
주성분 분석이란 무엇일까?
주성분 분석은 차원 축소에 사용되는 대표적인 알고리즘이다. 차원 축소는 고차원 공간 데이터를 저차원 공간으로 옮기는 것을 말한다. 그렇다면 이 차원축소가 왜 필요할까? 고차원으로 표현된 데이터는 계산 비용 많고 분석에 필요한 시각화가 어렵기 때문이다. 또 고차원을 이루는 피처 중 상대적으로 중요도가 떨어지는 피처가 존재할 수 있기 때문이다. 따라서 중요도가 낮은 피처를 제외하는 대신 계산 비용이나 비교적 준수한 성능을 얻는다. 주성분 분석을 진행하면 차원 축소로 인해 표현력이 일부 손실된다. 만약 4차원에서 2차원으로 축소를 통해 첫 번째 주성분과 두 번째 주성분을 얻고, 이 두 개가 원래 피처 표현력의 90%를 띤다면 나머지 10%의 손실을 감수하더라도 계산 효율을 얻게 된다.
주성분 분석을 통해 저차원 공간으로 변환할 때 피처 추출(feature extraction)을 진행한다. 이는 기존 피처를 조합해 새로운 피처로 만드는 것을 의미한다. 이 때 새로운 피처와 기존 피처 간 연관성이 없어야 한다. 연관성이 없도록 하기 위해 직교 변환을 수행한다. 직교 변환을 수행하면 새로운 피처 공간과 기존 피처 공간이 90도를 이루게 된다. 즉 내적하면 0이 되는 것이다. 이러한 직교 변환을 수행할 때 기존 피처와 관련 없으면서 원 데이터의 표현력을 '잘' 보존해야 한다. 잘 보존하는 것은 주성분 분석의 핵심인 분산(Variance)을 최대로 하는 주축을 찾는 것이다.
여기서 분산이란? 데이터가 퍼진 정도를 의미한다. 예를 들어 만약 4차원 공간이 있고 3차원 공간으로 차원 축소를 한다면 3차원 공간상에서 데이터 분포가 넓게 퍼지는, 즉 분산을 가장 크게 만드는 벡터를 찾아야 한다. 만약 3차원 공간이 있고 2차원 공간으로 차원 축소한다면, 2차원 공간상에서 데이터 분포가 가장 넓게 퍼지도록 하는 벡터를 찾아야 한다. 만약 2차원 공간이 있고 1차원 공간으로 차원 축소 한다면 1차원 공간상에서 데이터 분포가 가장 넓게 퍼지게 만드는 벡터를 찾아야 한다.
애니메이션으로 이해하자면 다음과 같다.
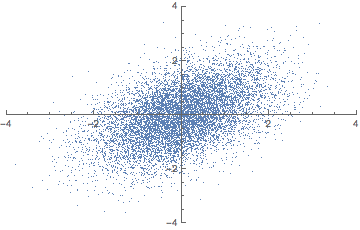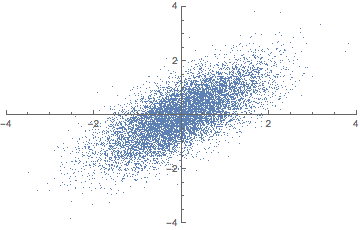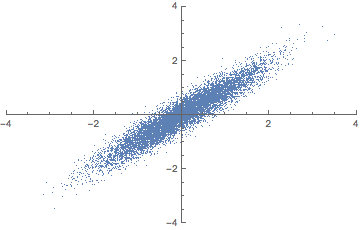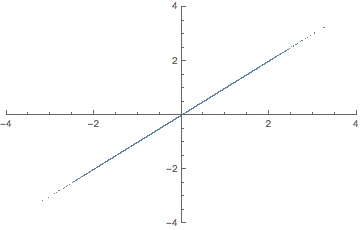
2차원 공간을 1차원으로 줄일 때 2차원에 넓게 퍼진 데이터 분포를 1차원 상에서도 똑같이 넓게 퍼질 수 있도록 하는 "벡터"를 찾아야 한다. 여기서 "벡터"는 곧 주축을 의미한다. 이 때 주축과의 동의어를 Eigen vector라고 한다. 주축을 찾고 주축에 피처들을 사상시키게 되면 주성분이 된다. 다르게 말해 피처들을 주축에 사상시킬 때 분산이 최대가 되는 주성분이 만들어진다. 이렇게 분산이 가장 큰 주성분을 첫 번째 주성분, 두 번째로 큰 축을 두 번째 주성분이라 한다.
그렇다면 이 주축인 Eigen vector는 어떻게 구하고, Eigen vector에 피처를 어떻게 사상시킬수 있는 것일까? Eigen vector를 구하기 위해서는 특이값 분해 (SVD, Singular Value Decomposition)가 수행된다. 또 사상을 위해서 공분산 행렬이 필요하다. 따라서 사실상 PCA를 한마디로 말하면 데이터들의 공분산 행렬에 대한 특이값 분해(SVD)로 볼 수 있다. 먼저 공분산 행렬에 대해 알아보자.
공분산 행렬이란 무엇일까?
공분산은 한 마디로 두 피처가 함께 변하는 정도, 즉 공변하는 정도를 나타낸다. 수식으로 표현하면 다음과 같다.
$\sum = Cov(X) = {X^TX\over n}$
여기서 n은 행렬 X에 있는 데이터 샘플 개수를 나타내며 $X$란 전체 피처와 데이터 값을 나타낸다. X의 열축은 피처가 되고 X의 행축은 데이터 개수가 된다. 예를 들어 $x_1, x_2, x_3 $ 피처 3개가 있다고 가정하면 $X^T \times T$는 아래와 같이 표현할 수 있다.
$X^T \times X = $ $\begin{vmatrix} 0.1 & 0.4 & 0.7 \\ 0.2 & 0.5 & 0.8 \\ 0.3 & 0.6 & 0.9 \end{vmatrix}$ $\times$ $\begin{vmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ 0.7 & 0.8 & 0.9 \end{vmatrix}$
전치 행렬과 행렬을 내적하게 되면 아래와 같은 대칭 행렬이 만들어진다.
$\begin{vmatrix} dot(x_1,x_1) & dot(x_1,x_2) & dot(x_1,x_3) \\ dot(x_2,x_1) & dot(x_2,x_2) & dot(x_2,x_3) \\ dot(x_3,x_1) & dot(x_3,x_2) & dot(x_3,x_3) \end{vmatrix}$
이 행렬에서 모든 대각 성분은 같은 피처 간 내적이므로 분산에 해당한다. 대각 성분 이외에는 모두 다른 피처 간 내적이므로 공분산에 해당한다. 즉 이러한 피처 간 내적을 통해 수치적으로 i번 피처와 j번 피처가 공변하는 정도를 알 수 있게 된다. 이것이 수식이 나타내는 의미이다. 수식에서 n으로 나눈 것은 공분산이 커질 수 있으므로 데이터 개수로 나누어 평균을 구한 것이다. 이렇게 만들어진 행렬을 공분산 행렬이라 한다.
공분산 행렬이 가지는 의미는 무엇이고 어떻게 활용할까?
공분산 행렬은 피처 간에 서로 함께 변하는 정도를 의미한다고 했다. 공분산 행렬은 이러한 공변의 의미와 더불어 한 가지 의미가 더 있다. 그 의미는 바로 벡터에 선형 변환(사상)을 가능하게 하는 것이다. 즉, 공간상에 한 벡터가 있을 때 공분산 행렬을 곱해주게 되면 그 벡터의 선형 변환이 이루어진다. 이는 선형대수학에서 행렬이 벡터를 선형 변환시키는 역할을 하기 때문이다. 즉 공분산 행렬엔 피처간 공변 정보가 담겨 있으므로 이를 주축인 Eigen vector에 사상시키면 주성분을 구할 수 있다. 다음으로 주축을 구하기 위한 특이값 분해(SVD)를 살펴보자.
특이값 분해란 무엇이며 이를 통해 어떻게 Eigen vector를 구할 수 있을까?
먼저 특이값 분해란 일종의 행렬에서 이뤄지는 인수 분해다. 정확히는 행렬을 대각화하는 방법 중 하나이다. 대각화하는 이유는 대각화된 행렬의 대각선에 있는 값이 특이값(Singular Value)에 해당하기 때문이다. PCA에서 특이값 분해 대상은 위에서 본 공분산 행렬이다. 공분산 행렬을 특이값 분해 함으로써 PCA에 필요한 주축인 Eigen vector와, Eigen vector 스케일링에 필요한 Eigen value를 얻을 수 있다. Eigen value를 얻은 뒤 내림차순으로 정렬했을 때 가장 첫 번째 값이 분산을 최대로 하는 값이다.
일반적으로 특이값 분해는 고유값 분해(EVD)와 함께 설명된다. 고유값 분해의 경우 m x m의 정방 행렬에서만 사용할 수 있지만, 특이값 분해의 경우 m x n 인 직사각 행렬에도 적용가능하다. 따라서 일반화가 가능하단 장점이 있다. 또 특이값이란 고유값에 루트를 씌운 값이다. 그렇다면 특이값 분해는 어떻게 진행될까? 먼저 실수 공간에서 임의의 m x n 행렬에 대한 특이값 분해는 다음과 같이 정의된다.
$ A = U\sum V^T$
수식 성분이 나타내는 바는 다음과 같다. 참고로 여기서 $\sum$이란 합을 의미하는 기호가 아니라 행렬을 의미한다.
$A = m \times n $ 직사각 행렬 (diagonal matrix)
$U = m \times m $ 직교 행렬 (orthogonal matrix)
$\sum = m \times n$ 직사각 대각행렬 (diagonal matrix)
$V = n \times x $ 직교 행렬 (orthogonal matrix)
특이값 분해를 이해하기 앞서 두 가지 선형대수적 특성을 알아야 한다. 첫 번째는 $U$, $V$가 직교 행렬이라면 선형대수적 특성에 의해 $UU^T = VV^T = E$, $U^{-1} = U^T, V^{-1} = V^T$가 만족한다는 것이다. 여기서 $E$는 항등행렬이다. 여기서 항등행렬이란 가령 $U$에 역행렬인 $U^{-1}$를 곱했을 때 나오는 행렬을 의미한다. 두 번째론 대칭 행렬은 고유값 분해가 가능하며 또 직교행렬로 분해할 수 있다는 것이다. 앞에 보았던 공분산인 행렬 $A$는 대각선으로 기준으로 값들이 대칭을 띠는 대칭 행렬이었다. 그러므로 고유값 분해 또는 직교행렬로 분해할 수 있다. 또 행렬 $A$가 대칭행렬이므로 $A^T$도 대칭 행렬이다.
결과적으로 PCA는 특이값 분해를 통해 $\sum$를 구하고자 한다. 이 $\sum$는 $AA^T, A^TA$를 고유값 분해해서 나오는 고유값들에 루트를 씌운 값들이 대각선에 위치하는 행렬이다. 그리고 $AA^T$와 $A^TA$의 고유값이 같다. 이를 증명하는 하는 과정은 다음과 같다.
앞서 특이값 분해의 정의는 $A = U\sum V^T$라고 했다. 이때 $A$는 대각행렬이므로 고유값 분해가 가능하다.
$AA^T = (U\sum V^T)(U\sum V^T)^T$
$= U\sum V^T V\sum^T U^T$ (이 때 $V^TV$ = $V^{-1}V$ 즉 직교행렬이므로 항등 행렬이 되어 사라짐)
$= U(\sum \sum^T)U^T$
즉 $AA^T$를 고유값 분해하면 = $U(\sum \sum^T)U^T$가 된다. 또,
$A^TA = (U\sum V^T)^T(U\sum V^T)$
$= V\sum^T U^TU\sum V^T$ (이 때 $U^TU$ = $U^{-1}U$ 즉 직교행렬이므로 항등 행렬이 되어 사라짐)
$= V(\sum ^T\sum)V^T$
즉 $A^TA$를 고유값 분해하면 = $ V(\sum ^T\sum)V^T$가 된다.
그리고 이를 정리하고 덧붙이면,
$U$는 $AA^T$를 고유값 분해 해서 얻은 직교행렬이다. 그리고 U의 열벡터를 A의 left singular vector라 부른다.
$V$는 $A^TA$를 고유값 분해 해서 얻은 직교행렬이다. 그리고 V의 열벡터를 A의 right singular vector라 부른다.
$\sum$은 $AA^T, A^TA$를 고유값 분해해서 나온 고유값($\lambda$, eigen value)들의 제곱근을 대각원소로 하는 직사각 대각행렬이다.
이 $\sum$의 대각원소들을 행렬 A의 특이값(singular value)라 부른다. 아래 수식과 같다.
$\begin{vmatrix} \sqrt\lambda_1 & 0 & 0 & \dots \\ 0 & \sqrt\lambda_2 & 0 & \dots \\ 0 & 0 & \sqrt\lambda_3 & \dots \\ 0 & 0 & 0 & \dots \end{vmatrix}$
* 참고로 $\sum$의 경우 직사각 대각행렬이므로 m > n이거나 m < n인 경우로 나뉜다. 이 두 경우 모두 항상 대각선에만 특이값이 있어야 한다는 점만 상기하면 혼동되지 않는다.
특이값들($\sum\sum^T or \sum^T\sum)$을 제곱하게 되면 $AA^T, A^TA$의 고유값과 같다.
결국 특이값 분해를 수행하게되면 $AA^T$와 $A^TA$의 고유벡터와, 고유값이 도출된다.
이후 고유벡터의 방향으로 피처들을 사상시키고, 고유값의 크기만큼 스케일링 해줌으로써 PCA 과정이 마무리 된다.
Reference
[1] Eigen Vector, Eigen Value: https://m.blog.naver.com/galaxyenergy/222123501087
[2] Covariance, SVD: https://www.youtube.com/watch?v=jNwf-JUGWgg
[3] SVD: https://blog.naver.com/galaxyenergy/222865992256
[4] SVD: https://rfriend.tistory.com/185
[5] SVD: https://darkpgmr.tistory.com/106
[6] Image: https://medium.com/vlgiitr/principal-components-analysis-82a7682323e6
'Artificial Intelligence > 선형대수학' 카테고리의 다른 글
| [선형대수학] 쿼터니언(Quaternion)과 짐벌락 현상 (0) | 2023.07.02 |
|---|---|
| [선형대수학] 벡터, 기저, 스팬 (Vector, Basis and Span) (0) | 2021.11.05 |

