논문 제목: Multi-Task Pre-Training for Plug-and-PlayTask-Oriented Dialogue System
게재 학회 / 게재 년도: ACL / 2022.05
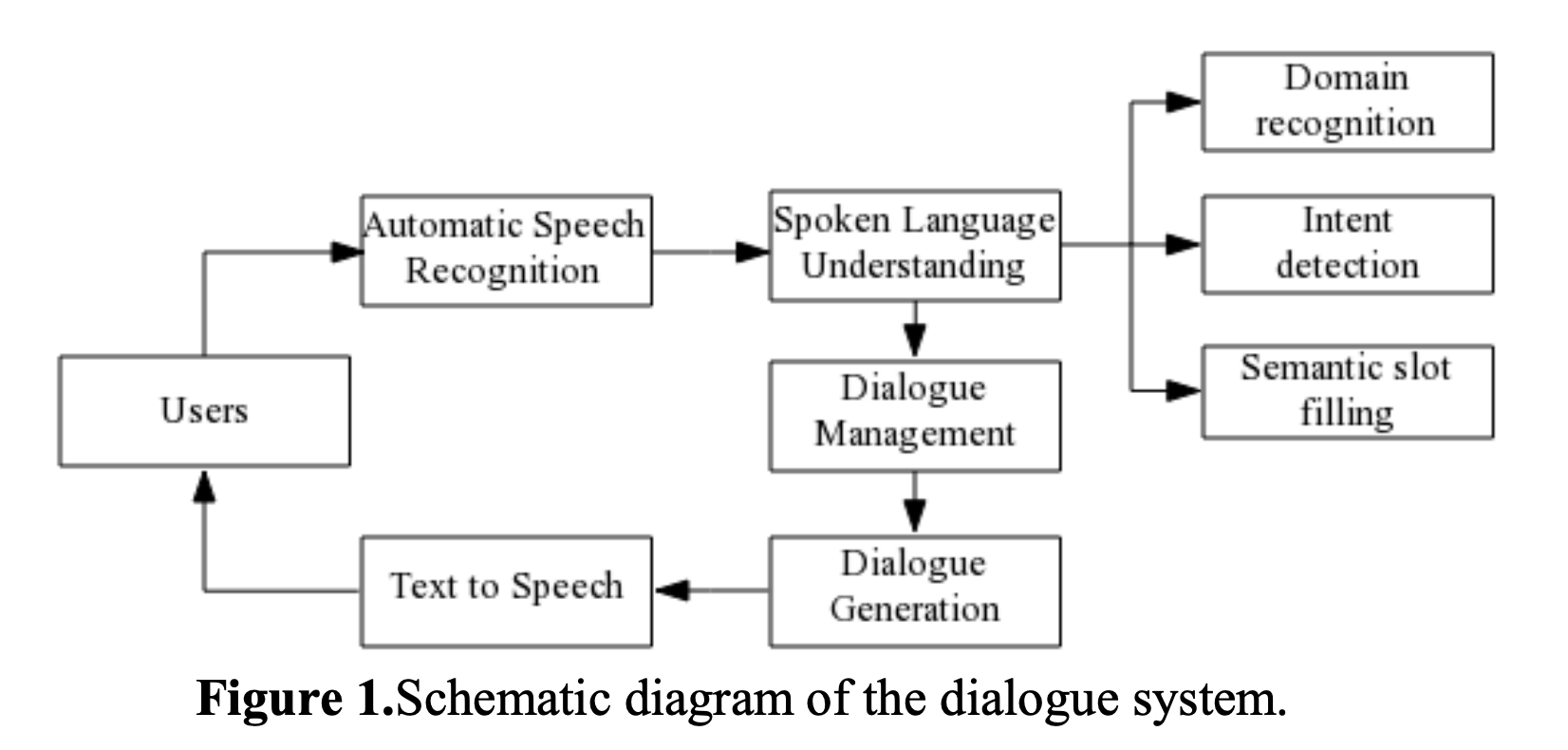
이 논문은 기존의 모듈화된 dialogue system을 하나의 모델에서 end-to-end 방식으로 동작가능한 PPTOD라는 모델에 관한 논문이다. 기존의 dialogue system은 대개 4개의 모듈인 NLU, DST, DP, NLG로 나뉜 방식으로 구성된다. 논문에서는 이러한 모듈화된 방식에 순서성이 있다고 하여 cascaded 방식이라 부른다. 하지만 이 방식에는 크게 3가지 문제가 있다고 말하며 PPTOD 모델의 연구 배경을 말한다. 그 문제는 모듈화된 계단식 dialogue system 구성이 첫 번째로 이전 모듈에서 에러가 발생하면 이후 모듈에 에러가 전파된다는 것이며 두 번째로 모든 모듈에서 각 모델이 학습하기 위해 각각의 데이터셋 수집과 라벨링 과정이 필요하고 마지막으로 계단식이기에 필연적으로 Inference latency가 느려진다는 것이다.
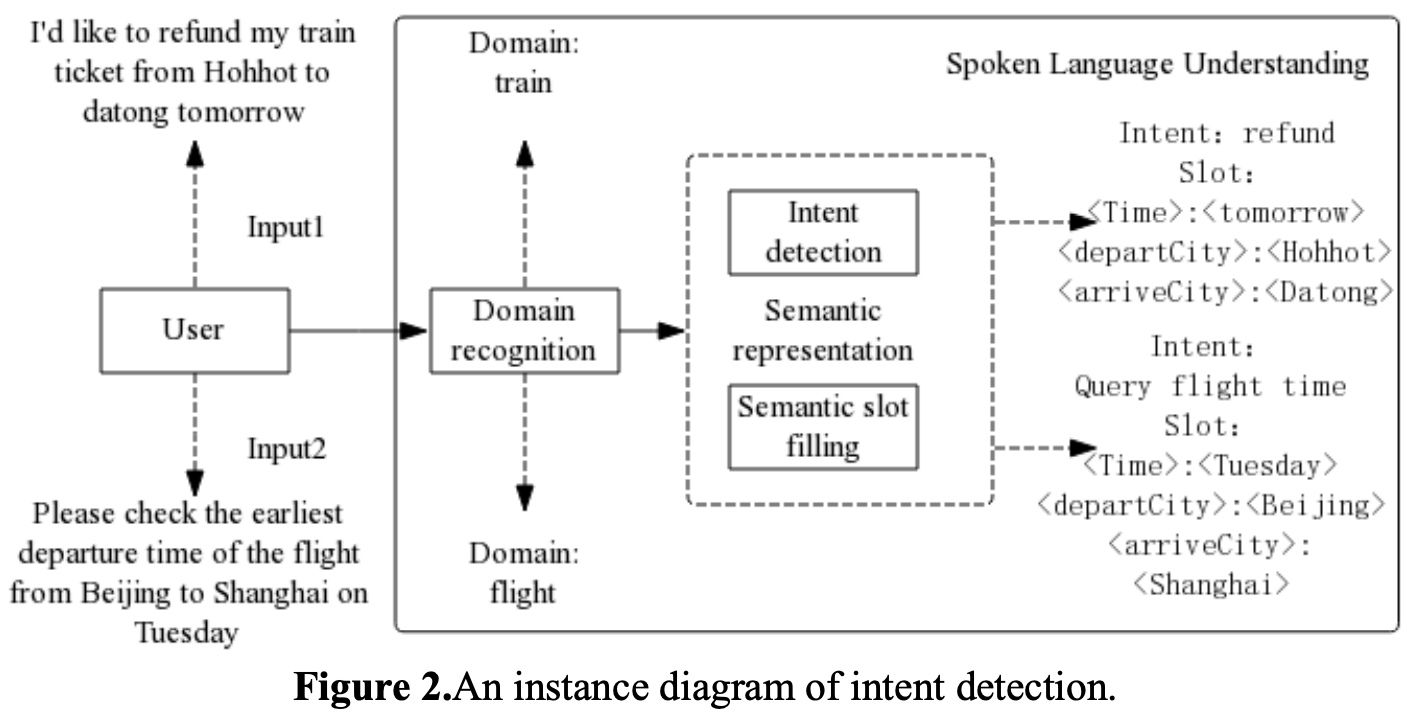
따라서 이러한 문제점을 해결하기 위해 end-to-end 방식의 PPTOD라는 모델을 제시한다. 여기서 end-to-end란 기존의 NLU, DST, DP, NLG를 하나로 통합한 것이다. 따라서 유저의 utterance가 들어오면 한번에 1. 의도 분류 2. 슬롯 필링 3. 액션 생성 4. 대답 생성이 가능하다. 아래 PPTOD 모델을 만들기 위해 pre-training하는 예시를 살펴보자.

가장 앞에 "translate dialogue to A"는 하나의 모델에서 DST, NLU, DP, NLG 중 어떤 것인지 구분하기 위해 사용되는 일종의 prefix이다. 이 prefix는 위 그림과 같이 "belief state", "user intent", "dialogue act", "system response"가 있다. 두 번째로 DST를 위해 이전까지 유저와 봇이 주고 받은 대화와 현재 유저의 utterance를 모두 concatenation해준 다음 입력으로 넣어준다. 그렇게 되면 이제 prefix에 따라 생성되는 결과값이 4가지로 분리된다. 즉, slot filling된 결과, user intent, bot action, bot 응답이다. 간단히 정리하면 prefix와 유저 utterance가 입력으로 들어가고 4개의 결과를 모두 출력할 수 있는 구조인 것이다. 다르게 말하면 세부적으로 모듈화된 task-oriented dialogue 문제를 단일한 포맷의 text generation 문제로 바꾼 모델이다.
이 T5 기반의 end-to-end 모델을 학습하기 위해 추가적인 pre-training과, fine-tuning 과정을 거쳤다. 데이터셋은 기존의 Dialogue System을 만들기 위해 공개된 아래 데이터셋을 조합했다.

총 80개 도메인의 230M개 가량의 유저 utterance 데이터셋을 사용했다. 우선 pre-training을 위해 사용한 세부적인 하이퍼파라미터는 learning rate: 5e-5, epoch: 10, optimizer: Adam, model: T5, max_seq_len: 1024, batch_size: 128, loss: maximum likelihood이며 구현의 용이성을 위해 허깅페이스 라이브러리를 사용했다. fine-tuning은 pre-training과 동일한 하이퍼 파라미터를 사용했다.
모델 학습에 사용하는 데이터셋의 형태는 $d = (z_t, x, y)$을 가진다. $d$는 데이터셋을 의미하고, $\displaystyle t \in \{NLU, DST, DP, NLG\}$이고 $z_t$는 "translate dialogue to A:" 형태의 prompt를 의미한다. $x$는 유저의 현재 발화 + 이전의 유저 발화 + 봇 응답이 전부 concatenation 된 형태이다. $y$는 생성해야할 target sequence를 의미한다. 학습에 사용한 loss 함수는 maximum likelihood를 사용했다.
PPTOD 모델의 버전은 크게 3가지로 small, base, large 모델이 있다. 각각 t5-small, t5-base, t5-large에 대해 pre-training하고 fine-tuning한 결과이다. 다만 학습시킬 때 각각의 사이즈 별로 다른 configuration을 사용했다고 한다. 이에 대한 별도의 언급은 없다. t5 모델의 기본 configuration을 사용했을 것이다.
PPTOD 모델을 평가하기 위해 크게 3가지 측면에서 벤치마킹을 수행했다. 1. end-to-end dialogue modeling 2. DST 3. user intent classification 측면이다. 벤치마킹을 위해 MultiWOZ 2.0과 MultiWOZ 2.1를 사용했다. 결과적으로 3가지 측면 모두 PPTOD 모델의 우수성을 이야기하고 있다.

첨언하자면 MultiWOZ 데이터셋에 있는 Inform, Success, BLeU, Combined Score는 MultiWOZ 데이터셋에서 제시하는 평가 가이드라인이라고 한다. 또 Combined Score는 (Inform + Success) * 0.5 + BLUE로 계산된다고 한다. 위 표의 성능을 보면 PPTOD base 모델이 가장 좋다. PPTOD large 모델이 오히려 성능이 떨어지는 것은 사전 훈련 단계에서 보지 못했던 어휘에 대해 토큰을 생성하는 방법 학습할 때 능력이 떨어지는 것으로 분석한다고 말한다. 이 말이 잘 와닿진 않지만 일단은 PPTOD base 모델이 가장 좋다고 한다.
이 논문의 저자들은 또 PPTOD 모델이 적은 데이터셋에서도 좋은 성능이 나는지 보기 위해서 학습 데이터셋을 1% 썼을 때, 5% 썼을 때, 10% 썼을 때, 20% 썼을 때에 대해 모델 성능을 비교했다. 참고로 표를 만들기 위해 5회 모델 학습에 대한 평균성능을 기재했다.
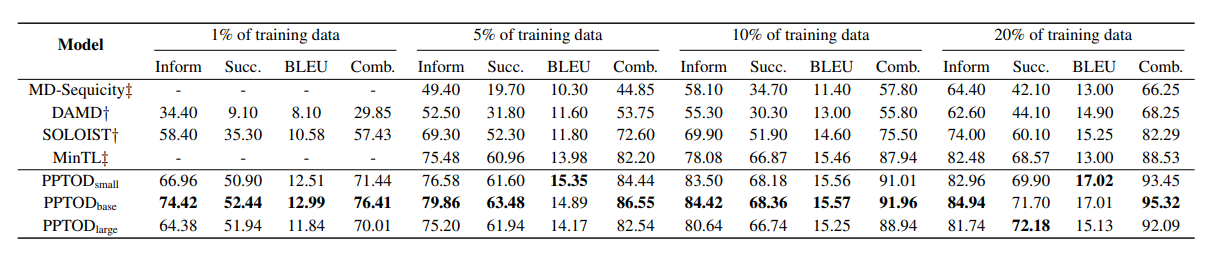
1% 학습 데이터셋만으로도 다른 모델들보다 성능이 뛰어남을 보인다. 여기까지가 1. end-to-end dialogue modeling에 대한 벤치마크 평가다. 이외의 2. DST 측면의 평가와 3. user intent classification 측면의 평가도 모두 PPTOD large 모델이 우수하다는 것을 말하므로 생략한다.
마지막으로 Inference latency 측면에서 PPTOD 모델(plug-and-play)이 기존의 cascaded 방식의 모델들보다 비약적으로 빨라졌다.

200ms도 느리진 않지만 서비스 측면에서는 14배 빠른 end-to-end (plug-and-play) 모델이 경쟁력을 보일 수 있을 것이다.
끝으로 이 논문의 핵심 컨트리뷰션은 기존의 챗봇이 NLU, DST, DP, NLG와 같이 모듈화되어 있었다면 이 모듈화된 것을 end-to-end 방식으로 바꿨다는 데 있다. 또 이를 통합함으로써 자연스럽게 모델 추론 속도가 향상되었다는 점이다. end-to-end 모델의 우수성은 이 논문의 PPTOD 모델로 증명되었다. 다만 TOD 챗봇을 위해 다양한 도메인의 데이터셋이 만들어진다면 앞으로 많은 end-to-end 연구가 이루어질 수 있을 것이라 생각한다.
'Artificial Intelligence > 논문 리딩&구현' 카테고리의 다른 글
| [논문 리뷰 #4] 멀티 도메인 대화시스템을 위한 도메인 결정 기술 (0) | 2022.11.25 |
|---|---|
| [논문 구현] ResNet 파이토치로 구현하기 (0) | 2022.09.18 |
| [논문 구현] GoogLeNet 파이토치로 구현하기 (0) | 2022.09.12 |
| [논문 구현] VGGNet 파이토치로 구현하기 (0) | 2022.09.08 |
| [논문 구현] AlexNet 파이토치로 구현하기 (2) | 2022.09.07 |