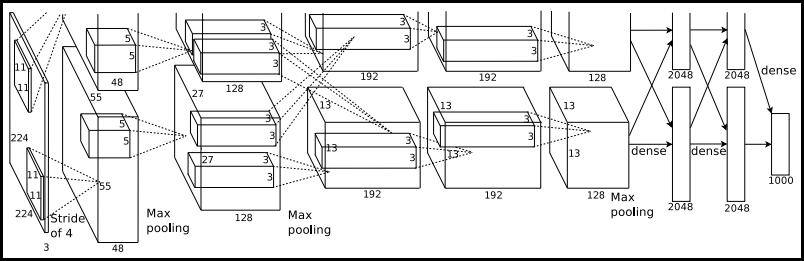
[논문 정보]
제목: Very Deep Convolutional Networks For Large-Scale Image Recognition
게재: 2015년
학회: ICLR (International Conference on Learning Representations)
이 글에서는 크게 두 개의 파트로, 첫 번째론 VGGNet 논문의 연구를 설명하고, 두 번째로 VGGNet 모델을 구현한다.
개요
VGGNet은 2014년 ILSVRC에서 localisation과 classification 트랙에서 각각 1위와 2위를 달성한 모델이다. 이 모델이 가지는 의미는 2012년 혁신적이라 평가받던 AlexNet보다도 높은 성능을 갖는다는 점에서 의미가 있다. 실제로 아래 벤치마크 결과를 확인해보면 맨 아래에 있는 Krizhevsky et al. (Alexnet) 보다도 성능이 월등히 좋은 것을 확인할 수 있다.

2010년 초/중반에는 위 성능 비교표가 나타내는 것처럼 Convolutional network를 사용한 모델의 성능이 점점 높아졌다. 이러한 성능 증가의 배경에는 ImageNet과 같은 large scale 데이터를 활용가능 했기 때문이고 high performance를 보여주는 GPU를 사용했다는 점이다.
2012년 AlexNet이 나온 이후에는 AlexNet을 개선하려는 시도들이 많았다. 더 작은 stride를 사용하거나 receptive window size를 사용하는 등 다양한 시도들이 있었다. VGGNet은 그 중에서 네트워크의 깊이 관점으로 성능을 올린 결과물이라 할 수 있다.
VGGNet을 만들기 위해 사용했던 아키텍처를 살펴보면 아래와 같다. 모든 모델 공통적으로 convolutional layer이후 fully-connected layer가 뒤 따르는 구조이다. 모델 이름은 A, A-LRN, B, C, D, E로 지정했으며 이 중 VGG라 불리는 것은 D와 E이다. 참고로 간결성을 위해 ReLU 함수는 아래 표에 추가하지 않았다.
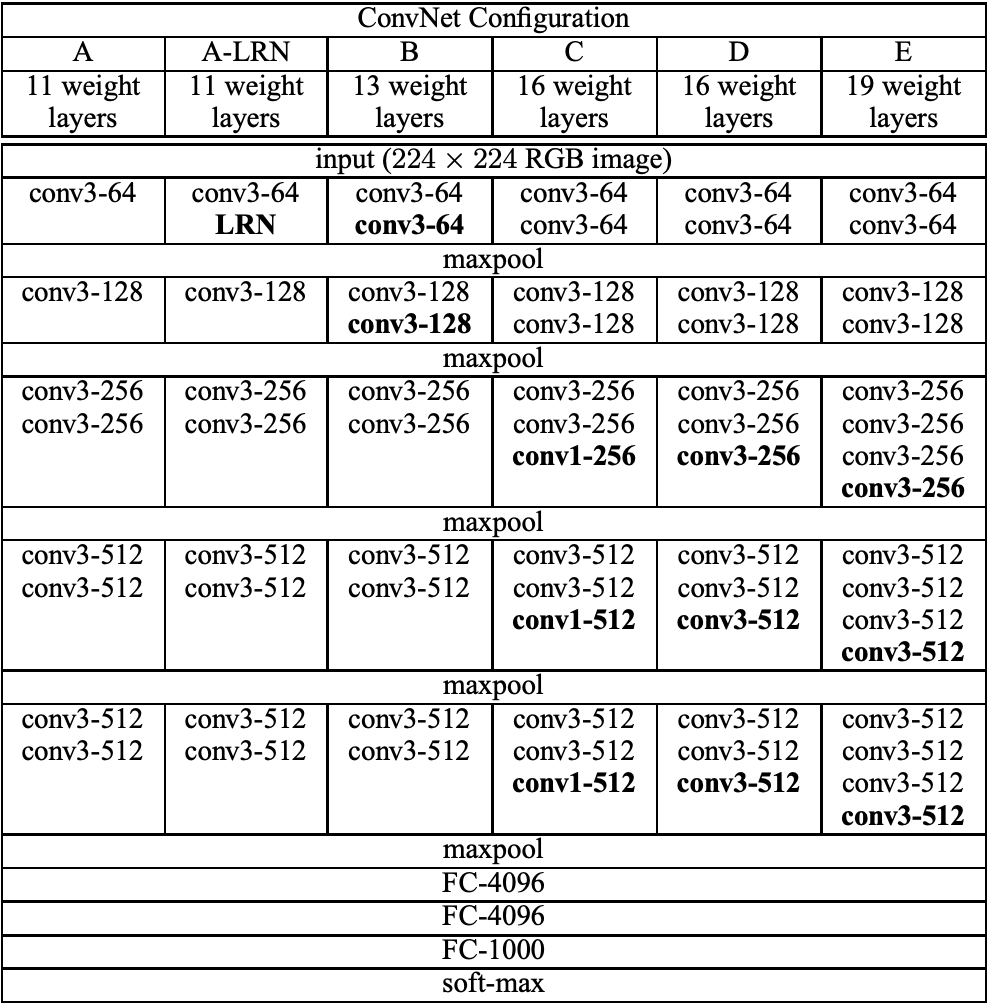
이 논문에선 실험을 위해 네트워크의 깊이를 늘려가면서도 동시에 receptive field를 3x3과 1x1로 설정했다. receptive field는 컨볼루션 필터가 한 번에 보는 영역의 크기를 의미한다. AlexNet은 receptive field가 11x11의 크기지만 VGGNet은 3x3으로 설정함으로써 파라미터 수를 줄이는 효과를 가져왔고 그 결과 성능이 증가했다. 실제로 3x3이 두 개가 있으면 5x5가 되고 3개를 쌓으면 7x7이 된다. 이 때 5x5 1개를 쓰는 것 보다 3x3 2개를 써서 layer를 더 깊이할 수록 비선형성이 증가하기에 더 유용한 feature를 추출할 수 있기에 위 아키텍처에서는 receptive field가 작은 convolution layer를 여러 개를 쌓았다. 참고로 receptive field를 1x1로 설정함으로써 컨볼루션 연산 후에도 이미지 공간 정보를 보존하는 효과를 가져왔다고 한다.
위 표 1에서 확인할 수 있는 A-LRN 모델을 통해서 보인 것은 AlexNet에서 도입한 LRN(Local Response Network)이 사실상 성능 증가에 도움되지 않고 오히려 메모리 점유율과 계산 복잡도만 더해진다는 것이다. 아래 표를 통해 LRN의 무용성을 확인할 수 있다. 또한 표 1에서 네트워크 깊이가 가장 깊은 모델 E (VGGNet)가 가장 좋은 성능을 보이는 것을 확인할 수 있다.
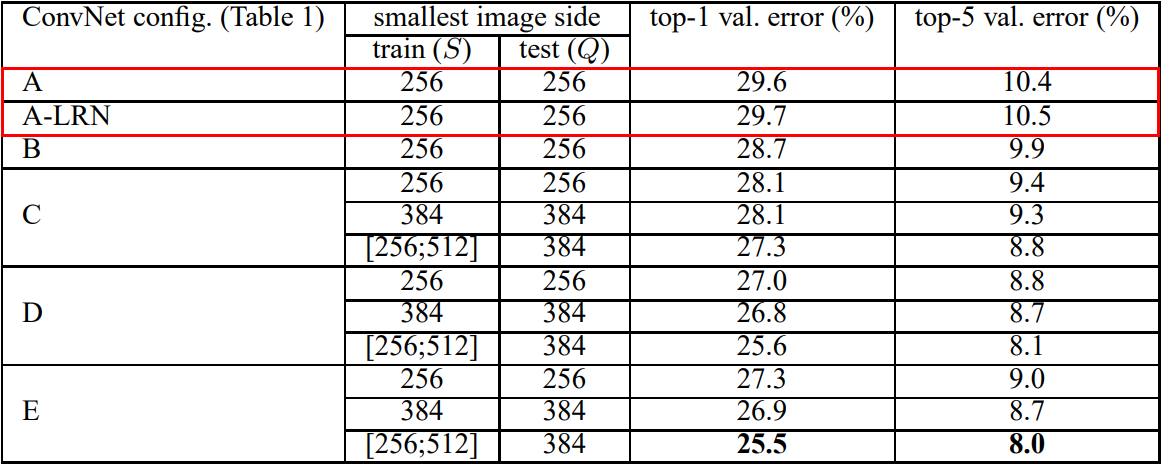
참고로, S, Q는 각각 train과 test에 사용한 이미지 사이즈 크기를 의미한다. 이를 기술한 이유는 scale jittering이라는 이미지 어그멘테이션 기법을 적용했을 때 성능이 더 높아진다는 것을 보인 것이다. 이 논문에선 scale jittering에 따라 달라지는 성능을 비교하기 위해 single-scale training과 multi-scale training으로 나누어 진행했다. single-scale training이란 이미지의 크기를 고정하는 것이다. 가령 train 때 256 또는 384로 진행하면 test때도 각각 256 또는 384로 추론을 진행하는 것이다. 반면 multi-scale training의 경우 S를 256 ~ 512에서 랜덤으로 크기가 정해지는 것이다. 이미지 크기의 다양성 때문에 모델이 조금더 robustness해지며 정확도가 높아지는 효과가 있다. 아래 표 4는 multi-scale training을 적용했을 때의 성능 결과이다.
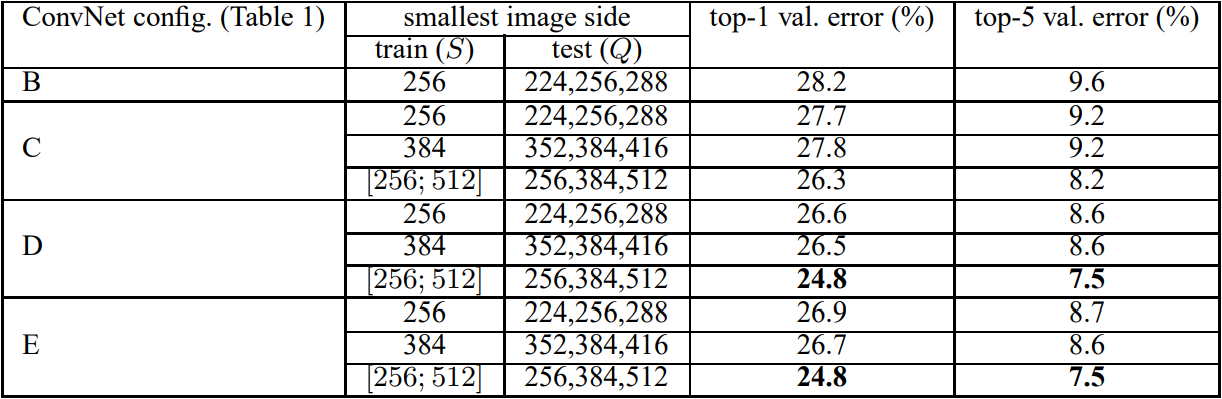
single-scale training에 비해 성능이 더욱 증가한 것을 알 수 있다. 추가적으로 S를 고정 크기의 이미지로 사용했을 경우보다 S를 256 ~ 512사이의 랜덤 크기의 이미지를 사용했을 때 더욱 성능이 높아지는 것을 확인할 수 있다.
또한 이 논문에서는 모델의 성능을 높이기 위해 evaluation technique으로 multi-crop을 진행했다. dense와 multi-crop을 동시에 사용하는 것이 더 높은 성능을 보이는 것을 확인할 수 있다.
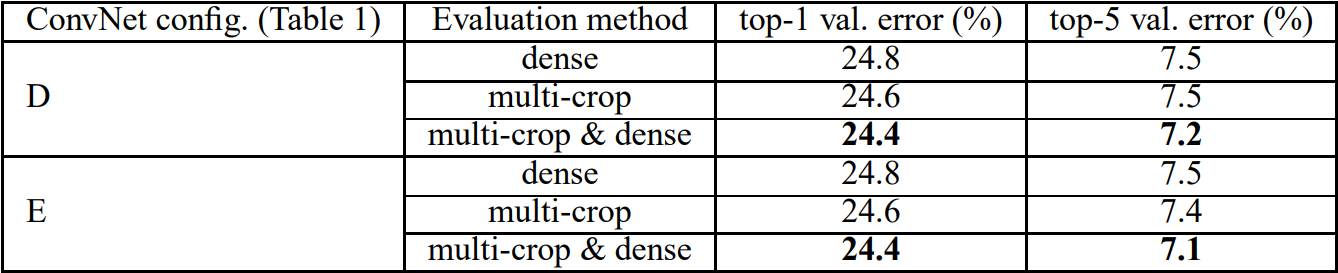
마지막으로 여지껏 개별 ConvNet 모델에 대해 성능을 평가했다면 앙상블을 통해 여러 개의 모델의 출력을 결합하고 평균을 냈다. 결론적으로 D, E 두 모델의 앙상블을 사용해 오류율을 6.8%까지 현저히 줄이는 것을 보였다.

여기까지가 VGGNet 논문에 대한 내용이다. 다음은 VGGNet 논문 구현에 관한 것이다. 이 논문을 읽으며 구현해야 할 목록을 정리해본 것은 다음과 같다.
1. Model configuration.
Convolution Filter
- 3x3 receptive field
- 좌/우/상/하를 모두를 포착할 수 있는 가장 작은 사이즈
- 1x1 convolution filter 사용
- spacial information 보존을 위함
Convolution Stride
- 1로 고정
Max-Pooling Layer
- kernel size: 2x2
- stride: 2
- 5개의 max-pooling 레이어에 의해 수행됨. 대부분 max-pooling은 conv layer와 함께하지만 그렇지 않은 것도 있음
Fully-Connected Layer
- convolutional layer 스택 뒤에 3개의 FC layer가 따라 옴
- 앞의 2개는 4096 채널을 각각 가지고 마지막은 1000개를 가지면서 소프트맥스 레이어가 사용됨
Local Response Normalization
- Local Response Normalization 사용 X: LRN Layer가 성능 개선X이면서 메모리 점유율과 계산 복잡도만 높아짐
2. Initialization
잘못된 초기화는 deep network에서 gradient 불안정성으로 학습 지연시킬 수 있기에 중요함
- weight sampling: 평균 0, 분산이 $10^{-2}$ variance인 정규분포 사용
- bias: 0로 초기화
3. Augmentation
- random crop:고정된 224x224 입력 이미지를 얻기 위함
- horizontal flip
- random RGB color shift
- 고정 사이즈 224x224 RGB image를 사용했고, 각 픽셀에 대해 RGB value의 mean을 빼주는 것이 유일한 전처리(?)
4. Hyper-parameter
- optimizer: SGD
- momentum: 0.9
- weight decay: L2 $5\cdot 10^{-4} = 0.0005$
- batch size: 256
- learning rate: 0.1
- validation set 정확도가 증가하지 않을 때 10을 나눔
- 학습은 370K iteration (74 epochs)에서 멈춤
- dropout: 0.5
- 1, 2번째 FC layer에 추가
이를 바탕으로 VGGNet에 대한 코드를 구현하면 다음과 같다. 크게 1. 모델 레이어 구성 2. 가중치 초기화 3. 하이퍼파라미터 설정 4. 데이터 로딩 5. 전처리 6. 학습으로 구성된다 볼 수 있다.
import time
import torch
import torch.nn as nn
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils import data
CONFIGURES = {
"VGG11": [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
"VGG13": [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
"VGG16": [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
"VGG19": [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGGNet(nn.Module):
def __init__(self, num_classes: int = 1000, init_weights: bool = True, vgg_name: str = "VGG19") -> None:
super(VGGNet, self).__init__()
self.num_classes = num_classes
self.features = self._make_layers(CONFIGURES[vgg_name], batch_norm=False)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7, 7))
self.classifier = nn.Sequential(
nn.Linear(in_features=512 * 7 * 7, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=num_classes),
)
if init_weights:
self._init_weight()
def _init_weight(self) -> None:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") # fan out: neurons in output layer
if m.bias is not None:
nn.init.constant_(m.bias, val=0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, val=1)
nn.init.constant_(m.bias, val=0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.constant_(m.bias, val=0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
# print (x.size()) # torch.Size([2, 512, 7, 7])
x = x.view(x.size(0), -1) # return torch.Size([2, 1000])
x = self.classifier(x)
return x
def _make_layers(self, CONFIGURES:list, batch_norm: bool = False) -> nn.Sequential:
layers: list = []
in_channels = 3
for value in CONFIGURES:
if value == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels=in_channels, out_channels=value, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(value), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = value
return nn.Sequential(*layers)
if __name__ == "__main__":
# for simple test
# x = torch.randn(1, 3, 256, 256)
# y = vggnet(x)
# print (y.size(), torch.argmax(y))
# set hyper-parameter
seed = torch.initial_seed()
BATCH_SIZE= 256
NUM_EPOCHS = 100
LEARNING_RATE = 0.1 # 0.001
CHECKPOINT_PATH = "./checkpoint/"
device = "cuda" if torch.cuda.is_available() else "cpu"
vggnet = VGGNet(num_classes=10, init_weights=True, vgg_name="VGG19")
# preprocess = transforms.Compose([
# transforms.RandomResizedCrop(size=224),
# transforms.RandomHorizontalFlip(),
# transforms.ColorJitter(),
# transforms.ToTensor(),
# transforms.Normalize(mean=(0.48235, 0.45882, 0.40784), std=(1.0/255.0, 1.0/255.0, 1.0/255.0))
# ])
preprocess = transforms.Compose([
transforms.Resize(224),
# transforms.RandomCrop(224),
transforms.ToTensor(),
#transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
train_dataset = datasets.STL10(root='./data', download=True, split='train', transform=preprocess)
train_dataloader = data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataset = datasets.STL10(root='./data', download=True, split='test', transform=preprocess)
test_dataloader = data.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(lr=LEARNING_RATE, weight_decay=5e-3, params=vggnet.parameters(), momentum=0.9)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=0.1, patience=3, verbose=True)
vggnet = torch.nn.parallel.DataParallel(vggnet, device_ids=[0, ])
start_time = time.time()
""" labels = ['airplane', 'bird', 'car', 'cat', 'deer', 'dog', 'horse', 'monkey', 'ship', 'truck']"""
for epoch in range(NUM_EPOCHS):
# print("lr: ", optimizer.param_groups[0]['lr'])
for idx, _data in enumerate(train_dataloader, start=0):
images, labels = _data
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
output = vggnet(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
if idx % 10 == 0:
with torch.no_grad():
_, preds = torch.max(output, 1)
accuracy = torch.sum(preds == labels)
print ('Epoch: {} \tStep: {}\tLoss: {:.4f} \tAccuracy: {}'.format(epoch+1, idx, loss.item(), accuracy.item() / BATCH_SIZE))
scheduler.step(loss)
#checkpoint_path = os.path.join(CHECKPOINT_PATH)
state = {
'epoch': epoch,
'optimizer': optimizer.state_dict(),
'model': vggnet.state_dict(),
'seed': seed,
}
if epoch % 10 == 0:
torch.save(state, CHECKPOINT_PATH+'model_{}.pth'.format(epoch))
transforms.Compose 메서드에서 Normalize에 들어갈 mean과 std를 구하는 과정은 아래 링크를 참조할 수 있다.
https://github.com/Seonghoon-Yu/AI_Paper_Review/blob/master/Classification/VGGnet(2014).ipynb
Code: https://github.com/roytravel/paper-implementation/tree/master/vggnet
Reference
[1] https://github.com/minar09/VGG16-PyTorch/blob/master/vgg.py
[2] https://github.com/pytorch/vision/blob/main/torchvision/models/vgg.py
[3] https://github.com/kuangliu/pytorch-cifar/blob/master/models/vgg.py
'Artificial Intelligence > 논문 리딩&구현' 카테고리의 다른 글
| [논문 구현] ResNet 파이토치로 구현하기 (0) | 2022.09.18 |
|---|---|
| [논문 구현] GoogLeNet 파이토치로 구현하기 (0) | 2022.09.12 |
| [논문 구현] AlexNet 파이토치로 구현하기 (2) | 2022.09.07 |
| [논문 리뷰 #3] Dialogue Management in Conversational Systems: A Review of Approaches, Challenges, and Opportunities (0) | 2022.08.19 |
| [논문 리뷰 #2] Review of Intent Detection Methods in the Human-Machine Dialogue System (0) | 2022.08.18 |