Abstract
- 의도 분류는 Spoken Language Understanding(SLU)의 하위 태스크에 해당하며, 의도 분류는 SLU의 또 다른 서브 태스크인 Semantic Slot Filling 태스크로 곧 바로 연계되기 때문에 그 중요성을 가짐.
- ML 기반으론 유저 발화 이해가 어렵다. 때문에 이 논문에선 DL 기반의 의도 분류 연구가 최근까지 어떻게 이뤄져왔는지 분석, 비교, 요약한하고, 나아가 다중 의도 분류 태스크가 어떻게 딥러닝에 적용되는지 기술함.
내가 추출한 키워드: intent detection, mulit-intent detection, spoken language understanding, semantic slot filling.
Introduction
Dialouge System은 크게 5개 파트로 나뉨: ASR, SLU, DM, DG, TTS.
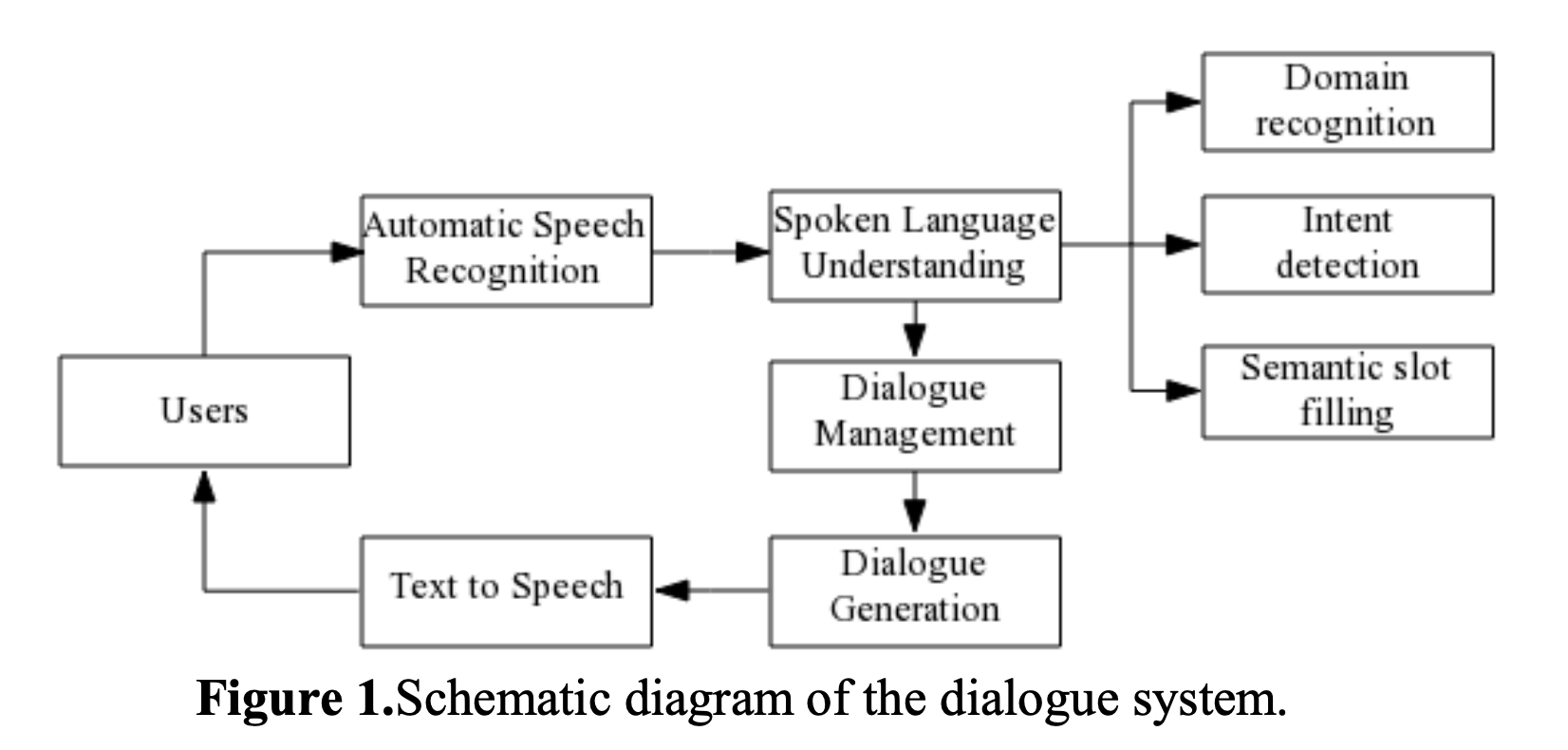
- 유저가 발화 하면 ASR을 통해 유저의 발화를 생성하고 SLU 과정으로 넘어가 말하고자 하는 1. 주제 파악 2. 의도 파악 3. Semantic slot filling을 과정을 거침. 이후 Dialouge Management를 거치고 답변 생성 후 TTS로 유저에게 전달.
- 과거엔 SLU에서 Domain recognition이 없었다. 왜냐면 dialouge system이 specific domain에 국한됐기 때문임. 하지만 최근엔 넓은 범위의 domain을 다루고자 하는 필요성이 있기 때문에 추가 됨.
- Intent detection을 다른말로 Intent classification이라고도 부름.
- 도메인 별, 의도 별 사전 정의된 카테고리를 이용해 유저 발화 분류함. 만약 사전 정의돼 있지 않다면 의도를 잘못 분류해서 잘못된 대답을 하게 됨.
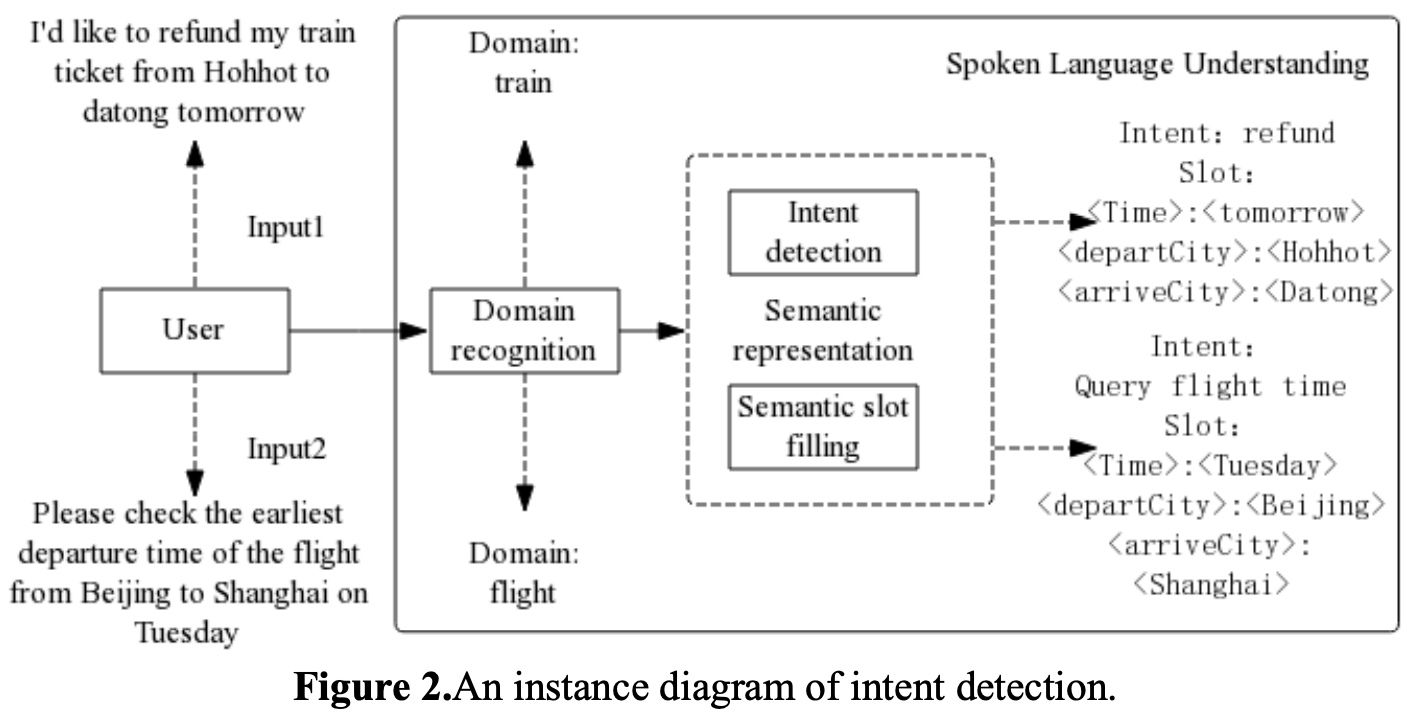
- 의도 분류에서 어려운 것은 다중 Domain이 들어왔을 때 어떤 Domain에 속하는지 명확히 해야함. 그렇지 않으면 Domain보다 더 세분화되어 있는 Intent category으로 접근하기 어려움. 위의 예시로 들면 맥락상 기차 말고 비행기 탈꺼니까 기차 환불하고 가장 빠른 비행기 시간 확인해 달라는 것임. 근데 환불인지 시간 확인인지 Domain 수준에서 파악이 안되면 그 다음 단계인 Intent detection과 semantic slot filling을 못함.
2. Intent Detection의 어려움
2.1 데이터 부족
부족하다.
2.2 화자 표현 광범위, 모호함.
- 일반적으로 구어체 사용하고, 짧은 문장과 넓은 컨텐츠를 다루기 때문에 의도 파악이 어려움. 가령 예를 들어 “I want to look for a dinner place”라고 말하면 저녁 식사 장소 찾고 싶단건데 domain이 명확하지 않음. (사실 이 정도면 충분하다 생각하는데 불확실한가 봄)
- 다른 예시 들자면 Hanting이라는 호텔이 있지만 Hanting Hotel이라고 구체적으로 이야기하지 않으면 이해하기 어려움. 또는 티켓 예약 하고 싶다고만 말하면 비행기 티켓인지 기차 티켓인지 콘서트 티켓인지 알 수 없는 것처럼 화자의 표현이 광범위하거나 모호한 경우가 발생해서 machine이 적절한 답변을 주기 어려움.
2.3 암시적인 의도 분류
의도는 명시적인 것(Explicit)과 암시적인 것(Implicit)으로 나눌 수 있음. 유저가 암시적으로 말하면 진짜 유저 의도가 뭔지 추론할 필요가 생김. 예를 들어 요새 건강에 관심이 있다고 말하면 아 오래살고 싶구나 하고 이해할 수 있어야 하는데 그게 어려움. (내가 만든 예시)
2.4 multiple intents detection
multi-label classification과 비슷하지만 다름. 그 차이점은 multi-label classification은 긴 문장 multiple intnets detection은 짧은 문장을 다룸. 짧은 문장으로 다중 의도 분류 해야해서 어려움. 짧은 발화안에 다양한 의도 분류를 해야하고 그 의도 수를 결정해야 하는게 쉽지 않음.
3. Main methods of intent detection
3.1 전통적인 Intent detection 방법론
- 최근에는 intent detection을 Semantic Utterance Classification (SUC)로 여긴다.
- 1993년엔 rule-based가 제안된 적 있고, 2002-2014까진 통계적으로 피처를 뽑아서 분류했다. 가령 예를 들면 나이브 베이즈나 SVM이나, Adaboost, 로지스틱 회귀를 썼었다. 근데 룰베이스의 경우 정확도는 높지만 새로운 카테고리가 추가될 때마다 수정해야 하는 번거로움이 있고, 통계적인 방식은 피처의 정확도나 데이터 부족문제가 있다. 근데 지금도 화자의 real intent detection은 여전히 어려운 연구 주제다.
3.2 현재 주류 방법론
워드 임베딩, CNN, RNN, LSTM, GRU, Attention, Capsule Network 등이 있다. 전통적인 방법과 비교하면 성능이 크게 좋아졌다.
3.2.1 워드 임베딩 기반 의도 분류
3.2.2 CNN 기반 의도 분류
- CNN 기반으로 해서 피처 엔지니어링 과정을 많이 줄이고 피처 표현력도 좋아졌다. 근데 여전히 CNN으론representation 한계 있다.
3.2.3 RNN 기반 의도 분류
- CNN과 달리 워드 시퀀스를 표현할 수 있음. 2013년에 context 정보 이용해서 Intent detection의 error rate를 줄인 연구가 있음. RNN은 기울기 소실과 기울기 폭발 문제가 있고 이 때문에 long-term depdendence 문제를 초래함.
- 그래서 이 문제 해결하려고 LSTM이 나옴. LSTM가지고 ATIS 데이터셋 (Air Travel Information System)에서 RNN보다 에러율 1.48%을 줄임.
- GRU는 LSTM 개선한 모델임. ATIS와 Cortana 데이터셋에서 성능이 둘다 같았지만 GRU가 파라미터가 적었음.
- 2018년엔 짧은 텍스트로 인해 발생하는 data sparse 문제를 해결하기 위해 Biterm Topic Model(BTM)과 Bidirectional Gated Recurrent Unit(BGRU) 기반 멀티턴 대화 의도 분류 모델이 제시됨.
- 위 두 모델을 합친 모델은 의료 의도 분류에서 좋은 성능을 냈음.
. . .
3.2.6 캡슐 네트워크 모델 기반 의도 분류
캡슐 개념은 CNN의 표현 한계 문제를 해결하기 위해 2011년에 힌튼에 의해 제시됐었음. 캡슐은 vector representation을 가짐. 이후 2017년에 CNN scalar output feature detector를 vector representation capsule로 대체하고 max pooling을 프로토콜 라우팅으로 대체하는 캡슐 네트워크가 제안됨. CNN과 비교하자면 캡슐 네트워크는 entity의 정확한 위치 정보를 유지함.
결론을 말하자면 capsule network는 텍스트 분류 태스크 잘 수행하고, multi-label 텍스트 분류에도 잘 동작함.
. . .
4. 의도 분류 평가 방법
현재 Intent Detection은 Semantic Discourse Classification 문제로 여겨짐. 결론은 F1-score 사용함.
5. 성능 비교
아래는 다른 연구 논문에서 가져온 성능 비교 결과임. 데이터셋은 SNIPS와 CVA(Commercial Voice Assistant)를 사용했음. 참고로 SNIPS는 영어 데이터셋이고 CVA는 중국어 데이터셋임.
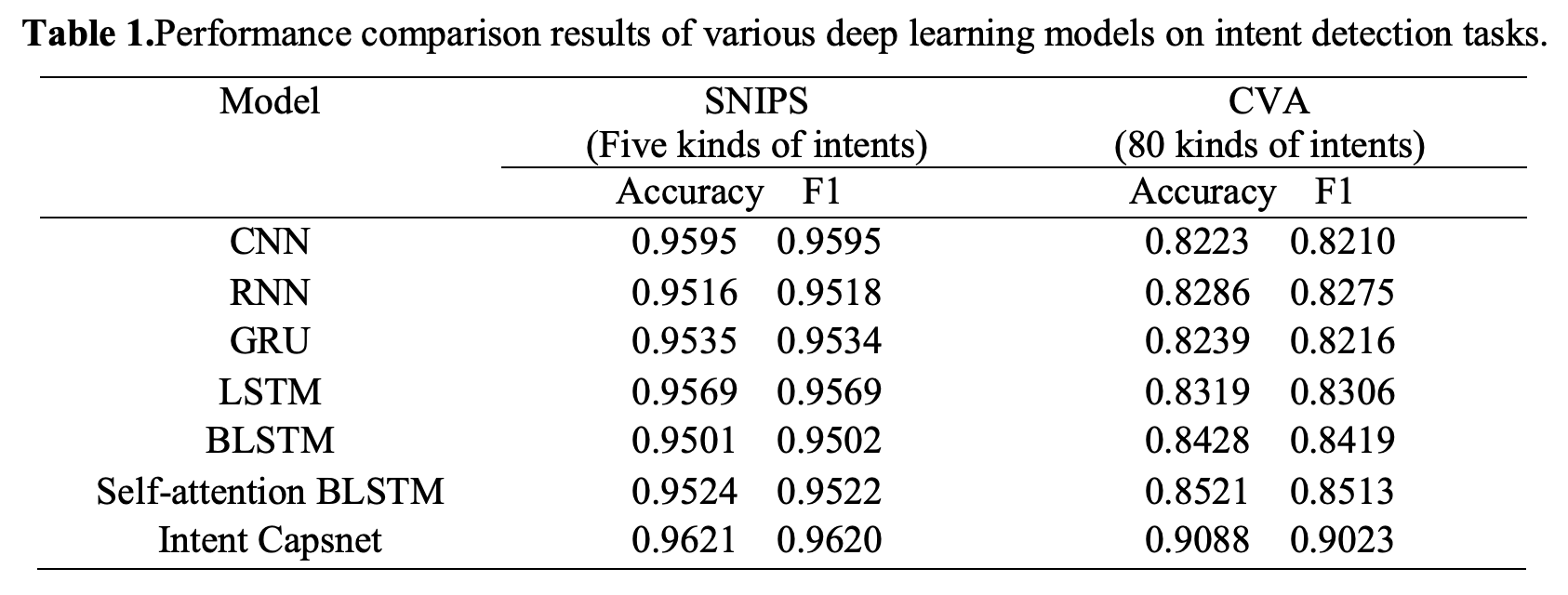
Intent Capsnet이 가장 성능이 좋더라.
Conclusion
- 머신러닝 기반의 의도 분류 태스크는 깊이 이해 못한다. 그래서 딥러닝 기반 의도 분류 태스크가 성능이 좋다. capsule network model이 의도 분류 태스크에서 좋은 성능을 내고, multi-label classification도 잘한다. self-attention 모델은 의도 분류 과정에서 문장의 다양한 semantic feature들을 추출할 수 있다.
- 의도 분류는 e-commerce, travel consumption, medical treatment, chat에도 적용되고 있으며, 침입 탐지 시스템과 같은 네트워크 보안 분야에서도 적용된다.
- 전통적인 dialouge system은 주로 single intent detection만 가능하다. 하지만 다양한 의도는 셀 수 없이 많으므로 multi intent detection이 가능하도록 연구가 필요하다.
궁금해진 것
- Semantic slot filling의 과정은 구체적으로 어떻게 이뤄지는가?
- Dialouge Management란 무엇이고 어떻게 동작하는가?
- Dialouge Generation 과정은 구체적으로 어떻게 이뤄지는가?
- task-oriented vertical domain이 무엇인가? vertical이 있으면 horizontal domain도 있을 것인데 각각은 무엇인가?
알게 된 것
- 도중에 fine-grained라는 말이 나옴. 이건 잘게 쪼갠 것을 의미함. 반면 coarse-grained는 덩어리째를 의미함.
한 줄 평
- 큰 틀에서 연구가 어떻게 이뤄지는지 대략적으론 알 수 있어서 좋았지만 Dialougue System의 구체적으로 어떻게 이뤄지는지 나와있지 않고 데이터셋을 잘 정리해서 소개하지 않아서 아쉬움.
'Artificial Intelligence > 논문 리딩&구현' 카테고리의 다른 글
| [논문 구현] GoogLeNet 파이토치로 구현하기 (0) | 2022.09.12 |
|---|---|
| [논문 구현] VGGNet 파이토치로 구현하기 (0) | 2022.09.08 |
| [논문 구현] AlexNet 파이토치로 구현하기 (2) | 2022.09.07 |
| [논문 리뷰 #3] Dialogue Management in Conversational Systems: A Review of Approaches, Challenges, and Opportunities (0) | 2022.08.19 |
| [논문 리뷰 #1] Cross-Lingual Ability of Multilingual Masked Language Models: A Study of Language Structure (0) | 2022.04.17 |