논문: Going Deeper with convolutions
게재: 2015년
학회: CVPR
GoogLeNet이란?
GoogLeNet은 한 마디로 네트워크의 depth와 width를 늘리면서도 내부적으로 inception 모듈을 활용해 computational efficiency를 확보한 모델이다. 이전에 나온 VGGNet이 깊은 네트워크로 AlexNet보다 높은 성능을 얻었지만, 반면 파라미터 측면에서 효율적이지 못하다는점을 보완하기 위해 만들어졌다.
CNN 아키텍처와 GoogLeNet
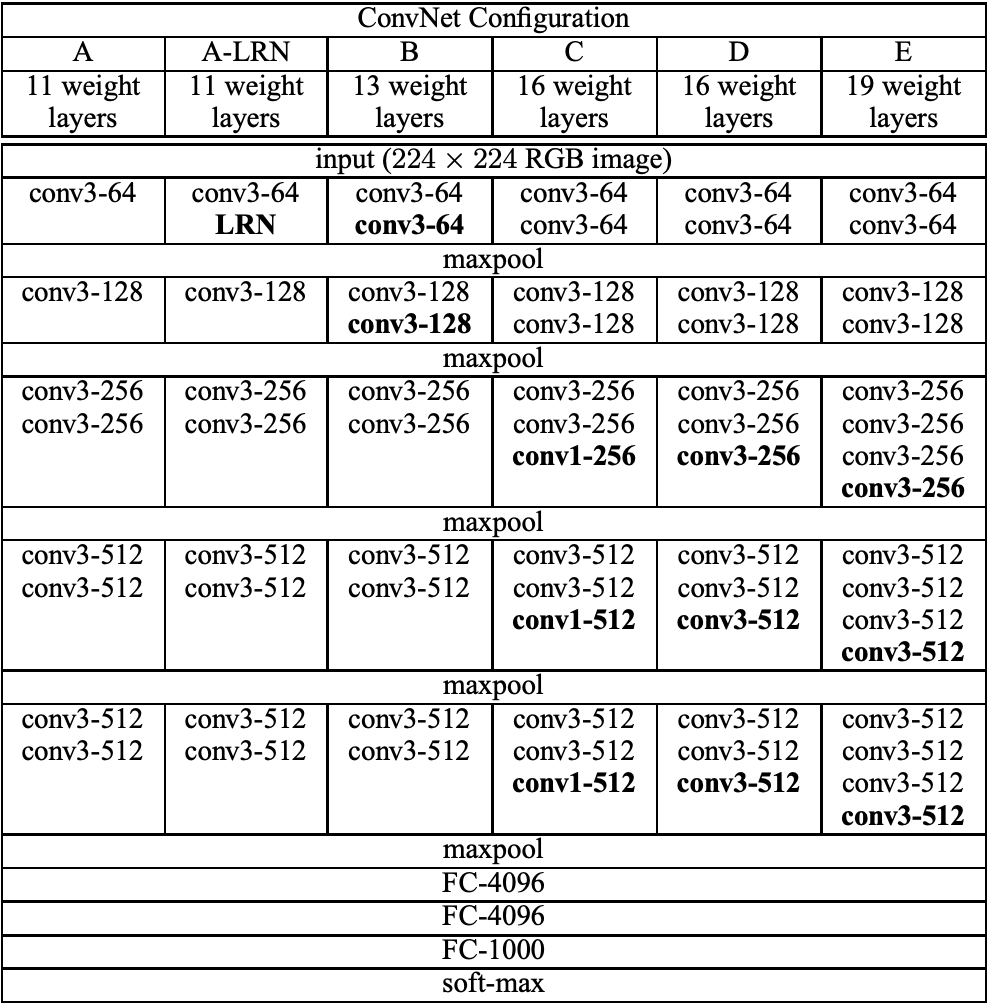
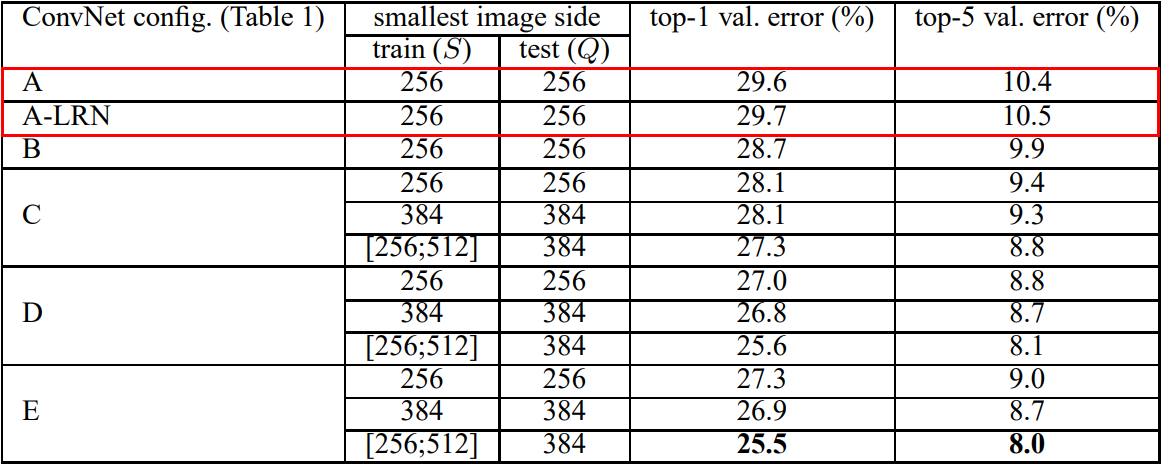
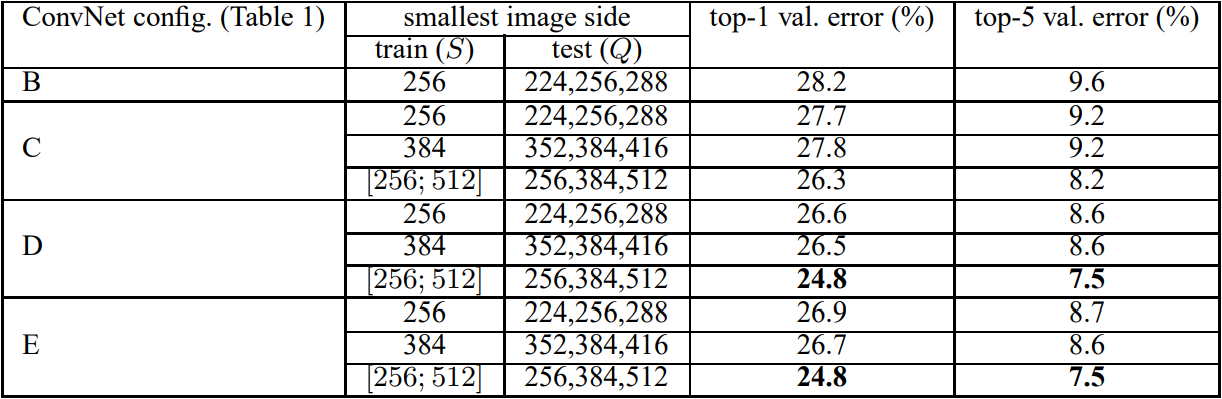
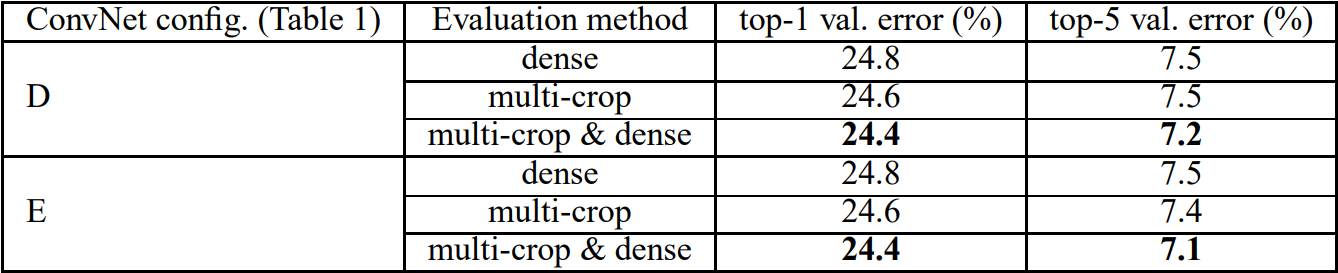
2010년 초/중반 CNN 아키텍처를 활용해 높은 이미지 인식 능력을 선보인 모델은 AlexNet (2012) → VGGNet (2014) → GoogLeNet (2014) → ResNet (2015) → ... 순으로 계보가 이어진다. 이 모델들은 네트워크의 depth와 width를 늘리면서 성능 향상이 이루어지는 것을 보며 점점 depth와 width를 늘려갔다. 하지만 이렇게 네트워크가 커지면서 두 가지 문제점이 발생했다. 첫 번째는 많은 파라미터가 있지만 이를 학습시킬 충분한 데이터가 없다면 오버피팅이 발생하는 것이고, 두 번째는 computational resource는 늘 제한적이기에 비용이 많이 발생하거나 낭비될 수 있다는 점이다. GoogLeNet은 이러한 문제점을 해결하기 위해 fully-connected layer의 neuron 수를 줄이거나 convolution layer의 내부 또한 줄여 상대적으로 sparse한 network를 만들고자 만들어졌다. 결과적으로 GoogLeNet은 가장 초반에 나온 AlexNet보다도 파라미터수가 12배 더 적지만 더 높은 성능을 보이는 것이 특징이다. 결과적으로 GoogLeNet은 ILSVRC 2014에서 classification과 detection 트랙에서 SOTA를 달성했다.
Inception: GoogLeNet 성능의 핵심
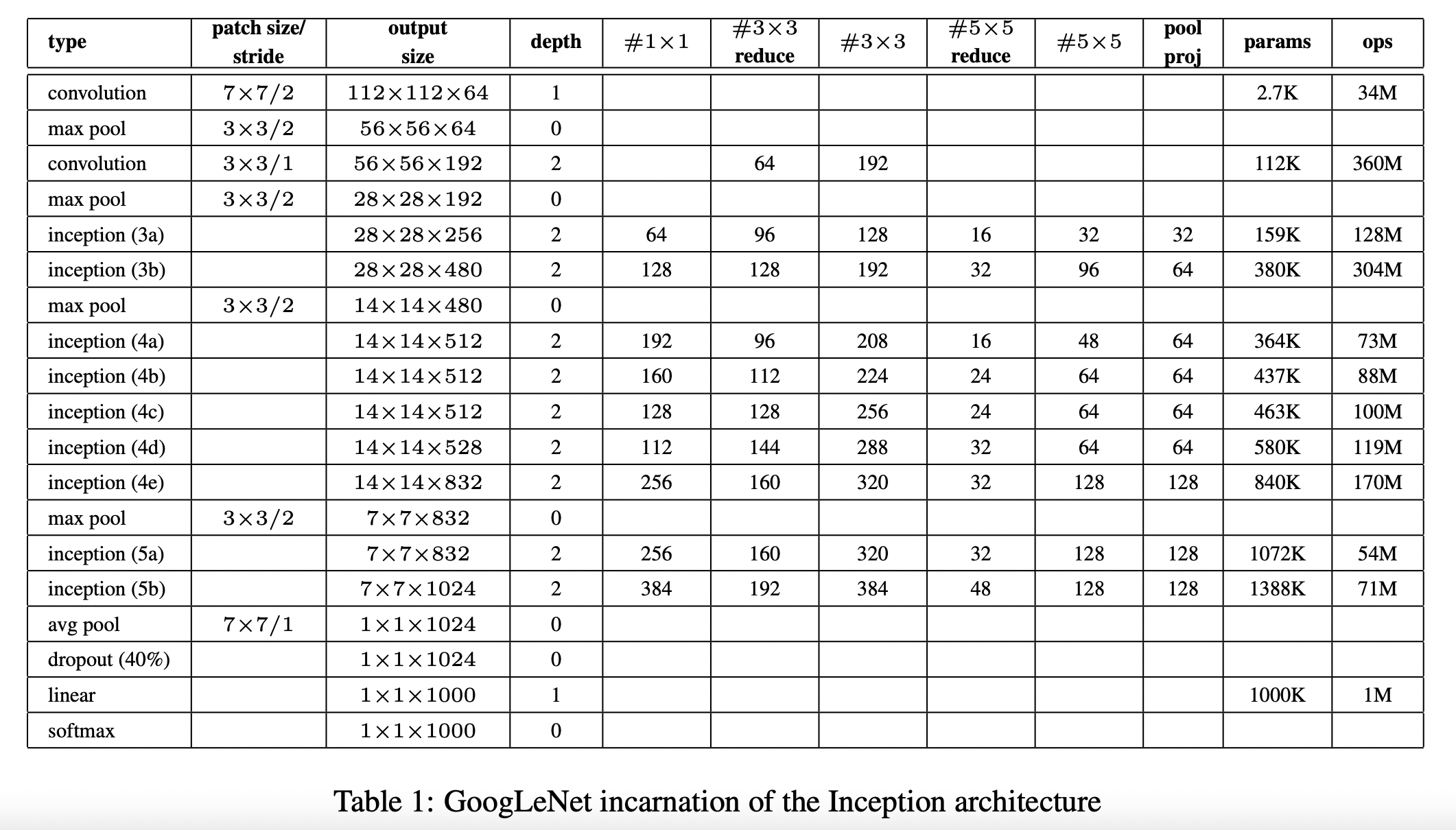
파라미터 효율적이면서도 높은 성능을 낼 수 있는 GoogLeNet 아키텍처의 핵심은 내부 Inception 모듈의 영향이다. Inception 모듈을 보기전 먼저 GoogLeNet 아키텍처를 살펴보면 다음과 같다.
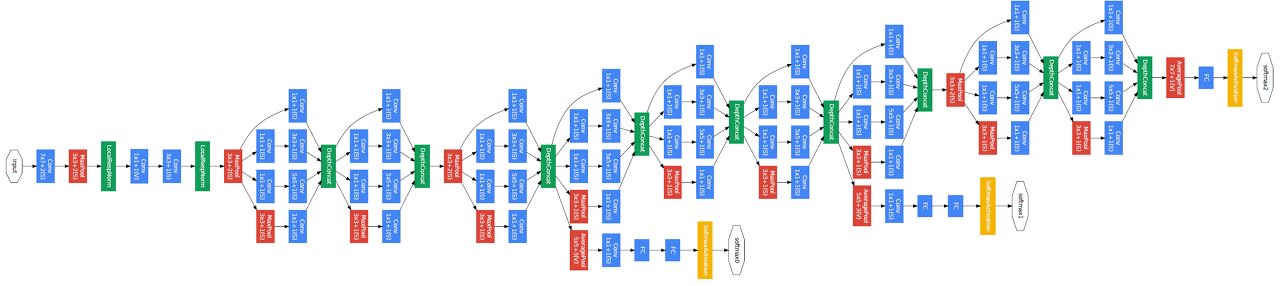
왼쪽(아래)에서 출발하여 오른쪽(위)으로 점점 깊어진다. Inception 모듈은 위 GoogLeNet 네트워크에서 사용되는 부분 네트워크에 해당한다. 그 부분 구조는 아래와 같다. 두 가지 버전이 있다.

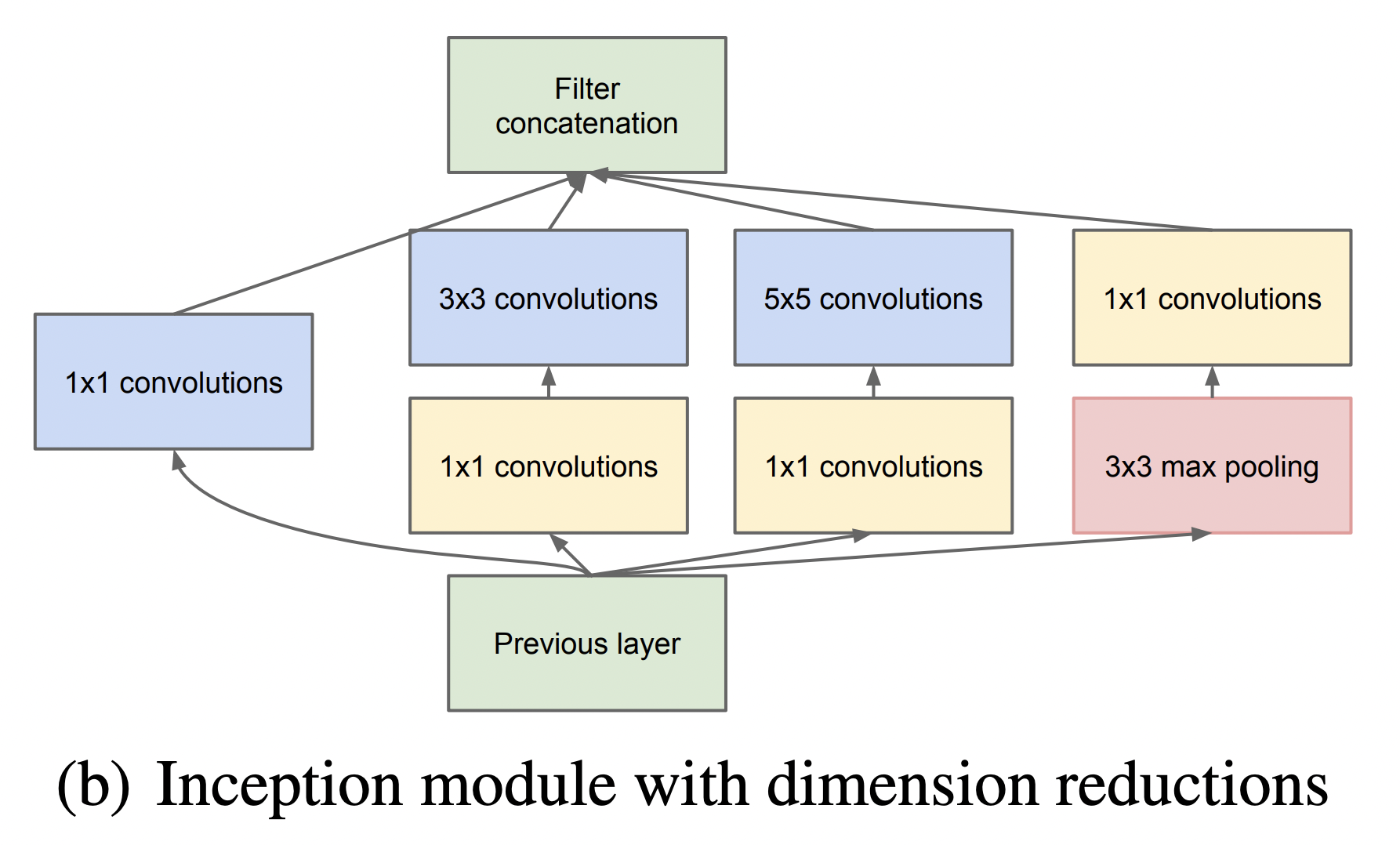
두 버전 모두 이미지 feature를 효율적으로 추출하기 위해 공통적으로 1x1, 3x3, 5x5 필터 크기를 갖는 convolution 연산을 수행한다. 이렇게 이미지의 다양한 영역을 볼 수 있도록 서로 다른 크기의 필터를 사용함으로써 앙상블하는 효과를 가져와 모델의 성능이 높아지게 된다. 참고로 필터 크기를 1x1, 3x3, 5x5로 지정한 것은 필요성에 의한 것이기보다 편의성을 기반으로 했다. 만약 짝수 크기의 필터 크기를 갖게 된다면 patch-alignment 문제라고하여 필터 사이즈가 짝수일 때 patch(필터)의 중간을 어디로 두어야 할지 결정해야하기에 번거로워지기 때문이다.
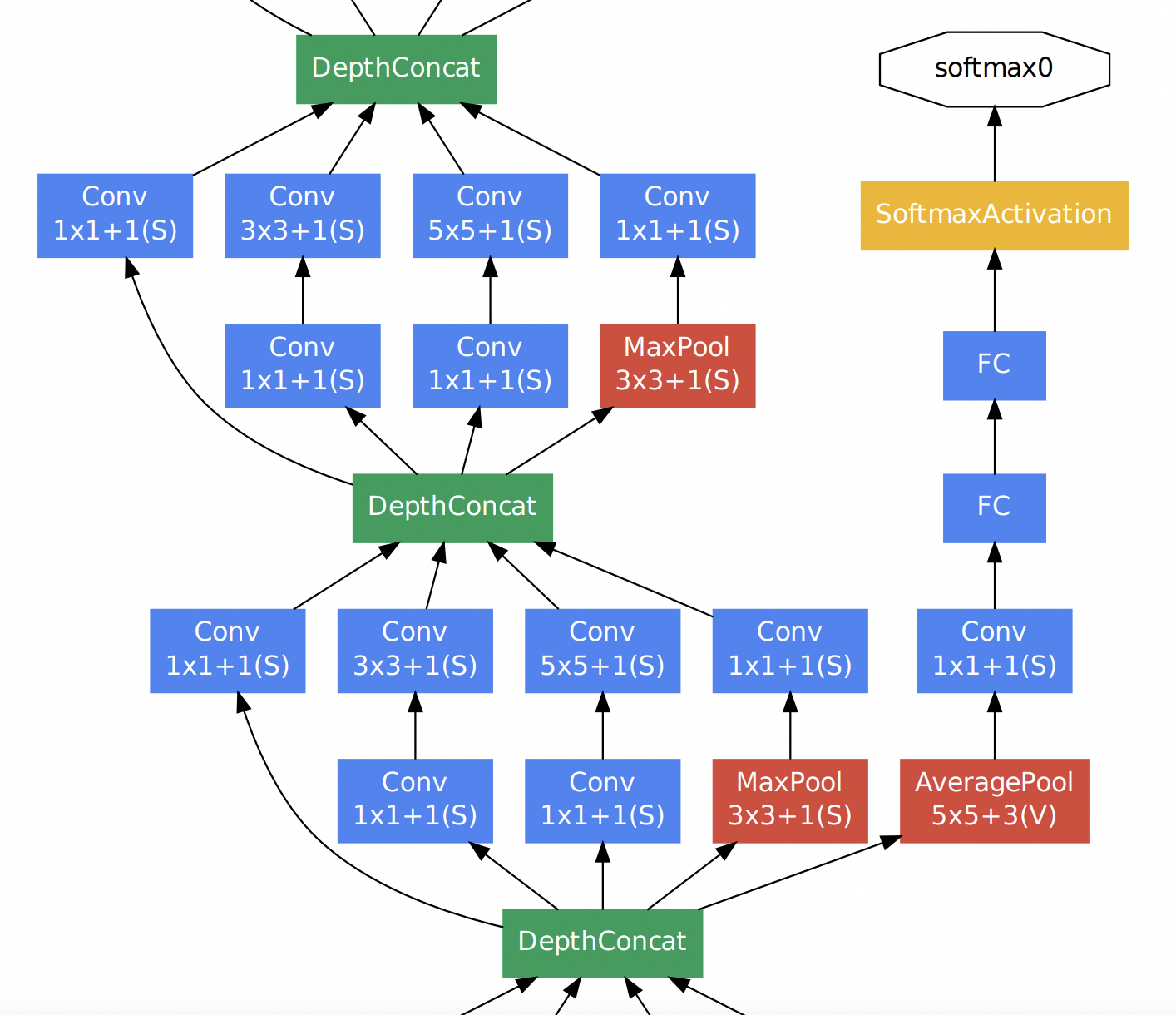
두 버전의 Inception 모듈을 비교해보자면, 먼저 좌측 naive Inception 모듈의 경우 1x1, 3x3, 5x5 convolution 연산과 3x3 max pooling 연산을 병렬 수행한 뒤 concatenation을 통해 결과를 합쳐주는 구조로 되어 있다. 하지만 결과적으로 이는 잘 동작하지 않았다. 그 이유는 convolution 결과와 max pooling 결과를 concatenation하면 기존 보다 차원이 늘어나는 문제점이 발생했기 때문이다. 정확히는 max pooling 연산의 경우 channel 수가 그대로 보존되지만 convolution 연산에 의해 더해진 channel로 인해 computation 부하가 늘어나게 된다. 이 과정을 도식화 한 것은 아래 그림과 같다. (출처: 정의석님 블로그)

위 그림과 같이 output channel의 크기가 증가하여 computation 부하가 커지는 문제점을 해결하기 위해 우측 두 번째 Inception 모듈이 사용된다. 두 번째 Inception 모듈을 통해 output channel을 줄이는 즉 차원을 축소하는 효과를 가져온다. 실제로도 이러한 효과로 인한 computation efficiency 때문에 GoogLeNet 아키텍처에서도 첫 번째 naive Inception 모듈이 아닌 두 번째 dimension reduction Inception 모듈을 사용한다.
그렇다면 두 번째 Inception module에서의 차원축소는 어떻게 이루어질까? 이에 대한 핵심은 1x1 convolution 연산에 있다. 1x1 convolution 연산은 Network in Network (Lin et al) 라는 연구에서 도입된 방법이다. 이름 그대로 1x1 필터를 가지는 convolution 연산을 하는 것이다. 1x1 convolution 연산은 아래 GIF와 같이 동작한다. 그 결과 feature map 크기가 동일하게 유지된다. 하지만 중요한 것은 1x1 filter 개수를 몇 개로 해주느냐에 따라 feature map의 차원의 크기(채널)를 조절할 수 있게 되는 것이다. 따라서 만약 input dimension 보다 1x1 filter 개수를 작게 해준다면 차원축소가 일어나게 되며, 그 결과 핵심적인 정보만 추출할 수 있게 된다.

Global Average Pooling (GAP)
GoogLeNet 아키텍처에선 Global Average Pooling 개념을 도입하여 사용한다. 이는 마찬가지로 Network in Network (Lin et al) 에서 제안된 것으로, 기존 CNN + fully connected layer 구조에서 fully-connected layer를 대체하기 위한 목적이다. 그 이유는 convolution 연산의 결과로 만들어진 feature map을 fully-connected layer에 넣고 최종적으로 분류하는 과정에서 공간 정보가 손실되기 때문이다. 반면 GAP은 feature map의 값의 평균을 구해 직접 softmax 레이어에 입력하는 방식이다. 이렇게 직접 입력하게 되면 공간 정보가 손실되지 않을 뿐만 아니라 fully-connected layer에 의해 파라미터를 최적화 하는 과정이 없기 때문에 효율적이게 된다.
Auxiliary classification
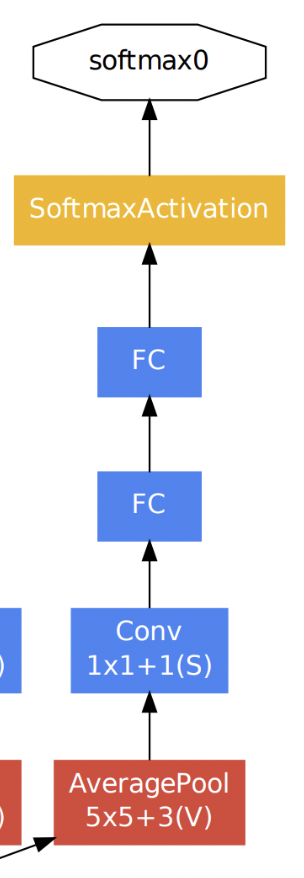
먼저 Auxiliary란 보조를 뜻하는 것으로 Auxiliary classification은 최종 classification 결과를 보조하기 위해 네트워크 중간 중간에 보조적인(Auxiliary) classifier를 두어 중간 결과 값을 추출하는 것이다. 아래 그림은 GoogLeNet 아키텍처를 부분 확대한 것이다. Auxiliary Classification 과정은 이 중 노란 박스 열에 해당한다.
이렇게 Auxiliary classifier를 중간 중간에 두는 이유는 네트워크가 깊어지면서 발생하는 gradient vanishing 문제를 해결하기 위함이다. 즉 네트워크가 깊어지면 loss에 대한 back-propagation이 영향력이 줄어드는 문제를 해결하기 위해 도입된 것이다. 이렇게 함으로써 중간에 있는 Inception layer들도 적절한 가중치 업데이트를 받을 수 있게 된다. 하지만 Inception 모듈 버전이 늘어날수록 Auxiliary classifier를 점점 줄였고 inception v4에서는 완전히 제외했다. 그 이유는 중간 중간에 있는 layer들은 back-propagation을 통해 학습이 적절히 이루어 졌지만 최종 classification layer에서는 학습이 잘 이루어지지 못해 최적의 feature가 뽑히지 않았기 때문이다.
파이토치로 GoogLeNet 구현하기
GoogLeNet 모델의 핵심은 Inception 모듈을 구현하는 것이다.
1. Inception 모듈 구현에 앞서 Inception 모듈에서 반복적으로 사용될 convolution layer를 생성하기 위해 ConvBlock이란 클래스로 다음과 같이 구현해준다. convolution layer 뒤에 batch normalization layer와 relu가 뒤따르는 구조이다.
import torch
import torch.nn as nn
from torch import Tensor
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs) -> None:
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
2. ConvBlock 클래스를 활용하여 Inception module을 구현하기 위한 Inception 클래스를 다음과 같이 구현해준다.
import torch
import torch.nn as nn
from torch import Tensor
class Inception(nn.Module):
def __init__(self, in_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj) -> None:
super(Inception, self).__init__()
self.branch1 = ConvBlock(in_channels, n1x1, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
ConvBlock(in_channels, n3x3_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n3x3_reduce, n3x3, kernel_size=3, stride=1, padding=1))
self.branch3 = nn.Sequential(
ConvBlock(in_channels, n5x5_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n5x5_reduce, n5x5, kernel_size=5, stride=1, padding=2))
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
ConvBlock(in_channels, pool_proj, kernel_size=1, stride=1, padding=0))
def forward(self, x: Tensor) -> Tensor:
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)
Inception 클래스를 확인하면 내부적으로 4개의 branch 변수를 만든다. 이 4개의 branch라는 변수는 각각 아래 Inception module에서 네 갈래로 분기되는 것을 구현해준 것이다.
Inception 모듈에 들어갈 인자는 다음과 같다.
1x1 convolution의 경우 kernel_size=1, stride= 1, padding=0
3x3 convolution의 경우 kernel_size=3, stride= 1, padding=1
5x5 convolution의 경우 kernel_size=5, stride= 1, pading=2
max-pooling의 경우 kernel_size=3, stride=1, padding=1
kernel_size는 아키텍처에 보이는 그대로와 같고, GoogLeNet에서는 stride를 공통적으로 1로 사용했다. 각각의 padding은 추후 네 개의 branch가 합쳐졌을 때의 크기를 고려하여 맞춰준다.
3. Auxiliary Classifier를 구현하기 위해 아래와 같이 InceptionAux라는 클래스로 구현해주었다. 1x1 convolution의 output channel의 개수는 논문에 기술된 대로 128을 적용해주었으며 dropout rate 또한 논문에 기술된 대로 0.7을 적용해주었다.
import torch
import torch.nn as nn
from torch import Tensor
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
super(InceptionAux, self).__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = ConvBlock(in_channels, 128, kernel_size=1, stride=1, padding=0)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=0.7)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.avgpool(x)
x = self.conv(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
InceptionAux 클래스는 아래와 그림과 같이 Auxiliary Classification 과정을 구현해 준 것이다.
4. ConvBlock, Inception, InceptionAux를 활용하여 GoogLeNet을 다음과 같이 구현할 수 있다.
import torch
import torch.nn as nn
from torch import Tensor
class GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=1000) -> None:
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
self.conv1 = ConvBlock(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.conv2 = ConvBlock(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0)
self.conv3 = ConvBlock(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(kernel_size=8, stride=1)
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = None
self.aux2 = None
def transform_input(self, x: Tensor) -> Tensor:
x_R = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_G = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_B = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat([x_R, x_G, x_B], 1)
return x
def forward(self, x: Tensor) -> Tensor:
x = self.transform_input(x)
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool3(x)
x = self.a4(x)
aux1: Optional[Tensor] = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
aux2: Optional[Tensor] = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.e4(x)
x = self.maxpool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1) # x = x.reshape(x.shape[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return aux1, aux2
else:
return x
Inception 모듈에 들어갈 모델 구성은 Table 1의 GoogLeNet 아키텍처를 참고하였다.
전체 코드는 다음과 같이 구현할 수 있다.
import torch
import torch.nn as nn
from torch import Tensor
from typing import Optional
class Inception(nn.Module):
def __init__(self, in_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj) -> None:
super(Inception, self).__init__()
self.branch1 = ConvBlock(in_channels, n1x1, kernel_size=1, stride=1, padding=0)
self.branch2 = nn.Sequential(
ConvBlock(in_channels, n3x3_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n3x3_reduce, n3x3, kernel_size=3, stride=1, padding=1))
self.branch3 = nn.Sequential(
ConvBlock(in_channels, n5x5_reduce, kernel_size=1, stride=1, padding=0),
ConvBlock(n5x5_reduce, n5x5, kernel_size=5, stride=1, padding=2))
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
ConvBlock(in_channels, pool_proj, kernel_size=1, stride=1, padding=0))
def forward(self, x: Tensor) -> Tensor:
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
x4 = self.branch4(x)
return torch.cat([x1, x2, x3, x4], dim=1)
class GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=1000) -> None:
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
self.conv1 = ConvBlock(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.conv2 = ConvBlock(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0)
self.conv3 = ConvBlock(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=0.4)
self.linear = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = None
self.aux2 = None
def transform_input(self, x: Tensor) -> Tensor:
x_R = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_G = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_B = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat([x_R, x_G, x_B], 1)
return x
def forward(self, x: Tensor) -> Tensor:
x = self.transform_input(x)
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.a3(x)
x = self.b3(x)
x = self.maxpool3(x)
x = self.a4(x)
aux1: Optional[Tensor] = None
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.b4(x)
x = self.c4(x)
x = self.d4(x)
aux2: Optional[Tensor] = None
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.e4(x)
x = self.maxpool4(x)
x = self.a5(x)
x = self.b5(x)
x = self.avgpool(x)
x = x.view(x.shape[0], -1) # x = x.reshape(x.shape[0], -1)
x = self.linear(x)
x = self.dropout(x)
if self.aux_logits and self.training:
return aux1, aux2
else:
return x
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs) -> None:
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.batchnorm(x)
x = self.relu(x)
return x
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes) -> None:
super(InceptionAux, self).__init__()
self.avgpool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = ConvBlock(in_channels, 128, kernel_size=1, stride=1, padding=0)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=0.7)
self.relu = nn.ReLU()
def forward(self, x: Tensor) -> Tensor:
x = self.avgpool(x)
x = self.conv(x)
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
return x
if __name__ == "__main__":
x = torch.randn(3, 3, 224, 224)
model = GoogLeNet(aux_logits=True, num_classes=1000)
print (model(x)[1].shape)
위 코드에서 Auxiliary Classifier의 입력 차원 같은 경우는 논문에서 기술된 대로 512, 528을 적용해주었고, fully-connected layer 또한 1024개의 unit으로 설정해주었다.
만약 GoogLeNet으로 간단한 학습을 진행해보고자 할 때 다음과 같이 코드 구현이 가능하다. 다만 CIFAR10 데이터셋을 예시로 사용하므로 위 코드에서 num_classes=10로 바꿔줘야 한다.
import os
import numpy as np
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import argparse
from googlenet import GoogLeNet
def load_dataset():
# preprocess
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load train, test data
train = datasets.CIFAR10(root="../data", train=True, transform=transform, download=True)
test = datasets.CIFAR10(root="../data", train=False, transform=transform, download=True)
train_loader = DataLoader(train, batch_size=args.batch_size, shuffle=True)
test_loader = DataLoader(test, batch_size=args.batch_size, shuffle=False)
return train_loader, test_loader
if __name__ == "__main__":
# set hyperparameter
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', action='store', type=int, default=100)
parser.add_argument('--learning_rate', action='store', type=float, default='0.0002')
parser.add_argument('--n_epochs', action='store', type=int, default=100)
parser.add_argument('--plot', action='store', type=bool, default=True)
args = parser.parse_args()
np.random.seed(1)
seed = torch.manual_seed(1)
# load dataset
train_loader, test_loader = load_dataset()
# model, loss, optimizer
losses = []
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GoogLeNet(aux_logits=False, num_classes=10).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=args.learning_rate)
# train
for epoch in range(args.n_epochs):
model.train()
train_loss = 0
correct, count = 0, 0
for batch_idx, (images, labels) in enumerate(train_loader, start=1):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
output = model.forward(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, preds = torch.max(output, 1)
count += labels.size(0)
correct += preds.eq(labels).sum().item() # torch.sum(preds == labels)
if batch_idx % 100 == 0:
print (f"[*] Epoch: {epoch} \tStep: {batch_idx}/{len(train_loader)}\tTrain accuracy: {round((correct/count), 4)} \tTrain Loss: {round((train_loss/count)*100, 4)}")
# valid
model.eval()
correct, count = 0, 0
valid_loss = 0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(test_loader, start=1):
images, labels = images.to(device), labels.to(device)
output = model.forward(images)
loss = criterion(output, labels)
valid_loss += loss.item()
_, preds = torch.max(output, 1)
count += labels.size(0)
correct += preds.eq(labels).sum().item() # torch.sum(preds == labels)
if batch_idx % 100 == 0:
print (f"[*] Step: {batch_idx}/{len(test_loader)}\tValid accuracy: {round((correct/count), 4)} \tValid Loss: {round((valid_loss/count)*100, 4)}")
# if epoch % 10 == 0:
# if not os.path.isdir('../checkpoint'):
# os.makedirs('../checkpoint', exists_ok=True)
# checkpoint_path = os.path.join(f"../checkpoint/googLeNet{epoch}.pth")
# state = {
# 'epoch': epoch,
# 'model': model.state_dict(),
# 'optimizer': optimizer.state_dict(),
# 'seed': seed,
# }
# torch.save(state, checkpoint_path)
전체 코드: https://github.com/roytravel/paper-implementation
Reference
[1] https://velog.io/@euisuk-chung/파이토치-파이토치로-CNN-모델을-구현해보자-GoogleNet편
[2] https://wikidocs.net/137251
[3] https://github.com/aladdinpersson/Machine-Learning-Collection/blob/master/ML/Pytorch/CNN_architectures/pytorch_inceptionet.py
[4] https://github.com/Lornatang/GoogLeNet-PyTorch/blob/main/model.py
[5] https://github.com/weiaicunzai/pytorch-cifar100/blob/master/models/googlenet.py
[6] https://github.com/soapisnotfat/pytorch-cifar10/blob/master/models/GoogleNet.py
[7] https://github.com/Mayurji/Image-Classification-PyTorch/blob/main/GoogLeNet.py
[8] https://github.com/cxy1997/MNIST-baselines/blob/master/models/googlenet.py
'Artificial Intelligence > 논문 리딩&구현' 카테고리의 다른 글
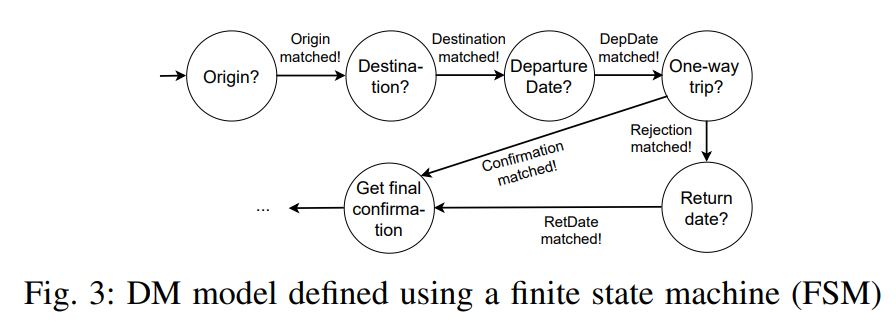
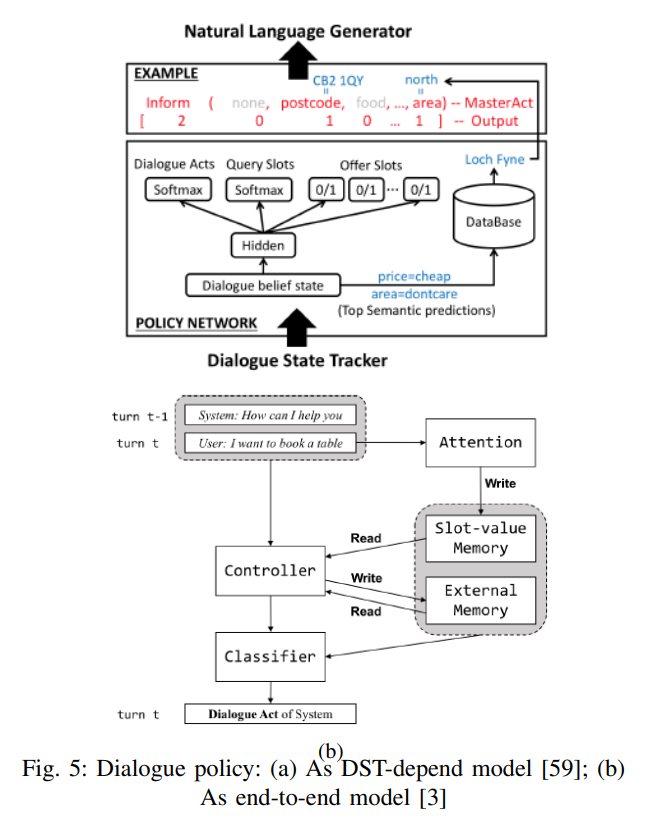
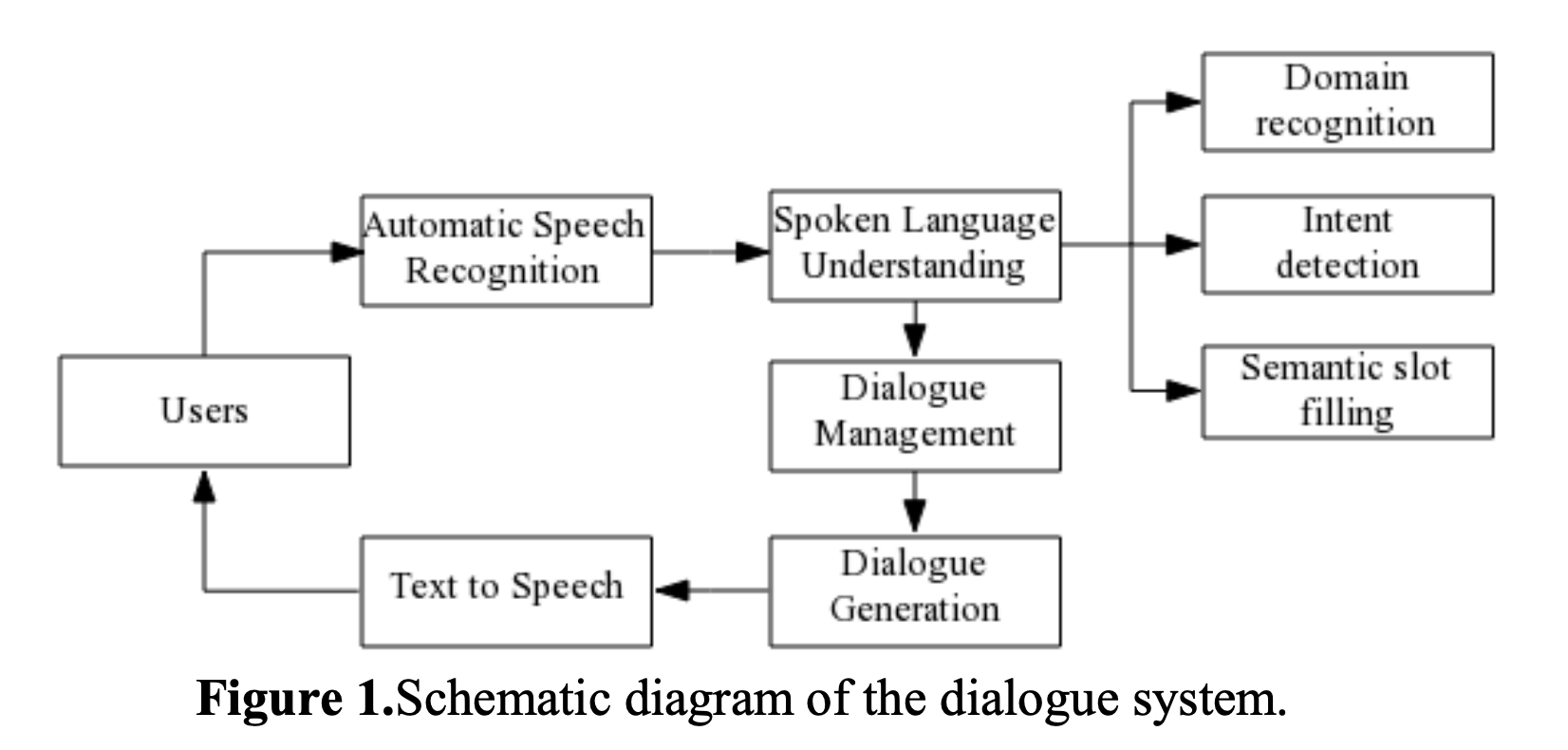
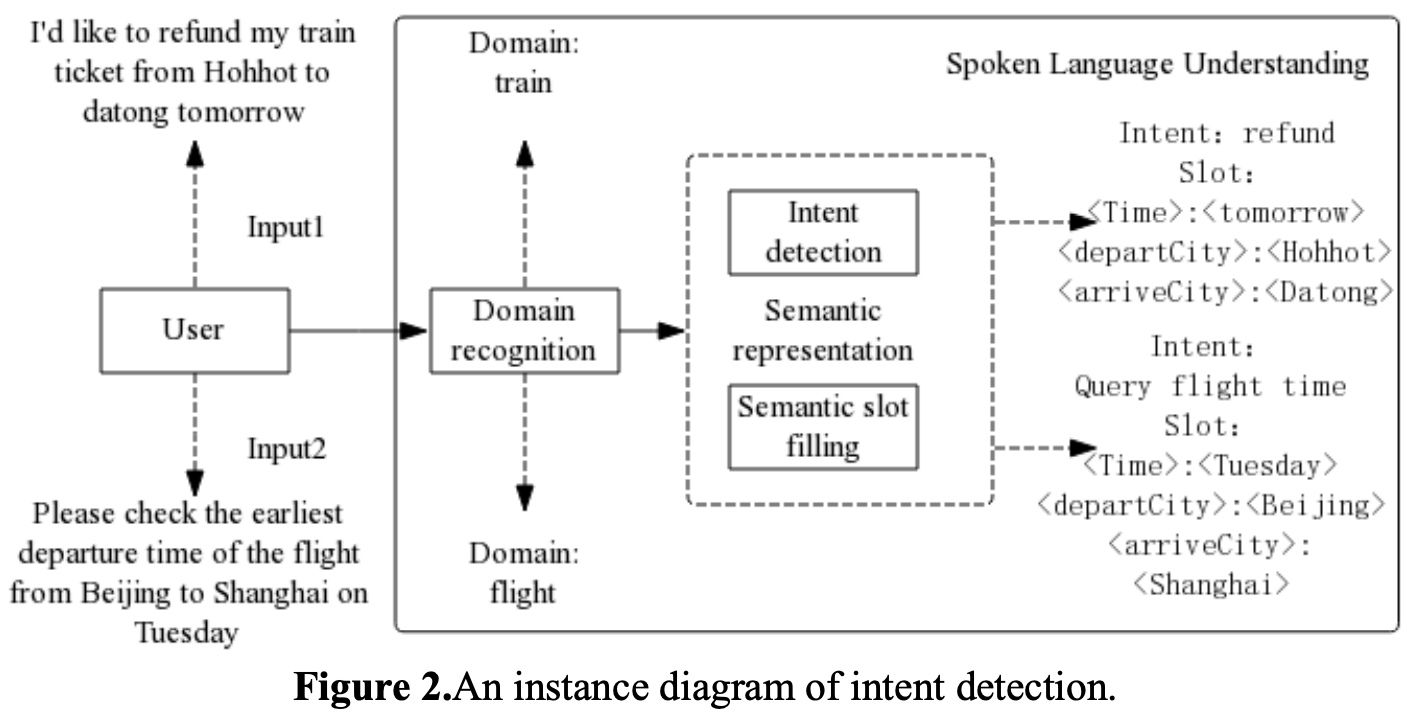
| [논문 리뷰 #4] 멀티 도메인 대화시스템을 위한 도메인 결정 기술 (0) | 2022.11.25 |
|---|---|
| [논문 구현] ResNet 파이토치로 구현하기 (0) | 2022.09.18 |
| [논문 구현] VGGNet 파이토치로 구현하기 (0) | 2022.09.08 |
| [논문 구현] AlexNet 파이토치로 구현하기 (2) | 2022.09.07 |
| [논문 리뷰 #3] Dialogue Management in Conversational Systems: A Review of Approaches, Challenges, and Opportunities (0) | 2022.08.19 |