import sys
input = sys.stdin.readline
fibo_nums = [0, 1]
for i in range(90):
fibo_nums.append(sum([fibo_nums[-1], fibo_nums[-2]]))
n = int(input())
print (fibo_nums[n])
학습법에 관심을 갖게 된 이후 학습이란 어떻게 해야하는가에 대한 확신을 가져다 준 책이다. 저자는 학습이란 크게 4가지 모듈로 구성된다고 말한다. 전략, 인풋, 추상화 및 구조화, 축적이다.
《전략》
전략의 배경은 우리가 독학에 사용할 수 있는 가용 시간이 적기 때문에 애초에 깊이, 자세히 아는 것은 불가능하기에 효율적인 인풋과 축적은 모두 전략에 달렸다며 그 중요성을 말한다. 전략의 핵심은 테마와 장르를 구분하는 것이라 말한다. 테마란 내가 알고자 하는 것이며 장르란 알고자 하는 것이 담긴 분야를 말한다. 저자는 테마가 메인이되고 장르를 서브로 두는 것이 효율적인 전략을 세우는 방법이라 말한다. 테마를 기반으로 여러 장르로부터 시사점과 통찰을 만들 수 있기 때문이다. 따라서 결론적으로 독학의 목표는 테마로 두어 알고자하는 것에 포커스를 맞추는 것이다.
《인풋》
인풋의 방법은 여러가지가 있었다. 그 중 3가지만 말하자면, 첫 번째론 독서 시 의식적인 목적 상기가 필요하다 말한다. 독서를 통해 무엇을 할 것인가? 무엇을 성취하고자 하는가? 지적 전투력을 상승시킬 것인가? 아니면 오락이 목적인가?와 같이 자신의 독서 목적을 상기시키면 자신이 원하는 테마에 대한 민감도가 높아져 효율적인 학습이 될 수 있다 말한다. 두 번째론 단기적인 시각으로 인풋해도 충분하다는 것이다. 커리어나 미래는 예측불가능하기 때문에 오히려 역산하여 어떤 것을 인풋할지 결정하는 것은 우연성이 낮아지고 위험성이 높아질 수 있다 말한다. 그렇기 때문에 지금 당장 도움 되는 재밌는 것을 고르라 말한다. 세 번째는 목적없이 인풋하는 것이 중요하다 말한다. 지금 당장 아웃풋을 많이 내는 사람은 살면서 절대적인 인풋의 시기가 존재했다는 것이다. 나중에 아웃풋하려면 인풋에 드는 기회비용이 많이 들기 때문에 타인이 아웃풋을 요구하지 않은 시기에 많은 것을 인풋하는 것이 중요하다고 한다.
《추상화 및 구조화》 추상화란 핵심만 뽑아내는 것이다. 다르게 말해 모델링을 하는 것이다. 추상화는 경험이나 지식으로부터 배운 것을 범용적으로 적용할 수 있는 상위의 통찰을 만드는 것이다. 어떠한 경험과 지식을 가지고 추상화를 하면 하나의 가설을 만들 수 있는데 이 가설의 진실여부는 중요하지 않다고 말한다. 계속해서 배운지식과 추상화로 얻은 가설을 함께 축적하는 습관을 가지는 것이 중요하다 말한다. 셜록홈즈가 남과 동일한 정보를 가지지만, 가설과 추리를 통해 기막힌 결과를 내는 것과 같이 말이다. 추상화를 비유로 들자면 수학에서 명제가 공리계에 닿을 때까지 만드는 것이다. 반대로 구조화는 공리계에서 명제를 도출하는 것이라 할 수 있다.
《축적》 축적에서 중요한 것은 기억에 의지하지 않는 것이다. 대부분 지극히 평범한 기억력이기 때문에 키워드나 컨셉만 자신만의 공간에 만들어두고 필요에 따라 검색할 수 있도록만 만들어도 충분하다는 것이다. 이를 위해 반복의 중요성을 말한다. 초독 때는 밑줄긋기를 통해 흥미로운 사실, 통찰/시사, 행동지침 등을 표시해두어야 하며, 재독때는 밑줄 쳤던 5~9줄 내의 중요 부분을 뽑아내고 우선순위를 정해야 하며 삼독때는 추후 참조 가능하도록 옮겨적어야 한다고 말한다.
실제로 이 책에서 설명하는 학습법을 사용했더니, 전공과는 무관하면서 내가 알고자 했던 테마인 신약 개발의 한 연구분야를 이해하고 한 시간 가량 설명할 수 있게 되었다. 무언가를 많이 배우고자 하는 사람들이나 빠르게 배우고자 하는 사람들이 있다면 일독을 권한다.
“첩보 기관이 입수하는 정보의 대부분은 우리 일반인도 접촉 가능한 정보다. 즉, 첩보 기관은 인풋된 정보의 양과 질보다도 모은 정보로부터 고도의 통찰을 얻어내는 능력에서 우월함을 가진 것이다.” - 야마구치 슈
비약적인 기술 발전으로 인해 미래 인류가 겪을 한 사회를 배경으로 한다. 어쩌면 인류들이라 표현할 수 있겠다. 인간과 더 이상 구분할 수 없을 정도로 정교하게 만들어진 휴머노이드와 인간의 공존을 그렸기 때문이다. 이 책은 내게 많은 흥미로운 키워드와 내용이 있었다. 강인공지능, 뇌 업로드, 영생, 순수의식, 우주정신, 노자사상, 불교사상 등이었다.
이들은 내게 몇 가지 생각을 가져다 주었는데 그 중 첫 번째는 영생에 대한 치우친 편향의 평형을 가져왔다. 의식을 업로드하여 영원히 살아가는 미래 인류들이 겪는 끝 없는 지루함과, 결국 죽음을 선택하는 모습을 엿보게 되면서, 어쩌면 죽지 못하는 것이 더욱 고통이란 생각이 들었다. 두 번째는 현재 사회와 미래 사회 간의 간극을 통해 나라는 존재는 무엇을 하며 살아가야 할까에 대한 방향성을 조율할 수 있게 됐다. 내가 살아있는 동안은 뇌공학, 생물학, 물리학, 나노공학, 인공지능과 같은 과학기술의 비선형적인 발전이 있을 것이라 생각했다. 그래서 공상과학을 구현해보고 싶고, 그런 삶을 살아갈 수 있다면 어떨까 하는 상상도 했다. 하지만 이 책을 읽으며 어쩌면 그런 특이점은 생각보다 늦은 시기에 도래할 것 같단 생각도 들며, 한 걸음 물러서 다시 삶을 바라보게 됐다. 마지막으로 인류애를 생각하게 되었다. 등장 인물 간의 대화를 통해, 우주라는 시공간 속에 찰나의 순간에 개별적인 의식을 갖고 살아가는 것은 엄청난 행운이라 말한다. 그렇기에 이 짧은 찰나의 생을 통해 조금이라도 더 나은 존재가 되도록 분투하고, 우주의 원리를 깊이 깨우치려 애써야 한다는 인상 깊은 대목이 있었기 때문이다.
나는 내 삶의 존재의의와 방향성을 생각하게 만드는 것을 좋아한다. 이 책이 그런 책이다. 평소에 소설을 주로 편식하는데, 이 책으로 인해 조금씩 더 먹어보고 싶은 호기심이 생긴 계기가 되었다. 마지막으론 내 삶의 존재의의와 방향성과 같은 끝없는 스스로의 사색과 사유가 필요한 문제에 대해 책에 의존하는 나의 정신적 빈곤함을 반성한다.
“인간은 과거와 현재, 미래라는 관념을 만들고 거기 집착합니다. 그래서 인간들은 늘 불행한 것입니다. 그들은 자아라는 것을 가지고 있고, 그 자아는 늘 과거를 후회하고 미래를 두려워할 뿐 유일한 실재인 현재는 그냥 흘려보내기 때문입니다.” - 책 속에서
스타트업에 관심있고 시작하려는 초심자들에게 유용한 현실적인 지침이 담긴 책이다. 책이 가벼우면서도 심플하며 핵심만 담아서 이해하기도 쉽다. 목차만 읽어도 말하고자 하는 핵심이 다 담겨있다. 저자는 다년간 스타트업을 운영하며 피보팅하고 리브랜딩하며 겨우겨우 정글에서 살아남은 경험을 담았다. 경험으로부터 쌓인 많은 지침이 있었지만 가장 핵심은 좋은 서비스를 만드는 것이라 생각한다. 몇몇 이외의 조언은 직원 채용은 최대한 보수적으로 하고, 혼자서도 할 수 있다는 신념으로 해야하며, 끊임없이 서비스에 대해 생각하고, 투자와 같은 치트키 말고 고객만족에 집중하며, 기획은 오래걸려도 좋으니 치밀하게 준비하고 반드시 대표가 함께하라는 것이다. 그리고 고통스럽더라도 끝끝내 존버하면 성공한다는 이야기다. 이 책의 내용을 모두 하나로 엮는 또 다른 핵심이 있다면 반드시 망한 스타트업을 분석하여 반면교사 삼아 같은 실패를 되풀이 하지않는 것일 것이다.
모든 것을 주어도 아깝지 않은 조건없는 사랑이다. 본능적인 사랑과는 구분되며, 헌신과 희생이 함께한다. 저자는 사랑이 결여된 세상에 깊은 통감을 드러낸다. 아가페와 같은 이상적인 사랑은 인격과 성품이 준비되어야 가능하다 말한다. 하지만 우리는 자라며 부모와 타인으로부터 아가페적인 사랑을 경험해보지 못했기에 우리 삶에 진정한 사랑이 결핍된다 말한다. 이렇게 자라난 우리는 이후 배운대로, 경험한대로 자녀와 타인을 대하기에 스스로 갖추지 못한 인격적인 부분이 고스란히 전달된다는 것이다. 때문에 다음 세대를 위한 따뜻한 공동체를 물려주기 위해서라도 진정한 사랑을 받을 줄 알고, 할 줄 아는 인격과 성품을 갖추는 것이 중요하고 필요하다 말한다.
책의 전반적인 내용은 사랑이라는 이면에 채색된 차가움인, 가정에서 이뤄지는 무관심, 폭행, 이혼 그리고 세상이 스스로의 존속을 위해 개인에게 부여한 이념, 사상과, 자신의 이익을 위해 한 개인과 가정을 갈라 놓는 종교에 대해 다룬다. 사랑이 아닌 경제력과 안정감을 위한 결혼을 하는 사람들, 경제력이 인권이자 생명인 시대에서 이혼하고 싶어도 능력이 없어 아픔 이상의 비극을 겪는 사람들, 부모의 건강과 재산문제로 갈라진 사람 등의 사회의 차가운 측면이다.
이 책을 읽으며 두 가지를 알게 되었다. 사랑을 알기 위해서는 결핍과 부재를 아는 것이 더 와닿는다는 것이며, 내가 차가운 사람이었다는 것이다. 나는 단 한번도 ‘사랑'에 대해 사유하거나 고찰하려하지 않았다. 우리 삶에서 흔히 들을 수 있었고, 필요성을 느끼지 못했으며, 어쩌면 받는 사랑이 부족하지 않기에 그랬던 것 같다. 따뜻함이 있어야 상대적인 차가움을 느낄 수 있을 것인데 내가 차갑기 때문에 차가움을 느끼지 못했다. 이는 저자가 세상을 향해 느끼는 차가움이 곧 세상을 바라보는 따뜻한 마음을 가졌음을 의미한다는 생각이 들었기 때문에 알게 되었다.
이 책을 처음 접했을 때 마음의 공감과 위로의 역할을 하는 줄 알았지만 그렇지 않았다. “사랑”이라는 주제를 다루기 위해 철학과 신학과 역사를 포함한 다양한 관점으로 접근해 인간 존재의 본질을 고찰한다. 우리 인간은 우주 속에서 어떠한 존재이며 어떤 의미를 갖는가? 우리 인간은 무엇을 위해 그리고 어딜 향해 나아가는가? 신이란 무엇인가? 종교는 왜 만들어졌는가? 우리 인간의 본능은 어딜 향하는가? 과연 신비는 존재하는가?와 같은 질문 사이에서 사랑이란 무엇이고 어떤 의미를 갖는지 살펴볼 수 있었다는 것은 소중한 기회가 되었다.
저자는 말한다. 개인의 가치관을 형성하는데 사랑이 필수적인 요소이기에 깊이 사유해보는 것이 필요하다고. 사람들을 조건 없이, 내안의 가치 판단 없이, 분별 없이 사랑하며 살아가고 싶은 마음이 있던 내게 그 마음을 다시 비춰볼 수 있는 계기가 되었다. 우리가 삶에게 묻는 질문에 대한 하나의 귀결점이 되는 사랑에 대해 알고자 하는 사람들에게 일독을 권한다. 부모를 앞두고, 자녀교육에 관심이 있는 사람에게도 좋을 것이다.
마음에 남는 한 대목
생명을 살리고 인권을 수호하여 역사를 올바른 방향으로 바꾸는 위대한 일들도 인간이 할 수 있는 가치 있는 일이지만 이런 일들을 자신의 모든 것을 바쳐서 하는 이유는 더 많은 사람이 행복하게 살기를 바라는 마음이 아니겠는가.
신약개발에서 진행되는 연구 중 MHC(Major Histocompatibility Complex, 주조직 적합성 복합체)와 펩티드(peptide)의 결합 친화도(binding affinity)를 예측하는 연구 분야가 있다. 먼저 MHC 같은 경우는 면역 반응에 관여하는 당단백질로, 대표적으로 백혈구(HLA, Human Leukocyte Antigen)가 있다. 펩티드의 경우 단백질과 동일하게 아미노산으로 구성되지만 단백질을 결정짓는 3차원 얼개가 없는 것이 가장 큰 차이점이다. 그렇다면 MHC-peptide의 binding affinity 예측은 왜 중요할까? 이는 MHC와 펩티드 간 상호작용하는 그 기전에 답이 있다. 결론은 향후 신약을 만들었을 때의 우리 몸의 면역 반응을 판단하기 위함이다.
MHC-peptide 면역학적 상호작용
MHC는 항원으로부터 떨어져 나온 펩티드 조각을 인식하는 능력을 갖고 있다. MHC는 세포표면에 자신이 만든 그루브에 펩티드 조각을 꽂아두면 면역 반응에 관여하는 T 세포가 와서 T 세포 수용체로 면역원(펩티드)을 인식하고, 만약 악성이라 판단될 경우 항체를 만들라는 면역 반응을 일으키게 된다. 하지만 이와 같은 기전이 일어나기 위해서는 MHC와 펩타이드 둘 간의 충분한 binding affinity로 결합이 되어야만 T 세포가 활성화 될 수 있다. 그렇기에 binding affinity를 예측하는 것은 이러한 면역학적인 과정을 이해하는 데 한 걸음 나아가는 것과 같고, 향후 신약 개발에 있어 후보 물질이 될 수 있는 펩티드를 스크리닝하는 데 많은 도움이 된다.
펩티드의 장점과 단점
참고로 펩티드 의약품은 분자 구조상 독성 문제가 적고, 조직 내 축적량이 적어 신약 후보물질로 주목 받는다. 하지만 체내에서 쉽게 분해된다는 단점이 있어 체내 안정성 확보가 어렵고, 이러한 펩티드 후보 물질을 탐색하는 시간이 오래걸린다는 문제가 존재한다.
MHC-peptide binding affinity 예측 연구의 과거와 현재
연구의 흐름은 in-vitro 방식에서 in-silico 방식으로 바뀌었다. 과거에는 일일이 MHC-peptide의 binding affinity를 계산했다. 하지만 이는 수많은 시간과 자원이 소모되었는데 그 이유는 MHC의 특성상 매우 큰 다형성(polymorphism)을 가졌기 때문이다. 다형성으로 인해 MHC와 펩타이드 시퀀스 간의 여러 경우의 수를 다 고려할 수 없었고, 따라서 computational 접근으로 나아가게 되었다. 이 computational 접근이 in-silico 방식의 또 다른 이름이다. in-silico 방식으로 나아갈 수 있게 된 배경은 in-vitro 방식을 통해 MHC-peptide의 binding affinity에 대한 데이터가 쌓였고, 아래와 같은 데이터셋이 축적되며 가능해졌다.
위와 같은 데이터셋들은 MHC-peptide binding affinity에 관한 아래의 주요 데이터베이스들에 모이게 되었다.
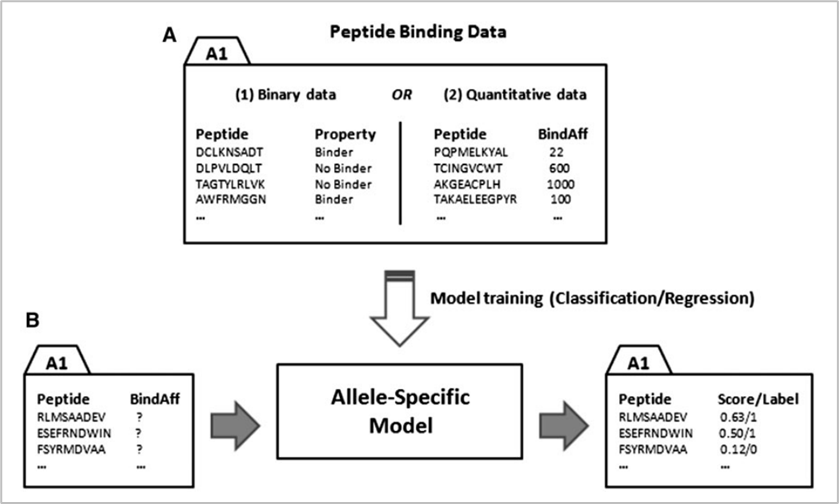
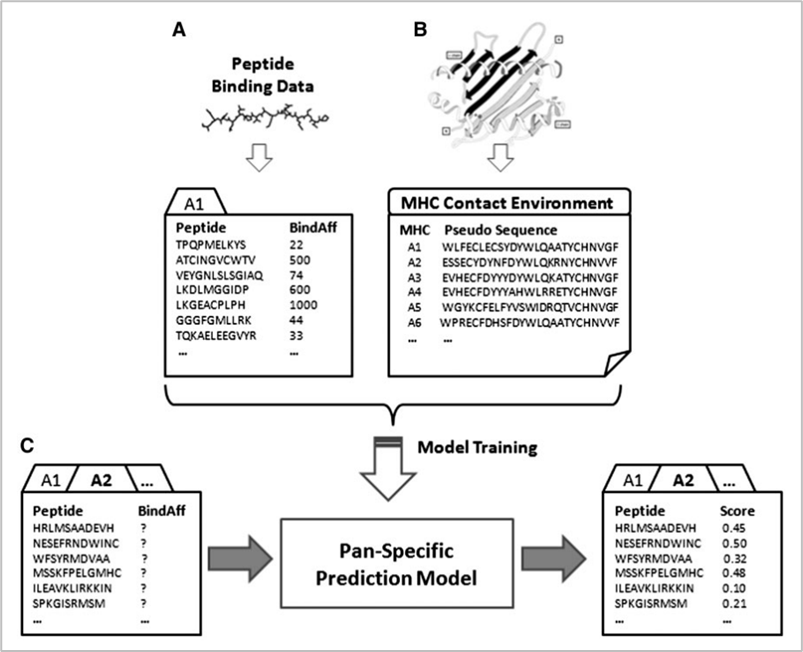
참고로 현재에도 대표적으로 가장 많이 사용되는 데이터베이스는 IEDB이다. in-silico 방식에는 위의 데이터베이스를 활용하는 크게 두 가지 방법이 있다. 첫 번째는 allele-specific 방법이고, 두 번째는 pan-specific 방법이다. 참고로 allele란 대립유전자를 의미하는 것으로 지금의 문맥에서는 인간의 MHC인 HLA를 의미한다. 아래는 두 방식에 대한 그림이다.
allele-specific 방법pan-specific 방법
두 방식의 공통점은 머신러닝 모델을 만들어 예측하는 것이다. 핵심 차이점은 allele-specific은 하나의 allele당 하나의 모델을 만들어야 하는 반면 pan-specific 방법은 하나의 모델에 여러 allele를 학습시킬 수 있다. 때문에 allele-specific 방법은 범용성은 약하지만 특정 allele와 peptide가 어떤 binding affinity로 결합할지에 대해 pan-specific에 비해 비교적 더 정확하게 예측할 수 있다는 장점이 있다. 반면 pan-specific 모델은 특정한 allele와 peptide의 binding affinity 예측에는 약하지만, 전반적으로 일반화된 성능을 낼 수 있다는 것이 장점이다.
하지만 최근에는 증가하는 데이터셋과 머신러닝 모델 구조로 인해 allele-specific 모델보다 pan-specific 방식이 더 많은 각광을 받는 추세이며, 나아가 pan-specific 모델에 transfer learning을 적용함으로써 allele-specific 모델의 장점을 함께 취하는 방식도 사용되고 있다.
MHC-peptide binding affinity 예측 도구
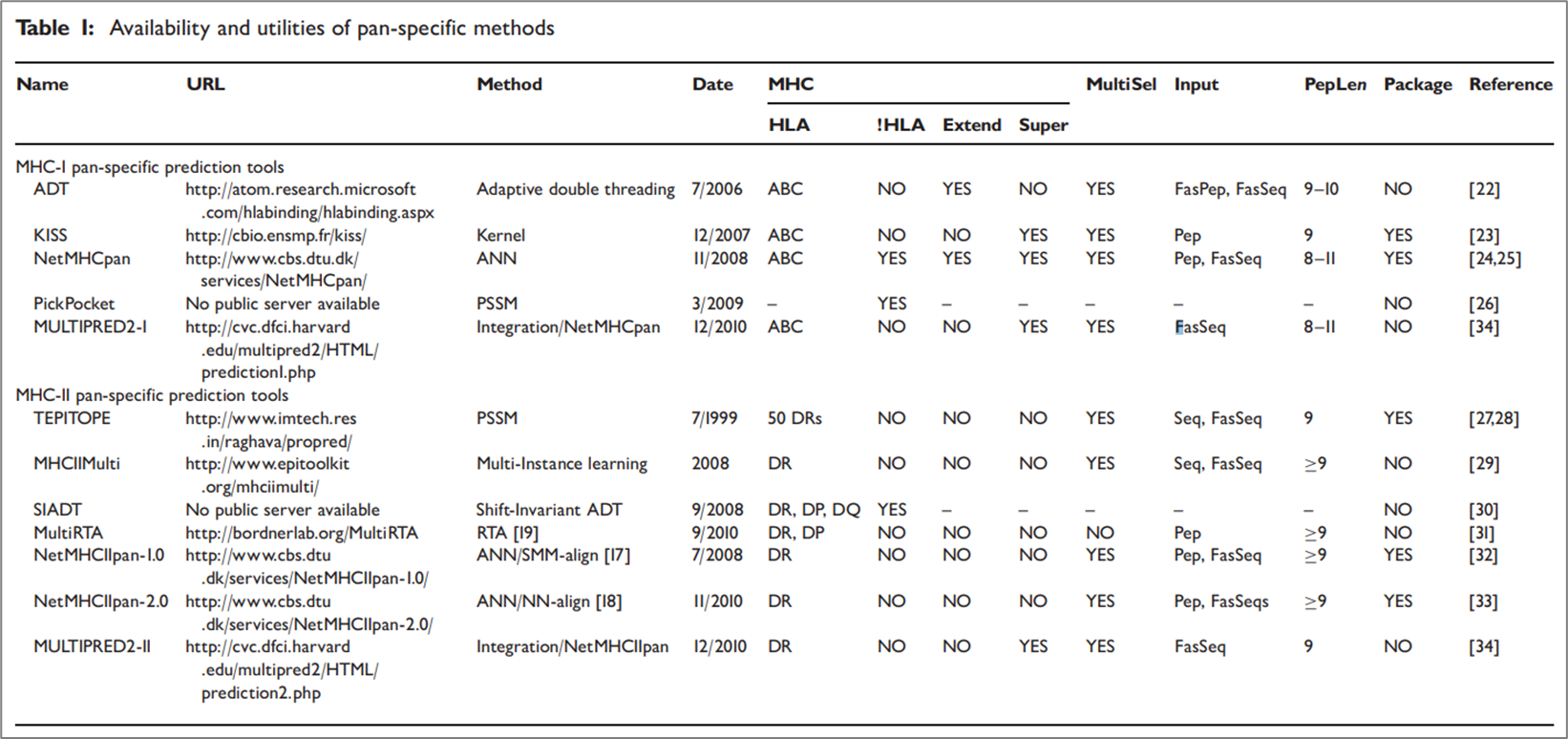
MHC-peptide binding affinity를 예측 하는 도구들은 1990년대 말 이후 지금까지도 관련 연구자들에 의해 만들어지고 있다. 아래는 2011년 기준으로 사용되고 있는 pan-specific 모델을 정리한 표이다.
참고로 MHC는 크게 3가지 클래스가 존재한다 MHC-I, MHC-II, MHC-III이다. 하지만 연구는 주로 MHC-I과 MHC-II를 기준으로 이루어진다. 위 그림을 크게 MHC-I pan-specific 예측 모델과 MHC-II pan-specific 예측 모델로 나눌 수 있는데, MHC-I에는 버전이 업그레이드되어 지금도 좋은 성능을 보이고 있는 NetMHCPan이 대표적이라 할 수 있다. 현재에는 더 발전하여 이외에도 ACME, DeepSeqPan, DeepAttentionPan, 등의 모델이 있다. MHC-II 같은 경우도 마찬가지로 NetMHCIIpan 모델이 대표적이라 할 수 있고 현재에는 더 발전하여 이외의 모델들이 여럿 존재한다.
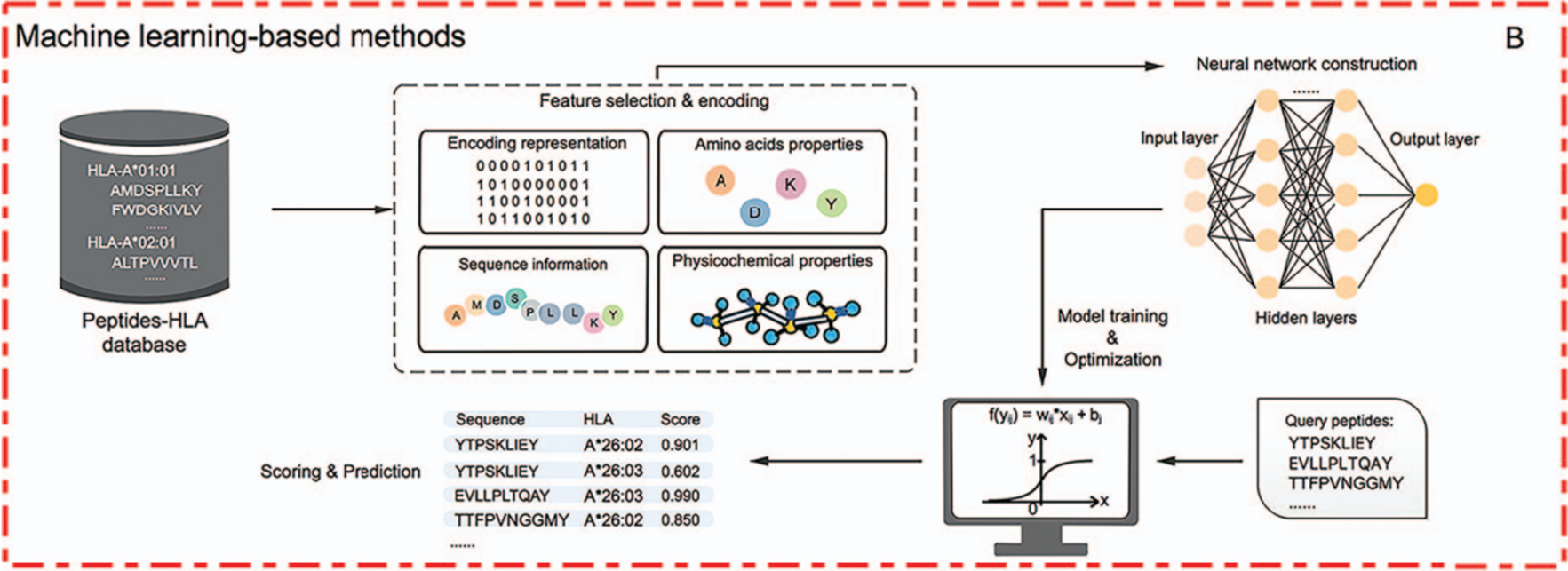
MHC-펩티드 피처화 방안 & 머신러닝 모델 종류
allele-specific 모델과 pan-specific 모델은 학습을 위해 MHC와 펩티드를 피처화 시키는 과정이 중요하다. 머신러닝을 사용하지 않고 계산했던 과거에는 Scoring Matrix를 사용했고 동작은 다음과 같다.
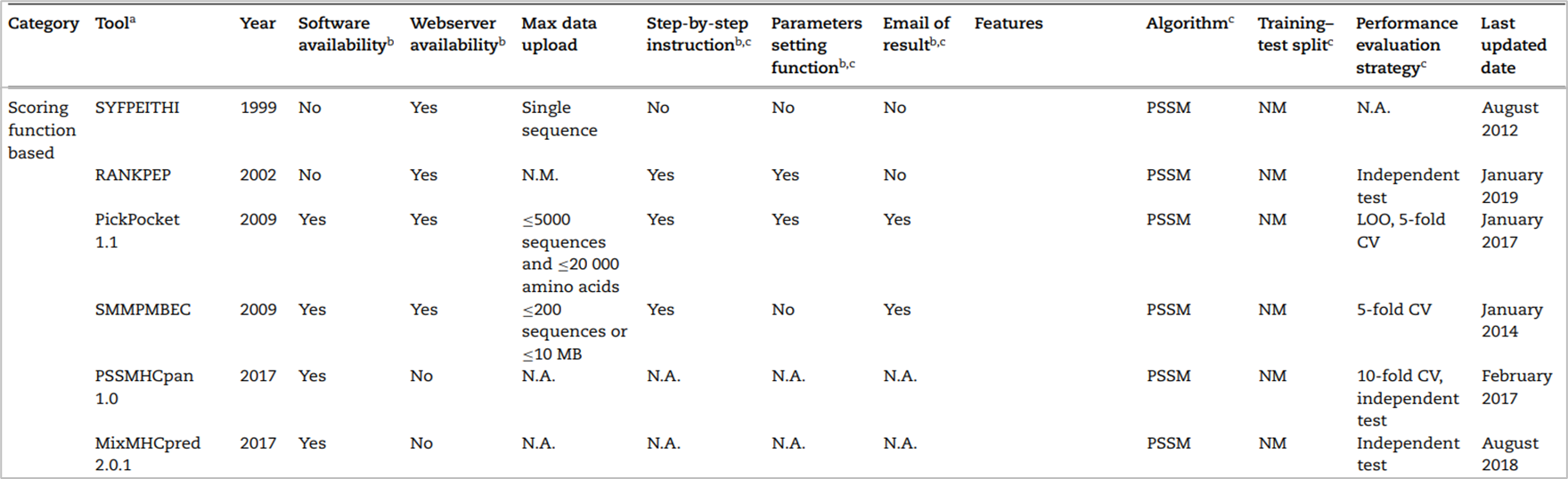
축적된 MHC-peptide에 대한 데이터를 기반으로 BLOSUM62와 PSSM이라는 대표적인 scoring matrix를 사용했다. 이는 펩티드의 motifs를 찾으려는 시도로, motifs는 특징이 보존된 짧은 펩티드 서열을 의미한다. scoring matrix를 만들기 위해 펩티드의 물리 화학적인 특성이나 한 아미노산에서 다음 아미노산으로 어느 정도의 빈도로 바뀌는가 또는 시퀀스의 유사도를 계산한 값을 반영한 matrix라 할 수 있다. 이를 통해 최종적으로 MHC(HLA)와 펩티드 시퀀스가 어느 정도의 binding affinity로 결합할 것인지 예측하는 것이다. 2019년 기준 대표적인 도구 리스트는 다음과 같다.
하지만 이 방법에도 단점이 있었으니, 정적인 scoring matrix를 통해서는 문제를 선형적으로 풀 수 있을 뿐 동적이고 비선형적으로 풀기 어렵다는 것이다. 이러한 한계점으로 인해 머신러닝 기반의 방법이 사용되었다.
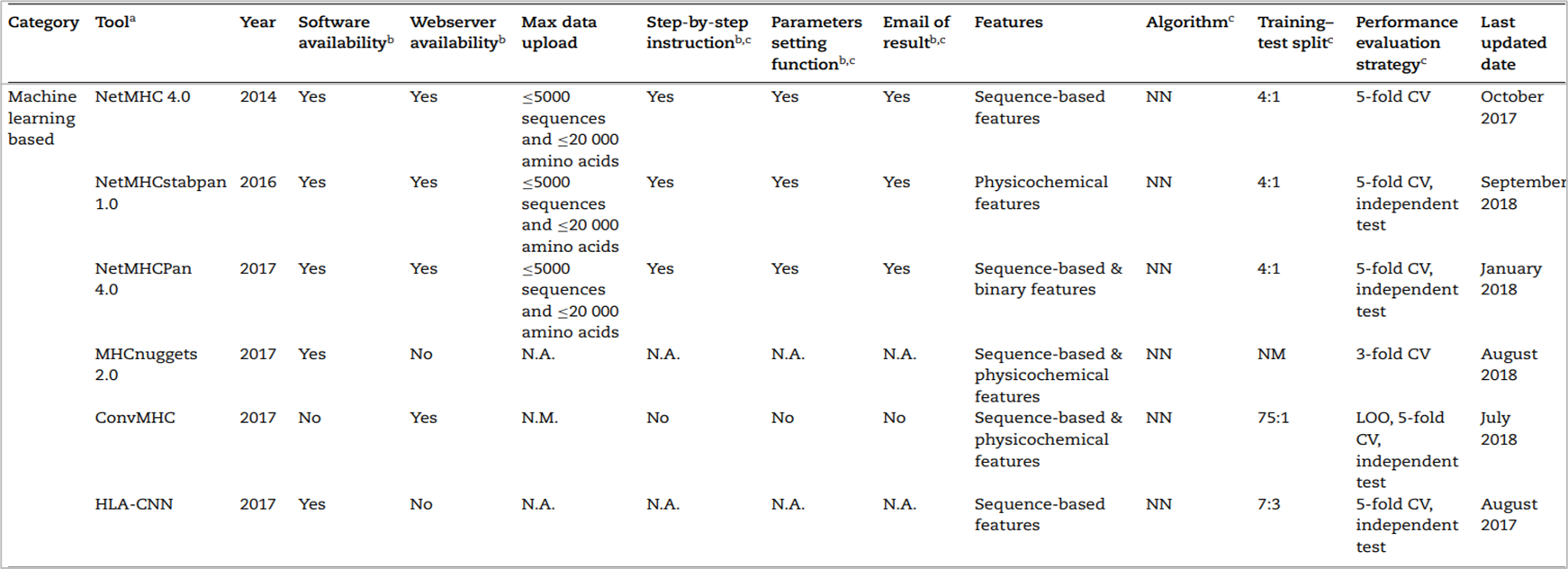
기존 scoring function 기반 방법과의 차이점은 뉴럴넷에 학습을 시킨다는 것이다. 하지만 동일한 것은 여전히 피처화 시키는데 있어서 BLOSUM62와 PSSM, one-hot encoding과 같은 방법을 사용한다. 데이터셋으로는 in-vitro 방식 또는 이전 연구들에서 binding affinity가 실험적으로 검증된 것을 사용하며 결과적으로 펩티드를 binder 또는 non-binder로 분류하는 것이 특징이다. 2019년 기준 대표적인 도구리스트는 다음과 같다.
그 중 가장 대표적인 모델은 NetMHCPan4.0이 있고, 후속 연구들에서 비교 대상으로 자주 사용된다.
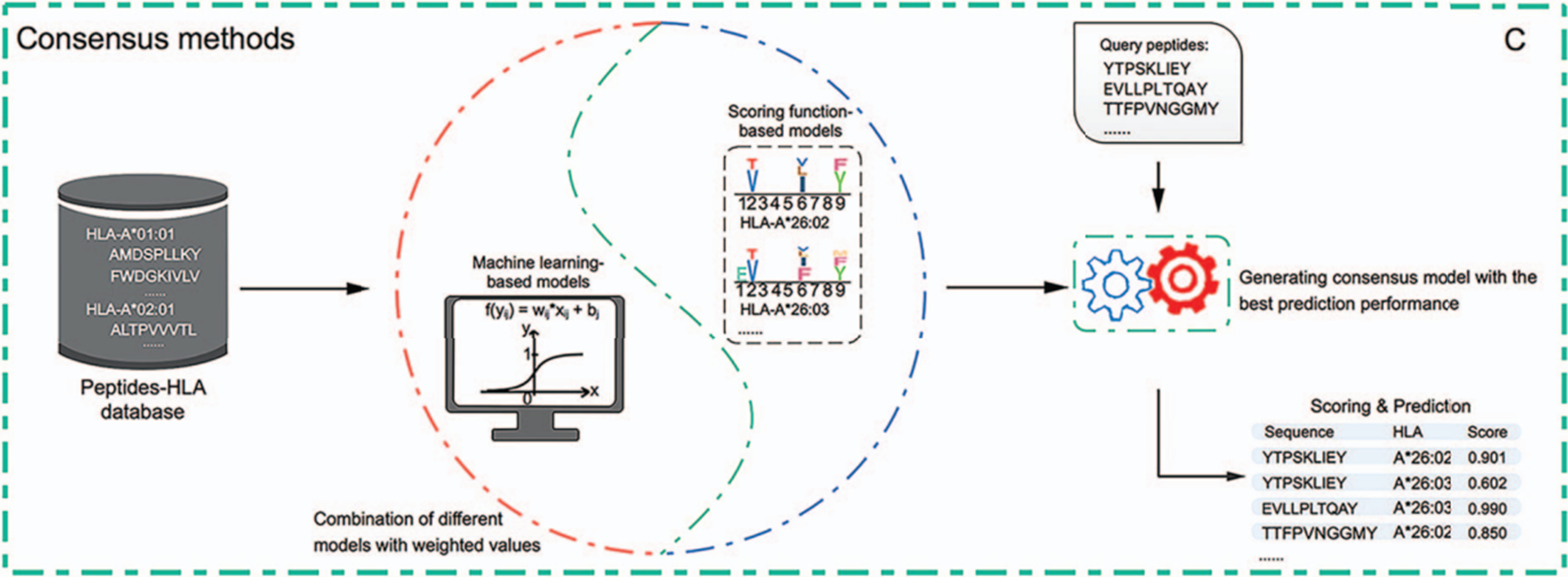
마지막으로는 consensus 방식으로 scoring function 기반 방법과 machine learning 기반 방법을 결합한 것이다.
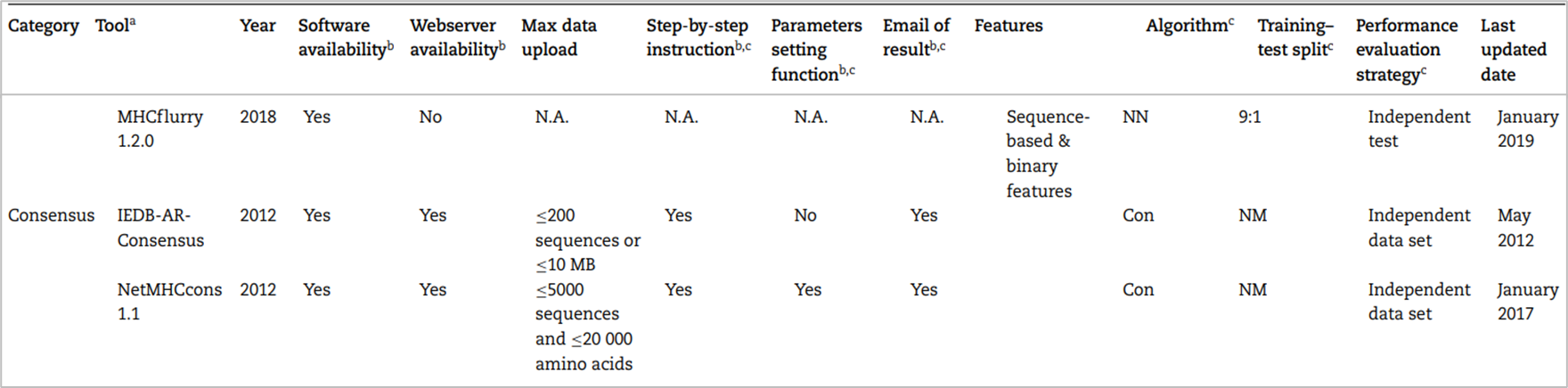
정확히는 scoring function 기반의 모델과 machine learning 기반의 모델의 출력값에 가중치를 부여하여 앙상블하는 방법이다. 예를 들면 가장 믿을 만한 모델의 예측 값에는 N점, 조금 낮은 모델의 예측 값에는 N-1점, ...을 부여하여 가중합을 매기고 평균을 구하는 것이다. 패러다임 시프트가 없는 이상 위와 같은 방법이 계속 사용될 것으로 전망된다. 2019년 기준 대표적인 도구 리스트는 다음과 같다.
가장 최근에 나온 MHCflurry1.2.0이 가장 대표적인 도구일 것이다.
여기까지 신약개발의 연구 분야 중 하나인 MHC-peptide binding affinity prediction의 연구 동향을 살펴보았다. 이 연구 분야에 대해 알아볼 때 생각보다 국내 자료가 많이 없어 빠른 파악이 힘들기도 했기에 관련 연구를 지향하는 사람들에게 작은 도움이 되었으면 한다.
Reference
[1] Toward more accurate pan-specific MHC-peptide binding prediction: a review of current methods and tools
[2] A comprehensive review and performance evaluation of bioinformatics tools for HLA class I peptide-binding prediction
이 책의 핵심은 지금 우리 사회에 만연한 통념인, 각자 노력과 기량을 통해 성취하며 사는 것이 옳다는 능력주의가 민주주의를 훼손하고 또 다른 계층을 만들어 낸다는 것이다. 본래 능력에 따라 부를 성취해야 한다는 능력주의는, 단지 귀족과 재벌의 자식이라는 이유로 부의 세습 받아 계층을 유지하는 부유층의 특권을 폐지하기 위해 주창되었다. 하지만 이러한 능력주의는 결과적으로 경제적 불평등과 정치적 불평등을 야기시키게 되었다. 세습되는 자본의 형태가 금융자본과 물적자본 대신 인적자본으로 대체되었을 뿐, 본질적으로 기존의 귀족, 재벌과 다를 것이 없다는 것이다. 많은 부를 쌓은 부유층은 교육에 수 많은 자본을 쏟으며 중산층, 빈곤층과 비교되지 않을 만큼, 학업 성취도를 양극화시켰다.
하지만 비단 학업에서 뿐만 양극화되는 것이 아니다. 직업과 직장에 있어서도 양극화를 초래한다. 학업 성취도를 말미암아 고도의 전문직을 지향하는 엘리트들은 의료, 금융, 경영, 법조계와 같은 몇 안되는 고소득 직종에 종사하며 막대한 수익을 벌어들인다. 실례로 이 책에서는 경영인, 금융인, 법조인이 여가 없이 자기를 가혹히 학대할만큼의 업무를 지향하며 중산층, 빈곤층과 비교 되지 않을 만큼의 소득을 벌어들임을 짚는다. 하지만 이러한 막대한 소득을 올리는 엘리트들은 다시 정치로 나아가 정치인들에게 자신에게 유리한 세금, 규제 회피와 같은 정책을 개편함으로써 정치적 불평등을 야기시키며 심지어는 정당화한다. 즉, 부를 통해 국가에 저항할 힘을 갖는 것이며, 이를 통해 민주주의가 훼손되는 것이다.
저자는 이를 해결하기 위한 방안을 두 가지 제시한다. 핵심은 세금 관련 규제라는 소실점을 통해 첫 번째, 현재 엘리트에 집중된 교육을 더욱 개방하고 분산화시키는 것이며 두 번째, 엘리트 근로 계층에게 집중된 생산이 중산층에게 골고루 분산되어야 한다는 것이다. 200년이라는 여러 세대에 걸쳐 만들어진 능력주의인만큼 저자는 해체를 위해서도 여러 세대가 걸릴 것이라 말한다. 하지만 뿌리 깊은 능력주의의 불평등을 뽑으려는 시도를 통해 이 사회의 진정한 진보가 가능할 것이다.
"능력주의는 개인의 기량과 노력이 부족하고 기준에 미달한다는 말로 정당화한다" - 대니얼 마코비츠
20년간 쓰인 이 책은 신랄한 어휘와 계층에 따른 생활양식의 차이를 말하며 우리 사회를 적나라게 드러낸다. 그 과정에서 보인 저자의 수준 높은 추상사고를 엿볼 수 있었던 것이 이 책에서 가장 좋았던 점이다.
우리 몸을 구성하고 생명활동을 움직이게 하는 단백질은 과연 어떻게 만들어질까? 단백질은 본질적으로 아미노산으로 구성된다. 아미노산이 짧은 수로 모이게 되면 펩타이드(Peptide)라 부르며, 많은 수가 모이면 단백질이라 부른다. 그렇다면 이 아미노산은 어떻게 만들어지게 될까? 생물학에서는 아미노산으로부터 단백질이 만들어지는 과정 전체를 센트럴도그마라고 부른다. 센트럴도그마는 크게 전사(Transcription)와 번역(Translation)의 두 과정으로 이루어진다. 전사와 번역을 알기 위해서는 먼저 DNA와 RNA를 알아야 한다. 먼저 요약하면 DNA는 단백질을 만들기 위한 설계도이며, RNA는 설계도를 기반으로 단백질 제조 역할을 한다. DNA는 개념적으로 디옥시리보핵산(DeoxyriboNucleic Acid)를 의미하는 것으로, 원핵 생물과 진핵 생물의 세포에 공통적으로 존재한다. RNA는 리보핵산(RiboNucleic Acid)를 의미하는 것으로 RNA에서 산소 원자가 하나 빠진 것(De-oxy)이 DNA이다.
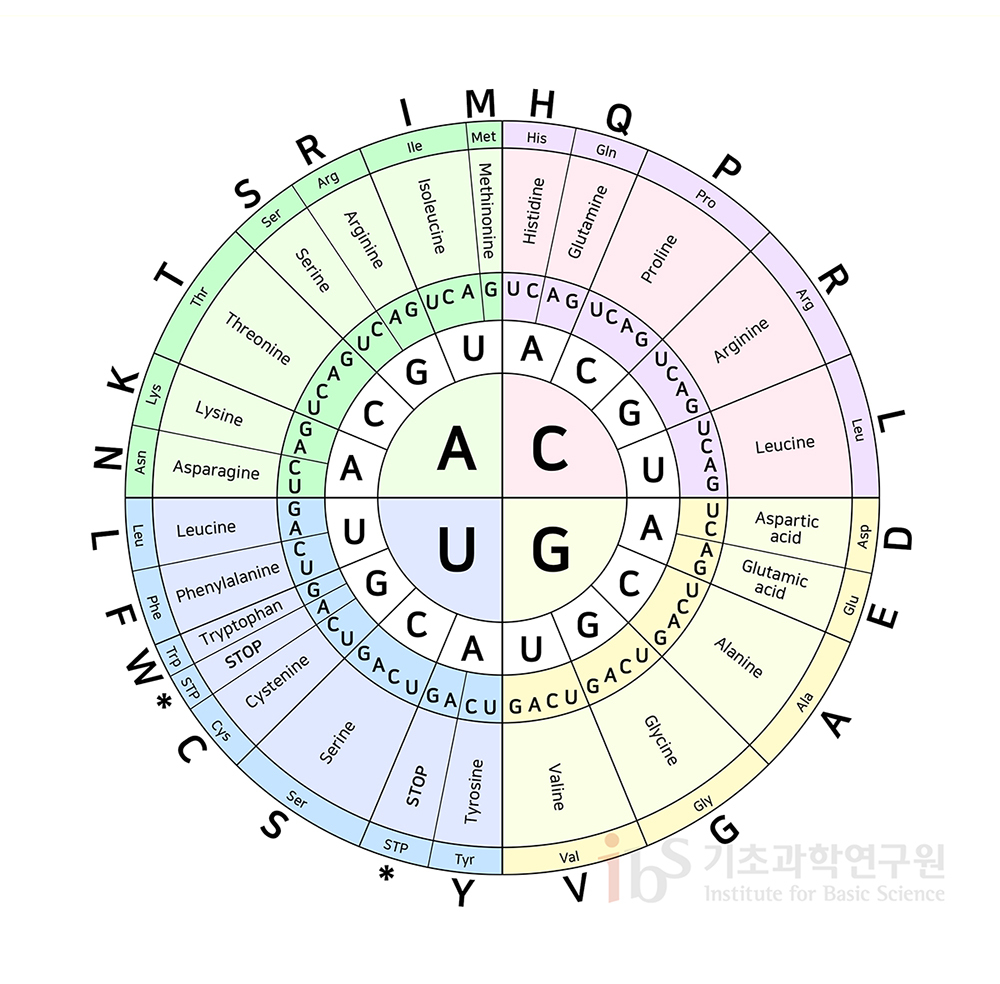
DNA의 구성요소는 크게 4가지로 ATCG(아데닌, 티아민, 사이토신, 구아닌)의 염기로 구성된다. 컴퓨터가 0과 1로 이루어진 2진수 체계이듯, 우리 몸은 ATCG라는 염기로 구성된 4진수 체계라고 할 수 있다. 2진수 체계인 지금의 컴퓨터로 무수한 것을 할 수 있듯, 4진수 체계인 우리 몸은 컴퓨터보다 더 큰 복잡성을 가진다. 이 복잡성은 4가지 염기의 결합에 의해 나타난다. 4가지 염기는 상호 결합이 정해져 있다. 가령 A는 T와 결합하고 C는 G와 결합하는 식이다. 이렇게 AT, TA, CG, GC로 결합한 염기쌍(base pair)들이 이어져 DNA 시퀀스가 된다. (참고로 RNA는 T대신 U(우라실)이 쓰인다.) 앞서 말했듯 DNA에는 어떤 단백질을 생성해야 할지에 대한 설계도를 가지고 있다 했다. 이 설계도는 DNA 시퀀스와 같다. DNA 시퀀스의 3개의 염기를 묶어 하나의 코돈(Codon)을 구성한다. 코돈은 우리 몸에 어떤 아미노산을 만들지 결정한다. 가령 AAA라는 3개의 염기가 모이면 라이신이라는 아미노산을 만들고, GCC라는 3개의 염기가 모이면 알라닌이라는 아미노산이 만들어진다. 인간의 몸에는 크게 20개의 아미노산이 있고 각각의 코돈들은 20개의 아미노산 중에 하나를 만들게 된다. 코돈이 어떤 아미노산으로 만들어질(부호화될)지는 유전 암호(부호)를 통해 확인할 수 있다. 아래는 기초과학연구원에서 가져온 유전 암호 표(?)이다.
참고로 다른 코돈이라도 같은 아미노산을 만들 수 있는 것이 특징이다. 여기서 중간 정리를 하자면, 전사(Transcription) 과정은 DNA 시퀀스에서 코돈이 될 3개의 염기를 읽어들이는 과정이다. 이 때 RNA가 관여하여 읽어 들이며, RNA가 3개의 염기 정보를 가지고 있으면 이를 mRNA (Messanger RNA)라 부른다. 전사 과정에서 만들어진 이 mRNA의 한 가닥은 인트론(Introns)과 엑손 영역(Exons)으로 나뉜다. 엑손은 단백질이 암호화된 영역이고 인트론은 비암호화된 영역이다. mRNA를 번역(Translation)에 사용하기 위해 비암호화된 영역인 인트론을 제거하고 5'cap과 3' poly-A tail라는 것을 추가한다. 그 다음 인접한 엑손끼리 결합하는데 이러한 과정을 대체 이어 맞추기(alternative splicing)이라고 한다. 이어 맞추기 과정은 큰 의미를 가진다. 그 이유는 mRNA에 담긴 일부 정보인 인트론을 제거한다는 것은 곧 원래의 DNA 서열과 달라질 수 있음을 의미하고 이는 하나의 DNA 서열이 실제로는 여러 단백질을 만들어낼 수 있다는 것을 의미한다.
다음으로 번역(Translation) 과정은 mRNA가 설계도를 가지고 단백질 제조공장인 리보솜에 가서 단백질을 주문하는 것이다. 제조 과정에는 rRNA와 tRNA가 관여한다. rRNA는 리보솜 RNA를 뜻하며, tRNA는 전달 RNA를 뜻한다. tRNA는 코돈을 인지하고 올바른 아미노산을 추가하는 역할을 하며, rRNA는 아미노산의 펩타이드 결합에 관여한다. 간단하게 기술하였지만 사실 조금 더 복잡한 기전이 이루어진다. 번역 과정에 사용되는 특별한 코돈이 있다. 번역 개시 코돈, 번역 종료 코돈이다. 번역은 mRNA의 개시 코돈에 리보솜 소단위체가 결합하며 시작한다. 이후 mRNA의 코돈 정보는 tRNA의 안티 코돈을 리보솜으로 운반한다. 여기서 안티코돈이란 mRNA의 코돈과 상보적인 결합을 이루는 염기쌍을 의미한다. tRNA의 안티코돈을 통해 아미노산이 리보솜으로 운반된다. 이러한 과정을 반복하여 아미노산들이 차례차례 연결되면서 단백질 합성 과정이 이루어진다. 마지막으로 tRNA가 mRNA의 번역 종료 코돈과 결합하면 아미노산 중합 반응이 끝이 난다. 이후 만들어진 단백질은 세포 내 기관인 소포체안으로 들어가고, 골지체를 통과하며, 분비 소낭을 통해 세포막을 통과한 뒤 필요로 하는 곳에 분비된다. 이렇게 만들어진 단백질은 소화 과정에서 음식을 분해하여 에너지를 얻는 대사과정과 같이 신체 대부분의 생리 기능이 발휘하기 위해 사용된다.
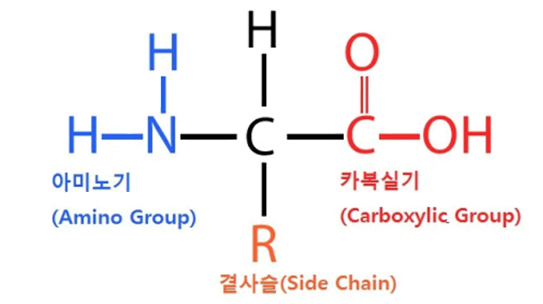
아미노산이란 단백질을 구성하는 요소이다. 아미노산들이 적은 개수로 결합되면 이를 펩타이드(peptide) 또는 펩티드라 부르며 많은 수가 결합되면 이를 단백질이라 부른다. 이러한 아미노산은 DNA에 포함된 유전자를 RNA가 전사하고 번역하는 과정에서 만들어진 코돈에 따라 어떤 아미노산으로 만들어질지(encoding) 결정된다. 아래는 아미노산의 구조를 나타낸다.
아미노산 구조 (왼쪽 = 오른쪽)
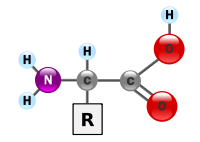
아미노산은 탄소 원자를 중심으로 크게 3부분으로 아미노기(NH2), 카복실기(COOH), 곁사슬로 구성된다. 자연계에는 300 종류의 아미노산이 있지만 포유류에게 미치는 아미노산은 20종류가 된다. 포유류인 인간에게 영향을 미치는 20종류 의 아미노산 중 19가지가 위의 구조를 따른다. 단지 나머지 아미노산인 프롤린(proline)만이 이를 따르지 않는다는 특징을 가진다. 결과적으로 아미노산의 종류를 결정 짓는 것은 곁사슬 R에 어떠한 것이 결합되느냐에 따라 아미노산의 종류가 결정된다. 한 가지 특이한 점은 아미노기와 카복실기는 산과 염기의 세기를 나타내는 pH에 따라 NH3+의 형태나 COO-로 이온화되어 존재할 수도 있다는 특징을 가진다.
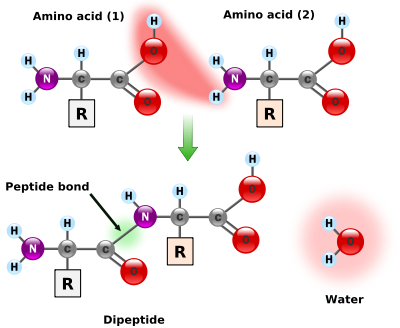
펩타이드 결합
펩타이드의 정의를 다시 짚고 넘어가자면 아미노산 중합체로서, 아미노산이 여러 개 합쳐진 것이라 할 수 있다.
펩타이드의 결합은 한 마디로 탈수축합반응이라 할 수 있다. 그 이유는 위의 그림과 같이 아미노산에 붙은 카복실기(COOH)와 아미노기(NH2)에서 각각 OH와 H가 빠져나오면서 아미노산 간의 결합이 이루어지는데 각각 빠져나온 것을 결합하면 물 분자인 H2O가 되기 때문이다.
생명공학에 관심을 갖게 되면서 기본적인 면역학이나 생화학, 유기화학 등을 학습할 필요가 있다 판단이 되었습니다. 면역학 서적을 구매해보니 양이 방대해서 정독까지는 시간이 걸릴 것 같고 필요한 부분만 발췌해서 학습하려합니다. 다만 도중에 빼곡히 적힌 지식들에 의해 좌절하는 날이 오지 않을까 주의를 기울이고 있습니다. 이 이야기를 하는 이유는 앞서 이야기한 배경으로부터 유기화학에서는 전공서적 분량에 의해 압도되지 않기 위해 먼저 가벼운 책으로 기본을 정리하고 전공서적을 탐독하자 합니다. 따라서 이 글은 쉬이 읽을 수 있는 『가볍게 읽는 유기화학』- 사이토 가쓰히로 저서의 책을 기반으로 작성하였습니다.
이 게시글은 계속해서 업데이트 됩니다. 모든 내용이 기술된다면 한 줄의 이 문장은 사라지게 됩니다.
책을 앞 부분만 읽었는데도 불구하고 정말 가볍고 기본적인 내용과 함께 카툰형식으로 구성되어 있어 읽기 편리함을 느꼈습니다. 괜히 스테디셀러에 올라와있는 게 아니라고 생각이 드네요. 고등학교 화학시간에 배웠던 내용들이 조금씩 되살아나는 느낌도 듭니다. 아래 부터는 중간 중간 단편적인 개념설명이 있거나 간단한 서술형식으로 구성됩니다. 내용들이 유기적으로 연결되는 부분이 많아 논리적으로 분할하여 설명하진 않는다는 점 참고해주시면 감사하겠습니다.
[원자의 구성]
원자의 구성은 원자핵과 전자로 구성이 되어 있고, 원자핵은 양전하를 띠고 전자는 음전하를 띱니다. 원자핵 안에는 양성자가 존재합니다. 원자번호는 이 양성자의 개수에 따라 결정된다고 합니다. 예를 들어 원자번호 6번인 탄소는 양성자를 6개를 갖고 있기 때문입니다. 다르게 말하면 곧 전자 또한 6개를 갖고 있는 것과 같습니다. 그 이유는 대부분의 원자들은 안정성을 위해 양성자와 전자의 개수를 동일하여 맞추어 전기적 중성을 띤다고 합니다. 의문이 들었던 것은 물리화학적 지식이 짧아서 그런지 안정성을 위한다는 것이 대체 왜 필요한 것이고 어떤 기전에 의해 이루어지는지 궁금했습니다. 전기적 중성이 왜 필요한 것인가에 대해 간단히 찾아봤을 땐 이해될만한 내용을 찾진 못했습니다. 혹시 아시는 분이 계시다면 댓글 남겨주시면 감사하겠습니다.
[전자와 전자껍질]
전자는 전자껍질이라고 하는 일종의 케이스안에 들어간다고 합니다. 이 전자껍질은 일종의 양파와 같이 반복되는 구조로 이루어져 있다고 생각하면 됩니다. 여기서 함께 사용되는 개념이 주양자수라는 개념인데요, 주양자수에 따라서 여러 전자껍질에 들어갈 수 있는 전자의 개수가 달라진다고 합니다. 공식은 $2n^2$입니다. 예를 들어 주양자수가 1개라면 2개의 전자를, 2->8개 전자, 3->18개 전자로 정원을 채울 수 있다고 합니다. 이 전자껍질은K, L, M, N 순으로 늘어나는 데요 시작이 A가아닌 K부터 시작합니다. 차례대로 K껍질, L껍질, M껍질, N껍질, ...이라 부릅니다. 주양자수에 따른 전자 정원을 계산하는 공식에 따라 K껍질은 최대 2개의 전자를 채울 수 있고 L껍질은 최대 8개의 전자를, M껍질은 최대 18개의 전자를 채울 수 있다고 이야기 합니다. 그리고 어떻게 보면 직관적이지만 한 껍질에 전자의 정원이 모두 차야 다음 껍질에 전자를 채울 수 있게 됩니다. 가령 K껍질을 다채워야만 L껍질에 채울 수 있게 됩니다. 이러한 과정을 전자 배치라고 합니다. 결론적으로 요약하면 주양자수에 따라 전자의 정원이 결정된다라고 이해하시면 되겠습니다.
[닫힌 껍질 구조와 열린 껍질 구조]
원자는 안정성을 위해 전기적 중성을 띤다고 이야기 했습니다. 다르게 말해 전자껍질에 전자의 빈자리가 얼마나 되느냐에 따라 원자의 화학적 안정성을 결정합니다. 닫힌 껍질 구조란 이러한 화학적 안정성이 있는 구조로, 각 전자껍질에 들어갈 수 있는 최대의 전자가 들어가있는 경우를 의미합니다. 반면 전자껍질에 빈자리가 있다면 이를 열린 껍질 구조라고 부릅니다. 예를 들면 수소의 경우 원자번호 1번으로 양성자1개와 전자1개를 갖게 됩니다. 하지만 전자1개는 K껍질의 최대 개수인 2개를 만족하지 못하기 때문에 열린 껍질 구조라 할 수 있습니다. 반면 원자번호 2번인 헬륨은 양성자2개와 전자2개를 갖게 됩니다. 따라서 K껍질의 최대 개수인 2개를 만족하게 되면서 닫힌 껍질 구조라 할 수 있습니다.
[이온화]
원자는 또한 안정성을 위해 닫힌 껍질 구조를 선호합니다. 즉 전자 껍질에 빈자리 없이 만석으로 채우는 것을 좋아합니다. 이를 위해 이온화라는 개념이 사용됩니다. 이온화란, 전자껍질의 안정성을 위해 전자를 채우거나 버리는 것 중 에너지가 덜 소모되는 방향으로 이루어지는 작용을 의미합니다. 예를 들어 플루오린(F)의 L껍질에는 7개의 전자가 들어 있는데 1개만 더 있다면 8개로 가득차서 네온과 같은 닫힌 껍질 구조가 됩니다. 때문에 플루오린은 전자 1개를 더 받아들여서 $F^-$가 되려고 합니다. 이렇게 전자를 받아들이거나 내보내는 과정을 이온화라고 합니다. 플루오린의 경우는 받아들이려 하기 때문에 음이온화라고 할 수 있겠습니다. 반면 원자번호 11번인 나트륨(Na) 같은 경우는 전자가 K껍질에 2개 L껍질에 8개 M껍질에 1개 존재하게 되는데 오히려 전자를 버리는 것이 닫힌 껍질 구조가 되기에 더 적합하므로 하나를 방출하는, 즉 양이온화가 되어 $Na^+$가 된다고 할 수 있습니다.
[전기 음성도]
앞서 말한대로 원자는 안정성을 위해 닫힌 껍질 구조를 선호합니다. 때문에 음이온 또는 양이온이 되고자 합니다. 이와 관련한 개념은 전기 음성도로 즉 원자가 전자를 받아들여 음이온이 되려고 하는 정도를 수치화한 것입니다. 전기 음성도가 큰 원자일수록 전자를 받아들여 하전되기 쉬운 특징을 가집니다.
[분자식과 분자량]
분자식이란 분자를 구성하는 원자의 종류와 개수를 나타내는 것을 의미합니다. 매우 간단하지만 물분자식은 $H_2O$로 표현하며 수소(H) 2개와 산소(O) 1개로 이루어집니다. 분자량의 경우 분자 하나의 무게를 나타내는 지표로서 분자를 구성하는 모든 원자의 원자량의 합으로 구성됩니다. 원자량은 양성자와 중성자의 개수로 구성됩니다. 가령 탄소(C)의 경우 6개의 양성자와 6개의 중성자를 가지기 때문에 원자량이 12가 됩니다. 그렇다면 벤젠인 $C_6H_6$의 경우 12*6 + 1*6이 되면서 78이 분자량입니다. 분자의 질량을 나타내기 위해서는 78에 g만 붙여 78g으로 표현합니다. 이것과 관련한 개념은 몰이 있습니다. 몰은 원자의 일정량을 모아 하나의 단위를 만든 것으로 1몰(mol) = $6.02 \times 10^{23}$입니다. 분자 1몰은 분자량에 g을 붙인 것과 같아서, 벤젠 1몰은 78g이 됩니다. (+1몰의 기체 부피는 22.4L입니다)
[분자의 결합 종류]
공유 결합, 금속 결합, 이온 결합, 수소 결합, 반데르발스 힘 등이 있습니다. 크게 나누자면 공유 결합 비공유 결합으로 나뉠 수 있기도 한 것으로 압니다. 공유 결합은 전자쌍을 공유하여 결합하는 것으로 유기화학에서 거의 대부분의 결합을 차지합니다. 공유 결합은 크게 단일 결합, 이중 결합, 삼중 결합 등으로 나눌 수 있습니다. 또한 여기서 단일 결합은 포화 결합이며 이중 및 삼중 결합은 불포화결합이라 말합니다. 참고로 콘쥬게이션 이중 결합이라는 것이 있는데 이는 단일 결합과 이중 결합의 중간 결합도에 있는 것을 의미합니다. 금속 결합은 금속 원자가 자유 전자를 통한 결합을 의미합니다. 이온 결합은 이온화된 원자가 정전기적 인력으로 인한 결합을 의미합니다. 참고로 공유 결합, 금속 결합, 이온 결합의 경우 전형적인 결합으로 원자나 이온을 결합시킨 결합입니다. 하지만 분자간의 결합도 있으며 여기에는 물분자끼리 결합시키는 수소결합과 전기적으로 중성인 분자끼리 결합시키는 반데르발스 힘이 있습니다.
[결합 거리와 결합 에너지]
결합 거리는 결합 에너지(세기)를 나타냅니다. 공유 결합에서의 단일 결합은 거리가 가장 길며 이중 결합이 그 보다 짧고 삼중 결합이 가장 짧습니다. 결합 거리가 짧을 수록 결합 에너지는 강해진다는 특징을 가집니다.
[전자껍질과 오비탈]
전자껍질 내부에는 사실 구체적으로 몇 개의 오비탈로 나뉘어져 있습니다. 전자는 각 오비탈에 2개씩 들어 있습니다. 하지만 짝을 이루지 않는 전자도 있으며 이를 홀전자라고 합니다. 이러한 홀전자를 내놓으면서 이루어지는 결합을 공유 결합이라고 합니다.
[화합물, 홑원소 물질, 동소체]
셋 다 분자에 속하는 개념이지만 화합물은 다른 원자들 간의 결합이 된 것을 의미하며 홑원소 물질은 오롯이 하나의 원소로만 이루어진 분자를 의미합니다. 예를 들어 풀러렌을 나타내는 $C_{60}$이 있습니다. 동소체 같은 경우는 홑원소 물질이지만 다른 분자량을 나타낼 때를 의미합니다. 가령 탄소 원자 60개로 이루어진 풀러렌외에 탄소는 다른 분자량을 통해 흑연이나 다이아몬드, 카본 나노 튜브 등으로 나타낼 수 있는데 이를 동소체라고 합니다.
[유기물]
유기와 무기를 결정짓는 것은 화합물에 탄소(C)의 포함 여부라고 알고 있었습니다. 이 책에서는 탄소(C)를 포함하여, 수소(H), 산소(O), 질소(N) 또한 유기물을 구성하는 원소라고 합니다.
[메테인/에테인/에틸렌/아세틸렌]
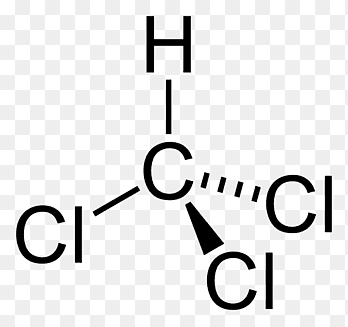
메테인은 $CH_4$로 가장 작은 유기물로써 모든 유기물의 기초가 되는 분자를 의미합니다. 참고로 메테인의 분자 형태는 테트라포트 형으로, 바닷가에 방파를 위해 설치한 구조물과 동일한 형태를 띱니다. 에테인은 $C_2H_6$의 분자식을 가집니다. 에틸렌은 $C_2H_4$의 분자식을 가지는 것으로 탄소간의 이중 결합이 되어 있는 것이 특징입니다. 아세틸렌은 $C_2H_2$의 분자식을 가지는 탄소간의 삼중 결합이 이루어진 분자입니다. 다시 정리하자면 에틸렌은 이중 결합 중 가장 작은 분자이며, 아세틸렌은 삼중 결합 중 가장 작은 분자라고 할 수 있습니다.
[분자 구조식]
분자를 표현하기 위해 사용했던 분자식으로는 분자의 3차원 구조를 나타낼 수 없다는 한계점이 있습니다. 때문에 분자 구조식을 사용해서 3차원 모양을 표현해야 합니다. 이렇게 분자의 구조를 표현하기 위해 사용되는 3가지 선(line)과 3가지 구조식이 있습니다. 먼저 3가지 선의 종류는 아래와 같이 점선과 실선과 쐐기선이 있습니다.
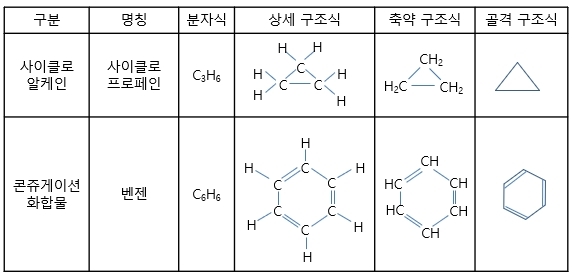
점선 같은 경우는 뒷쪽에 있음을 나타내고, 실선은 평면에 있음을 나타내고, 쐐기선은 앞으로 튀어 나와 있음을 의미합니다. 세 가지 구조식의 종류는 상세 구조식, 축약 구조식, 골격 구조식이 있고 아래와 같이 표현합니다.
상세 구조식으로 표현할 경우 분자량이 크다면 상세히 표현하기 어려워지므로 분자식과 선(line)을 이용하여 축약합니다. 하지만 축약 또한 커진다면 골격 구조식을 사용합니다. 골격 구조식에는 간단한 규칙 두 가지가 있습니다. 첫 번째는 직선의 양 끝과 곡선부에는 탄소(C)가 존재하는 것이며, 두 번째는 각 탄소(C)에는 충분한 수의 수소(H)가 결합한다는 것입니다.
[알케인, 알켄, 알킨]
근간이 되는 분자는 탄화수소입니다. 탄화수소는 유기화합물의 골격을 만든다는 특징을 가집니다. 알케인은 탄화수소가 단일결합으로만 이루어진 것을 의미합니다. 알켄은 탄화수소가 이중결합으로 이루어진것을 의미하며, 마지막으로 알킨은 탄화수소가 삼중결합으로 이루어진 것을 의미합니다. 참고로 탄소가 고리 형태로 결합한 탄화 수소를 고리형 탄화수소라고 하는데 이들이 알케인, 알켄, 알킨에 적용되면 사이클로 알케인, 사이클로 알켄, 사이클로 알킨이 됩니다.
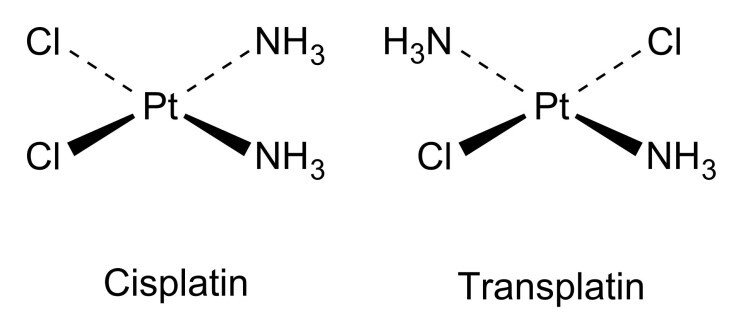
이성질체란 같은 분자식과 분자량을 가지지만 구조가 다른 것을 의미합니다. 예를 들어 아래와 같이 플라틴이라는 분자가 있을 경우 분자식은 같지만 구조가 다릅니다. 이 때 겹치는 NH3가 같은 쪽에 있다면 시스체, 다른 쪽에 있다면 트랜스체라고 부릅니다.
참고로 이러한 이성질체는 분자량이 커질수록 기하급수적으로 늘어나는 특징을 갖고 있습니다.
[카이랄성]
-
[수소, 반수소]
원자핵이 양전하를 전자가 음전하를 띠는 것을 일반적으로 원자라고 한다. 이에 완전히 반대되는 것이 있다. 원자핵이 음전하를, 전자가 양전하를 띠는 것이다. 가령 수소가 반수소와 충돌하게 되면 이는 빛을 내면서 소멸하게 된다.
[치환기, 알킬기, 작용기]
이를 아우르는 상위 개념은 유기 화합물 분자가 됩니다. 유기 화합물의 종류는 다양합니다. 다만 성질이 비슷한 것을 그룹화할 수 있으며 이 때 중요한 역할을 하는 것이 치환기입니다. 유기화합물은 본체 부분과 부수적인 부분으로 나뉩니다. 이 때 부수적인 부분이 치환기입니다. 하지만 우리의 머리와 몸이 둘 다 중요하듯 부수적인 부분이라 하여 중요성이 떨어짐을 의미하지 않습니다. 유기 화합물의 구조를 나타내면 아래와 같습니다.
유기 화합물
- something (main)
- 치환기 (sub)
-- 알킬기
-- 작용기
본체인 something과 부수적인 치환기로 구성이 되며 치환기는 알킬기와 작용기로 나뉩니다. 알킬기는 크게 특징이 두 가지입니다. 첫 번째는 탄소(C)와 수소(H)로 단일결합 된 것이고 두 번째는 알케인에서 수소가 하나빠진 것을 의미하는 것입니다. 즉 메테인($CH_4$)에서 수소하나가 빠진 메틸기($CH_3$)를 알킬기라 칭합니다. 또는 에틸기($CH_2CH_3$)입니다. 알칼기는 기호로 $R$로 표현합니다.
작용기는 알킬기 이외의 치환기를 의미합니다. 작용기는 이중 결합을 포함한 탄화수소이거나 대부분 C, H이외의 원소를 포함하고 있습니다. 작용기는 분자의 성질이나 반응성을 결정하기 때문에 분자의 얼굴과도 같습니다. 즉, 유기물의 성질은 작용기의 성질에 따라 결정됩니다. 한마디로 요약하면 작용기는 탄화수소에 장식으로 붙어 있는 원자단을 의미합니다.
전체를 요약하면 알킬기, 작용기의 핵심 차이점은 탄화수소로 결정됩니다. 알킬기는 탄소와 수소의 단일 결합으로 이루어진 것이며, 작용기는 탄소와 수소를 포함한 이외의 원자와 함께 결합하며 이중 결합도 포함됩니다.
[알코올]
알코올은 메탄올이나 에탄올처럼 알킬기에 하이드록시기(OH)가 결합한 화합물을 의미합니다. 참고로 메탄올과 에탄올은 대표적인 알코올입니다. 하지만 우리가 주로 알코올을 이야기할 때는 주성분인 에탄올을 의미할 때가 많습니다. 알콜은 중성이며 알칼리 금속과 반응해 금속염과 수소 가스가 생깁니다. 알코올은 크게 1차 알코올, 2차 알코올, 3차 알코올이 있는데요, 하이드록시기가 붙은 탄소에 알킬기가 1개 붙을 때 마다 늘어나는 식입니다.
[페놀]
벤젠에 하이드록시기가 붙은 것을 의미합니다. 주로 살균작용이 있어 소독제로 사용됩니다. 다크 초콜릿에 든 폴리페놀이 떠오릅니다. 항산화작용을 통해 노화를 방지해주는데 이와 관련이 있는 것 같아 보이네요.
[에터]
두 개의 알킬기가 산소에 의해 결합된 화합물을 의미합니다. 이 때 두 개의 알킬기가 모두 메틸기일 경우 다이메틸 에터, 에틸기일 경우 다이에틸 에터라 합니다. 참고로 다이는 수사로써 숫자 2를 의미합니다. 다이에틸 에터는 유기물을 녹이기 쉽기 때문에 유기 반응의 용매로 자주 사용되며 한 땐 마취제로 사용되기도 했습니다. 휘발성이 있어 폭발 위험도 있습니다. 종류는 크게 고리형과 사슬형 에터가 존재합니다.
[카보닐 화합물, 케톤]
카보닐 화합물이란 탄소와 수소가 이중 결합된 C=O 원자단을 포함한 화합물을 의미합니다.
카보닐기(C=O), 폼일기(CHO), 카복실기(COOH)
카보닐기에 2개의 알킬기가 결합한 것을 케톤이라 부르며 아세톤이나 벤조 페논 등이 있습니다. 아세톤은 유기물을 녹이는 힘이 매우 강하고 물과 잘 섞이는 성질이 있습니다. 케톤을 환원하면 2차 알콜이 되고 반대로 2차 알코올을 산화하면 케톤이 됩니다.
[알데하이드]
폼일기(CHO)를 포함한 화합물을 알데하이드라고 부릅니다. 참고로 폼일기에 포함된 CO는 이중 결합되어 있습니다. 이러한 알데하이드의 종류 중에는 폼알데하이드나 아세트알데하이드 벤조알데하이드등이 있습니다.
평범한 기자였던 저자가 1년만에 세계 메모리 챔피언쉽에 참가해 우승한 비법에 대해 알려주는 책이다.
해당 대회에서 요구하는 것은 포커카드 52장을 순서대로 외우거나 무작위 사람 이름 99개를 외우거나, 원주율과 같은 무작위 숫자를 외우는 것이다. 어떻게 가능해라고 생각했지만 저자는 타고난 기억력은 없다며 만들어지는 것이라고 말한다. 실제로 그가 알려준 방법을 사용해보니, 충분한 연습만 있다면 가능하겠다는 판단이 선다.
그 방법은 크게 기억의 궁전법과 숫자-메이저 시스템이다. 먼저 기억의 궁전법이란 인간은 텍스트보다 이미지를 기억하는 데 매우 뛰어나다는 것에 착안한 방법으로 고대 그리스에서 사용되었던 방법이다. 자신이 익숙하거나 또는 가상의 공간을 만들어 그 공간에 기억해야할 것을 시각화하는 것이다. 이 때 기억하기 쉽도록 동적이며 외설스럽고 재밌으면 좋다고 한다.
가령 마트에서 양말과 양파와 와인을 사야한다면 내가 익숙한 공간에 양파가 머리에 양말을 뒤집어쓰고 와인을 마시면서 비틀거리는 모습을 두는 것이다. 이와 같은 방법으로 여러 개를 두고 필요할 때 그 장소만 떠올리면 모두 기억할 수 있다는 것이다. 여기서 핵심 요소는 창의력으로, 시각화하기 어려운 것을 시각화를 잘할 수 있게 끔 바꾸는 것이라 말한다.
이 같은 방법이 가능한 이유는 뇌에는 우리는 과거를 회상할 때 늘 장소를 함께 떠올리게 되는데 이는 기억이 "장소 세포"에 의존하기 때문에 공간과 함께 기억의 저장이 이루어진다는 것이다. 두 번째로는 숫자-메이저 시스템으로 쉽게 말해 숫자 잘 외우는 방법이다. 가령 1:ㄱ, 2:ㄴ 3:ㄷ, ... 같은 방식으로 치환하여 213이라는 숫자가 있다면 "난 고독"으로 바꾸어 고독한 나의 모습을 상상하는 것이다. 이 때 기억의 궁전법과 함께 활용하면 좋을 것이다.
실제로도 이 책을 읽은 뒤, 급하거나 잊지말고 해야할 말을 하기 위해 사용하기도 한다. 다만, 무궁무진하다는 이 기억법을 조금 더 복잡한 일에는 활용하지 못하고 있어 아쉽다는 생각은 든다. 앞으로는 조금 더 풍성하게 사용할 수 있도록 갈고 닦아야 겠다.
"기억력이 보통이라해도 제대로 활용하기만 하면 대단한 능력을 발휘할 수 있다는 것을 알아야 한다" - 책 속에서
Cross-Lingual, Multilingual, Language Structure, typological similarity
먼저, 이 논문을 한 마디로 요약하면 typological similarity는 크게 중요한 요소가 아니라는 것을 주장하는 논문입니다.
이 논문의 연구 배경은 Multilingual Masked Languagde Model(이하 Multilingual MLM)이 어떻게 별도의 Cross-lingual 지도학습 없이도 좋은 성능을 내는지에 대한 물음을 기반으로 시작되었습니다. "How multilingual is Multilingual BERT?"(이하 mBERT) 이라는 multilingual의 시작이 되는 논문에서 multilingual 모델의 성능은 언어학적인 유사성(typological similarity)이 높을수록 좋은 성능이 나온다고 하였지만 이 논문에서는 이를 정면으로 반박합니다. 그 이유는 언어학적 유사성이 높다는 것은 정확한 통제변인이 이루어지지 않았음을 지적합니다.
예를 들면 mBERT 논문에서는 언어의 문법 구성인 SVO(주어, 동사, 목적어)와 AN(형용사, 명사)만 고려했습니다. 세계의 많은 언어는 SVO 순을 쓰거나 SOV 순을 쓰는 언어가 존재하고 AN 순을 쓰거나 NA 순을 사용하는 언어가 존재합니다. 하지만 이 논문에서는 다른 품사(전치사, 부사, 접속사, 한정사) 등을 모두 고려하지 않은 실험 결과라고 말합니다. 아래는 mBERT 논문에서 가져온 실험결과 입니다.
(a)는 SVO의 어순을 가진 언어끼리 그룹화하고 SOV의 어순을 가진 언어끼리 그룹화해서 zero-shot trasnfer를 수행할 때의 macro-averaged POS accuracy를 나타냅니다. (b) 또한 (a)와 동일한 맥락입니다. 한 마디로 같은 어순을 가진 그룹끼리는 성능이 좋지만 다른 어순을 가지면 성능이 떨어진다는 것을 의미합니다. 즉, multilingual MLM이 어순이 다른 것은 학습하지 못한다는 것을 보였습니다.
하지만 이 논문에서는 mBERT에서 언어학적 유사성으로 가져온 피처가 2개밖에 되지 않는다고 이야기합니다. 즉, 다시 한 번 말해, 하나의 언어를 구성하는데는 SVO와 AN만 있는 것이 아니라 전치사, 부사, 접속사, 한정사 등과 같은 여러 품사가 존재하는 데 모두를 고려하지 않고 두 개의 피처만 가지고 유사성을 비교했다라는 것을 지적하는 것입니다.
이에 대해서 저자들은 정확한 실험을 위해선 통제 변인을 잘 설정하는 것이 중요하다고 이야기하며 artificial sentence를 아래와 같이 생성합니다.
예를 들면 영어가 주어동사목적어 순일 때 주어목적어동사로 영어에서 맞지 않는 문법인 인공의 문장을 데이터셋으로 만듭니다. 마찬가지로 전치사 명사를 명사 전치사로, 형용사 명사를 명사 형용사 순으로 바꿉니다. 참고로 이 때 사용한 83A, 85A, 87A 언어 구조와 관련한 피처로 세계 언어 구조에 대한 데이터베이스인 WALS (World Altas of Language Structure)의 피처를 기준으로 하였습니다. (총 192개의 피처가 존재)
WALS에서 제시하는 세계 언어에 대한 특성
위와 같이 WALS의 피처를 기준으로 인공의 문장을 생성한 뒤 6개의 target언어에 대해 평가한 결과는 아래와 같습니다.
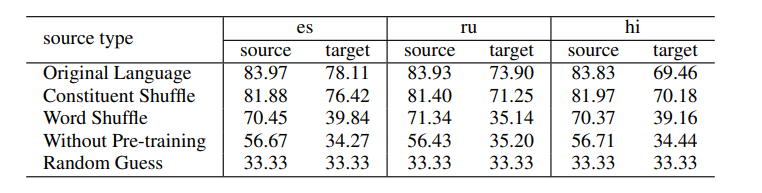
6개의 target 언어는 ru(러시아), hi(힌디어), tr(터키), es(스페인), th(태국), vi(베트남)입니다. 여기서 표 한 부분만 해석해도 됩니다. 영어와 어순이 같은 러시아어의 비교표를 기준으로 설명하겠습니다. 먼저 source는 모두 영어만 사용했습니다. 영어 데이터를 변형하지 않은 en의 경우 소스를 순수 영어로하고 target을 러시아어로했을 때 transfer 성능이 83.93%과 73.90%이 나왔습니다.
하지만 영어의 어순 VO를 OV로 변경한 en-OV의 결과를 확인하면 어순을 바꿨음에도 불구하고 어순이 같았던 러시아어에 대해 transfer 성능이 오히려 높아지는 결과를 확인할 수 있습니다. 마찬가지로 전치사를 사용하는 영어에서 후치사로 바꾼 en-Post에서도 오히려 더 성능이 높아진 것을 확인할 수 있습니다. AN 또한 명사, 형용사로 바꾼 en-NA에서는 다소 낮아짐으로써 결과의 일관성이 없음을 볼 수 있습니다. 즉, 이 표가 말하고자 하는 것은 한마디로 mBERT 논문에서 주장했던 typological similarity가 중요하지 않다는 것을 시사하고 있습니다.
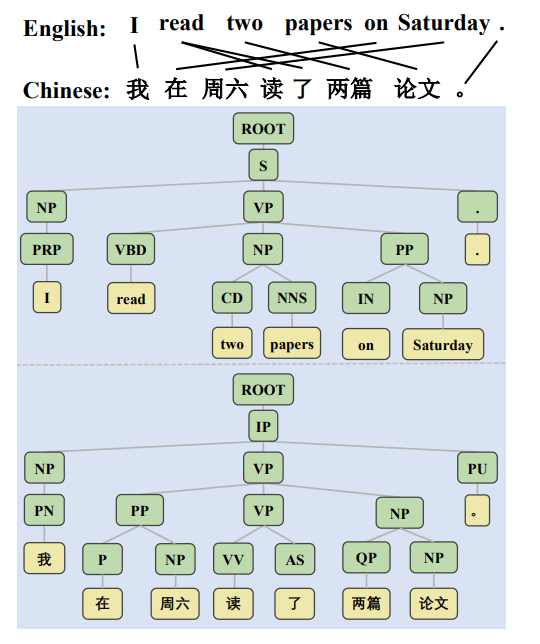
그러면서 가장 중요한 것은 composition이라고 말합니다. 앞서서 미리 알려드리지 못했으나 이 논문에서는 크게 언어학적인 속성 3개에 대해 실험을 진행했습니다. 세 언어학적 요소는 constituent order, composition, word co-occurrence 입니다. 위 어순을 바꾼 실험이 constituent order에 대한 실험이었습니다. 참고로 constituent order는 구성 순서를 의미하는 것으로 아래의 그림에 있는 NP, VP, PRP, VBD와 같은 constituent의 순서를 변경했을 때의 multilingual 모델의 성능을 보는 것입니다.
composition 같은 경우는 조금 더 친절한 설명이 있지 않아 지금도 이해가 어려운 부분이 있는데요, 논문에서 제시하는 예시는 "two"라는 단어와 "papers"라는 단어를 합치면 "two papers"와 같은 조금 더 복잡한 단어를 만들 수 있다고 합니다. 따라서 나이브하게 합성어 정도라고 이해하고 있습니다.
마지막으로 word co-occurrence 같은 경우는 동시 발생으로 일종의 관용구나 의미적 유사성을 나타내는 속성이라고 합니다. 예를 들면 "티끌 모아 __"하면 태산이 나오는 것 처럼 티끌과 태산은 함께 나오는(co-occurrence) 단어다 정도로만 이해를 했습니다.
consituent order를 변형한 결과를 보여준 것관 달리 composition과 word co-occurrence에 대한 실험은 하나의 표에 결과를 함께 보여주는데요 그 표는 다음과 같습니다.
Original Language 같은 경우는 소스언어인 영어 데이터를 변형하지 않았을 때의 결과를 나타냅니다. Constituent Shuffle 같은 경우는 constituent order를 제거했을 때의 성능을 나타내구요, Word Shuffle 같은 경우는 constituent order와 composition을 제거 했을 때의 결과를 나타냅니다.
여기서 중요한 것은 constituent order를 제거했을 때는 성능 저하가 미미하지만 composition과 함께 제거할 경우 target 언어에 대해 language transfer 성능이 확 떨어지는 것을 볼 수 있습니다. 이 결과를 바탕으로 저자들은 Multilingual MLM의 성능을 나타내는 언어학적인 세 요소 중에 가장 중요한 것이 composition이라고 합니다.
이 때까지 내용을 총 정리하면 크게 아래 두 줄로 요약할 수 있습니다.
1. mBERT에서 주장한 typological similarity가 높을 수록 성능이 좋다는 것은 사실이 아니며 잘못된 변인 통제에 의해 실험이 이루어졌다.
2. multilingual MLM의 성능을 좌우짓는 요소는 composition이다.
전반적으로 논문을 읽으며 다소 불친절한 설명이 있고, 직관적으로 파악하기 어렵다는 데 있어 아쉬운 측면은 있습니다. 예를 들면 Word Shuffle에 대해 조금 더 상세한 설명이 덧붙였으면 더 나은 논문이 되지 않았을까 싶습니다. 하지만 그럼에도 불구하고 잘못된 변인 통제를 기반으로 수행한 mBERT의 실험 결과를 정정한다는 측면에서는 의미 있는 연구라 생각이 듭니다.
사람이 읽기, 듣기를 동시에 못하는 것을 아는가? 읽는 것과 듣는 것이 본질적으로 같은 과정이기 때문이다.
오래전 별점 4점을 주었던 책이다. 하지만 이후 두뇌 사용법에 관한 서적 20여권을 더 읽었지만 이만큼 명료하고 많은 통찰을 이끌어 냈던 책은 없었다. 재평가가 필요한 것 같다. 5점을 주어도 전혀 손색이 없다. 석사과정 때 논문 세미나 발표를 해야할 당시 이 책의 조언을 대부분 갖추었더니 정말 놀랍게도 모두 한 마디씩 발표 잘한다고 칭찬해주었던 것이 기억난다.
당시 발표 이후 외부 강의를 맡게 되었으니 이 책의 덕을 톡톡히 본 샘이다. 이 책에서 전해준 소중한 정보들이 있지만 지금 가장 기억에 남는 것은, 인간의 두뇌 메커니즘상 멀티태스킹이 불가능하다는 것이다. 예시로 상대의 프레젠테이션을 듣는 동시에 글을 읽을 수 없다는 것이다. 만약 그렇게 할 경우 이해도가 매우 떨어지게 된다고 한다. 따라서 발표자료에 텍스트를 많이 포함시키면 상대의 학습과 집중력을 방해하는 것이 된다. 이 말인 즉슨 상대가 우리 자신에게 인상적인 느낌을 얻을 확률이 매우 떨어진다는 것을 의미한다고 말한다. 때문에 인간의 두뇌가 텍스트에 비해 매우 짧은 시간에 이해할 수 있는 시각 이미지를 최대한 활용하고 텍스트를 최대한 줄이라 말한다.
하지만 주의점은 표나 그래프는 그림이 아니다는 것이다. 종종 세미나를 듣다보면 논문에 나온 표와 그래프를 설명하지 않고 보면 알죠?하는 듯이 넘어가는 사람들이 있었다. 그렇게 되면 저자는 뇌는 예측 기계이기 때문에, 제대로 이해하지 못하고 넘어가면 결핍된 정보에 신경을 쓰게 되면서 발표에 집중력이 떨어지게 된다는 것이다. 또한 저자는 청중의 집중력을 높이기 위해서는 정말 간단하게 손으로 가리키기만 하면 된다고 말한다. 이를 통해 손가락으로 표와 그래프를 가리키며 상세히 설명 했었던 것 또한 좋은 발표로 느끼게끔 했으리라 생각된다.
위의 내용을 포함하여 발표 시 고려해야 할 점은 다음과 같다.
1. 발표 자료에는 텍스트를 아주 최소한만 삽입해라
2. 발표 자료에 삽입된 단어와 내가 말하는 단어가 같다면 방해되고 흥미를 잃는다. 키워드만 짚어가면서 이야기 해라
3. 슬라이드 하나에 한 이미지만 넣어라
4. 그래프와 표는 그림이 아니다. 해석해주지 않으면 한 번에 이해하지 못한다.
5. 문자를 과감히 지우고 이미지를 추가하는 것이 학습력 향상에 도움 된다.
6. 일관된 레이아웃을 가진 발표 자료가 기억력을 최대 35%를 더 향상시킨다.
7. 사람들 집중력을 높이고 싶다면 손으로 가리켜라.
8. 참고자료는 발표 끝난 후에 배포하라.
9. 중요 정보에 주목시켜야 한다면 일관된 레이어 구성을 탈피해서 뇌의 예측 불일치를 발생시켜라.
10. 시각 정보는 모든 이가 동일한 이해를 하도록 도와주며, 들은 이야기가 생생한 활기를 얻는다. 또한 읽기도 전에 이해할 수 있게 된다.
이렇게 작성하고 보니 직장인의 효율적인 프레젠테이션법 측면만 다루는 책 같다. 그렇지 않다. 저자는 신경과학의 연구 결과를 토대로 두뇌 메커니즘을 이야기한다. 간단하게만 더 이야기하자면 기억에는 세 개의 형태가 있다. 작동 기억, 절차 기억, 서술 기억이다. 작동 기억은 임시 저장소로 10~20초간의 내용을 담을 수 있고, 이 때문에 "일관성"이라는 의미를 머릿속에 형성 가능하다. 절차 기억은 운동과 관련된 것으로 양치질이나 자전거를 타는 것과 같이 배워두면 무의식적으로 할 수 있는 것과 같다. 마지막 서술 기억이 가장 흥미로웠는데 일반적으로 우리가 기억력이라 말하는 것이다. 구체적인 사실과 사건들을 기억하고 회상하는 능력이다. 이 서술 기억을 구성하는 핵심은 공간이다. 우리는 무언가를 떠올릴 때 공간과 함께 떠올리게 되는데 이는 해마에 있는 장소세포 때문이다.
서술 기억은 크게 일화적 기억(episode)과 의미적 기억(semantic) 두 가지로 구성되며 일화적 기억은 ex) 조카의 다섯 번째 생일날 오후, 아이스크림 케잌을 부엌 바닥에 떨어트린 것이며 의미적 기억은 ex) 생일이 한 개인이 태어난 날이다와 같은 어떠한 개념의 의미를 아는 것을 말한다. 저자는 모든 새로운 기억은 일화적 기억에 출발하여 다양한 맥락에서 같은 정보를 접했을 때 특정한 맥락에서 떨어져 나와 독립된 사실로 변한다고 말한다. 때문에 한 장소에서 공부나 훈련과 연습하면 그 장소와 밀접히 연관되므로, 다양한 장소에서 공부와 훈련과 연습을 하여 새로운 맥락 속에서도 좋은 성과를 낼 수 있도록 해야 한다고 말한다.
+ 학습 시 음악은 백색소음 처럼 집중하지 않을 만큼 예측적이여야 한다고 함.
+ 학습은 3R(Recognition, Review, Recall) 단계가 있고 그 중 Recall이 가장 중요하다. 회상의 종류는 자유 회상과 단서 회상이 있는데 자유 회상은 아무 것도 없는 것에서 곧 바로 배웠던 것을 회상하는 것이고 단서 회상은 키워드나 작은 실마리를 듣고 회상하는 것을 의미한다. 결론적으로 더 많이 회상할수록 미래에 그 기억에 접근하기 더 쉽다.
"회상은 깊고, 오래 지속되는, 접근하기 쉬운 기억을 형성하는 열쇠다." - 제레드 쿠니 호바스
한 마디로 super().__init__()은 부모 클래스의 속성 및 메소드를 가져오는 것이다.
class A():
def __init__(self):
print ('[*] This is class A')
class B(A):
def __init__(self):
super().__init__()
if __name__ == "__main__":
b = B()
(base) C:\github>python test.py
[*] This is class A
부모 클래스의 속성 가져오기
A 클래스에 self.name이라는 속성을 추가하였다. 상속을 받는 B 클래스에서는 self.name을 가져와서 사용할 수 있다.
class A():
def __init__(self):
self.name = "roytravel"
print ('[*] This is class A')
class B(A):
def __init__(self):
super().__init__()
print (self.name)
if __name__ == "__main__":
b = B()
(base) C:\github>python test.py
[*] This is class A
roytravel
부모 클래스의 메소드 가져오기
A 클래스에 print_name이라는 메소드를 추가하였다. 이후 B 클래스에서 super를 통해 A 클래스의 메소드에 접근할 수 있다.
class A():
def __init__(self):
self.name = "roytravel"
print ('[*] This is class A')
def print_name(self):
print (self.name)
class B(A):
def __init__(self):
super().__init__()
super().print_name()
if __name__ == "__main__":
b = B()
(base) C:\github>python test.py
[*] This is class A
roytravel
이 책은 과학기술이 발달함에 따라 정치적, 경제적, 사회적으로 어떻게 세상이 변할 것인가에 대해 서술한 책으로, 세계 석학이라 불리는 8인의 사람들의 인터뷰 형식으로 구성되어 있다.
가장 흥미로웠던 부분은 과학기술의 발전으로 민주주의의 기능이 올바른 역할을 하지 못하고 있다는 것을 지적한 것이었다. 20세기 가장 성공한 정치구조였지만 최근 정보가 기하급수적으로 늘면서 세계에서 일어나는 수 많은 일을 파악하기 어렵다는 것이다. 파악하고 예측할 수 없으니 미래에 추구할 목표나 가치를 결정할 수도, 계획을 세울 수도 없다 말한다. 때문에 새로운 정치구조가 도입될 가능성을 제시했고, 과연 미래에는 어떤 정치 구조가 도입될 수 있을까 생각해볼 수 있었다.
이 책을 관통해서 말하는 기술은 인공지능이다. 세계 석학은 인공지능의 발달로 무용(無用)계급이 도래할 것이라 말한다. 범용 인공지능이 대두 되면서 사람들의 일자리를 뺏을 수 있다는 것이다. 이에 대한 대안으로 최근 계속 다뤄지고 있는 기본 소득에 대한 도입 배경을 알 수 있었다. 하지만 흥미로웠던 것은 기본 소득의 여러 문제점 중 삶의 의미에 관한 문제였다. 단순히 의식주를 제공한다면 모든 것이 해결 될 것인가? 인간 삶의 의미가 어떻게 변할지 생각해볼 수 있는 대목이었다.
세계 석학은 끊임 없이 익히고 급변하는 상황에 대응할 수 있어야 된다고 말한다. 그 이유는 인간수명의 장기화와 과학기술로 인한 세계 변화의 가속화 때문이라 말한다. 인생에는 배우는 시기와 배운 것을 활용하는 두 시기가 있지만 21세기는 통하지 않는 다는 것이다. 끊임없이 학습하고 혁신해야 한다고 말한다.
이 책에 대한 총평은, 세상이 직면한 문제와 어떻게 바뀔 것인가에 대한 거시적 관점으로 바라볼 수 있었다는 것이 가장 좋았던 장점이고 단점으로는 내용의 깊이가 깊지 않았다는 것이다. 세상의 변화에 대해 가벼운 마음으로 보고자 한다면 이 책을 추천한다.
별점: ⭐️⭐️
수명이 늘어나면 재산을 모으기보다, 지금보다 오래 일하기 위한 자산을 축적해두어야 한다. - 책 속에서
이 포스팅은 『밑바닥부터 시작하는 딥러닝』을 기반으로 작성되었습니다. 간단한 이론이지만 누군가에게 설명할 수 있는가에 대해 생각한 결과, 올바르게 설명하지 못한다고 판단되어 이를 쇄신하고자 하는 마음으로 작성합니다.
신경망 학습과 손실함수
신경망을 학습한다는 것은 훈련 데이터로부터 매개변수(가중치, 편향)의 최적값을 찾아가는 것을 의미한다. 이 때 매개변수가 얼마나 잘 학습되었는지를 어떻게 판단할 수 있을까? 방법은 손실함수(loss function)을 사용하는 것이다. 손실함수란 훈련 데이터로부터 학습된 매개변수를 사용하여 도출된 출력 신호와 실제 정답이 얼마나 오차가 있는지를 판단하는 함수이다. 다시 말해 학습된 신경망으로부터 도출된 결과 값과 실제 정답이 얼마나 차이가 나는지를 계산하는 함수이다. 값의 차이를 손실이라고 말하며 신경망은 이 손실함수의 값이 작아지는 방향으로 매개변수를 업데이트 하게 된다.
그렇다면 신경망의 학습을 위해 사용하는 손실함수의 종류들은 무엇이 있을까? 종류를 논하기에 앞서 손실함수는 풀고자하는 태스크에 따라 달라질 수 있다. 예를 들어 머신러닝 태스크는 크게 분류 태스크와 회귀 태스크가 있을 것이다. 분류 태스크라고 한다면 이 사진이 강아지, 고양이, 원숭이 중 어디에 해당할지 분류 하는 것이다. 분류 태스크의 특징은 실수와 같이 연속적인 것이 아니라 정수와 같이 불연속적으로 정확하게 강아지, 고양이, 원숭이 중 하나로 나눌 수 있다. 반면 회귀 태스크는 연속이 아닌 불연속적(이산적)인 값을 가지는 태스크를 수행하는 것을 의미한다. 예를 들어 사람의 키에 따르는 몸무게 분포를 구하는 태스크일 경우 몸무게와 같은 데이터는 실수로 표현할 수 있기 때문에 출력 값이 연속적인 특징을 가지는 회귀 태스크라 할 수 있다.
그렇다면 손실함수의 종류와 특징들에 대해서 알아보도록 하자.
손실함수 (Loss Function)
평균제곱오차 (Mean Squared Error, MSE)
여러 종류의 손실함수 중 평균제곱오차라는 손실함수가 있다. 이 손실함수를 수식으로 나타내면 다음과 같다.
$$ MSE = {1\over n}\sum_i^n(\hat{y}_i - y_i)^2 $$
간단한 수식이다. 천천히 살펴보자면, $\hat{y}_i$는 신경망의 출력 신호이며 $y_i$는 실제 정답이다. $n$은 학습 데이터 수를 의미한다. 이를 해석하자면 출력(예측) 신호와 실제 정답 간의 차이를 구한다음 제곱을 해준 값을 데이터셋 수 만큼 반복하며 더해주는 것이다. 제곱을 해주는 이유는 음수가 나오는 경우를 대비하여 마이너스 부호를 없애기 위함이다. $1\over n$를 곱해주는 이유는 평균 값을 구해주기 위함이다. 즉 MSE를 한마디로 이야기하면 오차의 제곱을 평균으로 나눈다고 할 수 있다. 따라서 MSE는 값이 작으면 작을 수록 예측과 정답 사이의 손실이 적다는 것이므로 좋다.
출력 신호인, 예측 확률 output이 가지고 있는 가장 높은 확률 값과 정답이 차이가 적을수록 손실 함수의 출력 값도 적은 것을 확인할 수 있다. 반면 가장 높은 확률이 정답이 아닌 다른 곳을 가리킬 때 손실함수의 출력 값이 커지는 것을 확인할 수 있다. 위에서 볼 수 있듯 평균제곱오차(MSE)는 분류 태스크에 사용 된다.
교차 엔트로피 오차 (Cross-Entropy Error, CEE)
위와 달리 회귀 태스크에 사용하는 손실함수로 교차 엔트로피 오차가 있다. 수식으로 나타내면 다음과 같다.
$$ CEE = -\sum_i\hat{y_i}\ log_e^{y_i} $$
$\hat{y_i}$는 신경망의 출력이며 $y_i$는 실제 정답이다. 특히 $\hat{y_i}$는 one-hot encoding으로 정답에 해당하는 인덱스 원소만 1이며 이외에는 0이다. 따라서 실질적으로는 정답이라 추정될 때($\hat{y_i}=1$)의 자연로그를 계산하는 식이 된다. 즉 다시 말해 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정하게 된다.
실제로 구현할 때는 log가 무한대가 되어 계산 불능이 되지 않도록 하기 위해 delta 값을 더해주는 방식으로 구현한다. 예측 정답이 2번이고 실제 정답이 2번일 경우의 손실함수 값은 0.051이고 이와 달리 예측 정답이 2번이고 실제 정답이 7번일 경우 손실함수 값은 2.302가 된다. 즉, 정답에 가까울수록 손실함수는 줄어들고 오답에 가까울수록 손실함수는 커진다고 볼 수 있다. 신경망의 목표는 이러한 손실함수의 값을 줄이는 방향으로 학습하는 것이다.
import sys
input = sys.stdin.readline
fibo_nums = [0, 1]
for i in range(45):
fibo_nums.append(sum([fibo_nums[-1], fibo_nums[-2]]))
n = int(input())
print (fibo_nums[n])
#include <iostream>
using namespace std;
int main(void)
{
int N = 0;
cin >> N;
if (N>=1 and N<=100000)
{
for (int i=N; i>0; i--)
{
cout << i << '\n';
}
}
return 0;
}
#include <iostream>
using namespace std;
int main(void)
{
int N = 0;
cin >> N;
if (N>=1 and N<=100000)
{
for (int i=1; i<=N; i++)
{
cout << i << '\n';
}
}
}
#include <stdio.h>
int main(void)
{
int N = 0;
scanf("%d", &N);
if (N >= 1 and N <= 9)
{
for (int i=1; i<=9; i++)
{
printf("%d * %d = %d\n", N, i, N*i);
}
}
else
return 0;
return 0;
}
import sys
T = int(input())
for _ in range(T):
count, string = sys.stdin.readline().split()
P = ""
for s in range(len(string)):
P += string[s] * int(count)
if s == len(string) -1:
print (P)
#include <iostream>
using namespace std;
int main(void)
{
int M = 0;
int N = 0;
int Count = 0;
int Min = 0;
int Sum = 0;
int flag = true;
cin >> M;
cin >> N;
if (M<=10000 and M>=1 and N<=10000 and N>=1) // initial condition
{
for (int i=M; i<=N; i++) // M이상 N이하 자연수
{
for (int j=1; j<=i; j++) // M까지의 수
{
if (i % j == 0) // 소수 확인을 위해 M을 j로 나누어 Count를 계산
{
Count = Count + 1;
}
}
if (Count == 2) // 나누어지는게 1과 자기 자신 밖에 없는 소수라면
{
Sum = Sum + i;
if (flag)
{
Min = i;
flag = false;
}
}
Count = 0;
}
if (Sum == 0)
{
cout << -1 << endl;
return 0;
}
cout << Sum << endl;
cout << Min << endl;
}
return 0;
}
#include <iostream>
#define NUM 10
using namespace std;
//int getDigitCount(int Value)
//{
// int count = 0;
//
//
// while (true)
// {
// Value = Value / 10;
// count = count + 1;
//
// if (Value == 0)
// {
// break;
// }
// }
//
// return count;
//}
int main(void)
{
int A, B, C = 0;
int sum = 0;
int count = 0;
cin >> A >> B >> C;
if (A>=100 and A<1000 and B>=100 and B<1000 and C>=100 and C<1000)
{
sum = A * B * C;
// count = getDigitCount(sum);
int Array[NUM] = {0,};
while (sum!=0)
{
Array[sum % 10] = Array[sum % 10] + 1;
sum = sum / 10;
}
for (int j=0; j<NUM; j++) // Loop for printing the count of each digit.
{
cout << Array[j] << endl;
}
}
return 0;
}
#include <iostream>
#define NUM 9
using namespace std;
int main(void)
{
int Array[NUM] = {0,};
int Max = 0;
int Order = 0;
for (int i=0; i<NUM; i++) // loop for input
{
cin >> Array[i];
}
for (int j=0; j<NUM; j++) // loop for checking boundary
{
if (Array[j] > 100)
{
return 0;
}
}
for (int k=0; k<NUM; k++)
{
if (Array[k] >= Max)
{
Max = Array[k];
Order = k+1;
}
}
cout << Max << endl;
cout << Order << endl;
return 0;
}