신장 트리란 그래프 상에서 모든 노드가 사이클 없이 연결된 부분 그래프를 뜻한다. 이 부분 그래프는 여러개가 존재할 수 있다. 따라서 최소 신장 트리란 여러 개의 부분 그래프 중 모든 정점이 최소 간선의 합으로 연결된 부분 그래프이다.
(* 트리와 그래프 관계: 트리는 그래프 중에서 특수한 경우에 해당하는 자료구조로,사이클이 존재하지 않는 방향 그래프다)
최소 신장 트리의 활용
이런 최소 신장 트리는 실생활 곳곳에 활용된다. 예를 들어 도로 건설 문제에서 도시를 노드, 도로를 간선으로 두고 도시 간 이어지는 도로 길이를 최소화 할 때 사용된다. 또 네트워크에서 최적의 라우팅 경로를 선택할 때도 사용되며, 통신에서도 전화선 길이가 최소가 되는 케이블망 구축에 사용되는 등 여러 곳에서 활용된다.
최소 신장 트리 알고리즘
최소 신장 트리를 찾을 수 있는 알고리즘은 크게 2가지로 크루스칼(Kruscal), 프림(Prim) 알고리즘이 있다. 두 알고리즘 간 차이점은 크루스칼은 간선 중심이고 프림은 정점 중심 알고리즘이다. 간선이 적으면 크루스칼을, 간선이 많으면 프림을 사용하는 것이 좋다. 알고리즘 시간 복잡도는 크루스칼이 $O(E+\log (E))$, 프림이 $O(V+E) \log (V)$이다. 두 알고리즘의 공통점 중 하나는 음수 사이클이 있더라도 최소 신장 트리를 구할 수 있다. 본 포스팅에서는 크루스칼 알고리즘만 다룬다.
크루스칼 알고리즘 (Kruscal Algorithm)
크루스칼 알고리즘은 음의 가중치가 없는 무방향 그래프에서 최소 신장 트리를 찾는 알고리즘이다. 최소 신장 트리를 찾기 위해선 사이클 발생 여부를 판단할 수 있어야 한다. 사이클 발생 여부는 union find 알고리즘을 사용해서 판단한다. union find를 알면 크루스칼 알고리즘 이해에 도움되지만 모르더라도 아래 설명을 통해 어느정도 이해 가능할 것이다.
크루스칼 알고리즘은 크게 아래 3단계로 구성되며 2~3이 반복 수행된다.
1. 주어진 모든 간선을 오름차순 정렬 수행한다.
2. 정렬된 간선을 하나씩 확인하며 현재 간선이 노드 간 사이클을 발생시키는지 확인한다.
3. 사이클 발생시키지 않을 경우 최소신장트리에 포함, 사이클 발생할 경우 포함하지 않는다.
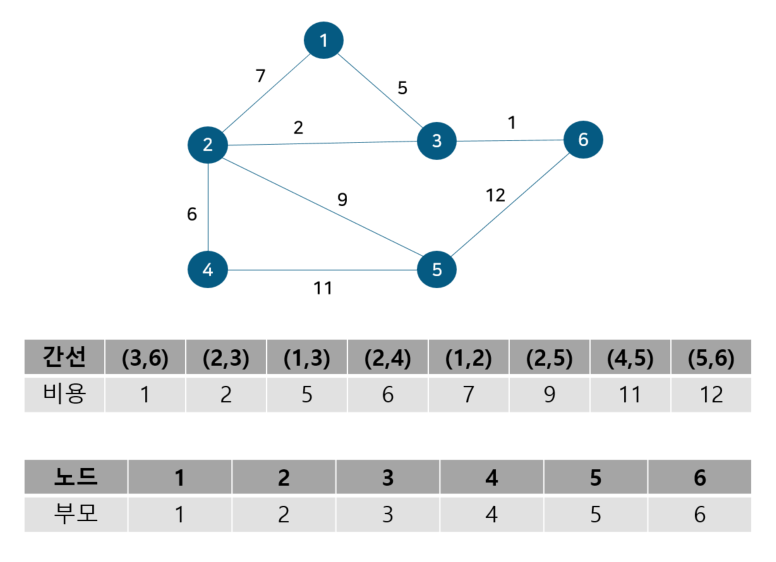
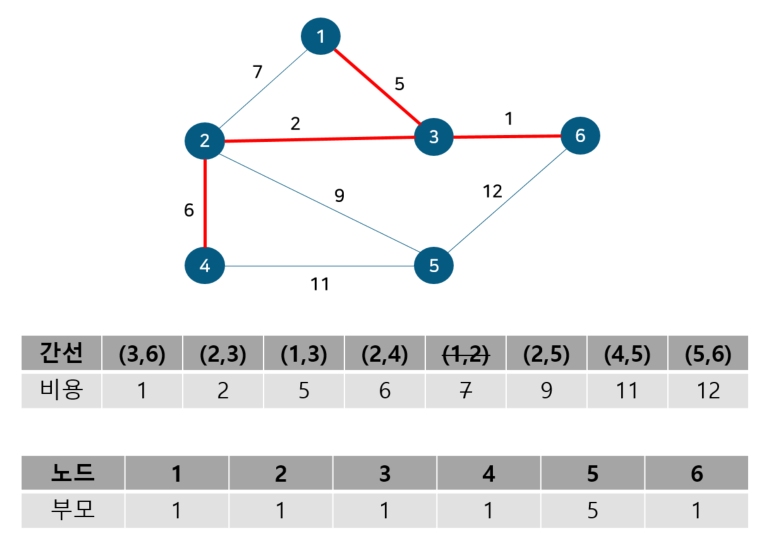
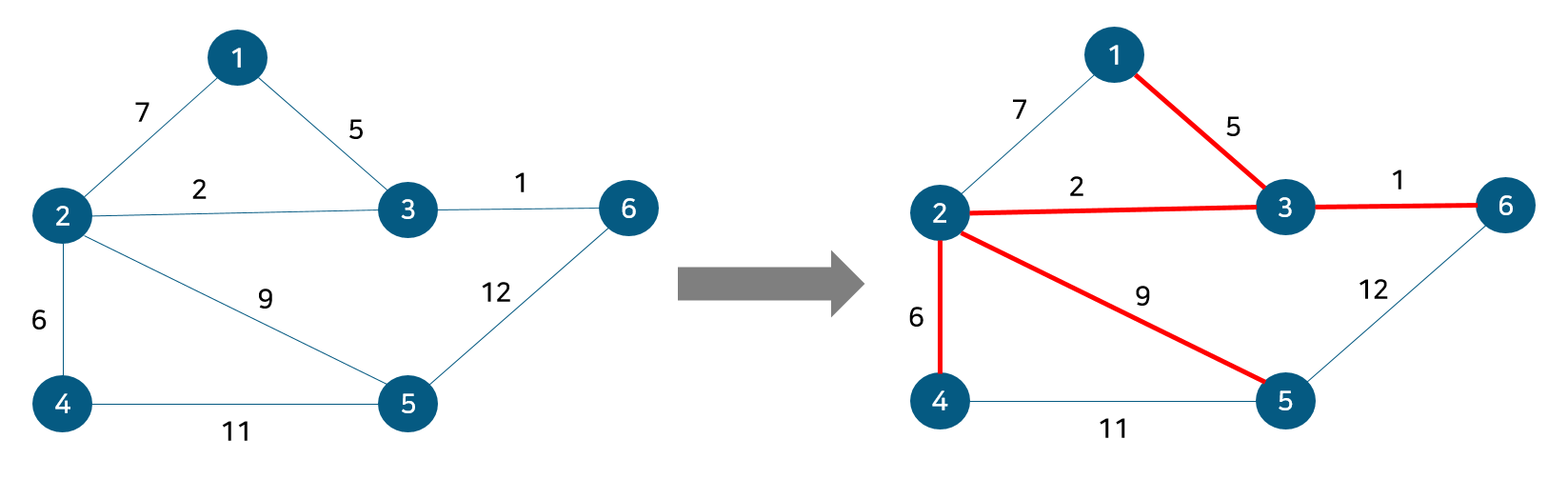
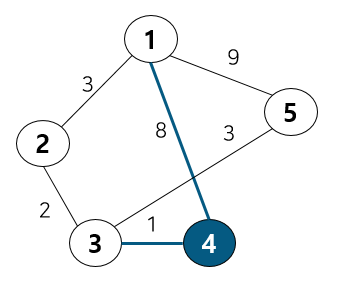
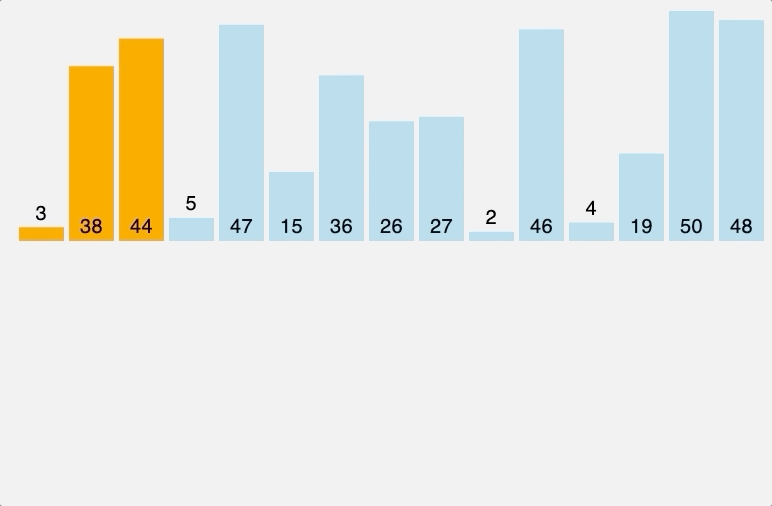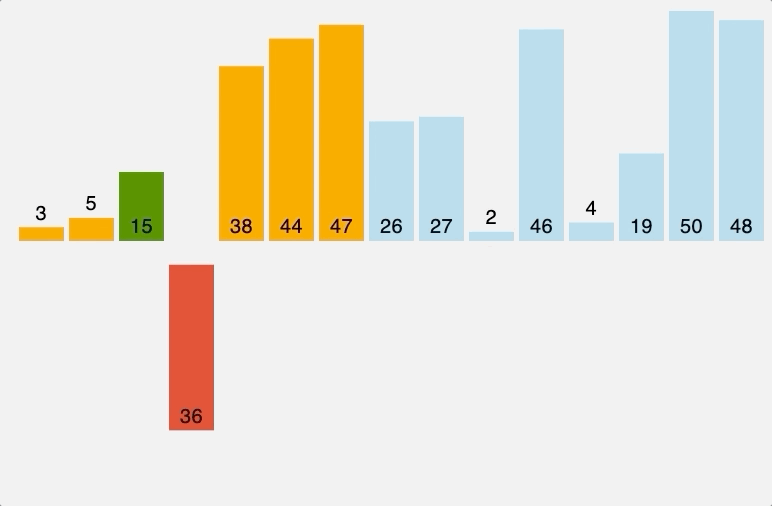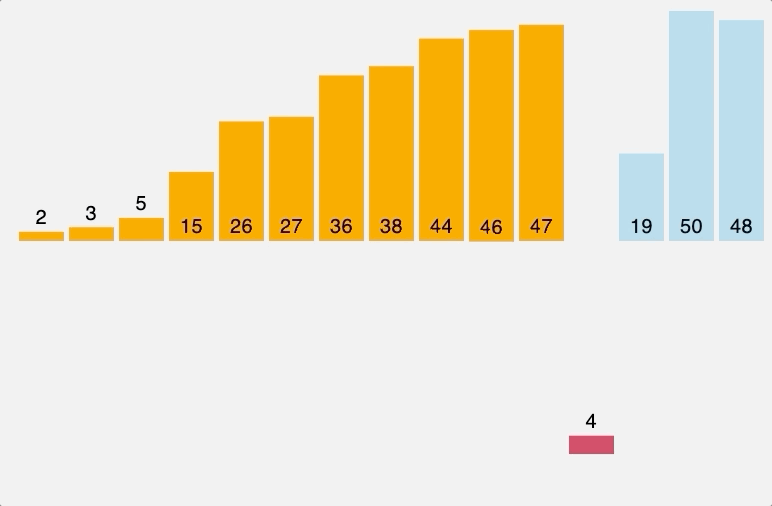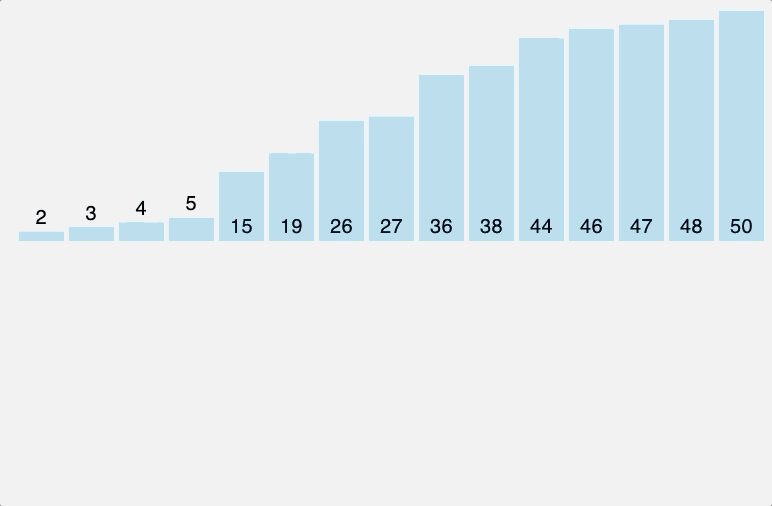
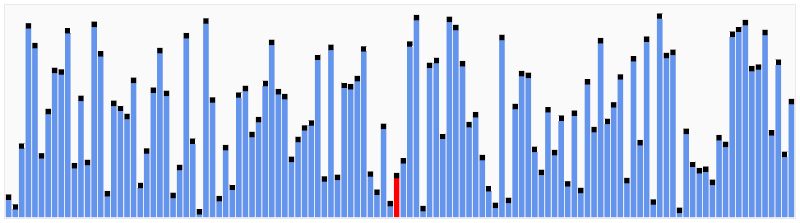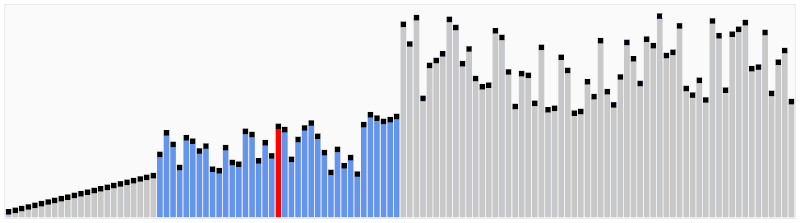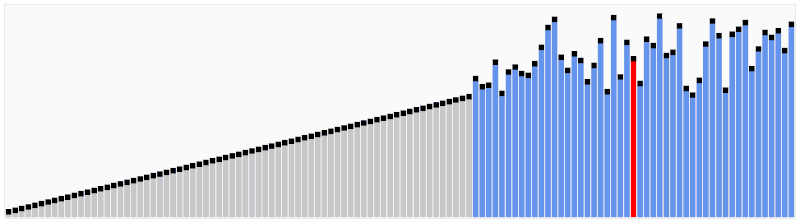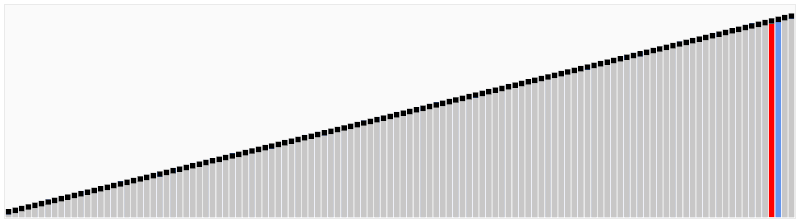
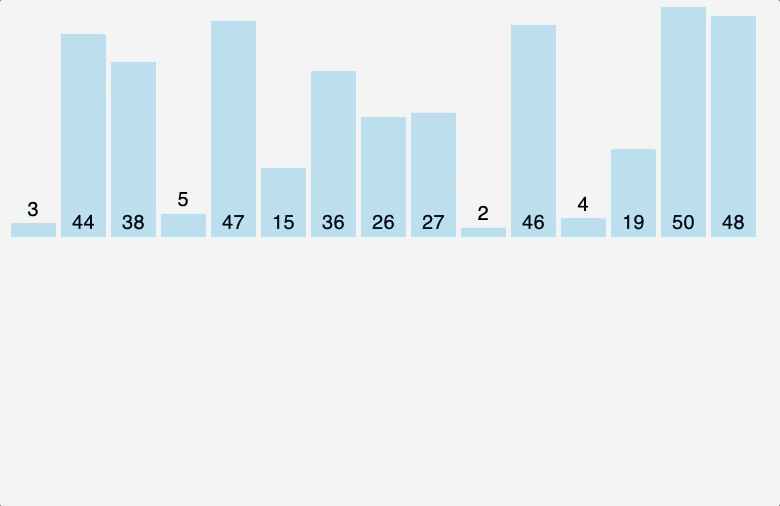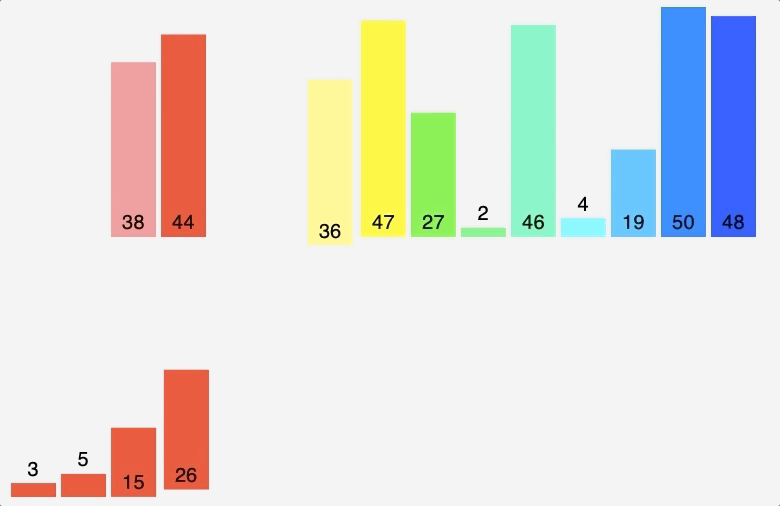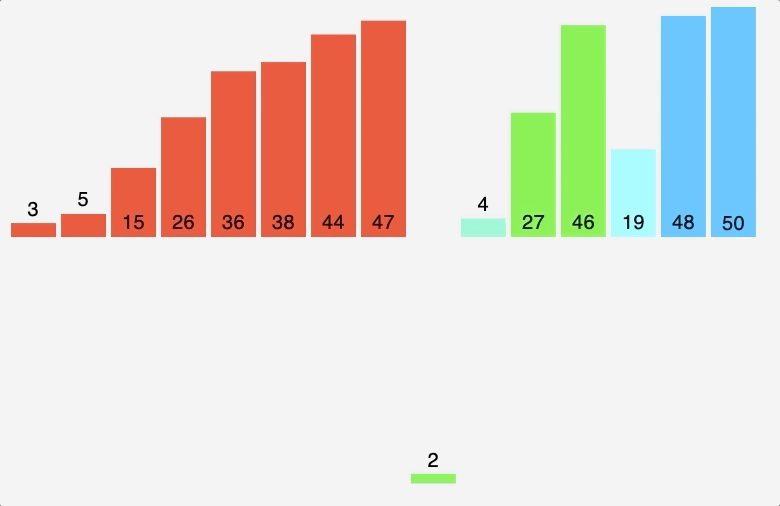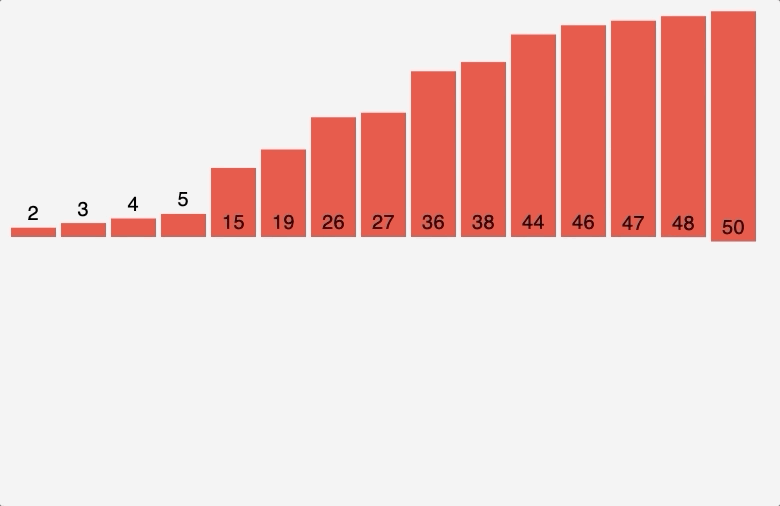
도식화 한 예시로 확인해보자. 예를 위해 아래와 같이 노드 6개와 간선 8개로 구성된 그래프가 있다 가정하자.
위 그림에서 간선의 비용 별로 오름차순 정렬해 주었다. 또 내부적으로 사이클 여부를 판별하기 위해 union-find 알고리즘을 사용하므로 부모 테이블을 만들어주고 초기값은 노드 자기자신으로 둔다. 이제 간선을 비용이 작은 순서대로 확인하기 위해 먼저 간선 (3,6)을 살펴보자.
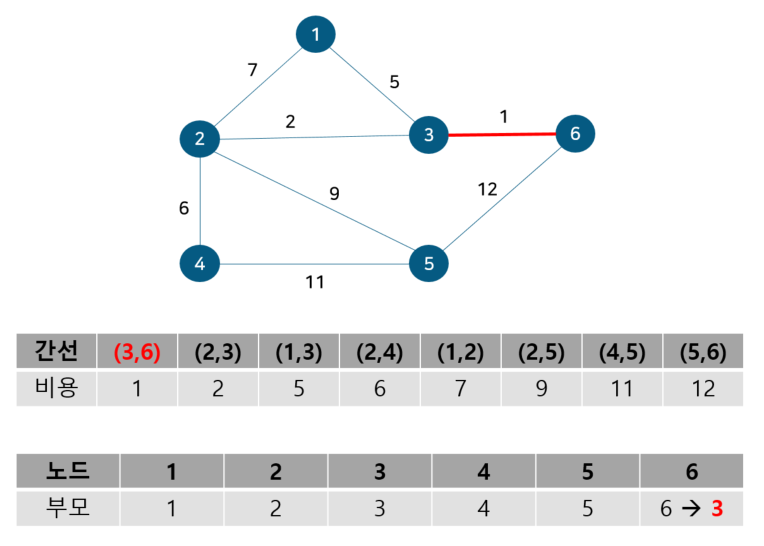
노드 3, 6의 부모 노드를 살펴보면 각각 3, 6으로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (3, 6)을 포함시키고 부모 테이블에서 노드 6의 부모를 노드 3으로 업데이트 해준다. 참고로 일반적으로 부모 노드는 작은 노드 번호 기준으로 업데이트한다. 다음으로 노드 2, 3을 살펴보자
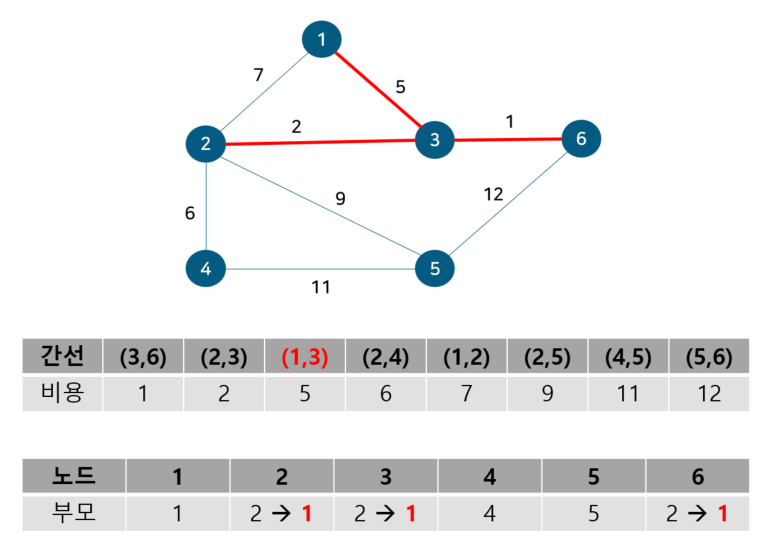
노드 2, 3의 부모 노드를 살펴보면 각각 2, 3으로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (2, 3)을 포함시키고 부모 테이블에서 노드 3의 부모를 노드 2로 업데이트 해준다. 이 때 노드 6도 부모 노드를 3으로 가지는 종속 관계에 있으므로 함께 바꿔준다. 다음으로 노드 1, 3을 살펴보자
노드 1, 3의 부모 노드를 살펴보면 각각 1, 2로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (1, 3)을 포함시키고 부모 테이블에서 노드 3의 부모를 노드 1로 업데이트 해준다. 이 때 노드 2, 6도 부모 노드를 2로 가지는 종속 관계에 있으므로 함께 바꿔준다. 다음으로 노드 2, 4를 살펴보자
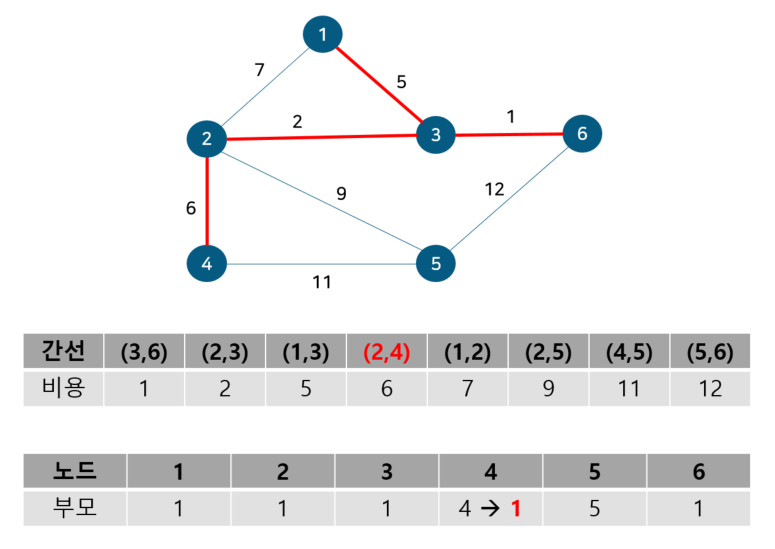
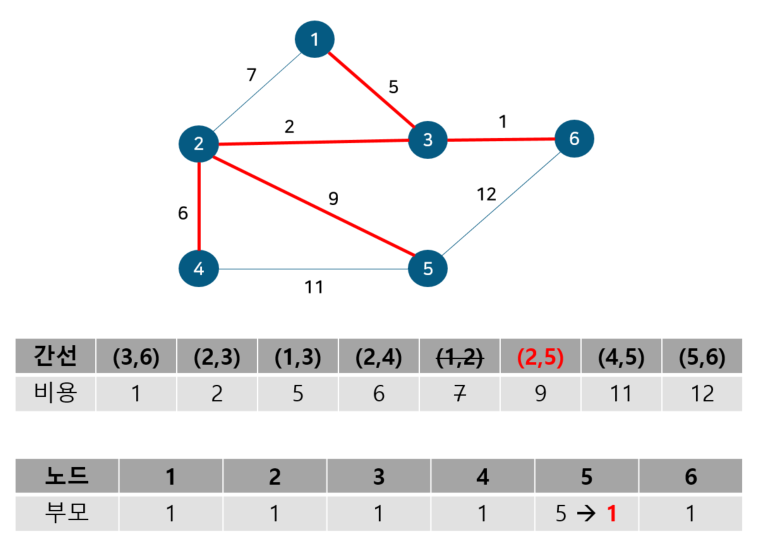
노드 2, 4의 부모 노드를 살펴보면 각각 1, 4로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (2, 4)를 포함시키고 부모 테이블에서 노드 4의 부모를 노드 1로 업데이트 해준다. 다음으로 노드 1, 2를 살펴보자
노드 1, 2의 부모 노드를 살펴보면 각각 1, 1로 같아 사이클이 발생했다. 그러므로 최소 신장 트리에 포함시키지 않고, 부모 테이블 업데이트도 이뤄지지 않는다. 다음으로 노드 2, 5를 살펴보자
노드 2, 5의 부모 노드를 살펴보면 각각 1, 5로 다르기에 사이클이 발생하지 않는다. 따라서 최소 신장 트리에 (2, 5)를 포함시키고 부모 테이블에서 노드 5의 부모를 노드 1로 업데이트 해준다. 다음으로 노드 4, 5를 살펴보자
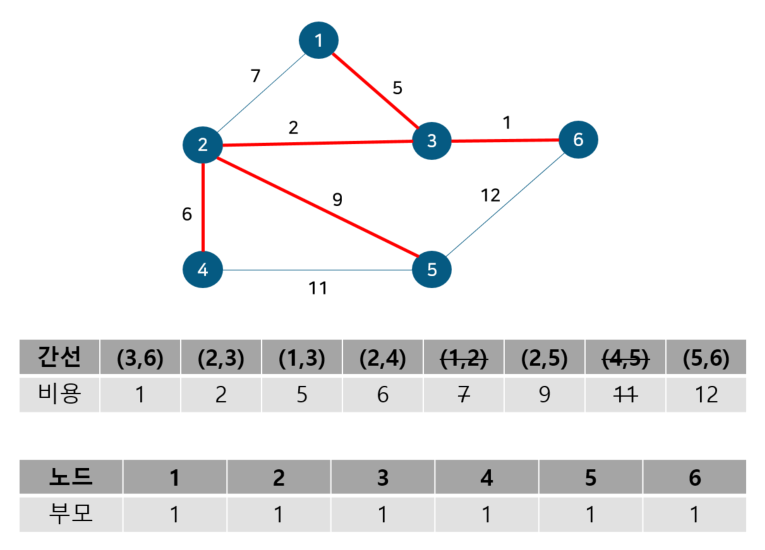
노드 4, 5의 부모 노드를 살펴보면 각각 1, 1로 같아 사이클이 발생했다. 그러므로 최소 신장 트리에 포함시키지 않고, 부모 테이블 업데이트도 이뤄지지 않는다. 다음으로 노드 5, 6를 살펴보자
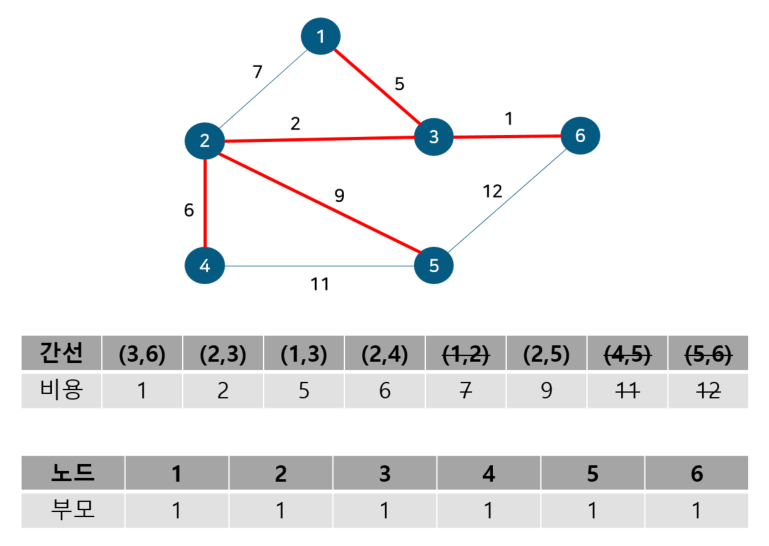
노드 5, 6의 부모 노드를 살펴보면 각각 1, 1로 같아 사이클이 발생했다. 그러므로 최소 신장 트리에 포함시키지 않고, 부모 테이블 업데이트도 이뤄지지 않는다. 이것으로 최소 신장 트리를 찾는 크루스칼 알고리즘 동작이 종료된다. 동작 전과 동작 후를 비교해보자면 다음과 같다.
기존의 그래프 전체에서 사이클 없이 모든 정점을 최소 비용 간선으로 잇는 부분 그래프인 최소 신장 트리다. 이를 코드로 구현하면 다음과 같다.
""" This is input value. you can just copy and past it.
then you can get "[(3, 6), (2, 3), (1, 3), (2, 4), (2, 5)]" and "23"
6 8
1 2 7
1 3 5
2 3 2
2 4 6
2 5 9
3 6 1
4 5 11
5 6 12
"""
import sys
input = sys.stdin.readline
def find_parent(parent, x):
""" 부모 노드를 찾기 위해 재귀 수행"""
if parent[x] != x:
parent[x] = find_parent(parent, parent[x])
return parent[x]
def union_parent(parent, a, b):
""" 부모 노드 비교 후 부모 노드 업데이트 """
a = find_parent(parent, a)
b = find_parent(parent, b)
if a < b:
parent[b] = a
else:
parent[a] = b
if __name__ == "__main__":
V, E = map(int, input().split()) # make graph
graph = []
for _ in range(E):
a, b, cost = map(int, input().split())
graph.append([a, b, cost])
graph.sort(key=lambda x:x[2])
parent = [0] * (V+1) # make parent table
for i in range(1, V+1):
parent[i] = i
costs, mst = 0, [] # get mst
for i in range(E):
a, b, cost = graph[i]
if find_parent(parent, a) != find_parent(parent, b): # check cycle
union_parent(parent, a, b)
mst.append((a, b))
costs += cost
print (mst)
print (costs)
최단 거리 알고리즘이란 그래프 상에서 노드 간의 탐색 비용을 최소화하는 알고리즘이다. 일반적으로 네비게이션과 같은 길찾기에 적용된다. 최단 거리 알고리즘 종류는 크게 3가지가 있다. 1. 다익스트라(Dijkstra) 2. 플로이드 워셜(Floyd Warshall) 3. 벨만 포드(Bellman Ford)이다.
1. 다익스트라 (Dijkstra) 알고리즘
다익스트라 알고리즘은 그래프 상에서 특정 한 노드에서 다른 모든 노드까지의 최단거리를 구하는 알고리즘이다. 다르게 표현하면 가중 그래프에서 간선 가중치의 합이 최소가 되는 경로를 찾는 알고리즘 중 하나이다.
다익스트라는 그리디와 동적 계획법이 합쳐진 형태이다. 현재 위치한 노드에서 최선의 경로를 반복적으로 찾으면서도 계산 해둔 경로를 활용해 중복된 하위 문제를 풀기 때문이다. 다익스트라는 만약 그래프에 음의 가중치가 있다면 사용할 수 없다. 그 이유는 그리디를 통해 최단 경로라고 여겨진 경로 비용을 DP 테이블에 저장한 뒤, 재방문하지 않는데, 만약 음의 가중치가 있다면 이러한 규칙이 어긋날 수 있기 때문이다. 음의 가중치가 포함된다면 플로이드 워셜이나 벨만 포드 알고리즘을 사용해 최단 경로를 구할 수 있다. 다만 시간 복잡도가 늘어나는 단점이 있기에 해결하고자 하는 문제에 맞게 사용해야 한다.
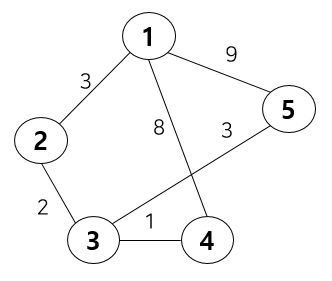
만약 아래와 같은 그래프가 있다 가정하고 동작 원리를 확인해보자.
위와 같은 초기 노드와 간선을 테이블에 나타내보자면 다음과 같다. 예를 들자면 1행 4열은 1번 노드에서 4번 노드로 가는 것을 나타내며 비용은 8이 든다.
0
3
INF
8
9
3
0
2
INF
INF
INF
2
0
1
3
8
INF
1
0
INF
9
INF
3
INF
0
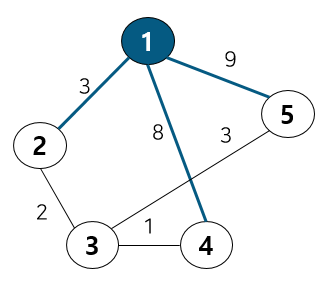
다익스트라 알고리즘은 특정 한 노드에서 다른 모든 노드까지의 최단 거리를 구하는 알고리즘이라 했다. 예를 들어 특정 한 노드를 1이라 가정하면 [0, 3, INF, 8, 9]는 다음과 같은 과정을 통해 업데이트 된다.
아래와 같이 노드 1을 선택하게 되면 1과 연결된 3개의 간선을 확인한다.
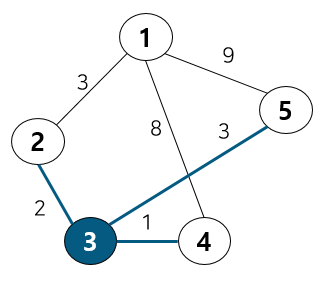
이 중에서 다른 정점으로 가는 최소 비용이 2번 노드가 가장 작기 때문에 2번 노드로 이동하고, 노드 1번은 방문 처리한다. 이 때 테이블 값 변화는 없다.
0
3
INF
8
9
2번 노드에 연결된 노드는 1번과 3번이다. 하지만 1번의 경우 이미 방문했고, 비용이 크므로 볼 필요 없다. 2와 최소비용으로 연결된 노드는 3이기 때문에 노드 3으로 이동하고, 2를 방문처리 한다. 이 때 테이블 값 변화가 발생한다. 1과 3은 연결되지 않았었다. 하지만 그리디와 같이 계속해서 최적의 상태를 업데이트 하므로 다른 노드를 탐색하다 3을 방문할 수 있기 때문에 1 → 2 → 3으로 이동하는 동안의 비용인 5로 업데이트 해준다.
0
3
5
8
9
다음으로 3번 노드에 연결된 간선은 총 3개이다. 하지만 2의 경우 방문처리 되었으니 노드 4, 5번 두 개만 고려하면 된다.
노드 4, 5번 중 더 비용이 적은 것은 4번 노드이므로, 4번 노드로 이동하고 3번 노드는 방문처리 해준다. 마찬가지로 테이블 값 변화가 발생한다. 기존에는 1 → 4로 가는 비용이 8이었지만 1 → 2 → 3 → 4를 거치는 것이 6이 들기에 테이블 값을 6으로 업데이트 시켜준다.
0
3
5
6
9
다음으로 4번 노드에 연결된 간선은 총 2개이다. 하지만 두 개 모두 방문처리 되었고 5로 가는 간선이 없다.
따라서 테이블 값 업데이트는 없다. 또 알고리즘은 여기서 끝이 난다. 최종적으로 1에서 다른 모든 노드까지의 비용은 아래 테이블이 된다.
0
3
5
6
9
이를 코드로 구현하기 위해서는 가중치에 중요도가 있으므로 자료구조 힙을 사용해 표현해준다. 전체 코드는 다음과 같다.
""" This is input value. you can just copy and paste it.
5 6 1
1 2 3
1 4 8
1 5 9
2 1 2
2 3 2
3 2 2
3 4 1
3 5 3
4 1 8
4 3 1
5 1 9
"""
import heapq
def dijkstra(start):
heap = []
heapq.heappush(heap, [0, start]) # 최소힙은 배열의 첫 번째 값을 기준으로 배열을 정렬.
INF = float('inf')
weights = [INF] * (vertex+1) # DP에 활용할 memoization 테이블 생성
weights[start] = 0 # 자기 자신으로 가는 사이클은 없으므로.
while heap:
weight, node = heapq.heappop(heap)
if weight > weights[node]: # 비용 최적화 전부터 큰 비용일 경우 고려할 필요 없음.
continue
for n, w in graph[node]: # 최소 비용을 가진 노드를 그리디하게 방문한 경우 연결된 간선 모두 확인
W = weight + w
if weights[n] > W: # 여러 경로를 방문해 합쳐진 가중치 W가 더 비용이 적다면
weights[n] = W # 업데이트
heapq.heappush(heap, (W, n)) # 최소 비용을 가진 노드와 합쳐진 가중치 추가
return weights
vertex, edge, start = map(int, input().split())
graph = [[] for _ in range(vertex+1)]
for i in range(vertex+edge):
src, dst, weight = map(int, input().split())
graph[src].append([dst, weight])
weights = dijkstra(start)
print (weights) # [inf, 0, 3, 5, 6, 8]
최종 출력되는 최소 비용 중 1에서 1로 가는 사이클은 없으므로 0이 된다. 또한 만약 주어진 문제가 1에서 3으로 가는 최소비용을 구하는 것이라면 5가 되고, 1에서 4로가는 최소 비용을 구하는 것이라면 6이 된다.
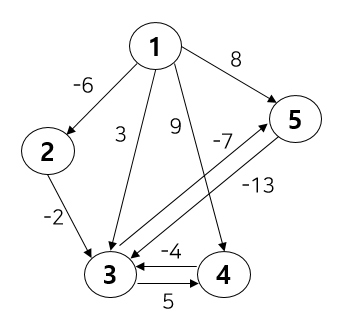
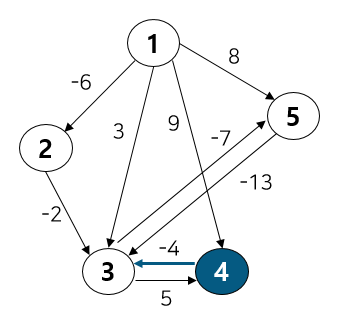
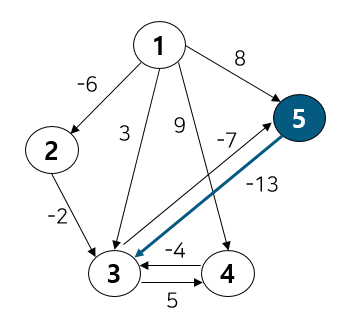
벨만 포드 알고리즘은 가중 유향 그래프 상에서 특정 한 노드로 부터 다른 노드까지의 최단 경로를 구하는 알고리즘이다. 다익스트라 알고리즘의 한계점을 보완하기 위해 나왔다. 그 한계점이란 간선이 음수일 때 최단 경로를 구할 수 없다는 것이다. 사실 정확히는 음의 가중치 자체가 문제가 되진 않는다. 문제는 사이클 형성 여부에 따라 달렸다. 만약 사이클을 형성하면 문제가 된다. 아래 그림을 보자.
만약 다익스트라 알고리즘을 통해 특정 한 노드(1)에서 다른 노드(2)로의 최소 거리를 구하는 문제를 해결하려 한다면 가중치 3 → 4 → 5를 거쳐 비용이 12가 된다. 하지만 중간에 사이클이 있기 때문에 3 → 4 → -6 → 4 → -6 → 4 → -6 ...이 되어 비용이 무한히 작아지게 된다.
이러한 문제점을 해결하기 위해 나온 알고리즘이 벨만 포드이다. 기본적으로 다익스트라와 동일하지만 핵심 차이점은 간선의 가중치가 음일 때도 최소 비용을 구할 수 있다. 다만 시간복잡도가 늘어나기 때문에 가중치가 모두 양수일 경우 다익스트라를 사용하는 것이 좋다. 시간 복잡도가 늘어나는 이유는 그리디하게 최소 비용 경로를 찾아가는 다익스트라와 달리, 벨만 포드는 모든 경우의 수를 고려하는 동적 계획법이 사용되기 때문이다.
그렇다면 모든 경우의 수를 어떻게 고려할까? 그 방법은 매 단계 마다 모든 간선을 전부 확인하는 것이다. 다익스트라는 출발 노드에서만 연결된 노드를 반복적으로 탐색하며 다른 모든 노드까지의 최소 거리를 구했다. 하지만 벨만 포드는 모든 노드가 한번씩 출발점이 되어 다른 노드까지의 최소 비용을 구한다.
아직 조금 추상적이니 구체적인 아래 그림을 보며 동작 과정을 알아보자.
위와 같은 그래프가 있다고 할 때 모든 노드가 한 번씩 출발 노드가 될 것이다. 복잡하지 않다. Itertation 1회, 2회일 때를 이해하면 귀납적으로 적용하여 이해할 수 있기 때문이다.
위와 같은 초기 상태의 그래프가 있을 때, 가중치를 담을 DP 테이블 값은 아래와 같이 모두 INF가 된다.
INF
INF
INF
INF
INF
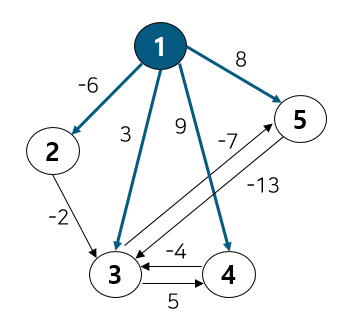
[Iteration 1] 첫 번째로 노드 1번을 먼저 탐색해보자.
1번 노드에 연결된 인접노드에 해당하는 간선의 가중치를 업데이트 해준다.
0
3
5
6
9
가중치 업데이트에 있어 시작 노드는 사이클이 없으므로 0이 되고, 2~5모두 연결된 간선이 있으므로 해당 가중치 값을 업데이트 해준다.
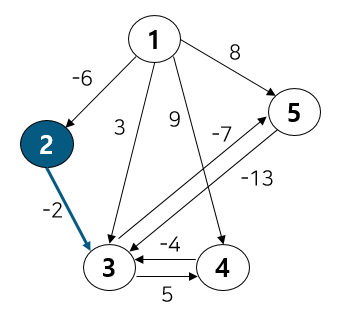
[Iteration 1] 이제 2번 노드를 보자. 2번 노드는 3번과 연결되어 있다.
1 → 3 경로 비용인 3보다 1 → 2 → 3 경로 비용인 -8이 더 작으므로 DP 테이블 값을 3에서 -8로 업데이트 해준다.
0
-6
-8
9
8
[Iteration 1] 이제 3번 노드를 보자. 4번과 5번 노드에 연결되어 있다.
1 → 4 비용인 9보다 1 → 2 → 3 → 4 비용인 -3이 작으므로 9를 -3으로 업데이트 해준다.
0
-6
-8
-3
8
또 1 → 5 비용인 8보다 1 → 2 → 3 → 5 비용인 -15가 작으므로 8을 -15로 업데이트 해준다.
0
-6
-8
-3
-15
[Iteration 1] 이제 4번 노드를 보자. 3번 노드와 연결되어 있다.
DP 테이블의 3번에 담긴 비용인 -8이 1 → 4 → 3 비용인 5보다 작으므로 업데이트 하지 않는다.
0
-6
-8
-3
-15
[Iteration 1] 이제 5번 노드를 보자. 3번 노드와 연결되어 있다.
DP 테이블 3번의 -8이 1 → 5 → 3의 비용 -5보다 더 작으므로 업데이트 하지 않는다.
0
-6
-8
-3
-15
이를 노드 개수(V) - 1까지 반복 진행한다. 그리고 추가적으로 음의 사이클의 존재 여부를 파악하고 싶다면 마지막으로 1번더 반복하여 총 V번의 반복 했을 때 V-1번 했을 때와 값이 달라진다면 음의 사이클이 있는 것이라 판별할 수 있다. 음의 사이클이 있다면 반복시 무한히 작아지기 때문이다.
Iteration1 종료시 [inf, 0, -6, -8, -3, -15]
Iterataion2 종료시 [inf, 0, -6, -28, -23, -35]
Iteration3 종료시 [inf, 0, -6, -48, -43, -55]
Iteration4 종료시 [inf, 0, -6, -68, -63, -75]
가되며 마지막으로 여기서 한 번더 수행했을 때 값이 바뀐다면 음의 사이클이 존재하는 것이다.
Iteration5 종료시 [inf, 0, -6, -88, -63, -75]
이를 코드로 구현하면 다음과 같다.
"""
5 9
1 2 -6
1 3 3
1 4 9
1 5 8
2 3 -2
3 4 5
3 5 -7
4 3 -4
5 3 -13
"""
import sys
input = sys.stdin.readline
def bellman_ford(start):
weights[start] = 0
for i in range(V):
for src, dst, weight in graph:
W = weights[src] + weight
if weights[src] != INF and weights[dst] > W:
weights[dst] = W
if i == V -1:
return False # negative cycle exists
return True # there is no cycle
V, E = map(int, input().split())
graph = []
for _ in range(E):
src, dst, weight = map(int, input().split())
graph.append([src, dst, weight])
INF = float('inf')
weights = [INF] * (V+1)
if bellman_ford(1): # 출발 노드를 인자 값으로 넣어줄 것
for i in range(2, V+1): # 출발 노드인 1을 제외하고 다른 모든 노드로 가기 위한 최단 거리 출력
print (weights[i], end = ' ')
else:
print ("There is negative cycle.")
플로이드 워셜 알고리즘은 모든 노드 간의 최단거리를 구할 수 있다. 한 노드에서 다른 모든 노드까지의 최단 거리를 구하는 다익스트라와 벨만포드 알고리즘과 대조된다. 플로이드 워셜 알고리즘은 그래프 상에서 음의 가중치가 있더라도 최단 경로를 구할 수 있다. 하지만 음의 가중치와 별개로 음의 사이클이 존재한다면 벨만 포드 알고리즘을 사용해야 한다.
플로이드 워셜 알고리즘은 모든 노드 간의 최단거리를 구하고 이 때, 점화식이 사용되기에 동적 계획법에 해당한다. 동적 계획법에 해당하므로 최단 거리를 업데이트할 테이블이 필요하다. 이 때 모든 노드간의 최단 거리이므로 2차원 배열이 사용된다. 특정 한 노드에서 출발하는 다익스트라가 1차원 배열을 사용하는 것과 차이점이 있다.
플로이드 워셜 알고리즘의 핵심은 각 단계마다 특정한 노드 k를 거쳐 가는 경우를 확인한다. 아래 점화식을 살펴보면 다음과 같다.
$D_{ij} = min(D_{ij}, D_{ik} + D_{kj})$
$i$에서 $j$로 가는 것과 $i$에서 $k$를 거쳐 $j$로 가는 것 중 어느 것이 최소 비용인지를 찾는 것이다.
구현은 매우 간단하여 3중 for문이 사용된다. 아래 코드는 위 점화식을 기반으로 코드화 시킨 것이다.
for k in range(1, V+1): # via
graph[k][k] = 0 # 사이클 없으므로 자기 자신 0
for i in range(1, V+1): # src
for j in range(1, V+1): # dst
graph[i][j] = min(graph[i][j], graph[i][k]+graph[k][j])
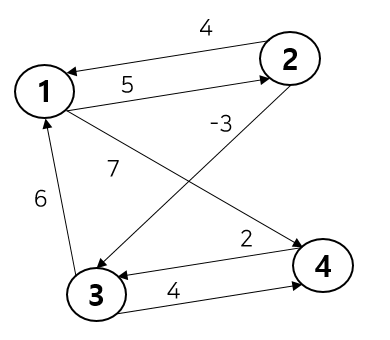
코드와 함께 동작 과정을 아래 그래프를 통해 살펴보자.
노드 4개와 간선 7개로 구성된 그래프다. 이를 바탕으로 DP 테이블 초기 상태를 만들면 다음과 같다. 하나의 노드에서 다른 노드로 바로 갈 수 있다면 가중치를, 없다면 INF를 저장해준다.
INF
5
INF
7
4
INF
-3
INF
6
INF
INF
4
INF
INF
2
INF
이제 3중 for문을 사용해 거쳐가는 노드를 설정 후 해당 노드를 거쳐갈 때 비용이 줄어드는 경우 값을 업데이트 시켜줄 것이다. 먼저 거쳐가는(k) 노드가 1일 때의 경우를 살펴보자
[Iteration 1] 거쳐가는 노드 K = 1
Iteration 1의 테이블 첫 번째 행을 업데이트 해보자. 노드 1에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[1][2] = min(graph[1][2], graph[1][1]+graph[1][2]) : 5와 0+5를 비교하는 것이므로 업데이트 X
graph[1][3] = min(graph[1][3], graph[1][1]+graph[1][3]): INF와 0+INF를 비교하는 것이므로 업데이트 X
graph[1][4] = min(graph[1][4], graph[1][1]+graph[1][4]): 7과 0+7을 비교하는 것이므로 업데이트 X
Iteration 1의 테이블 첫 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 없었으므로 전과 동일하다. 다만 graph[k][k] = 0에 의해 첫번째 값만 INF에서 0으로 바뀌었다.
0
5
INF
7
4
INF
-3
INF
6
INF
INF
4
INF
INF
2
INF
Iteration 1의 테이블 두 번째 행을 업데이트 해보자. 노드 2에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[2][1] = min(graph[2][1], graph[2][1]+graph[1][1]): 4와 4+0을 비교하는 것이므로 업데이트 X
graph[2][2] = min(graph[2][2], graph[2][1]+graph[1][2]): INF와 4+9를 비교하는 것이므로 업데이트 O
graph[2][3] = min(graph[2][3], graph[2][1]+graph[1][3]): -3과 4+INF를 비교하는 것이므로 업데이트 X
graph[2][4] = min(graph[2][4], graph[2][1]+graph[1][4]): INF와 4+7을 비교하는 것이므로 업데이트 O
Itertaion 1의 테이블 두 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 두 번 이뤄졌다.
0
5
INF
7
4
INF → 9
-3
INF → 11
6
INF
INF
4
INF
INF
2
INF
Iteration 1의 테이블 세 번째 행을 업데이트 해보자. 노드 3에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[3][1] = min(graph[3][1], graph[3][1]+graph[1][1]): 6과 6+0을 비교하는 것이므로 업데이트 X
graph[3][2] = min(graph[3][2], graph[3][1]+graph[1][2]): INF와 11을 비교하는 것이므로 업데이트 O
graph[3][3] = min(graph[3][3], graph[3][1]+graph[1][3]): INF와 6+INF를 비교하는 것이므로 업데이트 X
graph[3][4] = min(graph[3][4], graph[3][1]+graph[1][4]): 4와 13을 비교하고 원래 4였으므로 업데이트 X
Itertaion 1의 테이블 세 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 한 번 이뤄졌다.
0
5
INF
7
4
9
-3
11
6
INF → 11
INF
4
INF
INF
2
INF
Iteration 1의 테이블 네 번째 행을 업데이트 해보자. 노드 4에서 노드 1을 거쳐 노드 1~4까지 탐색하는 경우이다.
graph[4][1] = min(graph[4][1], graph[4][1]+graph[1][1]): INF와 INF+0을 비교하므로 업데이트 X
graph[4][2] = min(graph[4][2], graph[4][1]+graph[1][2]):INF와 INF+5를 를 비교하므로 업데이트 X
graph[4][3] = min(graph[4][3], graph[4][1]+graph[1][3]): 2와 INF+INF를 비교하고 원래 2였으므로 업데이트 X
graph[4][4] = min(graph[4][4], graph[4][1]+graph[1][4]): INF와 INF+7을 비교하므로 업데이트 X
Itertaion 1의 테이블 네 번째 행을 업데이트 한 결과는 다음과 같다. 업데이트는 이뤄지지 않았다.
0
5
INF
7
4
9
-3
11
6
11
INF
4
INF
INF
2
INF
이러한 과정을 노드의 수만큼 반복해주면 된다. 이를 요약하면 다음과 같다.
Iteration2는 노드 1~4에서 노드2를 거쳐 노드 1~4를 탐색하는 경우가 될 것이다.
Iteration3은 노드 1~4에서 노드3을 거쳐 노드 1~4를 탐색하는 경우가 될 것이다.
Iteration4는 노드 1~4에서 노드4를 거쳐 노드 1~4를 탐색하는 경우가 될 것이다.
이를 코드로 나타내면 앞서 본 것과 동일하다. 중요한 것은 거쳐서 노드 k를 거쳐갈때 다이렉트로 가는 것보다 비용이 적어지는가를 판단하는 것이다.
for k in range(1, V+1): # via
graph[k][k] = 0 # 사이클 없으므로 자기 자신 0
for i in range(1, V+1): # src
for j in range(1, V+1): # dst
graph[i][j] = min(graph[i][j], graph[i][k]+graph[k][j])
이러한 플로이드 워셜 알고리즘을 구현하는 전체 코드는 다음과 같다.
""" This is input value. you can just copy and paste it.
4 7
1 2 5
1 4 7
2 1 4
2 3 -3
3 1 6
3 4 4
4 3 2
"""
import sys
input = sys.stdin.readline
V, E = map(int, input().split())
INF = float('inf')
graph = [[INF] * (V+1) for _ in range(V+1)]
for _ in range(E):
src, dst, weight = map(int, input().split())
graph[src][dst] = weight
for k in range(1, V+1): # via
graph[k][k] = 0
for i in range(1, V+1): # src
for j in range(1, V+1): # dst
graph[i][j] = min(graph[i][j], graph[i][k]+graph[k][j])
for i in range(1, V+1):
for j in range(1, V+1):
print (graph[i][j], end= ' ')
print()
링크드 리스트란 데이터와 포인터를 담은 노드를 연결시킨, 연결 자료구조다. 다음 노드만 가리키는 포인터만 있다면 단순 연결 리스트(Single Linked List)라 하고, 다음 노드와 이전 노드를 가리키는 포인터 두 개가 있다면 이중 연결 리스트(Doubly Linked List)라고 한다. 만약 두 링크드 리스트에서 head와 tail이 서로 앞 뒤로 연결되어 있다면 환형 연결 리스트(Circular Linked List)이다.
링크드리스트는 순차 자료구조인 배열과 달리 포인터를 사용하기에 삽입과 삭제가 용이하다. 또한 배열과 달리 크기를 동적으로 조절할 수 있는 것도 장점이다. 반면 링크드 리스트는 특정 노드를 바로 접근할 수 없는 것이 단점이다. 링크드 리스트를 전부를 탐색해야 할 수 있도 있다. 따라서 링크드 리스트와 배열은 경우에 따라 나누어 사용해야 한다. 데이터가 빈번히 추가되거나 삭제될 경우 링크드리스트를 쓰는 것이 적합하고, 데이터 탐색과 정렬이 위주라면 배열을 쓰는 것이 적합하다. 참고로 윈도우 작업 관리자가 대표적인 링크드 리스트를 사용한 구현물이다. 하나의 프로세스는 앞 뒤로 다른 프로세스들과 연결되어 있는 Circular Linked List 구조로 되어 있다. 첫 번째 프로세스부터 다음 포인터를 계속 탐색하면 모든 프로세스 리스트를 가져올 수 있다.
단순 연결 리스트의 경우 기능은 크게 삽입/삭제/조회/탐색으로 구성된다. 이를 구현하기 위해 노드에 정보를 담을 Node 클래스와 기능을 구현할 SinglyLinkedList 클래스가 필요하다. 구현물은 다음과 같다.
class Node:
def __init__(self, data, next = None) -> None:
self.data = data
self.next = next
class SinglyLinkedList:
def __init__(self) -> None:
self.head = None
self.size = 0
def size(self):
return self.size
def is_empty(self):
return self.size == 0
def insert_front(self, data):
if self.is_empty():
self.head = Node(data, None)
else:
self.head = Node(data, self.head)
self.size += 1
def insert_back(self, data, current):
current.next = Node(data, current.next)
self.size += 1
def delete_front(self):
if self.is_empty():
raise LookupError("There is no node in the linked list")
self.head = self.head.next
self.size -= 1
def delete_back(self, current):
if self.is_empty():
raise LookupError("There is no node in the linked list")
temp = current.next
current.next = temp.next
self.size -= 1
def traverse(self):
array = []
current = self.head
while current:
array.append(current.data)
current = current.next
return array
def search(self, target):
current = self.head
for i in range(self.size):
if current.data == target:
return i
current = current.next
return None
def print_list(self):
current = self.head
while current:
if current.next != None:
print (current.data, '→ ', end='')
else:
print (current.data)
current = current.next
if __name__ == "__main__":
S = SinglyLinkedList()
# Insert
S.insert_front('apple')
S.insert_front('bear')
S.insert_front('cat')
S.insert_back('dog', S.head.next)
S.insert_front('egg')
S.insert_front('fish')
# Search
S.print_list() # fish → egg → cat → bear → dog → apple
print(f"Index: {S.search('dog')}") # Index: 4
# Delete
S.delete_front()
S.print_list() # egg → cat → bear → dog → apple
S.delete_back(S.head)
S.print_list() # egg → bear → dog → apple
# Traverse
print (S.traverse()) # ['egg', 'bear', 'dog', 'apple']
더블 링크드 리스트 또한 구현을 위해 노드에 정보를 담을 Node 클래스와 기능을 구현할 SinglyLinkedList 클래스가 필요하다. 구현물은 다음과 같다.
class Node:
def __init__(self, data=None, prev=None, next=None):
self.data = data
self.prev = prev
self.next = next
class DoublyLinkedList:
def __init__(self):
self.head = Node()
self.tail = Node(prev=self.head)
self.head.next = self.tail
self.size = 0
def size(self):
return self.size
def is_empty(self):
return self.size == 0
def insert_front(self, current, data):
temp = current.prev
next = Node(data, temp, current)
current.prev = next
temp.next = next
self.size += 1
def insert_back(self, current, data):
temp = current.next
next = Node(data, current, temp)
temp.prev = next
current.next = next
self.size += 1
def delete(self, current):
front = current.prev
back = current.next
front.next = back
front.prev = back
self.size -= 1
return current.data
def print_list(self):
if self.is_empty():
raise LookupError('There is no node in the linked list')
else:
current = self.head.next
while current != self.tail:
if current.next != self.tail:
print(current.data, '←→ ', end='')
else:
print(current.data)
current = current.next
D = DoublyLinkedList()
D.insert_back(D.head, 'apple')
D.insert_front(D.tail, 'bear')
D.insert_front(D.tail, 'cat')
D.insert_back(D.head.next, 'dog')
D.print_list() # apple ←→ dog ←→ bear ←→ cat
D.delete(D.tail.prev)
D.print_list() # apple ←→ dog ←→ bear
D.insert_front(D.tail.prev, 'fish') # apple ←→ dog ←→ bear ←→ fish ←→ cat
D.print_list()
D.delete(D.head.next) # dog ←→ bear ←→ fish ←→ cat
D.print_list()
D.delete(D.tail.prev) # dog ←→ bear ←→ fish
D.print_list()
이진 탐색 알고리즘은 탐색 알고리즘 종류 중 하나로, 이름 그대로 절반씩 나누어 원하는 값을 알고리즘이다. 이진 탐색을 위한 전제 조건으로 배열이 오름차순 또는 내림차순으로 정렬되어 있어야 한다. 동작 방식은 간단하다. 배열의 중앙을 기준으로 원하는 값이 작은지 큰지 비교하여 한 쪽을 배제하고 나머지 부분을 반복해서 탐색하는 방식이다.
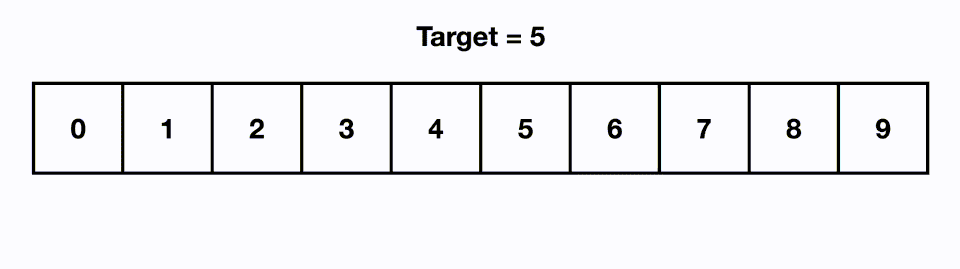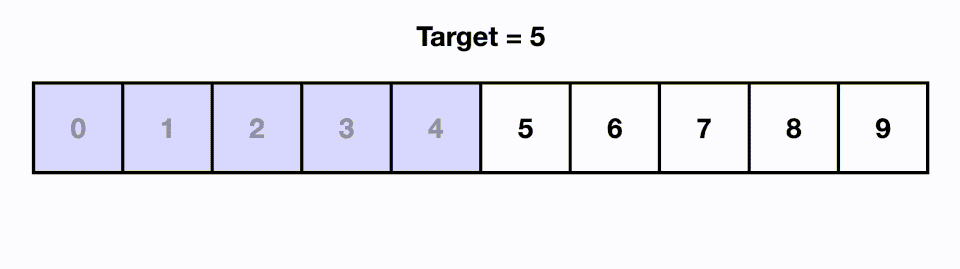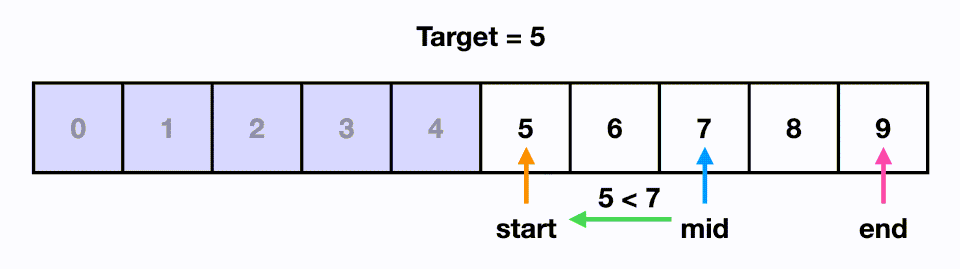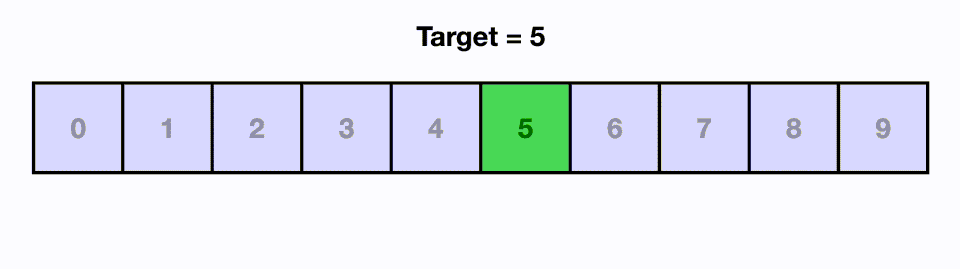
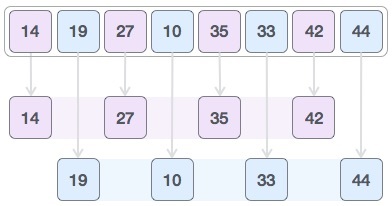
가령 예를 들어 아래와 같이 찾고자 하는 값이 5일 경우, 배열의 가운데인 4를 기준으로 삼은 다음 오른쪽에 있다는 것을 알 수 있다. 이후 왼쪽 배열 0~4를 배제하고 오른쪽 배열 5~9 부분을 탐색한다. 찾고자 하는 값이 5~9 부분의 중앙인 7을 기준으로 왼쪽에 있으므로 다시 오른쪽 배열을 배제하고 왼쪽 배열 5~7을 탐색한다. 6을 기준으로 왼쪽에 있으므로 오른쪽 7을 배제하고 왼쪽 5를 찾으며 탐색이 완료되는 방식으로 동작한다.
원하는 값을 찾기 위해 배열의 모든 원소를 탐색하는 순차 탐색의 경우 시간복잡도가 $O(n)$이다. 하지만 이진 탐색의 경우 시간복잡도가 이보다 작은 $O(logN)$이 된다는 것이 특징이다. 조금 덧붙이자면 시간복잡도 $O(logN)$는 배열이 정렬되고 고정된 상태에서 가능하다. 만약 배열에 삽입, 제거, 탐색과 같은 연산이 함께 이뤄진다면 시간복잡도가 $O(n)$까지 떨어질 수 있다. 때문에 삽입, 제거, 탐색과 같은 연산이 함께 이뤄지는 경우 이진탐색 트리를 자료구조로서 사용해야 한다. 이진탐색트리의 경우 삽입, 제거, 탐색을 해도 시간복잡도가 $O(logN)$이 보장되는 특징이 있기 때문이다.
이진 탐색 알고리즘 구현은 크게 두 가지 방법이 있다. 첫 번째는 재귀를 사용하지 않는 방식이고, 두 번째는 재귀를 사용하는 방식이다. 두 구현 방법 모두 공통적으로 세 종류의 변수들이 필요하다.
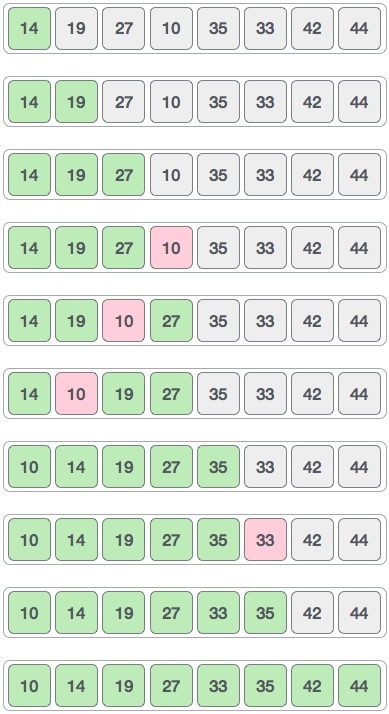
버블정렬은 서로 인접해 있는 요소 간의 대소 비교를 통해 정렬한다. 버블 정렬은 정렬 알고리즘 중 가장 단순한 알고리즘으로, 단순한 만큼 비효율적이다. 시간 복잡도가 최고, 평균, 최악 모두 $O(n^2)$이며 공간복잡도는 하나의 배열만 사용하므로 $O(n)$을 가진다. 동작 방식은 인접한 두 요소간의 대소 비교를 진행한다.
만약 배열에 n개의 요소가 있을 경우 1번째 원소 vs 2번째 원소를 비교하고 2번째 원소 vs 3번째 원소를 비교하고, ... n-1번째 원소 vs n번째 요소를 비교하면 1회전 비교가 끝난다. 1회전이 끝나면 가장 큰 원소는 맨 뒤에 위치하게 되므로 2회전 비교에서는 제외된다. 마찬가지로 두 번째로 큰 원소는 가장 큰 원소 앞에 위치하게 되므로 3회전 비교에서는 제외된다. 즉 버블 정렬을 1회 수행할 때 마다 정렬해야 할 원소가 하나씩 줄어든다. 이를 코드로 구현하면 아래와 같다.
def bubble_sort(array):
""" Best: O(n^2) Average: O(n^2) Worst: O(n^2) | O(n) """
for i in range(len(array)):
for j in range(len(array)-i-1):
if array[j] > array[j+1]:
array[j], array[j+1] = array[j+1], array[j]
return array
2. 삽입 정렬 (Insert Sort)
삽입 정렬이란 정렬을 진행할 원소의 index보다 낮은 곳에 있는 원소들을 탐색하며 알맞은 위치에 삽입해주는 정렬 알고리즘이다. 동작 방식은 두 번째 index부터 시작한다. 그 이유는 첫 번째 index는 비교할 원소가 없기 때문이다. 알고리즘이 동작하는 동안 계속해서 정렬이 진행되므로 반드시 맨 왼쪽 index까지 탐색하지 않아도 된다는 장점이 있다. 모두 정렬되어 있는 Optimal한 경우 모든 원소가 한 번씩만 비교되므로 $O(n)$의 시간 복잡도를 가진다. 또한 공간복잡도는, 하나의 배열에서 정렬이 이루어지므로 $O(n)$이다.
삽입 정렬을 코드로 구현하면 아래와 같다. 첫 번째 for문은 정렬할 원소를 차례대로 선택하는 것이며, 두 번째 for문은 정렬할 원소보다 아래 인덱스에 있는 요소와 비교하기 위함이다.
def insert_sort(array):
""" Best: O(n) Average: O(n^2) Worst: O(n^2) | O(n) """
for i in range(1, len(array)):
for j in range(i, 0, -1):
if array[j-1] > array[j]:
array[j-1], array[j] = array[j], array[j-1]
return array
삽입 정렬을 최적화할 경우 아래 코드와 같다.
def insert_sort(array):
for i in range(1, len(array)):
j = i
while j > 0 and array[j-1] > array[j]:
array[j-1], array[j] = array[j], array[j-1]
j -= 1
return array
3. 선택 정렬 (Selection Sort)
선택 정렬이란 배열에서 최소값을 반복적으로 찾아 정렬하는 알고리즘이다.
시간복잡도 최선, 평균, 최악 모두 $O(n^2)$에 해당하는 비효율적인 알고리즘으로 정렬 여부와 상관없이 모든 경우의 수를 전부 확인한다. 동작방식 3단계로 구성된다. 첫 번째는 주어진 배열에서 최소값을 찾는다. 두 번째는 최소값을 맨 앞의 값과 바꾼다. 세 번째는 바꿔준 맨 앞 값을 제외한 나머지 원소를 동일한 방법으로 바꿔준다. 이를 알고리즘으로 나타내면 다음과 같다.
def selection_sort(array):
""" Best: O(n^2) Average: O(n^2) Worst: O(n^2) | O(N^2) """
for i in range(len(array)):
idx = i
for j in range(i+1, len(array)):
if array[idx] > array[j]:
idx = j
array[idx], array[i] = array[i], array[idx]
return array
덧붙여 선택 정렬은 크게 2가지로 최소 선택 정렬과, 최대 선택 정렬이 있다. 최소는 위와 같이 오름차순으로 정렬하는 것이고 최대는 위와 반대로 내림차순으로 정렬하는 것이다.
4. 퀵 정렬 (Quick Sort)
퀵 정렬은 분할정복법과 재귀를 사용해 정렬하는 알고리즘이다.
퀵 정렬에는 피봇(Pivot)이라는 개념이 사용된다. 피봇은 한 마디로 정렬 될 기준 원소를 뜻한다. 피봇 선택 방법에 따라 퀵 정렬의 성능이 달라질 수 있다. 최적의 피봇 선택이 어려우므로 임의 선택을 해야 한다. 보통 배열의 첫 번째 값이나 중앙 값을 선택한다. 퀵 정렬의 동작방식은 다음과 같다. 가령 예를 들어 배열 [5, 6, 1, 4, 2, 3, 7]이 있고, 피봇을 임의로 4를 선택했다 가정하자. 이후 4를 기준으로 작은 것은 왼쪽으로 큰 것은 오른쪽으로 보내 [1, 2, 3] < 4 < [5, 6, 7]를 생성한다. 다시 왼쪽에서부터 임의의 피봇 2를 설정하여 [1] < 2 < [3]을 생성하고 오른쪽에선 임의의 피봇 6를 설정하여 [5] < 6 < [7]로 나눈다. 만약 배열 길이가 1이 된다면 가장 정렬 완료된 것이므로 분할된 배열을 합쳐 줌으로써 정렬을 마친다. 이를 알고리즘으로 구현하면 다음 코드와 같다.
def quick_sort(array : list) -> list:
""" Best: O(nlogn) Average: O(nlogn) Worst: O(n^2) | O(nlogn) """
if len(array) <= 1:
return array
pivot = array[len(array) // 2]
small, equal, big = [], [], []
for num in array:
if num < pivot:
small.append(num)
elif num > pivot:
big.append(num)
else:
equal.append(num)
return quick_sort(small) + equal + quick_sort(big)
5. 병합 정렬 (Merge Sort)
병합 정렬은 분할정복과 재귀 알고리즘을 사용하는 정렬 알고리즘이다.
퀵 정렬과 함께 두 개의 알고리즘이 사용된다는 측면에서 공통점을 가진다. 하지만 차이점은 퀵 정렬이 피봇 선택 이후 피봇 기준으로 대소를 비교하는 반면, 병합 정렬은 배열을 원소가 하나만 남을 때 까지 계속 이분할 한 다음, 대소관계를 고려하여 다시 재배열 하며 원래 크기의 배열로 병합한다. 예를 들어 배열 [6, 5, 1, 4, 3, 2, 8, 7]이 있을 때, 첫 번째로 [6, 5, 1, 4]와 [3, 2, 8, 7]로 분리한다. 두 번째로 [6, 5], [1, 4], [3, 2], [8, 7]로 나눈다. 세 번째로 [6], [5], [1], [4], [3], [2], [8], [7]로 나눈다. 이렇게 모든 원소가 분리되면 대소 관계를 고려하여 병합 과정을 거친다. 첫 번째로 [5, 6], [1, 4], [2, 3], [7, 8]이 되며, 두 번째는 [1, 4, 5, 6], [2, 3, 7, 8]이 된다. 마지막으로 하나의 배열로 병합되면서 [1, 2, 3, 4, 5, 6, 7, 8]와 같이 정렬이 완료되면서 알고리즘이 종료된다. 이를 코드로 나타내면 아래 코드와 같다.
def merge_sort(array: list) -> list:
""" Best: O(nlogn) Average: O(nlogn) Worst: O(nlogn) | O(n) """
if len(array) < 2:
return array
mid = len(array)//2
low = merge_sort(array[:mid])
high = merge_sort(array[mid:])
merged_array = []
l, h = 0, 0
while l < len(low) and h < len(high):
if low[l] < high[h]:
merged_array.append(low[l])
l += 1
else:
merged_array.append(high[h])
h += 1
merged_array += low[l:]
merged_array += high[h:]
return merged_array
시간 복잡도의 경우 최선, 평균, 최악 모두 $O(nlogn)$이며 공간 복잡도의 경우 정렬된 원소를 담을 배열이 하나 필요로 하므로 $O(n)$.
6. 힙 정렬 (Heap Sort)
힙이란 트리 기반의 자료구조로서, 두 개의 노드를 가진 완전 이진 트리를 의미한다. 따라서 힙 정렬이란 완전 이진 트리를 기반으로 하는 정렬 알고리즘이다. 힙의 분류는 크게 최대 힙과 최소 힙 두 가지로 나뉜다. 최대 힙은 내림차순 정렬에 사용하며, 최소 힙은 오름차순 정렬에 사용한다.
최대힙의 경우 부모 노드가 항상 자식노드 보다 크다는 특징을 가진다. 반대로 최소힙의 경우 부모 노드가 항상 자식노드 보다 작다는 특징을 가진다. 이러한 힙에서 오해할 수 있는 특징은 힙은 정렬된 구조가 아니다. 부모 자식 간의 대소 관계만 나타내며 좌우 관계는 나타내지 않기 때문이다. 예를 들어 최소 힙에서 대부분 왼쪽 노드가 오른쪽 노드보다 작지만 4의 자식 노드인 7과 5는 왼쪽이 오른쪽보다 크다.
힙은 완전 이진 트리기 때문에 적절히 중간 레벨의 노드를 추출하면 중앙값에 가까운 값을 근사치로 빠르게 추출할 수 있다는 장점을 갖고 있다. 때문에 힙은 배열에 순서대로 표현하기 적합하다. 또한 균형을 유지하려는 특징 때문에 힙은 우선순위 큐, 다익스트라, 힙 정렬, 프림 알고리즘에 활용된다. 특히 힙 덕분에 다익스트라 알고리즘의 시간 복잡도는 $O(V^2)$에서 O(ElogV)로 줄어들 수 있었다.
힙 정렬 과정을 최대힙을 기준으로 우선 간략히 보자면 아래 GIF와 같다.
최대힙 정렬 동작 과정
최대 힙의 동작을 코드로 작성하면 아래와 같다.
def heap_sort(array : list) -> list:
""" Best: O(nlogn) Average: O(nlogn) Worst: O(nlogn) | O(nlogn) """
n = len(array)
for i in range(n//2-1, -1, -1):
heapify(array, i, n)
for i in range(n-1, 0, -1):
array[0], array[i] = array[i], array[0]
heapify(array, 0, i)
return array
def heapify(array : list, index : int, heap_size : int) -> None:
smallest = index
left = (2 * index) + 1
right = (2 * index) + 2
if left < heap_size and array[left] < array[smallest]:
smallest = left
if right < heap_size and array[right] < array[smallest]:
smallest = right
if smallest != index:
array[smallest], array[index] = array[index], array[smallest]
heapify(array, smallest, heap_size)
if __name__ == "__main__":
array = [1, 10, 5, 5, 2, 9, 8, 7, 6, 4, 0, 3, 2, 9]
print (heap_sort(array)) # [10, 9, 9, 8, 7, 6, 5, 5, 4, 3, 2, 2, 1, 0]
먼저 heapify 함수의 역할은 부모와 자식의 대소 관계를 확인해 자리를 바꿔주는 동작을 한다. 예를 들어 위 같이 최대힙을 구현할 때 부모 노드가 자식 노드보다 작다면 상호 간의 자리를 바꿔주는 것이다. left, right는 비교가 진행 될 노드의 인덱스를 의미한다. 초기 값은 루트 노드의 바로 아래 두 자식 노드이다. 첫 번째 조건문은 왼쪽 자식이 부모보다 작은지 확인한다. 두 번째 조건문은 오른쪽 자식이 부모보다작은지 확인한다. 세 번째 조건문은 초기 index와 동일하지 않다면 부모 자식간의 상호 위치를 변경한 뒤 재귀를 통해 반복한다.
7. 셸 정렬 (Shell Sort)
셸 정렬이란 삽입 정렬의 단점을 보완하고자 도입되었다. 삽입 정렬은 주어진 정렬 상태가 역순으로 배열되어 있을수록 비교횟수가 늘어나고, 최선의 경우 $O(N)$이지만 최악의 경우 $O(N^2)$으로 성능 차이가 크다. 셸 정렬은 이러한 시간복잡도를 평균적으로 $O(N^{1.25})$ 또는 $O(N^{1.5})$ 수준으로 낮추고자 도입된 알고리즘이다. 셸 정렬에 사용되는 핵심 개념은 interval (간격)이다. interval은 비교할 원소 간의 간격을 의미한다. 셸 정렬에서는 비교 횟수를 줄이기 위해 interval은 큰 값에서 낮은 값으로 낮춰간다. 동작 방식은 배열에서 interval 만큼 떨어진 원소들을 부분집합으로 구성한 뒤 삽입 정렬을 진행하는 방식으로 진행된다. 초기 interval 값은 len(array) // 2로 설정하며 계속 2로 나누어준다. 예를 들어 아래와 같이 배열 크기가 8이라면 초기 interval = 4가 되어 아래와 같이 비교가 진행 된다.
interval이 4인 경우 거리가 4만큼 떨어져 있는 원소끼리 부분집합을 이루어 비교대상이 된다. 위 그림에선 (35, 14), (33, 19), (42, 27), (10, 44)이 서로 비교 대상이 된다. 비교 진행한 뒤 interval을 2로 나누어주어 4에서 2가 된다. 이후 다시 interval만큼 떨어진 원소를 부분집합화하여 비교한다.
interval이 2인 경우 거리가 2만큼 떨어져 있는 원소끼리 부분집합을 이뤄 비교한다. (14, 27, 35, 42), (19, 10, 33, 34)가 부분집합이 되어 정렬이 진행된다. 이후 다시 interval을 2로 나눠주어 1이 되면 아래와 같이 삽입 정렬이 진행된다.
이를 코드로 구현하여 나타내면 다음과 같다. 주로 가독성을 위해 변수명을 interval을 h로 표현하기도 한다.
def shell_sort(array : list) -> list:
""" Best: O(n) Average: O(n^1.25,1.5) Worst: O(n^2) | O(n) """
n = len(array)
interval = n // 2
while interval > 0:
for i in range(interval, n):
j = i - interval
temp = array[i]
while j >= 0 and array[j] > temp:
array[j+interval] = array[j]
j -= interval
array[j+interval] = temp
interval //= 2
return array
8. 기수 정렬 (Radix Sort)
기수 정렬은 non-comparison 알고리즘으로 원소간의 대소 비교를 하지 않고 정렬하는 알고리즘이다. 대신 기수 정렬은 정렬하고자 하는 수의 낮은 자리 수를 차례대로 확인하여 정렬하는 방식이다. 정렬을 위해 총 10개의 queue를 사용한다.
첫 번째로, 1의 자리 수를 확인하여 각 원소의 1의 자리에 해당하는 queue에 쌓아준다. 이후 0~9의 queue를 순회하며 차례대로 가져온다. 두 번째로, 10의 자리 수를 확인하여 각 원소의 10의 자리에 해당하는 queue에 쌓아준다. 이후 0~9의 queue를 순회하며 차례대로 가져온다. 세 번째가 진행되기 위해서는 100의 자리수를 가진 값이 있어야 하며, n번째가 진행되기 위해서는 $10^{(n-1)}$의 자리수를 가진 수가 있어야 한다.
이를 코드로 구현하면 다음과 같다.
from collections import deque
def radix_sort(array : list) -> list:
""" Best: O(n) Average: O(n) Worst: O(n)"""
buckets = [deque() for _ in range(10)]
MAX = max(array)
queue = deque(array)
radix = 1
while MAX >= radix:
while queue:
num = queue.popleft()
buckets[(num // radix) % 10].append(num)
for bucket in buckets:
while bucket:
queue.append(bucket.popleft())
radix *= 10
return queue
자리수를 담을 bucket을 총 10개 생성해준다. 이후 가장 큰 자리 수 만큼 반복해야 하므로 max(array)를 통해 가져온다. 알고리즘은 크게 두 단계로 나눠서 보면 간단하다. 첫 번째는 queue에 있는 배열을 각 자리수에 해당하는 bucket에 담아주는 과정이다. 두 번째는 bucket에 담은 원소들을 다시 queue에 담아주는 과정이다. 다만 이 두 과정을 반복하되 배열 최대값이 가지는 최대 자리수까지는 비교해주어야 하므로 radix에 10을 곱해줘서 반복하며, 배열 최대값의 자리수보다 넘어가면 끝나는 것이다.
9. 카운팅 정렬 (Counting Sort)
카운팅 정렬(계수 정렬)은 non-comparison sort 알고리즘에 해당하는 알고리즘으로 comparison sort에 해당하는 버블, 선택, 힙, 병합, 퀵, 삽입이 기껏해야 평균적으로 $O(nlogn)$이나 $O(n^2)$의 시간복잡도를 갖기에 이를 $O(n)$ 수준으로 낮추고자 도입된 알고리즘이다. 카운팅 정렬의 동작은 이름 그대로 배열에 존재하는 원소 별 개수를 세어 정렬하는 방식으로 간단히 나타내보이자면 아래 GIF와 같다.
배열에 담긴 요소의 개수를 count라는 배열에 담아 넣은 뒤 차례대로 개수만큼 출력해준다. 우선, 결과적으로 코드를 구현해보자면 아래와 같이 간단한 코드로 나타낼 수 있으며 크게 5단계로 이뤄진다.
def counting_sort(array : list) -> list:
""" Best: O(n) Average: O(n+k) Worst: O(n+k) | O(n+k) """
count = [0] * (max(array) + 1) # 1. create a count array to check how many numbers each have.
for num in array: # 2. check how many numbers each have.
count[num] += 1
for i in range(1, len(count)): # 3. do cumulative sum
count[i] += count[i-1]
arr = [0] * len(array) # 4. create a new array to contain the numbers to be sorted.
for num in array: # 5. sort.
idx = count[num]
arr[idx-1] = num
count[num] -= 1
return arr
1. 배열에 있는 원소 개수를 담을 count 배열을 생성한다. 배열 크기는 원소 값 그대로를 인덱스로 사용하기 위해 max(array)+1로 해준다.
2. 배열에 있는 원소 개수를 count 해준다.
3. 누적합을 진행한다. 그 이유는 누적합을 진행하게 되면 앞 뒤 원소 간의 개수 차이가 곧 몇 칸을 차지할지 알 수 있기 때문이다. 이 부분이 제일 처음 잘 이해가 되지 않는 부분이었다. 예를 들어 설명하기 위해 임의의 배열 [2, 5, 3, 2, 1, 4, 4, 2]라는 배열이 있다 하자. 그러면 count 배열이 [0, 1, 3, 1, 2, 1]가 된다. 이후 count 배열에 누적합을 진행하면 [0, 1, 4, 5, 7, 8]이 된다. 이 누적합을 통해 아래와 같은 사실을 알 수 있다.
count[0] = 0: count 배열의 0번째 인덱스인 값 0은 (0-0)칸을 차지하고, 위치하게 되는 인덱스는 [0:0]이 된다. count[1] = 1: count 배열의 1번째 인덱스인 값 1은 (1-0)칸을 차지하고, 위치하게 되는 인덱스는 [0:1]이 된다. count[2] = 4: count 배열의 2번째 인덱스인 값 2는 (4-1)칸을 차지하고, 위치하게 되는 인덱스는 [1:4]가 된다. count[3] = 5: count 배열의 3번째 인덱스인 값 3은 (5-4)칸을 차지하고, 위치하게 되는 인덱스는 [4:5]가 된다. count[4] = 7: count 배열의 4번째 인덱스인 값 4는 (7-5)칸을 차지하고, 위치하게 되는 인덱스는 [5:7]이 된다. count[5] = 8: count 배열의 5번째 인덱스인 값 5는 (8-7)칸을 차지하고, 위치하게 되는 인덱스는 [7:8]이 된다.
즉, 누적합 해준 배열을 통해 원소 개수 만큼 도출된 인덱스에 넣어주면 자연스럽게 정렬 되는 것이다. 이러한 과정을 거치기 위해 다음 2단계를 더 진행 한다.
4. 정렬 된 원소를 담고자하는 새로운 배열을 생성해준다. 새 배열 크기는 원래 배열 크기와 동일하다.
5. 정렬하고자 하는 배열의 원소를 순회하며 count[원소]의 위치에서 누적합 되어 있는 값을 index로 지정해준다. 이후 새로 생성한 배열 result에 그 값을 넣어주고 누적합된 값을 -1을 해준다. 여기서 누적합 값에 -1을 해주는 것은 result의 index에 차례대로 같은 수를 담는 것이 아니라 역순으로 담아야 하기 때문이다. 역순으로 값을 담는 이유는 현재 알고리즘 구조상 역순으로 담아야 하기 때문이다. 이중 루프를 통해서 차례대로 값을 담을 수 있지만 코드 가독성과 동작 효율성을 고려하면 위와 같이 작성하는 것이 더 좋다.
마지막으로 시간복잡도는 $O(n+k)$가 된다. k가 상수이긴 하지만 생략되지 못하는 것은 그 만큼 영향을 미칠 수 있기 때문이다. 1~4번 과정 모두 $O(n)$에 해당한다. 하지만 5번에서 count 배열을 업데이트 하는 과정에서 원소 중 max 값인 k를 k만큼 반복하게 되므로 $O(n+k)$가 된다. 만약 정렬하고자 하는 배열의 max 값이 배열의 개수보다 작다면 $O(n)$이 된다. 하지만 배열의 개수보다 커지면 커질수록 배열 공간만 차지하고 값이 들어있지 않는 sprase한 배열이 될 수 있고, 무의미한 공간도 탐색해야 하므로 시간 복잡도가 높아질 수 있는 것이다.
10. Tim Sort
Tim Sort는 삽입정렬과 병합정렬이 결합된 정렬 알고리즘이다. Tim Peter라는 자에게 의해 고안된 알고리즘으로 파이썬 내장 정렬 알고리즘으로 채택되어 있다. Tim Sort는 왜 다른 알고리즘에 비해 상대적으로 느린 삽입정렬을 사용할까? 삽입정렬의 경우 앞서 기술한 바와 같이 평균과 최악의 경우 $O(n^2)$로 다른 알고리즘에 비해 시간복잡도가 높아 잘 사용되지 않는다. 하지만 이러한 단점에도 불구하고 삽입정렬에는 참조 지역성이라는 주요한 성질이 있다. 운영체제 시간에 배우거나 신입 개발자 인터뷰에 때때로 물어보는 내용이다.
CPU가 빠른 연산을 위해 사용하는 캐시 메모리에 데이터를 담을 때 적중률을 높이기 위해 사용하는 원리다. 쉽게 말해 최근 참조했던 메모리와 인접한 메모리를 참조할 확률이 높으니 이들을 캐시 메모리에 미리 담아두는 것이며, 삽입정렬은 인접한 메모리와 비교를 반복하기에 참조 지역성의 원리를 잘 만족하고 있다고 할 수 있다. 또 삽입정렬은 원소가 많아질수록 느려지는 단점이 있지만 정렬 수가 적당히 작은 수라면 퀵정렬보다 빨라지는 장점이 있다. Tim Sort는이러한 삽입정렬의 특성을 활용하여 전체 정렬 대상 원소들을 부분부분(divide)으로 작게 나눈 다음 삽입정렬을 수행하고 병합(conqure)을 수행하면 정렬이 조금 더 빠르지 않을까 하는 아이디어를 기반으로 만들어졌다. 이러한 Tim Sort는 실제로 시간복잡도를 최선의 경우 $O(n)$, 평균은 $O(n\log n)$, 최악의 경우 $O(n\log n)$를 갖는다.
Tim Sort에서는 이러한 삽입정렬을 그대로 사용하진 않고 속도를 개선한 이진삽입정렬을 사용한다. 이진삽입정렬을 사용하면 앞서 말한 참조 지역성이 떨어지게 되나 적당히 작은 수의 원소를 정렬한다면 참조 지역성이 크게 문제가 되지 않으면서 시간복잡도를 개선할 수 있게 된다.
RUN = 32
def insert_sort(array, left, right):
for i in range(left + 1, right + 1):
key = array[i]
j = i - 1
while j >= left and array[j] > key:
array[j + 1] = array[j]
j -= 1
array[j + 1] = key
def merge(array, left, mid, right):
len1 = mid - left + 1,
len2 = right - mid
left_array, right_array = [], []
for i in range(0, len1):
left_array.append(array[left + i])
for i in range(0, len2):
right_array.append(array[mid + 1 + i])
i, j, k = 0, 0, left
while i < len1 and j < len2:
if left_array[i] <= right_array[j]:
array[k] = left_array[i]
i += 1
else:
array[k] = right_array[j]
j += 1
k += 1
while i < len1:
array[k] = left_array[i]
k += 1
i += 1
while j < len2:
array[k] = right_array[j]
k += 1
j += 1
def tim_sort(array):
""" Best: O(n) Average: O(nlogn) Worst: O(nlogn) | O(n) """
n = len(array)
for i in range(0, n, RUN):
insert_sort(array, i, min((i + RUN - 1), n - 1))
size = RUN
while size < n:
for left in range(0, n, size * 2):
mid = left + size - 1
right = min((left + size * 2 - 1), (n - 1))
merge(array, left, mid, right)
size = size * 2
return array
if __name__ == "__main__":
array = [5, 2, 8, 4, 1, 9, 6, 3, 7]
sorted_array = tim_sort(array)
print(sorted_array)