먼저 이 논문에 대한 메타데이터는 아래와 같습니다. 2022.04.17 시점으로 아직 저널이나 학회에 등록되지 않은 논문으로 arXiv에 우선적으로 업로드된 논문입니다.
| Element | Description |
| Link | https://arxiv.org/pdf/2203.08430.pdf |
| Venue | arXiv |
| Year/Month | 2022.03 |
| Affiliation | Beihang University(1) Microsoft(2) |
| Author | Yuan Chai(1), Yaobo Liang, Nan Duan |
| Keyword | Cross-Lingual, Multilingual, Language Structure, typological similarity |
먼저, 이 논문을 한 마디로 요약하면 typological similarity는 크게 중요한 요소가 아니라는 것을 주장하는 논문입니다.
이 논문의 연구 배경은 Multilingual Masked Languagde Model(이하 Multilingual MLM)이 어떻게 별도의 Cross-lingual 지도학습 없이도 좋은 성능을 내는지에 대한 물음을 기반으로 시작되었습니다. "How multilingual is Multilingual BERT?"(이하 mBERT) 이라는 multilingual의 시작이 되는 논문에서 multilingual 모델의 성능은 언어학적인 유사성(typological similarity)이 높을수록 좋은 성능이 나온다고 하였지만 이 논문에서는 이를 정면으로 반박합니다. 그 이유는 언어학적 유사성이 높다는 것은 정확한 통제변인이 이루어지지 않았음을 지적합니다.
--------------------------------------------------------------------------------------------------------------------------------
예를 들면 mBERT 논문에서는 언어의 문법 구성인 SVO(주어, 동사, 목적어)와 AN(형용사, 명사)만 고려했습니다. 세계의 많은 언어는 SVO 순을 쓰거나 SOV 순을 쓰는 언어가 존재하고 AN 순을 쓰거나 NA 순을 사용하는 언어가 존재합니다. 하지만 이 논문에서는 다른 품사(전치사, 부사, 접속사, 한정사) 등을 모두 고려하지 않은 실험 결과라고 말합니다. 아래는 mBERT 논문에서 가져온 실험결과 입니다.

(a)는 SVO의 어순을 가진 언어끼리 그룹화하고 SOV의 어순을 가진 언어끼리 그룹화해서 zero-shot trasnfer를 수행할 때의 macro-averaged POS accuracy를 나타냅니다. (b) 또한 (a)와 동일한 맥락입니다. 한 마디로 같은 어순을 가진 그룹끼리는 성능이 좋지만 다른 어순을 가지면 성능이 떨어진다는 것을 의미합니다. 즉, multilingual MLM이 어순이 다른 것은 학습하지 못한다는 것을 보였습니다.
--------------------------------------------------------------------------------------------------------------------------------
하지만 이 논문에서는 mBERT에서 언어학적 유사성으로 가져온 피처가 2개밖에 되지 않는다고 이야기합니다. 즉, 다시 한 번 말해, 하나의 언어를 구성하는데는 SVO와 AN만 있는 것이 아니라 전치사, 부사, 접속사, 한정사 등과 같은 여러 품사가 존재하는 데 모두를 고려하지 않고 두 개의 피처만 가지고 유사성을 비교했다라는 것을 지적하는 것입니다.
이에 대해서 저자들은 정확한 실험을 위해선 통제 변인을 잘 설정하는 것이 중요하다고 이야기하며 artificial sentence를 아래와 같이 생성합니다.

예를 들면 영어가 주어 동사 목적어 순일 때 주어 목적어 동사로 영어에서 맞지 않는 문법인 인공의 문장을 데이터셋으로 만듭니다. 마찬가지로 전치사 명사를 명사 전치사로, 형용사 명사를 명사 형용사 순으로 바꿉니다. 참고로 이 때 사용한 83A, 85A, 87A 언어 구조와 관련한 피처로 세계 언어 구조에 대한 데이터베이스인 WALS (World Altas of Language Structure)의 피처를 기준으로 하였습니다. (총 192개의 피처가 존재)

위와 같이 WALS의 피처를 기준으로 인공의 문장을 생성한 뒤 6개의 target언어에 대해 평가한 결과는 아래와 같습니다.

6개의 target 언어는 ru(러시아), hi(힌디어), tr(터키), es(스페인), th(태국), vi(베트남)입니다. 여기서 표 한 부분만 해석해도 됩니다. 영어와 어순이 같은 러시아어의 비교표를 기준으로 설명하겠습니다. 먼저 source는 모두 영어만 사용했습니다. 영어 데이터를 변형하지 않은 en의 경우 소스를 순수 영어로하고 target을 러시아어로했을 때 transfer 성능이 83.93%과 73.90%이 나왔습니다.
하지만 영어의 어순 VO를 OV로 변경한 en-OV의 결과를 확인하면 어순을 바꿨음에도 불구하고 어순이 같았던 러시아어에 대해 transfer 성능이 오히려 높아지는 결과를 확인할 수 있습니다. 마찬가지로 전치사를 사용하는 영어에서 후치사로 바꾼 en-Post에서도 오히려 더 성능이 높아진 것을 확인할 수 있습니다. AN 또한 명사, 형용사로 바꾼 en-NA에서는 다소 낮아짐으로써 결과의 일관성이 없음을 볼 수 있습니다. 즉, 이 표가 말하고자 하는 것은 한마디로 mBERT 논문에서 주장했던 typological similarity가 중요하지 않다는 것을 시사하고 있습니다.
그러면서 가장 중요한 것은 composition이라고 말합니다. 앞서서 미리 알려드리지 못했으나 이 논문에서는 크게 언어학적인 속성 3개에 대해 실험을 진행했습니다. 세 언어학적 요소는 constituent order, composition, word co-occurrence 입니다. 위 어순을 바꾼 실험이 constituent order에 대한 실험이었습니다. 참고로 constituent order는 구성 순서를 의미하는 것으로 아래의 그림에 있는 NP, VP, PRP, VBD와 같은 constituent의 순서를 변경했을 때의 multilingual 모델의 성능을 보는 것입니다.
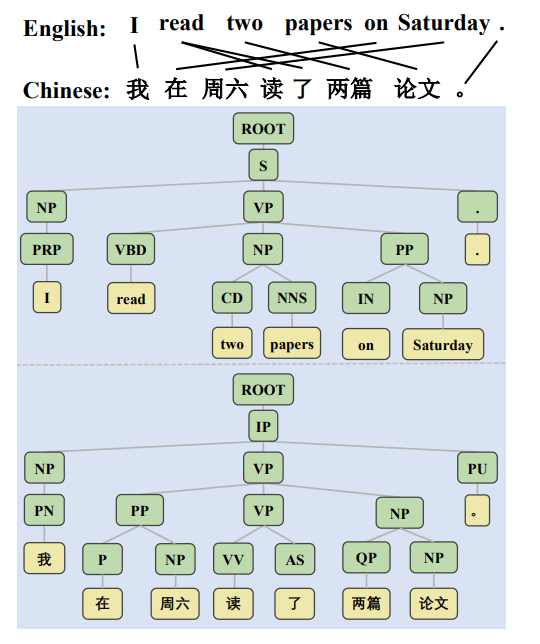
composition 같은 경우는 조금 더 친절한 설명이 있지 않아 지금도 이해가 어려운 부분이 있는데요, 논문에서 제시하는 예시는 "two"라는 단어와 "papers"라는 단어를 합치면 "two papers"와 같은 조금 더 복잡한 단어를 만들 수 있다고 합니다. 따라서 나이브하게 합성어 정도라고 이해하고 있습니다.
마지막으로 word co-occurrence 같은 경우는 동시 발생으로 일종의 관용구나 의미적 유사성을 나타내는 속성이라고 합니다. 예를 들면 "티끌 모아 __"하면 태산이 나오는 것 처럼 티끌과 태산은 함께 나오는(co-occurrence) 단어다 정도로만 이해를 했습니다.
consituent order를 변형한 결과를 보여준 것관 달리 composition과 word co-occurrence에 대한 실험은 하나의 표에 결과를 함께 보여주는데요 그 표는 다음과 같습니다.
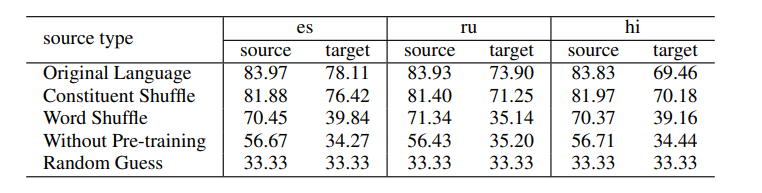
Original Language 같은 경우는 소스언어인 영어 데이터를 변형하지 않았을 때의 결과를 나타냅니다. Constituent Shuffle 같은 경우는 constituent order를 제거했을 때의 성능을 나타내구요, Word Shuffle 같은 경우는 constituent order와 composition을 제거 했을 때의 결과를 나타냅니다.
여기서 중요한 것은 constituent order를 제거했을 때는 성능 저하가 미미하지만 composition과 함께 제거할 경우 target 언어에 대해 language transfer 성능이 확 떨어지는 것을 볼 수 있습니다. 이 결과를 바탕으로 저자들은 Multilingual MLM의 성능을 나타내는 언어학적인 세 요소 중에 가장 중요한 것이 composition이라고 합니다.
이 때까지 내용을 총 정리하면 크게 아래 두 줄로 요약할 수 있습니다.
1. mBERT에서 주장한 typological similarity가 높을 수록 성능이 좋다는 것은 사실이 아니며 잘못된 변인 통제에 의해 실험이 이루어졌다.
2. multilingual MLM의 성능을 좌우짓는 요소는 composition이다.
전반적으로 논문을 읽으며 다소 불친절한 설명이 있고, 직관적으로 파악하기 어렵다는 데 있어 아쉬운 측면은 있습니다. 예를 들면 Word Shuffle에 대해 조금 더 상세한 설명이 덧붙였으면 더 나은 논문이 되지 않았을까 싶습니다. 하지만 그럼에도 불구하고 잘못된 변인 통제를 기반으로 수행한 mBERT의 실험 결과를 정정한다는 측면에서는 의미 있는 연구라 생각이 듭니다.
'Artificial Intelligence > 논문 리딩&구현' 카테고리의 다른 글
| [논문 구현] GoogLeNet 파이토치로 구현하기 (0) | 2022.09.12 |
|---|---|
| [논문 구현] VGGNet 파이토치로 구현하기 (0) | 2022.09.08 |
| [논문 구현] AlexNet 파이토치로 구현하기 (2) | 2022.09.07 |
| [논문 리뷰 #3] Dialogue Management in Conversational Systems: A Review of Approaches, Challenges, and Opportunities (0) | 2022.08.19 |
| [논문 리뷰 #2] Review of Intent Detection Methods in the Human-Machine Dialogue System (0) | 2022.08.18 |