def factorial(N):
if N > 1:
return (N * factorial(N-1))
else:
return 1
T = int(input())
for _ in range(T):
N, M = list(map(int, input().split()))
print (factorial(M) // (factorial(M-N) * factorial(N)))
2. 다이나믹 프로그래밍 적용 O
T = int(input())
dp = [[0] * 30 for _ in range(30)]
for i in range(30):
for j in range(30):
if i == 1:
dp[i][j] = j
else:
if i == j:
dp[i][j] = 1
elif i < j:
dp[i][j] = dp[i-1][j-1] + dp[i][j-1]
for _ in range(T):
N, M = list(map(int, input().split()))
print (dp[N][M])
문제의 핵심은 홀수인 자연수 N이 주어지면, 1부터 $N^2$까지의 자연수를 아래와 같이 달팽이 모양으로 $N * N$의 표에 채우라는 것이다.
입력
첫째 줄에 홀수인 자연수 N(3 ≤ N ≤ 999)이 주어진다. 둘째 줄에는 위치를 찾고자 하는 N2 이하의 자연수가 하나 주어진다.
출력
N개의 줄에 걸쳐 표를 출력한다. 각 줄에 N개의 자연수를 한 칸씩 띄어서 출력하면 되며, 자릿수를 맞출 필요가 없다. N+1번째 줄에는 입력받은 자연수의 좌표를 나타내는 두 정수를 한 칸 띄어서 출력한다.
접근 방법
알고리즘을 처음 접하는 입장으로써 주위 개발자에게 조언을 구했다. 처음엔 코드를 작성하면서 변수를 생각했다. 하지만 이것은 비효율적인 방법이라고 한다. 머리로 사용할 변수들을 최대한 미리 생각하고 이후에 필요에 따라 추가/제거 하는 것이 중요하다.
1. 먼저 문제에서 바로 확인할 수 있는 변수 두 개인 홀수 자연수를 N으로 두고, 찾아야 할 값을 want로 선언하였다.
2. 찾아야 할 값 want의 2차원 좌표를 나타낼 변수를 x, y로 선언하였다.
3. 2차원 배열을 다루기 위해 사용되는 행렬을 row, col로 선언하였다.
4. 그리고 핵심이 되는 것은 dir(direction)이라는 방향을 나타내는 변수이다.
dir은 위와 같은 흐름으로 2차원 배열 변수에 값을 담기 위한 변수이다. dir을 1 또는 -1로 설정하여 row와 col에 더해줄 것이다. dir을 1로 설정하여 row에 더해줄 경우 자연스럽게 row가 증가하고, col에 더해줄 경우 col이 증가한다. 이후 dir을 -1로 설정하면 row가 감소하고, col이 감소한다. 이후 다시 dir을 1로 설정하면 row가 증가하여 최종적으로 1에 도달하는 식이다. (위 그림에 맞대어 row와 col에 dir을 더해주는 것을 시뮬레이션 해볼 것을 권한다. 이것이 문제 풀이의 핵심이다)
작성 코드
#include <iostream>
#include <cstring>
using namespace std;
int main(void)
{
// 1. 변수 선언부
int N = 0; // 입력 받을 홀수 자연수
int want = 0; // N^2 이하의 찾고자 하는 자연수
int x = 0, y = 0 ; // Want의 좌표를 나타낼 x, y 값
int row = -1, col = 0;; // 달팽이를 나타낼 행, 열
int dir = 1; // 방향을 나타낼 변수
cin >> N;
int copy = N;
cin >> want;
int squared = N * N; // N^2을 표현할 변수
int** arr;
arr = new int* [N]; // 2차원 배열의에서 사용할 배열의 길이(row)
for (int i = 0; i < N; i++)
{
arr[i] = new int[N]; // N = 2차원 배열에서 사용할 배열의 길이(column)
memset(arr[i], 0, sizeof(int)*N); // 0으로 배열 초기화 for security.
}
// 2. 핵심 알고리즘 동작부
while (squared > 0)
{
for (int i = 0; i < copy; i++)
{
row = row + dir;
arr[row][col] = squared;
if (squared == want)
{
x = row + 1;
y = col + 1;
}
squared = squared - 1;
}
copy = copy - 1;
for (int i = 0; i < copy; i++)
{
col = col + dir;
arr[row][col] = squared;
if (squared == want)
{
x = row + 1;
y = col + 1;
}
squared = squared - 1;
}
dir = dir * (-1);
}
// 3. 결과 출력부
for (int i = 0; i < N * N; i++)
{
int r = i / N;
int c = i % N;
cout << arr[r][c] << " ";
if ((i % N) == N - 1) cout << endl;
}
cout << x << " " << y << endl;
// 4. 2차원 배열 할당 해제부
for (int i = 0; i < N; i++)
delete[] arr[i];
delete[] arr;
return 0;
}
코드는 크게 4개의 부로 구성된다.
1. 변수 선언부
알고리즘 작성 이전에 필요로 하는 변수를 선언한 부분이다.
2. 핵심 알고리즘 동작부
배열에 값을 넣기 위한 핵심적인 알고리즘이 동작하는 부분이다.
3. 결과 출력부
$N^2$부터 1까지 달팽이 모양으로 출력하는 부분이다.
4. 2차원 배열 할당 해제부
달팽이 모양으로 값을 담기 위해 생성했던 2차원 동적 배열을 할당 해제하는 부분이다.
참고로 memset 함수는 0, -1로만 초기화 가능하다. 그 이유는 바이트 단위로 초기화가 이루어지기 때문이다.
정답 비율 & 제출 결과
초반에 알고리즘 풀지 못했을 때 정답 비율이 50%나 된다는 것에 가벼운 충격을 받았다. 최소한 둘에 하나는 풀 수 있다는 생각에 말이다. 아무튼 동시에 초심자로서 알고리즘적 사고를 잘 하는 사람들이 많다는 것에 내게 자극을 심어준 문제였다.
알고리즘 그룹을 만드려고 하니 50문제를 풀어야만 만들 수 있다고 한다. 하필 49문제였다. 급하게 쉬운 문제 찾아본다고 풀어본 것이다.
문제
상수는 수를 다른 사람과 다르게 거꾸로 읽는다. 예를 들어, 734와 893을 칠판에 적었다면, 상수는 이 수를 437과 398로 읽는다. 따라서, 상수는 두 수중 큰 수인 437을 큰 수라고 말할 것이다. 두 수가 주어졌을 때, 상수의 대답을 출력하는 프로그램을 작성하시오.
예시 입력
734 893
예시 출력
437
알고리즘
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main(void)
{
string a, b;
cin >> a >> b;
if (a.size() == 3 and b.size() == 3)
{
reverse(a.begin(), a.end());
reverse(b.begin(), b.end());
if (a > b)
cout << a;
else
cout << b;
}
return 0;
}
숫자를 int 형으로 받지 않고 string으로 받았다. 문자의 길이를 확인할 수 있는 size() 함수를 사용하기 위해서.
이후 문자열을 뒤집는 reverse 함수를 사용하여 문자열을 플립하였다. reverse 함수는 #include <alogrithm>를 선언하여 사용할 수 있다.
특이사항은 숫자 비교를 위해서 int 형으로 바꾸어야 할 것이라 생각했는데 그러지 않아도 동작함.
100개의 계단이 있으며 나는 한 번에 10개의 계단을 오를 수 있는 능력을 가지고 있다.
이 때, 100개의 계단을 올라갈 수 있는 경우의 수는 몇 개인가?
2. 해결 코드
문제를 보고 생각할 수 있는 가장 초기의 코드를 작성한 것이다.
stairs = 100
skill = 10
table = [0 for i in range(stairs+1)]
table[0] = 1
for i in range(1, stairs+1):
s=0
for j in range(1,skill+1):
if i-j<0:
t=0
else:
t= table[i-j]
s = s+t
table[i] = s
print (table[stairs])
2. 초기 코드를 확인 후 줄일 수 있는 부분을 확인 후, 파이썬의 강점을 살려 개선 코드를 작성한 것이다
stairs = 100
skill = 10
table = [0 for i in range(stairs+1)]
table[0] = 1
for i in range(1, stairs+1):
s=0
for j in range(1,skill+1):
t=(table[i-j],0)[i-j<0]
s = s+t
table[i] = s
print (table[stairs])
3. 개선 코드를 작성 후 하나의 함수로 만듦으로써 n 계단 오르기를 구현한 것이다.
def climbing(staris, skill):
table = [0 for i in range(stairs + 1)]
table[0] = 1
for i in range(1, stairs+1):
s=0
for j in range(1,skill+1):
t=(table[i-j],0)[i-j<0]
s = s+t
table[i] = s
return table[stairs]
r = (climbing(100,10))
print (r)
4. 함수의 최적화와 코드의 최적화를 구현한 것이며 아래의 코드는 계단 오르기 문제에 있어 가장 최적화 된 코드이다.
def climbing(n,m):
table=[0 for i in range(n+1)]
table[0]=1
for i in range(1,n+1):
s=(i-m,0)[(i-m)<0]
table[i]=sum(table[s:i])
return table[n]
a=climbing(100,10)
print (a)
2.1 비방향 그래프를 보고 크루스칼 알고리즘을 이용하여 최소 비용 신장 트리를 구하는 과정을 단계별로 보이시오
크루스칼 알고리즘의 핵심
오름차순
가중치를 기준으로 간선을 오름차순 정렬
낮은 가중치의 간선부터 시작해서 하나씩 그래프에 추가
사이클을 형성하는 간선을 추가하지 않음
간선의 수가 정점의 수보다 하나 적을 때 MST가 완성
내림차순
가중치를 기준으로 간선을 내림차순으로 정렬
높은 가중치의 간선부터 시작해서 하나씩 그래프에서 제거
두 정점을 연결하는 다른 경로가 없을 경우 해당 간선은 제거하지 않음
간선의 수가 정점의 수보다 하나 적을 때 MST가 완성
2.2 그래프를 보고 다익스트라 알고리즘을 이용하여 v6를 출발점으로하는 최단 거리를 구하는 과정을 단계별로 보이시오
간선의 가중치를 오름차순으로 정렬한다.
가중치가 낮은 순서대로 간선을 하나씩 그래프에 추가한다.
그래프 내에서 사이클을 형성하는 간선은 추가하지 않는다.
간선의 개수가 정점의 개수보다 '1' 작으면 끝낸다.
3. NP, NP-complete
3.1 NP, NP-hard, NP-complete의 정의
$P$ : 어떤 문제가 주어졌을 때 다항식으로 표현되어 polynomical time 즉, 다항 시간내에 해결 가능한 알고리즘을 의미하며 알고리즘의 복잡도가 $O(n^k)$로 표현되는 문제를 '$P$'라 한다.(복잡도 $O(n^k)$ 이하를 가지는 경우 같은 복잡도 내에 모든 해를 구한다.)
$NP$ : 어떤 문제가 주어졌을 때 다항식으로 표현될 수 있는지의 여부가 결정되지 않은 문제들을 'NP(Non-deterministic polynomial)'라 한다.
$NP-Complete$ : NP이면서 동시에 NP-Hard 에 속한다면 그 문제는 'NP-Complete'라 한다. (전수조사가 답)
$NP-Hard$ : 적어도 모든 NP 문제만큼은 어려운 문제들의 집합이며,만약P-NP 문제가P=NP로 풀린다면 P=NP=NP-Complete이므로 P와 NP는 NP-Hard의 부분집합이 되고, P≠NP인 경우는 P와 NP-Hard는서로소가 된다.*다항시간 : $T(n) = O(n^k), k$ 는 상수 => $k$가 상수로 고정이 된다면 그 문제는 해결하기 쉬운 문제. 다항시간안에 풀 수 있는 문제이므로.
3.2 해밀턴회로 거리 구하기(그래프가 주어질 때 그래프의 모든 점을 정확하게 한번씩만 지나는 경로가 존재하는가?) (NP-hard)
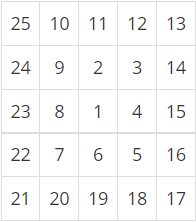
4. 배열 제시 후 소팅 알고리즘을 사용하여 정렬 과정을 보여라
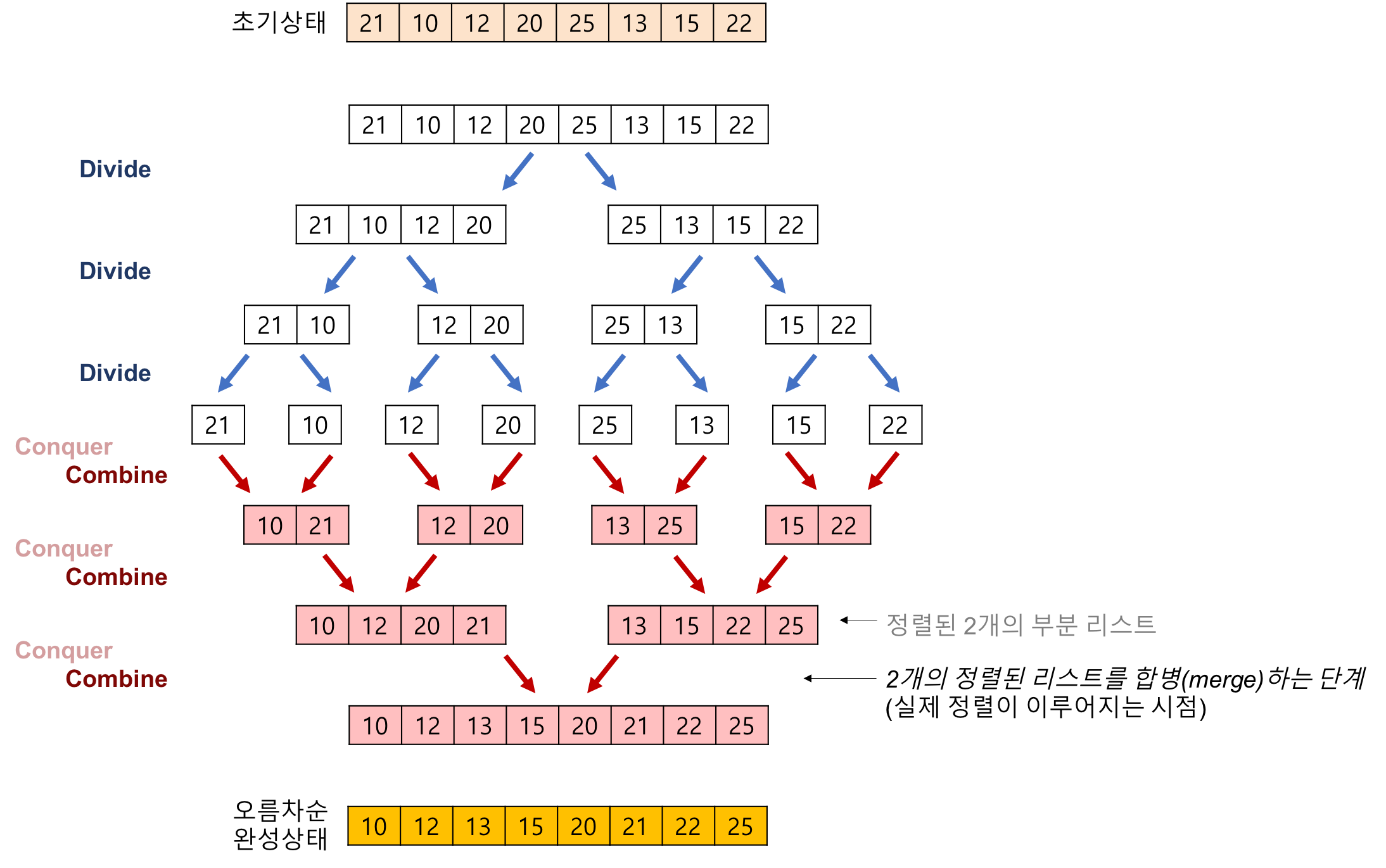
4.1 Merge sort 알고리즘을 사용하여 8개의 숫자를 정렬하는 과정을 보여라
병합 정렬의 예
4.2 각종 정렬 기법들의 장단점과 시간복잡도
5. Divide and Conquer 알고리즘과 Dynamic Programming 알고리즘 차이
5.1 분할 정복법이 비효율적인 경우를 설명하라
5.2 분할 정복법과 동적프로그래밍을 이용하여 이항계수를 구하는 알고리즘 작성 후 두방식의 차이점에 대해 적으시오
분할 정복법(Divide and Conquer)
어떠한 큰 문제를 해결하기 위해 큰 문제를 작은 단위의 문제로 나누어 해결하는 방법 (Top-down)
문제의 크기가 충분히 작아질때까지 반복적으로 분할
해결한 작은 문제를 가지고 바로 윗 단계의 문제를 해결해 나가는 방식
대표적인 예로는 Binary Search와 Merge Sort, Quick Sort 등이 있다.
동적 프로그래밍(Dynamic Programming)
문제를 작은 인스턴스들로 나누고 Bottom-up 순서로 풀어나가면서 문제의 값을 정해놓고 필요할 때 가져와 문제를 해결하는 방식이다. "기억하며 풀기"라 생각하면 된다.
대표적인 예로는 TSP 문제, 피보나치 수열, 파스칼의 트리 작성 등이 있다.
분할정복법과 동적 프로그래밍의 공통점과 차이점
공통점 : 문제를 작은 단위로 나누어 해결
차이점 : 분할정복법은 Top-down 방식이며, 동적 프로그래밍은 Bottom-up 방식이다.
5.3 Binomial coefficient를 계산하려할 때 다음을 구해라
Divide-and-Conquer 방법을 사용하는 pseudo code 작성
Dynamic Programming 방법을 사용하는 pseudo code 작성
위 두 접근 방법의 차이점을 서술
5.4 이항계수 수학적 귀납법으로 증명하고, 동적 프로그래밍으로 알고리즘을 구현하라.
bottom-up 방식
int binomial(int n, int k)
{
for (int i=0; i<=n; i++)
{
for (int j=0; j<=k && j<=i; j++)
{
if (k==0 || n==k)
arr[i][j] = 1;
else
arr[i][j] = arr[i-1][j-1] + arr[i-1][j];
}
}
return arr[n][k];
}
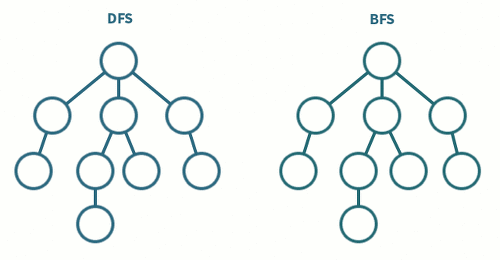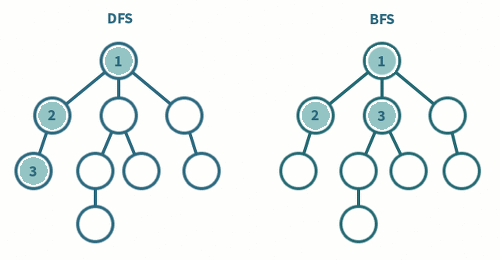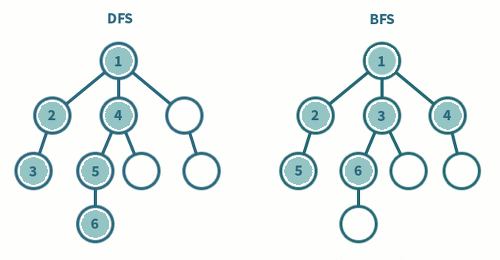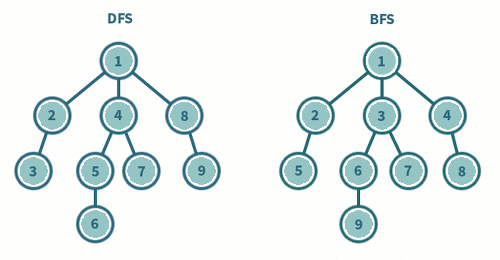
6. DFS(Depth First Search)와 BFS(Breadth First Search)의 차이
DFS, BFS의 의사코드를 작성하고 이들의 차이를 제시한 다음, 간단한 트리를 작성하여 순회하는 것을 보이시오.
8. 행렬을 주고 TSP에 관한 문제
9. Strassen 행렬 알고리즘을 사용하여 2*2 행렬 A,B의 곱 C를 구하라(m1,m2,...,m7)을 사용해야함
9.1 Strassen's Matrix Multiplication 알고리즘에 대해 설명하라
11. Floyd 알고리즘을 사용하여 W(=D0) 행렬과 D(=D) 행렬을 구하라. W, D를 구하는 과정을 서술하라
11.1 방향 그래프를 보고 플로이드 알고리즘을 이용하여 D와 P를 단계별로 적으시오.
12. 하노이의 탑 알고리즘을 써라
#include <stdio.h>
void HanoiTowerMove(int num, char from, char by, char to)
{
if (num == 1)
printf("원반 1을 %c에서 %c로 이동 \n", from, to);
else
{
HanoiTowerMove(num - 1, from, to, by);
printf("원반 %d를 %c에서 %c로 이동 \n", num, from, to);
HanoiTowerMove(num - 1, by, from, to);
}
}
int main(void)
{
// 막대 A의 원반 5개를 막대 B를 경유하여 막대 C로 옮기기
HanoiTowerMove(5, 'A', 'B', 'C');
return 0;
}
13. 탐욕적 방법 Greedy Algorithm이 항상 최적의 해를 내지 못하는 경우의 예를 들라
Greedy Algorithm이 사용되는 대표적인 예제로는 "최소 수의 동전으로 거스름돈 거슬러주기" 문제가 있다.
만약 우리가 마트의 캐셔로 일을 하고 있고, 850원을 거슬러 주어야 할 때 500원 동전 1개와 100원 동전 3개와 50원 동전 1개 총 4개의 동전을 건넴으로써 최소한의 동전을 거슬러 줄 수 있다. 하지만 이렇게 하지 않고 10원짜리 동전 85개를 건네주거나 50원짜리 17개를 건네주는 방법과 같이 다양한 경우의 수가 존재하며 이와 같을 경우 반드시 최적의 해를 내는 것은 아니다.
또한 우리나라의 경우 총 4개의 동전 500원, 100원, 50원, 10원이 있다. 하지만 만약 400원 동전이 발행된다면 400원 동전 2개, 50원 동전 1개를 통해 총 3개의 동전을 거슬러 줄 수 있을 것이다. 가장 최적의 방법이지만, 기존 알고리즘에 따르면 500원 1개, 100원 3개, 50원 1개로 거슬러주게 될 것이다. 이와 같이 탐욕 알고리즘은 항상 최적의 결과를 보장하지 못한다.
어떠한 큰 문제를 해결하기 위해 큰 문제를 작은 단위의 문제로 나누어 해결하는 방법 (Top-down)
문제의 크기가 충분히 작아질때까지 반복적으로 분할
해결한 작은 문제를 가지고 바로 윗 단계의 문제를 해결해 나가는 방식
대표적인 예로는 Binary Search와 Merge Sort, Quick Sort 등이 있다.
동적 프로그래밍(Dynamic Programming)
문제를 작은 인스턴스들로 나누고 Bottom-up 순서로 풀어나가면서 문제의 값을 정해놓고 필요할 때 가져와 문제를 해결하는 방식이다. "기억하며 풀기"라 생각하면 된다.
대표적인 예로는 TSP 문제, 피보나치 수열, 파스칼의 트리 작성 등이 있다.
분할정복법과 동적 프로그래밍의 공통점과 차이점
공통점 : 문제를 작은 단위로 나누어 해결
차이점 : 분할정복법은 Top-down 방식이며, 동적 프로그래밍은 Bottom-up 방식이다.
분할정복법의 장점, 단점, 특징
장점 : 문제를 나누어 해결한다는 특징상 병렬적으로 문제를 해결하는 데 큰 강점이 있다.
단점 :함수를 재귀적으로 호출함으로 인해 오버헤드가 발생한다. 또한 스택에 다양한 데이터를 보관하고 있어야 하므로 스택오버플로우가 발생한다.
특징 : 분할정복법은 보통 재귀함수를 이용하여 구현하는 것이 일반적이나, 재귀호출을 사용하지 않고 스택, 큐 등의 자료구조를 이용하여 구현하기도 한다.
이항 계수
이항계수는 분할 정복과 동적 프로그래밍에서 차이점을 서술하기 위해 자주 사용된다.
또한 이항계수란 $n$개의 원소에서 $r$개의 원소를 선택하는 방법의 수를 나타내며 재귀 프로그래밍의 기초가 된다. 이항계수는 수학에서 $_nC_r$로 나타낼 수 있으며, 이항계수 프로그래밍의 해결 방법은 $_nC_r =\ _{n-1}C_{r-1}\ +\ _{n-1}C_r$의 공식으로 이루어진다.
위 공식을 재귀적으로 구현할 경우 다음과 같다.
int binomial(int n, int k) {
if (n == k || k == 0)
return 1;
else
return binomial(n - 1, k) + binomial(n - 1, k - 1);
}
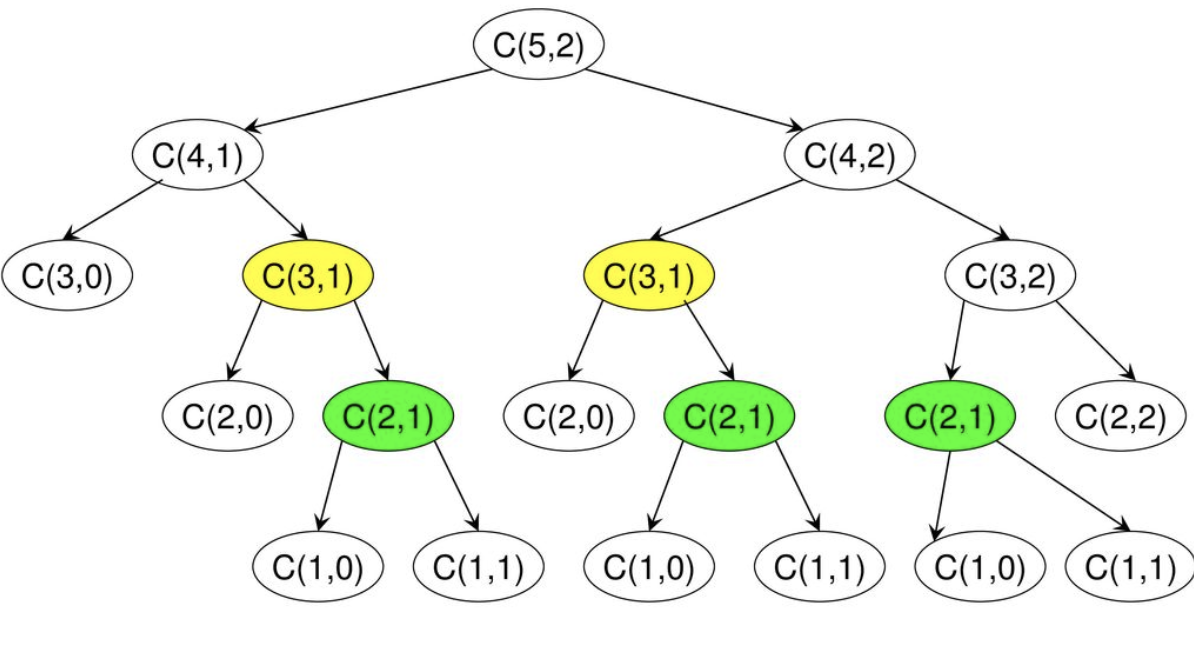
만약 binomical(5,2)를 계산하면 아래와 같이 동일한 문제들을 중복으로 풀게되어, 부분문제의 중복 문제가 발생한다. 즉, 알고리즘의 효율이 떨어지게 된다.
위와 같이 중복 계산으로 인해 효율이 떨어지는 것을 보완하기 위해서는, 하위 문제를 이용하여 최종 결과의 해를 도출하는 동적 프로그래밍 방법으로 접근하여 해결할 수 있다. 이전 계산 결과 값을 메모이제이션을 이용하여 풀면 다음과 같이 작성할 수 있다.
int binomial(int n, int k) {
if (n == k || k == 0)
return 1;
else if (arr[n][k] > -1) /* 배열 arr이 -1로 초기화되어 있다고 가정 */
return arr[n][k];
else {
arr[n][k] = binomial(n-1, k) + binomial(n-1, k-1);
return arr[n][k];
}
}
*메모이제이션(Memoization) : 이차원 배열에 인덱스에 해당하는 중복 조합을 저장 후, 만약 해당 인덱스에 값이 존재할경우(캐싱되었을 경우) 앞서 계산했다고 판단하여 해당 값을 반환함으로써 중복 계산을 줄여주는 기술. 즉, 동일 계산의 반복 수행을 제거한다.
Bottom-up 방식으로 해결할 경우 다음과 같이 작성할 수 있다.
int binomial(int n, int k) {
for (int i=0; i<=n; i++) {
for (int j=0; j<=k && j<=i; j++) {
if (k==0 || n==k)
arr[i][j] = 1;
else
arr[i][j] = arr[i-1][j-1] + arr[i-1][j];
}
}
return arr[n][k];
}
장점 : 인접한 값만 계속해서 비교하는 방식으로 구현이 쉬우며, 코드가 직관적이다. n개 원소에 대해 n개의 메모리를 사용하기에 데이터를 하나씩 정밀 비교가 가능하다.
단점 : 최선이든 최악이든 $O(N^2)$이라는 시간복잡도를 가진다. n개 원소에 대해 n개의 메모리를 사용하기에 원소의 개수가 많아지면 비교 횟수가 많아져 성능이 저하된다.
힙 정렬
장점 : 추가적인 메모리를 필요로하지 않으면서 항상 $O(N\times logN)$의 시간 복잡도를 가진다. $O(N\times logN)$인 정렬 방법 중 가장 효율적인 정렬방법이라 할 수 있다. 퀵 정렬의 경우 효율적이나 최악의 경우 시간이 오래걸린다는 단점이 있으나 힙 정렬의 경우 항상 $O(N\times logN)$이 보장된다.
단점 : 이상적인 경우에 퀵정렬과 비교했을 때 똑같이 $O(N\times logN)$이 나오긴 하나 실제 시간을 측정하면 퀵정렬보다 느리다고 한다. 즉, 데이터의 상태에 따라서 다른 정렬들에 비해서 조금 느린편이다. 또한, 안정성을 보장받지 못한다.
선택 정렬
장점 : 정렬을 위한 비교 횟수는 많으나 교환 횟수가 적기에, 교환이 많이 이루어져야 하는 상태에서 효율적으로 사용될 수 있으며, 이에 가장 적합한 자료상태는 역순 정렬이다. 즉, 내림차순이 정렬되어 있는 자료를 오름차순으로 재졍렬할 때 적합하다.
단점 : 정렬을 위한 비교 횟수가 많으며, 이미 정렬된 상태에서 소수의 자료가 추가되면 재정렬할 때 최악의 처리 속도를 보인다.
빠른 정렬
장점 : 기준값(Pivot)에 의한 분할을 통해 구현하는 정렬 방법으로, 분할 과정에서 $logN$이라는 시간이 소요되며, 전체적으로 $N\times logN$으로 준수한 편이다.
단점 : 기존값에 따라 시간복잡도가 크게 달라진다(안정성이 없다). 기준값을 이상적인 값으로 선택했다면 $N\times logN$의 시간복잡도를 가지지만, 최악의 기준값을 선택할 경우 $O(N^2)$라는 시간복잡도를 갖게 된다.
삽입 정렬
장점 : 최선의 경우 $O(N)$이라는 빠른 효율성을 가지고 있다. 버블정렬의 비교횟수를 줄이기 위해 고안된 정렬이다. 버블정렬의 경우 비교대상의 메모리 값이 정렬되어 있더라도 비교연산을 진행하나, 삽입정렬은 버블정렬의 비교횟수를 줄이고 크기가 적은 데이터 집합을 정렬하는 알고리즘을 작성할 때 효율이 좋다.
단점 : 최악의 경우 $O(N^2)$이라는 시간복잡도를 가지게 된다. 즉, 데이터의 상태와 크기에 따라 성능의 편차가 큰 정렬 방법이다.
병합 정렬
장점 : 퀵 정렬과 비슷하게 원본 배열을 절반씩 분할해가면서 정렬하는 정렬법으로써 분할하는 과정에서 $logN$ 만큼의 시간이 소요된다. 즉, 최종적으로 보게되면 $N\times logN$이 된다. 또한 퀵 정렬과 달리 기준값을 설정하는 과정없이 무조건 절반으로 분할하기에 기준값에 따라 성능이 달라지는 경우가 없다. 따라서 항상 $O(N\times logN)$이라는 시간복잡도를 가지게 된다.
단점 : 병합정렬은 임시배열에 원본맵을 계속해서 옮겨주며 정렬을 하는 방식이기에 추가적인 메모리가 필요하다는 점이다. 데이터가 최악인 면을 고려하면 퀵 정렬보다는 병합정렬이 훨씬 빠르기 때문에 병합정렬을 사용하는 것이 많지만, 추가적인 메모리를 할당할 수 없다면 병합정렬을 사용할 수 없기 때문에 퀵을 사용해야 하는 것이다.
쉘 정렬
장점 : 삽입정렬의 단점을 보완하고 개념을 확대해서 만든 정렬방법으로, 삽입 정렬에 비해 성능이 우수하며, 어떤 데이터가 제 위치에서 멀리 떨어져있을 경우 여러 번의 교환이 발생하는 버블정렬의 단점을 해결한다.
단점 : 일정한 간격에 따라 배열을 보아야 하며, 간격을 잘못 설정할 경우 성능이 급격히 저하될 수 있다.
기수 정렬
장점 : $O(N)$이라는 시간복잡도를 가지는 정렬방법으로 매우 빠른 속도를 가지고 있다.
단점 : 버킷이라는 데이터 전체 크기와 기수 테이블의 크기만큼의 추가적인 메모리가 할당되어야 한다.
카운팅 정렬
장점 : 비교를 하지 않고 정렬하는 방법으로 $O(N)$이라는 시간복잡도를 가지게 된다.
단점 : 숫자 갯수를 저장해야 될 별도의 공간, 또 결과를 저장할 별도의 공간 등 추가적인 메모리가 필요하다.
정렬 알고리즘 장단점 요약
Sorting
장점
단점
버블 정렬
인접한 두 개의 데이터를 비교하기에 구현이 쉬우며 정밀 비교 가능
원소의 갯수가 많아지면 비교 연산이 많아져서 성능이 저하
선택 정렬
정렬을 위한 교환 횟수가 적어 내림차순된 데이터를 오름차순할 때 효율이 좋음
정렬 비교 횟수가 많고,정렬된 상태서 소수의 자료가 추가되면 재정렬 시 최악의 처리 속도를 보임
삽입 정렬
버블정렬의 비교횟수를 줄이기 위해 고안된 방법이며, 크기가 적은 데이터 집합을 정렬하는 알고리즘을 작성할 때 효율이 좋음
데이터의 상태와 크기에 따라 성능 편차가 큰 정렬 방법
힙 정렬
추가적인 메모리를 필요로하지 않으면서 항상시간 복잡도$O(N\times logN)$ 를 가짐
실제 시간을 측정 시 퀵정렬보다 느림. 즉, 데이터의 상태에 따라서 다른 정렬들에 비해 느린편. 안정성을 보장받지 못함
병합 정렬
퀵 정렬과 달리 기준값을 설정하는 과정없이 무조건 절반으로 분할하기에 기준값에 따라 성능이 달라지는 경우가 없음
병합정렬은 임시배열에 원본맵을 계속해서 옮겨주며 정렬을 하는 방식이기에 추가적인 메모리가 필요
퀵 정렬
기준값(Pivot)에 의한 분할을 통해 구현하는 정렬 방법으로, 분할 과정에서 $logN$이라는 시간이 소요되며, 전체적으로 $N\times logN$으로 준수