제목: Deep Residual Learning for image Recognition
학회: IEEE Conference on Computer Vision and Pattern Recognition
게재: 2016년
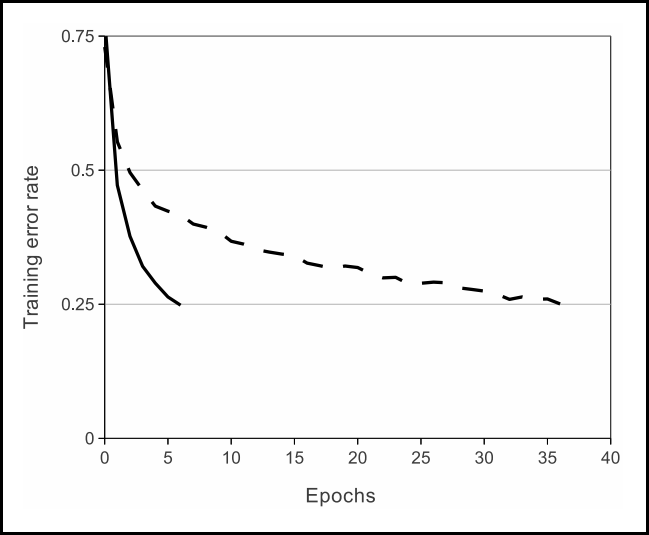
컴퓨터 비전에서 높은 이미지 인식 능력 모델의 발전은 AlexNet → VGGNet → GoogLeNet → ResNet 순으로 이뤄진다. 이러한 높은 인식 능력의 배경에는 네트워크의 깊이를 늘림으로써 high level feature부터 low level feature를 효율적으로 추출할 수 있기 때문이다. 대개 네트워크의 깊이를 늘림으로써 모델의 성능이 늘어난다. 하지만 반드시 그렇지는 않다. 아래 그래프가 이를 뒷받침 한다.
위 그래프를 보면 상대적으로 더 깊은 네트워크가 training error가 더 높다. 즉 성능이 더 낮아진다. 왜 이렇게 낮아질까? 네트워크 깊이를 늘리는 데 있어 한계가 있기 때문이다. 그리고 그 한계란 gradient vanishing 문제를 말한다. 이는 레이어가 깊을수록 역전파를 하는 과정에서 미분 값이 줄어들기 때문에 앞단 레이어는 영향을 거의 받지 못하기 때문이다. 이 문제를 해결하기 위해 ResNet이 만들어졌다. 즉 ResNet은 gradient vanishing 문제를 해결하는 모델인 것이다. 그 핵심 방법은 아래 그림 오른쪽과 같이 residual network를 사용하는 것이다.
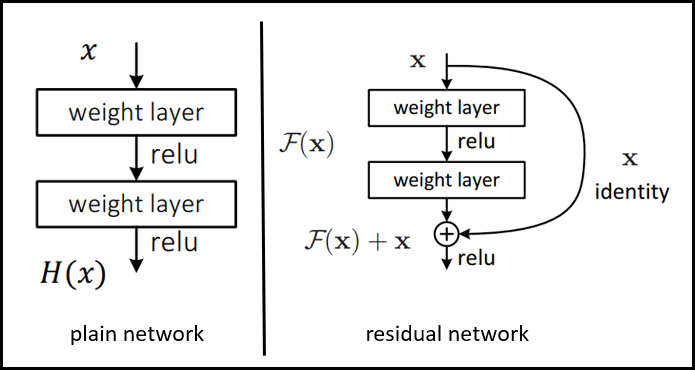
residual network는 앞단 레이어의 출력값이 입력으로 들어온 x를 feed forward 한 값에 다시 x를 더해준다. 이게 왜 효과가 있을까? 왼쪽 일반 신경망과의 학습 방식이 다르기 때문이다. 일반 신경망은 입력 $x$를 통해 출력 $H(x)$를 얻는 $H(x) = x$다. 반면 오른쪽 residual network는 $H(x) = F(x) + x$가 된다. 중간에 $F(x)$가 추가된 것이다. 이 때 이 추가된 $F(x)$를 0이 되도록 학습한다면 일반 신경망인 $H(x) = x$와 같아진다. 하지만 이렇게 둘러온다면 하나의 큰 장점이 있다. 일반 신경망처럼 역전파가 진행될 때 $H(x) = x$에서 미분하는 것과 달리 residual network를 이용해 미분하게 되면 $H'(x) = F'(x) + 1$이 된다. 즉 1도 남기 때문에 기울기가 0에 수렴하여 소실되지 않고 역전파가 끝까지 진행될 수 있는 것이다.
이해가 안될 경우를 대비해 조금 더 설명하면, $H(x) = F(x) +x$을 이항하면 $F(x) = H(x) - x$가 된다. 이 때 $F(x)$를 0에 근사하게 만든다면 $H(x) - x$도 0에 근사하게 된다. 다시 이항하면 기존 신경망과 같이 $H(x) = x$의 형태가 된다. 양쪽 모두 역전파로 인해 미분되어 0에 근사하게 되면 기울기 소실 문제가 발생하는 것이다. 참고로 $H(x) - x$을 residual이라 부르며, residual network에선 기존 신경망의 학습 목적인 $H(x)$를 최소화 해주는 것이 아니라 $F(x)$를 최소화 시켜주는 것이다. $F(x) = H(x) - x$이므로.
ResNet에서는 residual network를 아래 두 가지 방식을 사용해 구현했다. 첫 번째는 바로 위 그림과 마찬가지로 단순한 구조를 사용하는 Identity 방식과, 두 번째는 1x1 convolution 연산을 통해 차원을 스케일링 해주는 Projection 방식이다.
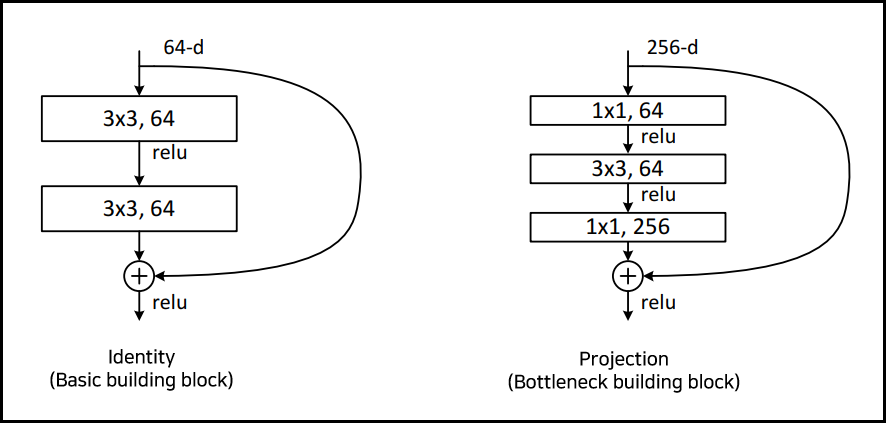
기존의 Identity 방식에 더해 Projection 방식이 더해진 이유는 입력/출력 차원이 다를 때 스케일링 해주기 위함이다. 또 Projection 방식은 네트워크를 깊게 만들어줄 때 학습 시간을 줄이기 위해 사용하는데, 위 두 구조가 비슷한 시간 복잡도를 갖기 때문이라고 한다.
다시 돌아와 이러한 residual network 구조를 사용하는 것이 ResNet 이해의 핵심이다. 이렇게 residual network를 모델 레이어로 쌓으면 다음과 같은 성능 증가를 가져오게 된다.
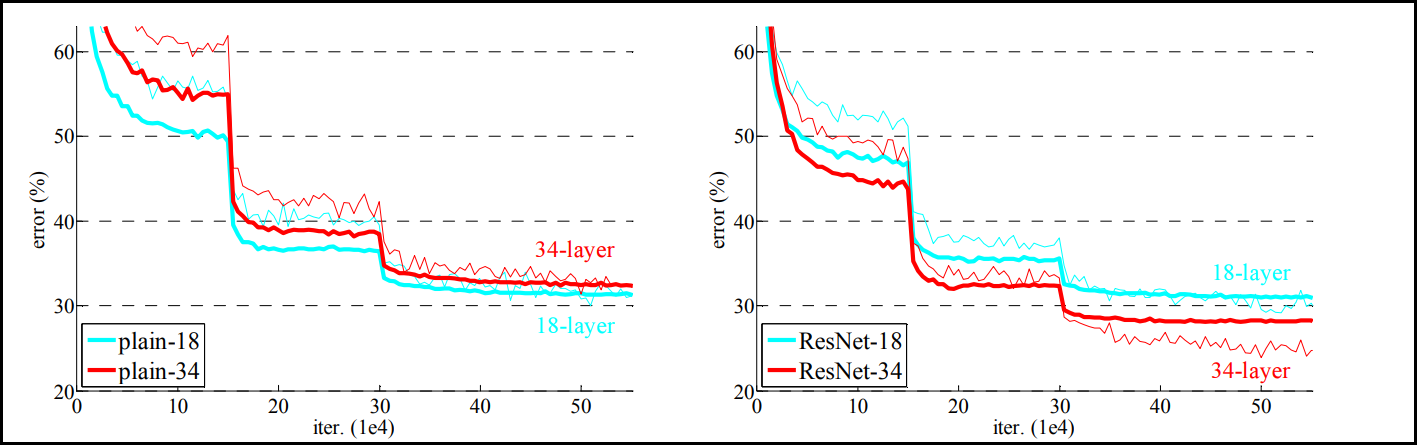
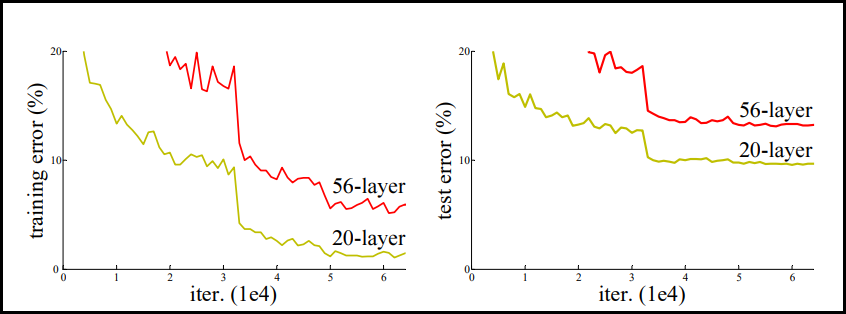
좌측의 residual network를 적용하지 않은 plain network를 살펴보면 레이어를 깊게 해줄수록 성능이 오히려 떨어지게 된다. 반면 residual network를 모델에 적용하게 되면 레이어가 깊더라도 error rate가 떨어져 성능이 더 좋아지는 것을 확인할 수 있다.
그렇다면 더욱 더 residual network를 쌓게 되면 어떤 결과가 나올까? 아래를 보자. 참고로 ResNet에서 50개의 layer가 넘어가는 모델들은 Projection 방법 (Bottleneck building block)을 사용하여 만든 모델이다. 반대로 50개 미만은 Identity 방법 (Basic building block)으로 만들었다.
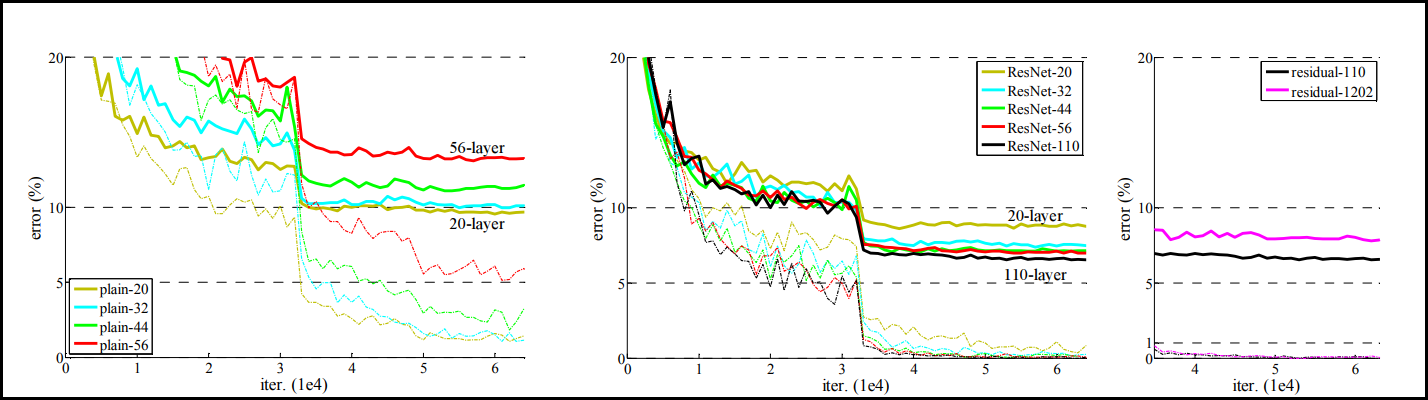
좌측 residual network를 적용하지 않은 plain network의 경우에는 레이어가 깊어질수록 성능이 계속 떨어지는 것을 볼 수 있다. 반면 가운데 그래프처럼 ResNet을 적용하면 error율이 아닐 때 보다 더 감소한 것을 볼 수 있다. 또한 110개의 네트워크를 쌓더라도 성능이 증가하는 것을 볼 수 있다. 다만 우측 그래프처럼 residual network를 1202개까지 쌓게 되면 오히려 110개를 쌓았을 때 보다 성능이 좋지 않다. 하지만 이를 두고 1202개 가량을 쌓았을 때가 ResNet의 한계라고 해석할 수 없다. 그 이유는 CIFAR-10 데이터셋만으로는 불충분해 overfitting 되었을 가능성이 있기 때문이고, 또 ResNet 논문 저자들은 그 어떤 Dropout과 같은 Regularization을 적용하지 않았다고 말했다. 따라서 강력한 Regularization을 적용한다면 성능 향상의 여지가 있는 것이다.
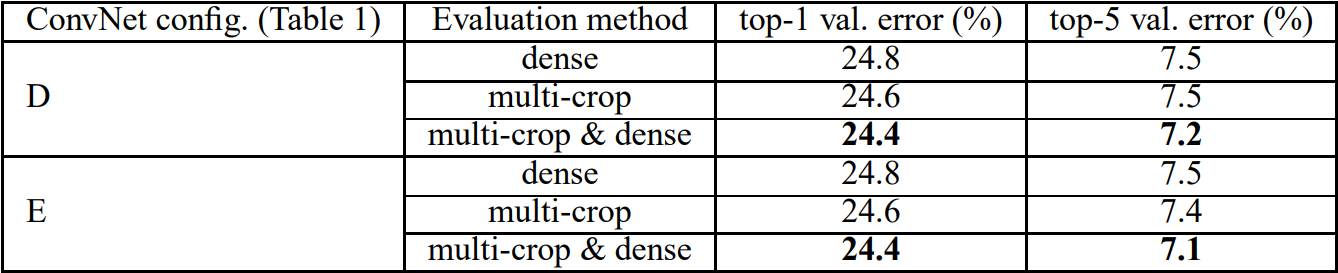
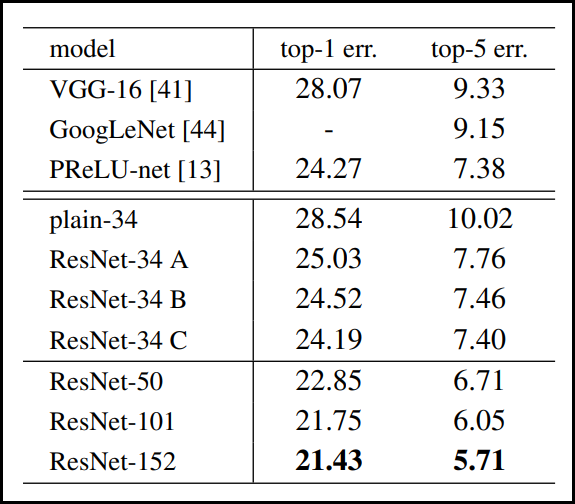
마지막으로, ResNet 모델의 개선 여지가 있음에도 불구하고 아래 표와 같이 이전에 나온 VGGNet과 GoogLeNet 모델보다도 높은 성능을 보였다.
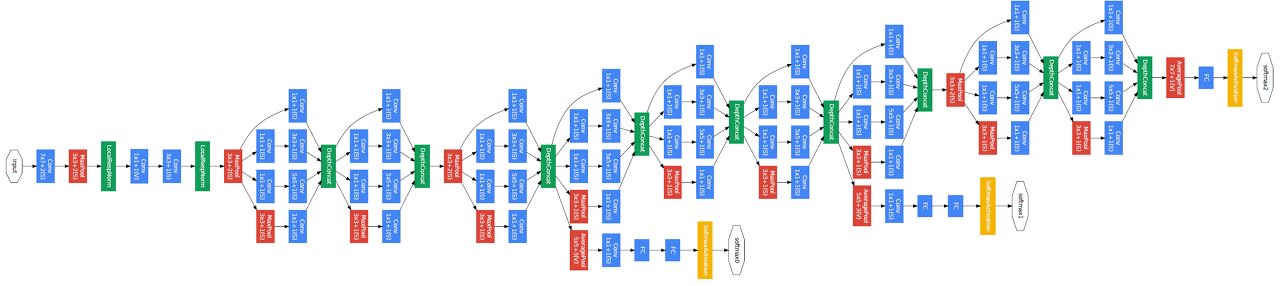
ResNet을 구현하기 위해 먼저 가장 핵심인 ResNet 모델 아키텍처를 살펴보면 다음과 같다.

하나의 max-pool 레이어와, 하나의 average-pool 레이어를 제외하고 모두 convolution 레이어로 구성되어 있다. 또 18, 34 layer는 레이어 구조상 Basic Building Block을 사용하며 50, 101, 152 layer는 Bottleneck Building Block을 사용한다.
그리고 논문에서 구현에 적용되었던 augmentation 기법과 레이어 특이 사항, 하이퍼파라미터 값을 정리하면 다음과 같다.
1. Augmentation
- 이미지를 스케일 별 augmentation을 위해 이미지 사이즈를 256~480 범위에서 랜덤 샘플링 진행
- 픽셀별 mean substracted을 진행하고, 224x224 이미지에 crop을 랜덤 샘플링 수행하거나 수평 플립을 적용한 이미지에서 crop을 랜덤 샘플링함
- color augmentation을 사용함
2. Layer
- Batch Normalization 적용 (convolution 이후, activation function 이전)
- weight initialization 진행
- Dropout 미사용
- residual network에서 차원이 증가한다면 아래 두 가지 방식 적용
- 제로 패딩으로 차원 증가에 대응: 추가적인 파라미터 없어 좋음
- 1x1 convolution으로 차원 스케일링 해준 뒤 다시 원래 차원으로 스케일링 진행
3. Hyper-parameter
- 옵티마이저: SGD 사용
- 배치 사이즈: 256
- weight decay: 0.0001, momentum: 0.9
- 학습율: 0.1로 시작해서 validation error가 줄지 않으면 x10씩 줄여나감.
- $60\times 10^4$ iteration까지 진행되었음
ResNet 구현을 위해 가장 먼저 핵심이 되는 Identity 방식의 Basic building block을 만들어준다.
import torch
from torch import Tensor
import torch.nn as nn
class BasicBlock(nn.Module):
expansion_factor = 1
def __init__(self, in_channels: int, out_channels: int, stride: int = 1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU()
self.residual = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion_factor:
self.residual = nn.Sequential(
nn.Conv2d(in_channels, out_channels*self.expansion_factor, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*self.expansion_factor))
def forward(self, x: Tensor) -> Tensor:
out = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.bn2(x)
x += self.residual(out)
x = self.relu2(x)
return x
다음으로 또 다른 구조인 Projection 방식의 Bottleneck building block을 만들어 준다.
class BottleNeck(nn.Module):
expansion_factor = 4
def __init__(self, in_channels: int, out_channels: int, stride: int = 1):
super(BottleNeck, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu1 = nn.ReLU()
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU()
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion_factor, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels*self.expansion_factor)
self.relu3 = nn.ReLU()
self.residual = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion_factor:
self.residual = nn.Sequential(
nn.Conv2d(in_channels, out_channels*self.expansion_factor, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*self.expansion_factor))
def forward(self, x:Tensor) -> Tensor:
out = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.conv3(x)
x = self.bn3(x)
x += self.residual(out)
x = self.relu3(x)
return x
위 두 구조에 따라 ResNet을 구성할 수 있도록 모델을 구성해준다.
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.conv2 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.conv3 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.conv4 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.conv5 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(512 * block.expansion_factor, num_classes)
self._init_layer()
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion_factor
return nn.Sequential(*layers)
def _init_layer(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x: Tensor) -> Tensor:
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
ResNet 아키텍처에 표시된 레이어의 개수를 맞춰준 모델을 반환하는 클래스를 정의한다.
class Model:
def resnet18(self):
return ResNet(BasicBlock, [2, 2, 2, 2])
def resnet34(self):
return ResNet(BasicBlock, [3, 4, 6, 3])
def resnet50(self):
return ResNet(BottleNeck, [3, 4, 6, 3])
def resnet101(self):
return ResNet(BottleNeck, [3, 4, 23, 3])
def resnet152(self):
return ResNet(BottleNeck, [3, 8, 36, 3])
마지막으로 간단한 테스트를 위해 모델을 불러오고 랜덤 생성한 데이터를 넣어주고 결과를 확인한다.
model = Model().resnet152()
y = model(torch.randn(1, 3, 224, 224))
print (y.size()) # torch.Size([1, 10])
데이터셋으로 직접 학습 시켜보고자 한다면 train 코드는 아래 링크에 함께 구비해두었다.
전체 코드: https://github.com/roytravel/paper-implementation/tree/master/resnet
Reference
[1] https://github.com/weiaicunzai/pytorch-cifar100/blob/master/models/resnet.py
[2] https://github.com/kuangliu/pytorch-cifar/blob/master/models/resnet.py
[3] https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
'Artificial Intelligence > 논문 리딩&구현' 카테고리의 다른 글
| [논문 리뷰 #5] PPTOD 모델을 활용한 end-to-end 챗봇 시스템 설계 (0) | 2022.11.26 |
|---|---|
| [논문 리뷰 #4] 멀티 도메인 대화시스템을 위한 도메인 결정 기술 (0) | 2022.11.25 |
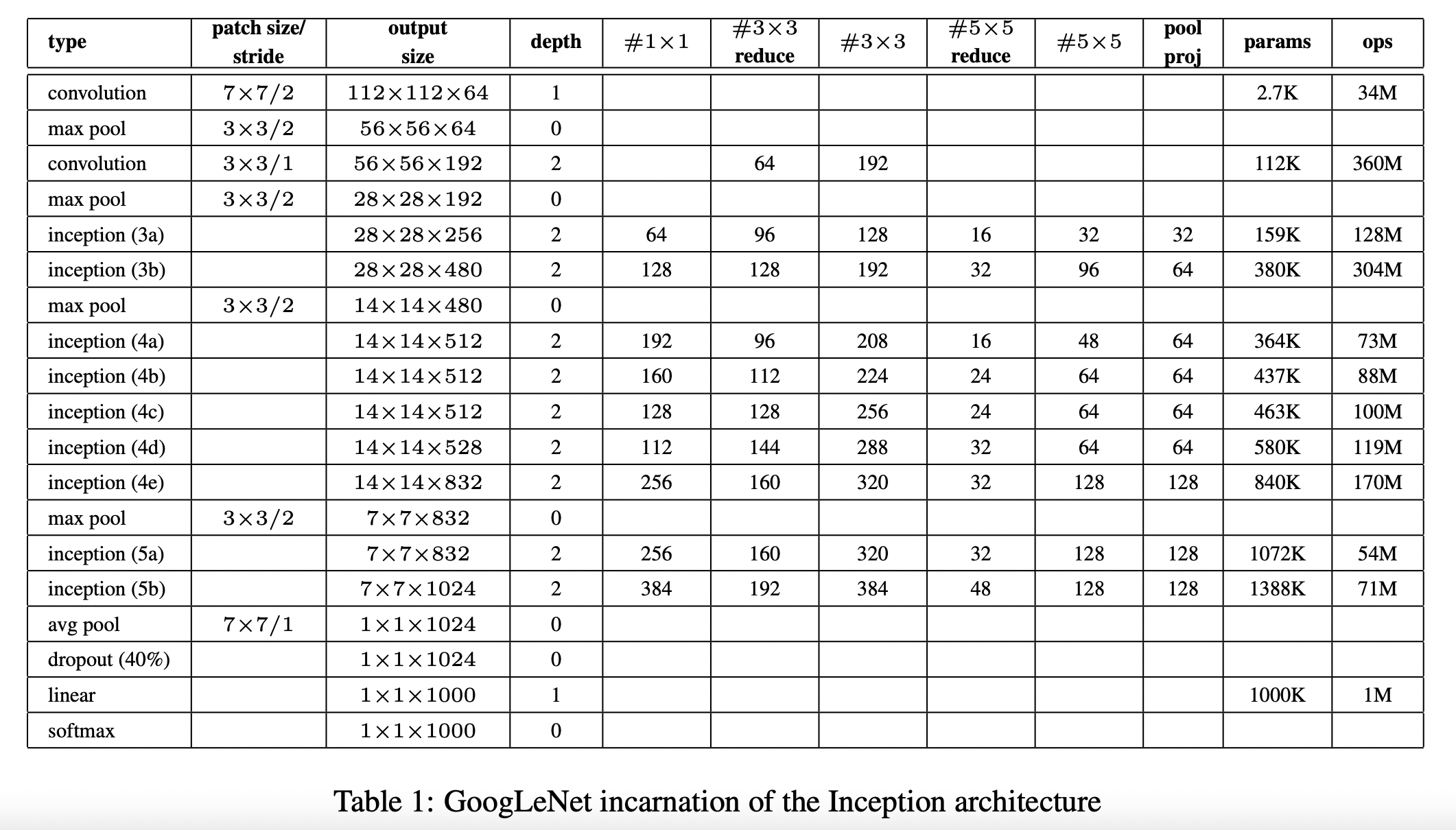
| [논문 구현] GoogLeNet 파이토치로 구현하기 (0) | 2022.09.12 |
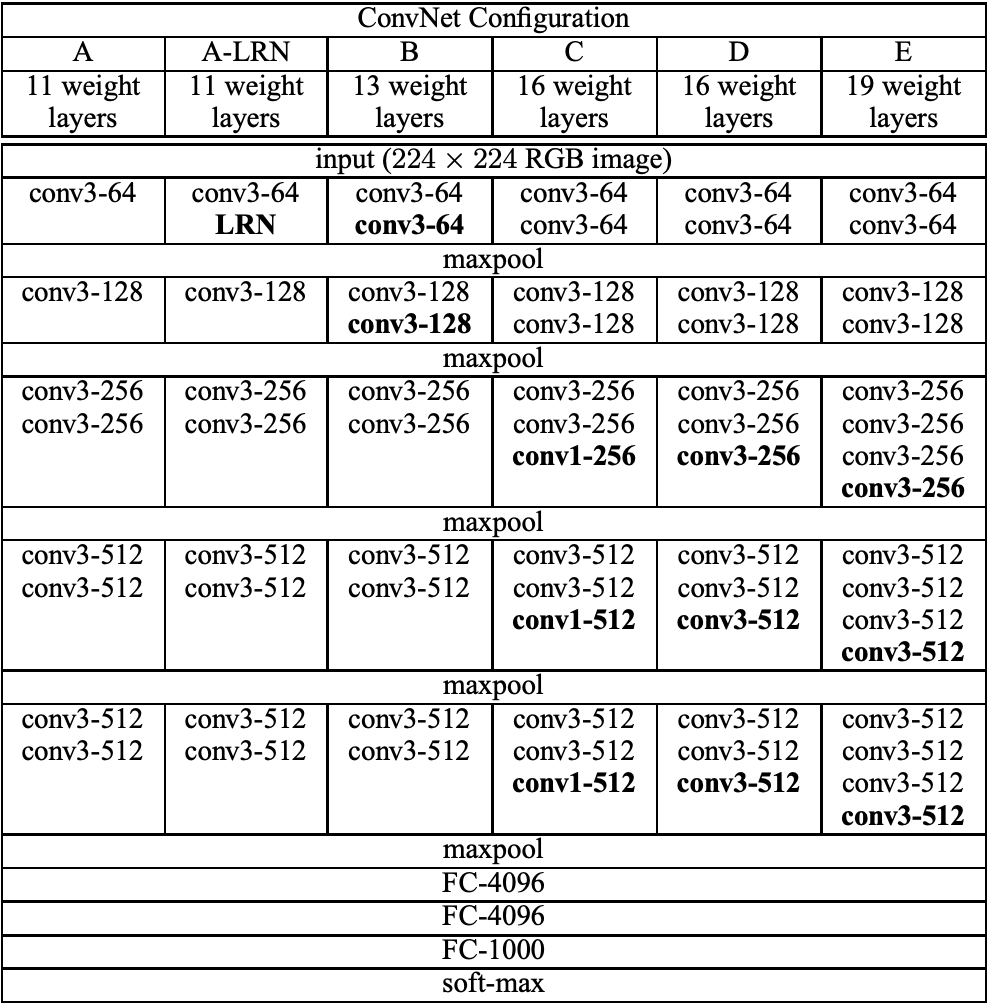
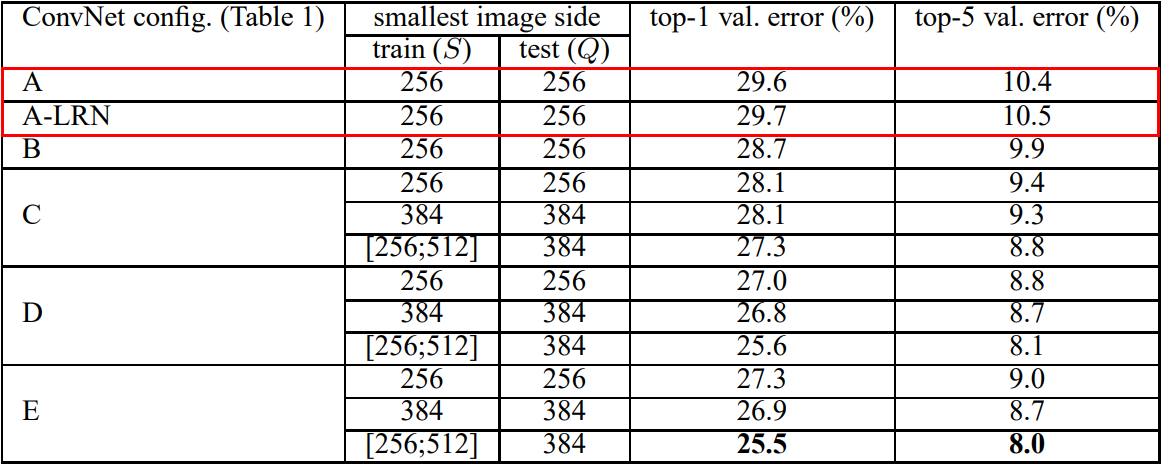
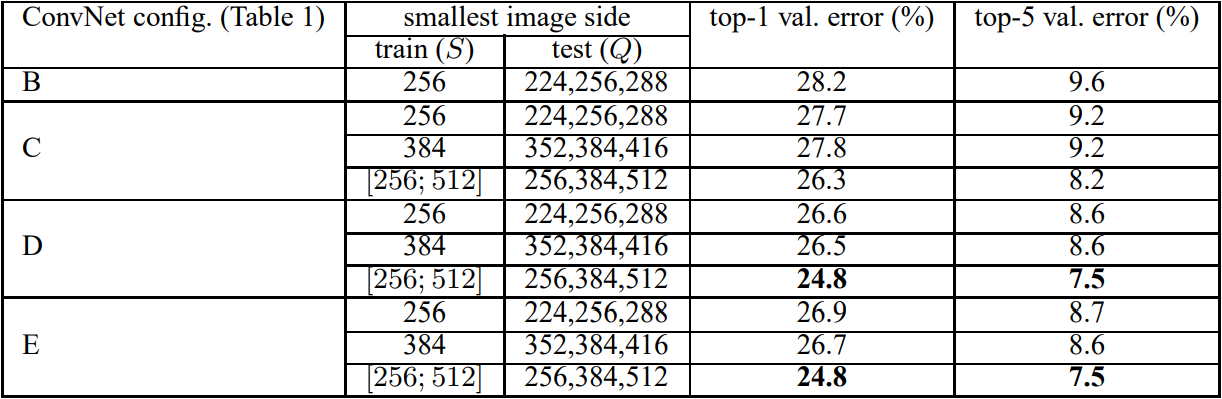
| [논문 구현] VGGNet 파이토치로 구현하기 (0) | 2022.09.08 |
| [논문 구현] AlexNet 파이토치로 구현하기 (2) | 2022.09.07 |