프래질이라는 것은 쉽게 부서진 다는 의미이다. 하지만 안티 프래질은 쉽게 부서지지 않는다는 의미가 아닌, 고통과 충격을 가할 수록 더 강해진다는 의미이다.
저자는 전 세계 어떤 나라에서도 존재하지 않던 안티 프래질이라는 개념을 창안했다. 이 저자는 2008년 금융위기를 예측했던 것으로 유명하다. 이 책에서 말하는 핵심은 기꺼이 불확실성을 받아들여야 한다는 것이다. 그 이유를 경제, 사회, 정치 다양한 분야에서 안티 프래질이 더 유리한 이유를 설명한다. 불확실성, 스트레스, 무작위성, 가변성과 함께한 삶이라면 우리를 더 번창하게 한다고 말한다.
읽은지 2년이 지났지만 이 책으로 부터 배웠던 것 중 기억나는 것이 있다면 당연한 것이지만, 사회적으로 낮은 계층에 있는 사람을 무시해서는 안된다는 것이다. 자신이 존재할 수 있는 이유는 상대적으로 프래질한 사람이 있기 때문이며 그러한 사람 없이는 자신이 안티프래질해질 수 없다는 것이다.
태어나 처음으로 한 700여 페이지 되는 분량을 읽어 본 책이었다. 인턴 시절 회사 마치고 쪼개고 쪼개서 읽었지만 모르는 것들 투성이었기에 힘들지 않고 오히려 기뻤다. 기꺼이 처음 책을 읽는 내게 나도 두꺼운 책을 읽을 수 있구나 생각하게 만들어준 책이다.
"바람은 촛불 하나는 꺼트리지만 모닥불은 활활 타오르게 한다. 불이 되어 바람을 맞이하라." - 나심 니콜라스 탈레브
우리는 늘 잠을 잔다. 그리고 잠의 효능도 알고 그 중요성에 대해서도 들어보았거나 알고 있다. 하지만 우리 대부분은 겉으로 알고 있지만 그 중요성을 제대로 알지 못해 수면 건강을 챙기지 못하고 있다. 알람 없이 상쾌하게 일어날 수 있는 날이 언제였는가? 아마 대부분은 답하기 어려울 것이다.
수면 주기와 생존 적합도
사람은 개개인별로 3가지 수면 주기가 있다. 첫 번째는 아침형 인간으로 전체인구의 40%에 해당하며, 두 번째는 저녁형 인간으로 전체 인구의 30%에 해당한다. 마지막은 아침형과 저녁형 인간의 중간인 사람들로 전세계 인구의 30%에 해당한다. 왜 사람마다 이런 차이가 발생하게 된 것일까? 가장 설득력 있는 근거는 우리 조상의 생존 적합도를 높이기 위함이라는 것이다. 낮에 사냥과 채집과 같은 활동을 하다가 밤이 되면 잠에 들게 되는데, 이 때 모든 무리의 구성원이 잠을 자게 된다면 외부의 위협으로부터 위험하다. 때문에 두 그룹의 구성원으로 나누어 잔다는 것이다. 가령 첫 번째 그룹은 오후 9시나 10시에 잠이 들어 오전 4시 오전5시에 깬다면 두 번째 그룹은 보초를 서다가 오전 1시나 2시에 잠이 들어 오전 10시나 오전 11시에 깬다는 것이다. 이렇게 함으로써 외부의 위협으로부터 어느정도 안전해질 수 있다. 이러한 방식으로 진화해온 결과가 지금의 수면 주기의 차이를 빚어낸 것이다.
하지만 현대 사회에는 이러한 진화 과정의 차이를 무시한 채 저녁형 인간에게 약간의 불이익을 가하고 있다. 첫 번째는 저녁형 인간이 게으르다는 인식을 심는 것이며, 두 번째는 일과의 시작이 아침형 인간을 중심으로 이루어진다는 것이다. 때문에 저녁형 인간은 오후쯤 되어 활동을 하다가 비교적 늦게 잠이 들게 되는데 일과가 아침에 몰려 있다보니 충분한 수면에 있어 불리함에 놓이게 된다. 이러한 차이를 알고 있는 기업들이 있기 때문에 자율출퇴근제도나 수면실을 갖추게 되는 것으로 보인다. 여담이지만 저녁형 인간에 가까운 나로서는 향후 창업을 할 경우 자율출퇴근제도와 수면실을 반드시 갖출 것이다.
수면의 원인과 카페인
우리는 왜 수면을 할까? 왜 낮에 깨어 있다가 밤이 되면 잠이 올까? 그 답은 수면에 관여하는 단백질인 아데노신에 있다. 우리가 깨어있는 동안 꾸준히 뇌의 어딘가에 아데노신이 쌓이게 된다. 그래프로 표현하자면 시간의 흐름에 따라 하락하지 않고 아데노신이 꾸준히 상승하는 선형에 가까운 그래프라 볼 수 있다. 이 물질이 우리에게 수면 압력을 가하는 물질이다. 때문에 졸음이 쏟아지게 되며 비로소 우리는 잠을 자는 것이다. 잠의 효능 중 하나를 먼저 이야기하면 이 아데노신이 청소된다는 것이다. 하지만 만약 잠을 적게 자거나 못자게 되면 아데노신이 청소되지 않아 다음날도 피로감이 쉽게 찾아오고 잠이 계속 오게 된다는 것이다. 8시간 정도를 자야 아데노신을 말끔히 청소할 수 있다. 사람마다 개인차는 있지만 4~6시간만 자도 괜찮다는 사람은 정말 전 세계적으로 극소수라고 한다. 어느 한 뇌과학자는 전세계에서 5시간 미만으로 자도 괜찮은 사람의 비율을 올림 해도 0이라고 한다. 즉, 우리 모두는 잠을 잘 자는 것에 있어서 벗어날 수 없다는 것이다.
충분한 수면을 하지 못하게 되는 원인 중 하나는 흔히 카페인이 있다. 카페인은 석유다음으로 가장 많이 거래되는 상품으로, 카페인의 효능은 모두 알다시피 각성의 효과가 있다. 약 30분 뒤가 최고조라고 알려져 있다. 하지만 카페인이라고 하는 것이 반감기가 있다는 사실을 아는가? 카페인의 반감기는 평균 5시간에서 7시간이다. 때문에 매일 마시게 되는 사람들은 반감되어 사라지기도 전에 계속 섭취하게 되는 것이다. 이 카페인의 부정적인 측면은 바로 아데노신의 수면 신호를 차단하는 물질이라는 것이다. 밤 늦게 카페인을 마시게 되면 뇌가 반대세력인 카페인에 맞서 싸우게 되기 때문에 쉽게 잠이 오지 않거나 잠을 설치게 되는 것이다. 그렇다고해서 디카페인을 주로 마시는 것도 권장되지는 않는다. 디카페인은 용어 그대로와는 달리 기존 카페인의 15%~30%가 들어 있기 때문에 이름 그 자체와는 거리가 멀다.
수면의 종류와 특징
수면의 중요성을 말하기 위해 먼저 수면의 종류를 살펴볼 것이다. 수면은 크게 비렘수면과 렘수면이 있다. 렘(REM)수면이란 Rapid Eye Movement를 의미하는 것으로 수면 중 우리의 눈이 빠르게 움직이는 수면 상태를 말한다. 우리는 수면도중 이런 비렘수면과 렘수면을 반복적으로 거치게 된다. 여담이지만 렘수면의 주기가 90분인 것을 이용해 1시간 30분 단위로 자면 깨어날 때 조금 덜 피곤하다는 점을 이용하여 수면에 적용하는 사람도 있다. 2년전 우연히 만났던 서울대학교 학생이 그랬다. 처음에는 그런 것도 있구나 하고, 서울대생은 다르구나 느꼈다. 그때까지만해도 단순히 그런 것이 있구나 싶었는데 이런 렘수면의 중요성을 알게 된 것은 최근들어서이다.
여하튼 이런 렘수면과 비렘수면 사이에는 90분이라는 주기가 있다고 했다. 초반부에 비렘수면 상태가 우세하고 후반부에 렘수면 상태가 우세해진다. 비렘수면은 낮 동안 받아들였던 신호를 큼직큼직하게, 덩어리로, Abstract하게 처리하여 기억 다발에다 연결한다. 반면 렘수면은 낮 동안 받아들였던 신호를 미세미세하게, 조각으로, Concrete하게 처리하여 기억다발에다 연결한다. AI에 관심이 있는 사람으로써 AI로 비유를 하자면 BERT라는 자연어처리 모델이 있을 때 일반화된 성능을 위해 pre-training하는 것이 비렘수면의 기능이며 구체적인 태스크를 수행하기 위해 fine-tuning하는 것이 렘수면의 기능이라 이해할 수 있다. 사람은 8시간을 자야 비렘수면과 렘수면을 통해 pre-training, fine-tuning이 가능해지면서 기억을 강화할 수 있다. 하지만 만약 2시간을 덜자서 6시간 밖에 잠을 못잤다면 어떻게 될까? 논리적으로는 25%가 줄었지만 기억을 미세하게 다루는 렘수면 단계가 후반부에 몰려있기 때문에 Concrete하게 처리하는 과정의 60%~90%를 잃게 된다. 이런 렘수면과 비렘수면의 메커니즘 때문에 수면 시간을 충분히 하지 않을 경우 기억 강화에 심각한 손상을 입게 되고 학습 능력에 저하가 오게 된다.
렘수면과 운동신경
잠을 잘 때 누구와 싸우는 꿈을 꾼적이 있는가? 그렇다면 그 때 주먹이 날아가지 않아 답답했던 적은 없는가? 싸우는 꿈을 꿀때면 주먹이 나가지 않아 시원하게 펀치를 날릴 수 없어서 매우 가슴이 언짢은 상태로 깼다. 이는 렘수면의 특징이라고 한다. 렘수면 때 꿈을 꾸게 되는데 렘수면 상태가 되면 몸의 근육 활동이 '불법화' 된다는 것이다. 즉 근육억제체계가 활성화되어 꿈을 꿀 때 몸을 구금시키게 된다. 때문에 몸이 움직이지 않게 되는데 이는 생존을 위한 것이라고 한다. 우리는 잠을 자면서 주위 환경에 대한 의식을 인지하지 못하기 때문에 만에 하나 꿈과 현실을 구분하지 못해 주먹질을 하고 일어나거나 달리게 된다면 위험해진다는 것이다. 자연은 우리가 렘수면을 취하는 동안 우리의 몸이 움직이지 못하도록 프로그래밍 한 것이다. 이런 근육억제체계는 우리가 자라면서 계속해서 형성된다.
우리가 자라면서 근육억제체계가 계속해서 형성되기 때문에 태아 때는 발달 되지 않은 상태이다. 산모의 배에 태아의 손이나 발이 움직이는 것을 본적이 있을 것이다. 태아의 경우 대부분의 상태를 렘수면 상태로 보낸다. 렘수면의 전형적인 특징이 뇌의 전기 활성이 무작위로 솟구치게 되며 그로 인해 태아의 팔다리가 움직이게 되는 것이다. 성인의 경우 렘수면시 근육억제체계가 발달해서 움직이지 못하지만 태아의 경우 근육억제체계가 발달되지 않아 몸이 렘수면 상태임에도 불구하고 움직이게 되는 것이다.
렘수면의 다른 특징으로는 깨어있을 때 집중하는 뇌파와 동일하다는 것이다. 이를 통해 신경 통로들이 무성하게 자라도록 자극하며 각 통로에 시냅스 말단을 풍부하게 덧붙이게 된다. 태아의 발달 2분기 3분기 때 뇌와 구성 부분의 세세한 측면이 빠르게 형성되는데 그 때 렘수면이 대폭 늘어나는 시기이기도 하다. 이는 우연의 일치가 아니며 때문에 우리 성인도 낮 동안 학습한 것을 세세하게 신경다발로 연결하기 위해서는 잠의 후반부에 몰린 렘수면을 충분히 취할 수 있어야 한다는 것이다. 실제로 태어나기 전이나 태어난 직후에 발달중인 아기의 렘수면을 방해하거나 교란하면 후유증이 생기며, 렘수면만 막더라도 태아의 발달 과정이 지체된다.
비렘수면의 특징
비렘수면 시 강한 뇌파가 전두엽에서 생성된다. 이 뇌파가 뇌의 전반에 신호를 보낸다. 추후 아래에서 다시 한번 이야기하겠지만 이 신호는 수면방추라는 뇌파이다. 수면방추가 많이 일어나면 일어날수록 우리는 일어났을 때 개운하다고 느낄 수 있다. 수면방추의 특징은 짧고 강력한 뇌파인데, 운동 신경에도 관여하여 낮에 축적된 피로도를 줄일 수 있다. 또한 학습할 수 있는 일종의 공간을 다시 재마련해주는 일종의 휴지통 비우는 작업을 한다. 실제로 기억하는 자료의 양 사이의 상관관계는 깊은 렘수면을 더 취할수록 다음 날 더 많은 정보를 기억한다. 사람은 기억하라고 한 것과 기억하지 말라고 한 것을 분류하는 작업은 이러한 비렘수면을 취할 때 일어난다.
수면패턴의 변화
인간은 자라면서 수면 패턴이 바뀌게 된다. 크게 다상 수면, 이상 수면, 단상 수면이 있다. 먼저 다상 수면이란 분할 수면을 의미하는 것으로 아이처럼 여러번 일어났다 깼다 하는 수면 패턴을 의미한다. 때문에 다상 수면의 경우 유아기에서 많이 볼수 있는 특징이다. 이러한 다상 수면이 일어나게 되는 원인은 무엇일까? 답은 인간의 몸안에 있는 하루 주기 리듬을 조절하는 기관에 있다. 그 기관은 시교차상핵이라 하여 뇌 속에서 시신경들이 교차하는 지점 바로 위에 존재한다. 역할로는 태양과 같은 빛 신호를 추출해서 약 24시간 주기를 맞춰준다. 하지만 빛 신호가 아니더라도 기온 변화나 규칙적인 음식과 같이 반복되는 신호들에 연동되면 점점 더 강하게 하루 주기 리듬이 맞춰지게 된다.
이러한 이유로 갓 태어난 아기는 시교차상핵에 하루주기리듬이 매여있지 않으므로 첫돌이 지나 일정한 주기가 생길때까지 다상 수면 패턴을 유지게 하게 된다. 만 4세쯤 되면 다상수면 패턴에서 이상 수면 패턴으로 넘어가서 밤에는 쭉자고 낮에 한 차례 정도 낮잠을 자게 되고, 이후 유년기가 끝나게 되면 단상 수면 패턴으로 바뀌면서 낮에 깨어있다가 밤에 자는 패턴이 된다.
기억용량과 수면의 상관관계와 수면방추
해마와 주위 기관
수면은 우리가 낮에 배웠던 학습 내용들을 단기기억에서 장기기억으로 옮기는 역할을 하게 된다. 단기기억에 관여하는 기관은 해마(Hippocampus)로, 일종의 용량 작은 USB이다. 잠을 자면서 해마에 들어 있던 학습 내용을 장기기억에 관여하는 기관인 피질(Cortex)에 옮기게 된다. 피질은 일종의 대용량 하드 디스크(HDD)이다. 잠을 잠으로써 해마에서 피질로 정보가 옮겨지면서 기억 공간의 용량을 확보하는 효과를 누릴 수 있게 된다. 이와 관련해서 실험이 하나 있다. 실제로 학습을 시킨 뒤 낮잠을 잔 그룹과 낮잠을 자지 않은 그룹의 학습 능력과 기억력을 평가한 결과 낮잠을 잔 그룹이 20%가 높다는 연구 결과가 있었다. 즉, 수면이 뇌로 하여금 학습을 가능하게 하는 용량을 복구하여 새로운 기억을 위한 공간을 마련한 것이다.
수면방추 (sleep spindle)
그렇다면 어떤 원리로 새로운 기억 공간을 마련할 수 있는 것일까? 그 답은 수면방추라는 뇌파에 있다. 약 8Hz ~ 14Hz에 해당한다. 이 수면방추는의 특징은 비렘수면 단계때 전기 활성이 짧고 강력하게 치솟게 한다. 낮잠을 잘 때 수면방추가 많이 나타났다면 깨어났을 때 단기 기억 용량을 더 많이 복원한다. 반대로 수면방추가 더 적게 나타나면 단기 기억 용량을 비우지 못했기 때문에 일어났을 때 학습 능력이 저하된다. 비렘수면에서 특이하게 발생하는 이런 수면방추 같은 경우는 아침에 가까울수록 특히 많이 나타난다고 알려져 있다. 정확히는 8시간 수면 중 마지막 2시간쯤에서 수면방추가 가장 많이 치솟는다고 한다. 수면방추는 단기 기억 용량을 늘릴 뿐만아니라 기억력에도 관여한다고 한다. 해야 할 것 기억하지 말아야 할 것을 잘 구분한다고 하며, 이에 대해서 구체적으로 정확히 아는 바는 없지만 솟구치는 전기 활성으로 인해 가진 더 많은 에너지로 넓은 범위의 신경 회로 전달하기 때문이 아닐까 한다.
마지막으로, 수면방추는 운동 신경에도 관여한다고 한다. 운동을 한 뒤 잠을 자게 되면 수면방추는 비렘수면 때 학습했던 운동 역량을 미세하게 다듬는다고 한다. 이를 운동기술기억 향상이라하며 또한 수면방추를 통해 근육피로도를 줄이고 활력을 다시 샘솟게 할 수 있다. 그래서 올림픽과 같은 대회에 서는 선수들의 역량을 가르는 핵심 요인 중 하나로 시합 직전의 낮잠이 있다고도 한다. 실제로 우사인볼트는 대회 몇 시간 전에 낮잠을 자고 일어나 세계기록을 세웠다.
수면과 질병의 상관관계
기억력 저하 노년이 되면 잠이 잘 오지 않는다고들 한다. 하지만 이런 양상과는 달리 노년에도 청년이나 중년처럼 많은 잠이 필요하다. 다만 필요한 만큼 잠을 잘 수 없을 뿐이다. 40대 중후반으로 들어서게 되면 10대 때 누렸던 깊은 수면 중 60% ~ 70%가 사라진다고 한다. 여기서 핵심 문제점은 깊은 수면이 줄어드는 것 뿐만 아니라, 우리가 잠을 얼마나 푹 잤는지 평가할 수 있는 평가지표가 없다는 것이다. 즉 사람들이 자신이 늙어 갈수록 자신의 깊은 잠의 양과 질이 얼마나 떨어지는지 깨닫지 못한다. 이로 인해 노인들은 수면악화와 건강악화가 연결되어 있음을 알아차리지 못하게 되는 것이다. 수면이 만성적으로 악화, 교란된다면 신체 질병이나 정신 건강 불안정, 각성도 저하, 기억 장애가 발생하게 된다.
나이가 들면 가장 극적으로 퇴화하는 영역은 전두엽이다. 전두엽의 역할 중 하나는 비렘수면 시 강한 뇌파를 생성하여 뇌의 전반에 신호를 보내주는 역할을 한다. 하지만 비렘수면과 관련된 전두엽의 기능이 떨어지면서 뇌의 전반에 신호를 보내지 못하게 된다. 이로 인해 수면의 양과 질이 떨어지게 되는 것이며, 이로 인해 학습 능력이 떨어지고 결과적으로 기억력이 저하 된다. 노년에 나타나는 이런 기억력 저하와 수면 악화의 경우 우연의 일치가 아닌 것이다.
자폐증 렘수면 부족은 자폐증과도 연관성이 있다. 자폐증의 핵심 증상은 사회적 상호 작용의 부족이라 할 수 있다. 자폐의 정확한 원인은 제대로 밝혀지지 않았지만 뇌 초기 발달 단계 때 시냅스 형성 과정에서 부적절한 배선이 장애의 핵심이라고 여겨지고 있다. 여기서 흥미로운 것은 자폐 진단을 받은 자폐아의 수면 패턴과 비자폐아의 수면 패턴이 다른데, 수면 패턴 차이점의 핵심은 렘수면 부족이다. 앞서 언급한 바와 같이 학습한 내용을 렘수면을 통해 우리 신경 회로들을 추가하고 붙이는 역할을 하지만 그 회로가 잘못 놓여 있고, 그 회로를 형성에 관여하는 렘수면이 매우 적다는 것이다. 실제로 자폐아의 경우 비자폐아에 비해 렘 수면 양이 30% ~ 50%가 부족하다고 알려져 있다.
수면 장애 불면증이나, 수면과다증, 기면증의 경우 수면방추가 비정상적으로 감소하거나 증가됨으로써 발생한다. 만약 불면증 환자라면 수면방추를 늘려주는 방식으로 수면 장애를 치료할 수 있고, 수면과다증 환자의 경우 수면방추를 감소시켜주는 방식으로 수면 장애를 치료할 수 있다.
알츠하이머 실제로 비렘수면이 제대로 이루어지지 않으면 알츠하이머 발병에 많은 확률을 높인다. 알츠하이머는 베타아밀로이드라는 물질이 뇌안에 쌓이면서 발생하게 된다. 참고로 베타아밀로이드는 알츠하이머의 직접적인 원인은 아니다. 하지만 알츠하이머 환자를 분석했을 때 베타아밀로이드라는 일종의 끈적한 단백질이 쌓여 있어 주요 바이오 마커가 된다. 원래 베타아밀로이드는 원래 우리 몸의 방어기제로서 생성되는 긍정적인 단백질이다. 우리 몸에 독소가 들어와 시냅스를 파괴하려고 할 때 독소들을 끈끈하게 만들어 시냅스 파괴를 하지 못하도록 만든다. 정상적으로 생성된 베타아밀로이드는 비렘수면 때 나오는 글림프계의 뇌척수액에 의해 씻겨내려간다. 하지만 비렘수면이 줄어들게 된다면 뇌척수액에 다 씻겨내려가지 못한 부분이 남아있게 되고 이게 축적되면 알츠하이머가 되면서 되려 시냅스를 파괴하여 인지기능의 저하와 나아가 자신 스스로를 잊게 되는 증상을 가져오오게 되는 것이다. 실제로 생쥐를 비렘수면에 들지 못하게 막았다니 그 즉시 뇌안에 아밀로이드가 쌓이는 연구 결과가 있었다. 이렇듯 부족한 잠은 알츠하이머병을 유발하고 상호작용하면서 악순환을 일으키기 때문에 수면은 중요하다.
졸음운전과 미세수면
수면을 충분히 취하지 못하면 운전석에서 일시적으로 집중력을 상실하는 미세수면에 빠질 수 있게 된다. 미세수면 때는 우리 뇌는 잠시 바깥 세계와 단절이 된다. 시각 뿐 아니라 모든 지각 영역이 그렇다. 그 시간에 어떤 일이 일어났는지 지각하지 못한다. 실제로 경험을 해보니 확 느끼게 되었다. 운전면허시험 때 하룻밤을 새고 갔더니 정지 신호 받은 뒤 약 몇 분간의 시간이 블랙아웃되어 사라지는 경험이 있었고 정말 주의할 필요가 있다는 교훈을 얻게 됐다. 실제로 오전 7시부터 온종일 깨어있다가 새벽에 차를 몰고 귀가할 때는 음주 운전자만큼 지장을 받는다고 한다. 수면시간감소와 자동차 사고 사망률 그래프는 기하급수적인 양상을 띤다. 졸음운전은 음주운전과 위험 수준이 동일하다.
감정 조절과 수면
수면이 부족하게 되면 뇌의 양쪽에 있는 편도체에서 감정 반응을 60% 증폭시킨다. 잠이 부족하게 되면 뇌가 통제가 안되는 원시적인 양상으로 돌아가게 된다. 구체적으로 수면을 제대로 취하지 못하게 되면 편도체와 전전두엽피질 사이의 불균형이 발생한다는 것이다. 편도체는 일종의 감정가속폐달과도 같고 전전두엽피질은 브레이크와도 같은데 잠을 잘 못자게 되면 이 둘 사이의 강한 연결이 끊기게 된다고 한다.
"우리는 얼마나 수면부족이 우리에게 영향을 미치는지 알지 못한다. 모든 사람이 일관되도록 자신의 수행 능력 감소를 과소평가 한다"
3년전 캐글에 올라온 주제인 Real and Fake Face Detection이라는 competition이 있다. 소셜 네트워크를 사용할 때 가짜 신분을 사용하는 사람이 있고 이를 탐지하여 WWW을 더 나은 곳으로 만들자는 것이 이 competition의 목적이다.
Competetion의 핵심 task는 크게 아래 2가지를 탐지하는 것이다.
1. 데이터셋 내에서 변조된 얼굴 이미지와 변조되지 않은 얼굴 이미지를 분류하는 것
2. 만약 얼굴 이미지가 변조되었다면 변조된 영역을 분류하는 것
변조된 영역은 아래와 같이 네 부분으로 나뉜다. 왼쪽 눈, 오른쪽 눈, 코, 입이다.
2. 데이터셋 구성 및 특징
데이터셋의 경우 포토샵 전문가가 변조/합성한 얼굴 이미지와 변조/합성하지 않은 얼굴 이미지로 구성되어 있다. 이렇게 포토샵으로 만들어진 데이터셋의 경우 GAN 기반의 데이터셋과 비교가될 수 있다. 이 데이터셋을 만든 배경은 GAN으로만은 충분하지 않다는 것이다. GAN은 Fake 이미지를 생성하기 쉬울 뿐더러 포토샵 전문가가 만드는 것과 GAN이 만드는 메커니즘 자체가 다르기 때문에 GAN이 학습한 패턴은 무의미할 수 있다는 것이다.
데이터셋 폴더 구성은 아래와 같다.
데이터셋은 크게 두 개로 훈련 데이터셋(real_and_fake_face_detection)과 테스트 데이터셋(real_and_fake_face)으로 구성되어 있고, 이는 다시 각각 합성 이미지(training_fake)와 원본 이미지(training_real)로 구성되어 있다. 특히 합성 이미지의 경우 난이도가 크게 3가지로 easy, mid, hard로 나뉜 것이 특징이며 아래와 같이 mid 난이도만 되어도 시각적으로 합성 여부 탐지가 어려운 것이 특징이다.
mid_389_1101.jpg
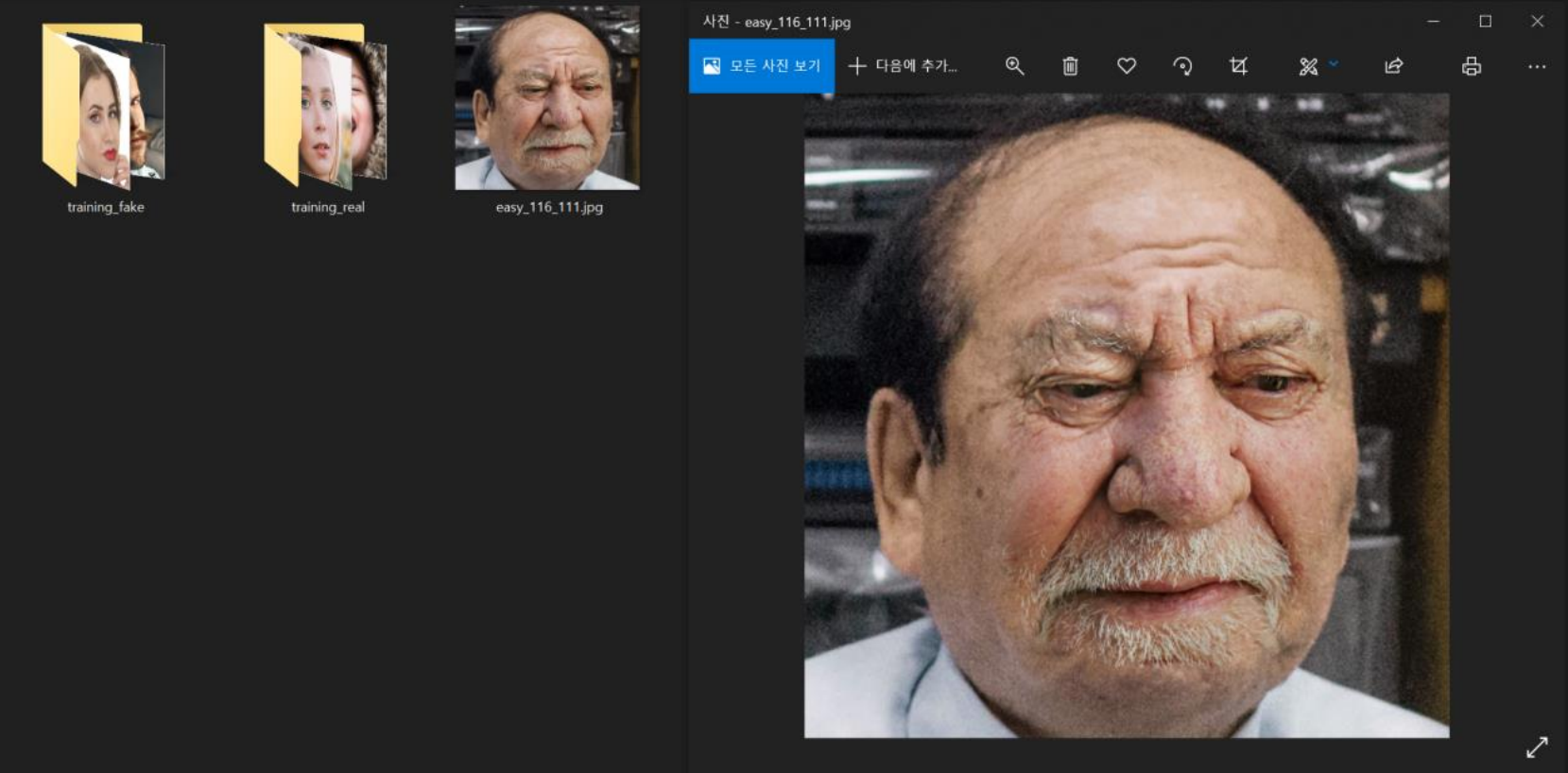
라벨링된 이미지를 확인하던 도중 아래와 같이 라벨링이 잘못되어 있어 학습에 사용하기 어려운 이미지를 확인하였고, 따라서 아래의 해당 이미지는 학습에서 제외하였다.
라벨링 오류 데이터셋 (easy_116_111.jpg)
따라서 본 Task를 수행하기 위해 아래와 같이 총 4,080장의 데이터셋을 이용하였다.
구분
폴더명
장수
중합
총합
train
training_fake
959장
2,040장
4,080장
training_real
1,081장
test
training_fake
959장
2,040장
training_real
1,081장
캐글에서 배포하는 이 데이터셋에서 아쉬운 점은 크게 두 가지가 있는데 첫 번째는 폴더 구성이 그다지 직관적이지 않다는 것이며, 두 번째는 training set과 test set이 동일한 데이터셋으로 구성되었다는 것이다. 그러다 보니 결과적으로 높은 성능이 나오기 쉬운 구조다. 하지만 본 데이터셋을 통해 캐글에 처음 입문하는 케이스로는 해볼만 하다고 판단된다.
3. 관련 연구
관련 연구를 찾기 위해 SOTA (State Of the Art) 연구를 모아둔 Paperswithcode라는 사이트에서 fake face detection과 관련된 자료를 찾던 도중 아래와 같은 연구를 확인할 수 있었다.
논문을 리뷰해본 결과 위 연구에서 사용하는 데이터셋이 GAN으로 만들어진 것이 아니라 본 competition과 동일하게 포토샵 기반의 데이터셋을 이용하는 것을 확인하였다.
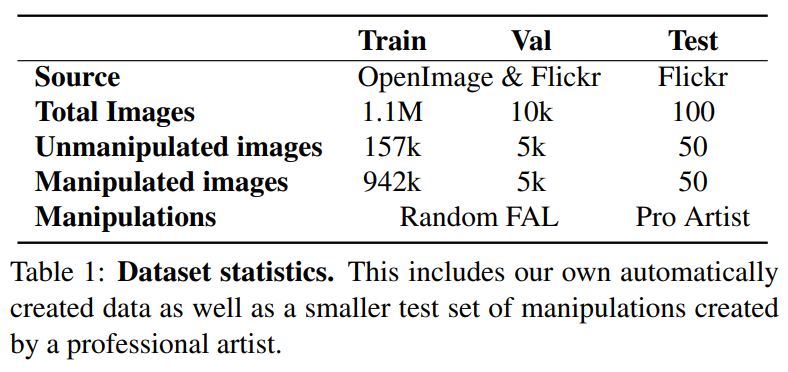
위 연구에서 실험을 위해 OpenImage와 Flickr에서 데이터셋을 마련하였으며 크게 변조되지 않은 이미지와 변조된 이미지로 구성하여 훈련, 검증, 테스트 셋으로 나누었다. 변조된 이미지의 변조 방법의 경우 Random FAL(일종의 변조 자동화 포토샵 스크립트)과 Pro Artist가 변조하는 방법을 사용하였다.
저자는 실험을 위해 크게 두 가지 모델을 만들었다. 이는 얼굴이 합성되었는지를 여부를 식별하는 글로벌 분류 모델과 합성된 위치를 예측하는 로컬 분류 모델이다. 따라서 위 연구를 기반으로 본 competetion에서도 합성 탐지 여부 모델과 합성 부위 예측 모델을 만들었다.
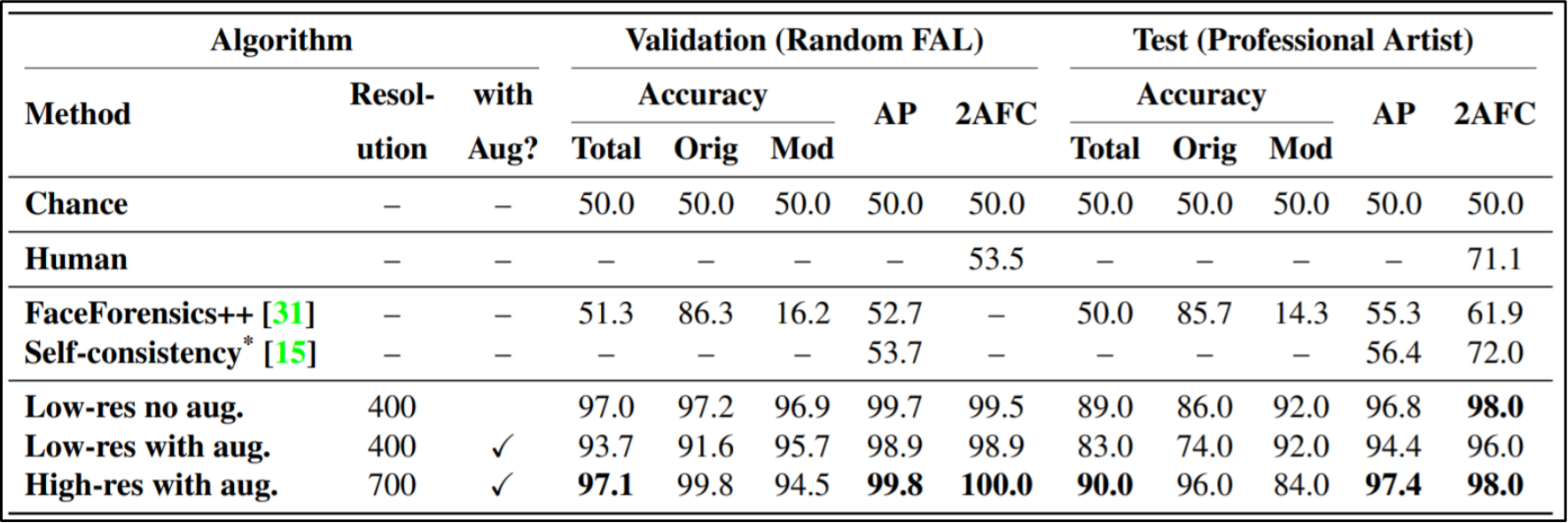
저자들은 실험을 위해 ImageNet 데이터셋으로부터 Pretrained된 DRN(Dialted Residual Network)의 변형인 DRN-C-26 모델을 사용하였다. 이를 통해 얻은 실험 결과는 다음과 같다.
저자들은 모델에 대해 스크립트를 통해 랜덤으로 변조한 Random FAL 방식과 프로 아티스트가 변조한 Professional Artist 방식에 대해 모델의 성능을 측정하였다. 성능 측정 결과, 고해상도의 인풋이 들어가면 더 높은 성능을 보이는 것을 확인하였다. 또한 augmentation이 없이 학습된 것이 더 뛰어난 것을 보였으나 augmentation을 적용한 것이 반대로 조금 더 모델이 robust한 결과를 보인다 하였다.
4. 모델 구현
4.1 원본/합성 판별 모델
위 관련 연구의 실험에 기반하여 이미지의 원본/합성 판별을 위한 모델과 합성된 위치를 예측하는 모델로 크게 두 개를 구현하였다. Pretrained Model을 사용하지 않고 학습을 위해 두 모델 모두 이미지 처리에 효율적이라 판단되는 Convolution Neural Network를 사용하였다.
4.1.1 레이어 구성
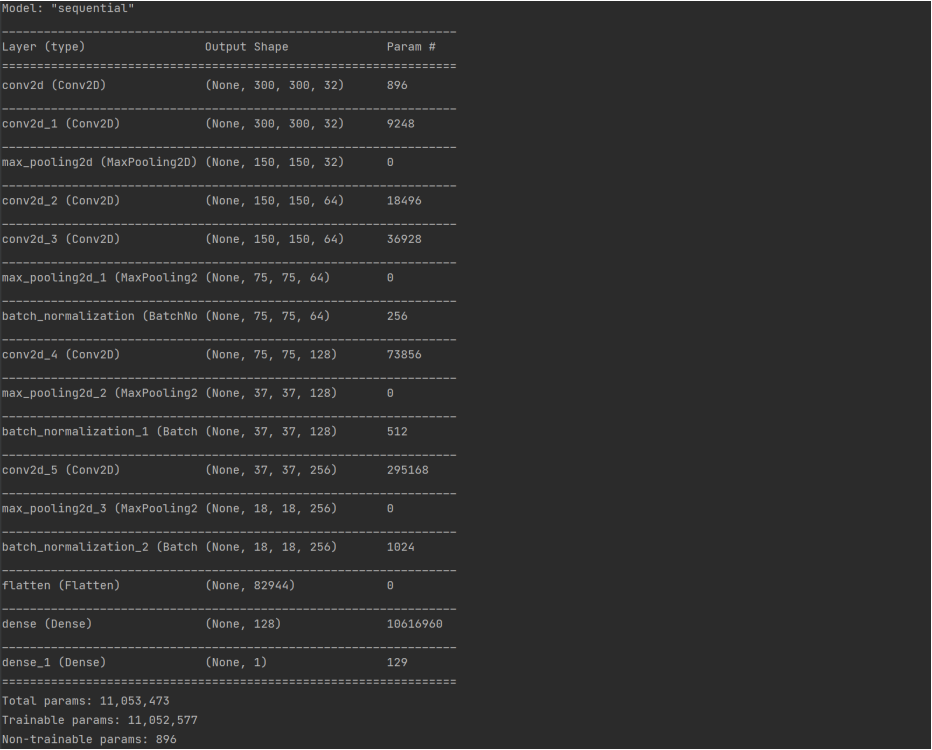
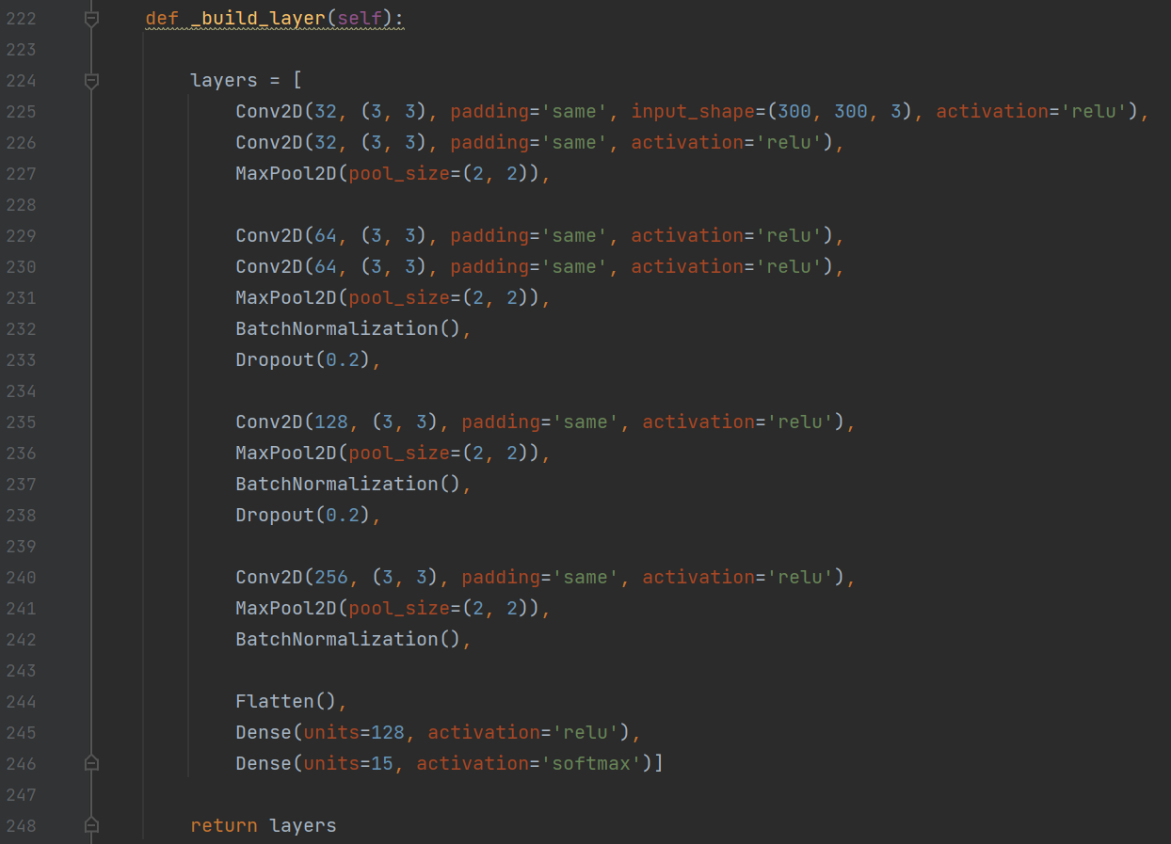
원본/합성 판별 모델 (syn_detect_model)
모델에 입력되는 이미지의 사이즈는 원본의 경우 600x600이나 원본 그대로 모델 학습시켜본 결과 시간이 오래 걸린다는 단점이 있어 300x300으로 축소하여 모델의 Input으로 지정하였다. 이후 Convolution 2D, Max Pooling, Batch Normalization, flatten, Dense 레이어로 모델을 구성하였고 출력 부분에는 sigmoid 함수를 통해 이진 분류가 가능하도록 하였다.
4.1.2 모델 학습 결과
학습 초반에는 위와 같이 loss 값이 0.9013, accuracy 0.5162로 시작하는 것을 확인할 수 있었고, 학습 종료 시점에는 아래와 같이 loss 값이 0.0479, accuracy가 0.9931임을 확인할 수 있었다. 또한 추가적인 다른 metric을 통해서도 학습이 전반적으로 잘 이루어지는 것을 확인할 수 있었다.
4.2 합성 위치 예측 모델
4.2.1 레이어 구성
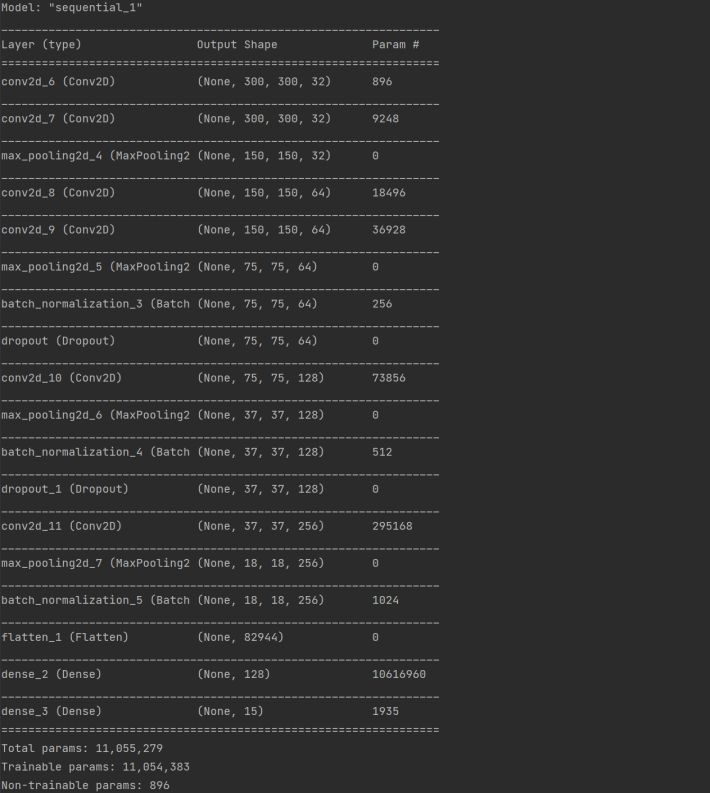
합성 위치 예측 모델 (loc_detect_model)
합성 위치 예측 모델 또한 원본/합성 탐지 모델과 거의 동일한 구조를 가지고 있다. 차이점은 학습 과정에서 빠른 과적합이 이루어지는 것을 확인하였다. 따라서 Dropout 레이어를 추가하였고 출력 부분에는 라벨을 15개로 지정하여 softmax 함수를 통해 출력되도록 하였다. 라벨에 대한 구체적인 내용은 실험 부분에 기술하였다.
4.2.2 모델 학습 결과
학습 종료 시점에 아래와 같이 loss 값이 0.0586, accuracy가 0.9875임을 확인할 수 있었고 추가적인 다른 metric을 통해서 학습이 전반적으로 잘 이루어져 있음을 확인할 수 있었다.
5. 실험
5.1 원본/합성 판별 모델
5.1.1 이미지 어그멘테이션 (Image Augmentation)
어그멘테이션을 진행하지 않고 원본/합성 탐지 모델을 학습한 결과 충분한 성능이 도출되지 않았다. 때문에 어그멘테이션 작업을 필요로 했고 아래와 같은 옵션을 사용하여 어그멘테이션을 진행하였다.
구분
옵션
값
비고
훈련 데이터셋
horizontal_flip
True
수평 플립
vertical_flip
False
수직 플립
shear_range
0.2
기울기 비율
zoom_range
0.2
확대 비율
rescale
1/255.
이미지 스케일링
테스트 데이터셋
rescale
1/255.
이미지 스케일링
validation_split
0.2
훈련/평가 분할 비율
모델의 Robustness를 위해 수평 플립을 True로 설정하였고 기울기와 확대 비율에 대해 주로 사용되는 값인 0.2를 설정하였다. 또한 훈련 데이터셋과 테스트 데이터셋에 대해 각각 이미지 스케일링을 적용하였고 테스트 데이터셋에 대해서는 0.2 비율로 평가와 테스트 데이터셋으로 나누었다. 어그멘테이션 옵션을 적용한 결과는 다음과 같다.
Training 데이터셋 2,040장 Validation 데이터셋 1,633장 Test 데이터셋 407장에 대해 어그멘테이션을 진행하였다.
5.1.2 모델 레이어 구성
6개의 Convolution 2D 레이어와 3개의 Maxpooling 2D 레이어, 그리고 3개의 Batch Normalization 레이어를 구성하고 출력부분에는 활성화 함수로 sigmoid를 사용하여 합성 여부를 탐지할 수 있도록 만들었다. Dropout의 경우 모델이 과적합되지 않아, 별도로 적용하지 않았다. 모델의 옵티마이저는 RMSProp을 사용하였고 learning rate 값으로 0.00001을 사용하였다.
모델 구성의 순서에서 CS231n 강의 기준으로 Conv2D → BatchNorm → MaxPool2D 순으로 쌓는 것이 적합하다 하였으나 Conv2D → MaxPool2D → BatchNorm 형태로 구성하는 것이 더 학습 성능이 좋은 것을 실험적으로 확인하였다.
5.1.3 모델 학습 결과
100회의 에폭을 통해 학습한 결과는 아래와 같다.
학습 과정
Early Stop을 적용하여 58번째 에폭에서 종료되었고, 점진적으로 loss가 줄고, accuracy가 증가하는 양상을 확인할 수 있었다. 부가적으로 precision, recall, auc에 대한 평가 metric을 추가하여 확인할 수 있도록 하였다. 학습된 모델에 대해 validation set으로 평가한 결과 아래와 같다.
결과 값으로 Loss값 5.6%, Accuracy값 98.7%, Precision 99.4%, Recall 98.0%, AUC 99.9%을 확인할 수 있다.
또한 별도의 인퍼런스 모듈을 생성하여 아래와 같이 확인하였다.
Inference 과정
최종적으로 합성 여부 탐지를 위해 Test 데이터셋의 모든 fake 이미지를 넣은 결과 위와 같이 대부분의 이미지가 올바르게 Inference되는 것을 확인할 수 있고, 일부 Real로 오분류 되는 것 또한 확인할 수 있다. Inference를 통해 최종적인 F1 Score의 경우 98.8%의 성능을 보임을 확인하였다.
F1 Score
5.1.4 손실함수 및 정확도 그래프 시각화
모델 학습의 초반부에 변화가 심한 양상을 보이기도 하나 점차 변화 폭이 좁아지면서 안정적으로 학습되는 것을 확인할 수 있다. Loss는 약 0.9에서 시작하여 0.05까지 줄어들며, Accuracy는 약 0.55부터 시작하여 0.99에 근접하게 학습되는 것을 확인할 수 있다.
5.2 합성 위치 예측 모델
5.2.1 데이터 프레임 생성
합성 여부와 달리 합성 위치에 대한 예측 모델을 만들기 위해서는 별도의 formal한 구조로 만들어 두어야 학습에 용이할 것이라 판단되어 아래와 같이 판다스(Pandas) 라이브러리를 이용하여 데이터프레임을 생성하였다.
Dataframe 생성
파일 이름의 합성 부위를 나타내는 4자리의 숫자만 추출하여 각각의 필드로 나타내었다. 특이한점은 label이라는 컬럼을 만들었는데 이는 기존 left_eye, right_eye, nose, mouth와 같이 별개의 컬럼을 라벨로 지정하여 학습을 시도한 결과, 방법론을 잘못 적용한 것인지 학습 결과가 좋지 않았다. 마지막 레이어에 sigmoid 또는 softmax로 Unit을 4로 설정하여도 학습 결과가 미미한 것을 확인하였다. 전반적으로 모델 설계 방식에 대한 방법론 조사를 시도했으나 크게 찾지 못하였다. 하지만 조사 도중 일부 예시에서 위와 같이 개개 별로 나누는 것이 아닌 하나로 통합하여 라벨로 두는 방법을 찾아 있는 것을 확인하였고, 이를 적용하였더니 학습 결과가 개선되는 것을 확인할 수 있었다.
5.2.2 이미지 어그멘테이션 (Image Augmentation)
합성 여부 탐지 모델과 달리 변조 부위 탐지 모델의 경우 합성된 이미지만 사용해야 했기에 충분한 학습을 위해 이미지 어그멘테이션 작업을 진행하였다. 다음은 이미지 어그멘테이션을 위해 사용한 옵션의 종류와 값을 나타내었다.
구분
옵션
값
비고
학습 데이터셋
horizontal_flip
False
수평 플립
vertical_flip
False
수직 플립
shear_range
0.2
기울기 비율
zoom_range
0.2
확대 비율
테스트 데이터셋
validation_split
0.2
훈련/평가 분할 비율
왼쪽 눈과 오른쪽 눈의 예측 위치가 바뀌어선 되지 않기에 수평 플립을 False로 주었고, 적은 데이터셋이기에 학습 데이터셋의 일부를 수직 플립하는 옵션 또한 False로 적용하였다. 나머지 옵션인 기울기, 확대, 분할 비율의 경우 일반적으로 0.2를 설정한다고 판단하여 값을 설정하였다.
Training Set의 경우 총 959개를 사용하였고, Validation Set과 Test Set은 0.2 비율로 각각 768개, 191개로 나누어 어그멘테이션을 진행하였다.
5.2.3 모델 레이어 구성 (Model Layer Structure)
합성 여부 탐지 모델과 동일하게 레이어를 구성하였으며 달라진 부분은 출력 부분에 합성의 경우의 수인 15가지에 대해 softmax 함수를 적용한 것이다. 15가지는 합성 부위 별로 나올 수 있는 경우의 수인 $2^4$에서 합성되지 않은 0000에 대한 경우를 제외한 것이다. 또한 Dropout 레이어를 추가하여 학습이 과적합 되지 않도록 하였다. Dropout을 0.1로 모두 적용하여 진행한 결과 적용하지 않은 것과 비슷하게 대부분의 평가 메트릭에서 99%대를 확인할 수 있었고, Dropout을 0.2로 적용한 결과 조금 더 느슨하게 학습되는 것을 확인할 수 있었다. 다음은 모델학습 결과이다.
5.2.4 모델 학습 결과
모델 학습 결과 (epoch: 61 종료)
61번째 에폭에서 Early stop이 적용되어 종료되었다. 점진적으로 loss가 줄고, accuracy가 증가하는 양상을 확인할 수 있었고, 부가적으로 precision, recall, auc에 대한 평가 metric을 추가하여 확인할 수 있도록 하였다. (그림의 가시성을 위해 val_precision, val_recall, val_auc 정보를 담지 않았다) 모델에 대해 Validation Set을 사용하여 평가한 결과 다음과 같다.
모델 Evaluation 결과
모델 성능 평가 결과 값으로 Loss 값 16%, Accuracy 값 96.9%, Precision 99.0%, Recall 94.0%, AUC 99.9%를 확인할 수 있다. 다음으로 학습한 합성 부위 예측 탐지 모델에 대해 합성 이미지 전체를 입력으로 넣어 추론을 진행하는 과정을 아래와 같이 진행하였다.
Inference 진행 과정
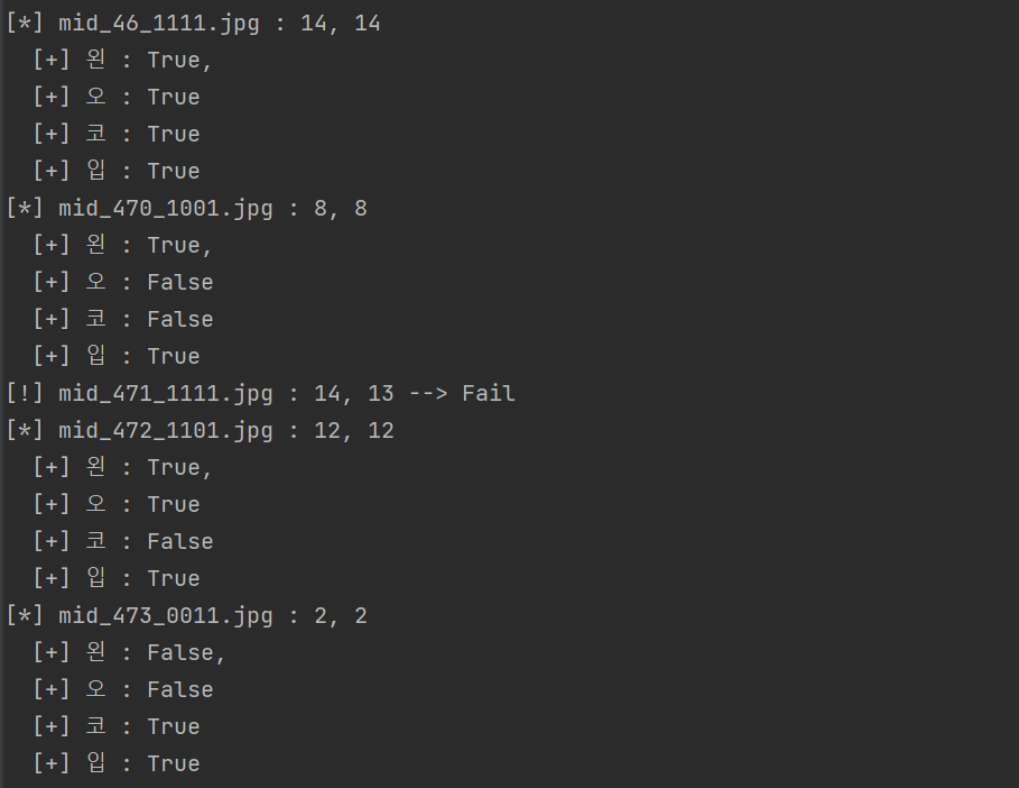
0 ~ 15사이의 값을 0001, 0010, 0011 ~ 1111 값으로 딕셔너리로 아래와 같이 매핑 해두었다.
실제 합성 이미지가 들어 갔을 때 실제 값과 예측 값을 출력하였으며 만약 다를 경우 Fail이라는 문자열을 출력하도록 하여 구분하도록 하였다. 올바르게 합성 부위를 탐지한 결과의 경우 부위를 합성 부위를 True/False로 표현하여 확인할 수 있도록 하였다. 전체 959장의 합성 이미지에서 Inference를 통해 F1 Score를 계산한 결과는 다음과 같다.
Inference 진행 결과, F1 Score 97.0%로 학습이 매우 잘 이루어졌음을 확인할 수 있다.
5.2.5 손실함수 및 정확도 그래프 시각화
합성 여부 탐지 모델과 달리 초반 변화폭이 큰 양상이 없으며 전반적으로 loss 값이 줄어들고 accuracy가 증가하는 추세를 확인할 수 있다. 이와 같은 추세와 F1 Score를 통해 모델 학습 잘 이루어졌음을 알 수 있다.
문제의 핵심은 홀수인 자연수 N이 주어지면, 1부터 $N^2$까지의 자연수를 아래와 같이 달팽이 모양으로 $N * N$의 표에 채우라는 것이다.
입력
첫째 줄에 홀수인 자연수 N(3 ≤ N ≤ 999)이 주어진다. 둘째 줄에는 위치를 찾고자 하는 N2 이하의 자연수가 하나 주어진다.
출력
N개의 줄에 걸쳐 표를 출력한다. 각 줄에 N개의 자연수를 한 칸씩 띄어서 출력하면 되며, 자릿수를 맞출 필요가 없다. N+1번째 줄에는 입력받은 자연수의 좌표를 나타내는 두 정수를 한 칸 띄어서 출력한다.
접근 방법
알고리즘을 처음 접하는 입장으로써 주위 개발자에게 조언을 구했다. 처음엔 코드를 작성하면서 변수를 생각했다. 하지만 이것은 비효율적인 방법이라고 한다. 머리로 사용할 변수들을 최대한 미리 생각하고 이후에 필요에 따라 추가/제거 하는 것이 중요하다.
1. 먼저 문제에서 바로 확인할 수 있는 변수 두 개인 홀수 자연수를 N으로 두고, 찾아야 할 값을 want로 선언하였다.
2. 찾아야 할 값 want의 2차원 좌표를 나타낼 변수를 x, y로 선언하였다.
3. 2차원 배열을 다루기 위해 사용되는 행렬을 row, col로 선언하였다.
4. 그리고 핵심이 되는 것은 dir(direction)이라는 방향을 나타내는 변수이다.
dir은 위와 같은 흐름으로 2차원 배열 변수에 값을 담기 위한 변수이다. dir을 1 또는 -1로 설정하여 row와 col에 더해줄 것이다. dir을 1로 설정하여 row에 더해줄 경우 자연스럽게 row가 증가하고, col에 더해줄 경우 col이 증가한다. 이후 dir을 -1로 설정하면 row가 감소하고, col이 감소한다. 이후 다시 dir을 1로 설정하면 row가 증가하여 최종적으로 1에 도달하는 식이다. (위 그림에 맞대어 row와 col에 dir을 더해주는 것을 시뮬레이션 해볼 것을 권한다. 이것이 문제 풀이의 핵심이다)
작성 코드
#include <iostream>
#include <cstring>
using namespace std;
int main(void)
{
// 1. 변수 선언부
int N = 0; // 입력 받을 홀수 자연수
int want = 0; // N^2 이하의 찾고자 하는 자연수
int x = 0, y = 0 ; // Want의 좌표를 나타낼 x, y 값
int row = -1, col = 0;; // 달팽이를 나타낼 행, 열
int dir = 1; // 방향을 나타낼 변수
cin >> N;
int copy = N;
cin >> want;
int squared = N * N; // N^2을 표현할 변수
int** arr;
arr = new int* [N]; // 2차원 배열의에서 사용할 배열의 길이(row)
for (int i = 0; i < N; i++)
{
arr[i] = new int[N]; // N = 2차원 배열에서 사용할 배열의 길이(column)
memset(arr[i], 0, sizeof(int)*N); // 0으로 배열 초기화 for security.
}
// 2. 핵심 알고리즘 동작부
while (squared > 0)
{
for (int i = 0; i < copy; i++)
{
row = row + dir;
arr[row][col] = squared;
if (squared == want)
{
x = row + 1;
y = col + 1;
}
squared = squared - 1;
}
copy = copy - 1;
for (int i = 0; i < copy; i++)
{
col = col + dir;
arr[row][col] = squared;
if (squared == want)
{
x = row + 1;
y = col + 1;
}
squared = squared - 1;
}
dir = dir * (-1);
}
// 3. 결과 출력부
for (int i = 0; i < N * N; i++)
{
int r = i / N;
int c = i % N;
cout << arr[r][c] << " ";
if ((i % N) == N - 1) cout << endl;
}
cout << x << " " << y << endl;
// 4. 2차원 배열 할당 해제부
for (int i = 0; i < N; i++)
delete[] arr[i];
delete[] arr;
return 0;
}
코드는 크게 4개의 부로 구성된다.
1. 변수 선언부
알고리즘 작성 이전에 필요로 하는 변수를 선언한 부분이다.
2. 핵심 알고리즘 동작부
배열에 값을 넣기 위한 핵심적인 알고리즘이 동작하는 부분이다.
3. 결과 출력부
$N^2$부터 1까지 달팽이 모양으로 출력하는 부분이다.
4. 2차원 배열 할당 해제부
달팽이 모양으로 값을 담기 위해 생성했던 2차원 동적 배열을 할당 해제하는 부분이다.
참고로 memset 함수는 0, -1로만 초기화 가능하다. 그 이유는 바이트 단위로 초기화가 이루어지기 때문이다.
정답 비율 & 제출 결과
초반에 알고리즘 풀지 못했을 때 정답 비율이 50%나 된다는 것에 가벼운 충격을 받았다. 최소한 둘에 하나는 풀 수 있다는 생각에 말이다. 아무튼 동시에 초심자로서 알고리즘적 사고를 잘 하는 사람들이 많다는 것에 내게 자극을 심어준 문제였다.
책의 핵심 키워드는 극한의 오너십이다. 리더는 자신이 속한 세상의 모든 것의 오너가 되어야 하며, 남 탓하거나 책임을 돌리지 말아야 한다는 것이다.
평소 읽고 싶던 13권의 책을 주문했을 때 함께 샀던 책이다. 육체의 한계를 넘도록 훈련받은 특수부대는 어떤 정신을 가지고 있을까 궁금했고 또한 특수부대원로써의 삶을 살았다면 어땠을까 하는 생각이 있었기 때문이다. 책에서 이야기하는 네이비씰로부터 도출된 여러 통찰의 특징은 삶의 전반 어느 곳에나 쓰일 수 있다는 것이다. 특히 저자는 기업경영컨설팅에도 동일한 원칙을 적용하는데, 전쟁 상황에서의 원칙이 기업에서도 다르지 않다고 한다.
책 내용 중 기록하고 싶은 것은 많지만 크게 두 가지만 뽑자면 아래의 내용들이다.
[나쁜 팀은 없다 나쁜 리더만 있을 뿐] 네이비씰에서 흥미로운 일화가 있다. 네이비씰 요원을 뽑기 위한 훈련에서 계속 일등을 하던 팀이 있었고, 계속 꼴등을 하던 팀이 있었다. 그 때 정확히 일등 팀의 리더와 꼴등 팀의 리더만 바꾸어 훈련을 진행하였다. 그 결과, 꼴등하던 팀이 계속 일등을 하게 된 것이다. 바뀐 것은 없었다. 리더만 제외하면. 팀이 문제라던 불평만하던 꼴등팀 리더는 그 사건을 계기로 훌륭한 장교로 거듭날 수 있었던 계기가 되었다고 한다.
[위와 아래를 모두 이끌어라] 리더쉽의 특징은 지휘 계통의 아래로만 흐르는 것이 아니라 위로도 흐르는 특징을 가진다. 때문에 우리는 우리를 둘러싼 모든 것의 오너가 되어야 한다고 말한다. 만약 상부에서 말도 안되는 질문을 한다면 그것은 상부가 원하는 정보를 제대로 보고하지 못한 우리의 잘못이며, 상부가 우리를 이끄는 것이 아니라 우리가 상부를 이끌어야 한다고 말한다.
또한 만약 상관이 동기부여를 하지 못해준다면 좌절하지 말고 스스로 동기부여 해야한다고 말한다. 책임지고 일하고, 기회로 삼아 일을 되게 만들어야 한다. 나약한 상관을 두고 있는 것은 내 활동 폭이 더 넓어지기 때문에 오히려 좋은 일이며, 반대로 상사가 강인한 사람이라도 좋은 일이라 말한다. 때문에 상사가 나약하다는 것은 변수가 되지 못한다고 일러준다. 만약 이렇게 극한의 오너십 정신이 팀 내에 배어 있으면 모든 팀원이 자발적으로 움직여 확실하게 최고의 성과를 내어 승리하는 팀을 만들 수 있다고 한다.
책 덕분에 반성하게 되었다. 올바르게 돌아가지 않고 있는 프로젝트가 있었고, PM이 강인한 리더십을 가지고 책임을 져야지하는 안일한 생각과 책임을 돌리는 태도를 가졌었다. 책을 읽고 생각이 바뀌게 되었다. 나는 책임 전가를 하지 않는다고 생각했었는데 실상은 그러지 않았다. 앞으로는 책임을 짊어지고, 이러한 극한의 오너십 정신을 지속적으로 추구하는 삶을 살 것이다.
"리더가 극한의 오너십을 체화하고 조직 내에 그 문화를 전파하면 나머지는 알아서 돌아간다." - 조코 윌링크
별점: ⭐️⭐️⭐️⭐️
이외의 내용 메모는 아래와 같다.
리더는 저성과자가 개선의 여지가 없다면 그를 내보내고 대체자를 찾는 악역도 감수해야 한다.
팀 내에 극한의 오너십 문화가 배어 있으면 모든 팀원이 자발적으로 움직여 확실하게 최고의 성과를 낼 수 있다.
리더가 임무에 대한 믿음을 가지면, 그 믿음은 지휘 계통 위아래로 퍼져 나간다. 확실한 믿음과 자신감에서 나오는 말과 행동은 단단하다.
어려운 문제가 동시다발로 터졌을 때는 반드시 우선순위를 정해서 실행하는 원칙을 고수해야 한다.
작전의 궁극적 목표를 정확하게 이해하면 대원들이 일일이 허락을 구하지 않고도 전략적 목표를 위해 스스로 움직이게 된다.
브리핑이 성공적이었는지 판가름하는 척도는 단순하다. 팀원과 지원 병력 모두 계획의 의도와 목표를 완벽히 이해했는가이다.
대원들이 임무를 완전히 이해했는지 확인하기 위해 각자 맡은 임무를 설명하게 하고 세부사항에 관한 질문을 해야한다.
브리핑에서 가장 중요한 것은 지휘 의도를 설명하는 것이다. 작전에 참여하는 모든 대원이 작전의 목적과 작전이 의도하는 결과를 이해하면 특별한 지시 없이도 스스로 알아서 판단하고 행동하게 된다.
상관이 제때 결정을 내리지 않거나 필요한 지원을 해 주지 않아도 그를 원망하지 말고 먼저 자신을 돌아보아야 한다. 지휘 체계의 상부를 이끌려면 특히 직속상관을 요령껏 다루는 법을 익혀야 한다. 이를 위해 상부에 상황 보고를 지속적으로 하는 것이 중요하다.
본사 임원에게 현장 상황을 정확히 이해시키려면 더 많은 노력이 필요하다. 더 상세하게 정보를 보고하고, 임원들과 더 긴밀하게 소통해야 한다. 임원들이 현장 상황을 정확히 이해하지 못한다고 생각되면 이곳으로 와서 직접 보라고 요청해야 한다.
결정을 내릴 만큼 충분한 정보가 없다는 말은 역설적으로 결정을 내릴 만큼 충분한 정보를 이미 가지고 있다는 의미로 해석할 수도 있다.
모든 리더는 자기 없이도 조직이 돌아가는 것을 목표로 삼아야 한다. 리더는 후배들이 언제라도 승진해 더 큰 권한을 가질 수 있도록 훈련시키고 지도하는 데 온 힘을 쏟아야 한다.
리더가 되었다면 겸손해져야 한다. 남을 존중해야 한다. 계급과 직책은 상관없다. 다른 사람보다 돈을 수백 배 더 벌어도 마찬가지다. 모든 사람을 존중해야 한다. 반드시 남의 말에 귀를 기울여야 한다. 남의 말을 들으면 그 사람과 당신이 연결된다. 그게 리더인 우리가 해야 하는 일이다.
마이크로매니지먼트는 상황에 따라 필요하다. 하지만 그것으로 시작해서 점차 지휘권 분산으로 변화해야 한다.
마이크로매니지먼트를 한다는 것은 리더로서 해야할 일을 못하고 있는 것이기 때문에 하고 싶지 않지만 어쩔 수 없이 해야하는 일이라는 느낌을 가져야 한다. 이후 어느정도 하면 물러나야 한다. 시시콜콜 간섭받는 것을 좋아하는 사람은 아무도 없다.
선형대수학을 볼 때마다 느끼지만 대수적으로만 기술되어 있다보니 늘 추상적으로 느껴지고 직관적이지가 않았습니다. 이번에 국문과 공대생이라는 블로그를 운영하시는 분의 글을 보다가 명불허전이라는 분의 선형대수 강의를 수강하고보니 선형대수 이해를 이렇게 잘 알려주는 사람이 있구나 하면서 감탄했습니다. 아무래도 선형대수에서 흔히 배우는 방식인 대수적인 측면이외에도 기하적인 측면의 설명과 더불어 시각화 자료가 높은 이해도의 핵심을 차지 한 것 같습니다.
늘 선형대수를 보며 그래서 대체 물리와 어떻게 연결해 설명할 수 있는 것인지 궁금했습니다. 중고등학교때 함수나 미적분을 왜 배우는지 몰랐지만 지나고나니 물리학에서 파동을 기술하거나 다른 물리량을 알아내는 데에 쓰인다는 것을 알게 되었고, 수학으로 물리학을 말할 수 있다는 사실이 흥미로워지면서 더 관심을 갖게 됐습니다. 마찬가지로 선형대수도 물리학적으로 가지는 의미를 이해하면 더 이해가 높아질 것 같아서 그런 강의가 없을까 했는데 3Blue1Brown라는 유튜버의 강의를 접하고나서 많이 해소가 된 것 같습니다.
첫 강의에서부터 선형대수를 바라볼 수 있는 3가지 측면을 언급하면서 시작합니다. 물리학의 관점, 컴퓨터 과학의 관점, 수학의 관점이 있다고 이야기합니다. 선형대수에서 자주 쓰이는 벡터는 물리학의 관점에서 화살표와 동일하며, 컴퓨터과학에서는 숫자 리스트, 수학의 관점에서는 모든 것이라 이야기합니다. 관점으로는 간단히 여기까지만 이야기하고 이후로는 선형대수의 개념에 대해 설명을 진행합니다. 저는 물리 이외에도 (당연하지만) 컴퓨터과학과 수학의 관점에서 바라볼 수 있다고 언급한 것에서 넘어가서 계속 보게 된 것 같습니다.
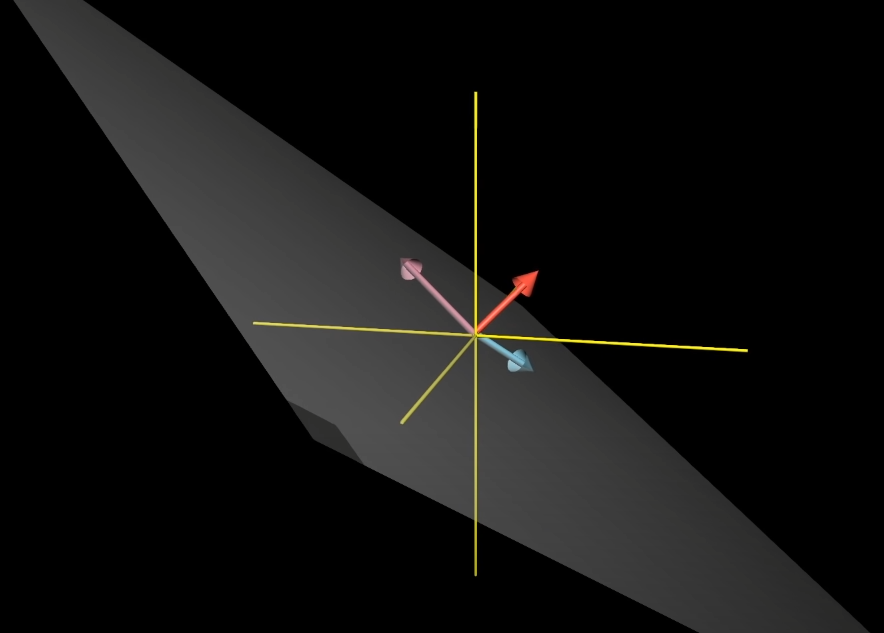
기초 벡터 연산
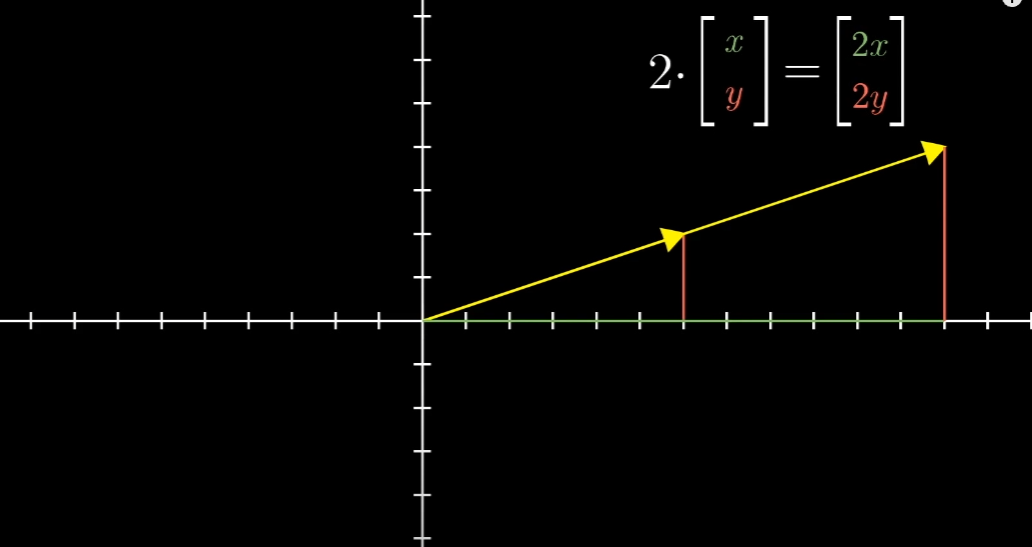
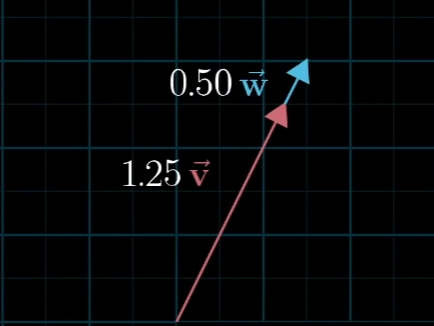
선형대수학에서는 크게 두 가지 기본적인 연산으로 이루어집니다. 벡터 합과 스칼라곱입니다. 벡터는 단순합니다. 화살표라고 생각해도 됩니다. 또는 화살표의 좌표를 나타내는 것이라 생각하면 됩니다. 이후 강의를 통해 스칼라의 의미를 처음으로 제대로 이해하게 됐습니다.
스칼라는 단순히 숫자로만 이해하고 있었으나 위와 같이 하나의 벡터(화살표)의 길이를 늘리거나 줄이거나 방향을 바꾸는 것을 Scaling이라 하는데, 위의 그림과 같이 2, 1/3, -1.8과 같이 벡터 스케일링에 사용되는 숫자들을 스칼라(scalar)라고 한다고 합니다. (스칼라의 영어발음이 스케일라였습니다.) 즉 선형대수에서 스칼라는 벡터 스케일링을 목적으로 사용됩니다.
벡터에 스칼라를 곱하는 것은 숫자 리스트(행렬)라는 개념에서 리스트의 각 원소에 숫자를 곱하는 것과 같습니다. 스칼라를 이용해 벡터를 스케일링할 수 있고 이렇게 스케일링된 두 벡터끼리 더하는 것을 선형결합(linear combination)이라고 합니다.
기저
기저 또한 처음으로 시원하게 강의를 듣게 되어 이해할 수 있었습니다. 기저를 설명하기 위해서는 먼저 2차원 x, y 좌표계상의 특별한 두 가지 벡터가 있다고 합니다. 바로 x축에 있는 단위 벡터(unit vector)인 $\hat{i}$와 y축에 있는 단위 벡터인 $\hat{j}$입니다. 이 둘을 좌표계의 기저(basis)라고 합니다.
그렇다고하면 이 기저는 어떤 의미를 가지는가?라고 했을 때 핵심은 벡터의 변환을 구할 수 있다는 것입니다. 조금 더 설명하면 어떤 벡터 $(x, y)$가 있을 때 어떤 행렬을 거쳐서 공간상에 $(x', y')$로 매핑된다면 그 기저는 어떤 행렬이 되는 것입니다. 즉 Input vector $(x, y)$는 기저만 알고 있다면 바로 output vector $(x', y')$를 도출해낼 수 있는 것과 같습니다. 조금 더 자세히 말해 벡터가 행렬로부터 변환이 된다면 벡터를 이루는 기저 또한 변환이 되는데 결과적으로 변환된 기저벡터를 알고 있다면 어떤 벡터 $(x, y)$가 와도 변환을 바로 시킬 수 있다는 것입니다. (보충 설명은 앞으로 작성될 선형변환 포스팅에서 참고 바랍니다)
이 기저라고 하는 것은 암묵적으로 원점을 기준으로 하는 것으로 사용하고 있습니다. 때문에 움직이는 것은 두 벡터만 움직입니다. 두 벡터를 가지고 어디에 활용할까요? 아래와 같이 2차원 공간상의 모든 좌표를 표현할 수 있게 됩니다. 무한하고 평평한 2차원 평면을 만들 수 있다는 것입니다.
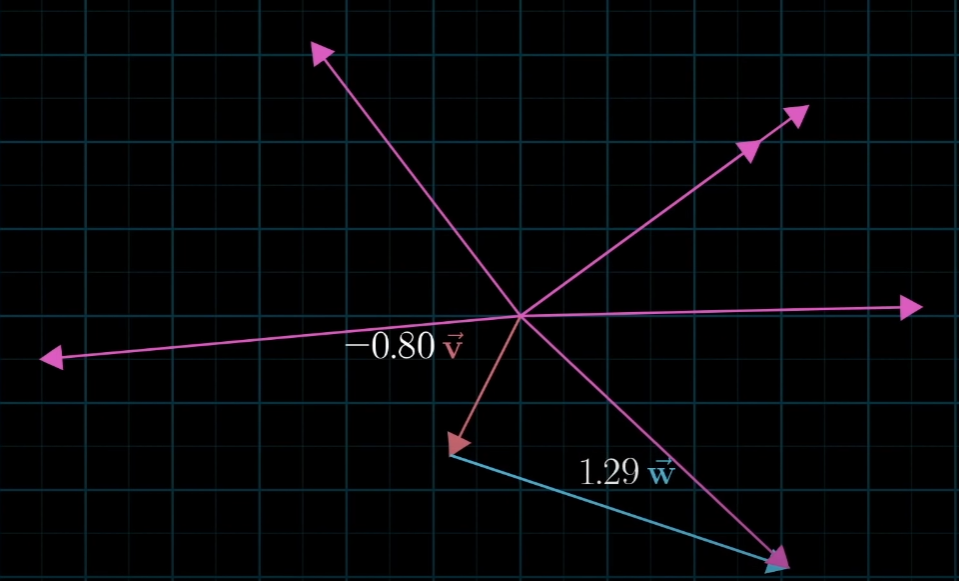
이렇게 두 벡터를 통해 표현할 수 있는 공간을 Span이라고 합니다. 정확히 Span의 사전적 정의는 주어진 두 벡터 쌍의 조합으로 나타낼 수 있는 output vector의 집합입니다. 2차원 벡터쌍의 span은 대부분 2차원 공간 전체가 됩니다.
하지만 이러한 span이 특정 선 위로 제한이 되는 경우도 있습니다. 바로 두 벡터 중 하나가 다른 벡터와 겹치게 되는 경우 입니다.
이럴 때는 Span이 2차원 공간이 아니라 단순히 직선 하나로 볼 수 있습니다. 이렇게 하나의 벡터가 다른 벡터에 겹치게 되어 Span이 한 차원 확장되지 못하는 경우를 선형 종속(Linear Dependent)이라고 합니다. 다시 말해 벡터가 하나만 있었다면 1차원 선만 표현하지만 2개라면 2차원을 표현해야합니다. 하지만 2개의 벡터가 있음에도 불구하고 1차원 밖에 표현하지 못하는 것을 의미합니다.
반대로 하나의 벡터를 추가하여 기존 Span이외에 다른 차원을 추가해주는 것이 가능하다면 선형 독립(Linear Independent)라고 합니다. 이는 3차원에서도 마찬가지입니다.
세 개의 벡터가 있을 때 스팬은 모든 가능한 선형결합의 결과집합입니다. 즉, 세 개의 벡터로 모든 3차원 공간을 다 만들 수 있는 것과 동일합니다. 하지만 2차원과 마찬가지로 예외가 존재하는데, 만약 세 번째 벡터가 두 개의 벡터가 만드는 스팬(평면)에 놓여있다면 세 번째 벡터를 추가해도 스팬이 바뀌지 않습니다. 이를 선형종속이라 하였습니다.
자연어처리 프로젝트 진행 도중 우분투에 딥러닝 학습 환경을 만들 필요성이 생겼고 설치 과정을 정리하여 이후에 참고하고자합니다. 먼저 우분투에 딥러닝 환경 설치하는 방법에 대해서는 https://webnautes.tistory.com/1428에서 참조하였습니다. 참조한 블로그의 포스팅과 차이점은 핵심만 추려 간소화한 것입니다.
딥러닝 환경을 구성하기 위해서는 크게 3가지가 필요하다.
1. NVIDIA 드라이버
2. CUDA
3. cuDNN
이를 위해 아래의 명령어를 순차적으로 실행하면 된다.
우분투 최신 환경 유지
sudo apt-get update
sudo apt-get upgrade
현재 사용중인 그래픽카드에 설치할 수 있는 드라이버 목록 확인
ubuntu-drivers devices
* 만약 ubuntu: command not found 에러가 발생한다면 아래와 같이 관련 패키지 설치를 우선하면 된다.
sudo apt-get install -y ubuntu-drivers-common
결과로 확인된 driver 중 하나를 설치하며, 가급적 recommended라 표시된 것을 설치한다. 설치 이후 적용을 위해서 재부팅이 필요함.
만약 명령어의 결과값이 위 처럼 나오지 않고 출력값이 없을 경우 그래픽카드가 올바르게 연결되어 있지 않은 것이므로 연결을 잘 확인해야 함.
여기까지하면 딥러닝 환경 설치에 필요한 NVIDIA 드라이버, CUDA Toolkit, cuDNN 설치를 완료한 것임.
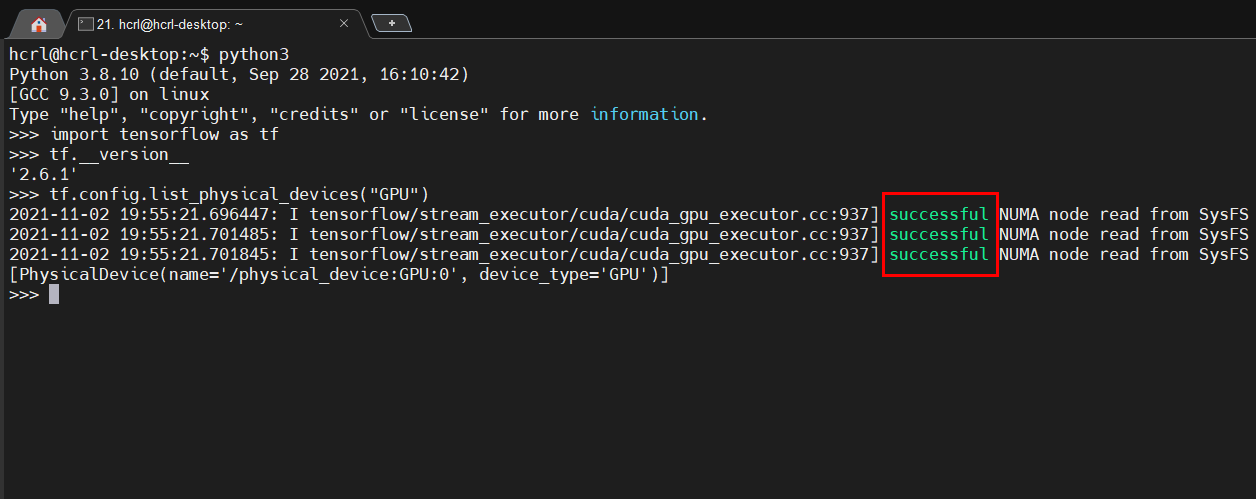
실제로 GPU가 학습에 사용될 수 있는지 여부를 확인하기 위해서는 추가적으로 텐서플로우를 설치.
pip3 install tensorflow
이후 위의 tf.config.list_physical_devices("GPU")를 통해 successful이 보인다면 정상적으로 학습에 사용할 수 있음. 끝.
설치 자체는 위 명령어들만 입력해주면 간단하게 설치되어서 문제 없었음. 하지만 도중에 그래픽 카드 낮은 성능인거 확인하고 다른 그래픽카드로 갈아끼우는데 애먹어서 힘들었음. 그래픽 카드 장착 해제하기 위해서 멈치 찾고 누르는게 어찌나 어렵던지... 갈아끼우고 나서 ubuntu-drivers devices 명령어 입력 했을 때 결과가 출력되지 않아서 당황도 했음. PCI 선을 꼽지 않아서 그래픽 카드에 연결이 되지 않았던 것임. 그래서 연결하려고 PCI 선 하나 꼽았다가 비프음 4번 나는거 듣고 파워 부족이라는거 보고 PCI 선 다 넣어주고 켰더니 이번엔 비프음 5번 또 발생함. 그래픽카드와 모니터가 연결안되어서 발생하는 문제였음. 그래서 올드한 VGA 케이블에서 HDMI로 바꾸니까 됐음. 연구실 사람들 도움 받아서 하긴했는데 멈치가 망가짐 아닌 망가지긴 했음. 무튼 다음에는 삽질을 좀 덜할 수 있을 것으로 보임