
1. GAN 모델 개요
GAN이란 무엇인가? GAN은 Generative Adversarial Nets이라는 논문을 통해 나온 모델로 위와 같이 진짜와 동일해 보이는 이미지를 생성하는 모델이다. 그렇다면 우선 GAN은 언제 만들어졌고 어떠한 과정을 거쳐 성장하게 되었는가? 아래는 GAN의 History를 나타내는 그림이다.

GAN은 2014년 arXive에 처음 올라온 논문이며 이후, 인공지능 관련 학회인 NIPS에서 정식으로 게재되었다. 처음 GAN 모델이 소개된 이후 수 많은 GAN의 후속 연구들이 이어지고 있는 것을 확인할 수 있다. 위 [그림 2]에 기재된 연구의 경우 대표적인 논문들을 기재한 것이며 이외에도 포함되지 않은 연구들이 여럿 존재한다.
GAN은 포스팅 되는 2021.09.14 시점으로 약 35,000회의 인용이 있는 것을 확인할 수 있고. 화두가 되었었던 Tensorflow가 발표되었던 논문보다도 더욱 많은 관심을 받고 있는 것을 확인할 수 있다.


얀르쿤(Yann LeCun)은 GAN 모델이 지난 20년간 딥러닝 분야에서 가장 멋진 아이디어라고 말한다.

그렇다면 이 GAN이라고 하는 모델은 왜 각광받고 있고 후속 연구들이 이어지고 있는 것인가?
여러 이유가 있지만 그 중 단연 핵심이라 생각되는 것은 바로 기존의 지도학습의 한계 때문이다.
기존의 지도학습의 경우 데이터셋이 필수적으로 수반된다. 하지만 이러한 데이터셋을 만드는 과정에 드는 시간 등의 비용의 한계가 있기 때문에 어렵다는 것이다. 하지만 GAN은 지도학습에 사용되는 라벨 없이도 학습 가능한 비지도학습에 속하며, 데이터를 직접 생성하는 큰 장점을 가진다. 따라서 GAN의 경우 비지도학습의 선두주자로 불리고도 있으며, 몇몇의 사람들은 비지도학습이 더욱 각광받는 기술이 될 것이라 전망한다.

아래는 처음 GAN이 나왔을 당시 논문에서 제시한 GAN 모델의 결과 중 일부이다.


왼쪽 그림은 MNIST 데이터셋을 학습하여 오른쪽 노란박스와 같이 모델이 숫자를 생성할 수 있음을 보였다. 또한 오른쪽 그림은 TFD(Torronto Faces Dataset)을 이용하여 학습한 뒤 GAN 모델이 사람의 얼굴을 생성할 수 있음을 보였다.
초기의 결과물은 색채가 없고 화질이 좋지 않았다. 하지만 GAN 모델의 단점을 극복하는 연구들이 intensive하게 진행됨에 따라 아래와 같이 진짜 이미지와 구분하기 힘들 정도로 발전하는 단계가 되었다.

우리는 여기서 이러한 GAN 모델의 성능을 발전을 가능케 했던 대표적인 연구들을 살펴보고자 한다. 이를 위한 첫 단계로 모카님의 블로그에서 아래와 같은 GAN 연구의 분류체계를 확인할 수 있었다.

모카님은 GAN을 크게 3가지로 Unconditional GAN, Conditional GAN, Super Resolution으로 나누었다. 분류체계의 기준은 어떻게 정하였는지는 잘 모르겠다. 하지만 서칭 결과 더 체계적이라 판단되는 분류체계는 찾을 수 없었다. 따라서 이를 기반으로 주요 연구들을 살펴보았다.
우리가 알아보고자 하는 대표적인 연구들은 아래와 같다.
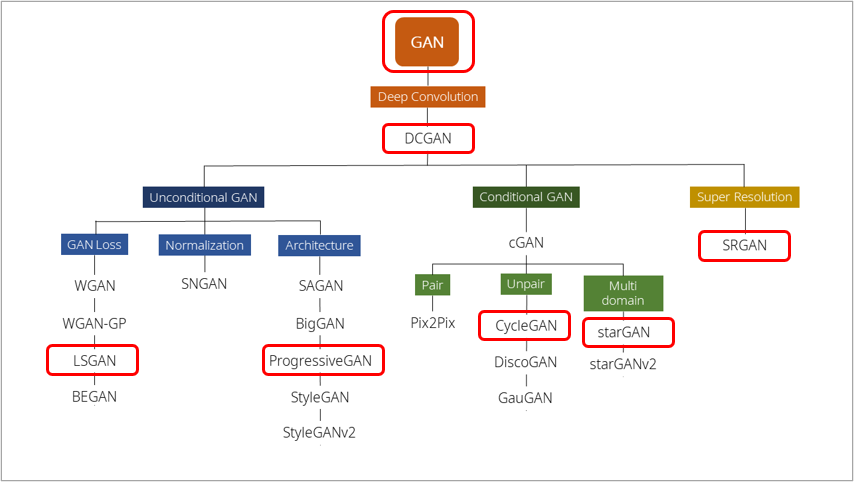
먼저 위 연구에 대해 한마디로 정리하면 다음과 같다.
DCGAN: 얀르쿤이 GAN을 낳았다면 Facebook은 DCGAN을 통해 모든 후속연구가 이어질 수 있도록 키운 모델
LSGAN: 기존 GAN에 적용된 Loss의 수식을 Least Square loss로 바꾸어 성능 향상을 도모한 모델
PGGAN: 기존 모델과 달리 점진적으로 학습하여 1024x1024의 고화질 이미지 생성을 가능하게 한 모델
CycleGAN: 역함수 개념과 순환일관성 손실 함수를 이용해 특정 이미지의 화풍을 다른 이미지에 적용할 수 있게 한 모델
StarGAN: 단일 생성자/판별자로 Domain Transfer가 가능하도록 만든 모델
SRGAN: GAN 모델의 인지적 해상도를 높여 고화질 이미지 생성을 가능하게 한 모델
2. Original GAN
2.1 Origianl GAN의 아키텍처
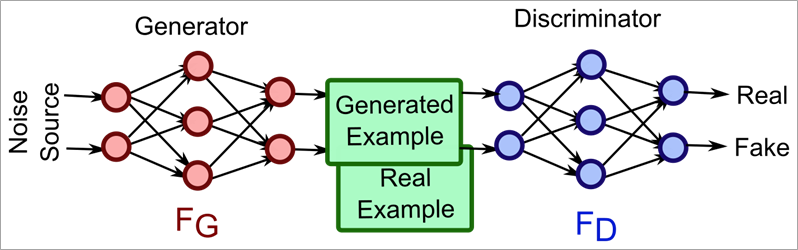
먼저 GAN의 아키텍처를 확인해보면 아래의 왼쪽 그림과 같이 간단한 형태를 가진다.
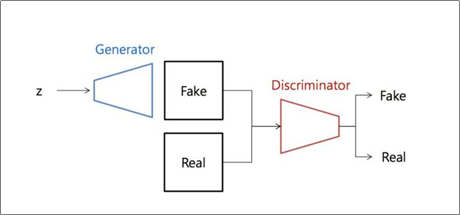
GAN은 크게 2가지 모델로 이루어져 있다. Generator와 Discriminator로 이루어져 있어 동시에 두 개의 모델을 훈련하는 것이 특징이다.
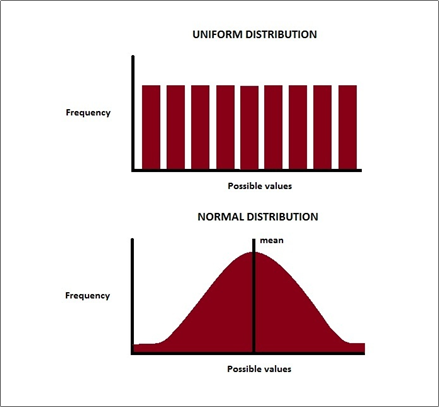
여기서 z라고 하는 것은 랜덤 벡터 z를 의미하는 것으로 오른쪽 그림의 uniform distribution이나 normal distribution을 따른다고 한다.
이 랜덤 벡터 z를 Generator의 입력으로 넣어 Fake를 생성한다. 이후 Real의 경우 실제 데이터셋을 의미하는 것으로 생성된 Fake와 실제 Real 이미지를 Discriminator의 입력으로 넣게 되면 Fake 또는 Real이라고 출력하게 된다.
GAN은 최종 출력인 Fake와 Real의 확률이 1/2에 수렴하여 진짜와 가짜를 구분할 수 없도록 학습하게 된다.
GAN을 더욱 이해하기 위해서는 확률밀도함수의 개념을 알아야 한다. 아래는 어떤 모종의 확률밀도함수를 나타내는 그래프이다.
2.2 확률 밀도 함수(PDF, Probability Density Function)
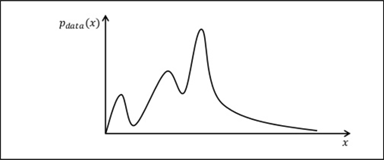
먼저 확률밀도함수란 통계학에서 사용되는 개념으로, 용어에서부터 직관적으로 이해할 수 있듯 확률변수의 분포를 나타내는 것으로, 연속확률변수 x에 대한 f(x)를 의미하는 것이라 볼 수 있다.
가령 최윤제님의 발표자료에 있던 예시를 가져온 것은 아래와 같다.
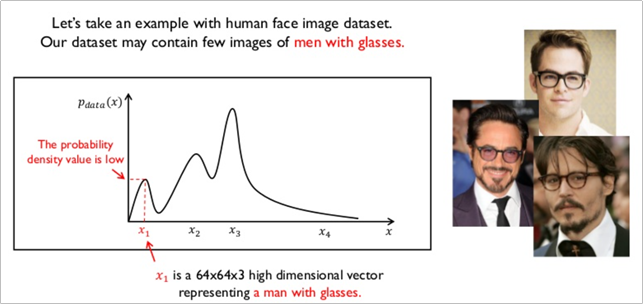
가령 GAN 모델에 안경을 낀 남성의 데이터를 학습시킨다고 할 경우, 안경을 낀 남성의 특징은 x1이라고 하는 벡터가 가지게 된다.
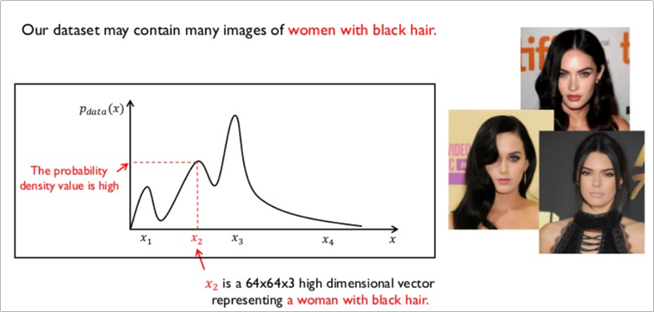
흑발 여성의 데이터셋을 학습 시킬 경우, 흑발 여성에 대한 특징을 x2라고 하는 벡터가 가지게 되며
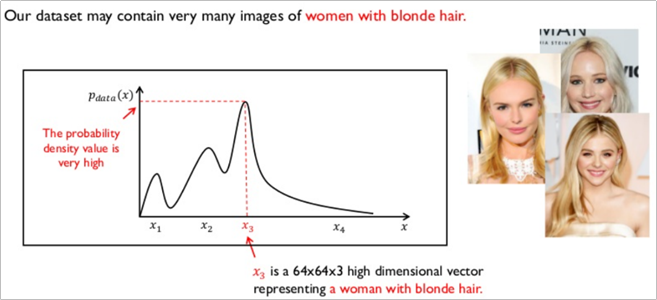
금발 여성의 데이터셋을 학습 시킬 경우 GAN 모델은 금발 여성에 대한 특징을 x3라고 하는 벡터에 학습시키게 된다.
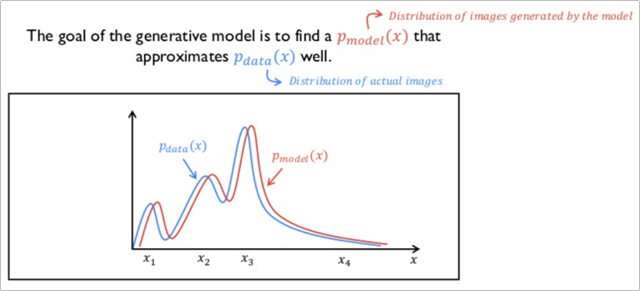
결론적으로 이렇게 학습된 확률밀도함수가 있을 때, 아래와 같이 GAN 모델이 생성한 이미지가 가지는 확률밀도함수와 둘 사이의 차이가 줄어들면 줄어들 수록 원래의 실제 이미지와 같아지는 원리라고 할 수 있다.
실제 Original GAN의 논문에 실린 그림은 아래와 같다.
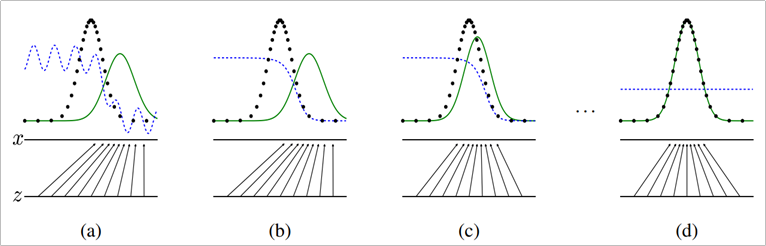
※ 검은 점선: 원 데이터의 확률분포, 녹색 점선: 생성자가 만들어 내는 확률분포, 파란 점선: 판별자의 확률분포
파란 점선인 판별자(Discriminator)는 학습이 진행됨에 따라 GAN이 만들어내는 녹색 점선(Generator)와 분포가 동일해지는 것을 확인할 수 있다.
따라서 (d)의 단계에서는 판별자가 Real/Fake를 분류하게 되어도 확률이 같기 때문에 분류를 해도 소용 없게 되며 생성자는 실제 데이터와 매우 흡사하게 이미지를 생성할 수 있게 된다.
2.3 수식으로 이해하는 GAN
GAN은 생성자와 판별자의 경쟁구도이며, 경쟁을 통해 균형점(nash equilibrium)을 찾는 것이 목표라 할 수 있다.
GAN에서 사용되는 수식은 아래와 같이 간단한 형태이다.
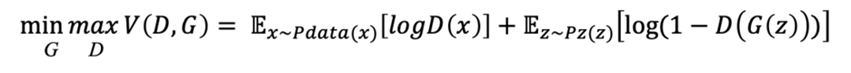
G(Generator)를 minimize하고 D(Discriminator)를 maximize한다고 생각하면 된다.
수식을 가장 빠르게 이해하는 방법 중 하나는 수식에 0을 만드는 요소라던지 극값을 넣어 간단한 형태로 환원시키는 것이다. 먼저 수식 내의 값들을 0으로 만들어 보자.
Case 1: D(x)를 1로 만드는 경우 (판별자가 모든 것을 분류 가능한 경우)
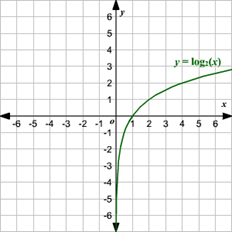
D(x)=1인 상황은 logD(x)를 0으로 만드려는 것과 같다. D(x)=1이라는 의미는 판별자가 모든 것을 다 올바르게 Real/Fake 분류를 할 수 있음을 의미한다. 이렇게 되면 동시에 D(G(z))=1이 된다. 그 이유는 G가 아무리 진짜와 같은 이미지를 생성하더라도 D가 100%의 확률로 전부 잡아낼 수 있기 때문이다. 결과적으로 수식의 앞 부분은 logD(x)는 0이 되어 사라지고, 뒷 부분은 log(1-1)이 되어 무한에 수렴하게 된다. (log 함수 그래프 참조)
Case 2: G(z)를 1로 만드는 경우 (판별자가 모든 것을 분류하지 못하는 경우)
G(z)=1인 상황은 생성자 G가 실제와 구분하지 못할 정도로 흡사하게 만들어 판별자 D가 하나도 구분하지 못하는 상황과 같다. 이렇게 되면 수식의 앞 부분인 logD(x)는 log0이 되어 무한에 수렴하게 되고, 뒷 부분인 log(1-D(G(z))는 0이 되어 사라지게 된다. (이 상황의 경우 minmax요소가 바뀜. min→D, max→G)
2.4 코드로 이해하는 GAN
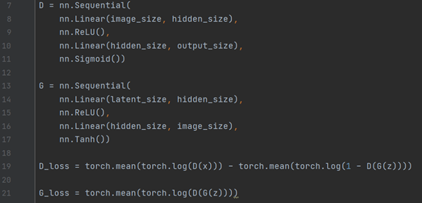
GAN의 수식을 코드로 표현할 경우 아래와 같아진다.
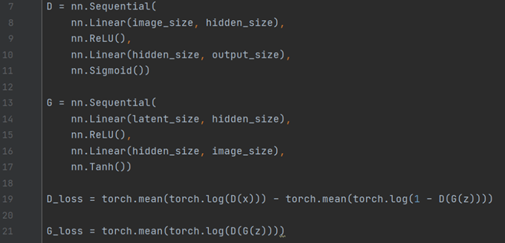
크게 4 영역으로 판별자 D의 layer, 생성자 G의 layer, D의 loss, G의 loss 부분으로 나뉜다. 핵심은 loss를 표현하는 영역으로 앞서 설명한 수식을 이용하여 위와 같이 작성할 수 있다.
2.5 실험 결과
결과적으로 앞서보았던 그림을 포함하여 크게 3종류인 (MNIST, TFD, CIFAR-10)의 데이터셋에 대해 학습하고 이를 생성자 모델을 사용하여 시각화 하는 것을 확인할 수 있다.

숫자와 얼굴의 경우 어느정도 식별 가능한 형태라 볼 수 있으며, 동물/사물에 대해서는 비교적 추상적으로나마 생성해내는 것을 확인할 수 있다.
2.6 한계점
기존의 GAN의 한계점은 크게 2가지로 나뉜다.
1. (성능 평가)
GAN 모델의 성능을 객관적 수치로 표현할 수 있는 방안이 부재했다. GAN의 경우 결과 자체가 새롭게 만들어진 데이터이기 때문에 비교 가능한 정량적 척도가 없었다는 것이다.
2. (성능 개선)
GAN은 기존 네트워크 학습 방법과 다른 구조여서 학습이 불안정했다. GAN은 Saddle Problem 혹은 Minmax를 풀어야 하는 태생적으로 불안정한 구조이기 때문이다.
실제 2016년 NIPS에서도 GAN의 안정화가 메인화두였다고 한다.
하지만 이의 두 단점을 모두 개선하여 GAN의 후속 연구가 줄줄이 이어나올 수 있도록 한 연구가 Facebook에서 개발한 DCGAN(Deep Convolutional GAN)이다.
2. DCGAN (Deep Convolutional GAN)
2.1 DCGAN의 연구 배경
기존의 GAN으로는 성능이 잘 나오지 않았는데 그 이유는 간단하게 Fully-Connected 되어 있는 구조이기 때문이다.
따라서 Facebook은 DCGAN이라고 하는 모델을 내놓으며 Fully-Connected 구조를 CNN으로 바꾸어 GAN의 성능 향상을 도모한 것이 핵심이라 할 수 있다.
2.2 DCGAN의 아키텍처
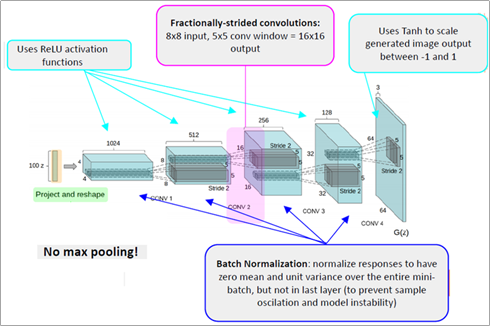
아래는 DCGAN의 Generator에 해당하는 아키텍처이다.
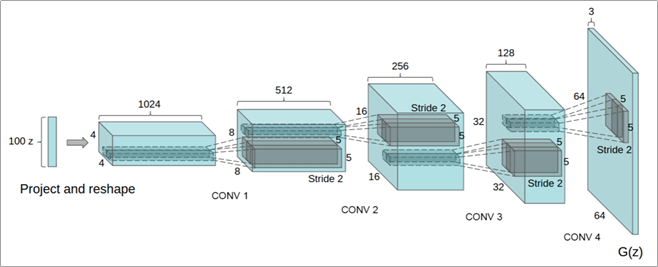
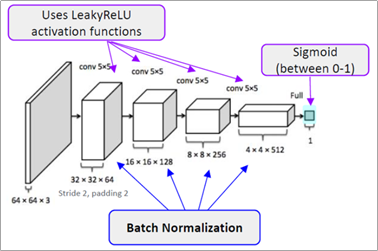
DCGAN은 생성자 모델에 Transposed Convolutional Network를 사용하여 Up-Sampling하는데 사용하였다. 위 그림에는 나와 있지 않지만 판별자 모델에는 단순 Convolutional Network를 사용한 것이 특징이다.
Trasnposed Convolutional Network의 경우 기존의 컨볼루션 네트워크처럼 줄어드는 것이 아닌 확대되는 것이라 할 수 있다. 아래 왼쪽은 기존의 컨볼루션 네트워크고 오른쪽의 경우 Transposed 컨볼루션 네트워크이다.
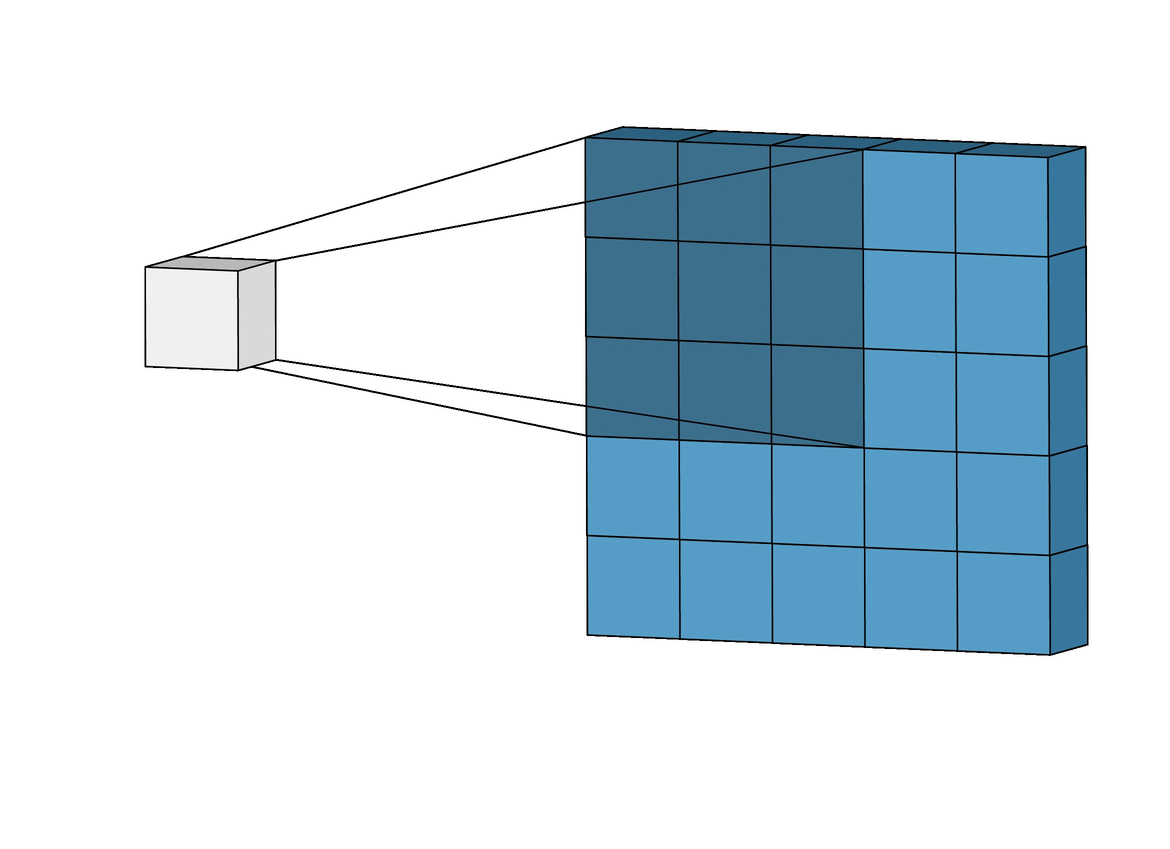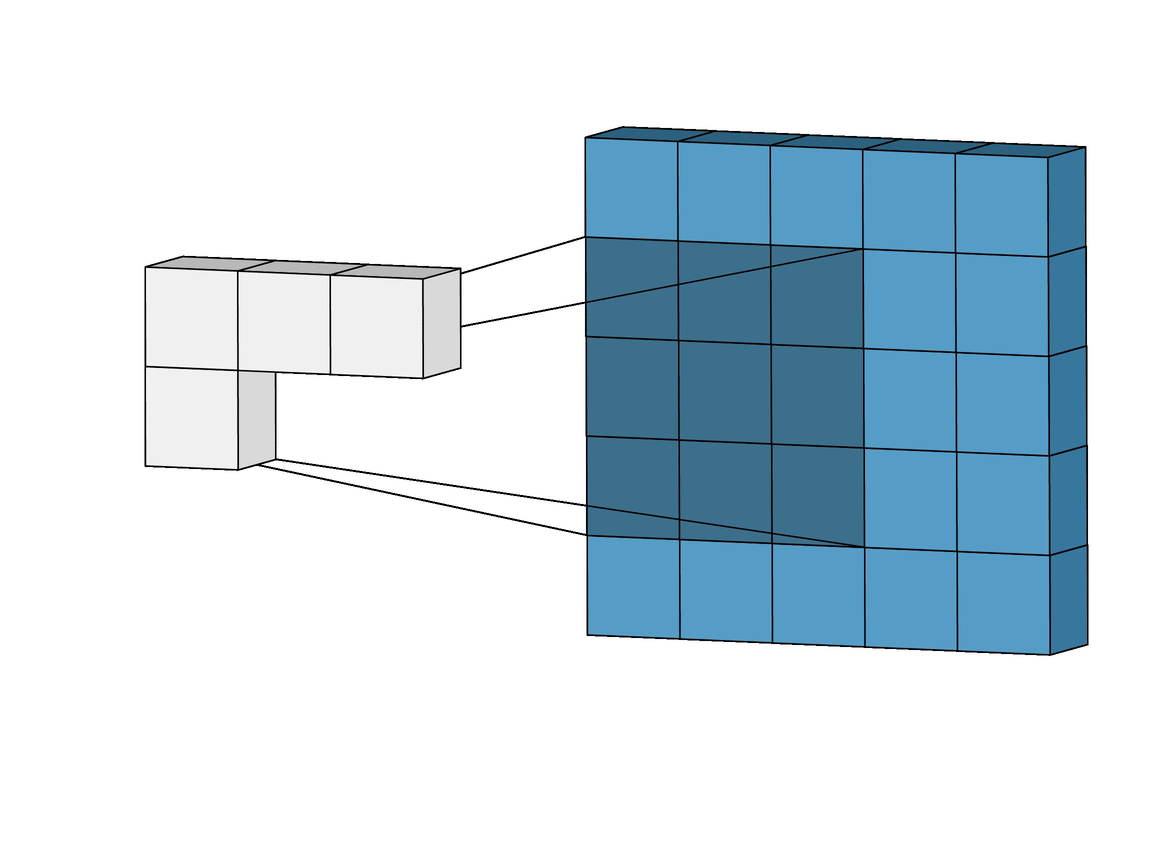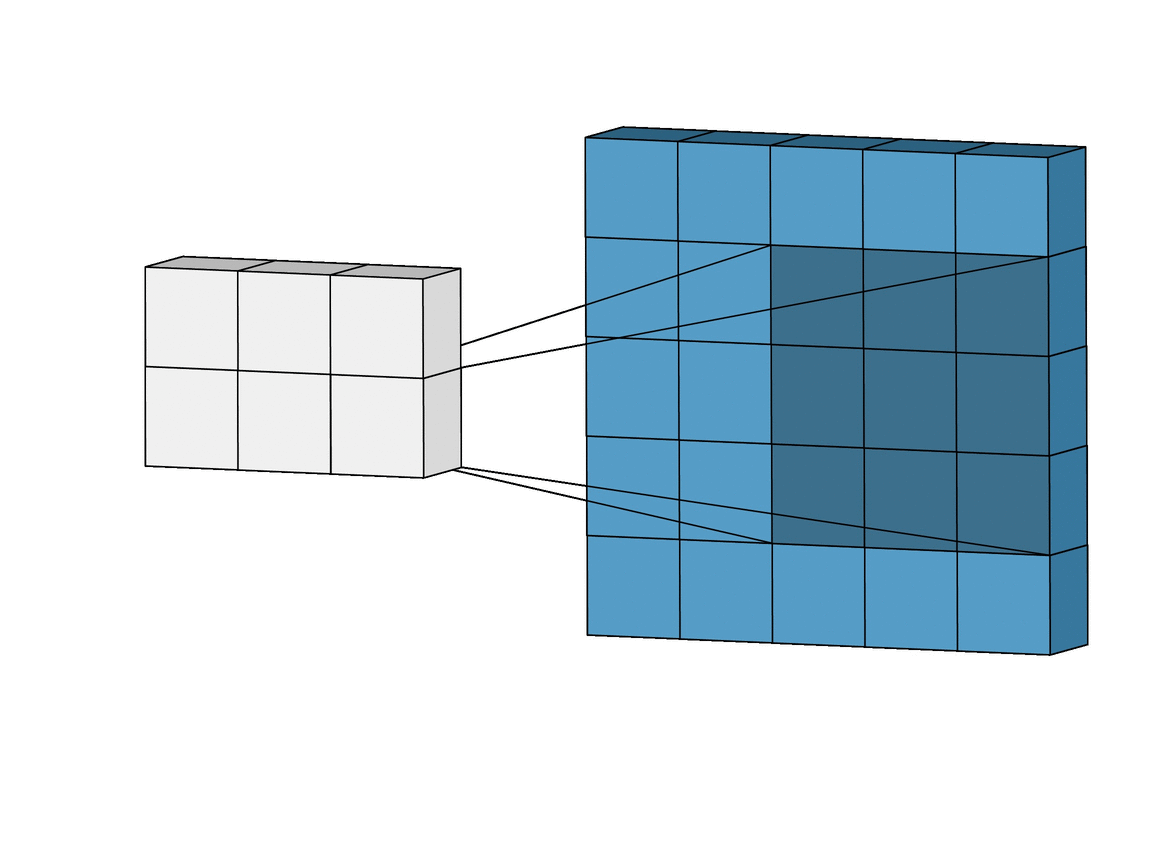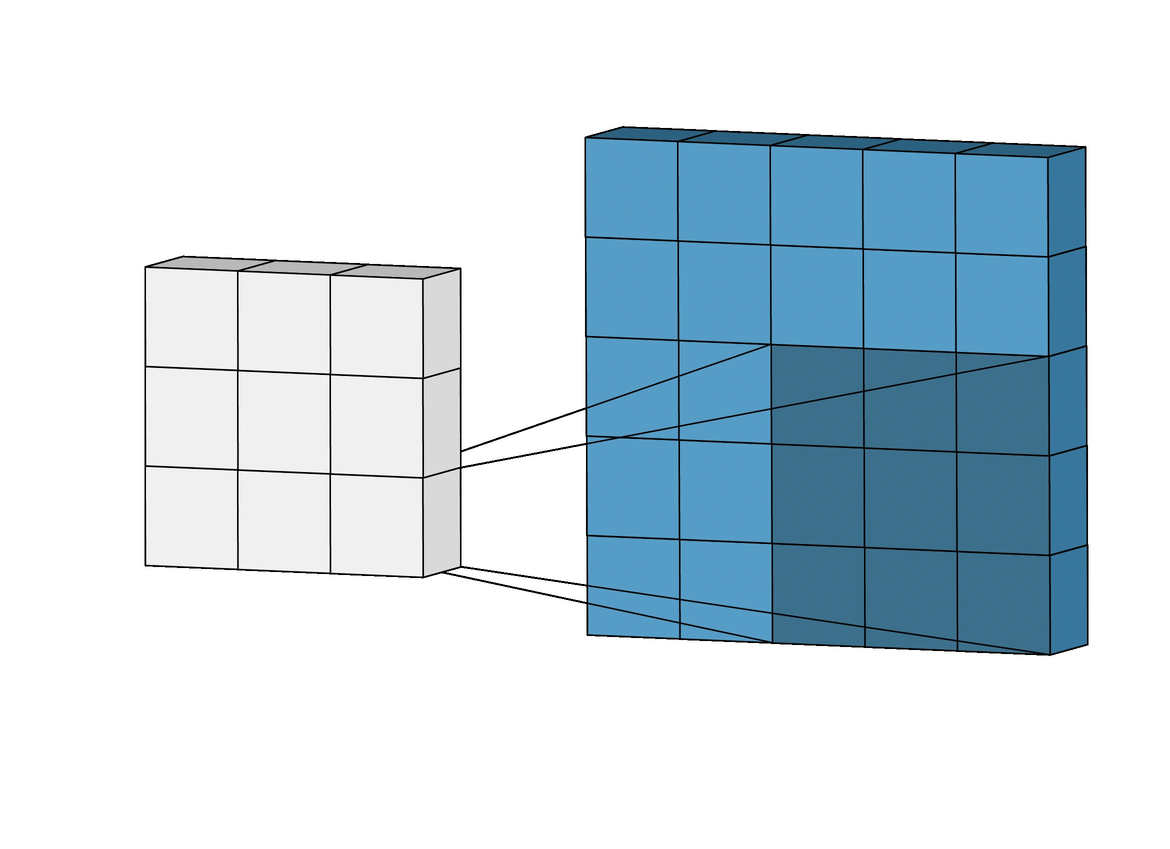
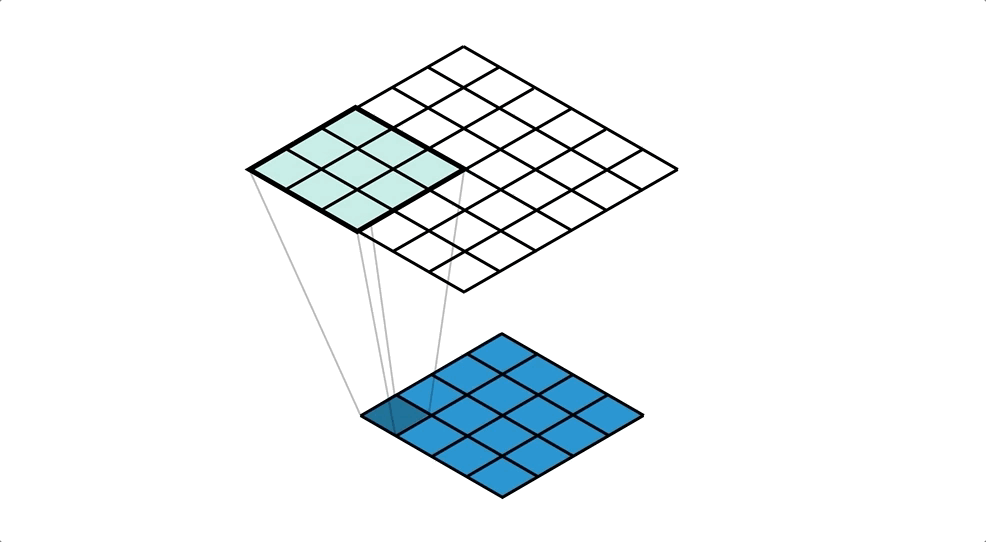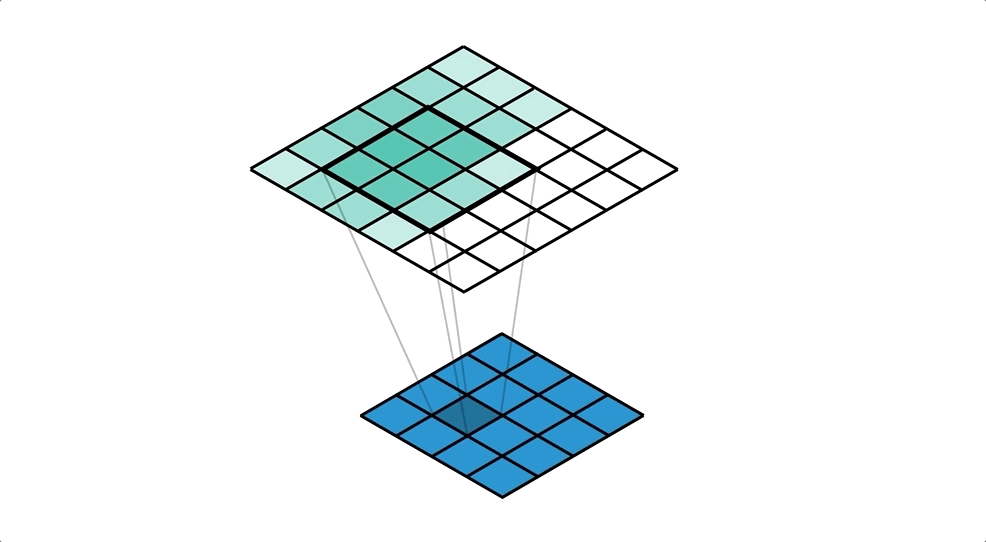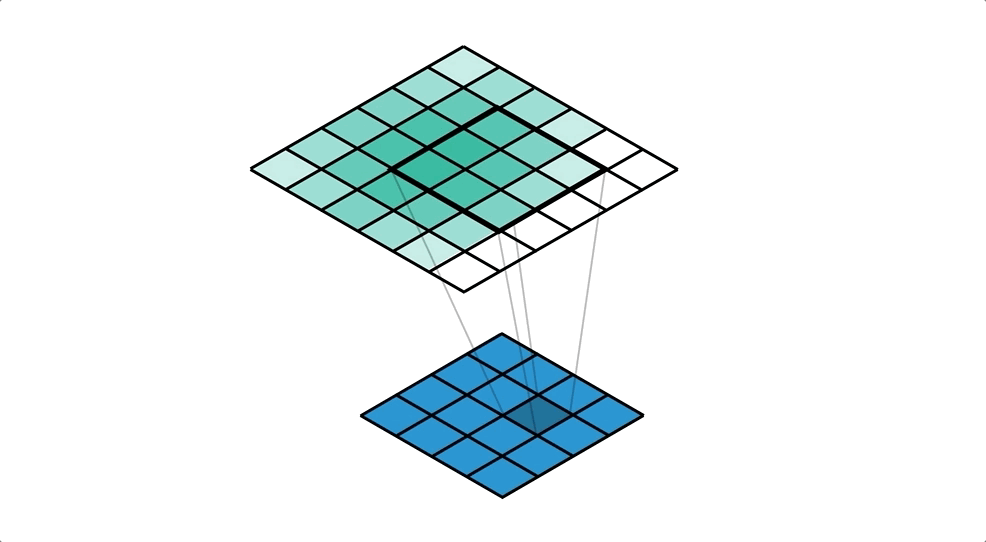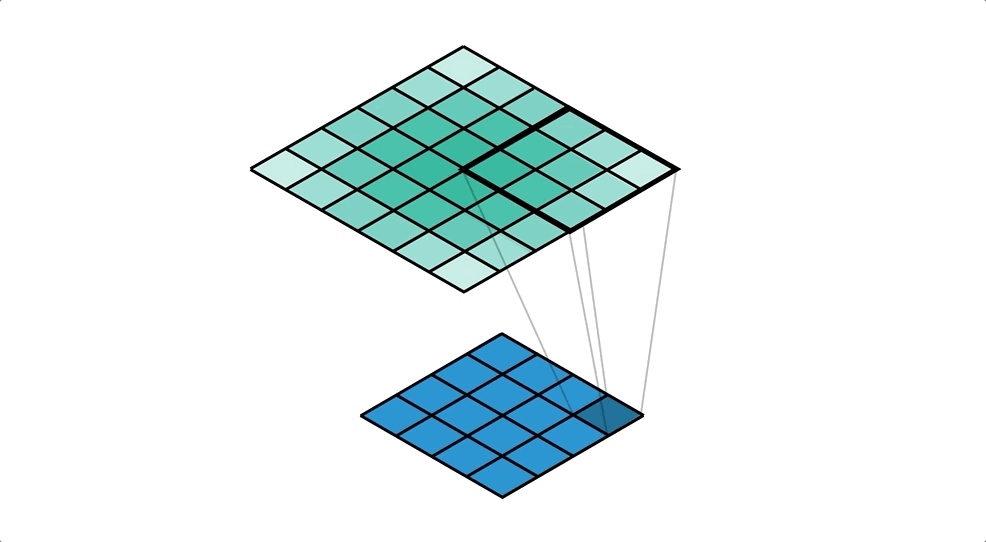
좌측 convolutional network는 5x5의 input에 3x3의 kernel을 사용하여 3x3의 output을 출력한다. 반면
우측 Transposed Convolutional Network는 4x4의 input과 3x3의 kernel을 통해 6x6의 output을 출력한다.
DCGAN은 Generator의 구조에 우측의 Transposed Convolutional Network를 사용하였다.
하지만 단순히 CNN으로 변경하는데 있어서 좋은 성능을 내지 못했다. 따라서 최적의 성능을 내기 위해 5가지 방법을 적용하였다.

1. 미분이 불가능한 Pooling Layer를 제거하고 미분 가능한 Convolution 레이어로 대체하였다. (Unpooling시 매우 이상한 사진을 생성한다 함)
2. BatchNormalization 레이어를 추가하였다.
3. fully-connected hidden layer를 삭제하였다.
4. 생성자 모델에 ReLU 함수를 적용하고 출력의 activation function은 Tanh로 설정하였다.
5. 마지막으로 판별자 모든 레이어에 LeakyReLU를 적용하여 유연성을 더하였다.
위와 같은 intensive한 실험을 통해 알아낸 최적의 generator 구조가 [그림 22]라고 할 수 있다.
DCGAN의 전체 아키텍처는 아래와 같다. [그림 24]의 실험을 통해 알아낸 방법을 적용한 결과를 나타낸다. (출처: Here)
2.3 실험 결과
DCGAN을 사용하여 모델을 학습 시켜 이미지를 생성한 결과는 다음과 같다.


얀르쿤의 GAN 모델보다 훨씬 더 다채롭고 가시적인 이미지를 생성하는 것을 확인할 수 있다.
위와 같은 이미지를 생성하기 위해 학습에 사용한 데이터셋은 LSUN(Large-scale Scene Understanding), ImageNet-1K, Face dataset이다.
아래는 판별자 모델의 필터를 시각화한 결과이다.

각각의 filter들이 침대나 창문과 같이 침실의 일부를 학습하였고, 필터 시각화를 통해 기존의 모델들이 Black Box였던 문제점을 해소하였다.
또한 보간(Interpolation)을 수행하여 이미지의 각도를 변경이 가능함을 보였다.
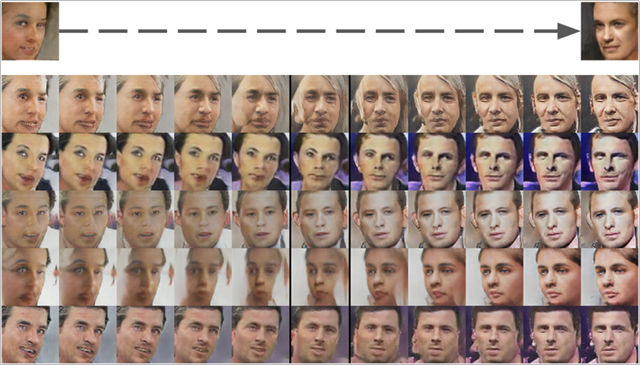
여기서 보간이란 수치해석학에서 사용되는 개념으로 두 점을 연결하는 방법이다. 보간을 사용하는 이유는 모든 점을 메모리에 올리면 비효율적이기 때문에 특징이 될 수 있는 점들만 대표적으로 메모리에 올려 계산하기 위해 사용된다. 종류에는 다항식 보간법, 스플라인 보간법, 라그랑지 보간법, 뉴턴 보간법 등의 여러 종류가 있다.
또한 DCGAN을 통해 벡터 산술 연산(Vector Arithmetic)이 가능함을 보였다.

선글라스 낀 남성 - 선글라스 벗은 남성 + 선글라스 벗은 여성 = 선글라스 낀 여성이다.
2.4 주요 Contribution
DCGAN은 크게 5가지 컨트리뷰션이 있다.
1. 대부분의 상황에서 언제나 안정적으로 학습하는 Convolution GAN 구조를 제안하였다는 점
2. word2vec과 같은 벡터 산술 연산이 가능하여 Generator를 semantic 수준에서 데이터를 생성할 수 있다는 점
3. 판별자가 학습한 필터들을 시각화하여 특정 필터들이 특정 물체를 학습했다는 것을 보였다는 점
4. 학습된 판별자 모델이 다른 비지도 학습 알고리즘과 비교해서 뒤쳐지지 않는 분류 성능을 보였다는 점
5. 마지막으로 모든 GAN 연구의 시작점이 될 수 있게 만들어준 연구라고 볼 수 있다.
3. LSGAN (Least Square GAN)
3.1 연구 배경
LSGAN의 경우 단순히 loss 값만 변경하여 성능을 끌어올린 GAN 모델이다. 연구 배경으로는 Sigmoid cross entropy loss가 Gradient Vanishing 문제를 일으킨다는 것이다. 따라서 Sigmoid cross entropy loss → Least Square loss로 변경하자는 것이 이 논문의 핵심이라 할 수 있다.
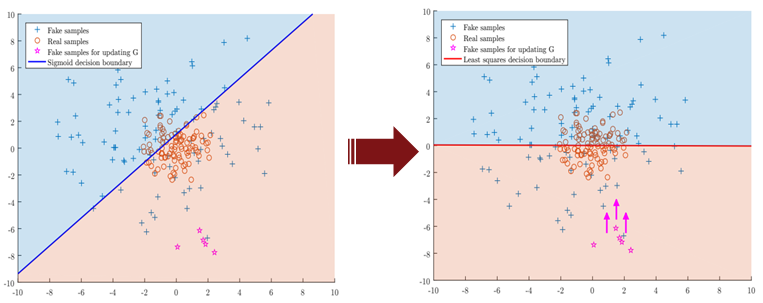
위 그림을 보면 분홍색 *(star)를 볼 수 있다. 분홍색 *는 Generator가 생성한 가짜 이미지라 보면 된다. 하지만 이 가짜이미지는 판별자를 속였고 때문에 더 이상 학습하지 않는(Gradient Vanishing) 것을 확인할 수 있다. 이 때 LSGAN 모델의 아이디어는 판별자를 속였더라도 더 정교하게 속이기 위해 실제 real과 동일한 수준으로 끌어올리자(추가 학습하자)는 것이다.
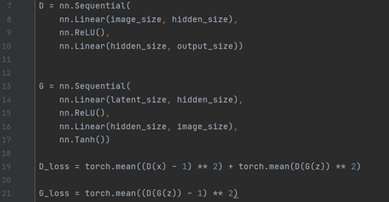
3.2 코드로 이해하는 LSGAN
기존의 GAN과의 가장 큰 차이점이라고 하면 아래와 같이 D의 loss 함수와 G의 loss 함수에 Least Square loss를 적용한 것이라 할 수 있다. (Cross Entropy loss → Least Square loss)
3.3 실험 결과
Original GAN보다 높은 퀄리티를 보이는 이미지를 생성하는 것을 확인할 수 있다.

이러한 이미지를 생성하기 위해 LSUN(풍경 데이터셋), CIFAR-10을 활용하였다.
주요 컨트리뷰션 포인트 중 첫 번째는 High Quaility라는 것이고 두 번째는 More Stable하다는 것이다.
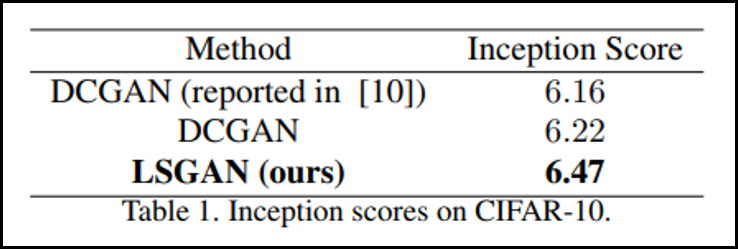
GAN을 평가하는 metric은 크게 두 가지 중 하나인 Inception Score가 Facebook에서 만든 DCGAN보다 뛰어난 성능을 보이는 것을 확인할 수 있다. (나머지 하나는 프리쳇 거리(Frechet Distance))
4. PGGAN (Progressive Growing GAN)
4.1 연구 배경
크게 2가지 단점을 극복하고자 PGGAN 모델이 만들어지게 되었다. 첫 번째로는 GAN을 고해상도로 만들면 판별자는 생성자가 생성한 이미지의 Real/Fake 여부를 구분하기 쉬워진다는 단점이 있고, 두 번째로는 고해상도로 만들어도 메모리 제약조건으로 batch size를 줄여야하고 줄이면 학습과정이 불안정해진다는 단점이 있었기 때문이다.
4.2 핵심 아이디어
PGGAN은 NVIDIA에서 진행한 연구이다. PGGAN의 핵심 아이디어는 4x4의 저해상도 이미지를 1024x1024 고해상도 이미지로 단계별(Progressive Growing)로 학습한다는 것이다.
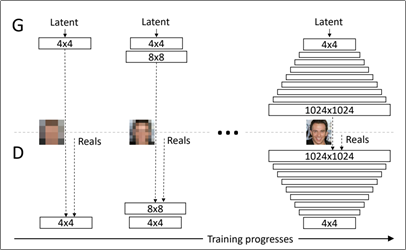

기존에는 처음부터 고해상도 이미지를 학습하려다 보니 학습이 올바르게 되지 않았다. 이는 초등생에게 처음부터 미적분을 묻는 것과 같다고 한다. 따라서 기본적인 사칙연산에 해당하는 4x4, 8x8, 16x16으로 점진적으로 학습하게 되면 계속해서 간단한 문제를 묻는 것과 같기 때문에 학습이 더 잘된다고 한다.
따라서 저해상도에서 보이는 Abstract을 우선적으로 학습 한 뒤 고해상도에서 보이는 Concrete(눈, 코, 입, 모공 등)를 학습하는 것이 특징이다.
이러한 PGGAN의 장점은 크게 3가지로 나뉜다.
1. 작은 이미지부터 점진적으로 학습하기 때문에 안정성 있다.
2. 처음부터 복잡한 질문을 하지 않기에 간단하다.
3. 저해상도에서 학습할 때 충분한 학습을 하게 되며 학습 시간이 짧다.
4.3 실험 결과
가장 처음 설명한 Original GAN의 결과와 비교했을 때 비약적으로 발전한 것을 느낄 수 있다.

위와 같은 이미지를 생성하기 위해 CelebA-HQ 데이터셋을 사용하여 30,000개의 유명인사 사진을 학습했다고 한다.
또한 PGGAN의 성능의 경우 Inception Score가 8.8에 달하는 것을 확인할 수 있다.

4.4 Contribution Point
PGGAN의 핵심 컨트리뷰션 포인트는 기존의 DEGAN, EBGAN, BEGAN 등이 128x128 이미지 밖에 생성하지 못했던 것을 1024x1024의 해상도까지 끌어올린 것이 핵심이라 할 수 있다.
5. SRGAN (Super Resolution GAN)
SRGAN은 Super Resolution GAN을 의미하는 것으로 한마디로 말하여 저화질의 이미지를 고화질의 이미지로 바꾸는 모델이라 할 수 있다.
5.1 연구 배경
기존의 SR 모델에서 목적 함수를 MSE (Mean Square Error)로 학습하여 높은 PSNR (Peak Signal-to-Noise Ratio)를 가진다. 하지만 High Frequency 성분을 갖는 detail이 결여되어 있기 때문에 Texture를 표현하는 것이 어렵다는 점을 극복하기 위해 진행 된 연구이다.

쉽게 말해 MSE는 이미지가 조금 흐릿한 형태를 띠게 되는데 이는 MSE loss function은 average(평균제곱오차)를 학습하기 때문이다. 전반적으로 smooth한 정보를 얻어서 high frequency content를 표현하지 못한다는 것이다. 다시 말해 평균을 loss로 잡았기 때문에 이미지의 고주파수 영역이 평균 값으로 회귀 된다는 의미이다.
5.2 PSNR
먼저 PSNR을 설명하면, 최대 신호대비 잡음비라고 할 수 있다. 구체적으로, 신호가 가질 수 있는 최대 전력에 대한 잡음의 전력이다. 주로 동영상이 압축될 때 화질 손실 정보를 평가할때 사용하는 지표로, 높을 수록 결과 값이 좋다 할 수 있다.

하지만 이러한 PSNR의 단점은 원본 이미지와 왜곡 이미지 사이의 수치적 차이로 평가하기 때문에 사람 인지와 일치되지 않는 품질 점수를 산출한다는 것이다. 예를 들면 아래 그림과 같다.

PSNR 값은 유사하지만 품질을 제대로 반영하지 못하는 것과 같다. 이는 PSNR을 산출하는 수식에 내재한 단점이라 볼 수 있다.
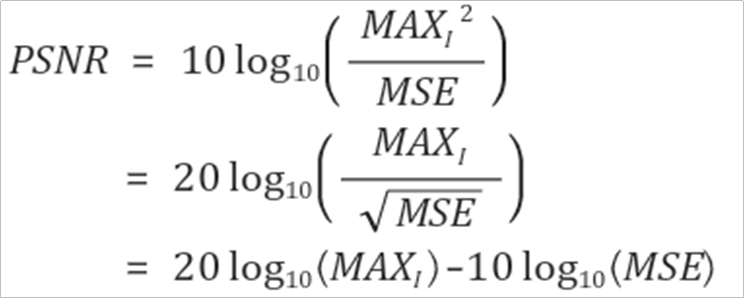
핵심은 맨 아랫줄만 확인하면 이해할 수 있다. PSNR은 MAX에 log scale을 취한 것에 MSE에 log scale을 취한 것을 빼준다. 하지만 앞서 언급하였던 MSE를 사용하기 때문에 이미지의 고주파수 영역을 나타내지 못하고 결과적으로 PSNR 값에 따른 이미지의 품질이 사람의 인지와 달라지는 것이다.
이러한 단점을 극복하기 위해 대안으로 사용하는 것은 SSIM, MOS, PSNR-HVS, PSNR-HVS-M, VIF 등이 있긴하다.

하지만 다시 SRGAN 모델로 돌아와서, 결과적으로 이 연구에서 하고자 하는 핵심은 해상도를 평가하는 PSNR이라는 수치는 높더라도 실제 사람의 눈으로 봤을 때 해상도가 높지 않다. 따라서 실제로 눈으로 보더라도 해상도가 높게 나올 수 있도록 만들겠다는 것이 이 연구의 핵심이라 할 수 있다.
5.3 연구 핵심
위와 같은 단점을 해결하기 위한 핵심 방안으로, 인지적 유사성에 주목한 perceptual loss를 사용하였다는 것이다. percepual loss는 크게 2가지인 content loss와 adversarial loss로 구성된다.
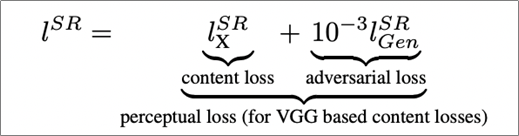
5.3.1 content loss
pixel space에서 유사성 대신에 perceptual 유사성을 학습하기 위한 loss이다.
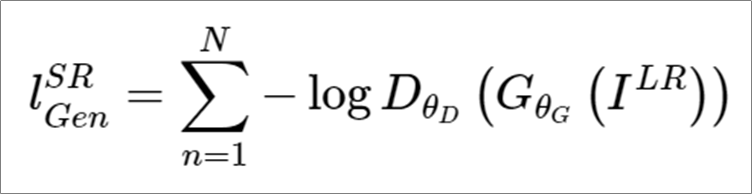
복잡할 것 없이 간단하게 이해하면 다음과 같다. LR(Low Resolution) 이미지를 즉, 저해상도 이미지를 생성자가 만들면 판별자가 판별할 것인데 N개를 판별한 합이 작아지도록 만드는 것이라 할 수 있다.
5.3.2 Adversarial loss
판별자를 속이기 위한 loss 함수라 할 수 있다.
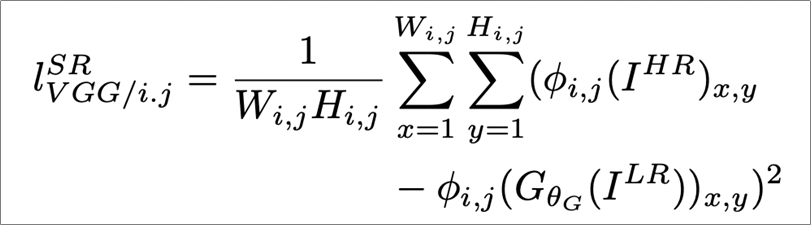
쉽게 간략히만 이해하면 HR(고해상도)의 이미지에서 LR(저해상도)의 이미지를 빼고 제곱을 취해준 값의 합이 점점 줄어들도록 학습하는 것이라 볼 수 있다.
5.4 아키텍처
논문에 언급된 아키텍처보다 더 직관적으로 설명되어 있는 그림을 확인할 수 있었고 아래와 같다.
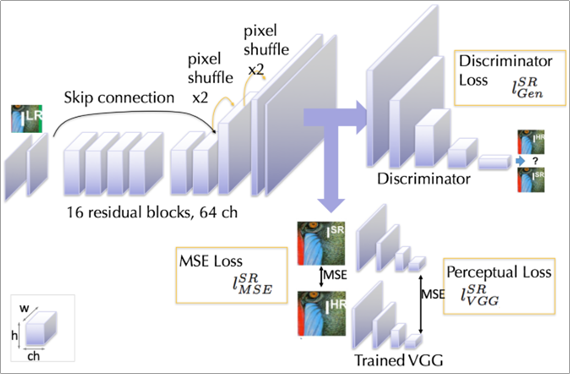
Pretrained된 2개의 VGG net loss를 사용한다. (reconstructed image와 reference image의 feature map 사이의 유클리디안 거리를 계산하는 방법을 사용) 여기에서 사용된 VGG22는 low level feature map을 대표하는 loss이며, VGG54는 high level feature map을 대표하는 loss라고 할 수 있다.
5.5 실험결과
평가 방법 중 MOS (Mean Opinion Score)를 사용하였는데 이는 Perceptual Quaility를 표현하기 위함이다.
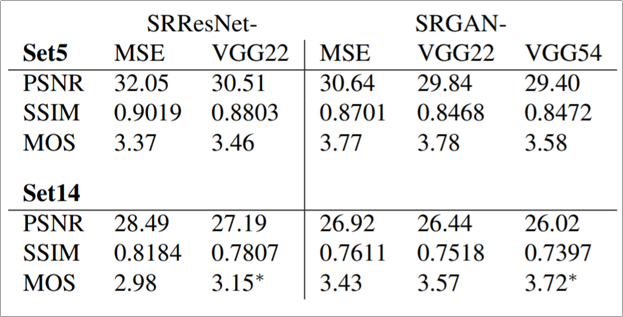
Set5와 Set14의 경우 데이터셋을 의미한다. 저자들은 MOS라고 하는 벤치마크 스코어를 사용하여 MSE를 사용하였을 때 보다 높은 MOS 스코어를 얻음을 보인다. 하지만 MOS라고 하는 것은 일종의 주관적인 평가로, 평가자 몇 명을 모집하여 사용하는 방식이라는 점에 있어서 정량적이라기 보다 정성적인 평가에 가깝다고 볼 수 있다.
주요 컨트리뷰션 포인트로는 크게 2가지로, 첫번째는 새로운 perceptual loss를 제안하였다는 점이고 두 번째로는 모호하지만 새로운 벤치마크 스코어인 MOS를 제안하였다는 것이다.
참고로 VGG54를 저자들은 SRGAN이라고 부른다.
5.6 적용 결과
저자들은 유튜브에 자신들이 만든 SRGAN을 이용한 영화 화질을 높이는 것을 보였다.
5.7 국내 연구 사례


또한 이러한 SRGAN을 사용하여 CCTV 영상의 화질을 개선하는 기법을 연구한 국내 연구 사례도 존재한다. 하지만 그럴듯하게 생성이 가능하다는 것이지 법적인 증거로서의 효력으로 채택되는 것은 별 개의 문제가 될 수 있겠다.
6. CycleGAN
6.1 연구 배경
CycleGAN 모델을 만든 저자는 한국인으로 이전의 pix2pix라는 연구의 확장이 CycleGAN이라 할 수 있다.

CycleGAN은 특정 화풍, 질감을 다른 사진에 적용할 수 있는가에 대한 질문에 답을 하기 위해 만들어진 모델이라 할 수 있다.
6.2 핵심 아이디어
특징이 겹치지 않는 서로 다른 이미지 집합(Unpaired)을 학습하기 위해 순환 일관성 손실 함수(Cycle Consistency)를 사용하였다는 것이다.
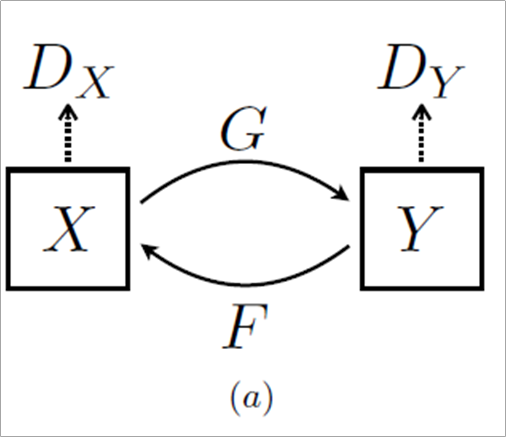
일종의 역함수라고 할 수 있다. 하지만 G를 통해 변환한 것이 F를 통해 재 변환될 때 원본과 최대한 가까워 지도록 loss 값을 설정하여 학습하는 것이라 할 수 있다.
참고로 Paired는 x좌표 값이 y좌표 값에 대응되는 정보가 담기지만 Unpaired는 대응되는 정보가 존재하지 않는 것이 특징이다.
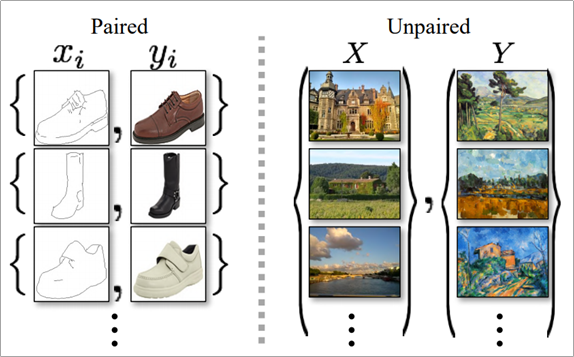
paired의 경우 pix2pix 모델에서 사용했다 할 수 있고 unpaired의 경우 cycleGAN에서 사용하였다.
이러한 unpaired dataset에서의 translate를 위해 사용한 함수는 순환 일관성 손실함수인데 그 전체는 아래와 같다.
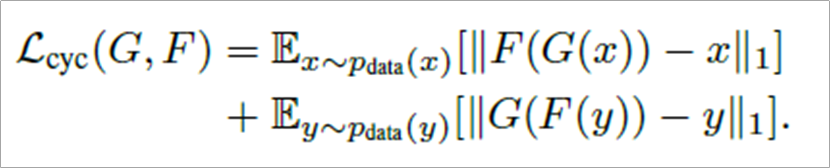
크게 어려울 것 없다. 역함수를 통해 나온 값이 만약 x'라면(strict하지 않기 때문에 x'가 나옴) x와의 차이가 줄어들도록 loss 값을 설정한 것이다. 마찬가지로 y'가 나온다면 y와의 차이 값이 줄어들도록 만든것이 순환 일관성 손실함수라 할 수 있다.
6.3 실험 결과

CycleGAN 모델의 실험 결과로 좌측의 Input 값을 넣으면 우측의 모네, 반고흐 등의 화풍으로 바꿔주는 것을 확인할 수 있다.
또한 CycleGAN에서는 실제 위성사진을 지도로 바꿔주고 지도를 실제 위성사진으로 얼마나 잘 바꾸어주는 가에 대한 실험도 하였고 아래 그림과 같다.

어색하거나 엉뚱한 결과를 내는 다른 모델들에 비해 Ground truth와 가장 유사한 그림을 만들어내는 것을 확인할 수 있다.
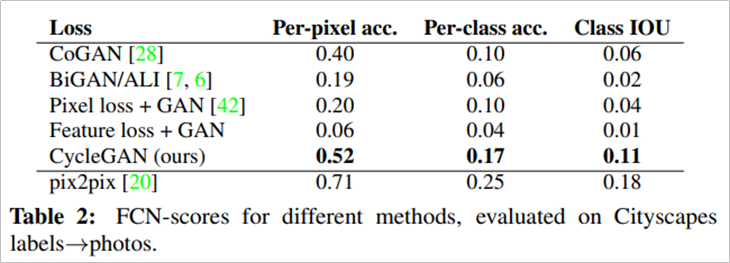
이러한 CycleGAN을 평가하기 위한 평가 메트릭으로는 AMT와 FCN-Score를 사용하였다.
AMT: 사람에게 어떤 것이 진짜인지 평가하는 방식으로 별도의 Metric이 없는 GAN에게 가장 강력한 점수
FCN Score: YOLO와 같은 객체 탐지 모델을 사용해 변환된 이미지에서 얼마나 사물을 잘 인식하는가?

CycleGAN이 다른 모델들에 비해 Map→Photo, Photo→Map에서 가장 우수한 성능을 보이는 것을 확인할 수 있다.
또한 FCN Score에서도 마찬가지로 CycleGAN이 다른 모델들과 비교하여 뛰어난 성능을 보이는 것을 알 수 있다. (pix2pix은 저자의 연구실에서 하던 이전 연구)
6.4 한계점
색상이나 질감은 변경할 수 있으나 객체의 모양은 바꿀 수 없는 것이 단점이다. 이는 여러 장의 데이터를 학습하여 분위기(화풍, 질감) 변경에만 초점을 두기 때문이다.

6.5 Contribution Point
주요 컨트리뷰션 포인트는 기존의 pix2pix 모델에 순환일관성 손실함수를 도입하여 unpaired한 데이터셋에서도 동작하게 만들었다는 것이 핵심이라 할 수 있다.
7. StarGAN
7.1 연구 배경
기존의 연구들은 image-to-image translation을 위해서 이미지 도메인 쌍을 학습해야 했다. 이러한 결과로 모델의 scalability와 robusteness가 떨어진다는 단점이 있었다.
여기서 도메인이란 이미지의 표정 변화, 이미지의 성별 변화, 이미지의 피부 색 변화 등을 의미한다.
따라서 StarGAN은 특정 도메인에 국한하지 않고, 하나의 Generator에서 다른 도메인으로 Transfer 할 수 있도록 만들었다는 것이다.
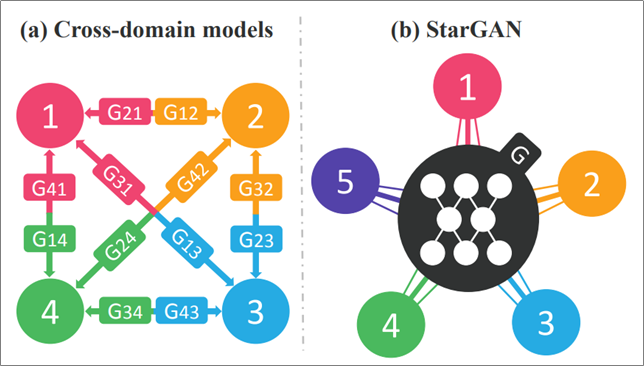
처음에는 StarGAN이라는 이름에서 유명인사를 의미하는 줄 알았으나 성(Star)형으로 모델을 구성하여 일종의 Transfer Learning이 가능하도록 만들었다는 것이다. 저자들은 Facial attribute transfer와 Facial expression synthesis task에서 경험적으로 효과가 있는 것을 확인하였다고 한다.
7.2 아키텍처
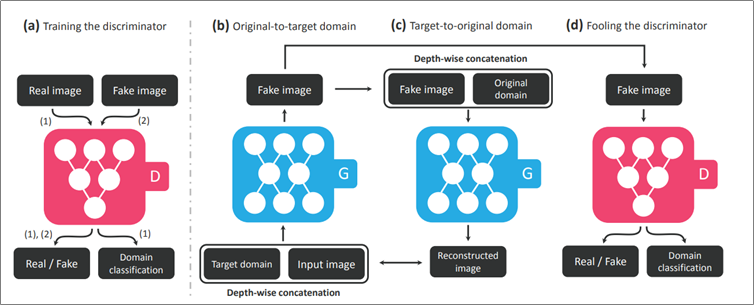
핵심만 간단하게 이야기하면 (a)의 Training the discriminator에서 기존 GAN처럼 Real/Fake만 출력하는 것과 달리 어떤 Task인지에 대한 Domain 정보까지 분류하도록 만들었다는 것이다. D는 결국 이미지와 도메인의 두 개의 확률 분포를 만들어낸다 볼 수 있다.
7.3 실험 결과


전반적으로 맨 아래의 StarGAN을 이용하면, 다른 여러 모델을 사용하여 Domain Transfer한 결과들 보다 가장 자연스럽게 나온다는 것을 확인할 수 있다.
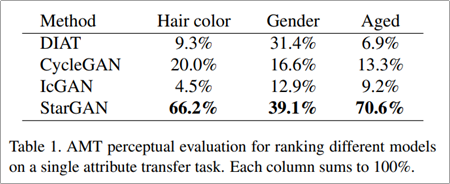
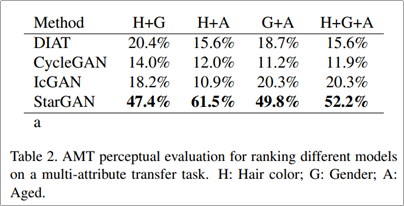
StarGAN은 AMT 평가 메트릭에서 single attribute transfer에 있어서 가장 높은 성능을 보이는 것을 확인할 수 있고 multi attribute transfer에 있어서도 가장 높은 성능을 보이는 것을 확인할 수 있다.
또한 저자들은 Facial attribution transfer와 Facial Expression synthesis에서 정성적/정량적 두 측면 모두 superity를 달성했다고 말한다.
7.4 Contribution Point
핵심 컨트리뷰션은 모든 도메인 사이에서 학습하는 새로운 GAN 모델이며, 단일 생성자와 판별자로만 가능하게 만들었다는 것이다.
부수적으로는 Mask Vector라는 것을 사용하여 여러 데이터셋 간의 모든 도메인 사이에서의 이미지 변환 학습을 어떻게 해야하는지 보였다는 것이다. 여기서 Mask Vector란 모델이 모르는 라벨은 무시하고 확실히 아는 라벨에만 집중하는 것이라고 한다.
8. 평가 지표
GAN 모델이 생성한 이미지의 품질을 평가할 수 있는 여러 메트릭이 존재하며 그 메트릭의 종류는 아래와 같다. (출처: Here)
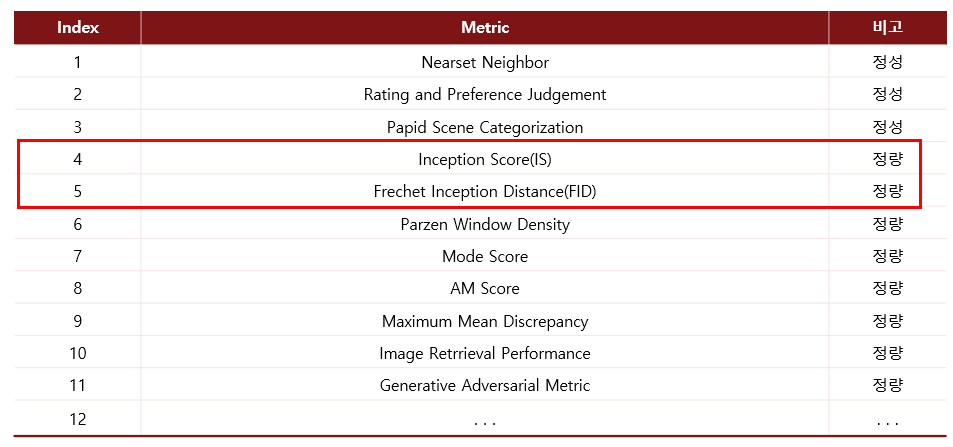
여러가지가 있지만 주로 크게 2개만 사용한하며 그것은 Inception Score(IS)와 Frechet Inception Distnace(FID)이다.
8.1 Inception Score (IS)
IS의 성능 평가기준 크게 2가지 이다.
- 생성된 이미지의 퀄리티 (Fidelity)
- 생성된 이미지의 다양성 (Diversity)
계산 방법은 Pretrained된 Inception 모델에 Real/Fake 데이터를 넣어 KL-Divergence를 계산한다고 한다.
이를 수식으로 이해하면 아래와 같다.
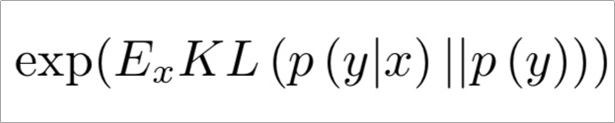
p(y|x)와 p(y)의 차이를 KL-Divergence로 측정하는데 두 분포가 크게 다르면 값이 커지는 지표이다. 쉽게 말해 두 확률분포의 차이를 계산하는데 사용하는 함수이다.
분류 모델에 이미지를 입력할 경우 높은 확률로 클래스를 예측한다면 생성 이미지(Fake)와 실제 이미지(Real)와 비슷하다 할 수 있다 이는 p(y|x)로 측정이 가능하다. 그리고 p(y|x)에서 x로 적분한 p(y)가 평등한 분포라면 생성된 이미지가 다양성을 갖고 있다 말할 수 있다. 이러한 두 가지 관점으로 생성된 이미지(Fake)를 평가하는 것이 IS이다. (출처: Here)
p(y|x): 주어진 input x에 대해 label y의 확률 분포
p(y): label 들의 확률 분포
이에 대한 이해도를 높이기 위해서는 아래의 공돌이의 수학정리노트라는 블로그에서 직접 변화를 관찰할 수 있다. (Here)
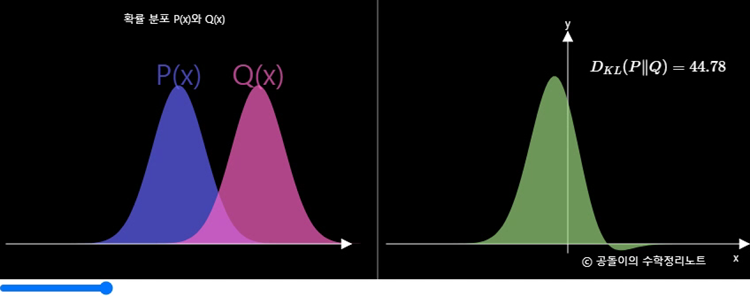
하지만 이러한 IS의 경우 생성된(Fake) 이미지만 사용하기 때문에 실제 이미지와 비교하지 못한다는 단점이 있다.
이를 보완하기 위해 나온 메트릭이 FID라고 할 수 있다.
8.2 Frechet Inception Distance (FID)
IS의 단점을 개선하기 위해 고안된 지표로, 두 분포 사이의 거리를 측정하는데 사용되는 방법이다.
1. 분류 모델에 따라 실제 이미지와 생성된 이미지의 특징량을 추출한다.
2. 특징량이 정규분포를 따른다 가정 후 그 분포 사이의 거리를 측정한다.

ur과 cr: 각각 실제 이미지에서 추출된 특징량의 평균과 공분산을 의미한다.
ug와 cg: 각각 생성 이미지에서 추출된 특징량의 평균과 공분산을 의미한다.
inception 네트워크의 중간 layer에서 feature를 추출하고 feature에서 평균과 공분산을 추출하고 계산한다.
FID 값이 낮으면 Real/Fake가 유사하다고 판단한다.
단점은 표본의 분포가 정규분포가 아닐 경우 제한적인 통계량(평균, 분산)만으로는 분포의 차이를 잘못 설명할 수 있다는 점이 있다.
9. GAN 모델 구현
https://github.com/eriklindernoren/Keras-GAN에서 GAN 모델을 구현한 코드를 제공하고 있으니 GAN에 관심이 있다면 참고하길 바란다.
12. GAN 활용 사례
실생활에서 사용되고 있는 GAN으로는 NAVER에서 웹툰에 GAN을 적용하여 몰입형 웹툰을 선보이기도 한다.
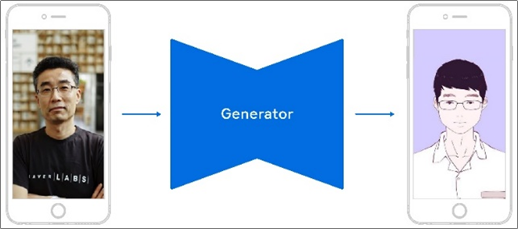
또한 PULSE9의 딥리얼 AI는 가상 인물 자동화 서비스를 제공한다. 20년간 활동한 국내 아이돌 이미지 데이터를 수집하여 가상의 101명의 아이돌을 만든다고 한다.

한국전자통신연구원(ETRI)에서는 SNS 트렌드를 분석해 6M장의 DB로 개인 취향의 패션상품 제작을 돕는 서비스를 개발한다고 한다.

패션영상 다중 정보 추출, 디자인 생성 & 스타일 변환, 착장 영상 자동 생성 등
또한 MyHeritage에서는 딥 노스텔지어라고 하여 정지된 사진에 생명을 불어 넣는 AI 서비스도 제공하고 있다.


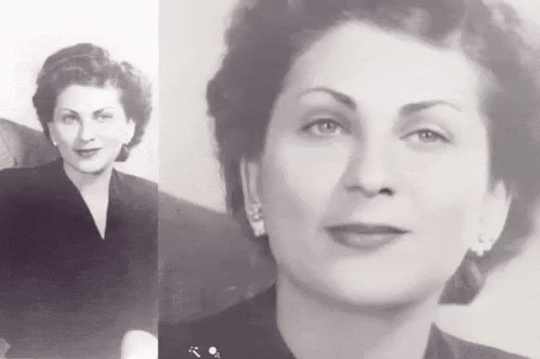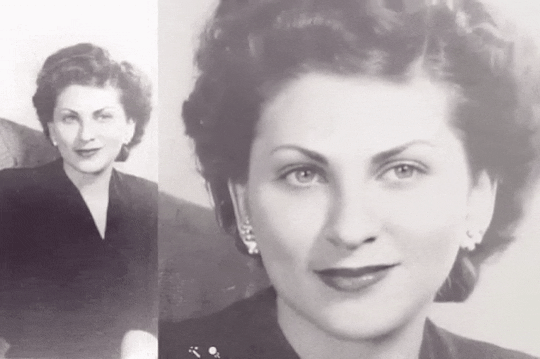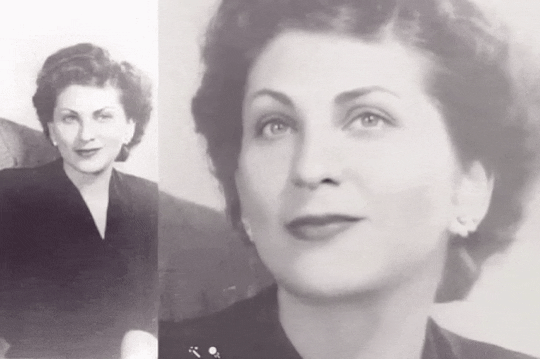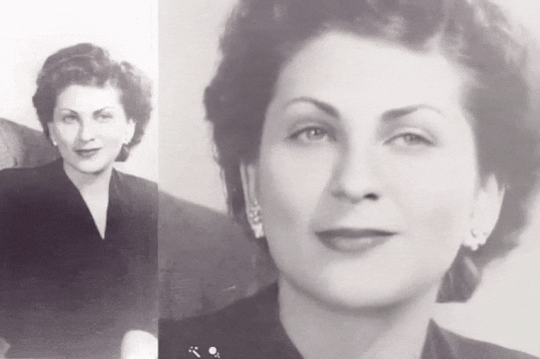
앞으로의 GAN의 미래는 어떻게 되고 세상은 어떻게 변할까? 특이점이 온다의 저자인 레이 커즈와일은 기술의 발전속도는 기하급수적으로 바뀌어 2045년이 되면 기계가 인간을 뛰어넘는 세상이 온다고 하였다. 최근 Google, Facebook, OpenAI, NAVER 등의 기업에서 눈부신 연구들이 이루어지고 있고 커즈와일이 예측한 미래는 점점더 현실로 가까워져 가는 것이 느껴진다. 아직도 헤쳐나가야 할 요소들이 많겠지만 21세기 안에는 더욱이 비약적인 발전들이 이루어질 것이라는 강한 확신이 든다. 그렇다면 전례없이 빠르게 변화하는 지금의 시대에 나라는 사람은 후대를 위해 어떤 가치를 창출 할 수 있을지 많은 고민이 든다.
Reference
[2] https://ysbsb.github.io/gan/2020/06/17/GAN-newbie-guide.html
[3] https://www.youtube.com/watch?v=odpjk7_tGY0&ab_channel=naverd2
[5] https://github.com/nightrome/really-awesome-gan
[6] https://generated.photos/face-generator/new
[7] http://www.aitimes.com/news/articleView.html?idxno=137405
[8] https://www.bloter.net/newsView/blt201806080001
[9] https://www.samsungsds.com/kr/insights/Generative-adversarial-network-AI.html
[10] https://aigong.tistory.com/51
'Artificial Intelligence > 머신러닝-딥러닝' 카테고리의 다른 글
| [머신러닝/딥러닝] Ubuntu 20.04에 딥러닝 환경 설치 (0) | 2021.11.02 |
|---|---|
| [컴퓨터 비전] 핀홀 카메라 (0) | 2021.10.20 |
| Attention is all you need (Transformer) (0) | 2021.09.09 |
| [인공지능 이론] Manifold Learning (3) | 2021.09.08 |
| 합성곱 신경망 (Convolutional Neural Network, CNN) (0) | 2021.09.08 |