습 관련 결과에 대해 parent_conn으로 전달한다. mp.spawn이 종료되면 parent_conn에서 poll() 메서드와 recv() 메서드를 통해 그 결과를 가져올 수 있다.
아래 함수는 실제로 파이토치에서 Multi-GPU를 활용해 학습하는 루틴을 정의한 함수다.
함수의 가장 처음과 끝은 setup()과 cleanup()으로 각각 Multi-GPU로 학습 가능하도록 초기화하고 학습 이후 환경 초기화를 수행하는 역할을 한다. 모델은 DDP로 래핑해주고 데이터셋도 DistributedSampler를 사용한 결과로 데이터로더를 만들어준다. 이후 학습을 수행하고 conn.send()를 통해 그 결과를 parent_conn()으로 전달한다.
파이썬으로 데이터베이스 처리를 위해 pymysql을 사용해 MySQL 쿼리는 자주 다뤘지만 pymongo를 이용한 MongoDB 쿼리는 많이 다뤄보지 못했다. pymongo 쿼리문은 pipeline으로 만들어 실행하는 것이 깔끔하게 작성하고 실행할 수 있다 생각들었다. 작성하고보니 pipeline은 단 3줄 밖에 안되지만 레퍼런스가 적다고 느꼈고 익숙하지 않아 조금의 시간이 소요됐다. 추후에도 많이 사용할 코드 스니펫일 것 같아 기록.
import os
from pymongo import MongoClient
from operator import itemgetter
client = MongoClient(host=os.environ.get('MONGO_HOST'),
port=int(os.environ.get('MONGO_PORT')),
username=os.environ.get('MONGO_USERNAME'),
password=os.environ.get('MONGO_PASSWORD'))
db = client[os.environ.get('MONGO_DB')]
collection = db['name']
pipeline = []
pipeline.append({'$match': {'col1': val1, 'col2': {'$gte', 1682899200}}})
pipeline.append({'$project': {'_id': True, 'col1': True, 'col2': True, 'col3': True}})
pipeline.append({'$limit': 100000})
unsorted_docs = collection.aggregate(pipeline)
unsorted_documents = []
unsorted_documents.extend(unsorted_docs)
documents = sorted(unsorted_documents, key=itemgetter('event_time'))
for document in documents:
...
ROS2에서 통신을 구현하기 위해 사용하는 서비스, 액션, 메시지에서 사용하는 interfaces를 커스텀하여 정의해야 하는 경우가 있다. 이를 커스텀하기 위해 별도의 폴더를 만들고 빌드해주지 않으면 파이썬에서 라이브러리로 불러오거나 C++에서 include할 때 에러가 발생한다.
ROS에서 명령을 실행하는 방법은 두 가지로 run과 launch가 있다. run은 단일한 명령이고 launch는 run의 집합이다. 만약 두 개의 ros 명령을 수행하려면 터미널 두 개를 띄우거나 실행하려는 두 명령을 다 입력해주어야 한다. ROS를 다루다보면 여러 ROS 명령을 수행해야 하므로 효율성을 위해 사실상 launch를 실질적으로 더 많이 사용한다. 파이썬을 이용해 launch 파일을 만들고 gazebo와 rviz를 띄우는 일종의 hello world를 수행해보자.
이를 위해 가장 먼저 작업 디렉터리를 생성하고 작업 디렉터리로 들어간다.
mkdir -p test_ws/src
cd test_ws/src
ROS는 패키지 단위로 프로그래밍이 이뤄지므로 아래 ROS 명령을 통해 패키지를 생성한다.
“gazebo_pkg”는 생성할 패키지 명이다. --buile-type은 사용할 빌드 시스템을 의미한다. ROS1에서는 catkin이 사용되었으나 ROS2에서는 catkin의 업그레이드 버전인 ament를 사용한다. 여기서 ament_python은 파이썬 전용 ament 빌드 시스템이다. 위 명령어를 수행하면 다음과 같이 패키지 폴더가 생성되며 폴더로 들어가면 아래와 같은 파일이 자동으로 생성된다.
목표는 시뮬레이션을 위한 gazebo와 시각화를 위한 rviz를 같이 띄우는 것이다. 이를 위해 launch 파일을 만들어야 하며 이러한 launch 파일이 담길 폴더를 ‘launch’로 생성해준다. 이는 ROS 개발에 있어 컨벤션으로 가급적 지켜주면 좋다. 이후 test.launch.py를 만들어 준다.
이후 gazebo와 rviz2를 실행하는 아래 코드를 test.launch.py 파일에 작성해준다
코드를 살펴보자면 launch 파일이 실행되기 위해 반드시 generate_launch_description 함수를 만들어야 한다. 이후 LaunchDescription에 수행할 명령을 리스트로 담아주면 된다. LaunchDescription은 해당 launch 파일이 실행해야 할 목록을 기술하는 클래스다. 안을 살펴보면 ExecuteProcess 클래스가 두 개 있다. 사용법이 매우 간단한 형태로 수행할 명령을 cmd 인자에 입력해주고 output 인자를 통해 로그를 터미널에 출력해줄 수 있도록 screen을 입력한다.
cd ~/test_ws
source /opt/ros/humble/local_setup.bash
ROS2 환경을 현재 셸 세션에 로드하여 ROS2 실행에 필요한 실행파일, 라이브러리, 환경변수 등에 접근할 수 있도록 하는 명령어다.
터미널이 새로 열릴 때 마다 새로운 세션이 생성되므로 매번 입력해주어야 한다. 귀찮다면 .bashrc에 해당 명령어를 입력해두면 터미널이 생성될 때 마다 자동으로 실행된다.
참고로 setup.bash가 있고 local_setup.bash가 있다. 둘 간의 차이점은 전자는 전역적으로 설치된 패키지 설정이고 후자는 지역적으로 설치된 패키지에 대한 설정을 수행한다. setup.bash를 수행하면 전역적으로 수행되어 간편하지만 다른 패키지와 충돌(?)이 발생할 수 있으므로 가급적(?) local_setup.bash를 사용한다.
만약 위 명령을 수행하지 않고 launch 파일을 실행하면 다음과 같이 만들어주었던 패키지 폴더를 찾지 못했다는 에러를 확인할 수 있다.
위 명령을 수행하고 다시 실행해보자. 이번엔 다른 에러가 발생했다. gazebo_pkg 폴더 안에 test.launch.py가 없다고 한다.
이렇게 에러가 발생하는 이유는 빌드 당시 setup.py를 제대로 설정해주지 않아서 발생한다.
~/test_ws/src/gazebo_pkg/setup.py에 들어가서 아래 15번째 줄에 있는 os.path.join(’share’, package_name, ‘launch’), glob(’launch/*.launch.py’))를 추가해주자. (import os, from glob import glob도 함께)
이후 다시 colcon build --symlink-install --packages-select gazebo_pkg 명령을 통해 빌드를 다시 수행한 뒤, launch 파일 실행을 위해 ros2 launch gazebo_pkg test.launch.py를 수행해주면 아래와 같이 gazebo와 rviz2가 함께 실행되는 것을 확인할 수 있다.
만약 gazebo를 실행할 때 시뮬레이션 환경이 구성되어 있는 world 파일을 넣고자 한다면 test.launch.py와 setup.py를 아래와 같이 살짝만 코드를 바꿔 world 파일 경로 인자를 추가해주는 방식으로 gazebo 실행 시 이미 만들어진 시뮬레이션 환경을 구성할 수 있다. (world 파일이 없다면 이전 포스팅 참고)