통계학의 대전제는 분석 대상 전체(모집단)를 분석하기에는 많은 비용이 발생하므로 부분(표본)을 통해 모집단의 특성을 파악하는 것이다. 모집단의 일부인 표본에 통계 분석 방법을 적용해 모수를 추정하는 방법을 모수 추정이라 한다. 모수는 모집단의 특성을 나타내는 수치를 의미한다. 모수의 종류는 모평균, 모분산, 모비율, 모표준편차, 모상관관계 등이 있다. 이런 모수들은 모집단 전체에 대한 값들이므로 알려지지 않은 수치다. 모집단의 특성을 파악하기 위해서는 이 모수들을 산출할 필요가 있다. 하지만 모집단 전체를 대상으로 산출하기에 비용이 많이 들어 현실적으로 가능하지 않다. 따라서 앞서 말한 것 처럼 표본을 추출하여 모집단의 일반적 특성을 추론하는데, 이를 통계적 추론이라 한다. 또 모수와 마찬가지로 표본의 특성을 나타내는 수치 종류로 표본평균, 표본분산, 표본비율, 표본표준편차, 표본상관관계 등이 있다. 이러한 수치들을 표본 통계량이라 한다. 정리하면 표본 통계량을 기반으로 모수를 구하는 것을 모수 추정 또는 통계적 추론이라 한다. 하지만 이러한 통계적 추론에는 부분을 통해 전체를 추정하는 격이므로 오차가 발생할 수 밖에 없다. 이러한 모수 추정에서 발생하는 오차를 표준오차라고 한다.
2. 모수 추정 방법: 점 추정(point estimation)과 구간 추정(interval estimation)
2.1 점 추정 (point estimation)
점 추정이란 표본으로부터 추론한 정보를 기반으로 모집단의 특성을 단일한 값으로 추정하는 방법이다. 예를 들어 대한민국 남녀 100명씩 표본으로 추출해 키를 조사한 결과 평균이 167.5가 나왔다면 모 평균을 단일한 점인 167.5로 추정하는 방법이다. 이러한 추정을 위해 표본평균과 표본분산 등을 계산해 모집단 평균과 모집단 분산 등을 추정한다. 이 때 표본평균과 표본분산 등은 모수를 추정하기 위해 계산되는 표본 통계량이자 추정량이라 부른다. 이 추정량은 추정치를 계산할 수 있는 함수(확률변수)이다. 이 추정량을 통해 표본에서 관찰된 값(표본평균, 표본분산 등)을 넣고 추정치(모평균, 모분산 등)를 계산한다.
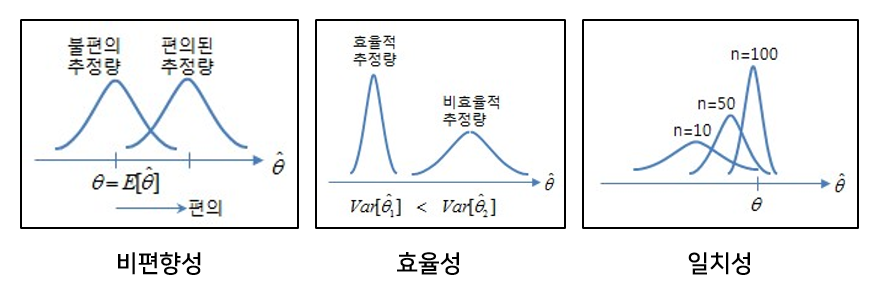
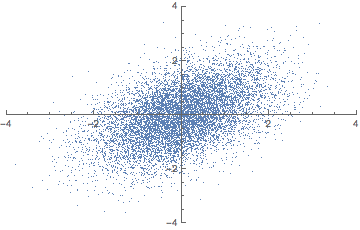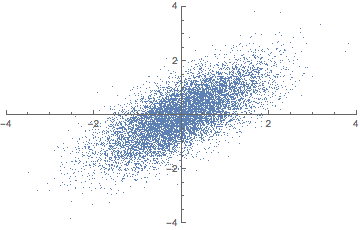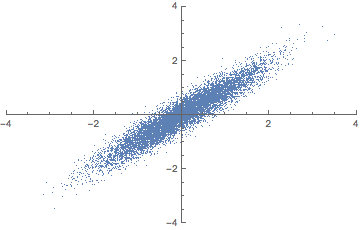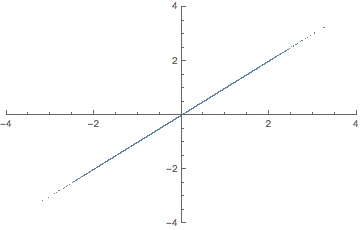
표본평균과 표본분산 등의 추정량(표본 통계량)을 구하기 위해 먼저 표본이 추출되어야 한다. 표본 추출에 있어 가장 중요한 것은 무작위성(비편향성)이다. 편향되어 어떤 표본이 자주 추출된다면 모집단의 일반화된 특성을 추론할 수 없기 때문이다. 아래 그림을 보면 두번째는 편향은 작되 분산이 큰 경우고, 세 번째는 편향이 크되 분산이 작은 경우다. 네 번째는 편향도 크고 분산도 큰 경우다. 모수 추정의 목표는 표본으로부터 구한 표본 분산과 표본 편향 등의 추정량(표본 통계량)이 모수(과녁)와 오차가 작은 첫 째 그림과 같은 형태가 되는 것이다. (만약 모수와 표본 간의 관계를 더 자세히 알고 싶다면 중심극한정리를 볼 것, 모수추정을 가능하게 하는 수학적 근간이다.)
위 그림이 나타내는 바와 같이 추정량에 따라 추정치가 달라지므로 모수와 오차가 적은 추정치를 구하기 위해서는 추정량 선정에 있어 4가지 기준을 고려해야 한다. 아래 4가지를 설명하기 위해 수식 몇 가지만 간단히 정의하자면 모수: $\theta$ 표본 통계량: $\hat{\theta}$ 기대값: $E$이다.
1. 비편향성 (unbiasedness): 표본으로부터 구한 통계량 기대치가 추정하려는 모수의 실제 값과 같거나 가까운 성질을 의미 한다. 즉 편향(편의)은 추정량의 기대치와 모수와의 차이를 의미하는 것으로 $E(\hat{\theta}) - \theta = 0$이다. 편향이 0에 가까워질수록 좋은 추정량이 된다. 이러한 비편향성을 띠는 추정량을 unbiased estimator라고 하며 결국 편향이 적은 추정량을 선택해야 한다. $E(\hat{\theta}) = \theta$을 최대한 만족하는.
2. 효율성 (efficiency): 추정량 분산이 작게 나타나는 성질을 의미한다.
3. 일치성 (consistency): 표본 크기가 클수록 추정량이 모수에 점근적으로 근접하는 성질을 의미한다.
4. 충분성 (sufficiency): 어떤 추정량이 모수 $\theta$에 대해 가장 많은 정보를 제공하는지 여부를 나타내는 성질을 의미한다.
2.2 구간 추정 (interval estimation)
점 추정의 추정치가 모수와 같을 확률이 낮고 따라서 신뢰성이 낮다는 한계를 극복하기 위해 나온 방법이 구간 추정이다. 구간 추정을 통해 표본으로부터 추정한 정보를 기반으로 모수 값을 포함할 것이라 예상되는 구간을 제시한다. 이 구간을 신뢰 구간이라 한다. 신뢰 구간은 표본평균의 확률분포에 모평균이 신뢰수준 확률로 포함되는 구간을 의미한다. 즉 어떤 구간 내에 몇 % 확률로 존재하는지 추정하는 것이다. 구간 추정은 구간의 [하한, 상한]으로 표현하고 구간의 간격(interval)이 작을수록 모수를 정확하게 추정할 수 있다. 따라서 구간 추정은 점 추정에 비해 신뢰성이 높다는 장점이 있다. 신뢰성이 높다하여 점 추정이 불필요한 것은 아니다. 점 추정치를 기반으로 구간 추정이 이뤄지기 때문이다.
3. 추정량 정확성 평가 척도
그렇다면 추정량의 '좋다'의 기준인 정확성 평가는 어떻게 이뤄질까? 추정량이 모수와 근사할수록 좋을 것이다. 이를 위해 정확성 평가는 정량적으로 이뤄지며 일반적으로 크게 3가지 방법을 사용한다. 평균 제곱 오차(MSE), 제곱근 평균 제곱 오차(RMSE), 가능도(Likelihood)이다.
3.1 평균 제곱 오차 (MSE, Mean Squared Error)
오차의 제곱에 대해 평균을 취한 것으로 값이 작을수록 좋다. 식으로는 다음과 같이 나타낸다. 참고로 $\theta$는 $X$로 표기하였다.
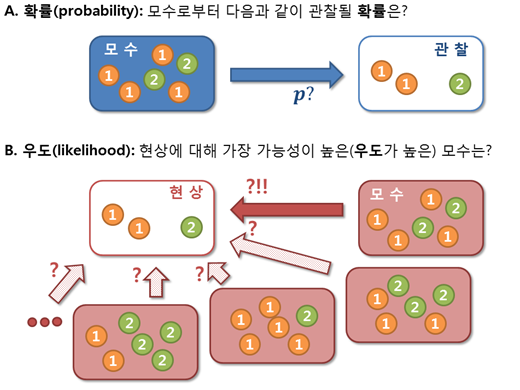
일반적으로 가능도를 이해하기 위해 확률과 비교하며 함께 설명된다. 그 이유는 가능도는 확률의 반대 개념이기 때문이다. 그렇다면 어떻게 반대될까? 이를 잘 나타내는 그림은 다음과 같다. (출처: adioshun)
즉 확률이란 모수를 알고 있는 상태에서 표본이 관찰될 가능성을 의미하는 값이다. 모수를 알고 있다는 것을 다른 말로 확률분포가 결정되어 있는 상태라고 할 수 있다. 반면 가능도는 모수를 모르는 상태(=확률분포를 모르는 상태)에서 관측한 표본이 나타날 가능성에 기반해 모수 추정(확률분포 추정)을 진행한다. 즉, 가능도는 표본을 관측해 이 표본들이 어떤 확률분포를 갖는 모집단에서 추출되었는지를 역으로 찾는 것을 의미한다.
가능도의 필요성에 대한 배경
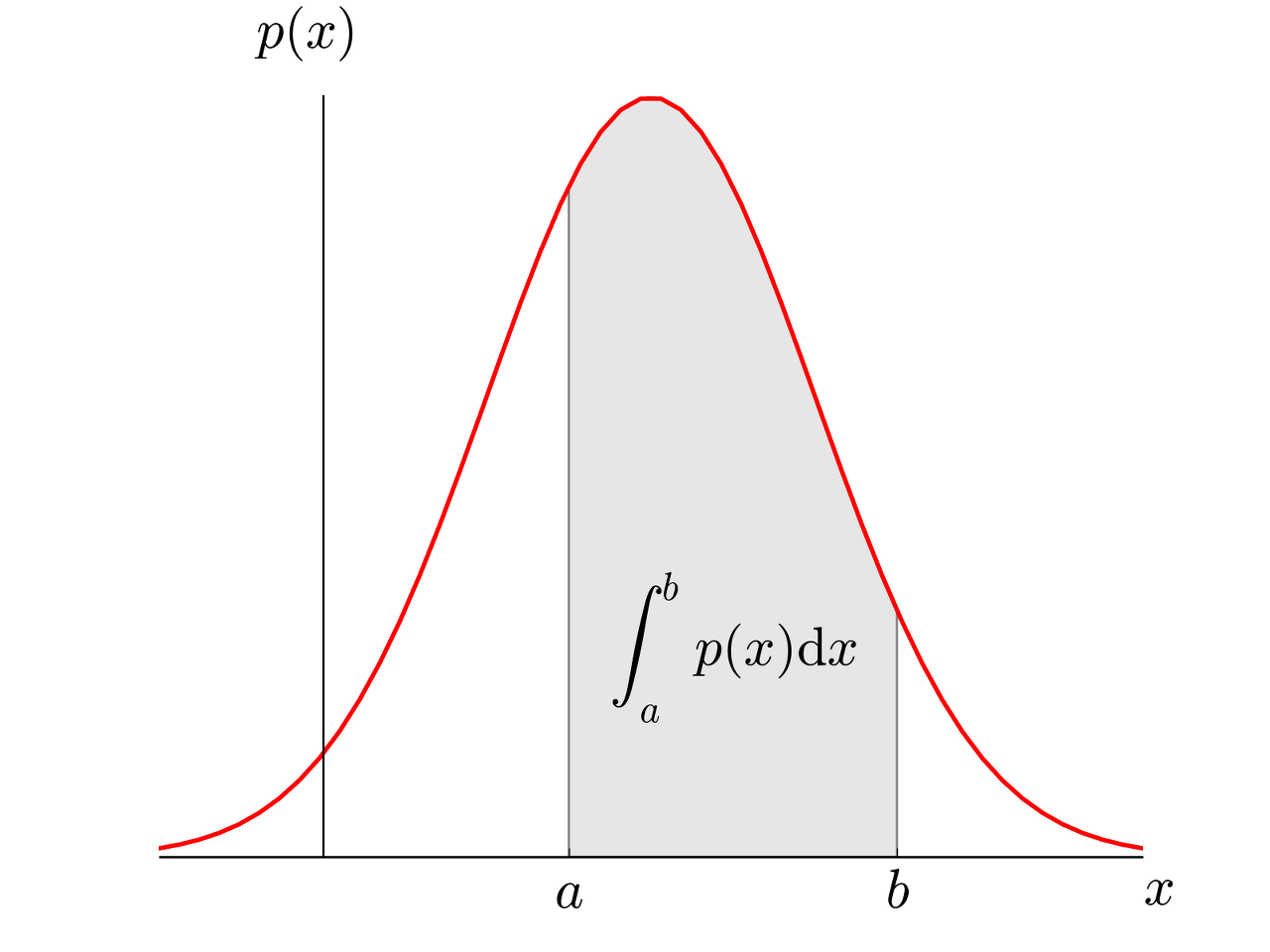
이런 가능도는 왜 필요할까? 왜 만들어졌을까? 그 이유는 확률의 한계 때문이다. 확률은 이산형 확률과 연속형 확률로 나뉜다. 이 때 연속형 확률에서 특정 표본이 관찰될 확률은 전부 0으로 계산되기 때문에 표본이 관찰될 확률을 비교하는 것이 불가능하다. 예를 들어 아래와 같이 연속형 확률을 표현하기 위한 확률 밀도 함수(PDF, Probability Density Function)가 있다 가정하자.
이 때 a와 b사이의 여러 표본들이 추출되어 관측될 수 있는 확률은 a와 b사이의 면적과 같다. 즉 a에서 b까지 적분하면 면적(확률)을 구할 수 있게 된다. 하지만 만약 어떤 특정 하나의 표본이 추출되면 하나의 직선만 되므로 넓이를 계산할 수 없게 된다는 문제점이 있는 것이다. 즉, 특정 관측치에선 확률값이 전부 0이 되어 버리는 것이다. 이러한 한계점을 해결해주는 것이 가능도인 것이다.
가능도에 대한 예시와 특징
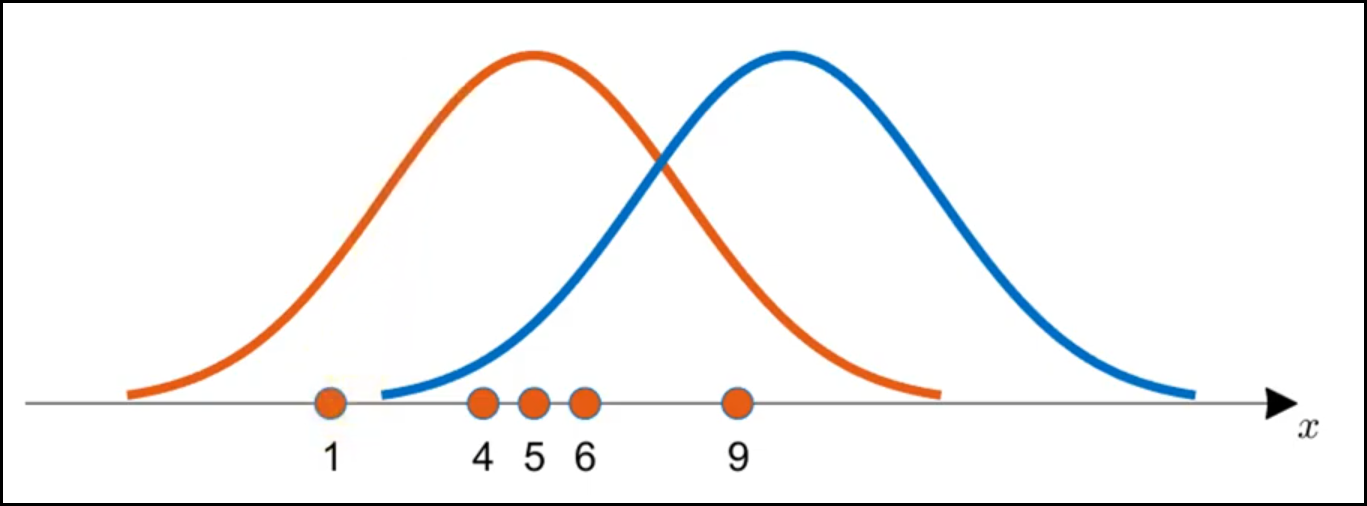
가능도란 한 마디로 추출된 표본으로부터 어떤 분포를 가진 확률밀도함수의 y값을 구해 모두 곱해준 값을 의미한다. 또 다른 의미로 가능도는 관측된 표본이 어떤 분포로부터 나왔을지를 수치로 표현한 것을 말한다. 아래 그림을 살펴보자 (출처: 공돌이의 수학정리노트)
만약 모수로부터 추출된 표본이 [1, 4, 5, 6, 9]가 있고, 모수의 후보인 주황색 확률밀도함수와 파란색 확률밀도함수 중 어떤 것이 더 모수와 가깝다고 추정할 수 있을까? 직관적으로 주황색 확률밀도함수라 할 수 있다. 이를 수치적으로 계산하기 위해서는 각 후보 확률밀도함수를 대상으로 각 표본을 전부 넣고 해당 확률밀도함수의 y값(높이)인 기여도를 구해 모두 곱해준다. 이렇게 기여도를 모두 곱하면 likelihood 값이 된다. 이때 이 likelihood 값이 가장 큰 확률밀도함수가, 모수가 지닌 분포를 따를 가능성이 가장 높다. 또 이런 가장 높은 likelihood 값으로 모수의 확률밀도함수를 추정하는 방법을 최대가능도법(Maximum Likelihood Estimation, MLE)이라 한다. 참고로 주의해야할 것은 가능도 함수는 확률 함수가 아니기 때문에 모두 합해도 1이 되지 않는다. 그 이유는 가능도의 수치적 계산은, 관측값이 나올 수 있는 확률분포를 추정하여 얻은 값을 모두 곱해주기 때문이다.
가능도 함수의 수식적 이해
앞서 설명한대로 가능도는 어느 한 분포에 대하여 표본들의 기여도를 전부 곱해준 값이라 했다. 이러한 가능도를 함수로 표현하면 다음과 같다.
$P(X|\theta) = \prod_{k=1}^nP(x_k|\theta)$
가능도 함수에 사용한 수식 기호는 다음과 같은 의미를 지닌다.
$\theta = \theta_1, \theta_2, \theta_3, \dots, \theta_m$: 어떤 분포를 따른다 가정하는 확률분포함수 집합
$X = x_1, x_2, x_3, \dots, x_n$: 모수에서 추출된 표본의 집합
$p$: 확률밀도함수(기여도, 높이값)
따라서 정리하자면 확률밀도함수에 표본을 넣고 구한 기여도인 $p(x|\theta)$값을 전부 곱해주게 되면 어떤 한 확률밀도함수에 대한 liklihood 값이 된다. 그리고 표본에 대해 이 likelihood 값이 가장 큰 확률밀도함수가 모수를 잘표현한다고 하며 이런 모수를 찾는 것을 최대가능도법이라 한다.
참고로 일반적으로 계산의 용이를 위해 자연 로그를 취해주는 아래의 log likelihood 함수를 사용한다.
$logP(X|\theta) = \sum_{k=1}^nlogP(x_k|\theta)$
4. 추정량 구하는 방법
추정량을 구하는 방법에는 일반적으로 크게 3가지 방법을 사용한다. 최대 가능도 추정법, 적률 방법, 베이즈 추정법이다. 이 세 방법은 모두 점 추정에 속하는 방법들이다.
4.1 최대가능도법 (MLE, Maxmimum Likelihood Estimation)
최대우도추정이라고도 불리는 MLE는 위에서도 설명한 바와 마찬가지로 모수 $\theta$를 추정하는 방법 중 하나이다. 관측치가 주어졌을 때 likelihood 함수 값을 최대화하는 $\theta$를 찾는 것이 목표이다. 이 $\theta$는 어떤 확률밀도함수들을 표현한 것이다. 또 관측치 $X = x_1, x_2, x_3, \dots, x_n$이 있을 때 이들을 수식으로 표현하면 likelihood 함수는 다음과 같은 형태를 가진다.
베이즈 추정은 베이즈 정리를 기반으로 한다. 베이즈 정리는 사전 확률(prior probability)과 사후 확률(posterior probability)의 관계를 나타내는 정리다. 이 베이즈 정리는 조건부 확률을 기반으로 한다. 조건부 확률이란 사건A가 발생했다는 전제하에 사건B가 일어날 확률이다.P(B|A)=P(B∩A)P(A)로 표현한다. 베이즈 정리는 이 조건부 확률에서 유도된 것으로 다음과 같은 수식으로 나타낸다.
위 두 수식은 동일한 것으로 변수명만 달리했다. 그 이유는 이해를 조금 더 쉽게 돕기 위함으로 왼쪽은 조건부 확률로부터 유도될 때 흔히 사용하고, 오른쪽은 베이즈 정리가 결국 모수(θ) 추정을 목적으로 한다는 것을 보이기 위함이다. 수식의 의미를 하나씩 분석해보자면, 먼저 posterior는 새로운 표본 X가 관측됐을 때 어떤 모수값을 갖는지를 의미한다.likelihood는 어떤 표본 X가 관찰되었을 때 어떤 확률분포를 갖는 모집단(모수)에서 추출되었을 확률을 의미한다. prior는 사전확률인 모수값을 의미하며, evidence는 모집단으로부터 표본 X가 관측될 확률이다. 결국 이베이즈 정리를 요약하면 가능도(likelihood), 사전확률(prior), 관측 데이터(evidence)를 이용해 사후 확률(posterior)를 예측하는 방법이다.
간단 용어 정리
추정 (Estimation) : 표본 통계량(표본 평균, 표본 분산 등)에 기초해 모집단의 모수(모 평균, 모 분산 등)를 추정하는 것
추정량 (Estimate) : 모수를 추정하는 통계량. 표본 통계량은 모두 추정량이 될 수 있음. 추정량은 어떤 표본 분포를 띤 확률변수가 됨. 추정량은 관측된 표본에 따라 모수를 추정하는 것으로써 관측 표본 때 마다 값이 달라지는 확률변수임.
주성분 분석은 차원 축소에 사용되는 대표적인 알고리즘이다. 차원 축소는 고차원 공간 데이터를 저차원 공간으로 옮기는 것을 말한다. 그렇다면 이 차원축소가 왜 필요할까? 고차원으로 표현된 데이터는 계산 비용 많고 분석에 필요한 시각화가 어렵기 때문이다. 또 고차원을 이루는 피처 중 상대적으로 중요도가 떨어지는 피처가 존재할 수 있기 때문이다. 따라서 중요도가 낮은 피처를 제외하는 대신 계산 비용이나 비교적 준수한 성능을 얻는다. 주성분 분석을 진행하면 차원 축소로 인해 표현력이 일부 손실된다. 만약 4차원에서 2차원으로 축소를 통해 첫 번째 주성분과 두 번째 주성분을 얻고, 이 두 개가 원래 피처 표현력의 90%를 띤다면 나머지 10%의 손실을 감수하더라도 계산 효율을 얻게 된다.
주성분 분석을 통해 저차원 공간으로 변환할 때 피처 추출(feature extraction)을 진행한다. 이는 기존 피처를 조합해 새로운 피처로 만드는 것을 의미한다. 이 때 새로운 피처와 기존 피처 간 연관성이 없어야 한다. 연관성이 없도록 하기 위해 직교 변환을 수행한다. 직교 변환을 수행하면 새로운 피처 공간과 기존 피처 공간이 90도를 이루게 된다. 즉 내적하면 0이 되는 것이다. 이러한 직교 변환을 수행할 때 기존 피처와 관련 없으면서 원 데이터의 표현력을 '잘' 보존해야 한다. 잘 보존하는 것은 주성분 분석의 핵심인 분산(Variance)을 최대로 하는 주축을 찾는 것이다.
여기서 분산이란? 데이터가 퍼진 정도를 의미한다. 예를 들어 만약 4차원 공간이 있고 3차원 공간으로 차원 축소를 한다면 3차원 공간상에서 데이터 분포가 넓게 퍼지는, 즉 분산을 가장 크게 만드는 벡터를 찾아야 한다. 만약 3차원 공간이 있고 2차원 공간으로 차원 축소한다면, 2차원 공간상에서 데이터 분포가 가장 넓게 퍼지도록 하는 벡터를 찾아야 한다. 만약 2차원 공간이 있고 1차원 공간으로 차원 축소 한다면 1차원 공간상에서 데이터 분포가 가장 넓게 퍼지게 만드는 벡터를 찾아야 한다.
애니메이션으로 이해하자면 다음과 같다.
2차원 공간을 1차원으로 줄일 때 2차원에 넓게 퍼진 데이터 분포를 1차원 상에서도 똑같이 넓게 퍼질 수 있도록 하는 "벡터"를 찾아야 한다. 여기서 "벡터"는 곧 주축을 의미한다. 이 때 주축과의 동의어를 Eigen vector라고 한다. 주축을 찾고 주축에 피처들을 사상시키게 되면 주성분이 된다. 다르게 말해 피처들을 주축에 사상시킬 때 분산이 최대가 되는 주성분이 만들어진다. 이렇게 분산이 가장 큰 주성분을 첫 번째 주성분, 두 번째로 큰 축을 두 번째 주성분이라 한다.
그렇다면 이 주축인 Eigen vector는 어떻게 구하고, Eigen vector에 피처를 어떻게 사상시킬수 있는 것일까? Eigen vector를 구하기 위해서는 특이값 분해 (SVD, Singular Value Decomposition)가 수행된다. 또 사상을 위해서 공분산 행렬이 필요하다. 따라서 사실상 PCA를 한마디로 말하면 데이터들의 공분산 행렬에 대한 특이값 분해(SVD)로 볼 수 있다. 먼저 공분산 행렬에 대해 알아보자.
공분산 행렬이란 무엇일까?
공분산은 한 마디로 두 피처가 함께 변하는 정도, 즉 공변하는 정도를 나타낸다. 수식으로 표현하면 다음과 같다.
$\sum = Cov(X) = {X^TX\over n}$
여기서 n은 행렬 X에 있는 데이터 샘플 개수를 나타내며 $X$란 전체 피처와 데이터 값을 나타낸다. X의 열축은 피처가 되고 X의 행축은 데이터 개수가 된다. 예를 들어 $x_1, x_2, x_3 $ 피처 3개가 있다고 가정하면 $X^T \times T$는 아래와 같이 표현할 수 있다.
이 행렬에서 모든 대각 성분은 같은 피처 간 내적이므로 분산에 해당한다. 대각 성분 이외에는 모두 다른 피처 간 내적이므로 공분산에 해당한다. 즉 이러한 피처 간 내적을 통해 수치적으로 i번 피처와 j번 피처가 공변하는 정도를 알 수 있게 된다. 이것이 수식이 나타내는 의미이다. 수식에서 n으로 나눈 것은 공분산이 커질 수 있으므로 데이터 개수로 나누어 평균을 구한 것이다. 이렇게 만들어진 행렬을 공분산 행렬이라 한다.
공분산 행렬이 가지는 의미는 무엇이고 어떻게 활용할까?
공분산 행렬은 피처 간에 서로 함께 변하는 정도를 의미한다고 했다. 공분산 행렬은 이러한 공변의 의미와 더불어 한 가지 의미가 더 있다. 그 의미는 바로 벡터에 선형 변환(사상)을 가능하게 하는 것이다. 즉, 공간상에 한 벡터가 있을 때 공분산 행렬을 곱해주게 되면 그 벡터의 선형 변환이 이루어진다. 이는 선형대수학에서 행렬이 벡터를 선형 변환시키는 역할을 하기 때문이다. 즉 공분산 행렬엔 피처간 공변 정보가 담겨 있으므로 이를 주축인 Eigen vector에 사상시키면 주성분을 구할 수 있다. 다음으로 주축을 구하기 위한 특이값 분해(SVD)를 살펴보자.
특이값 분해란 무엇이며 이를 통해 어떻게 Eigen vector를 구할 수 있을까?
먼저 특이값 분해란 일종의 행렬에서 이뤄지는 인수 분해다. 정확히는 행렬을 대각화하는 방법 중 하나이다. 대각화하는 이유는 대각화된 행렬의 대각선에 있는 값이 특이값(Singular Value)에 해당하기 때문이다. PCA에서 특이값 분해 대상은 위에서 본 공분산 행렬이다. 공분산 행렬을 특이값 분해 함으로써 PCA에 필요한 주축인 Eigen vector와, Eigen vector 스케일링에 필요한 Eigen value를 얻을 수 있다. Eigen value를 얻은 뒤 내림차순으로 정렬했을 때 가장 첫 번째 값이 분산을 최대로 하는 값이다.
일반적으로 특이값 분해는 고유값 분해(EVD)와 함께 설명된다. 고유값 분해의 경우 m x m의 정방 행렬에서만 사용할 수 있지만, 특이값 분해의 경우 m x n 인 직사각 행렬에도 적용가능하다. 따라서 일반화가 가능하단 장점이 있다. 또 특이값이란 고유값에 루트를 씌운 값이다. 그렇다면 특이값 분해는 어떻게 진행될까? 먼저 실수 공간에서 임의의 m x n 행렬에 대한 특이값 분해는 다음과 같이 정의된다.
$ A = U\sum V^T$
수식 성분이 나타내는 바는 다음과 같다. 참고로 여기서 $\sum$이란 합을 의미하는 기호가 아니라 행렬을 의미한다.
$A = m \times n $ 직사각 행렬 (diagonal matrix)
$U = m \times m $ 직교 행렬 (orthogonal matrix)
$\sum = m \times n$ 직사각 대각행렬 (diagonal matrix)
$V = n \times x $ 직교 행렬 (orthogonal matrix)
특이값 분해를 이해하기 앞서 두 가지 선형대수적 특성을 알아야 한다. 첫 번째는 $U$, $V$가 직교 행렬이라면 선형대수적 특성에 의해 $UU^T = VV^T = E$, $U^{-1} = U^T, V^{-1} = V^T$가 만족한다는 것이다. 여기서 $E$는 항등행렬이다. 여기서 항등행렬이란 가령 $U$에 역행렬인 $U^{-1}$를 곱했을 때 나오는 행렬을 의미한다. 두 번째론 대칭 행렬은 고유값 분해가 가능하며 또 직교행렬로 분해할 수 있다는 것이다. 앞에 보았던 공분산인 행렬 $A$는 대각선으로 기준으로 값들이 대칭을 띠는 대칭 행렬이었다. 그러므로 고유값 분해 또는 직교행렬로 분해할 수 있다. 또 행렬 $A$가 대칭행렬이므로 $A^T$도 대칭 행렬이다.
결과적으로 PCA는 특이값 분해를 통해 $\sum$를 구하고자 한다. 이 $\sum$는 $AA^T, A^TA$를 고유값 분해해서 나오는 고유값들에 루트를 씌운 값들이 대각선에 위치하는 행렬이다. 그리고 $AA^T$와 $A^TA$의 고유값이 같다. 이를 증명하는 하는 과정은 다음과 같다.
앞서 특이값 분해의 정의는 $A = U\sum V^T$라고 했다. 이때 $A$는 대각행렬이므로 고유값 분해가 가능하다.
$AA^T = (U\sum V^T)(U\sum V^T)^T$
$= U\sum V^T V\sum^T U^T$(이 때 $V^TV$ = $V^{-1}V$ 즉 직교행렬이므로 항등 행렬이 되어 사라짐)
$= U(\sum \sum^T)U^T$
즉 $AA^T$를 고유값 분해하면 = $U(\sum \sum^T)U^T$가 된다. 또,
$A^TA = (U\sum V^T)^T(U\sum V^T)$
$= V\sum^T U^TU\sum V^T$(이 때 $U^TU$ = $U^{-1}U$ 즉 직교행렬이므로 항등 행렬이 되어 사라짐)
$= V(\sum ^T\sum)V^T$
즉 $A^TA$를 고유값 분해하면 = $ V(\sum ^T\sum)V^T$가 된다.
그리고 이를 정리하고 덧붙이면,
$U$는 $AA^T$를 고유값 분해 해서 얻은 직교행렬이다. 그리고 U의 열벡터를 A의 leftsingular vector라 부른다.
$V$는 $A^TA$를 고유값 분해 해서 얻은 직교행렬이다. 그리고 V의 열벡터를 A의 right singular vector라 부른다.
$\sum$은 $AA^T, A^TA$를 고유값 분해해서 나온 고유값($\lambda$, eigen value)들의 제곱근을 대각원소로 하는 직사각 대각행렬이다.
이 $\sum$의 대각원소들을 행렬 A의 특이값(singular value)라 부른다. 아래 수식과 같다.
학회: IEEE Conference on Computer Vision and Pattern Recognition
게재: 2016년
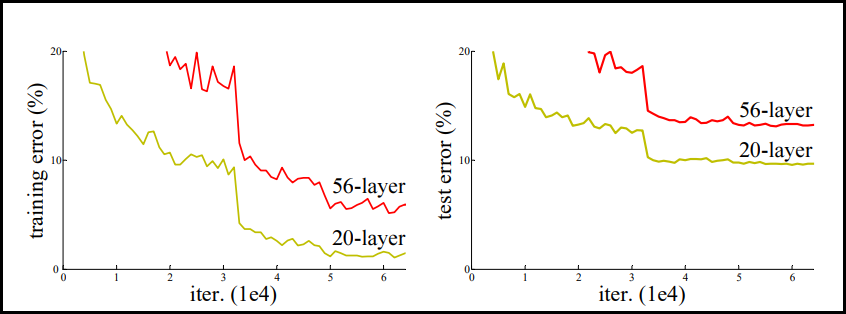
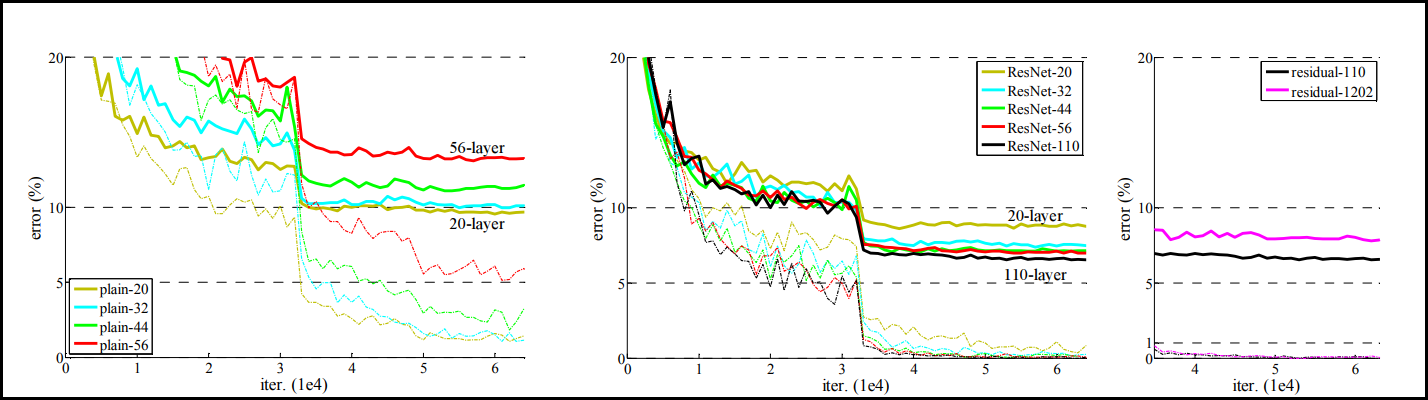
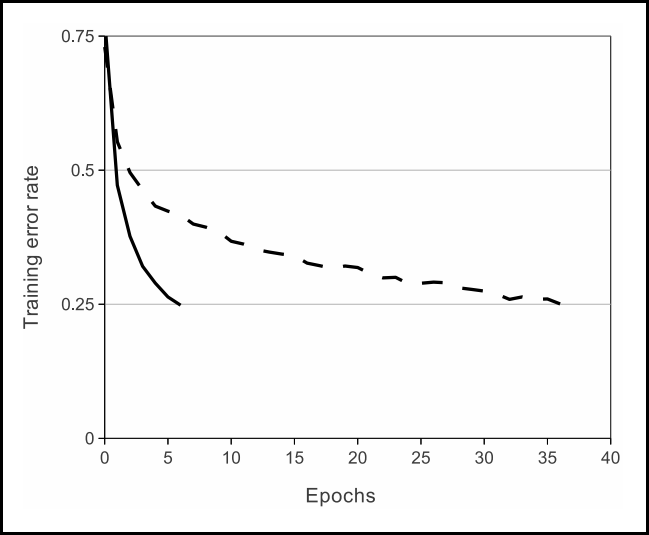
컴퓨터 비전에서 높은 이미지 인식 능력 모델의 발전은 AlexNet → VGGNet → GoogLeNet → ResNet 순으로 이뤄진다. 이러한 높은 인식 능력의 배경에는 네트워크의 깊이를 늘림으로써 high level feature부터 low level feature를 효율적으로 추출할 수 있기 때문이다. 대개 네트워크의 깊이를 늘림으로써 모델의 성능이 늘어난다. 하지만 반드시 그렇지는 않다. 아래 그래프가 이를 뒷받침 한다.
Training error & Test error on CIFAR-10 of "plain" network (no residual network)
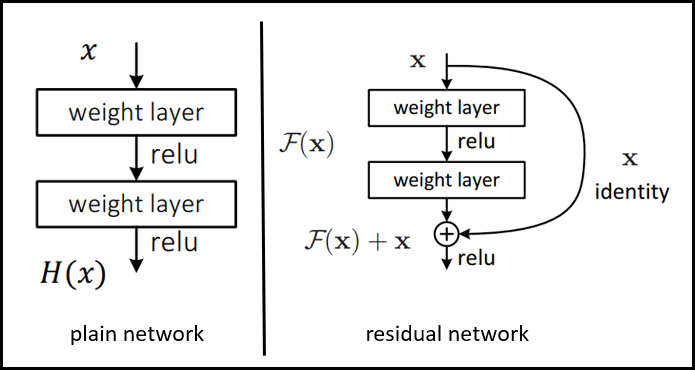
위 그래프를 보면 상대적으로 더 깊은 네트워크가 training error가 더 높다. 즉 성능이 더 낮아진다. 왜 이렇게 낮아질까? 네트워크 깊이를 늘리는 데 있어 한계가 있기 때문이다. 그리고 그 한계란 gradient vanishing 문제를 말한다. 이는 레이어가 깊을수록 역전파를 하는 과정에서 미분 값이 줄어들기 때문에 앞단 레이어는 영향을 거의 받지 못하기 때문이다. 이 문제를 해결하기 위해 ResNet이 만들어졌다. 즉 ResNet은 gradient vanishing 문제를 해결하는 모델인 것이다. 그 핵심 방법은 아래 그림 오른쪽과 같이 residual network를 사용하는 것이다.
residual network는 앞단 레이어의 출력값이 입력으로 들어온 x를 feed forward 한 값에 다시 x를 더해준다. 이게 왜 효과가 있을까? 왼쪽 일반 신경망과의 학습 방식이 다르기 때문이다. 일반 신경망은 입력 $x$를 통해 출력 $H(x)$를 얻는 $H(x) = x$다. 반면 오른쪽 residual network는 $H(x) = F(x) + x$가 된다. 중간에 $F(x)$가 추가된 것이다. 이 때 이 추가된 $F(x)$를 0이 되도록 학습한다면 일반 신경망인 $H(x) = x$와 같아진다. 하지만 이렇게 둘러온다면 하나의 큰 장점이 있다. 일반 신경망처럼 역전파가 진행될 때 $H(x) = x$에서 미분하는 것과 달리 residual network를 이용해 미분하게 되면 $H'(x) = F'(x) + 1$이 된다. 즉 1도 남기 때문에 기울기가 0에 수렴하여 소실되지 않고 역전파가 끝까지 진행될 수 있는 것이다.
이해가 안될 경우를 대비해 조금 더 설명하면, $H(x) = F(x) +x$을 이항하면 $F(x) = H(x) - x$가 된다. 이 때 $F(x)$를 0에 근사하게 만든다면 $H(x) - x$도 0에 근사하게 된다. 다시 이항하면 기존 신경망과 같이 $H(x) = x$의 형태가 된다. 양쪽 모두 역전파로 인해 미분되어 0에 근사하게 되면 기울기 소실 문제가 발생하는 것이다. 참고로 $H(x) - x$을 residual이라 부르며, residual network에선 기존 신경망의 학습 목적인 $H(x)$를 최소화 해주는 것이 아니라 $F(x)$를 최소화 시켜주는 것이다. $F(x) = H(x) - x$이므로.
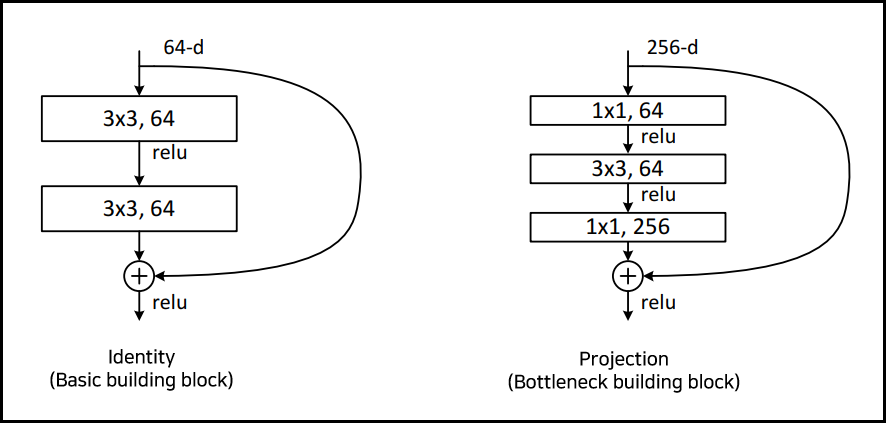
ResNet에서는 residual network를 아래 두 가지 방식을 사용해 구현했다. 첫 번째는 바로 위 그림과 마찬가지로 단순한 구조를 사용하는 Identity 방식과, 두 번째는 1x1 convolution 연산을 통해 차원을 스케일링 해주는 Projection 방식이다.
기존의 Identity 방식에 더해 Projection 방식이 더해진 이유는 입력/출력 차원이 다를 때 스케일링 해주기 위함이다. 또 Projection 방식은 네트워크를 깊게 만들어줄 때 학습 시간을 줄이기 위해 사용하는데, 위 두 구조가 비슷한 시간 복잡도를 갖기 때문이라고 한다.
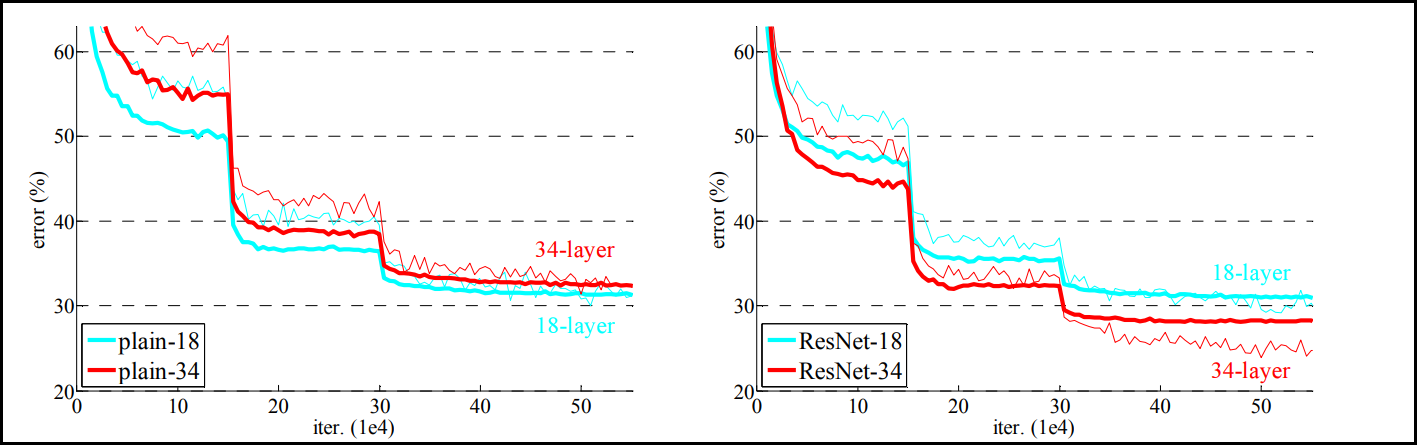
다시 돌아와 이러한 residual network 구조를 사용하는 것이 ResNet 이해의 핵심이다. 이렇게 residual network를 모델 레이어로 쌓으면 다음과 같은 성능 증가를 가져오게 된다.
가는 선: training error / 굵은 선: validation error
좌측의 residual network를 적용하지 않은 plain network를 살펴보면 레이어를 깊게 해줄수록 성능이 오히려 떨어지게 된다. 반면 residual network를 모델에 적용하게 되면 레이어가 깊더라도 error rate가 떨어져 성능이 더 좋아지는 것을 확인할 수 있다.
그렇다면 더욱 더 residual network를 쌓게 되면 어떤 결과가 나올까? 아래를 보자. 참고로 ResNet에서 50개의 layer가 넘어가는 모델들은 Projection 방법 (Bottleneck building block)을 사용하여 만든 모델이다. 반대로 50개 미만은 Identity 방법 (Basic building block)으로 만들었다.
model performance comparison on CIFAR-10 datasets
좌측 residual network를 적용하지 않은 plain network의 경우에는 레이어가 깊어질수록 성능이 계속 떨어지는 것을 볼 수 있다. 반면 가운데 그래프처럼 ResNet을 적용하면 error율이 아닐 때 보다 더 감소한 것을 볼 수 있다. 또한 110개의 네트워크를 쌓더라도 성능이 증가하는 것을 볼 수 있다. 다만 우측 그래프처럼 residual network를 1202개까지 쌓게 되면 오히려 110개를 쌓았을 때 보다 성능이 좋지 않다. 하지만 이를 두고 1202개 가량을 쌓았을 때가 ResNet의 한계라고 해석할 수 없다. 그 이유는 CIFAR-10 데이터셋만으로는 불충분해 overfitting 되었을 가능성이 있기 때문이고, 또 ResNet 논문 저자들은 그 어떤 Dropout과 같은 Regularization을 적용하지 않았다고 말했다. 따라서 강력한 Regularization을 적용한다면 성능 향상의 여지가 있는 것이다.
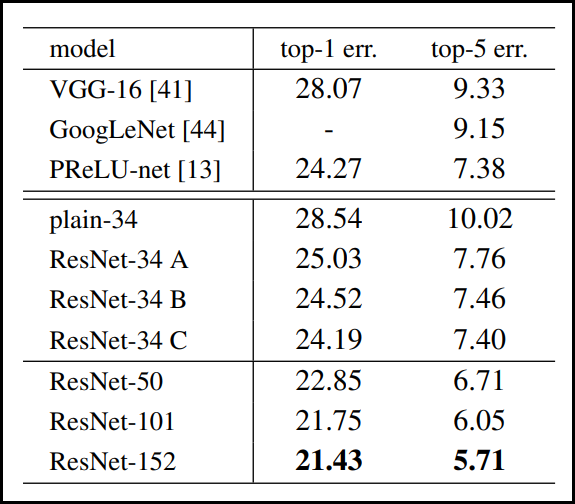
마지막으로, ResNet 모델의 개선 여지가 있음에도 불구하고 아래 표와 같이 이전에 나온 VGGNet과 GoogLeNet 모델보다도 높은 성능을 보였다.
Error rate on ImageNet validation
ResNet을 구현하기 위해 먼저 가장 핵심인 ResNet 모델 아키텍처를 살펴보면 다음과 같다.
하나의 max-pool 레이어와, 하나의 average-pool 레이어를 제외하고 모두 convolution 레이어로 구성되어 있다. 또 18, 34 layer는 레이어 구조상 Basic Building Block을 사용하며 50, 101, 152 layer는 Bottleneck Building Block을 사용한다.
그리고 논문에서 구현에 적용되었던 augmentation 기법과 레이어 특이 사항, 하이퍼파라미터 값을 정리하면 다음과 같다.
1. Augmentation
이미지를 스케일 별 augmentation을 위해 이미지 사이즈를 256~480 범위에서 랜덤 샘플링 진행
논문: Going Deeper with convolutions 게재: 2015년 학회: CVPR
GoogLeNet이란?
GoogLeNet은 한 마디로 네트워크의 depth와 width를 늘리면서도 내부적으로 inception 모듈을 활용해 computational efficiency를 확보한 모델이다. 이전에 나온 VGGNet이 깊은 네트워크로 AlexNet보다 높은 성능을 얻었지만, 반면 파라미터 측면에서 효율적이지 못하다는점을 보완하기 위해 만들어졌다.
CNN 아키텍처와 GoogLeNet
2010년 초/중반 CNN 아키텍처를 활용해 높은 이미지 인식 능력을 선보인 모델은 AlexNet (2012) → VGGNet (2014) → GoogLeNet (2014) → ResNet (2015) → ... 순으로 계보가 이어진다. 이 모델들은 네트워크의 depth와 width를 늘리면서 성능 향상이 이루어지는 것을 보며 점점 depth와 width를 늘려갔다. 하지만 이렇게 네트워크가 커지면서 두 가지 문제점이 발생했다. 첫 번째는 많은 파라미터가 있지만 이를 학습시킬 충분한 데이터가 없다면 오버피팅이 발생하는 것이고, 두 번째는 computational resource는 늘 제한적이기에 비용이 많이 발생하거나 낭비될 수 있다는 점이다. GoogLeNet은 이러한 문제점을 해결하기 위해 fully-connected layer의 neuron 수를 줄이거나 convolution layer의 내부 또한 줄여 상대적으로 sparse한 network를 만들고자 만들어졌다. 결과적으로 GoogLeNet은 가장 초반에 나온 AlexNet보다도 파라미터수가 12배 더 적지만 더 높은 성능을 보이는 것이 특징이다. 결과적으로 GoogLeNet은 ILSVRC 2014에서 classification과 detection 트랙에서 SOTA를 달성했다.
Inception: GoogLeNet 성능의 핵심
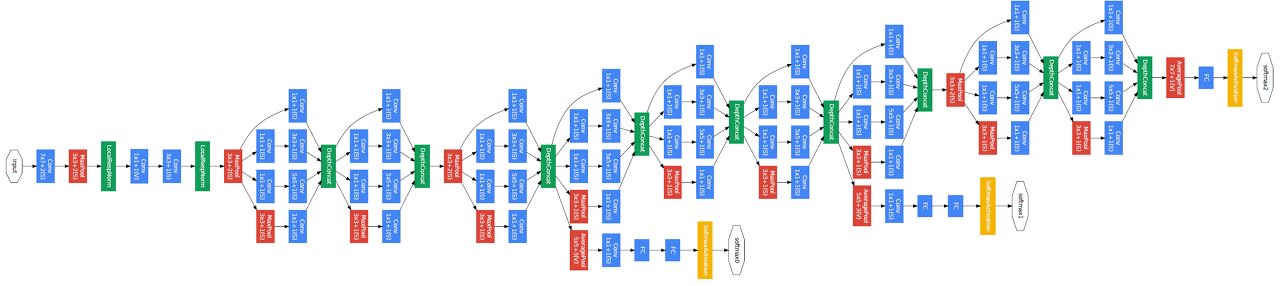
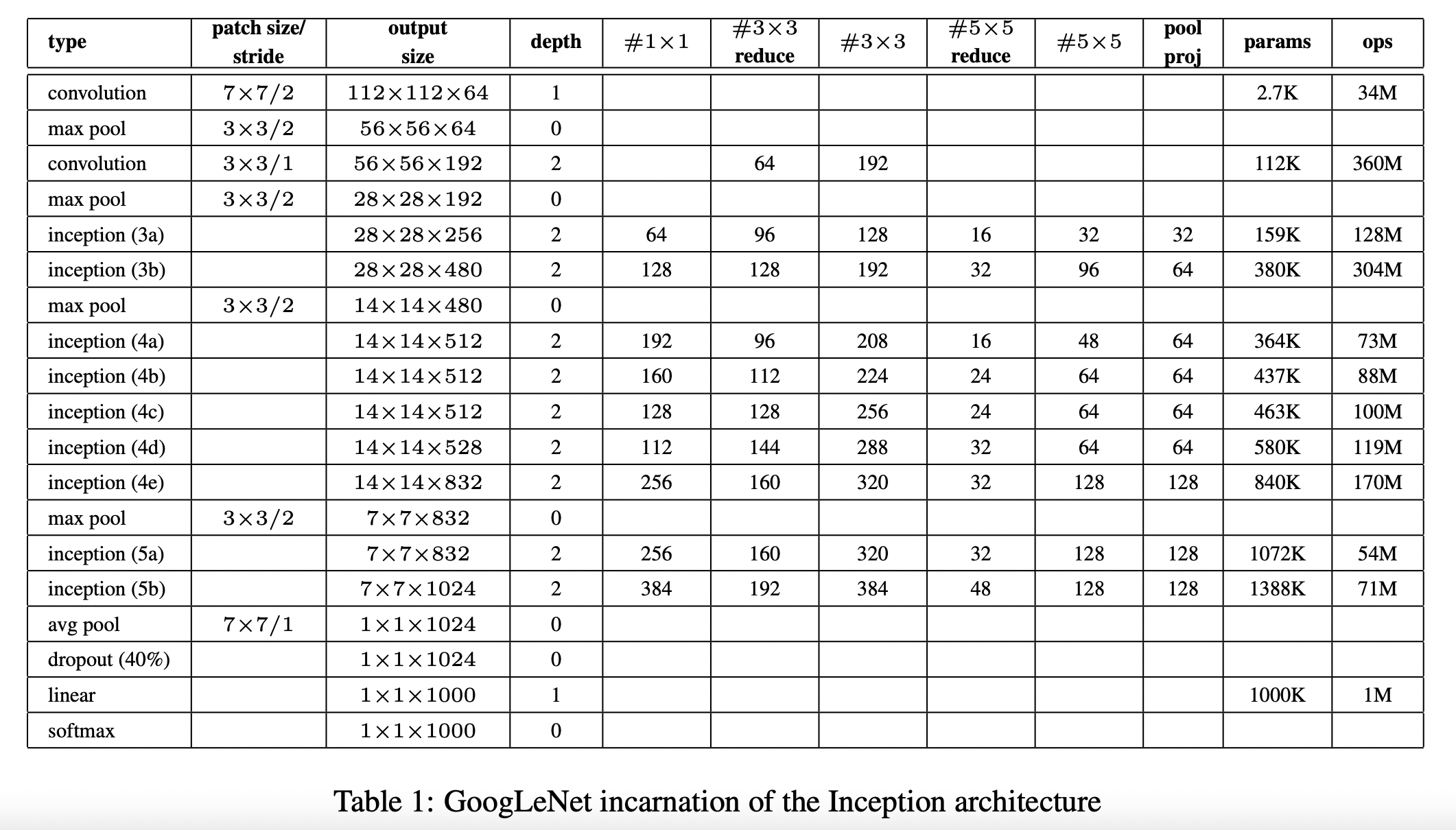
파라미터 효율적이면서도 높은 성능을 낼 수 있는 GoogLeNet 아키텍처의 핵심은 내부 Inception 모듈의 영향이다. Inception 모듈을 보기전 먼저 GoogLeNet 아키텍처를 살펴보면 다음과 같다.
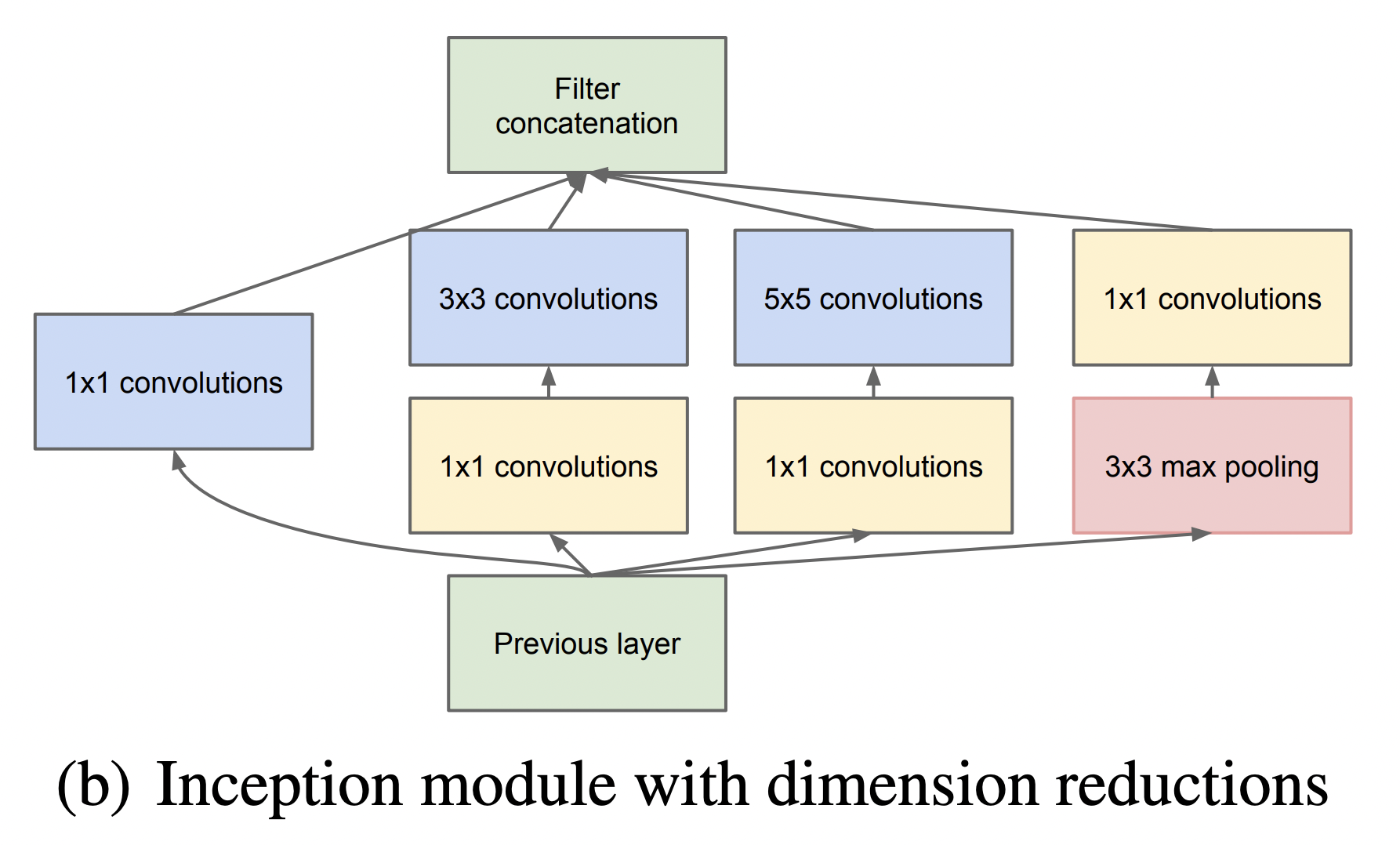
왼쪽(아래)에서 출발하여 오른쪽(위)으로 점점 깊어진다. Inception 모듈은 위 GoogLeNet 네트워크에서 사용되는 부분 네트워크에 해당한다. 그 부분 구조는 아래와 같다. 두 가지 버전이 있다.
두 버전 모두 이미지 feature를 효율적으로 추출하기 위해 공통적으로 1x1, 3x3, 5x5 필터 크기를 갖는 convolution 연산을 수행한다. 이렇게 이미지의 다양한 영역을 볼 수 있도록 서로 다른 크기의 필터를 사용함으로써 앙상블하는 효과를 가져와 모델의 성능이 높아지게 된다. 참고로 필터 크기를 1x1, 3x3, 5x5로 지정한 것은 필요성에 의한 것이기보다 편의성을 기반으로 했다. 만약 짝수 크기의 필터 크기를 갖게 된다면 patch-alignment 문제라고하여 필터 사이즈가 짝수일 때 patch(필터)의 중간을 어디로 두어야 할지 결정해야하기에 번거로워지기 때문이다.
두 버전의 Inception 모듈을 비교해보자면, 먼저 좌측 naive Inception 모듈의 경우 1x1, 3x3, 5x5 convolution 연산과 3x3 max pooling 연산을 병렬 수행한 뒤 concatenation을 통해 결과를 합쳐주는 구조로 되어 있다. 하지만 결과적으로 이는 잘 동작하지 않았다. 그 이유는 convolution 결과와 max pooling 결과를 concatenation하면 기존 보다 차원이 늘어나는 문제점이 발생했기 때문이다. 정확히는 max pooling 연산의 경우 channel 수가 그대로 보존되지만 convolution 연산에 의해 더해진 channel로 인해 computation 부하가 늘어나게 된다. 이 과정을 도식화 한 것은 아래 그림과 같다. (출처: 정의석님 블로그)
위 그림과 같이 output channel의 크기가 증가하여 computation 부하가 커지는 문제점을 해결하기 위해 우측 두 번째 Inception 모듈이 사용된다. 두 번째 Inception 모듈을 통해 output channel을 줄이는 즉 차원을 축소하는 효과를 가져온다. 실제로도 이러한 효과로 인한 computation efficiency 때문에 GoogLeNet 아키텍처에서도 첫 번째 naive Inception 모듈이 아닌 두 번째 dimension reduction Inception 모듈을 사용한다.
그렇다면 두 번째 Inception module에서의 차원축소는 어떻게 이루어질까? 이에 대한 핵심은 1x1 convolution 연산에 있다. 1x1 convolution 연산은 Network in Network (Lin et al) 라는 연구에서 도입된 방법이다. 이름 그대로 1x1 필터를 가지는 convolution 연산을 하는 것이다. 1x1 convolution 연산은 아래 GIF와 같이 동작한다. 그 결과 feature map 크기가 동일하게 유지된다. 하지만 중요한 것은 1x1 filter 개수를 몇 개로 해주느냐에 따라 feature map의 차원의 크기(채널)를 조절할 수 있게 되는 것이다. 따라서 만약 input dimension 보다 1x1 filter 개수를 작게 해준다면 차원축소가 일어나게 되며, 그 결과 핵심적인 정보만 추출할 수 있게 된다.
Global Average Pooling (GAP)
GoogLeNet 아키텍처에선 Global Average Pooling 개념을 도입하여 사용한다. 이는 마찬가지로 Network in Network (Lin et al) 에서 제안된 것으로, 기존 CNN + fully connected layer 구조에서 fully-connected layer를 대체하기 위한 목적이다. 그 이유는 convolution 연산의 결과로 만들어진 feature map을 fully-connected layer에 넣고 최종적으로 분류하는 과정에서 공간 정보가 손실되기 때문이다. 반면 GAP은 feature map의 값의 평균을 구해 직접 softmax 레이어에 입력하는 방식이다. 이렇게 직접 입력하게 되면 공간 정보가 손실되지 않을 뿐만 아니라 fully-connected layer에 의해 파라미터를 최적화 하는 과정이 없기 때문에 효율적이게 된다.
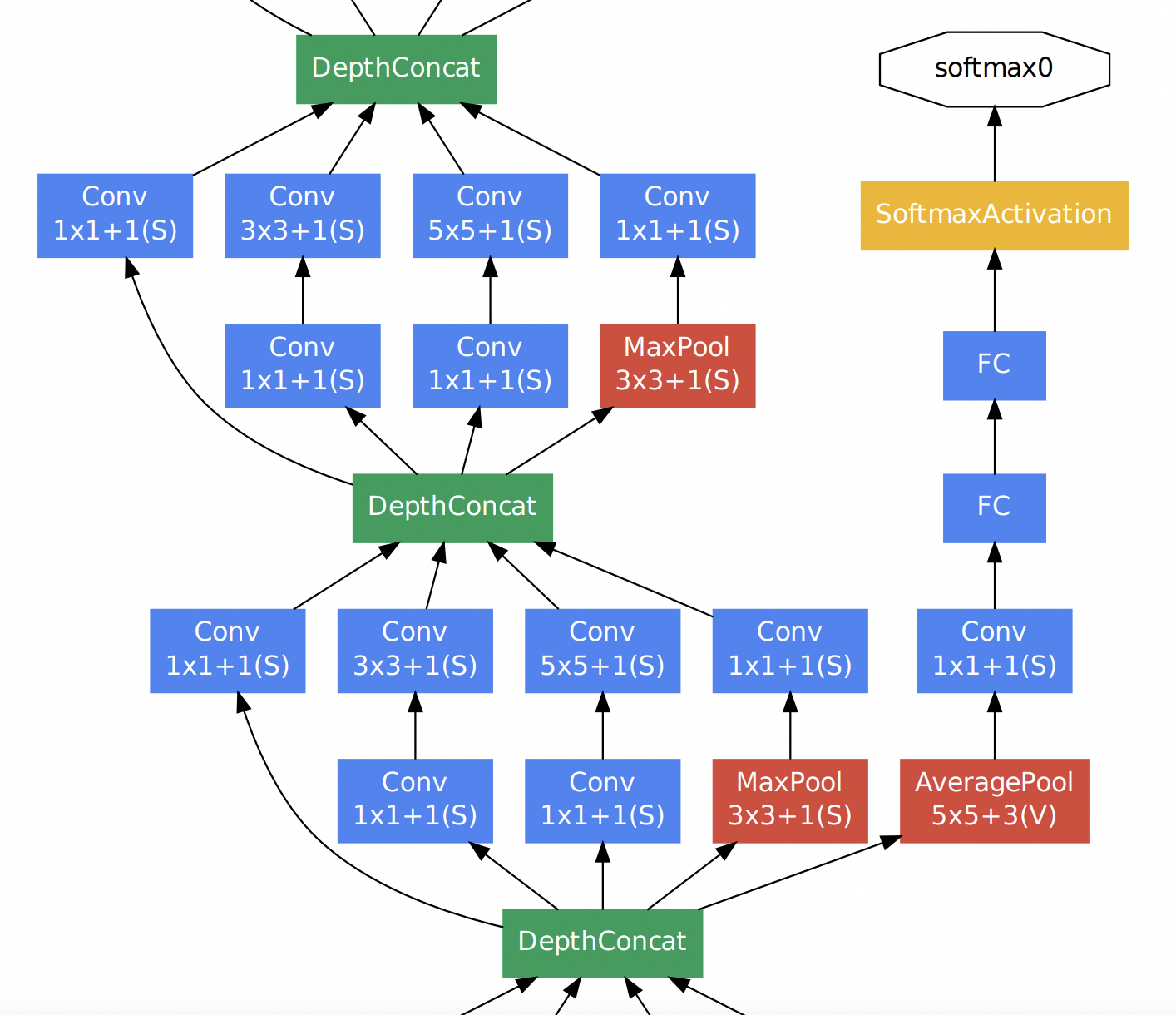
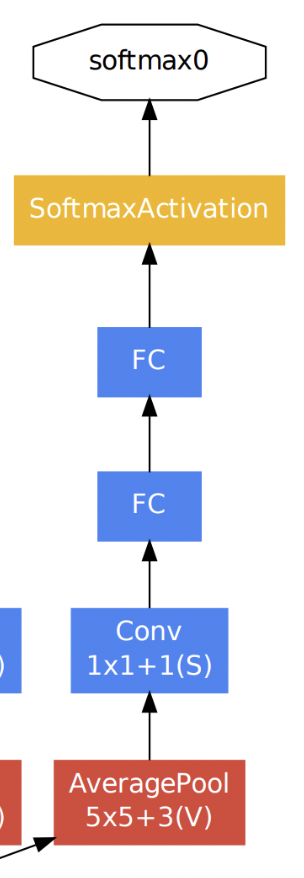
Auxiliary classification
먼저 Auxiliary란 보조를 뜻하는 것으로 Auxiliary classification은 최종 classification 결과를 보조하기 위해 네트워크 중간 중간에 보조적인(Auxiliary) classifier를 두어 중간 결과 값을 추출하는 것이다. 아래 그림은 GoogLeNet 아키텍처를 부분 확대한 것이다. Auxiliary Classification 과정은 이 중 노란 박스 열에 해당한다.
이렇게 Auxiliary classifier를 중간 중간에 두는 이유는 네트워크가 깊어지면서 발생하는 gradient vanishing 문제를 해결하기 위함이다. 즉 네트워크가 깊어지면 loss에 대한 back-propagation이 영향력이 줄어드는 문제를 해결하기 위해 도입된 것이다. 이렇게 함으로써 중간에 있는 Inception layer들도 적절한 가중치 업데이트를 받을 수 있게 된다. 하지만 Inception 모듈 버전이 늘어날수록 Auxiliary classifier를 점점 줄였고 inception v4에서는 완전히 제외했다. 그 이유는 중간 중간에 있는 layer들은 back-propagation을 통해 학습이 적절히 이루어 졌지만 최종 classification layer에서는 학습이 잘 이루어지지 못해 최적의 feature가 뽑히지 않았기 때문이다.
파이토치로 GoogLeNet 구현하기
GoogLeNet 모델의 핵심은 Inception 모듈을 구현하는 것이다. 1. Inception 모듈 구현에 앞서 Inception 모듈에서 반복적으로 사용될 convolution layer를 생성하기 위해 ConvBlock이란 클래스로 다음과 같이 구현해준다. convolution layer 뒤에 batch normalization layer와 relu가 뒤따르는 구조이다.
import torch
import torch.nn as nn
from torch import Tensor
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs) -> None:
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
2. ConvBlock 클래스를 활용하여 Inception module을 구현하기 위한 Inception 클래스를 다음과 같이 구현해준다.
Inception 클래스를 확인하면 내부적으로 4개의 branch 변수를 만든다. 이 4개의 branch라는 변수는 각각 아래 Inception module에서 네 갈래로 분기되는 것을 구현해준 것이다.
Inception 모듈에 들어갈 인자는 다음과 같다. 1x1 convolution의 경우 kernel_size=1, stride= 1, padding=0 3x3 convolution의 경우 kernel_size=3, stride= 1, padding=1 5x5 convolution의 경우 kernel_size=5, stride= 1, pading=2 max-pooling의 경우 kernel_size=3, stride=1, padding=1
kernel_size는 아키텍처에 보이는 그대로와 같고, GoogLeNet에서는 stride를 공통적으로 1로 사용했다. 각각의 padding은 추후 네 개의 branch가 합쳐졌을 때의 크기를 고려하여 맞춰준다.
3. Auxiliary Classifier를 구현하기 위해 아래와 같이 InceptionAux라는 클래스로 구현해주었다. 1x1 convolution의 output channel의 개수는 논문에 기술된 대로 128을 적용해주었으며 dropout rate 또한 논문에 기술된 대로 0.7을 적용해주었다.
import torch
import torch.nn as nn
from torch import Tensor
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
super(InceptionAux, self).__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = ConvBlock(in_channels, 128, kernel_size=1, stride=1, padding=0)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=0.7)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.avgpool(x)
x = self.conv(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
InceptionAux 클래스는 아래와 그림과 같이 Auxiliary Classification 과정을 구현해 준 것이다.
4. ConvBlock, Inception, InceptionAux를 활용하여 GoogLeNet을 다음과 같이 구현할 수 있다.
import torch
import torch.nn as nn
from torch import Tensor
class GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=1000) -> None:
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
self.conv1 = ConvBlock(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.conv2 = ConvBlock(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0)
self.conv3 = ConvBlock(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(kernel_size=8, stride=1)
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = None
self.aux2 = None
def transform_input(self, x: Tensor) -> Tensor:
x_R = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_G = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_B = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat([x_R, x_G, x_B], 1)
return x
def forward(self, x: Tensor) -> Tensor:
x = self.transform_input(x)
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool3(x)
x = self.a4(x)
aux1: Optional[Tensor] = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
aux2: Optional[Tensor] = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.e4(x)
x = self.maxpool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1) # x = x.reshape(x.shape[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return aux1, aux2
else:
return x
Inception 모듈에 들어갈 모델 구성은 Table 1의 GoogLeNet 아키텍처를 참고하였다.
전체 코드는 다음과 같이 구현할 수 있다.
import torch
import torch.nn as nn
from torch import Tensor
from typing import Optional
class Inception(nn.Module):
def __init__(self, in_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj) -> None:
super(Inception, self).__init__()
self.branch1 = ConvBlock(in_channels, n1x1, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
ConvBlock(in_channels, n3x3_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n3x3_reduce, n3x3, kernel_size=3, stride=1, padding=1))
self.branch3 = nn.Sequential(
ConvBlock(in_channels, n5x5_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n5x5_reduce, n5x5, kernel_size=5, stride=1, padding=2))
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
ConvBlock(in_channels, pool_proj, kernel_size=1, stride=1, padding=0))
def forward(self, x: Tensor) -> Tensor:
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)
class GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=1000) -> None:
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
self.conv1 = ConvBlock(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.conv2 = ConvBlock(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0)
self.conv3 = ConvBlock(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = None
self.aux2 = None
def transform_input(self, x: Tensor) -> Tensor:
x_R = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_G = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_B = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat([x_R, x_G, x_B], 1)
return x
def forward(self, x: Tensor) -> Tensor:
x = self.transform_input(x)
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool3(x)
x = self.a4(x)
aux1: Optional[Tensor] = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
aux2: Optional[Tensor] = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.e4(x)
x = self.maxpool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1) # x = x.reshape(x.shape[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return aux1, aux2
else:
return x
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs) -> None:
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
super(InceptionAux, self).__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = ConvBlock(in_channels, 128, kernel_size=1, stride=1, padding=0)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=0.7)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.avgpool(x)
x = self.conv(x)
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
model = GoogLeNet(aux_logits=True, num_classes=1000)
print (model(x)[1].shape)
위 코드에서 Auxiliary Classifier의 입력 차원 같은 경우는 논문에서 기술된 대로 512, 528을 적용해주었고, fully-connected layer 또한 1024개의 unit으로 설정해주었다.
만약 GoogLeNet으로 간단한 학습을 진행해보고자 할 때 다음과 같이 코드 구현이 가능하다. 다만 CIFAR10 데이터셋을 예시로 사용하므로 위 코드에서 num_classes=10로 바꿔줘야 한다.
제목: Very Deep Convolutional Networks For Large-Scale Image Recognition
게재: 2015년
학회: ICLR (International Conference on Learning Representations)
이 글에서는 크게 두 개의 파트로, 첫 번째론 VGGNet 논문의 연구를 설명하고, 두 번째로 VGGNet 모델을 구현한다.
개요
VGGNet은 2014년 ILSVRC에서 localisation과 classification 트랙에서 각각 1위와 2위를 달성한 모델이다. 이 모델이 가지는 의미는 2012년 혁신적이라 평가받던 AlexNet보다도 높은 성능을 갖는다는 점에서 의미가 있다. 실제로 아래 벤치마크 결과를 확인해보면 맨 아래에 있는 Krizhevsky et al. (Alexnet) 보다도 성능이 월등히 좋은 것을 확인할 수 있다.
2010년 초/중반에는 위 성능 비교표가 나타내는 것처럼 Convolutional network를 사용한 모델의 성능이 점점 높아졌다. 이러한 성능 증가의 배경에는 ImageNet과 같은 large scale 데이터를 활용가능 했기 때문이고 high performance를 보여주는 GPU를 사용했다는 점이다.
2012년 AlexNet이 나온 이후에는 AlexNet을 개선하려는 시도들이 많았다. 더 작은 stride를 사용하거나 receptive window size를 사용하는 등 다양한 시도들이 있었다. VGGNet은 그 중에서 네트워크의 깊이 관점으로 성능을 올린 결과물이라 할 수 있다.
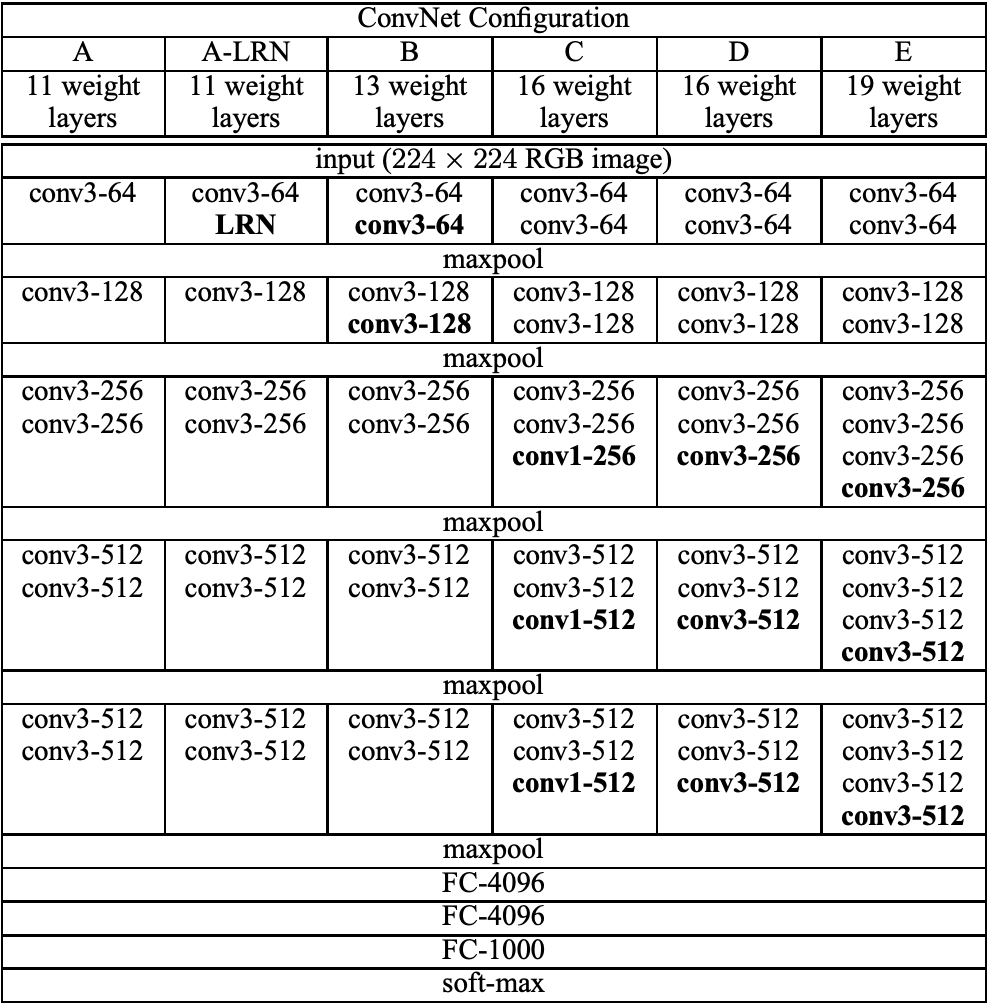
VGGNet을 만들기 위해 사용했던 아키텍처를 살펴보면 아래와 같다. 모든 모델 공통적으로 convolutional layer이후 fully-connected layer가 뒤 따르는 구조이다. 모델 이름은 A, A-LRN, B, C, D, E로 지정했으며 이 중 VGG라 불리는 것은 D와 E이다. 참고로 간결성을 위해 ReLU 함수는 아래 표에 추가하지 않았다.
표 1. Convolutional Network Configuration
이 논문에선 실험을 위해네트워크의 깊이를 늘려가면서도 동시에 receptive field를 3x3과 1x1로 설정했다. receptive field는 컨볼루션 필터가 한 번에 보는 영역의 크기를 의미한다. AlexNet은 receptive field가 11x11의 크기지만 VGGNet은 3x3으로 설정함으로써 파라미터 수를 줄이는 효과를 가져왔고 그 결과 성능이 증가했다. 실제로 3x3이 두 개가 있으면 5x5가 되고 3개를 쌓으면 7x7이 된다. 이 때 5x5 1개를 쓰는 것 보다 3x3 2개를 써서 layer를 더 깊이할 수록 비선형성이 증가하기에 더 유용한 feature를 추출할 수 있기에 위 아키텍처에서는 receptive field가 작은 convolution layer를 여러 개를 쌓았다. 참고로 receptive field를 1x1로 설정함으로써 컨볼루션 연산 후에도 이미지 공간 정보를 보존하는 효과를 가져왔다고 한다.
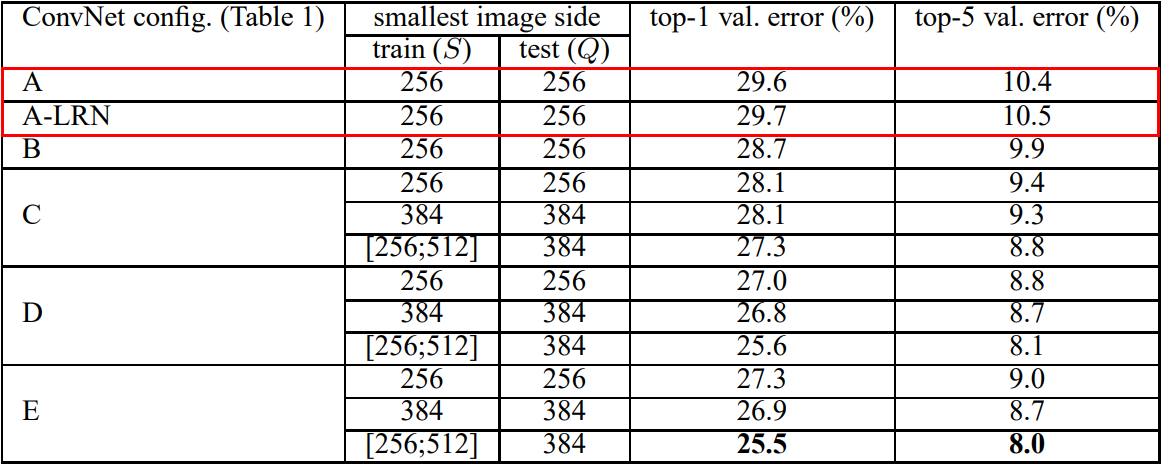
위 표 1에서 확인할 수 있는 A-LRN 모델을 통해서 보인 것은 AlexNet에서 도입한 LRN(Local Response Network)이 사실상 성능 증가에 도움되지 않고 오히려 메모리 점유율과 계산 복잡도만 더해진다는 것이다. 아래 표를 통해 LRN의 무용성을 확인할 수 있다. 또한 표 1에서 네트워크 깊이가 가장 깊은 모델 E (VGGNet)가 가장 좋은 성능을 보이는 것을 확인할 수 있다.
표 3. single test scale에서의 ConvNet 성능 비교
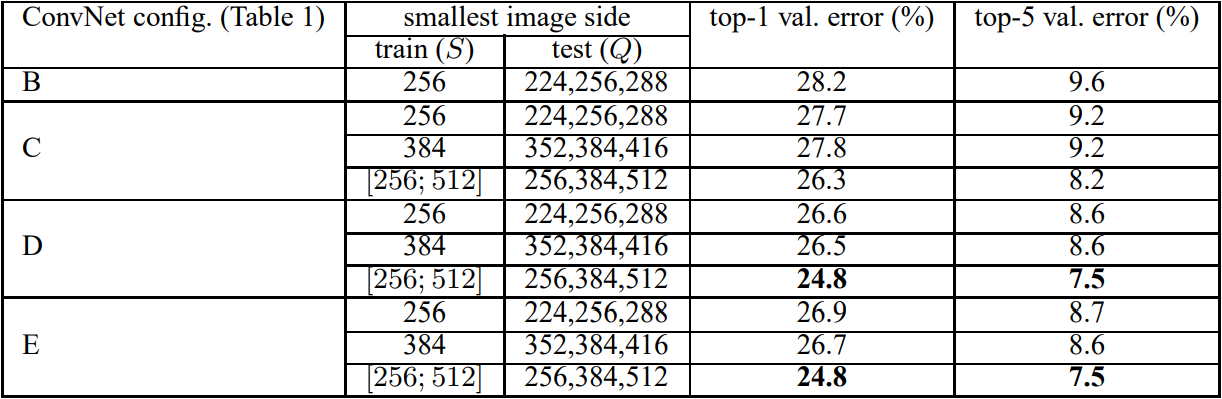
참고로, S, Q는 각각 train과 test에 사용한 이미지 사이즈 크기를 의미한다. 이를 기술한 이유는 scale jittering이라는 이미지 어그멘테이션 기법을 적용했을 때 성능이 더 높아진다는 것을 보인 것이다. 이 논문에선 scale jittering에 따라 달라지는 성능을 비교하기 위해 single-scale training과 multi-scale training으로 나누어 진행했다. single-scale training이란 이미지의 크기를 고정하는 것이다. 가령 train 때 256 또는 384로 진행하면 test때도 각각 256 또는 384로 추론을 진행하는 것이다. 반면 multi-scale training의 경우 S를 256 ~ 512에서 랜덤으로 크기가 정해지는 것이다. 이미지 크기의 다양성 때문에 모델이 조금더 robustness해지며 정확도가 높아지는 효과가 있다. 아래 표 4는 multi-scale training을 적용했을 때의 성능 결과이다.
표 4. multi test scale에서의 ConvNet 성능 비교
single-scale training에 비해 성능이 더욱 증가한 것을 알 수 있다. 추가적으로 S를 고정 크기의 이미지로 사용했을 경우보다 S를 256 ~ 512사이의 랜덤 크기의 이미지를 사용했을 때 더욱 성능이 높아지는 것을 확인할 수 있다.
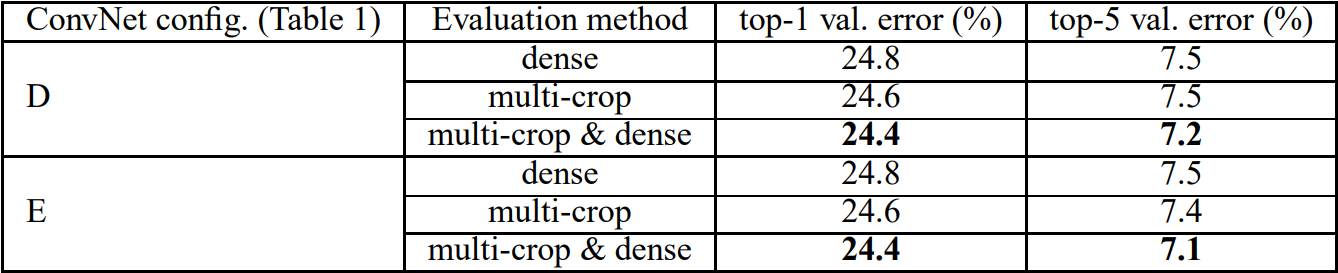
또한 이 논문에서는 모델의 성능을 높이기 위해 evaluation technique으로 multi-crop을 진행했다. dense와 multi-crop을 동시에 사용하는 것이 더 높은 성능을 보이는 것을 확인할 수 있다.
표 5. ConvNet evaluation 테크닉 비교
마지막으로 여지껏 개별 ConvNet 모델에 대해 성능을 평가했다면 앙상블을 통해 여러 개의 모델의 출력을 결합하고 평균을 냈다. 결론적으로 D, E 두 모델의 앙상블을 사용해 오류율을 6.8%까지 현저히 줄이는 것을 보였다.
표 6. Multiple ConvNet fusion 결과
여기까지가 VGGNet 논문에 대한 내용이다. 다음은 VGGNet 논문 구현에 관한 것이다. 이 논문을 읽으며 구현해야 할 목록을 정리해본 것은 다음과 같다.
1. Model configuration.
Convolution Filter
3x3 receptive field
좌/우/상/하를 모두를 포착할 수 있는 가장 작은 사이즈
1x1 convolution filter 사용
spacial information 보존을 위함
Convolution Stride
1로 고정
Max-Pooling Layer
kernel size: 2x2
stride: 2
5개의 max-pooling 레이어에 의해 수행됨. 대부분 max-pooling은 conv layer와 함께하지만 그렇지 않은 것도 있음
Fully-Connected Layer
convolutional layer 스택 뒤에 3개의 FC layer가 따라 옴
앞의 2개는 4096 채널을 각각 가지고 마지막은 1000개를 가지면서 소프트맥스 레이어가 사용됨
Local Response Normalization
Local Response Normalization 사용 X: LRN Layer가 성능 개선X이면서 메모리 점유율과 계산 복잡도만 높아짐
2. Initialization
잘못된 초기화는 deep network에서 gradient 불안정성으로 학습 지연시킬 수 있기에 중요함
weight sampling: 평균 0, 분산이 $10^{-2}$ variance인 정규분포 사용
bias: 0로 초기화
3. Augmentation
random crop:고정된 224x224 입력 이미지를 얻기 위함
horizontal flip
random RGB color shift
고정 사이즈 224x224 RGB image를 사용했고, 각 픽셀에 대해 RGB value의 mean을 빼주는 것이 유일한 전처리(?)
4. Hyper-parameter
optimizer: SGD
momentum: 0.9
weight decay: L2 $5\cdot 10^{-4} = 0.0005$
batch size: 256
learning rate: 0.1
validation set 정확도가 증가하지 않을 때 10을 나눔
학습은 370K iteration (74 epochs)에서 멈춤
dropout: 0.5
1, 2번째 FC layer에 추가
이를 바탕으로 VGGNet에 대한 코드를 구현하면 다음과 같다. 크게 1. 모델 레이어 구성 2. 가중치 초기화 3. 하이퍼파라미터 설정 4. 데이터 로딩 5. 전처리 6. 학습으로 구성된다 볼 수 있다.
적용 배경은 모델의 일반화를 돕는 것을 확인 (top-1, top-2 error율을 각각 1.4%, 1.2% 감소)
Activation Function
ReLU를 모든 convolution layer와 fully-connected에 적용
적용 배경은 아래 그래프처럼 실선인 ReLU가 점선인 tanH보다 빠르게 학습했음
2. 하이퍼 파라미터
optimizer: SGD
momentum: 0.9
weight decay: 5e-4
batch size: 128
learning rate: 0.01
adjust learning rate: validation error가 현재 lr로 더 이상 개선 안되면 lr을 10으로 나눠줌. 0.01을 lr 초기 값으로 총 3번 줄어듦
epoch: 90
그리고 별도로 레이어에 가중치 초기화를 진행 해줌
편차를 0.01로 하는 zero-mean 가우시안 정규 분포를 모든 레이어의 weight를 초기화
neuron bias: 2, 4, 5번째 convolution 레이어와 fully-connected 레이어에 상수 1로 적용하고 이외 레이어는 0을 적용.
def _init_bias(self):
for layer in self.layers:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01)
nn.init.constant_(layer.bias, 0)
nn.init.constant_(self.layers[4].bias, 1)
nn.init.constant_(self.layers[10].bias, 1)
nn.init.constant_(self.layers[12].bias, 1)
nn.init.constant_(self.classifier[1].bias, 1)
nn.init.constant_(self.classifier[4].bias, 1)
nn.init.constant_(self.classifier[6].bias, 1)
참고로 헷갈렸던 것은 위 nn.init.constant_(layer.bias, 0)에서의 0은 bool로 편향 존재 여부를 나타내는 것이지 bias를 0으로 설정하는 것이 아니다.
3. 이미지 전처리
고화질 이미지를 256x256 사이즈로 다운 샘플링후 이미지의 center에서 cropped out
각 픽셀에서 training set에 대한 평균 값을 빼줌
이를 바탕으로 전체 코드를 구현하면 아래와 같다. 크게 나누어 보자면 5가지 정도가 될 수 있다.
1. 레이어 구성 2. 가중치 초기화 3. 하이퍼파라미터 설정 4. 이미지 전처리 5. 학습 로직 작성이다. 참고로 이미지 전처리에 사용하는 transform 메서드에서 사용되는 상수 값은 별도로 논문에 기재되어 있지 않기에 pytorch 공식 documentation에서 기본 값을 가져와서 사용했다.
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils import data
import logging
from glob import glob
logging.basicConfig(level=logging.INFO)
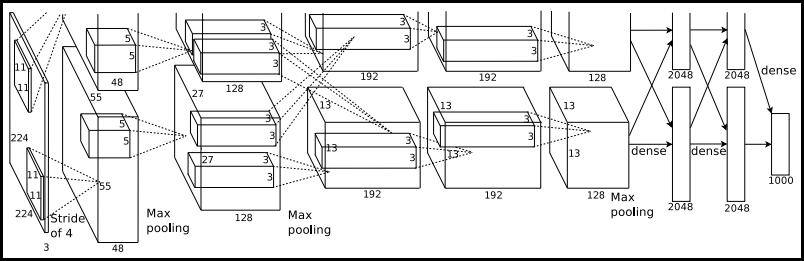
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.num_classes = num_classes
print (f"[*] Num of Classes: {self.num_classes}")
self.layers = nn.Sequential(
nn.Conv2d(kernel_size=11, in_channels=3, out_channels=96, stride=4, padding=0),
nn.ReLU(), # inplace=True mean it will modify input. effect of this action is reducing memory usage. but it removes input.
nn.LocalResponseNorm(alpha=1e-3, beta=0.75, k=2, size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(kernel_size=5, in_channels=96, out_channels=256, padding=2, stride=1),
nn.ReLU(),
nn.LocalResponseNorm(alpha=1e-3, beta=0.75, k=2, size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(kernel_size=3, in_channels=256, out_channels=384, padding=1, stride=1),
nn.ReLU(),
nn.Conv2d(kernel_size=3, in_channels=384, out_channels=384, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(kernel_size=3, in_channels=384, out_channels=256, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2))
self.avgpool = nn.AvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=256, out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=self.num_classes))
self._init_bias()
def _init_bias(self):
for layer in self.layers:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01)
nn.init.constant_(layer.bias, 0)
nn.init.constant_(self.layers[4].bias, 1)
nn.init.constant_(self.layers[10].bias, 1)
nn.init.constant_(self.layers[12].bias, 1)
nn.init.constant_(self.classifier[1].bias, 1)
nn.init.constant_(self.classifier[4].bias, 1)
nn.init.constant_(self.classifier[6].bias, 1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.layers(x)
x = self.avgpool(x)
x = torch.flatten(x, 1) # 1차원화
x = self.classifier(x)
return x
if __name__ == "__main__":
seed = torch.initial_seed()
print (f'[*] Seed : {seed}')
NUM_EPOCHS = 1000 # 90
BATCH_SIZE = 128
NUM_CLASSES = 1000
LEARNING_RATE = 0.01
IMAGE_SIZE = 227
TRAIN_IMG_DIR = "C:/github/paper-implementation/data/ILSVRC2012_img_train/"
#VALID_IMG_DIR = "<INPUT VALID IMAGE DIR>"
CHECKPOINT_PATH = "./checkpoint/"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print (f'[*] Device : {device}')
alexnet = AlexNet(num_classes=NUM_CLASSES).cuda()
checkpoints = glob(CHECKPOINT_PATH+'*.pth') # Is there a checkpoint file?
if checkpoints:
checkpoint = torch.load(checkpoints[-1])
alexnet.load_state_dict(checkpoint['model'])
#alexnet = torch.nn.parallel.DataParallel(alexnet, device_ids=[0,]) # for distributed training using multi-gpu
transform = transforms.Compose(
[transforms.CenterCrop(IMAGE_SIZE),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
train_dataset = datasets.ImageFolder(TRAIN_IMG_DIR, transform=transform)
print ('[*] Dataset Created')
train_dataloader = data.DataLoader(
train_dataset,
shuffle=True,
pin_memory=False, # more training speed but more memory
num_workers=8,
drop_last=True,
batch_size=BATCH_SIZE
)
print ('[*] DataLoader Created')
optimizer = torch.optim.SGD(momentum=0.9, weight_decay=5e-4, params=alexnet.parameters(), lr=LEARNING_RATE) # SGD used in original paper
print ('[*] Optimizer Created')
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer, factor=0.1, verbose=True, patience=4) # used if valid error doesn't improve.
print ('[*] Learning Scheduler Created')
steps = 1
for epoch in range(50, NUM_EPOCHS):
logging.info(f" training on epoch {epoch}...")
for batch_idx, (images, classes) in enumerate(train_dataloader):
images, classes = images.cuda(), classes.cuda()
output = alexnet(images)
loss = F.cross_entropy(input=output, target=classes)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if steps % 50 == 0:
with torch.no_grad():
_, preds = torch.max(output, 1)
accuracy = torch.sum(preds == classes)
print ('[*] Epoch: {} \tStep: {}\tLoss: {:.4f} \tAccuracy: {}'.format(epoch+1, steps, loss.item(), accuracy.item() / BATCH_SIZE))
steps = steps + 1
lr_scheduler.step(metrics=loss)
if epoch % 5 == 0:
checkpoint_path = os.path.join(CHECKPOINT_PATH, "model_{}.pth".format(epoch))
state = {
'epoch': epoch,
'optimizer': optimizer.state_dict(),
'model': alexnet.state_dict(),
'seed': seed
}
torch.save(state, checkpoint_path)
AlexNet의 경우 비교적 구현이 어렵지 않은 편이기에 논문 구현을 연습하기에 좋다고 느낀다.
이 논문에서 문제점으로 삼고 있는 것은 dialouge management(이하 DM)을 scalable하고 robust하게 만드는 것이 어렵다는 것임. 그리고 이 논문의 저자가 말하고자 하는 것은 DM을 디자인 관점에서 연구자들에게 향후 연구 방향을 알려주고자 함.
1. Introduction
Conversational System은 크게 두 분류로 나뉨 1. task-oriented system 2. non-task-oriented system 여기서 non-task-oriented는 단순 대화 같이 별도 행위가 필요하지 않은 시스템이고 task-oriented는 예매와 같은 구체적인 태스크를 수행하는 시스템임. 이 논문에선 task-oriented 시스템을 다룸. DM에는 다양한 접근법이 있고, 각각 장단점이 있음.
2. Problem fundamentals and dimensions
A. Dialouge Management
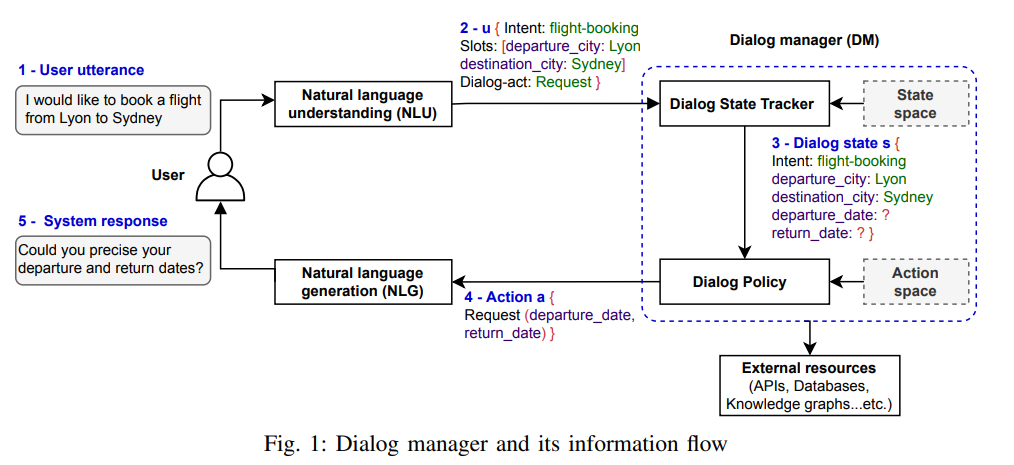
위 그림은 DM의 전체적인 플로우임. DM은 크게 위 아키텍처를 벗어나지 않고 거의 정석으로 사용됨. NLU가 가장 처음으로 유저 발화 정보를 추출함. 크게 3가지로 Intent, entity, dialouge act를 가져옴. 즉 어떤 의도로 말했고, 어떤 것을 말했고, 어떤 행위를 요구하는지를 파악하기 위함임.
intent는 goal/task와 거의 동의어로 사용됨
entity는 slot과 동의어로 봐도 됨. 위 그림 1을 예로 들자면 departure_city나 destination_city가 entity가 됨.
dialouge act는 유저가 단순 서술인지, 질문인지, 요청인지 파악하기 위해 사용됨
그리고 이 모든 정보는 Dialouge State Tracking(이하 DST)에게 전달함. 그리고 DST는 NLU에서 받은 구조적 representation을 저장해둠. 어떻게 대답할지 결정하기 위해. 다른 말로 표현하면 Dialouge State(이하 DS) 유지를 위해 명시적이거나 암시적인 정보까지 전부 저장해둠
그리고 DS에 기반해서 다음 행동은 Dialogue Policy(이하 DP)가 결정함. DP는 일종의 함수로 봐도 됨. DS에 기반해서 행동(Dialouge Act)을 매핑시켜주기 때문에. (일종의 if else와 같이 룰 베이스 형식인듯. NLU에서 처리한 Dialouge Act를 DP에서 받아서 실행시켜주는 방식인듯). 예를 들면 flight-booking이라는 domain에선 action이 크게 4가지로 제한됨. Request, Confirm, Query, Execute. 만약 Request라면 출발 시간과 도착 시간을 물어봐야하고, Confirm이라면 도착 위치가 여기가 맞는지 물어봐야하고, Query라면 항공편 리스트를 가져와야하고, Execute라면 예약 신청해야 함. 이러한 DP 동작의 결과를 NLG가 적절한 응답으로 생성함.
DM 시스템은 이렇게 동작하지만 산학계에서 제안 된 다양한 아키텍처들이 있음. 제시한건 NLU, DST, DP, NLG지만 하나로 합쳐진 것도 있고 그럼.
B. Analysis Dimension
크게 4가지 차원에서 구체적으로 설명함
DS: 어떻게 DS가 representation되고, 어떤 정보가 포함되고, 수작업인지 데이터로 학습하는지 설명
DST: DS가 결정되는 과정을 설명
DP: 다음 action이 어떻게 결정되는지 설명
Context support: 유저 의도를 파악하고 적절한 답을 주기 위해, 크게 3가지를 활용함 Converstional history, User profile, External knowledge
3. DM 접근법
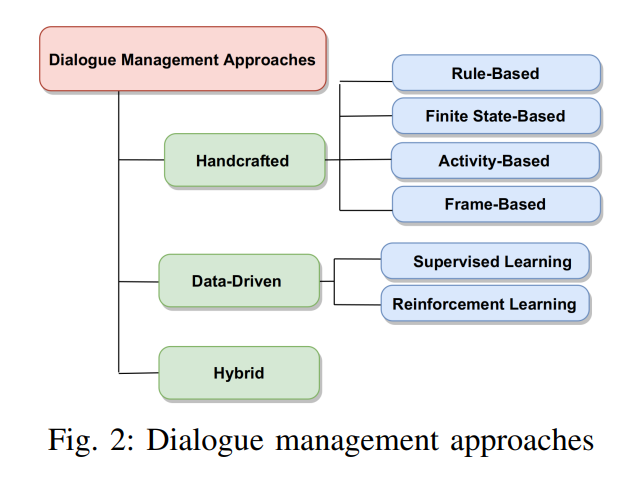
DM 방식에는 크게 3가지가 존재함 1. 수작업 2. data-driven 3. 혼합
3.1 Hand-crafted
Rule-based
Rule-based 방식은 가장 초기에 나온 방식으로 한 번에 NLU, DM, NLG 태스크를 수행하는 방식임. AIML(AI Markup Language)라는 개념이 있음. 이건 크게 두 개념으로 구성되는데 1. 카테고리 2. 주제로 구성됨. 명확히 이해는 안되지만 이 논문에선 챗봇으로 예를 들었는데 사용자가 Hi robot이라 입력해야 대화가 시작되고 Hi robot에 대한 답변이 이미 정해져 있어 Hi human이란 답을 하는 방식이라고 함. 아무튼 이 방식의 특징은 당연히 DST와 DP의 역할이 거의? 없다는 것. 바로 NLU 한 다음 NLG를 함. 결론적으로 수 많은 패턴이 있어야 하기 때문에 간단한 태스크 조차 쉽지 않고, 패턴간 중복이나 충돌이 발생해서 이걸 처리하는 비용이 들기 때문에 비효율적이다. (고비용 & 스케일업 어려움)
이런 비효율적인 Rule-based를 보완하기 위해서 DS와 DP가 필요했음. 왜냐면 rule-based는 보통 바로 이전 발화만 저장했는데, 정교하게 만들기 위해 이전 발화 모두를 저장해서 활용할 필요가 생겼고 또 사용자 맞춤을 위해 user-profile 정보가 필요했음. 이런 발화 정보와 유저 프로필과 같은 대화에 도움을 주는 것을 context support라 부름.
Finite State-based
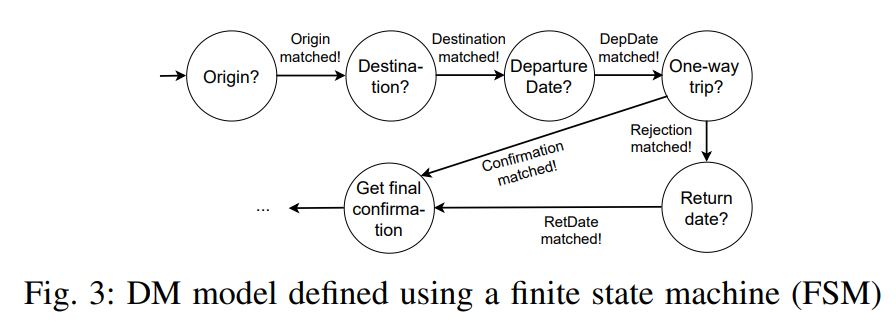
Final State Method는 규칙 기반으로 동일함. 하지만 룰베이스에서 조금 더 확장된 것이라 볼 수 있음. 사용자가 원하는 행위가 충분히 polynomial한 질문 수와 절차로 해결하는 방식이기 때문임. 비행기 예약과 위 그림 3 시나리오로를 보자면 프로그래밍을 통해 시퀀셜하게 이미 정해진 절차가 있어서 반드시 이걸 따라야 함. “다음 주 월요일에 리옹에서 시드니로 가는 편도 항공편을 예약하고 싶다"고 말 못함 왜냐면 “출발지 → 목적지 → 날짜 → 편도/왕복”의 일련의 절차 대로 말해야 하기에.
Frame-based
domain ontology기반 방식임. 예를 들자면 음악 틀어달라는 태스크라면 사전정의된 frame은 domain으로 Music을 가질 것이고 intent는 Play music일 것임. 그리고 slot이 될 수 있는 장르와 뮤지션을 요구하거나 수집할 수 있음. frame-based는 사전 정의된 frame을 보고 어느 슬롯이 채워졌고 안채워졌는지 확인해서 DS를 파악할 수 있음. rule-based와 activity-based 기반과 비교해 다른 점은 조금 더 유연하단 것이 장점임.
앞서 기술했듯 어떤 slot이 채워졌는지 안채워졌는지 파악해서 추가 요구하기 때문임. 반면 단점으론 복잡한 DP 알고리즘이 필요하고, 모든 조건에서 추가적으로 정보를 요청하는지 안하는지 테스팅이 필요함. 그럼에도 불구하고 frame-based는 현재에도 사용되는 방식임. 애플 시리, 아마존 알렉사, 구글 어시스턴트가 여기에 해당함. 그래도 이런 어시스턴트 들에서 조금 더 추가되는 부분은 NLU에서 머신러닝 방식이 사용되고, 프레임외에 control model을 추가한다고 함. Control model이 정확히 무엇인지 모르겠지만 봇 개발자가 복잡한 DP 지정을 방지할 수 있다고 함.
3.2 Data-driven
Data-driven 방식은 위 Hand-craft 방식과 달리 DS와 DP를 학습해서 사용함. 이를 위해 Supervised Learning(이하 SL)과 Reinforce Learning(이하 RL)이 사용됨. SL로는 라벨 있는 데이터로 corpus를 학습하고, RL로는 tiral-and-error 과정을 학습함
1) Supervised approach
Data-driven 방식의 최초 접근은 SL로, CRF나 최대 엔트로피 모델을 사용했었음. 하지만 이는 대개 DS 정의를 위해 NLU의 출력에 의존하는 단점이 있었음. 하지만 DL이 사용되면서 DST에 대한 성능이 높아짐. 성능 증가의 배경에는 DS를 NLU에 종속시키는 것이 아니라 NLU와 DS를 단일 모델로 병합하는 연구가 대부분 이뤄지면서 가능했음. 이런 연구의 한 예시로 아래 그림과 같은 Neural Belief Trakcer (NBT)가 있음.
NBT 모델은 시스템 출력과 유저 발화와 slot-value pair를 입력으로 넣고 중간에 Context Modeling과 Semantic Decoding을 거쳐 최종적으로 이진 분류하고 최종적으로 slot-value에 들어갈 값을 결정하는 구조를 가짐.
더욱 최근 DL 모델은 GNN 모델과 attnetion 메커니즘을 사용하기도 함. 최근 DL 모델도 결국 두 가지로 나뉨. pre-defined ontology-based(사전 정의된 온톨로지 기반)과 open-vocabulary candidate generation(개방형 어휘 후보 생성)으로 나뉨. 전자의 경우 도메인과 그에 해당하는 슬롯과 값이 제공된다고 가정함. 하지만 알다시피 정의된 것은 정확도가 높지만 동적인 환경에서는 여전히 취약함. 동적인 환경 예시는 영화 이름이나 사람 이름, 날짜, 위치 등이 있음 반면 후자의 경우 미리 정의된 것 없이 대화 기록이나 NLU 출력 값에서 슬롯 후보를 추정하는 방식임. 새로운 의도나 슬롯, 도메인을 추가할 때 데이터 수집이나 재학습과 같은 비용이 발생하지 않도록 제로샷으로 DST를 일반화 시키는 것이 현재 가장 메인이 되는 연구임.
Dialouge Policy
DP에 지도학습을 적용시키는 두 가지 접근이 있음. 1. DP 모델을 파이프 라인 모델로 두어 DST와 NLU 모듈과 독립적으로 학습시키는 방법임. 이 방법은 DST의 DS로부터 input을 가져와서 넣거나 NLU 결과를 직접 넣어서 다음 action을 출력함. 그 과정은 아래 그림의 (a)와 같음
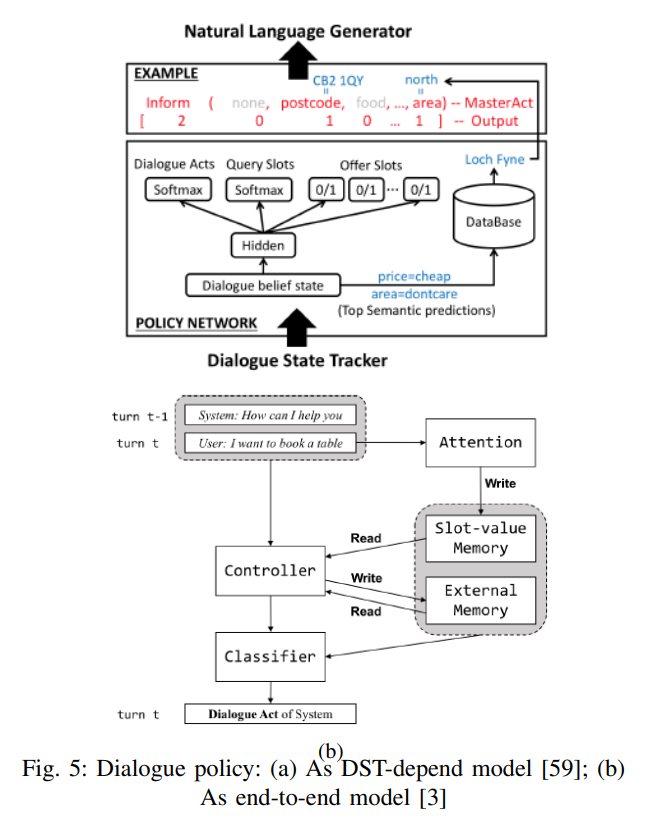
DP network안에는 Act와 Slot을 예측하는 두 개의 Softmax가 있음. Act는 request, offer, confirm, select, bye 중에 하나가 될 수 있고 Slot은 price-range, area 같은 것들이 될 수 있음. (b)의 모델은 3개의 메모리에 의존함 slot-value memory, external memory, control memory인데 read/write function과 augmented attention 메커니즘을 공유함.
두 번째 접근은 end-to-end 모델임. 이 방식은 user utterance를 읽어서 곧 바로 모델에 넣고 다음 system action을 생성하는 방식임. 구현을 위해선 seq2seq 계열 알고리즘이 사용됨. sqe2seq 알고리즘에 사용되는 encoder는 user utterance와 dialouge history이며 decoder는 API 호출, 데이터베이스 쿼리가 될 수 있음. 알다시피 RNN, LSTM 사용했지만 최근엔 어텐션 메커니즘 사용됨. end-to-end 방식의 괄목할만한 대표적인 DP 모델은 아래 논문에서 확인할 수 있다고 함.
" Z. Zhang, M. Huang, Z. Zhao, F. Ji, H. Chen, and X. Zhu, “Memory augmented dialogue management for task-oriented dialogue systems,” ACM Transactions on Information Systems (TOIS), 2019."
여하튼 end-to-end 방식은 앞전 pipelined policy과 달리 dialouge state를 추론할 수 있다는 것이 장점. 다만 데이터가 많은 데이터가 필요할 뿐. 참고로 pipelined policy 방법도 동일하게 지도학습함.
Context support
conversation history를 앞 전 하나만 사용하냐 모두 사용하냐도 나뉨. 크게 3가지 방법으로 conversation history 모델링이 이뤄짐. 첫 번째 방법은 모든 발화를 concatenation하는 것임. 근데 단점이 계산 복잡도가 증가하니까 두 번째 방법인 user/system dialouge act나 dialouge state의 특정한 feature들만 캡처하는 방식임. 세 번째 방식은 최근에 나온것으로 그래graph structrural information를 활용하는 거임. 이건 Spacy에 있는 dependency relation과 관련이 있다고 함.
2) Reinforcement learning
RL 접근은 DM을 최적화 문제로 봄. 유저의 경험과 시간이 지나면서 성능이 점진적으로 개선하는. 전형적으로 Markov Decision process가 사용됐었음. (RL 파트 생략)
결론부터 요약해두자면 이 논문에서 말하고자 하는 DM 접근법은 크게 3가지가 있고 장단점은 다음과 같다.
1. Handcrafted 방식은 구현 쉽다. 데이터 필요 없다. dialouge traceability 충족시킬 수 있다. 단점은 유지 비용 높고 스케일업과 모델의 robustness 측면에서 한계가 있다. 또 사용자 피드백 고려하지 않는다.
2. Data-driven 방식은 크게 지도학습 방식, 강화학습 방식으로 나뉨. (1) 지도학습 장점은 자연어의 variation을 다룰 수 있고 새로운 domain에 대한 적은 노력으로 적응 가능함. 반면 단점은 양질의 데이터 불충분과 DP에 적응하기 위한 유저 피드백 고려 못함. (2) 강화학습의 장점은 Robust하고 user utterance의 모호함을 다룰 수 있음. 단점은 작은 스케일의 대화 도메인에 한계가 있다..?, 양질의 데이터 필요하다.
3. Hybrid 방식은 위 둘을 섞은 것임. 장점은 학습 복잡도와 학습 데이터 줄어듦. 단점은 충분한 양질의 데이터와 개발 노력 필요
아래 표는 DM (Dialouge Manager)에 사용되는 3가지 피처임.
1. Conversation history 사용되고
2. User profile 사용되고
3. External knowledge 사용됨.
읽고 나서 궁금해진 것
- GNN (Graph Neural Network)
- Graph Attention Network
- Knowledge Graph
- End-to-end Dialouge Policy Modeling
- Reinforcement Learning
읽어 볼 논문
[1] Z. Zhang, M. Huang, Z. Zhao, F. Ji, H. Chen, and X. Zhu, “Memory augmented dialogue management for task-oriented dialogue systems,” ACM Transactions on Information Systems (TOIS), 2019.
[2] Y. Murase, Y. Koichiro, and S. Nakamura, “Associative knowledge feature vector inferred on external knowledge base for dialog state tracking,” Computer Speech & Language, vol. 54, pp. 1–16, 2019.
의도 분류는 Spoken Language Understanding(SLU)의 하위 태스크에 해당하며, 의도 분류는 SLU의 또 다른 서브 태스크인 Semantic Slot Filling 태스크로 곧 바로 연계되기 때문에 그 중요성을 가짐.
ML 기반으론 유저 발화 이해가 어렵다. 때문에 이 논문에선 DL 기반의 의도 분류 연구가 최근까지 어떻게 이뤄져왔는지 분석, 비교, 요약한하고, 나아가 다중 의도 분류 태스크가 어떻게 딥러닝에 적용되는지 기술함.
내가 추출한 키워드: intent detection, mulit-intent detection, spoken language understanding, semantic slot filling.
Introduction
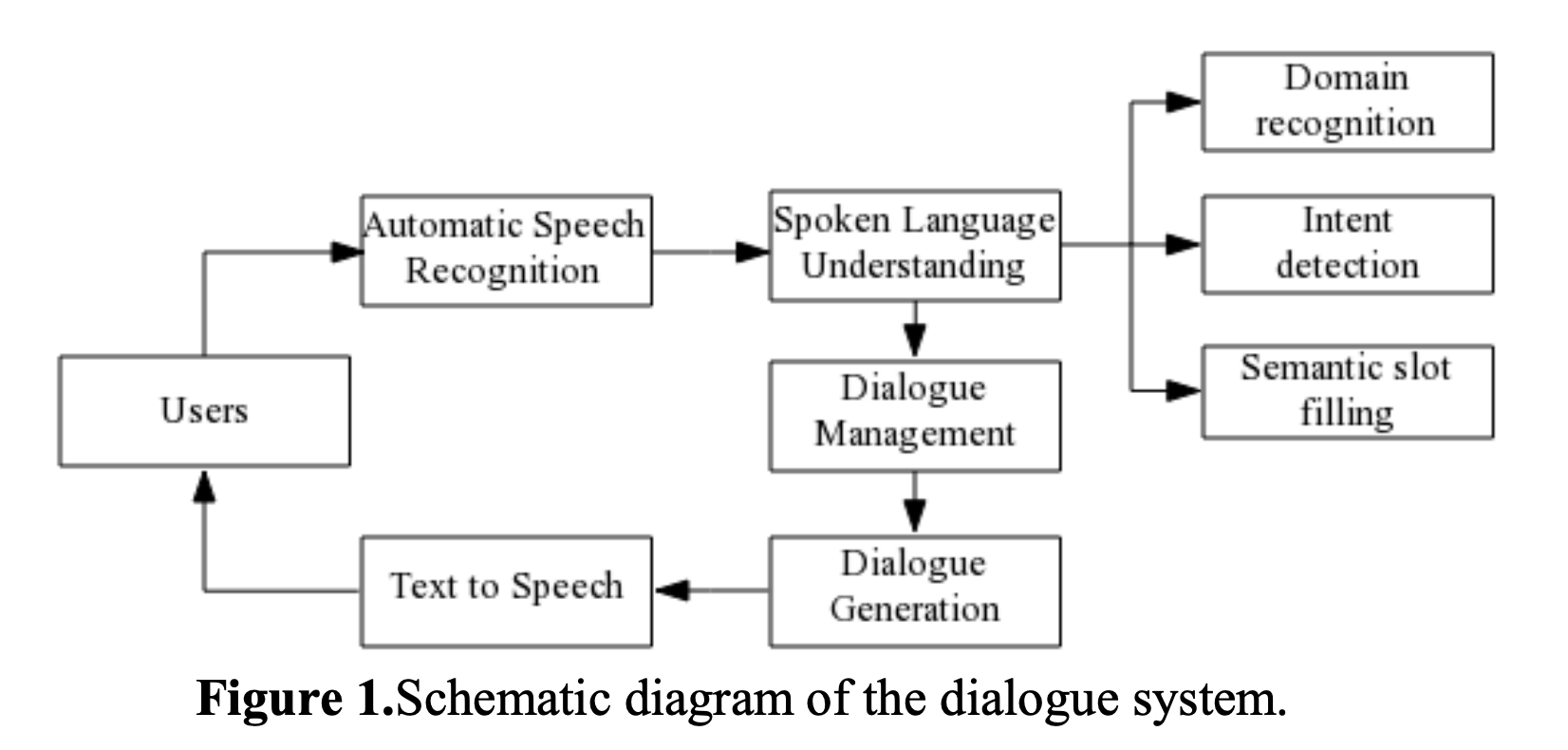
Dialouge System은 크게 5개 파트로 나뉨: ASR, SLU, DM, DG, TTS.
유저가 발화 하면 ASR을 통해 유저의 발화를 생성하고 SLU 과정으로 넘어가 말하고자 하는 1. 주제 파악 2. 의도 파악 3. Semantic slot filling을 과정을 거침. 이후 Dialouge Management를 거치고 답변 생성 후 TTS로 유저에게 전달.
과거엔 SLU에서 Domain recognition이 없었다. 왜냐면 dialouge system이 specific domain에 국한됐기 때문임. 하지만 최근엔 넓은 범위의 domain을 다루고자 하는 필요성이 있기 때문에 추가 됨.
도메인 별, 의도 별 사전 정의된 카테고리를 이용해 유저 발화 분류함. 만약 사전 정의돼 있지 않다면 의도를 잘못 분류해서 잘못된 대답을 하게 됨.
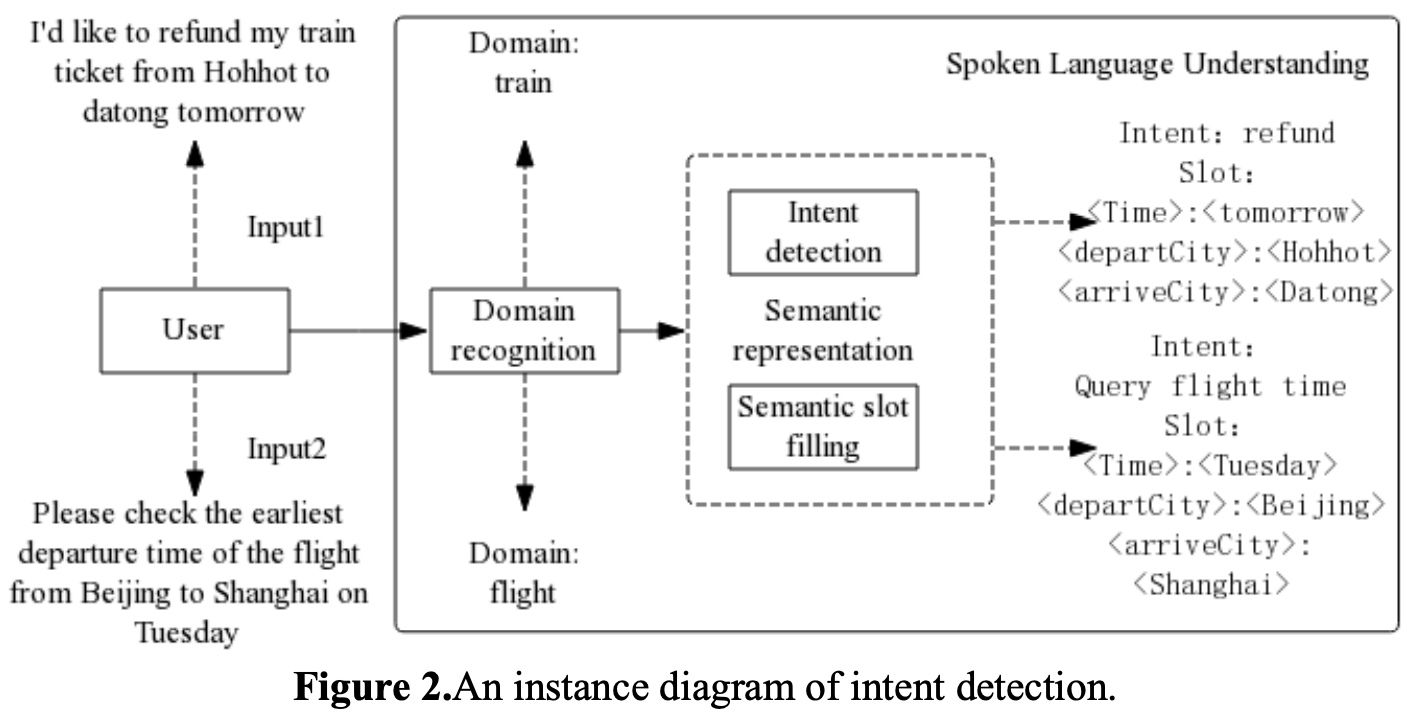
의도 분류에서 어려운 것은 다중 Domain이 들어왔을 때 어떤 Domain에 속하는지 명확히 해야함. 그렇지 않으면 Domain보다 더 세분화되어 있는 Intent category으로 접근하기 어려움. 위의 예시로 들면 맥락상 기차 말고 비행기 탈꺼니까 기차 환불하고 가장 빠른 비행기 시간 확인해 달라는 것임. 근데 환불인지 시간 확인인지 Domain 수준에서 파악이 안되면 그 다음 단계인 Intent detection과 semantic slot filling을 못함.
2. Intent Detection의 어려움
2.1 데이터 부족
부족하다.
2.2 화자 표현 광범위, 모호함.
일반적으로 구어체 사용하고, 짧은 문장과 넓은 컨텐츠를 다루기 때문에 의도 파악이 어려움. 가령 예를 들어 “I want to look for a dinner place”라고 말하면 저녁 식사 장소 찾고 싶단건데 domain이 명확하지 않음. (사실 이 정도면 충분하다 생각하는데 불확실한가 봄)
다른 예시 들자면 Hanting이라는 호텔이 있지만 Hanting Hotel이라고 구체적으로 이야기하지 않으면 이해하기 어려움. 또는 티켓 예약 하고 싶다고만 말하면 비행기 티켓인지 기차 티켓인지 콘서트 티켓인지 알 수 없는 것처럼 화자의 표현이 광범위하거나 모호한 경우가 발생해서 machine이 적절한 답변을 주기 어려움.
2.3 암시적인 의도 분류
의도는 명시적인 것(Explicit)과 암시적인 것(Implicit)으로 나눌 수 있음. 유저가 암시적으로 말하면 진짜 유저 의도가 뭔지 추론할 필요가 생김. 예를 들어 요새 건강에 관심이 있다고 말하면 아 오래살고 싶구나 하고 이해할 수 있어야 하는데 그게 어려움. (내가 만든 예시)
2.4 multiple intents detection
multi-label classification과 비슷하지만 다름. 그 차이점은 multi-label classification은 긴 문장 multiple intnets detection은 짧은 문장을 다룸. 짧은 문장으로 다중 의도 분류 해야해서 어려움. 짧은 발화안에 다양한 의도 분류를 해야하고 그 의도 수를 결정해야 하는게 쉽지 않음.
3. Main methods of intent detection
3.1 전통적인 Intent detection 방법론
최근에는 intent detection을 Semantic Utterance Classification (SUC)로 여긴다.
1993년엔 rule-based가 제안된 적 있고, 2002-2014까진 통계적으로 피처를 뽑아서 분류했다. 가령 예를 들면 나이브 베이즈나 SVM이나, Adaboost, 로지스틱 회귀를 썼었다. 근데 룰베이스의 경우 정확도는 높지만 새로운 카테고리가 추가될 때마다 수정해야 하는 번거로움이 있고, 통계적인 방식은 피처의 정확도나 데이터 부족문제가 있다. 근데 지금도 화자의 real intent detection은 여전히 어려운 연구 주제다.
3.2 현재 주류 방법론
워드 임베딩, CNN, RNN, LSTM, GRU, Attention, Capsule Network 등이 있다. 전통적인 방법과 비교하면 성능이 크게 좋아졌다.
3.2.1 워드 임베딩 기반 의도 분류
3.2.2 CNN 기반 의도 분류
CNN 기반으로 해서 피처 엔지니어링 과정을 많이 줄이고 피처 표현력도 좋아졌다. 근데 여전히 CNN으론representation 한계 있다.
3.2.3 RNN 기반 의도 분류
CNN과 달리 워드 시퀀스를 표현할 수 있음. 2013년에 context 정보 이용해서 Intent detection의 error rate를 줄인 연구가 있음. RNN은 기울기 소실과 기울기 폭발 문제가 있고 이 때문에 long-term depdendence 문제를 초래함.
그래서 이 문제 해결하려고 LSTM이 나옴. LSTM가지고 ATIS 데이터셋 (Air Travel Information System)에서 RNN보다 에러율 1.48%을 줄임.
2018년엔 짧은 텍스트로 인해 발생하는 data sparse 문제를 해결하기 위해 Biterm Topic Model(BTM)과 Bidirectional Gated Recurrent Unit(BGRU) 기반 멀티턴 대화 의도 분류 모델이 제시됨.
위 두 모델을 합친 모델은 의료 의도 분류에서 좋은 성능을 냈음.
. . .
3.2.6 캡슐 네트워크 모델 기반 의도 분류
캡슐 개념은 CNN의 표현 한계 문제를 해결하기 위해 2011년에 힌튼에 의해 제시됐었음. 캡슐은 vector representation을 가짐. 이후 2017년에 CNN scalar output feature detector를 vector representation capsule로 대체하고 max pooling을 프로토콜 라우팅으로 대체하는 캡슐 네트워크가 제안됨. CNN과 비교하자면 캡슐 네트워크는 entity의 정확한 위치 정보를 유지함.
결론을 말하자면 capsule network는 텍스트 분류 태스크 잘 수행하고, multi-label 텍스트 분류에도 잘 동작함.
. . .
4. 의도 분류 평가 방법
현재 Intent Detection은 Semantic Discourse Classification 문제로 여겨짐. 결론은 F1-score 사용함.
5. 성능 비교
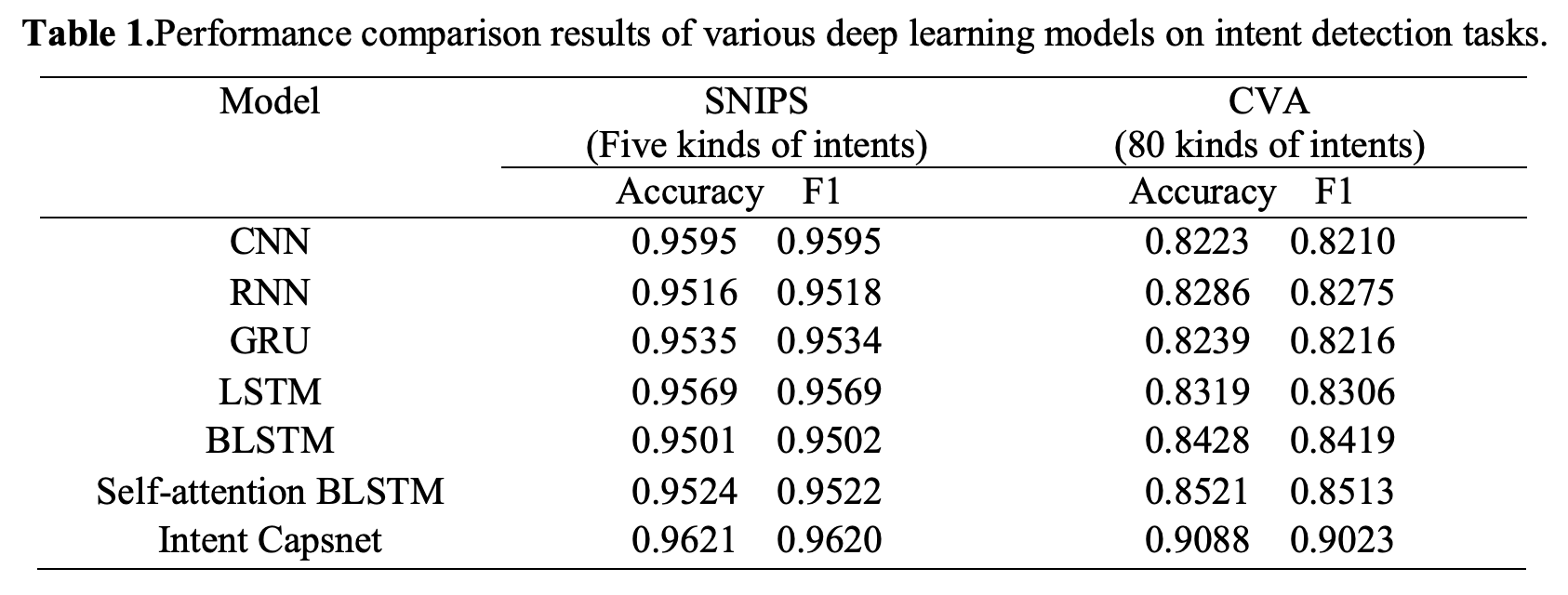
아래는 다른 연구 논문에서 가져온 성능 비교 결과임. 데이터셋은 SNIPS와 CVA(Commercial Voice Assistant)를 사용했음. 참고로 SNIPS는 영어 데이터셋이고 CVA는 중국어 데이터셋임.
Intent Capsnet이 가장 성능이 좋더라.
Conclusion
머신러닝 기반의 의도 분류 태스크는 깊이 이해 못한다. 그래서 딥러닝 기반 의도 분류 태스크가 성능이 좋다. capsule network model이 의도 분류 태스크에서 좋은 성능을 내고, multi-label classification도 잘한다. self-attention 모델은 의도 분류 과정에서 문장의 다양한 semantic feature들을 추출할 수 있다.
의도 분류는 e-commerce, travel consumption, medical treatment, chat에도 적용되고 있으며, 침입 탐지 시스템과 같은 네트워크 보안 분야에서도 적용된다.
전통적인 dialouge system은 주로 single intent detection만 가능하다. 하지만 다양한 의도는 셀 수 없이 많으므로 multi intent detection이 가능하도록 연구가 필요하다.
궁금해진 것
Semantic slot filling의 과정은 구체적으로 어떻게 이뤄지는가?
Dialouge Management란 무엇이고 어떻게 동작하는가?
Dialouge Generation 과정은 구체적으로 어떻게 이뤄지는가?
task-oriented vertical domain이 무엇인가? vertical이 있으면 horizontal domain도 있을 것인데 각각은 무엇인가?
알게 된 것
도중에 fine-grained라는 말이 나옴. 이건 잘게 쪼갠 것을 의미함. 반면 coarse-grained는 덩어리째를 의미함.
한 줄 평
큰 틀에서 연구가 어떻게 이뤄지는지 대략적으론 알 수 있어서 좋았지만 Dialougue System의 구체적으로 어떻게 이뤄지는지 나와있지 않고 데이터셋을 잘 정리해서 소개하지 않아서 아쉬움.
Cross-Lingual, Multilingual, Language Structure, typological similarity
먼저, 이 논문을 한 마디로 요약하면 typological similarity는 크게 중요한 요소가 아니라는 것을 주장하는 논문입니다.
이 논문의 연구 배경은 Multilingual Masked Languagde Model(이하 Multilingual MLM)이 어떻게 별도의 Cross-lingual 지도학습 없이도 좋은 성능을 내는지에 대한 물음을 기반으로 시작되었습니다. "How multilingual is Multilingual BERT?"(이하 mBERT) 이라는 multilingual의 시작이 되는 논문에서 multilingual 모델의 성능은 언어학적인 유사성(typological similarity)이 높을수록 좋은 성능이 나온다고 하였지만 이 논문에서는 이를 정면으로 반박합니다. 그 이유는 언어학적 유사성이 높다는 것은 정확한 통제변인이 이루어지지 않았음을 지적합니다.
예를 들면 mBERT 논문에서는 언어의 문법 구성인 SVO(주어, 동사, 목적어)와 AN(형용사, 명사)만 고려했습니다. 세계의 많은 언어는 SVO 순을 쓰거나 SOV 순을 쓰는 언어가 존재하고 AN 순을 쓰거나 NA 순을 사용하는 언어가 존재합니다. 하지만 이 논문에서는 다른 품사(전치사, 부사, 접속사, 한정사) 등을 모두 고려하지 않은 실험 결과라고 말합니다. 아래는 mBERT 논문에서 가져온 실험결과 입니다.
(a)는 SVO의 어순을 가진 언어끼리 그룹화하고 SOV의 어순을 가진 언어끼리 그룹화해서 zero-shot trasnfer를 수행할 때의 macro-averaged POS accuracy를 나타냅니다. (b) 또한 (a)와 동일한 맥락입니다. 한 마디로 같은 어순을 가진 그룹끼리는 성능이 좋지만 다른 어순을 가지면 성능이 떨어진다는 것을 의미합니다. 즉, multilingual MLM이 어순이 다른 것은 학습하지 못한다는 것을 보였습니다.
하지만 이 논문에서는 mBERT에서 언어학적 유사성으로 가져온 피처가 2개밖에 되지 않는다고 이야기합니다. 즉, 다시 한 번 말해, 하나의 언어를 구성하는데는 SVO와 AN만 있는 것이 아니라 전치사, 부사, 접속사, 한정사 등과 같은 여러 품사가 존재하는 데 모두를 고려하지 않고 두 개의 피처만 가지고 유사성을 비교했다라는 것을 지적하는 것입니다.
이에 대해서 저자들은 정확한 실험을 위해선 통제 변인을 잘 설정하는 것이 중요하다고 이야기하며 artificial sentence를 아래와 같이 생성합니다.
예를 들면 영어가 주어동사목적어 순일 때 주어목적어동사로 영어에서 맞지 않는 문법인 인공의 문장을 데이터셋으로 만듭니다. 마찬가지로 전치사 명사를 명사 전치사로, 형용사 명사를 명사 형용사 순으로 바꿉니다. 참고로 이 때 사용한 83A, 85A, 87A 언어 구조와 관련한 피처로 세계 언어 구조에 대한 데이터베이스인 WALS (World Altas of Language Structure)의 피처를 기준으로 하였습니다. (총 192개의 피처가 존재)
WALS에서 제시하는 세계 언어에 대한 특성
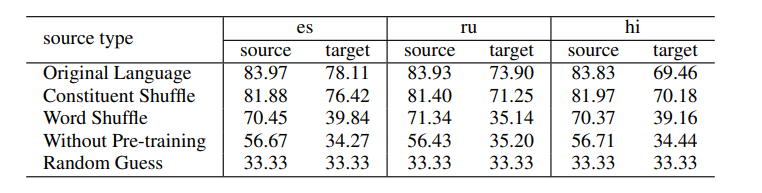
위와 같이 WALS의 피처를 기준으로 인공의 문장을 생성한 뒤 6개의 target언어에 대해 평가한 결과는 아래와 같습니다.
6개의 target 언어는 ru(러시아), hi(힌디어), tr(터키), es(스페인), th(태국), vi(베트남)입니다. 여기서 표 한 부분만 해석해도 됩니다. 영어와 어순이 같은 러시아어의 비교표를 기준으로 설명하겠습니다. 먼저 source는 모두 영어만 사용했습니다. 영어 데이터를 변형하지 않은 en의 경우 소스를 순수 영어로하고 target을 러시아어로했을 때 transfer 성능이 83.93%과 73.90%이 나왔습니다.
하지만 영어의 어순 VO를 OV로 변경한 en-OV의 결과를 확인하면 어순을 바꿨음에도 불구하고 어순이 같았던 러시아어에 대해 transfer 성능이 오히려 높아지는 결과를 확인할 수 있습니다. 마찬가지로 전치사를 사용하는 영어에서 후치사로 바꾼 en-Post에서도 오히려 더 성능이 높아진 것을 확인할 수 있습니다. AN 또한 명사, 형용사로 바꾼 en-NA에서는 다소 낮아짐으로써 결과의 일관성이 없음을 볼 수 있습니다. 즉, 이 표가 말하고자 하는 것은 한마디로 mBERT 논문에서 주장했던 typological similarity가 중요하지 않다는 것을 시사하고 있습니다.
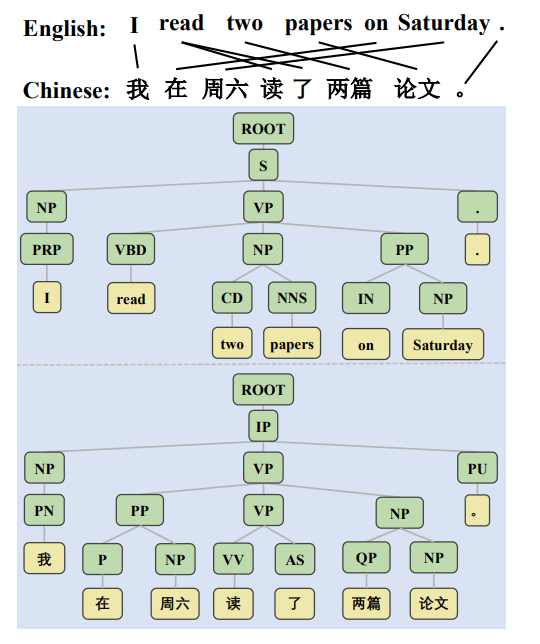
그러면서 가장 중요한 것은 composition이라고 말합니다. 앞서서 미리 알려드리지 못했으나 이 논문에서는 크게 언어학적인 속성 3개에 대해 실험을 진행했습니다. 세 언어학적 요소는 constituent order, composition, word co-occurrence 입니다. 위 어순을 바꾼 실험이 constituent order에 대한 실험이었습니다. 참고로 constituent order는 구성 순서를 의미하는 것으로 아래의 그림에 있는 NP, VP, PRP, VBD와 같은 constituent의 순서를 변경했을 때의 multilingual 모델의 성능을 보는 것입니다.
composition 같은 경우는 조금 더 친절한 설명이 있지 않아 지금도 이해가 어려운 부분이 있는데요, 논문에서 제시하는 예시는 "two"라는 단어와 "papers"라는 단어를 합치면 "two papers"와 같은 조금 더 복잡한 단어를 만들 수 있다고 합니다. 따라서 나이브하게 합성어 정도라고 이해하고 있습니다.
마지막으로 word co-occurrence 같은 경우는 동시 발생으로 일종의 관용구나 의미적 유사성을 나타내는 속성이라고 합니다. 예를 들면 "티끌 모아 __"하면 태산이 나오는 것 처럼 티끌과 태산은 함께 나오는(co-occurrence) 단어다 정도로만 이해를 했습니다.
consituent order를 변형한 결과를 보여준 것관 달리 composition과 word co-occurrence에 대한 실험은 하나의 표에 결과를 함께 보여주는데요 그 표는 다음과 같습니다.
Original Language 같은 경우는 소스언어인 영어 데이터를 변형하지 않았을 때의 결과를 나타냅니다. Constituent Shuffle 같은 경우는 constituent order를 제거했을 때의 성능을 나타내구요, Word Shuffle 같은 경우는 constituent order와 composition을 제거 했을 때의 결과를 나타냅니다.
여기서 중요한 것은 constituent order를 제거했을 때는 성능 저하가 미미하지만 composition과 함께 제거할 경우 target 언어에 대해 language transfer 성능이 확 떨어지는 것을 볼 수 있습니다. 이 결과를 바탕으로 저자들은 Multilingual MLM의 성능을 나타내는 언어학적인 세 요소 중에 가장 중요한 것이 composition이라고 합니다.
이 때까지 내용을 총 정리하면 크게 아래 두 줄로 요약할 수 있습니다.
1. mBERT에서 주장한 typological similarity가 높을 수록 성능이 좋다는 것은 사실이 아니며 잘못된 변인 통제에 의해 실험이 이루어졌다.
2. multilingual MLM의 성능을 좌우짓는 요소는 composition이다.
전반적으로 논문을 읽으며 다소 불친절한 설명이 있고, 직관적으로 파악하기 어렵다는 데 있어 아쉬운 측면은 있습니다. 예를 들면 Word Shuffle에 대해 조금 더 상세한 설명이 덧붙였으면 더 나은 논문이 되지 않았을까 싶습니다. 하지만 그럼에도 불구하고 잘못된 변인 통제를 기반으로 수행한 mBERT의 실험 결과를 정정한다는 측면에서는 의미 있는 연구라 생각이 듭니다.
이 포스팅은 『밑바닥부터 시작하는 딥러닝』을 기반으로 작성되었습니다. 간단한 이론이지만 누군가에게 설명할 수 있는가에 대해 생각한 결과, 올바르게 설명하지 못한다고 판단되어 이를 쇄신하고자 하는 마음으로 작성합니다.
신경망 학습과 손실함수
신경망을 학습한다는 것은 훈련 데이터로부터 매개변수(가중치, 편향)의 최적값을 찾아가는 것을 의미한다. 이 때 매개변수가 얼마나 잘 학습되었는지를 어떻게 판단할 수 있을까? 방법은 손실함수(loss function)을 사용하는 것이다. 손실함수란 훈련 데이터로부터 학습된 매개변수를 사용하여 도출된 출력 신호와 실제 정답이 얼마나 오차가 있는지를 판단하는 함수이다. 다시 말해 학습된 신경망으로부터 도출된 결과 값과 실제 정답이 얼마나 차이가 나는지를 계산하는 함수이다. 값의 차이를 손실이라고 말하며 신경망은 이 손실함수의 값이 작아지는 방향으로 매개변수를 업데이트 하게 된다.
그렇다면 신경망의 학습을 위해 사용하는 손실함수의 종류들은 무엇이 있을까? 종류를 논하기에 앞서 손실함수는 풀고자하는 태스크에 따라 달라질 수 있다. 예를 들어 머신러닝 태스크는 크게 분류 태스크와 회귀 태스크가 있을 것이다. 분류 태스크라고 한다면 이 사진이 강아지, 고양이, 원숭이 중 어디에 해당할지 분류 하는 것이다. 분류 태스크의 특징은 실수와 같이 연속적인 것이 아니라 정수와 같이 불연속적으로 정확하게 강아지, 고양이, 원숭이 중 하나로 나눌 수 있다. 반면 회귀 태스크는 연속이 아닌 불연속적(이산적)인 값을 가지는 태스크를 수행하는 것을 의미한다. 예를 들어 사람의 키에 따르는 몸무게 분포를 구하는 태스크일 경우 몸무게와 같은 데이터는 실수로 표현할 수 있기 때문에 출력 값이 연속적인 특징을 가지는 회귀 태스크라 할 수 있다.
그렇다면 손실함수의 종류와 특징들에 대해서 알아보도록 하자.
손실함수 (Loss Function)
평균제곱오차 (Mean Squared Error, MSE)
여러 종류의 손실함수 중 평균제곱오차라는 손실함수가 있다. 이 손실함수를 수식으로 나타내면 다음과 같다.
$$ MSE = {1\over n}\sum_i^n(\hat{y}_i - y_i)^2 $$
간단한 수식이다. 천천히 살펴보자면, $\hat{y}_i$는 신경망의 출력 신호이며 $y_i$는 실제 정답이다. $n$은 학습 데이터 수를 의미한다. 이를 해석하자면 출력(예측) 신호와 실제 정답 간의 차이를 구한다음 제곱을 해준 값을 데이터셋 수 만큼 반복하며 더해주는 것이다. 제곱을 해주는 이유는 음수가 나오는 경우를 대비하여 마이너스 부호를 없애기 위함이다. $1\over n$를 곱해주는 이유는 평균 값을 구해주기 위함이다. 즉 MSE를 한마디로 이야기하면 오차의 제곱을 평균으로 나눈다고 할 수 있다. 따라서 MSE는 값이 작으면 작을 수록 예측과 정답 사이의 손실이 적다는 것이므로 좋다.
출력 신호인, 예측 확률 output이 가지고 있는 가장 높은 확률 값과 정답이 차이가 적을수록 손실 함수의 출력 값도 적은 것을 확인할 수 있다. 반면 가장 높은 확률이 정답이 아닌 다른 곳을 가리킬 때 손실함수의 출력 값이 커지는 것을 확인할 수 있다. 위에서 볼 수 있듯 평균제곱오차(MSE)는 분류 태스크에 사용 된다.
교차 엔트로피 오차 (Cross-Entropy Error, CEE)
위와 달리 회귀 태스크에 사용하는 손실함수로 교차 엔트로피 오차가 있다. 수식으로 나타내면 다음과 같다.
$$ CEE = -\sum_i\hat{y_i}\ log_e^{y_i} $$
$\hat{y_i}$는 신경망의 출력이며 $y_i$는 실제 정답이다. 특히 $\hat{y_i}$는 one-hot encoding으로 정답에 해당하는 인덱스 원소만 1이며 이외에는 0이다. 따라서 실질적으로는 정답이라 추정될 때($\hat{y_i}=1$)의 자연로그를 계산하는 식이 된다. 즉 다시 말해 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정하게 된다.
실제로 구현할 때는 log가 무한대가 되어 계산 불능이 되지 않도록 하기 위해 delta 값을 더해주는 방식으로 구현한다. 예측 정답이 2번이고 실제 정답이 2번일 경우의 손실함수 값은 0.051이고 이와 달리 예측 정답이 2번이고 실제 정답이 7번일 경우 손실함수 값은 2.302가 된다. 즉, 정답에 가까울수록 손실함수는 줄어들고 오답에 가까울수록 손실함수는 커진다고 볼 수 있다. 신경망의 목표는 이러한 손실함수의 값을 줄이는 방향으로 학습하는 것이다.