uXRCE-DDS: Extremely Resource Constrained Environment - Data Distribution Service
uXRCE-DDS는 미들웨어이자 프로토콜이다. uXRCE-DDS는 ROS2와 PX4 중간에서 통신을 매개하는 역할을 한다. uXRCE-DDS를 통해 ROS2에서 드론 관련 정보를 받아오고 또 명령을 보낼 수 있도록 한다. 아래 아키텍처를 살펴보자.

아주 직관적인 구성이다. PX4와 ROS2로 양분되어 있고 PX4와 ROS2 사이를 uXRCE-DDS 프로토콜로 연결한다. 드론 관련 정보를 ROS2로 제공하는 쪽이 uXRCE-DDS client고 이러한 정보를 가공하여 PX4쪽으로 명령을 내리는 곳이 uXRCE-DDS agent다.
PX4는 ROS2와 마찬가지로 토픽을 통해 드론 비행제어를 위한 정보를 주고 받는다. 즉 publisher를 통해 드론 관련 정보를 발행하고 subscriber를 통해 드론을 제어한다. PX4에서는 토픽을 통해 publisher/subscriber을 사용하는 형식은 ROS2와 같지만 ROS2의 publisher/subscriber와 달라 호환되지 않는다. 이러한 호환을 가능하게 하는 것이 uXRCE-DDS인 것이다.
PX4는 토픽 publish/subscribe를 uORB를 통해 수행한다. uORB는 PX4의 내부에서 토픽이 동작할 수 있도록 하는 PX4 내부통신 메커니즘이다. PX4에서도 토픽을 사용하기 위해서는 ROS2에서와 마찬가지로 메시지 포맷이 필요하다. ROS2에서와 같이 *.msg 확장자를 가진다. 직접 확인해보자. https://github.com/PX4/PX4-Autopilot에서 소스를 다운로드 받아 msg 폴더를 살펴보면 아래와 같이 미리 정의되어 저장된 msg 파일을 확인할 수 있다.
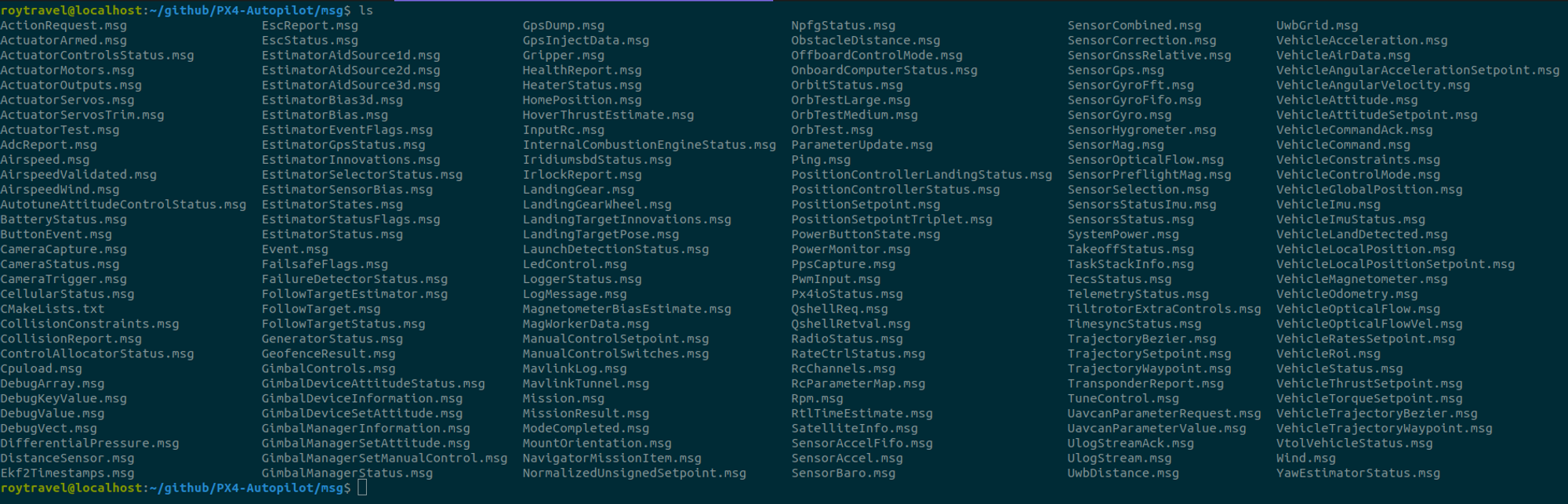
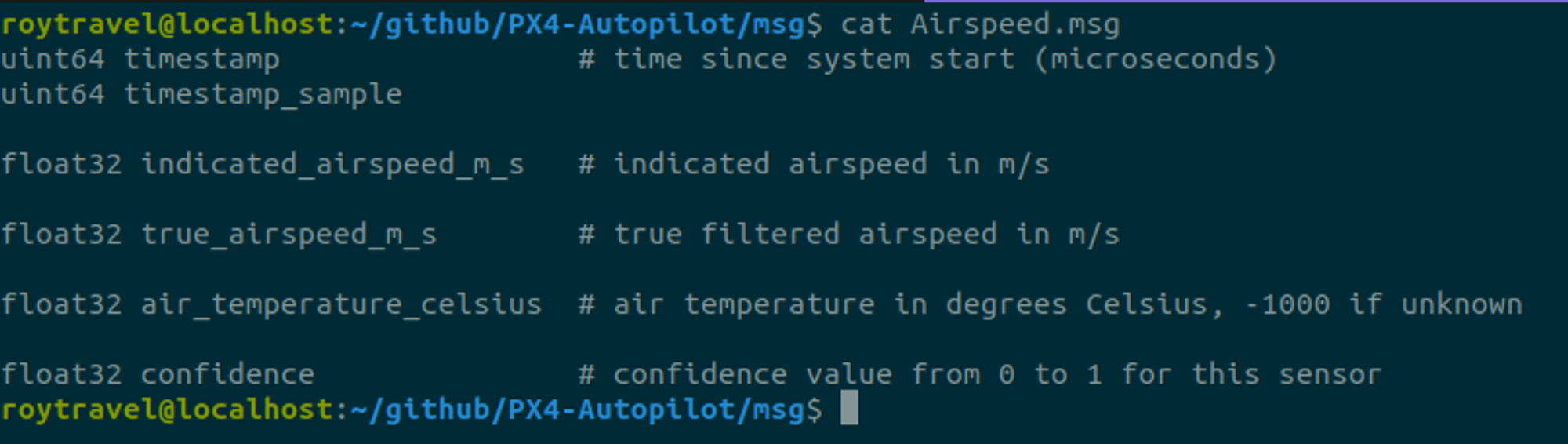
간단한 예시를 위해 Airspeed.msg를 살펴보면 다음과 같은 데이터 포맷으로 메시지 파일이 정의가 되어 있다.
PX4에서는 토픽을 사용하기 위해 *.msg 파일을 사용하지만 *.msg 파일을 바로 읽어 사용하는 것은 아니다. *.msg 파일은 빌드되어 C++ 구조체로 변환되어 사용된다. 실제로 *.msg 파일이 빌드되면 PX4-Autopilot/build/px4_sitl_default/uORB/topics 폴더에 *.h 파일로 저장된다. 아래는 Airspeed.msg가 빌드되어 저장된 airspeed.h 파일이다.

이렇게 변환된 헤더 파일에 저장된 메시지 포맷을 통해 토픽 publish/subscribe가 이뤄진다. 참고로 토픽은 빌드될 때 *.msg 파일 명과 동일한 이름으로 등록된다. abc.msg를 빌드하면 abc라는 이름의 토픽으로 등록되는 것이다.
이러한 토픽은 ROS2에서 노드(Node) 내부에서 구현된다. PX4에서도 마찬가지다. PX4에서는 ROS2의 노드를 모듈(module)이라 부르며 모듈 단위로 토픽을 publish/subscribe한다. 예컨데 카메라 센서 모듈, IMU 센서 모듈 등으로 모듈을 구현하여 토픽을 publish하고 subscribe하는 것이다. 만약 여러 모듈 간의 통신이 필요한 경우라면 PX4는 내부적인 모듈 간의 통신을 uORB를 통해 수행한다.
핵심 요약을 하자면 미들웨어라 불리는 XRCE-DDS client와 XRCE-DDS agent가 PX4-ROS2 통신의 핵심이다. 또 ROS2의 노드는 XRCE-DDS agent/client를 거쳐 PX4의 uORB 메시지 형태로 바뀌어 드론에게 전달되고 uORB 메시지는 XRCE-DDS client/agent를 거쳐 ROS2에서 제어 가능한 형태로 바뀌어 전달된다.
실제로 uXRCE-DDS client와 uXRCE-DDS agent를 사용해 드론 비행제어를 수행해보자.
uXRCE-DDS agent
uXRCE-DDS agent를 실행하기 위해서는 소스코드를 다운로드 받아야 한다.
git clone https://github.com/eProsima/Micro-XRCE-DDS-Agent.git
cd Micro-XRCE-DDS-Agent
mkdir build
cd build
cmake ..
make
sudo make install
sudo ldconfig /usr/local/lib/cd ~/Micro-XRCE-DDS-Agent/build
./MicroXRCEAgent udp4 -p 8888위 명령을 수행하면 아래와 같이 Agent가 실행됨을 확인할 수 있다.

uXRCE-DDS client
uXRCE-DDS client는 단순히 make px4_iris_default gazebo 명령을 통해 시뮬레이션 환경을 실행할 때 자동으로 실행된다.
cd ~/PX4-Autopilot
make px4_sitl_default gazebo
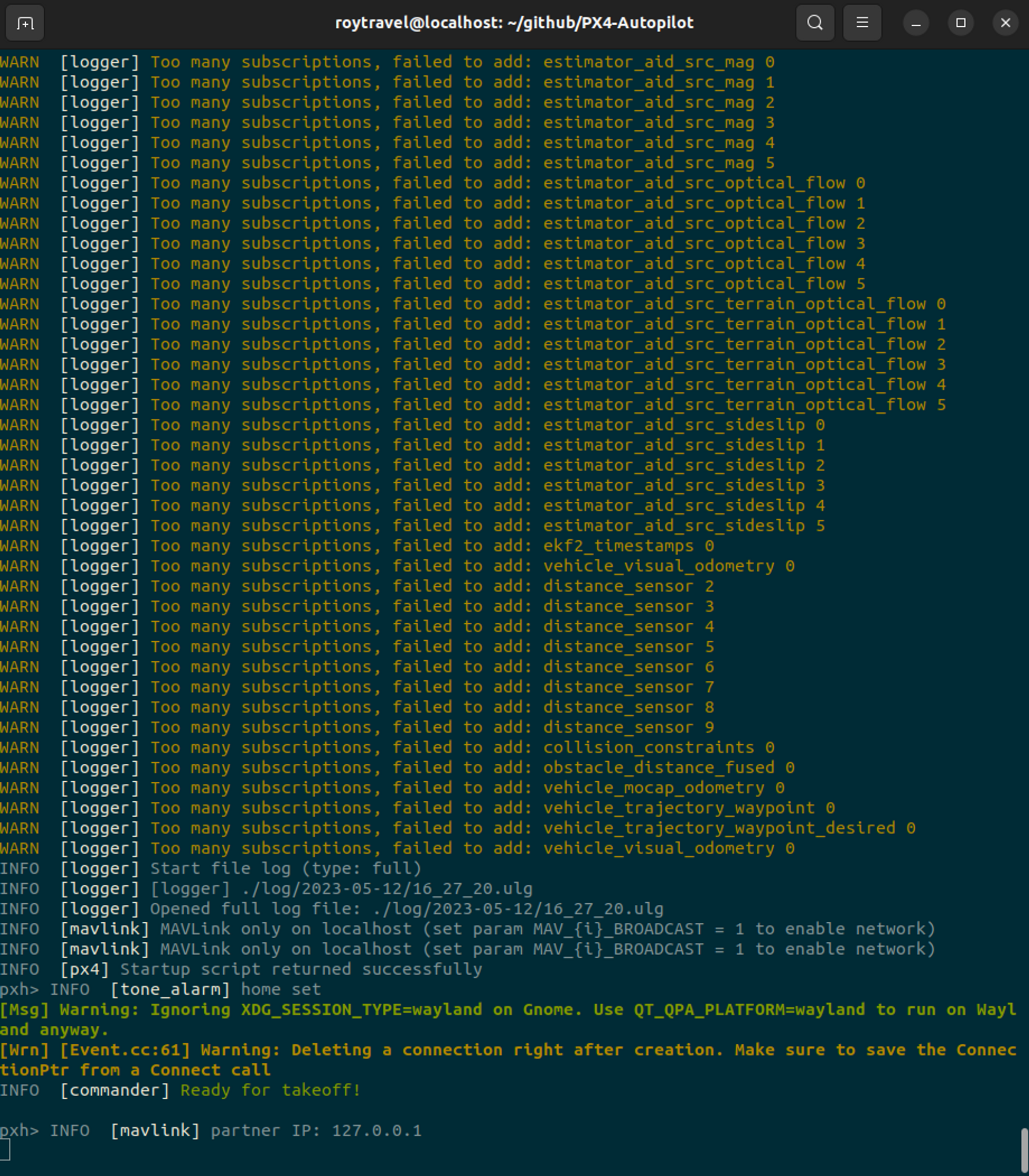
위 명령을 수행하면 아래와 같이 로그에 uxrce_dds_client가 실행되는 것을 확인할 수 있다.

여기까지하면 ROS2를 통해 드론 비행제어할 준비가 된 것이다. 마지막으로 이를 제어하기 위한 소스코드를 다운로드 받아 실행시켜보자.
mkdir -p ~/ws_offboard_control/src
cd ~/ws_offboard_control/src
git clone https://github.com/PX4/px4_msgs.git
git clone https://github.com/PX4/px4_ros_com.git
cd ..
source /opt/ros/humble/setup.bash
colcon build
source install/local_setup.bash
ros2 run px4_ros_com offboard_control
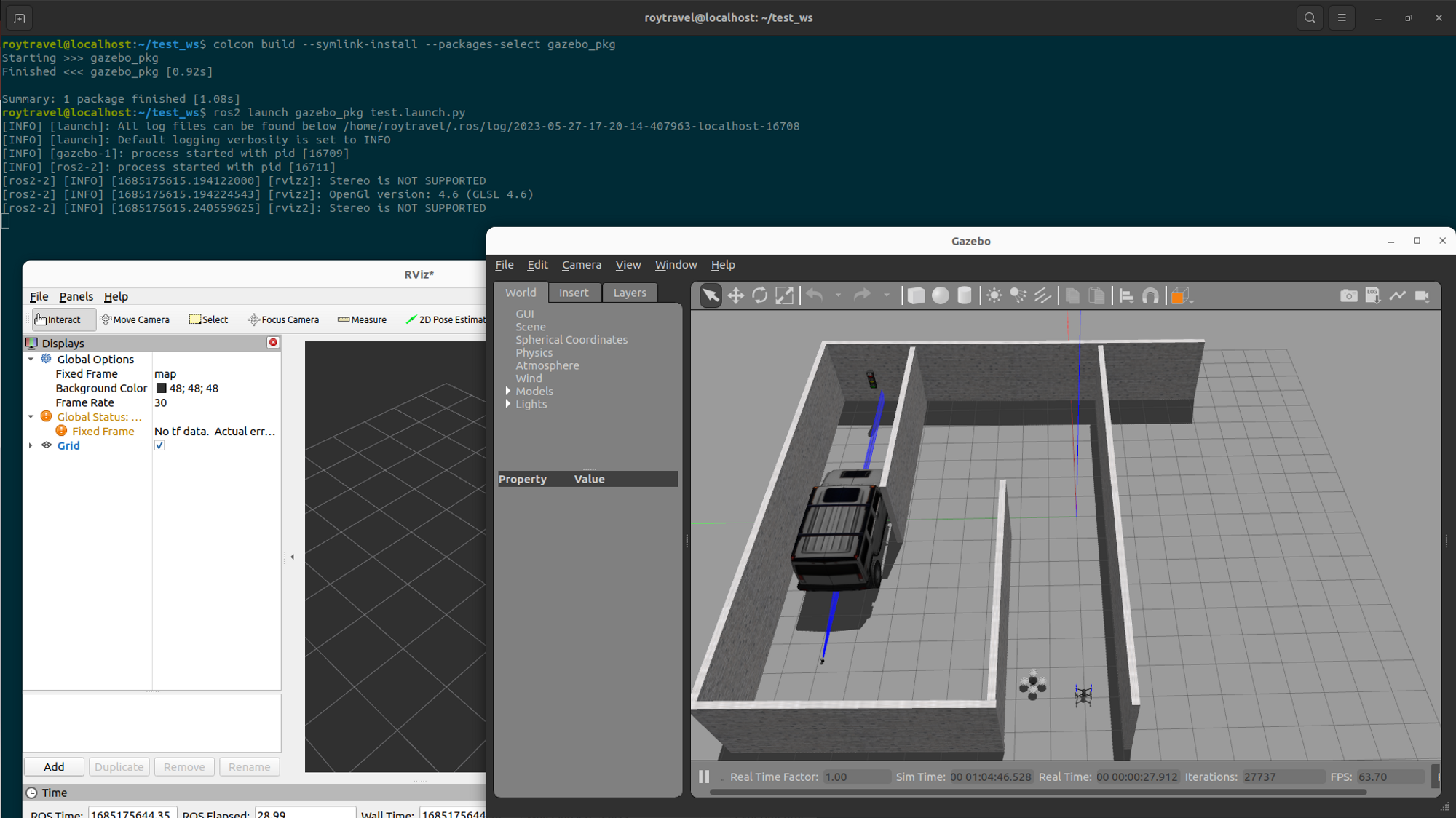
위 명령을 수행하게 되면 아래와 같이 ROS2를 통해 PX4에서 실행된 gazebo 환경에서 드론 비행이 가능한 것을 확인할 수 있다.

이제 드론 비행제어를 위해 각자 필요한 코드를 구현해 사용하면 될 것이다.
Reference
[1] https://docs.px4.io/main/ko/ros/ros2_offboard_control.html
'Computer Science > 로봇공학' 카테고리의 다른 글
| [PX4] Offboard 어플리케이션 예제 (0) | 2023.06.19 |
|---|---|
| [PX4] Lockstep이란? (0) | 2023.06.19 |
| ROS2 커스텀 interface 생성하기 (0) | 2023.06.11 |
| ROS2 launch 파일로 Gazebo와 Rviz2 실행하기 (0) | 2023.06.11 |
| Gazebo 시뮬레이션에서 world 파일 사용법 (1) | 2023.06.11 |